スライド 1: タイトルスライド
「The Executable Mind: 次世代AIエージェント記憶実装戦略と技術選定 (ORC-463 / ADR-053)」
ビジュアルイメージ: 脳神経ネットワークのパターンから、美しく整理されたPythonのクラス定義(コード構造)へとモーフィングする背景。
解説のポイント: 記憶システムが「ストレージ」から「コンパイル・実行環境」へと進化するパラダイムシフトの宣言
。
【ナレーション原稿】
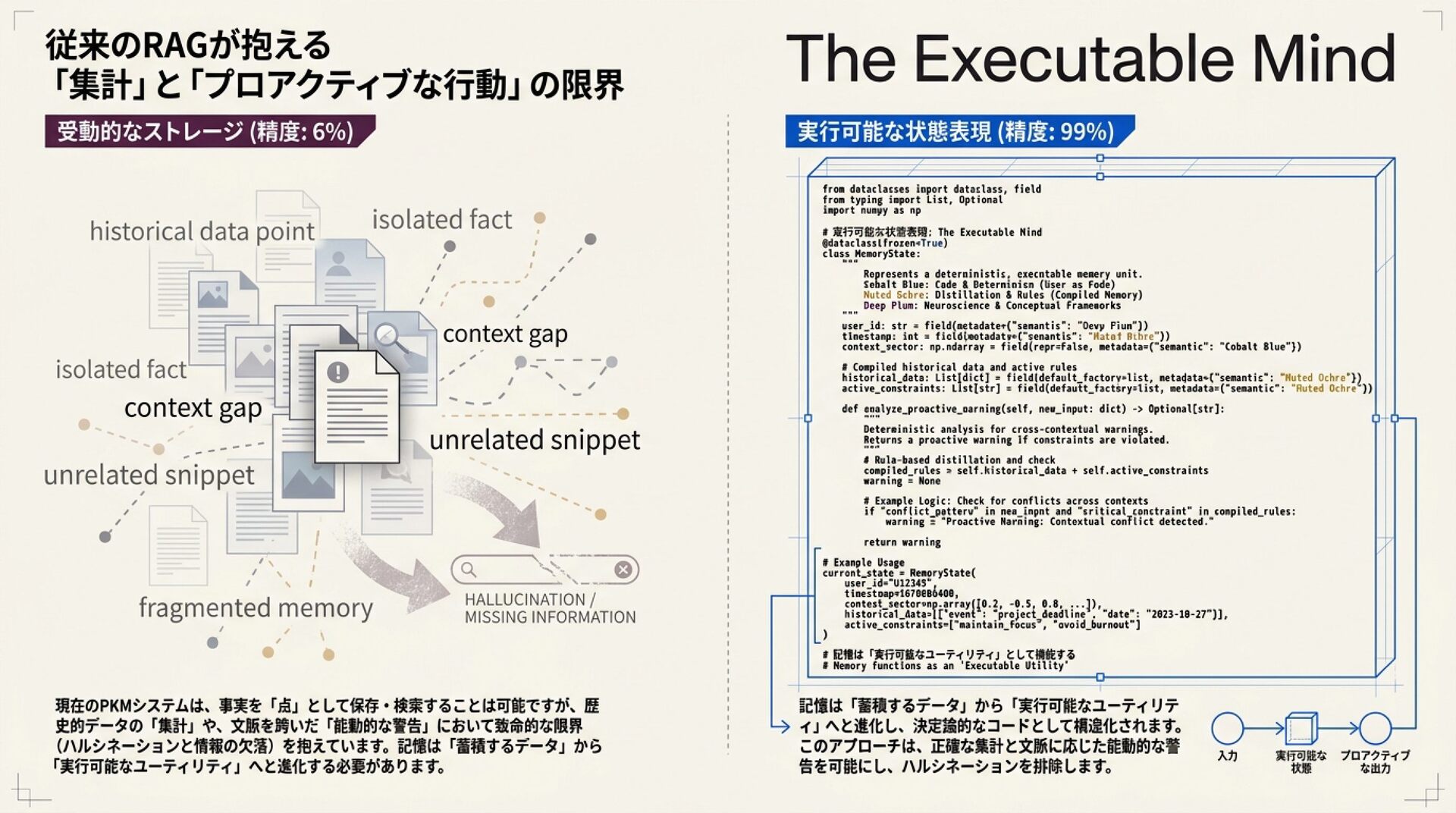
スライド 2: 記憶のパラダイムシフト
「Memory as Storage(記憶管理)から Memory as Utility(記憶効用)への移行」
ビジュアルイメージ: 左側に「MemGPT / Zep」などの階層型ページングによる『大量のテキスト流し込み(ノイズ増大)』の図
