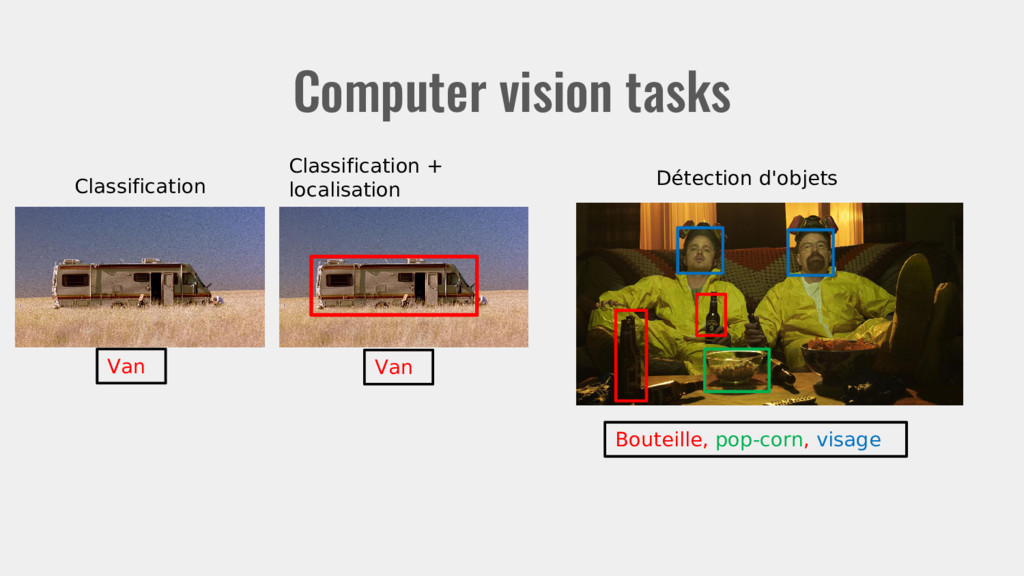
Une lampe Une statuette Un visage Reconnaissance de voix Ok Google! Traitement langage naturel Who is Hamlet's uncle? Conduite autonome Tout droit? Jeux Quel coup ?
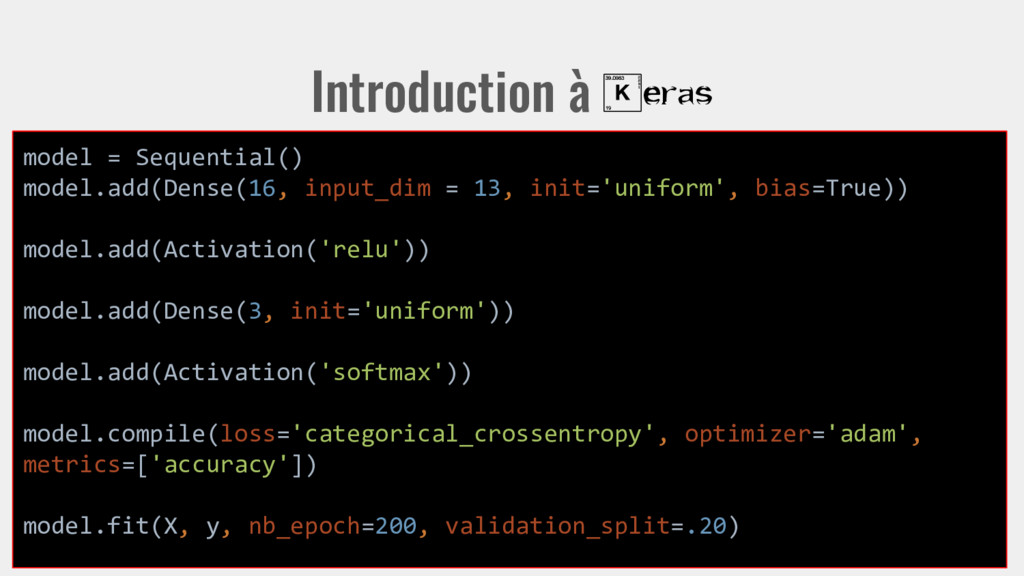
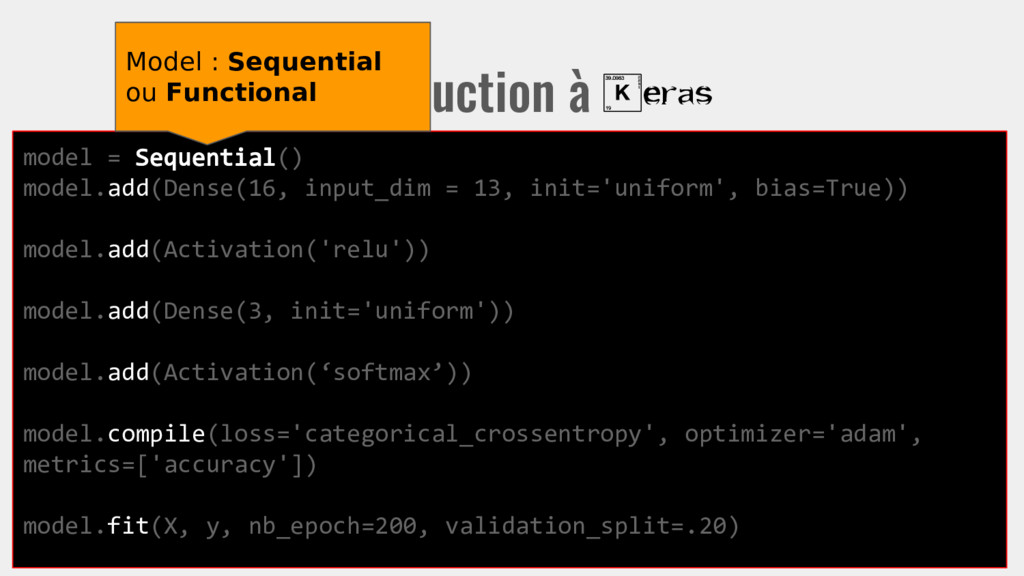
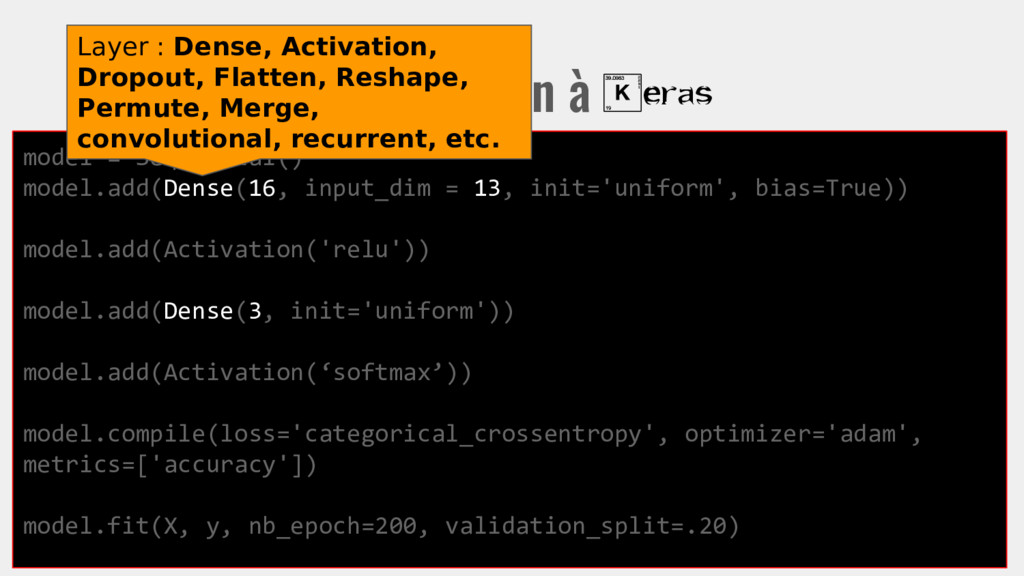
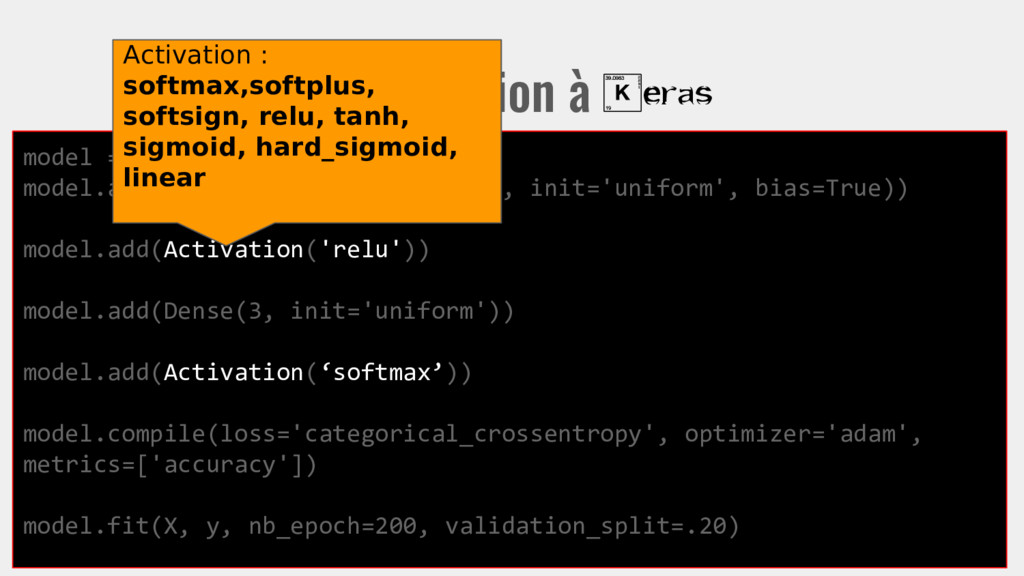
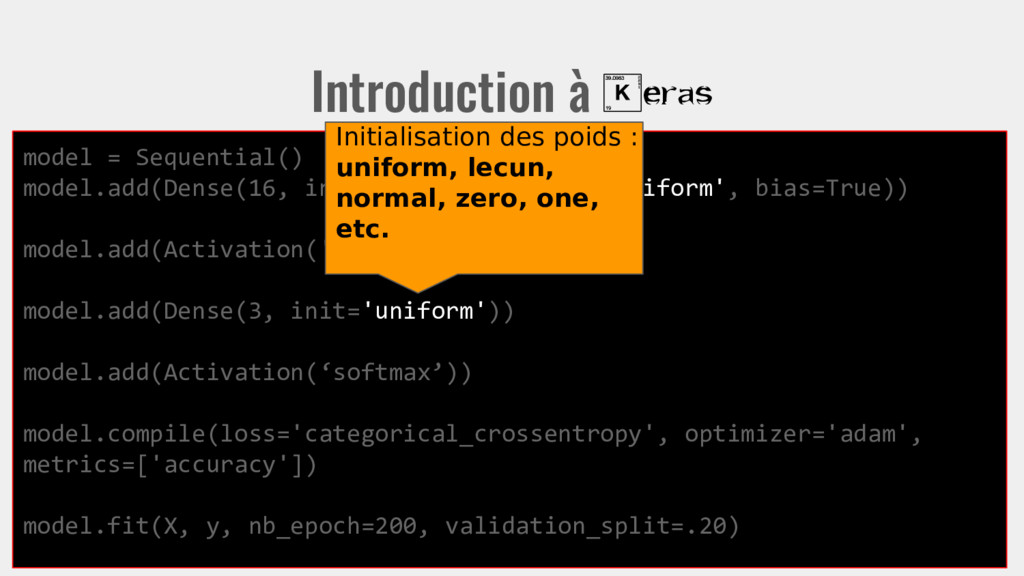
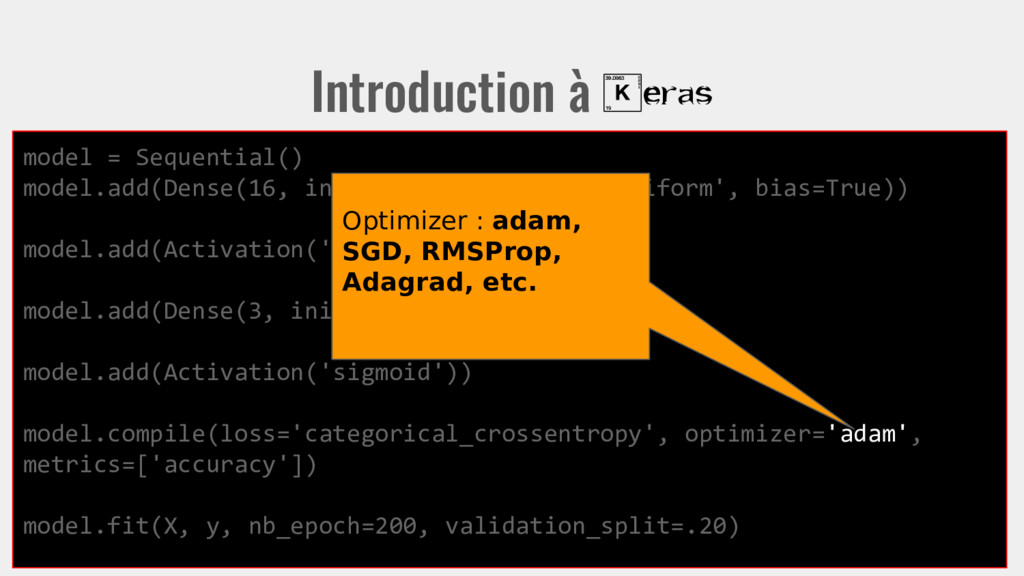
