Share
Présentation "SMACK my data up!" donnée au SnowCamp.io 2018 par Logan Hauspie (@lhauspie) et Manuel Verriez (@mverriez).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
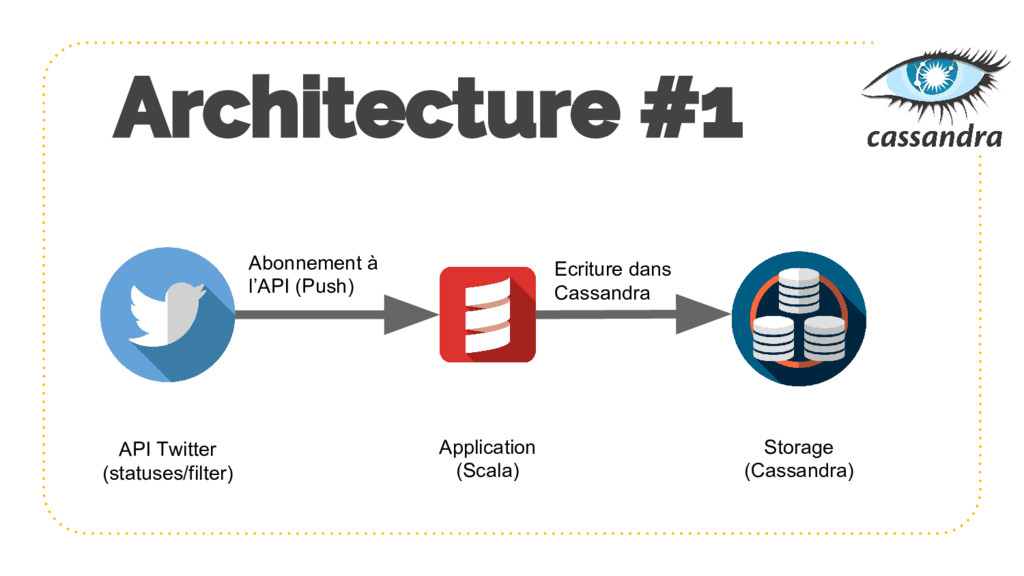{kind=link}
{kind=link}
{kind=link}
{kind=link}
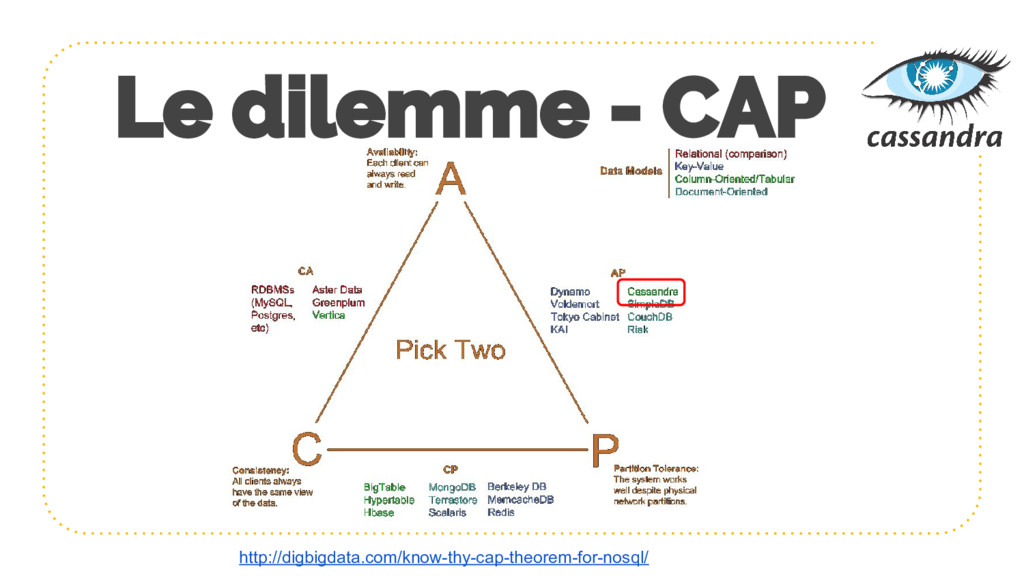{kind=link}