。右側に「Atlas / UaC」による『ルール蒸留とシステムプロンプトの永続的書き換え・状態定義』のクリーンな図
。
解説のポイント: 検索(RAG)の限界と、記憶ユーティリティ(学習、検証、行動変容)の重要性の対比
。
【ナレーション原稿】
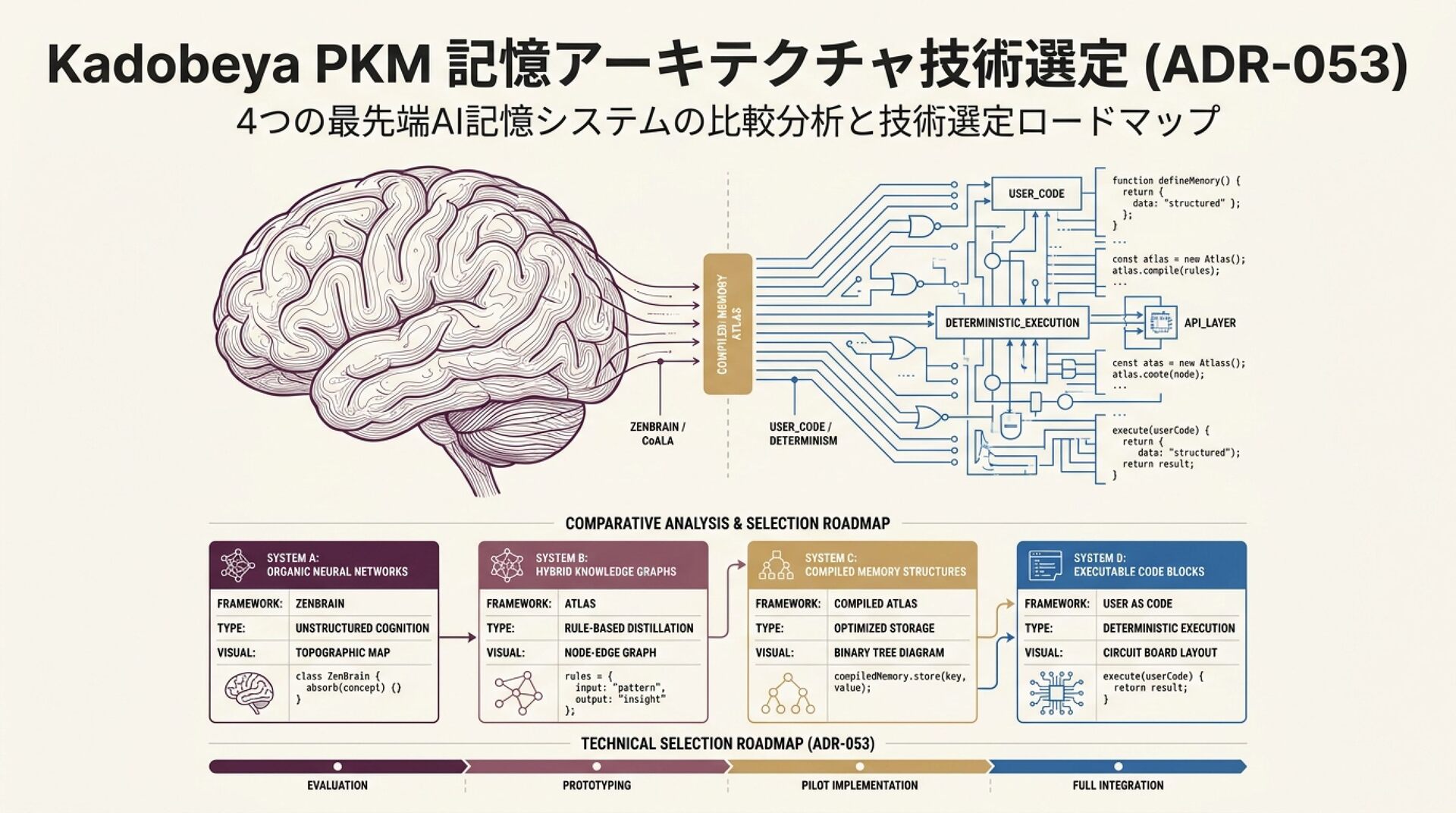
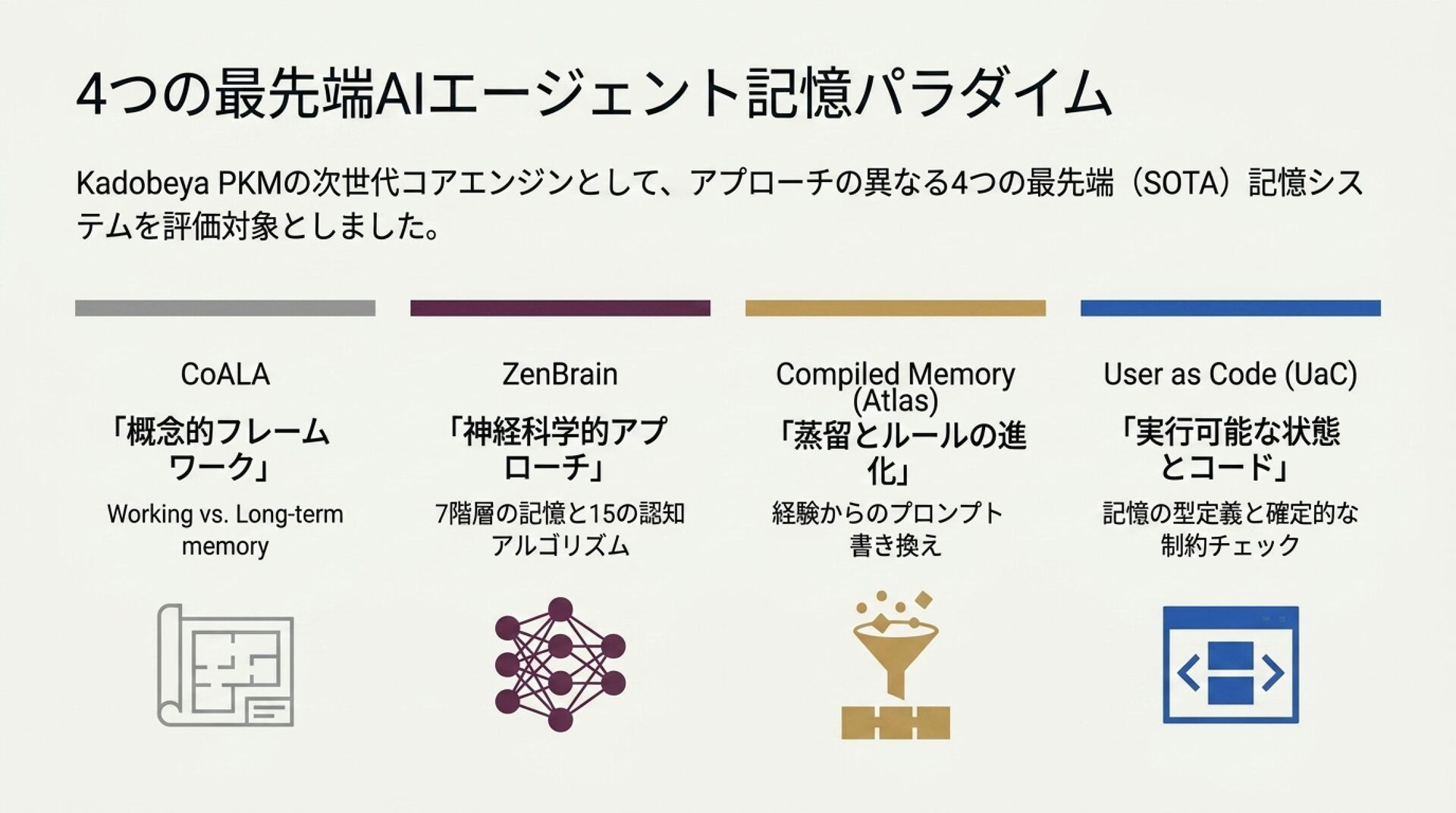
スライド 3: 4つのフロンティア記憶アーキテクチャ
「CoALA / ZenBrain / Compiled Memory / User as Code の全体像」
ビジュアルイメージ: 4つの象限に分割された比較マップ。
CoALA: 認知的枠組み、意思決定サイクル