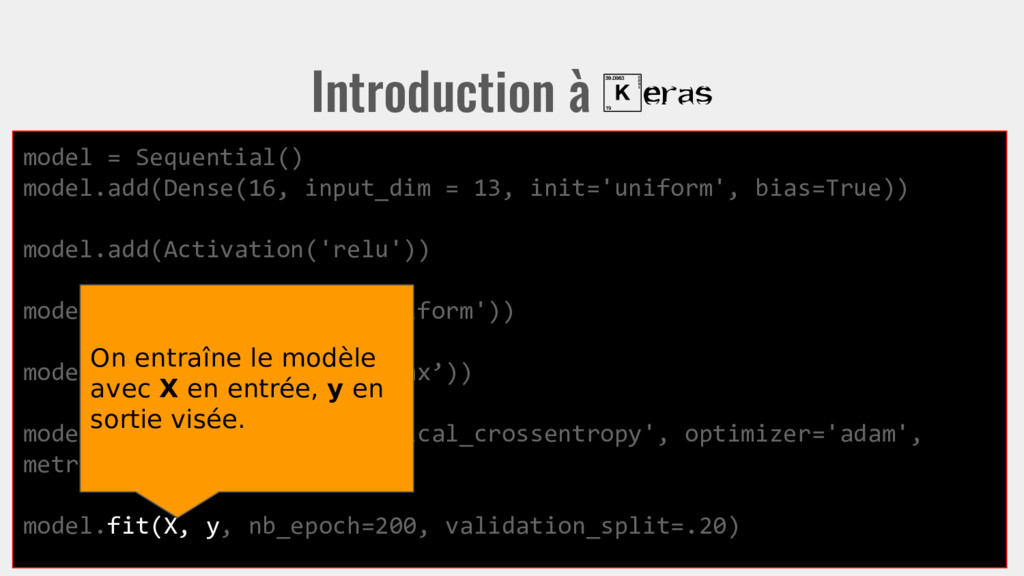
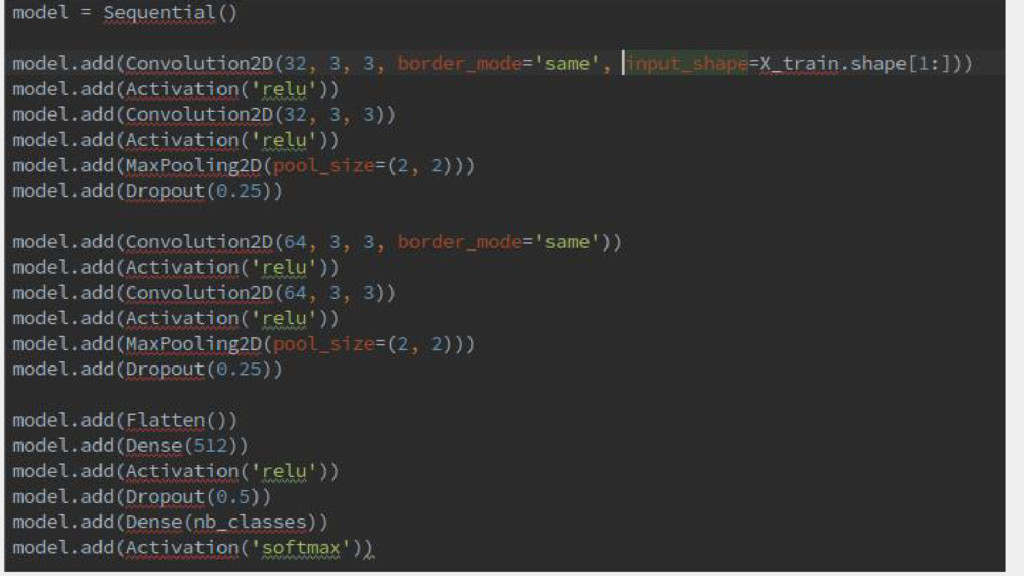
init='uniform', bias=True)) model.add(Activation('relu')) model.add(Dense(3, init='uniform')) model.add(Activation(‘softmax’)) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, y, nb_epoch=200, validation_split=.20) On entraîne le modèle avec X en entrée, y en sortie visée.
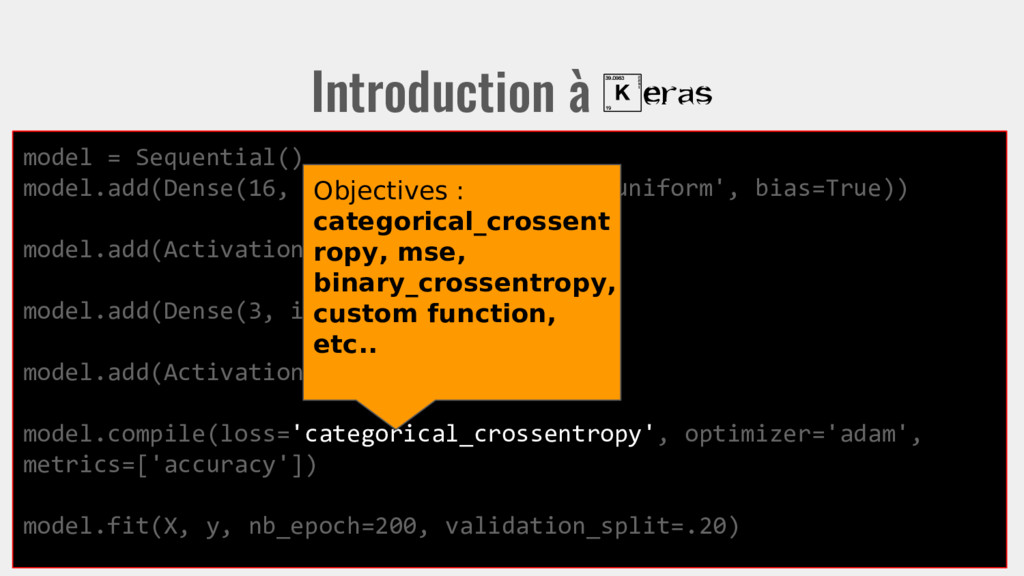
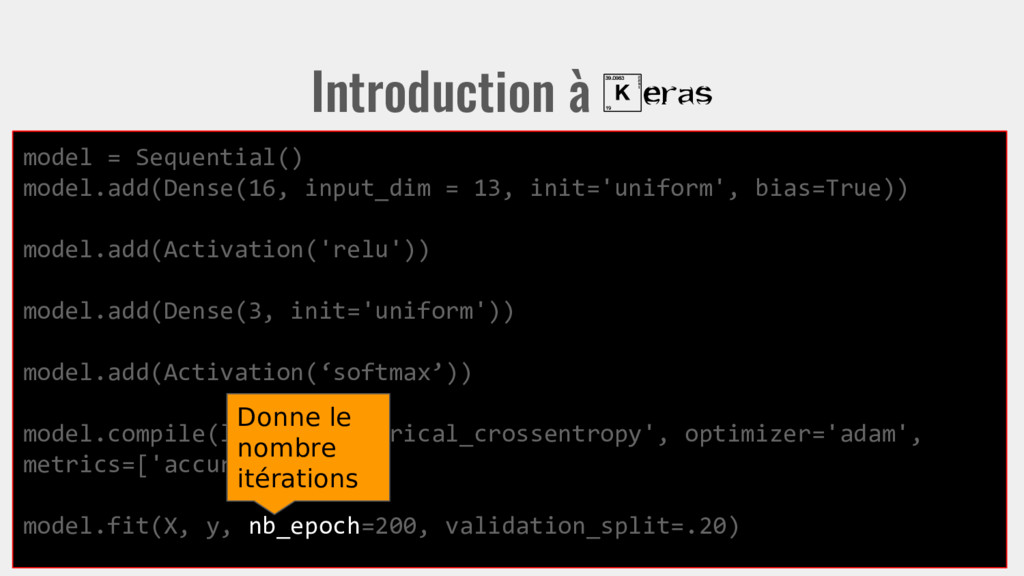