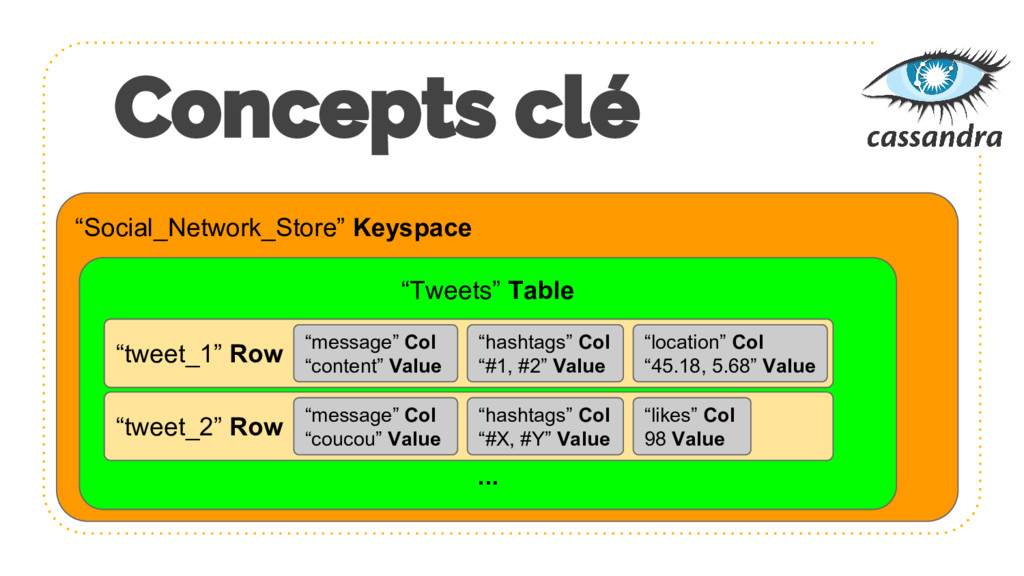{kind=link}
!["tweet":{ "id":951092652749021184, "createdAt":1515593133000, "lang":"en", "user":{...}, "text":"[...] #digital #trends", "hashtagEntities": [](https://files.speakerdeck.com/presentations/ab2c80f43d6b4b5b8a3bd134c9c9426f/slide_12.jpg){kind=link}