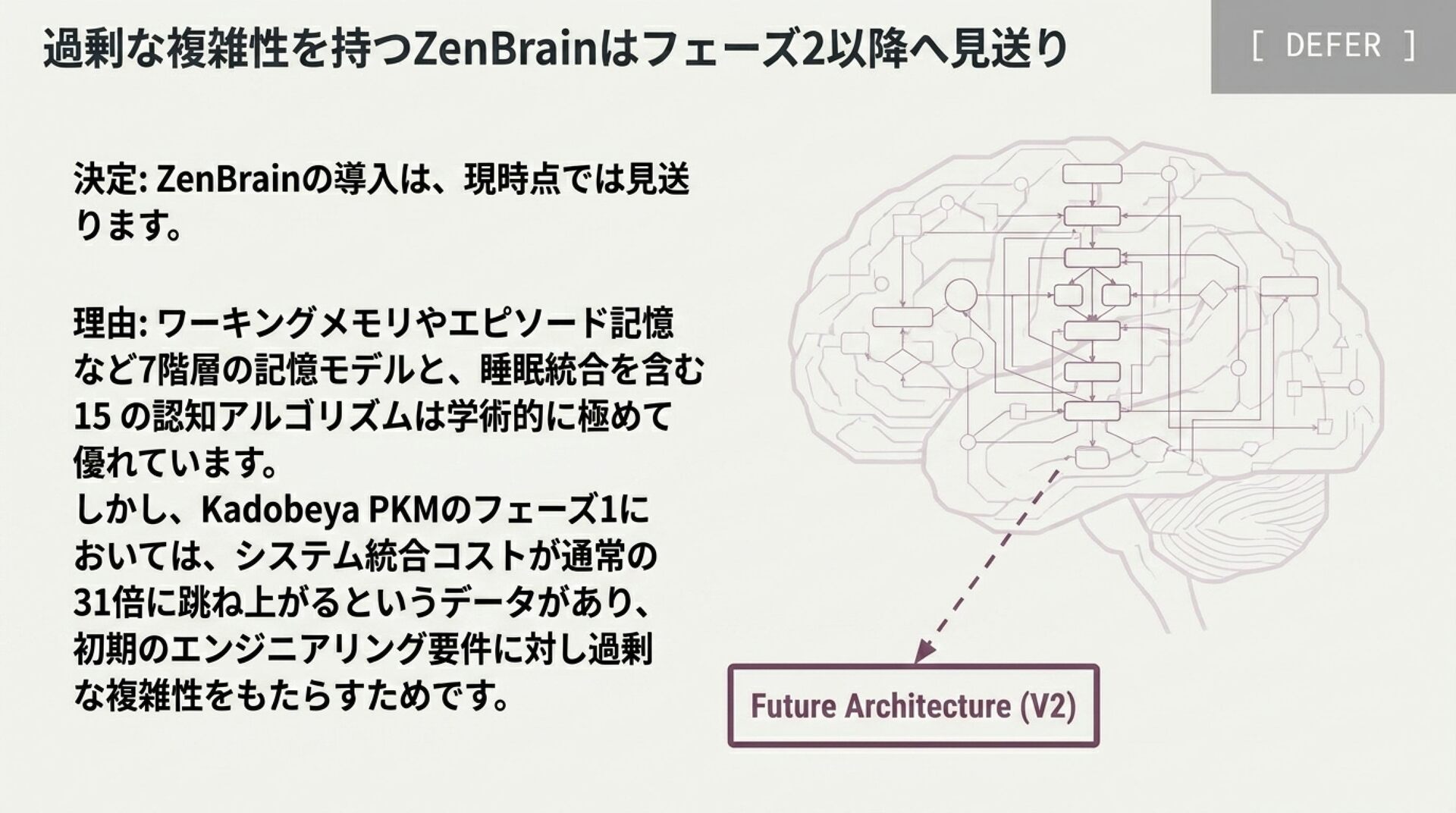
ZenBrain: 脳科学に立脚した7層メモリと15アルゴリズム
Compiled Memory (Atlas): 命令のコンパイルと3段検証ゲート
User as Code (UaC): ユーザーモデルのコード化、インタープリタ実行
解説のポイント: 本調査の対象となる4大思想のポジショニング
。
【ナレーション原稿】
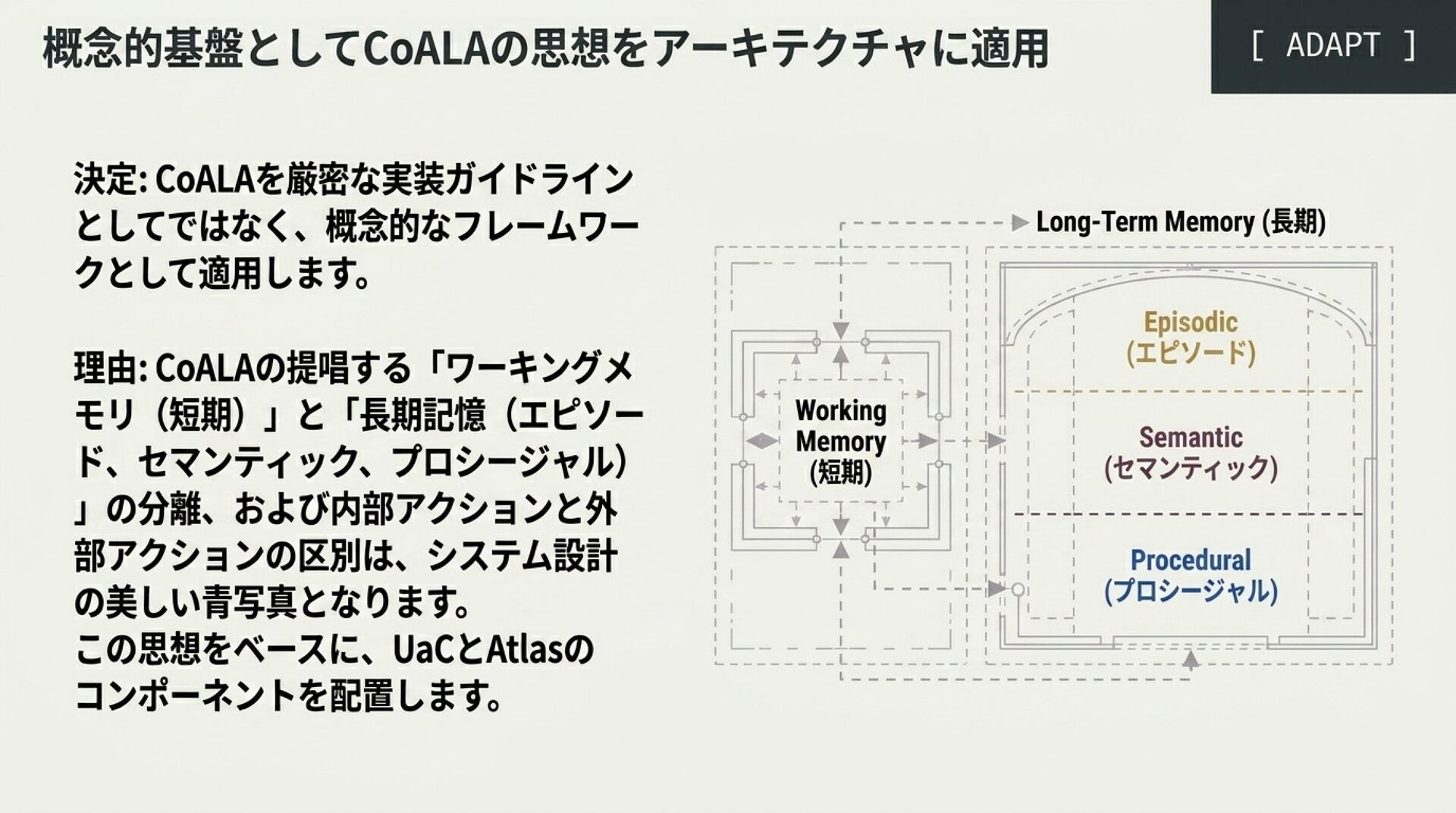
スライド 4: CoALA & ZenBrain の本質
「認知的行動スペースの定義と、脳科学駆動型7層メモリ」
ビジュアルイメージ: 左側にCoALAの外部行動(環境相互作用)と内部行動(理由づけ・検索・学習)のサイクル
