Share
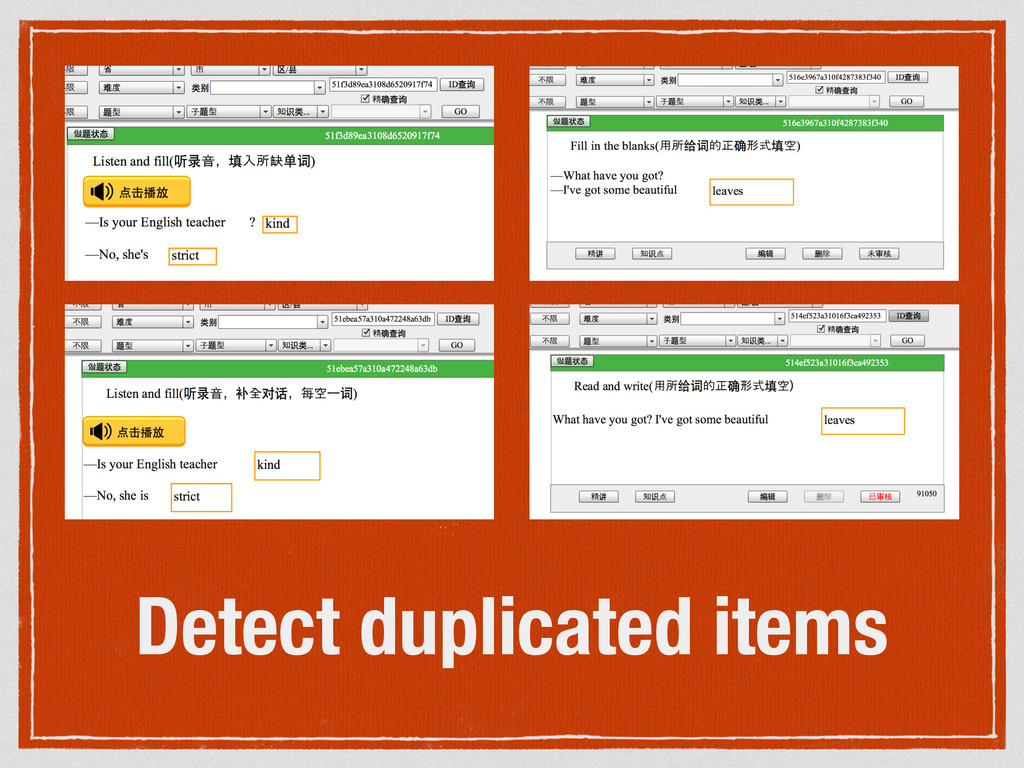
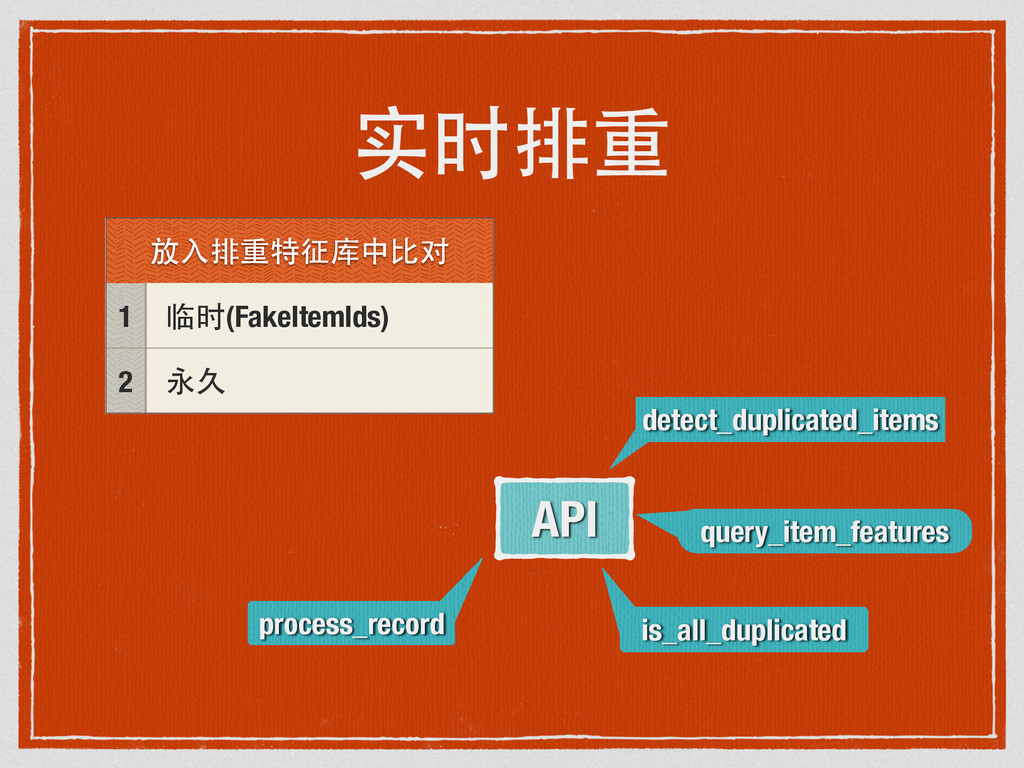
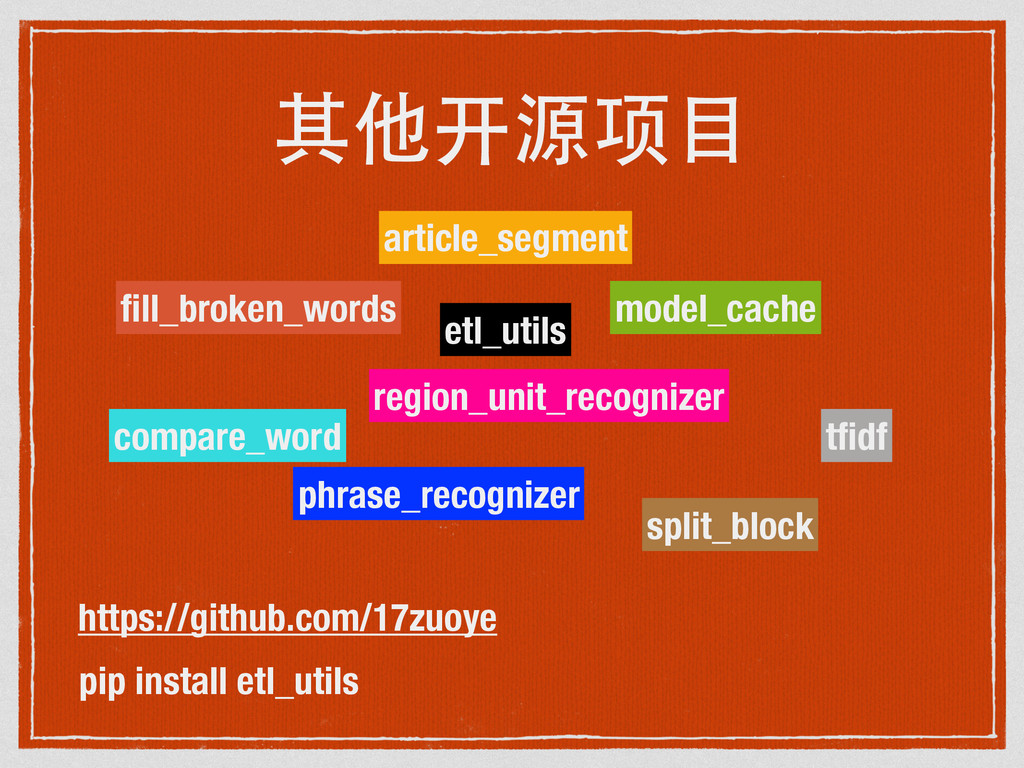
17zuoye内部 排重引擎 演讲稿分享。detdup是我在17zuoye第一个大项目,花了两三个月,最后代码加测试870行,目前应用于小学和初高中题库平台。项目源码 https://github.com/17zuoye/detdup ,欢迎交流。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}