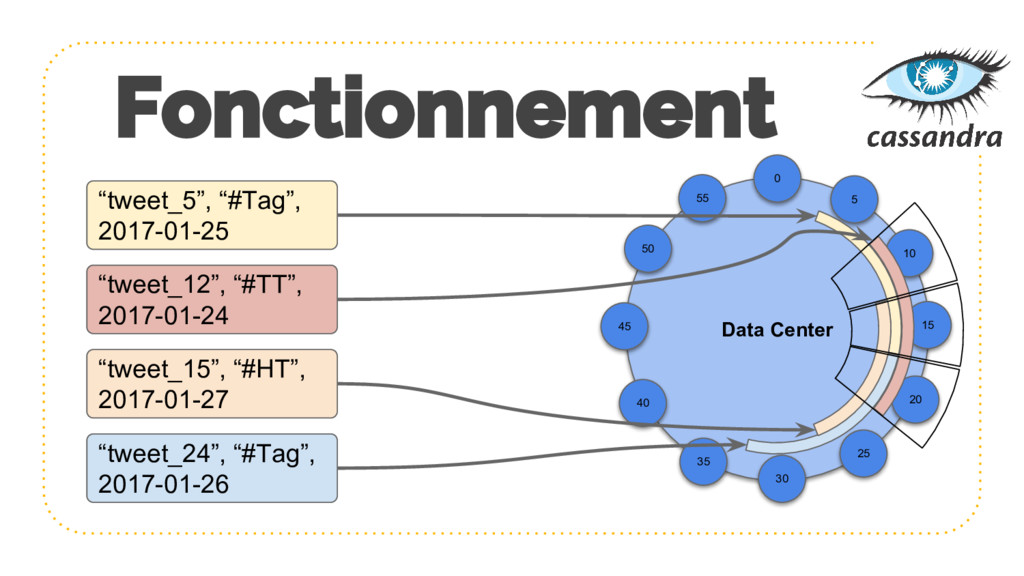{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
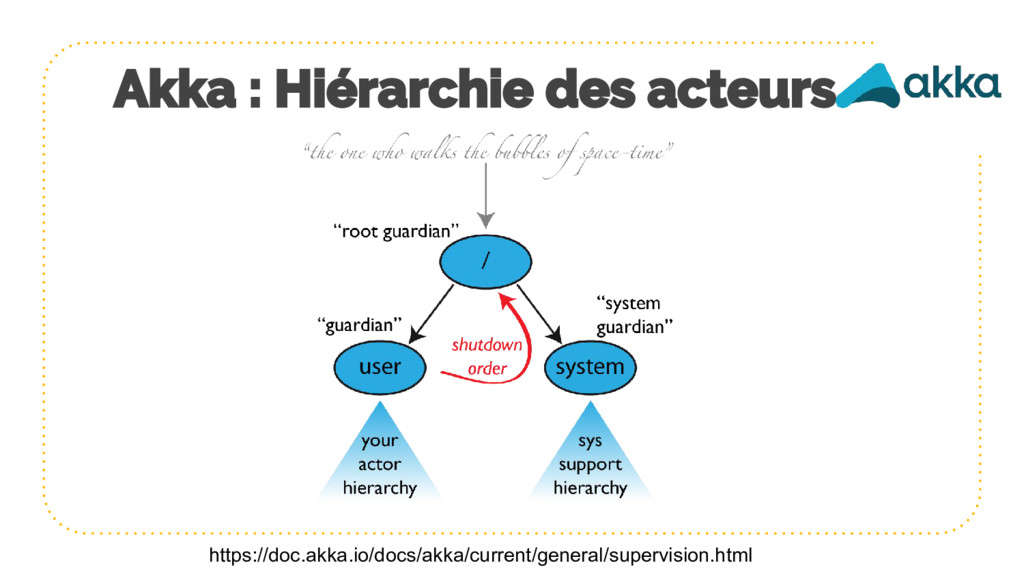{kind=link}
{kind=link}
{kind=link}
{kind=link}
![override def receive:Receive = { case query:Seq[String] => twitterStream.filter(query:_*) case](https://