。右側にZenBrainの7層記憶構造(Working, STM, Episodic, Semantic, Procedural, Core, Cross-Context)と、睡眠による記憶整理プロセス(Simulation-Selection loop)の図解
。
解説のポイント: 理論的定義(CoALA)と、複雑な神経科学シミュレーション(ZenBrain)の実装コストと提供価値
。
【ナレーション原稿】
スライド 5: Compiled Memory (Atlas)
「3段検証ゲートと corroboration(裏付け)信頼度数式」
ビジュアルイメージ:
3段検証ゲートの流れ: Deduplication(重複排除 τ
d
=0.92)→ LLM検証(一括バッチ評価)→ Grounding(2キーワード以上の一致)
。
信頼度更新のグラフ: c
i+1
=1−(1−c
i
)λ
+
の指数関数的上昇(初期値0.5 → 1回復唱で0.85 → 2回復唱で0.955)
。
解説のポイント: 記憶に昇格すべき真実の峻別(検証)プロセスと確信度(Confidence)の動的更新
。
【ナレーション原稿】
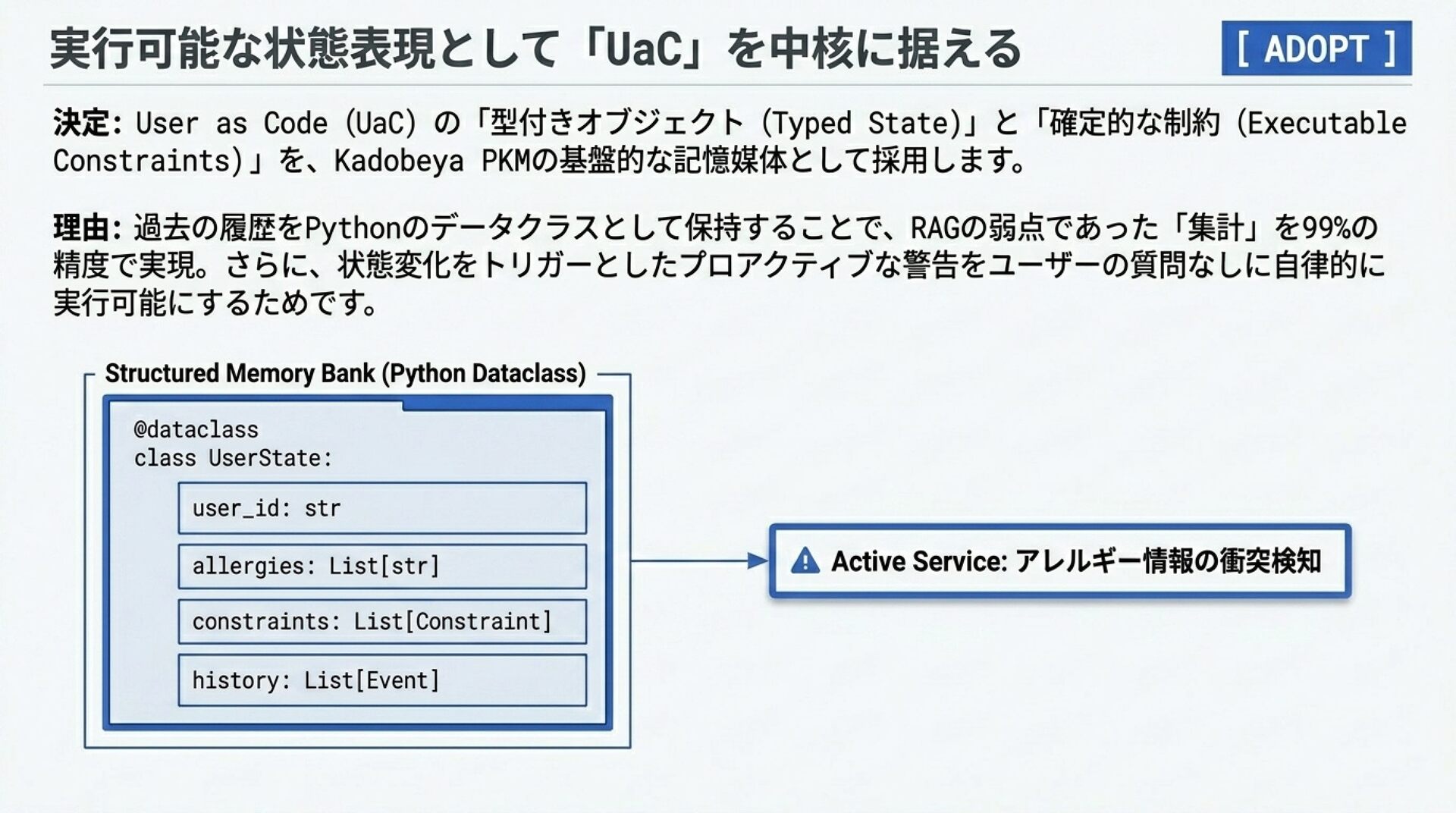
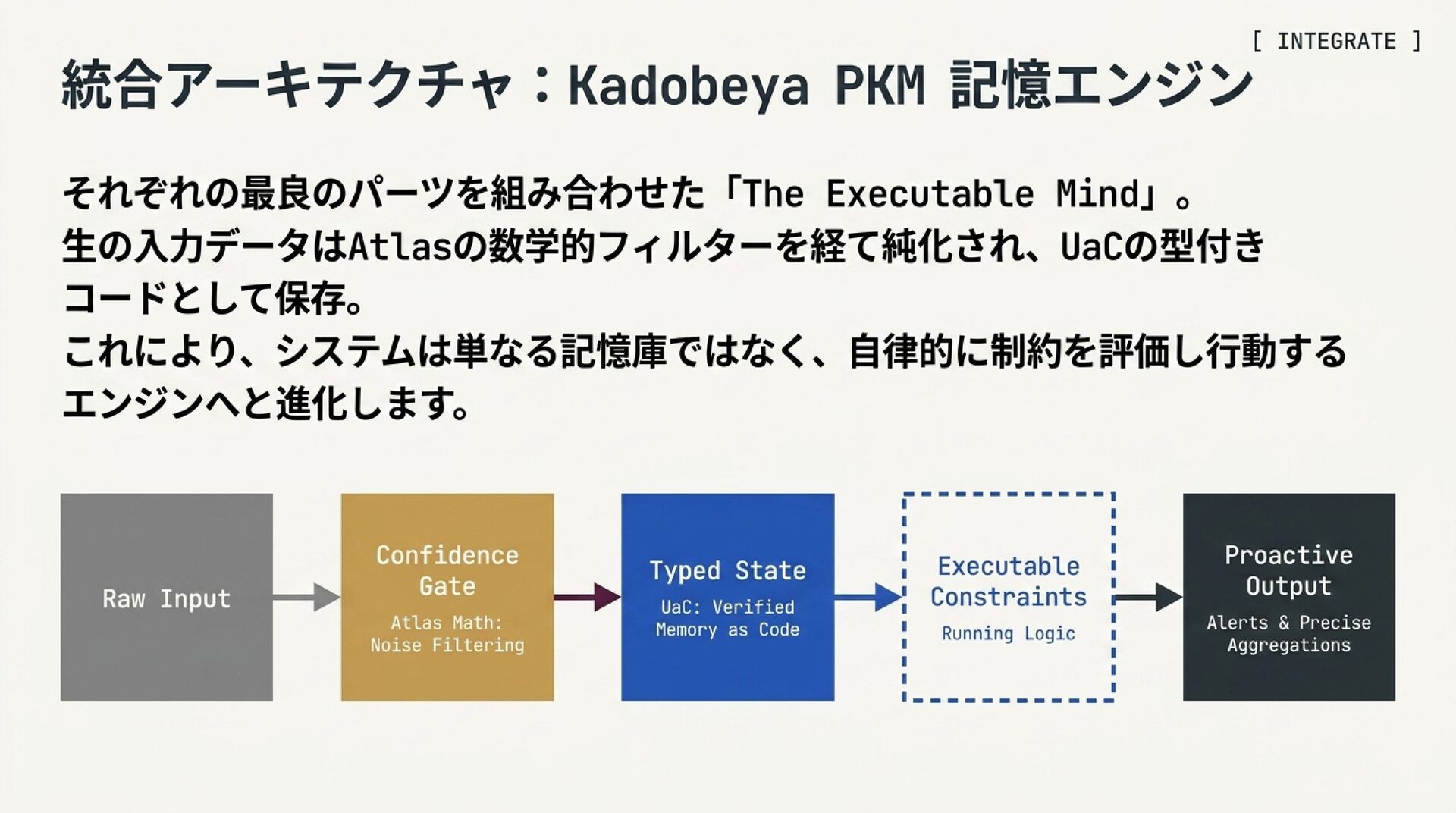
スライド 6: User as Code (UaC)
「実行可能なユーザー状態定義:記憶をソフトウェアプロジェクトにする」
ビジュアルイメージ:
2フェーズ・パイプライン: Phase 1(生データをすべて append-only ログとして保存)→ Phase 2(非同期で型定義された Python データクラスへ checkpoint コンパイル)のビジュアルフロー
。
