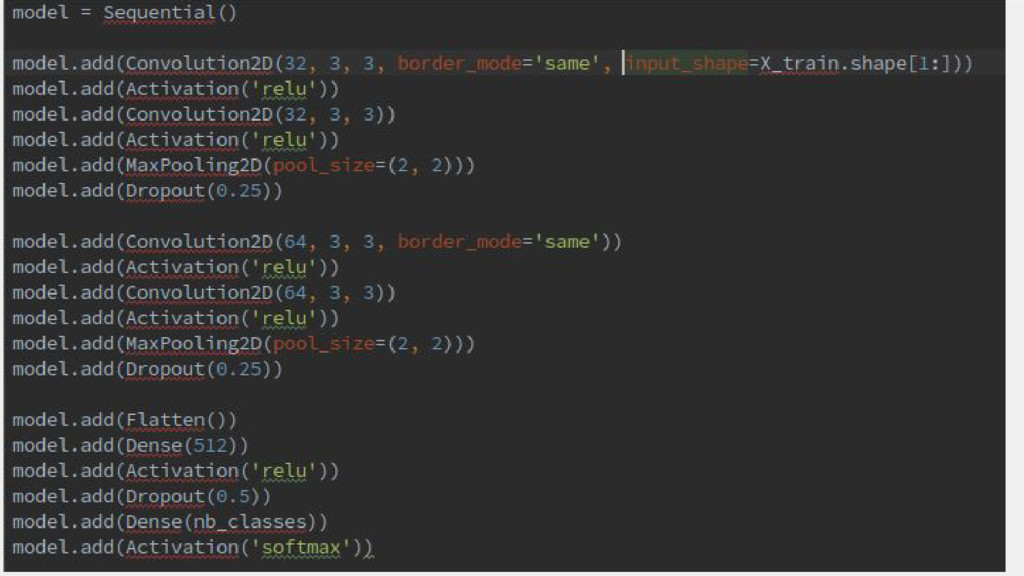
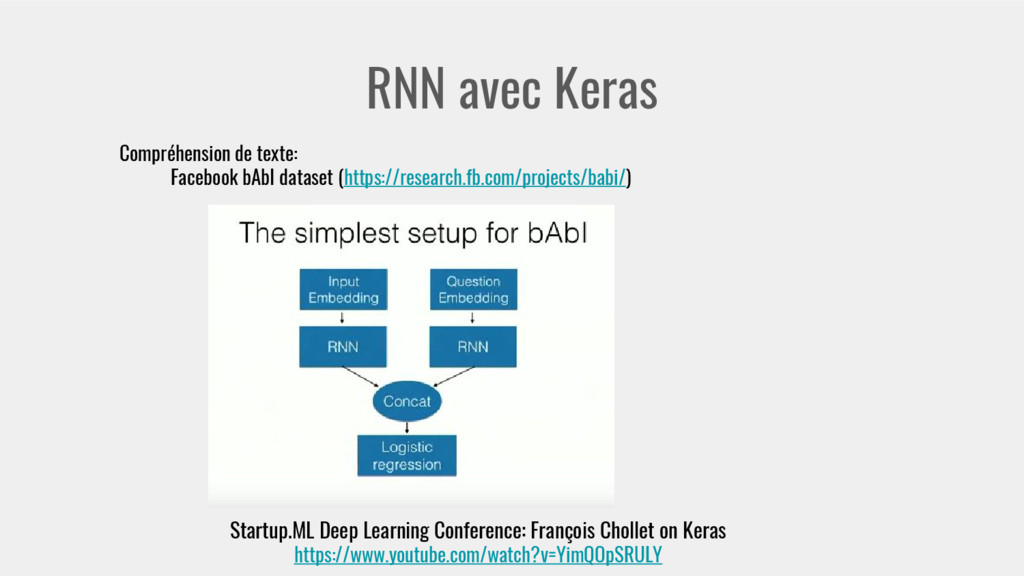
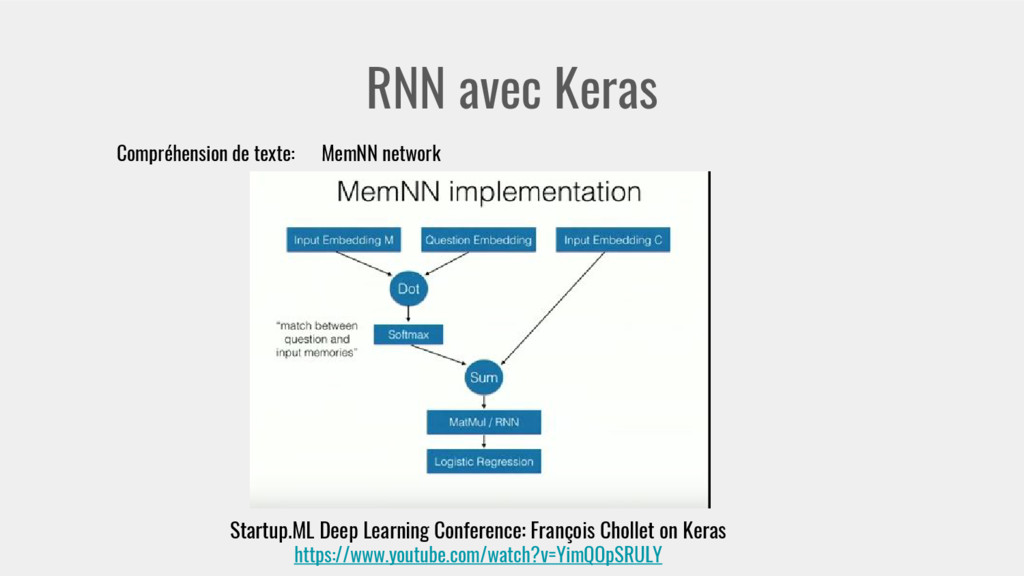
# output shape: (samples, 64) question_encoder = Sequential() question_encoder.add(Embedding(input_dim=vocab_size, output_dim=64)) question_encoder.add(LSTM(64, return_sequences=False)) # output shape: (samples, 