files.speakerdeck.com/presentations/ab2c80f43d6b4b5b8a3bd134c9c9426f/slide_38.jpg){kind=link}
{kind=link}
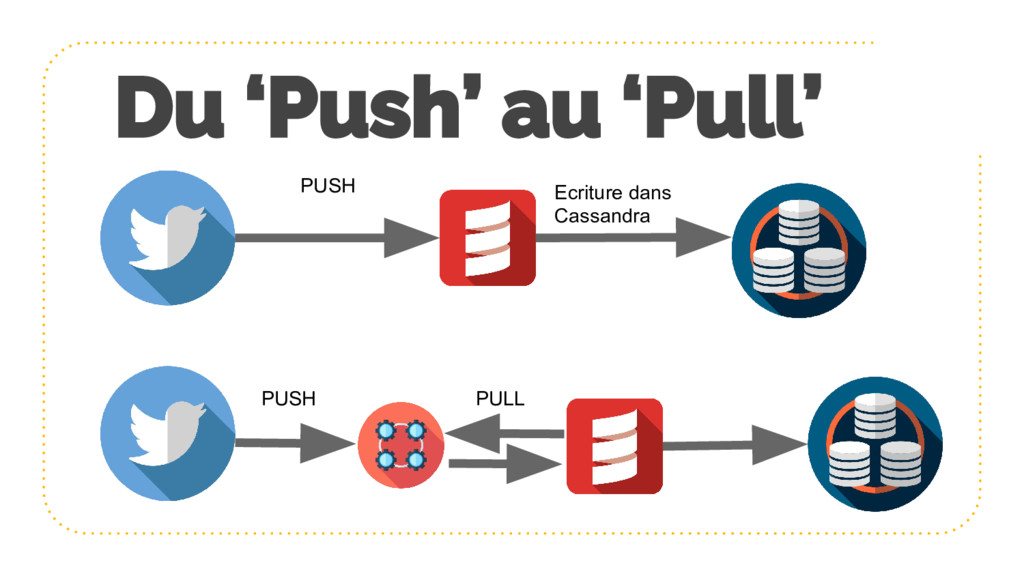{kind=link}
{kind=link}
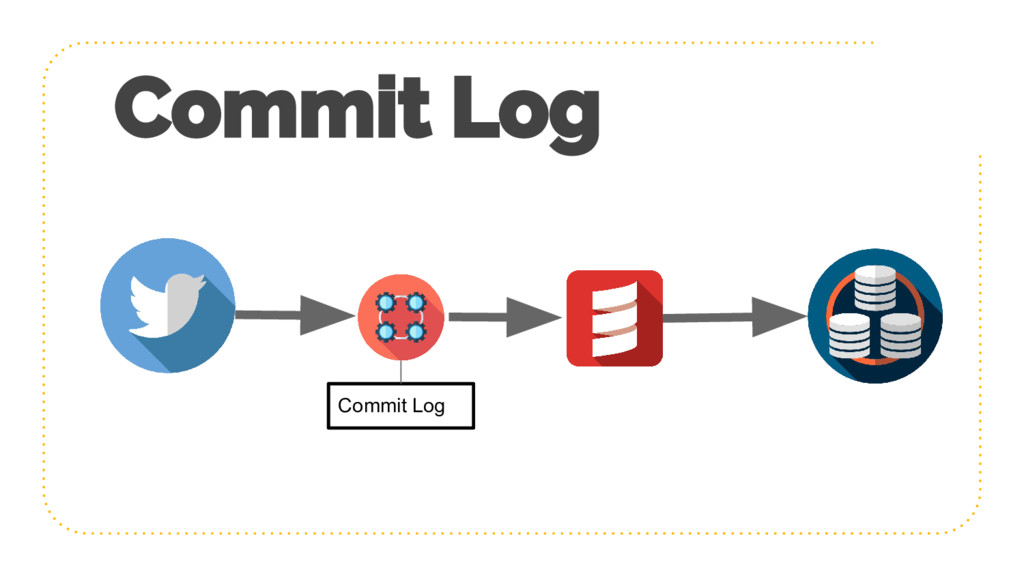{kind=link}
{kind=link}
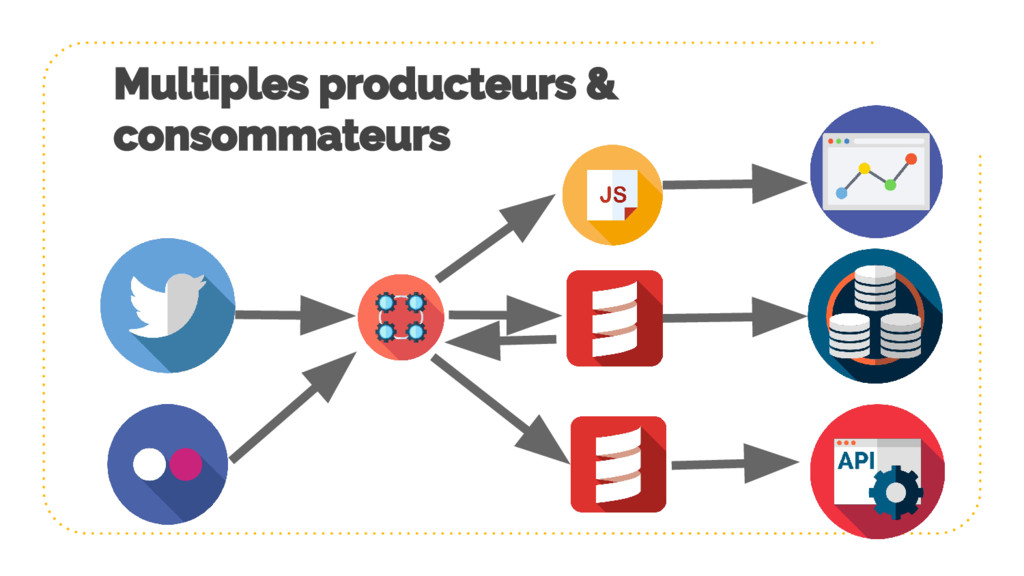{kind=link}
{kind=link}