実コードの比較: Jessicaの『ペニシリン・アレルギー(10ヶ月前)』と『アモキシシリン処方(現在)』という2つの出来事
。
解説のポイント: コード表現が「 storage(格納)と verification(検証)」の断絶を解消する仕組み
。
【ナレーション原稿】
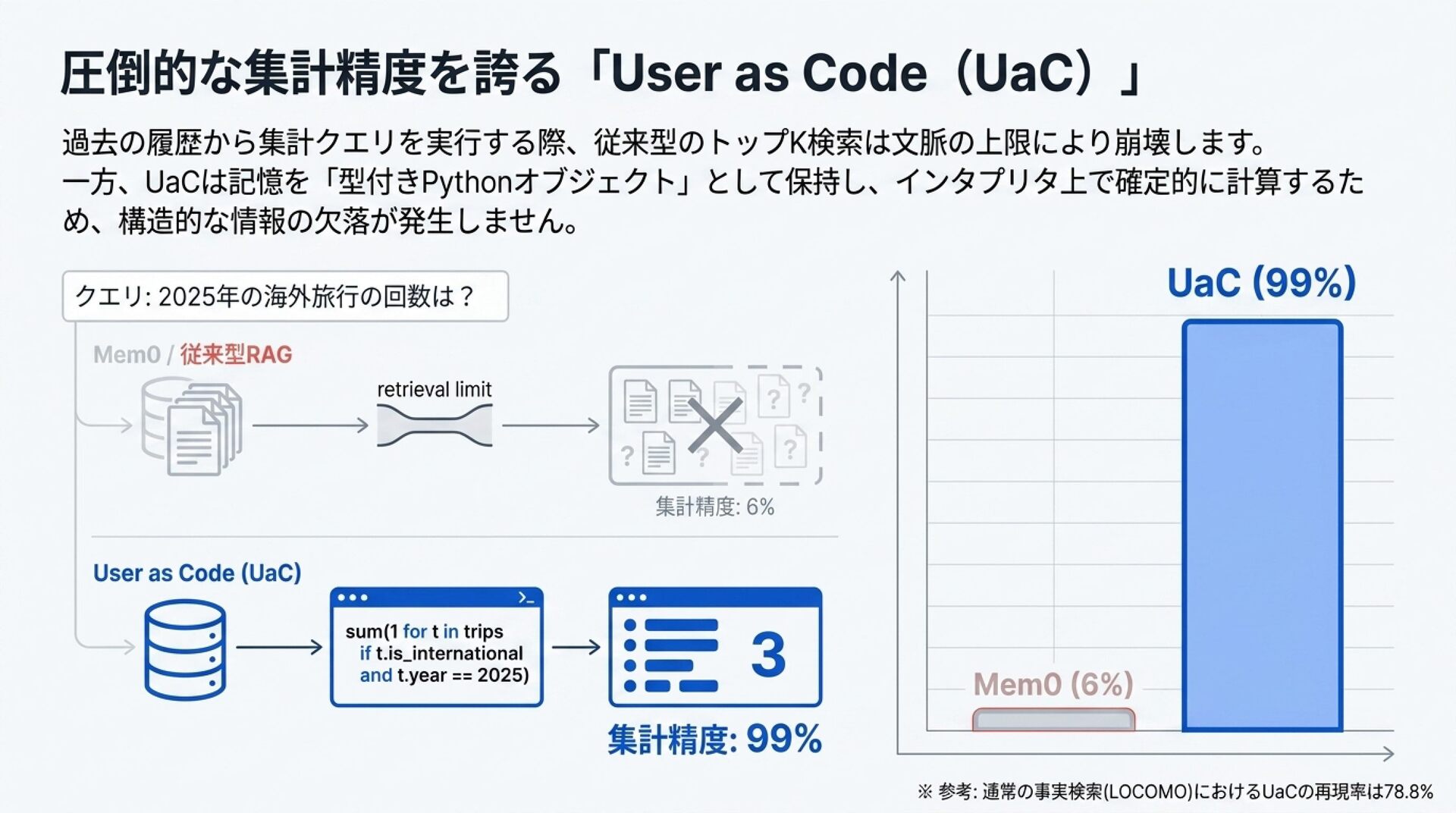
スライド 7: UaC の圧倒的な集計推論能力
「集計タスク精度:99% vs 6%(RAGの崩壊)」
ビジュアルイメージ: LOCOMOベンチマークに基づく「Analytical Inference(集計クエリ)」の精度推移グラフ(横軸:レコード数 N=20〜500。縦軸:正確性 0%〜100%)。UaCとFull Context+REPLはほぼ100%を維持するのに対し、MemMachine(RAG上位20件など)やMem0(ベクトル検索のみ)が N=50 以上で急激に崩壊(43%以下、最下位は6%)する対比