init='uniform', bias=True)) model.add(Activation('relu')) model.add(Dense(3, init='uniform')) model.add(Activation(‘softmax’)) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, y, nb_epoch=200, validation_split=.20) Donne le nombre itérations
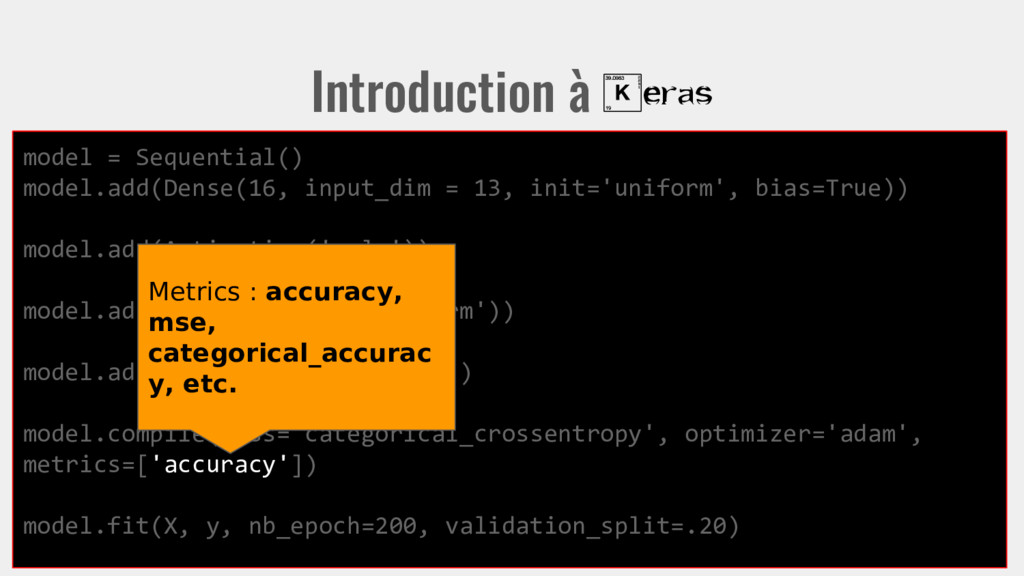
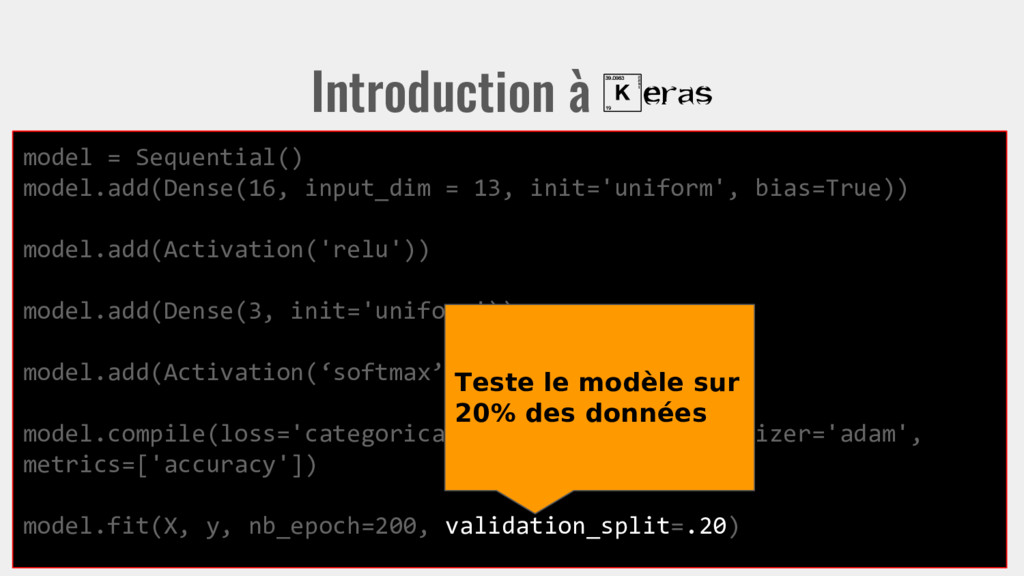
13, init='uniform', bias=True)) model.add(Activation('relu')) model.add(Dense(3, init='uniform')) model.add(Activation