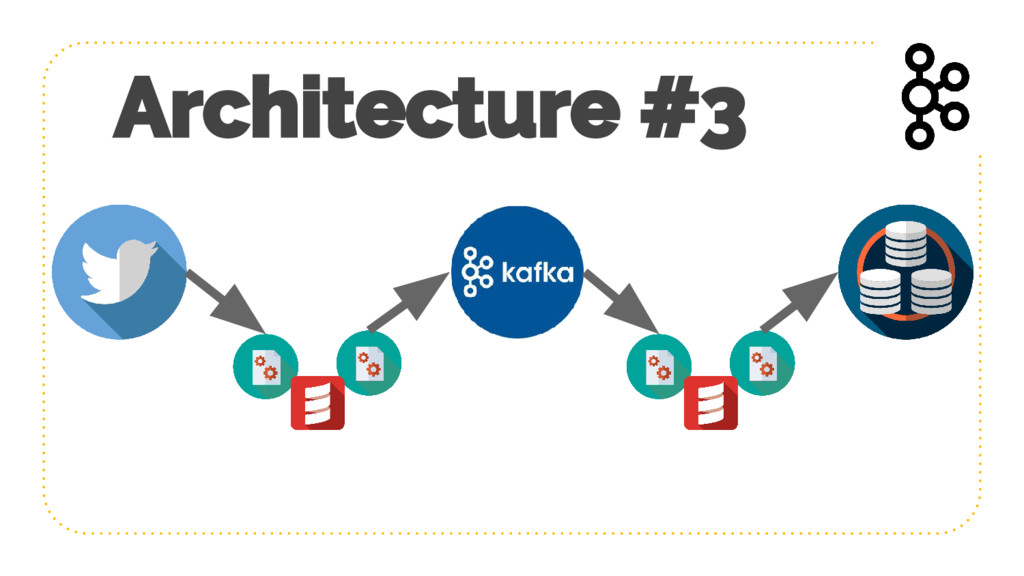{kind=link}
{kind=link}
{kind=link}
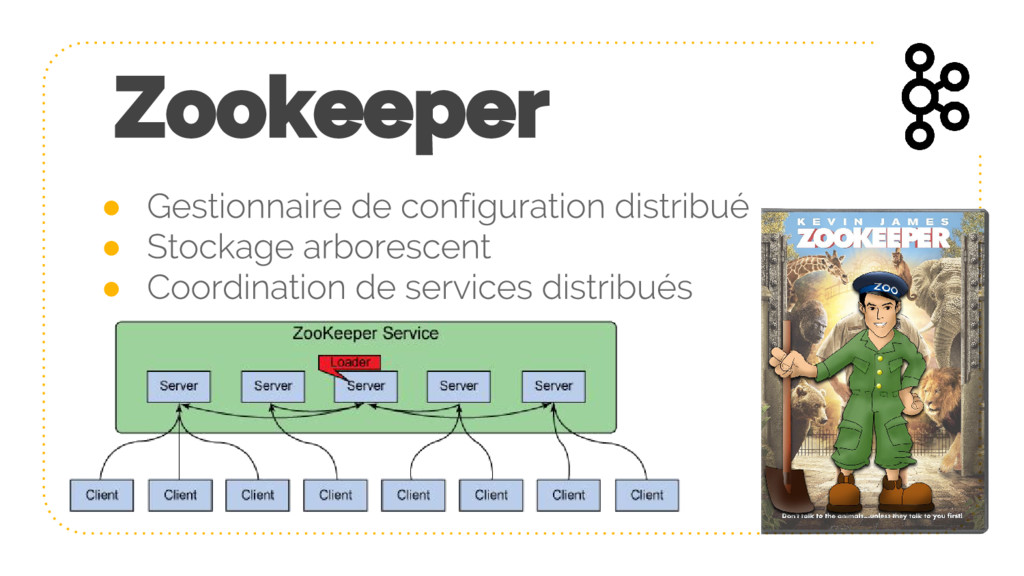{kind=link}
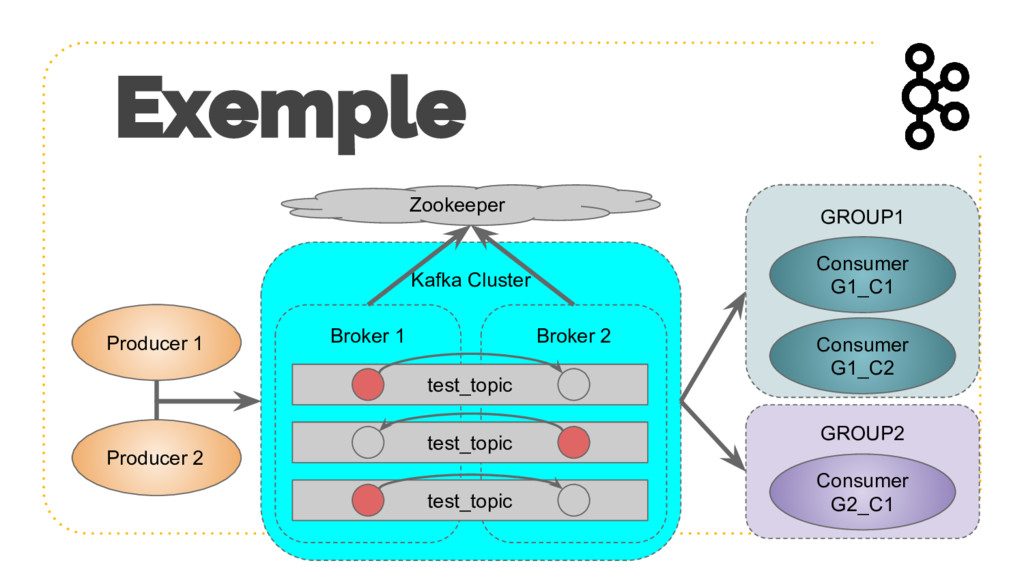{kind=link}
{kind=link}
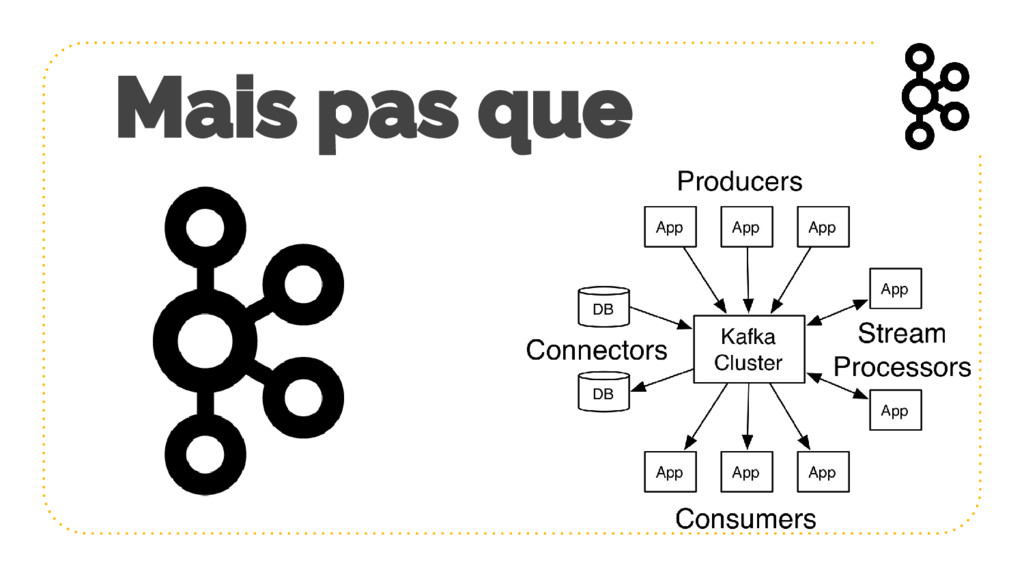{kind=link}
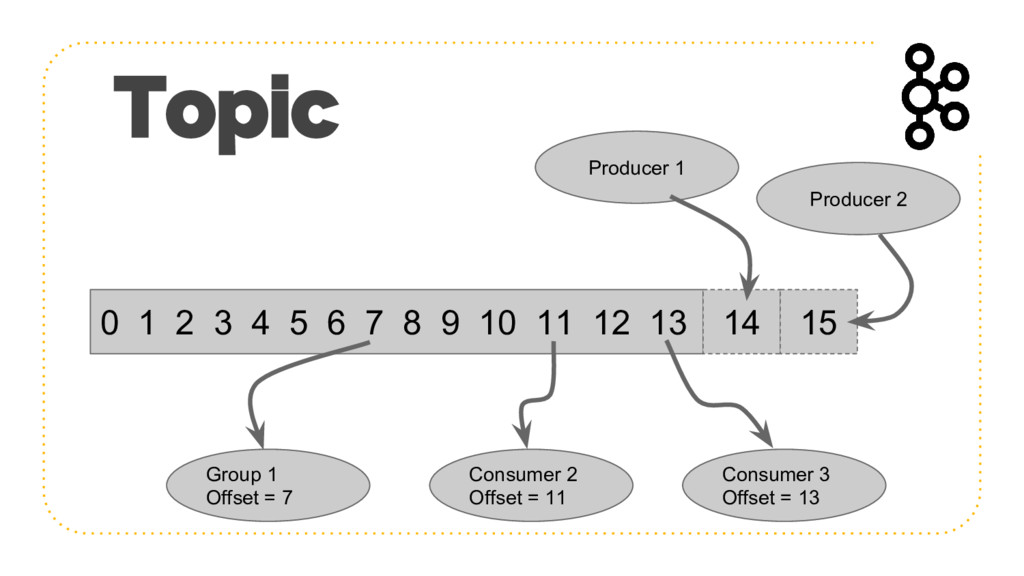{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