。
解説のポイント: 「RAGは検索(Rank)し、コード実行は全走査(Enumerate)する」という構造的優位性の実証
。
【ナレーション原稿】
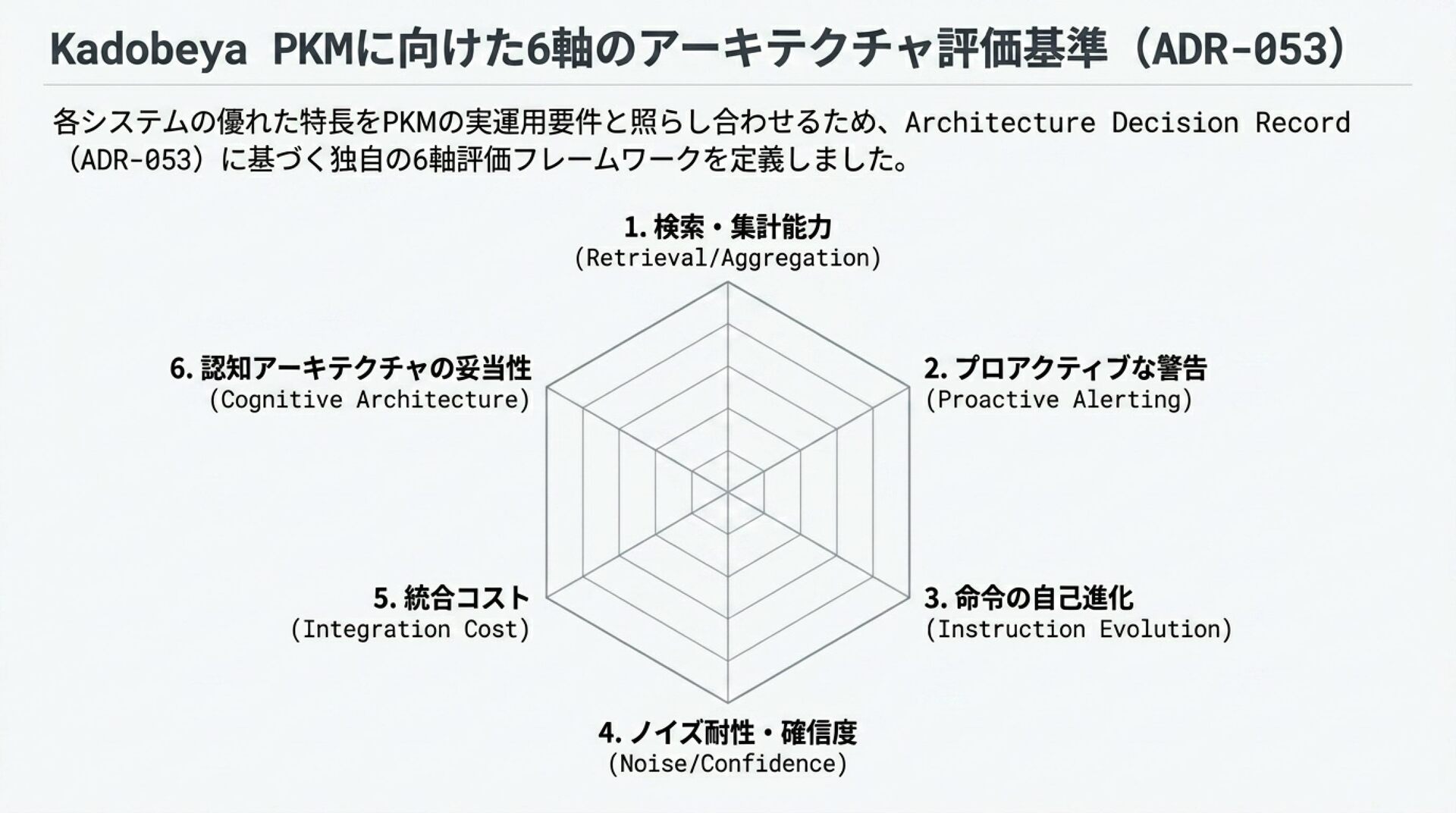
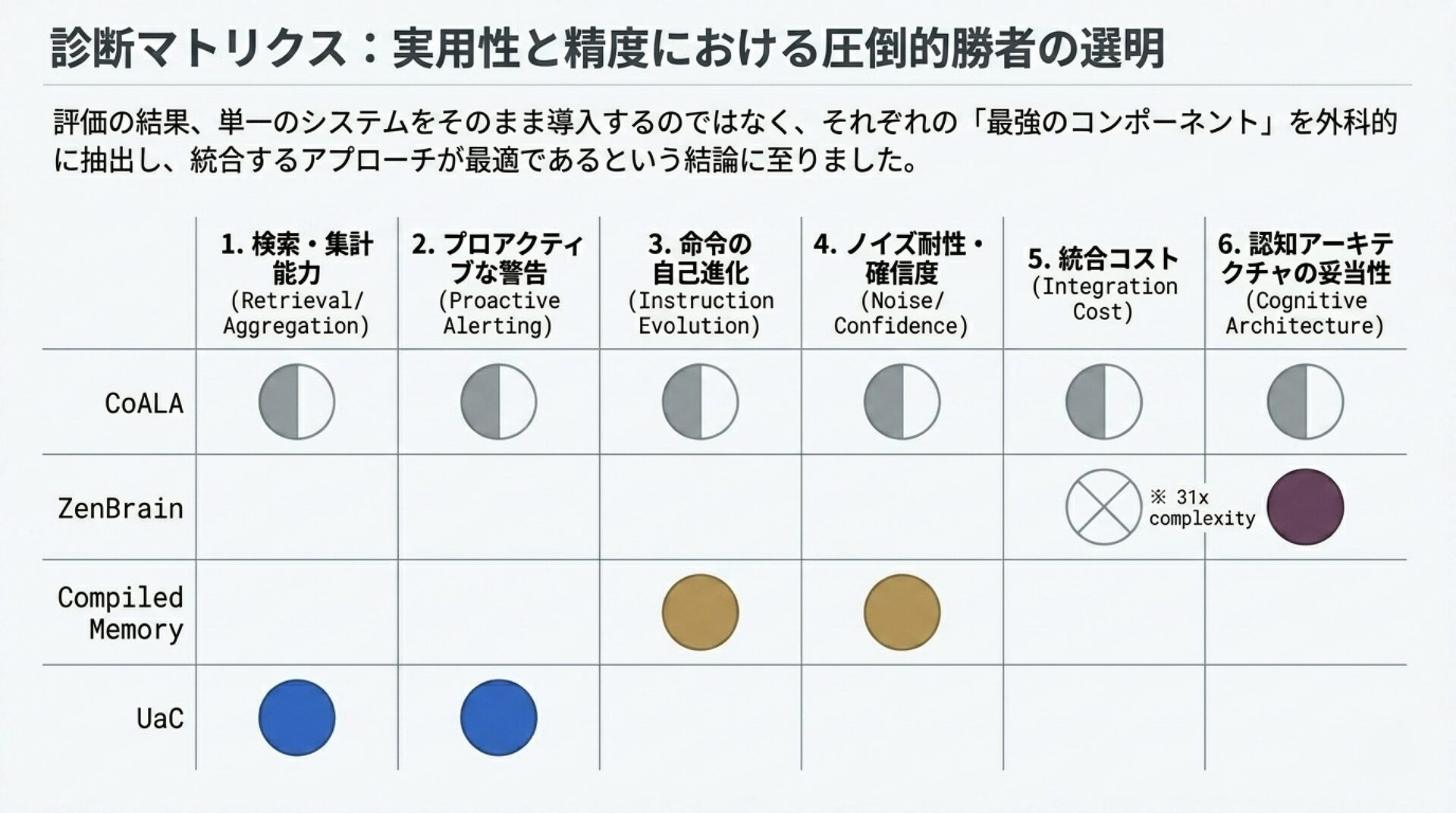
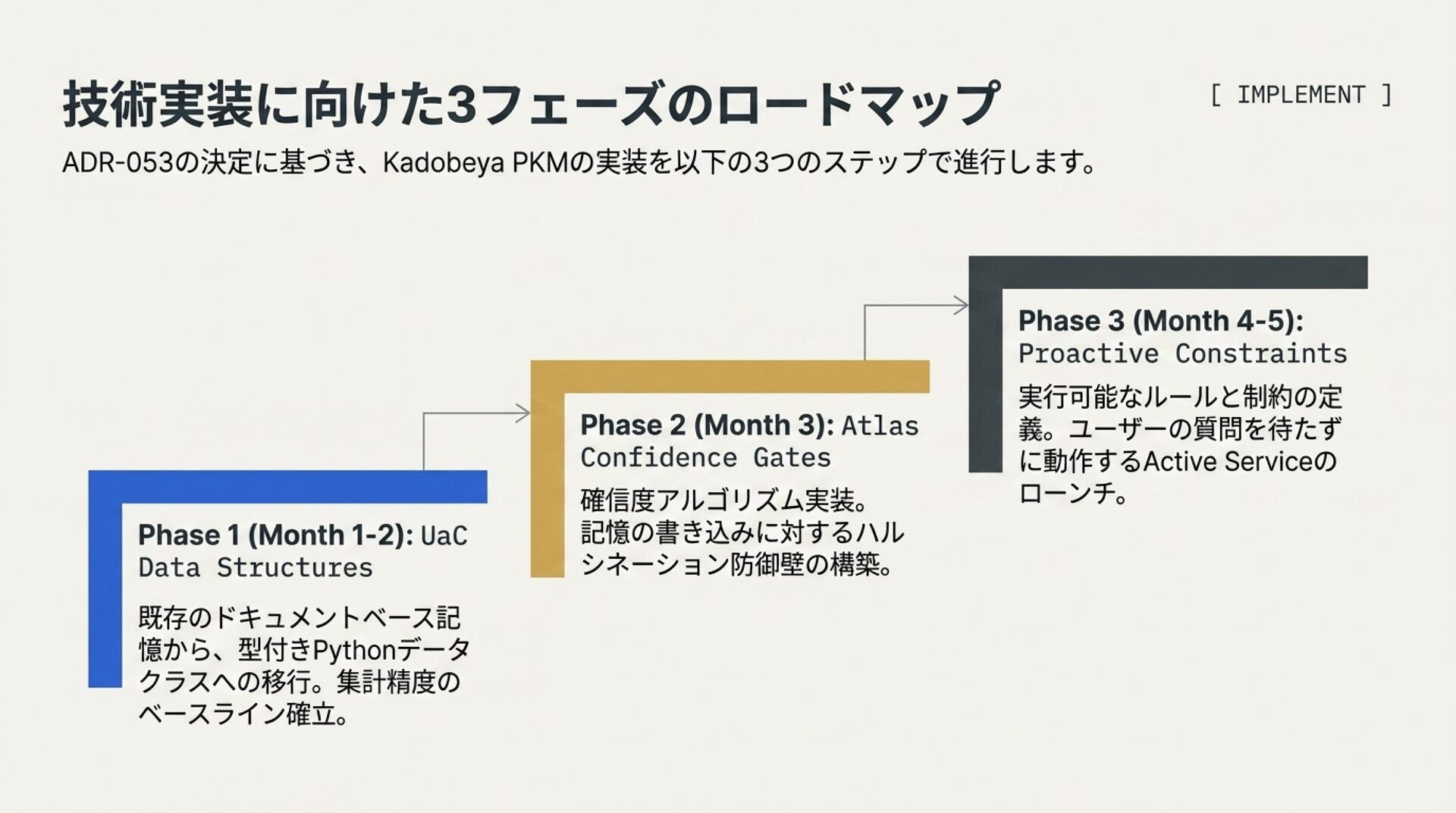
スライド 8: 技術選定ロードマップ (ADR-053)
「Kadobeya PKM における6軸評価と、採用・defer・見送りの決定」
ビジュアルイメージ: ADR-053の定める記憶の6軸評価マトリックス。
Type (データ型): UaCの Python データクラス型を採用
Decay (減衰): ZenBrainの Ebbinghaus 忘却曲線を部分借用
Provenance (不変ログ): UaCの 2フェーズ・パイプラインを採用
Confidence (確信度): Compiled Memory/Atlasの corroboration更新数式を全面採用
Conflict (衝突解決): UaC / ZenBrain の論理制約・Sheaf 数学モデルの部分借用
Cross-Substrate (汎用性): 知識をタスク依存に保ち、LLMの変更に対して不変に保つ
解説のポイント: なぜ各システムを「採用」「defer」「見送り」にしたかの論理的整合性
。
【ナレーション原稿】
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}