(‘softmax’)) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, y, nb_epoch=200, validation_split=.20) Teste le modèle sur 20% des données
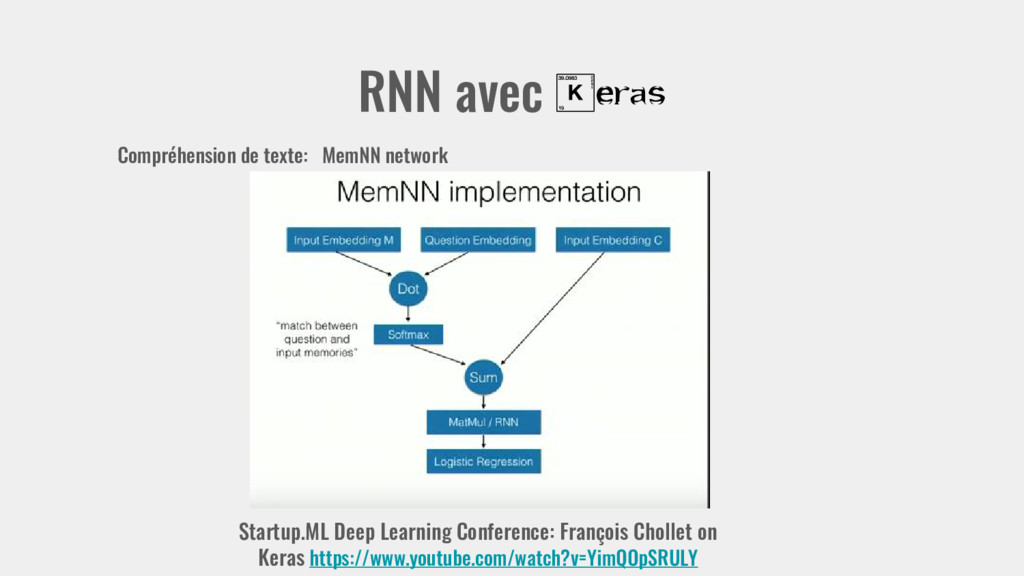
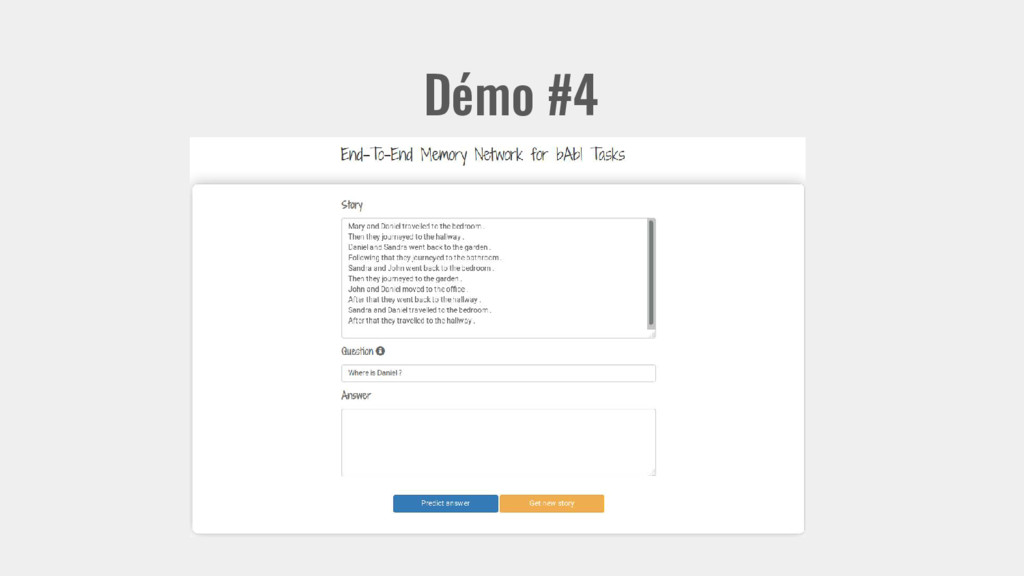
dataset (https://research.fb.com/projects/babi/) John travelled to the hallway. Walt journeyed to the bathroom. Daniel went back to the bathroom. John moved to the bedroom. Where is Walt? → bathroom Startup.ML Deep Learning