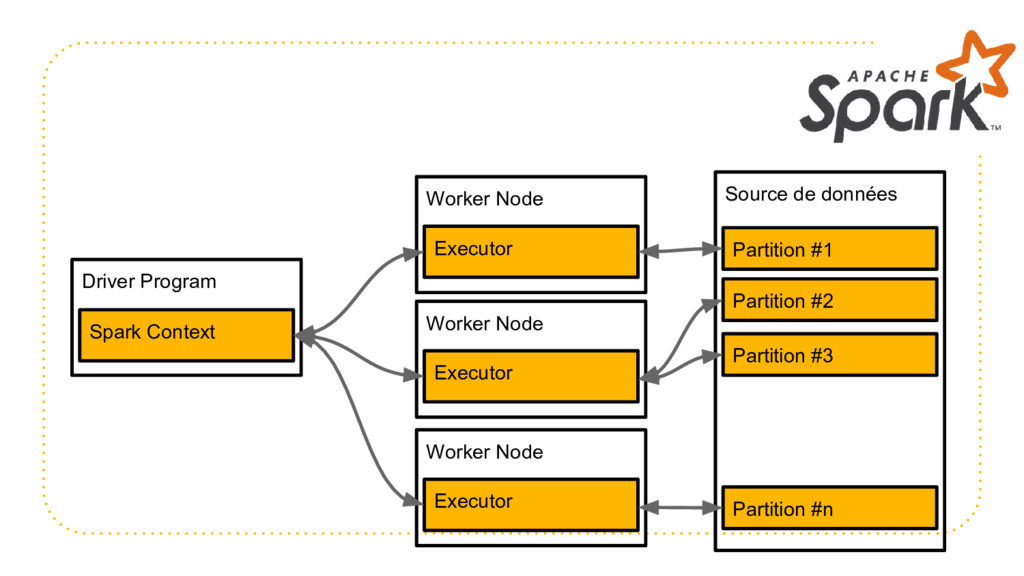{kind=link}
{kind=link}
{kind=link}
![[ethereum] => [bitcoin], 0.8405797101449275 [ethereum] => [blockchain], 0.9130434782608695 [ethereum,blockchain] =>](https://files.speakerdeck.com/presentations/ab2c80f43d6b4b5b8a3bd134c9c9426f/slide_65.jpg){kind=link}