64) model = Sequential() model.add(Merge([input_encoder, question_encoder], mode='concat',concat_axis=-1)) # output shape: (samples, 64*2) model.add(Dense(vocab_size)) model.add(Activation('softmax')) # output a probability distribution over all words model.compile(optimizer='adam', loss='categorical_crossentropy') print 'Training - reporting test accuracy after every iterations over the training data...' model.fit([inputs_train, queries_train], answers_train, batch_size=32, nb_epoch=50, show_accuracy=True, validation_data=([inputs_test, queries_test], answers_test)) Startup.ML Deep Learning Conference: François Chollet on Keras https://bitbucket.org/fchollet/keras_workshop
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
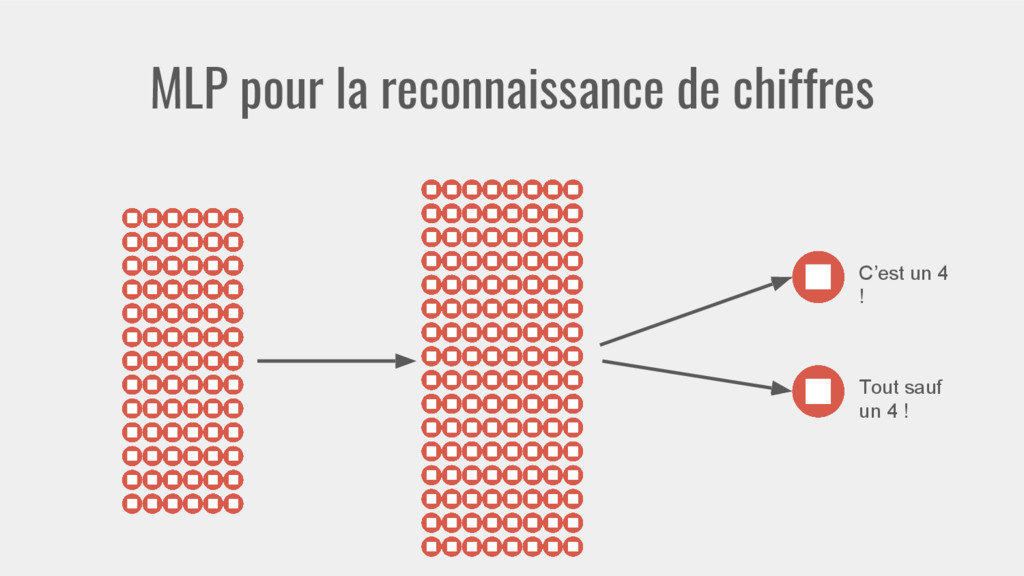{kind=link}
{kind=link}
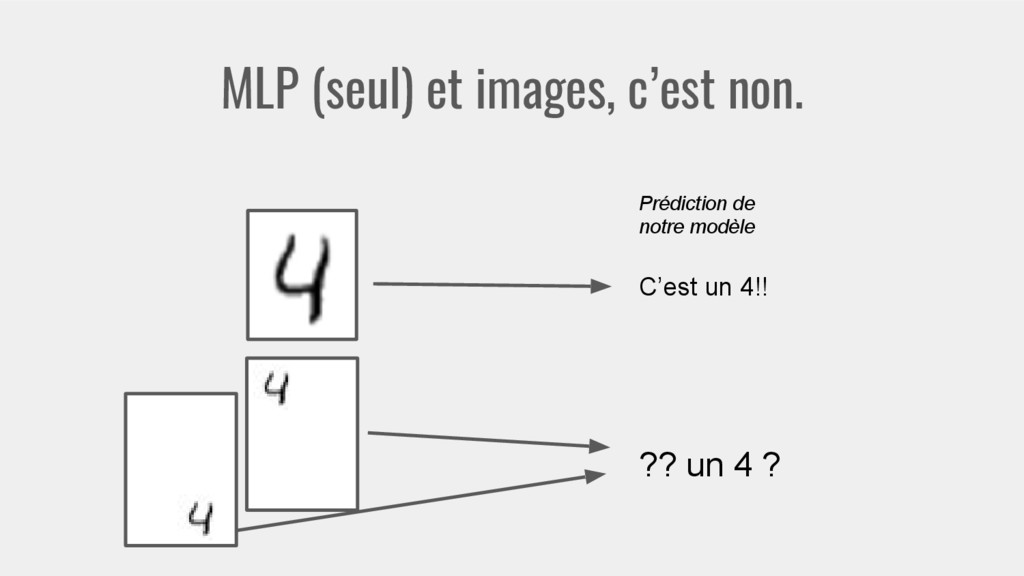{kind=link}
{kind=link}
{kind=link}
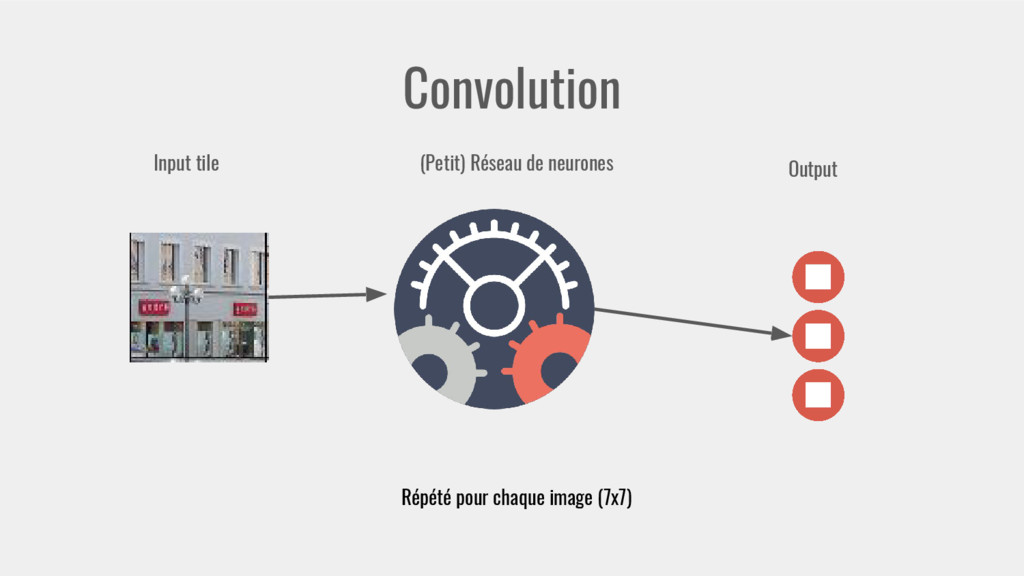{kind=link}
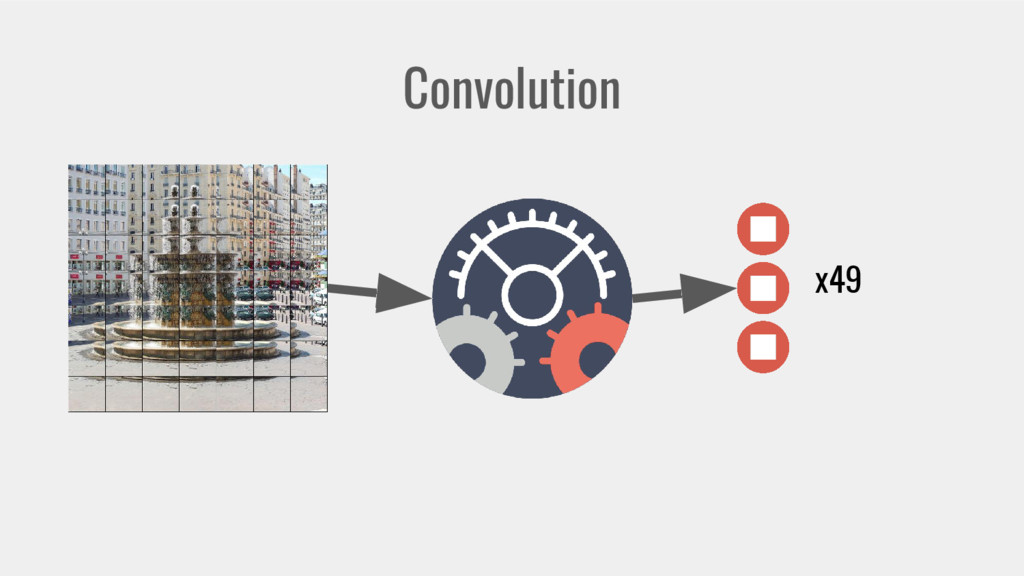{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