Conference: François Chollet on Keras https://www.youtube.com/watch?v=YimQOpSRULY Single fact
dataset (https://research.fb.com/projects/babi/) Startup.ML Deep Learning Conference: François Chollet on Keras https://www.youtube.com/watch?v=YimQOpSRULY Jesse is thirsty. Where will Jesse go? kitchen Jesse journeyed to the kitchen. Why did Jesse go to the kitchen? → thirsty Motivations
dataset (https://research.fb.com/projects/babi/) Startup.ML Deep Learning Conference: François Chollet on Keras https://www.youtube.com/watch?v=YimQOpSRULY Mary and Daniel went to the bathroom. Then they journeyed to the hallway. Where is Daniel? →hallway Associations
# output shape: (samples, 64) question_encoder = Sequential() question_encoder.add(Embedding(input_dim=vocab_size, output_dim=64)) question_encoder.add(LSTM(64, return_sequences=False)) # output shape: (samples, 64) model = Sequential() model.add(Merge([input_encoder, question_encoder], mode='concat',concat_axis=-1)) # output shape: (samples, 64*2) model.add(Dense(vocab_size)) model.add(Activation('softmax')) # output a probability distribution over all words model.compile(optimizer='adam', loss='categorical_crossentropy') print 'Training - reporting test accuracy after every iterations over the training data...' model.fit([inputs_train, queries_train], answers_train, batch_size=32, nb_epoch=50, show_accuracy=True, validation_data=([inputs_test, queries_test], answers_test)) Startup.ML Deep Learning Conference: François Chollet on Keras https://bitbucket.org/fchollet/keras_workshop
(avec ou sans poids) au format HDF5 • Import des modèles Keras vers Deeplearning4j • Distribution • GPU / Instances avec Tensorflow • Spark ( https://github.com/maxpumperla/elephas )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}