![stream .map(record => JsonMethods.parse(record.value()).extract[Tweet]) ... .map((_, 1)) .reduceByKeyAndWindow(_ + _,](https://files.speakerdeck.com/presentations/ab2c80f43d6b4b5b8a3bd134c9c9426f/slide_66.jpg){kind=link}
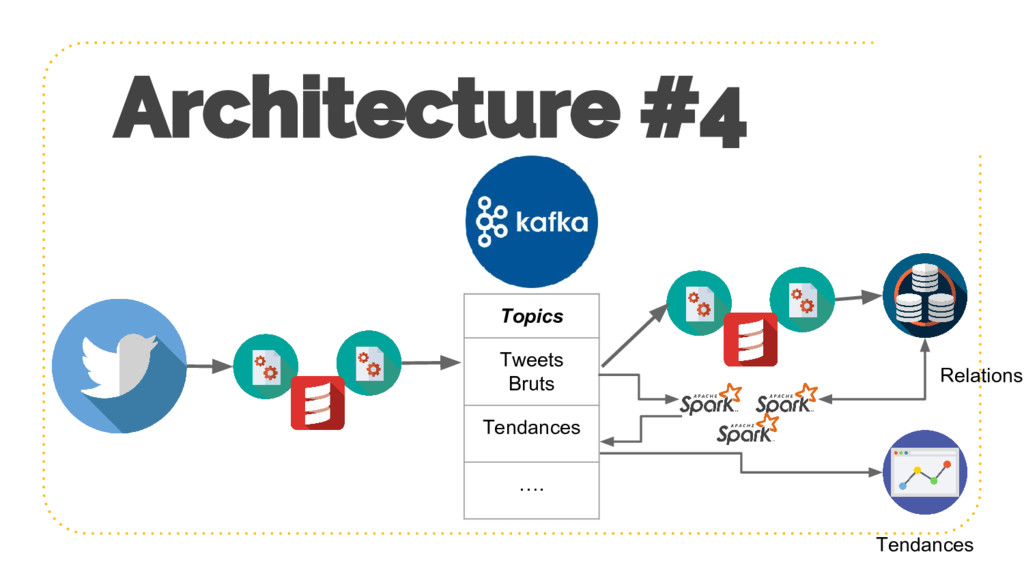{kind=link}