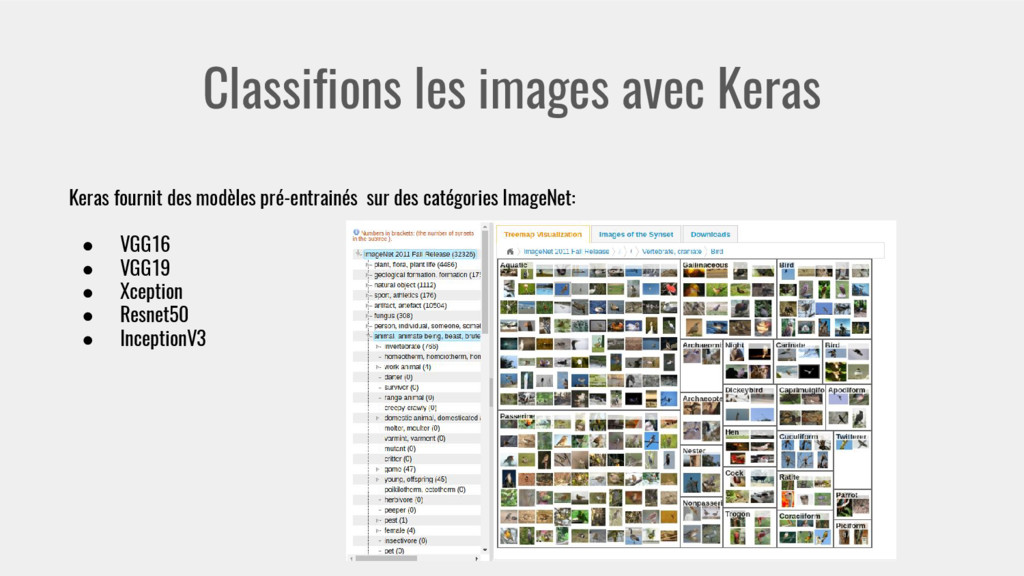{kind=link}
{kind=link}
{kind=link}
{kind=link}
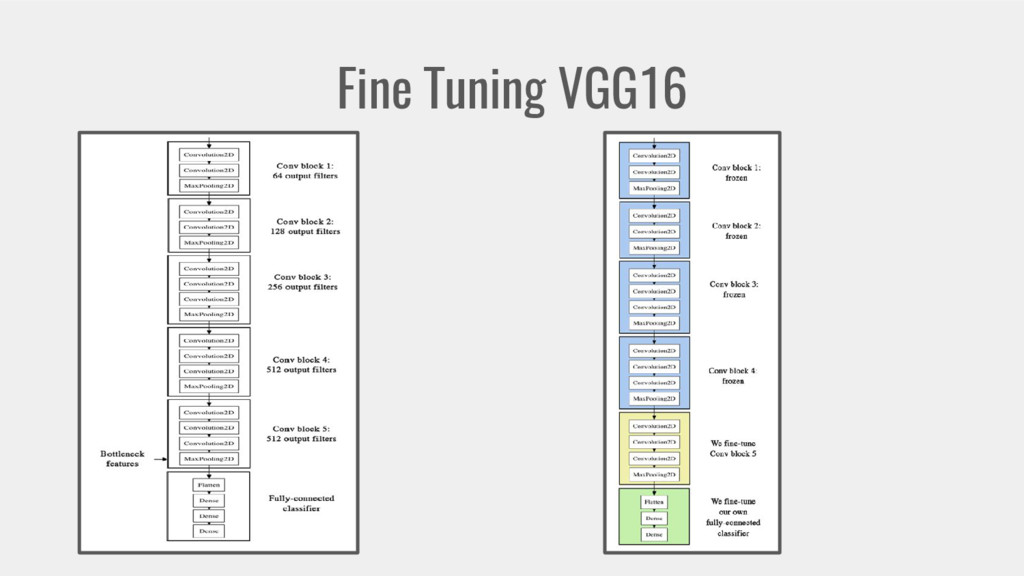{kind=link}
{kind=link}
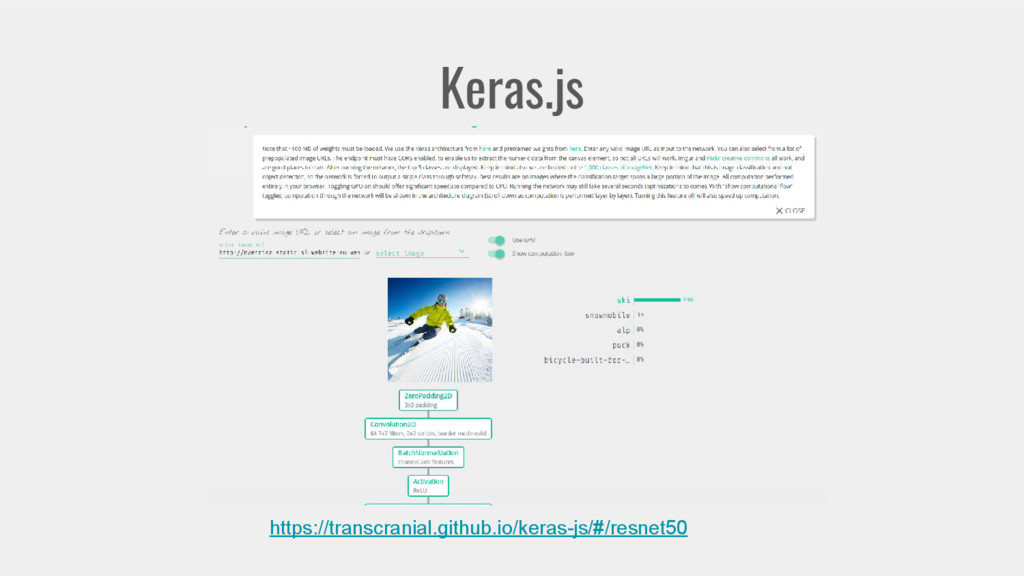{kind=link}
{kind=link}
{kind=link}
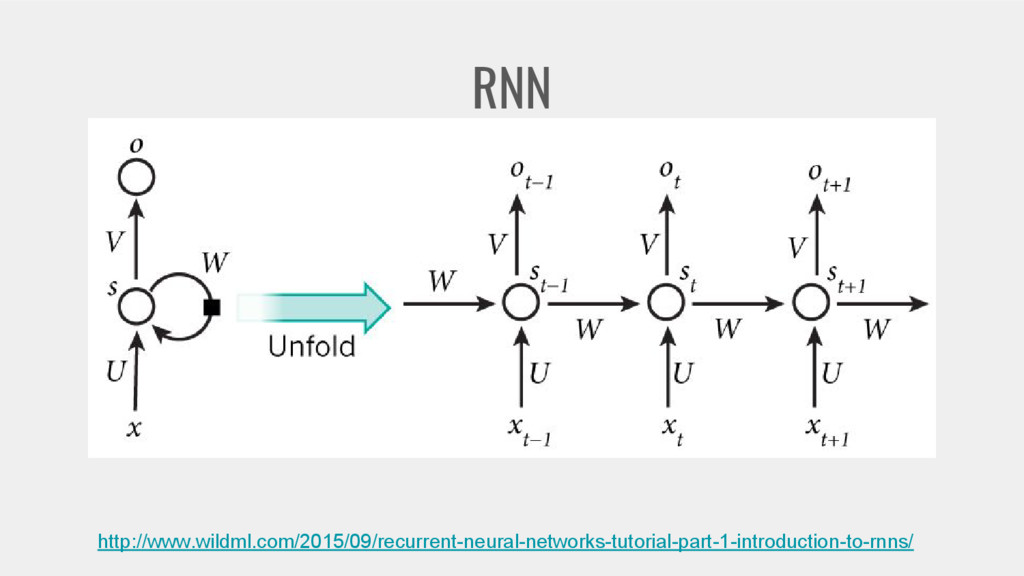{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}