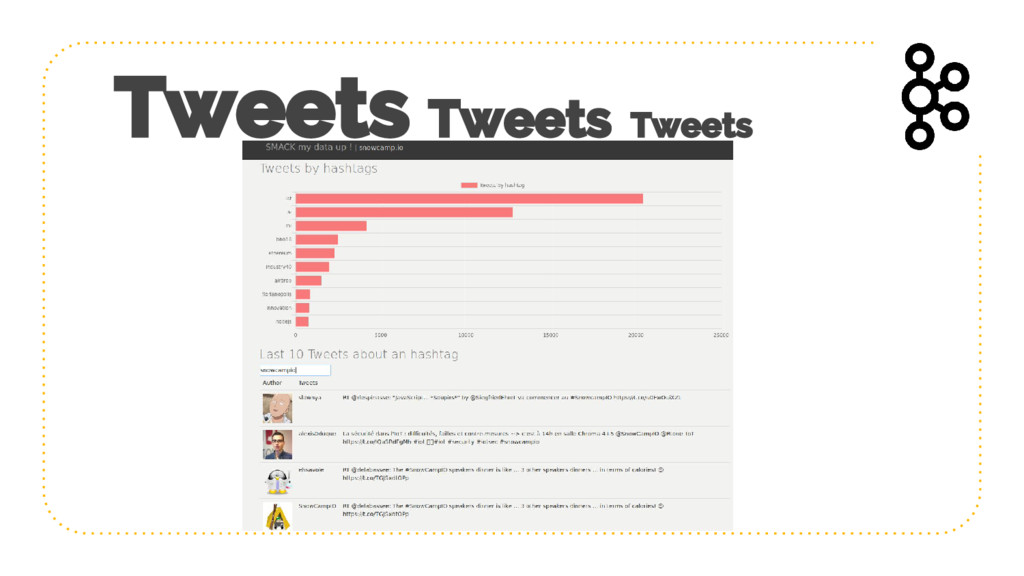{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
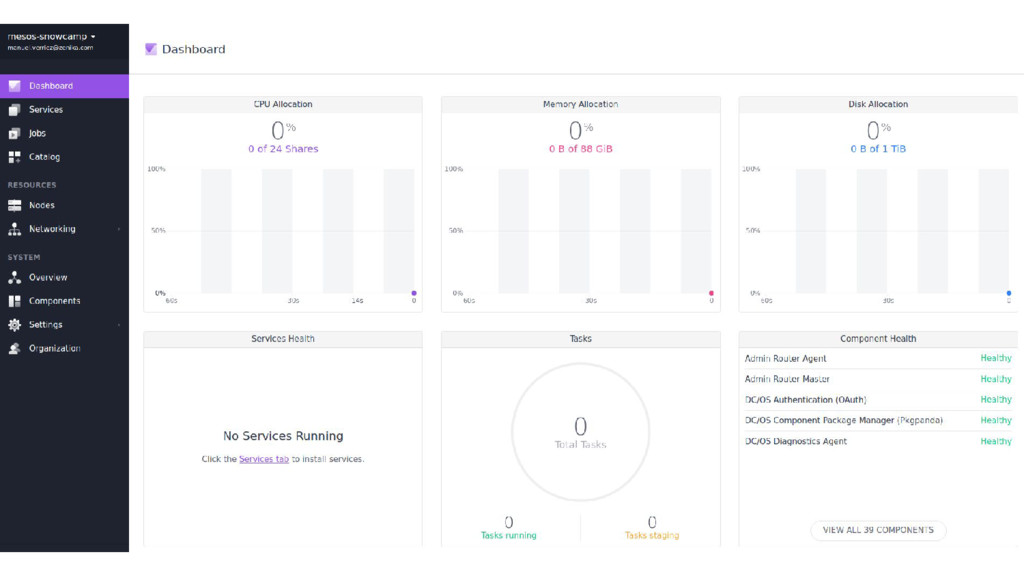{kind=link}
{kind=link}
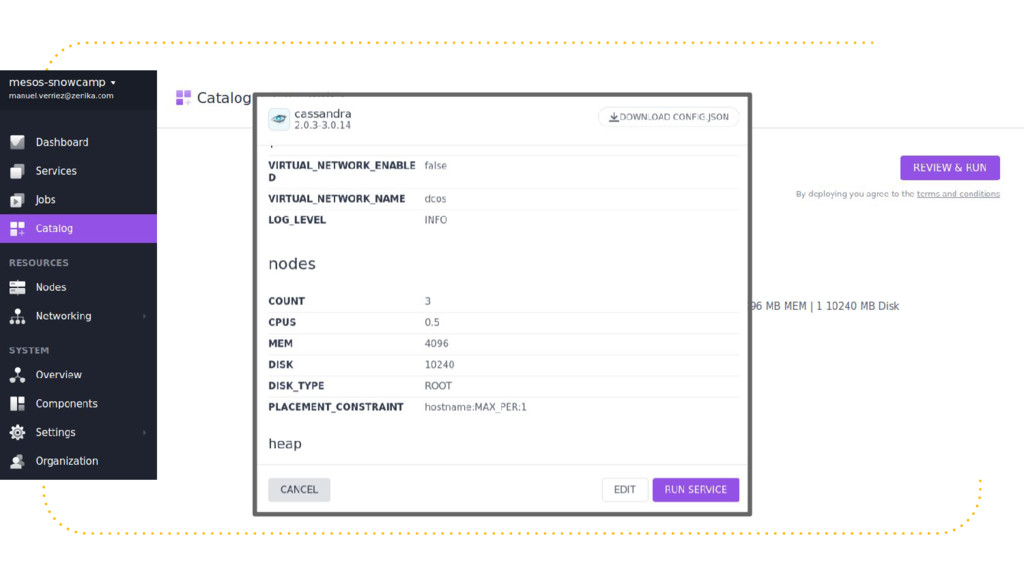{kind=link}
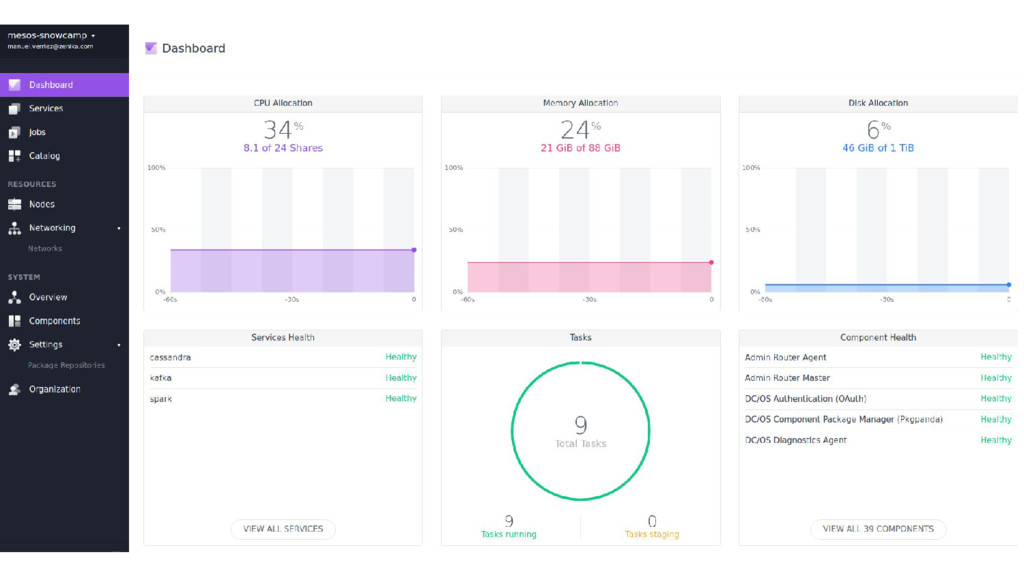{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}