Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Fujitsuの量子化技術を完全理解する
Search
nagiss
October 24, 2025
Technology
770
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Fujitsuの量子化技術を完全理解する
2025/10/23のDeNA/Go AI技術共有会の発表資料です。
nagiss
October 24, 2025
More Decks by nagiss
See All by nagiss
サンタコンペの話をさくっと
nagiss
0
72
F0推定の手法を色々試してみる
nagiss
1
1.4k
音信号の電子透かし
nagiss
0
1.3k
F0推定アルゴリズムHarvestは中で何をしているのか
nagiss
3
1.8k
ヒューリスティックコンテストで機械学習しよう
nagiss
10
6.8k
XNNPACKを直接使ってみた
nagiss
0
920
SantaとAHCと遺伝的アルゴリズム
nagiss
8
4.3k
Kaggleシミュレーションコンペの動向
nagiss
2
1.6k
Other Decks in Technology
See All in Technology
新しい SLO が良い感じにハマっている話
z63d
1
720
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.8k
AIQAのナレッジ構築について
qatonchan
1
130
LangfuseによるLLMOps基盤の構築と活用事例
zozotech
PRO
1
190
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
710
AI時代の強いチームの作り方
yuukiyo
14
8k
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
180
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
170
20260608_Codexの可能性_ノンプログラマー向け_大城追記
doradora09
PRO
0
120
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
360
GMOフィナンシャルゲートが挑む、「止まらない」決済インフラ構築の裏側【SORACOM Discovery 2026】
soracom
PRO
0
110
DevOps Agentで運用判断をチーム資産にする ~Agent InstructionsとAgent Skillを継続的に育てる~
fujioka6789
0
180
Featured
See All Featured
Product Roadmaps are Hard
iamctodd
55
12k
Technical Leadership for Architectural Decision Making
baasie
3
450
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
56
3.4k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Balancing Empowerment & Direction
lara
6
1.2k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Designing for Performance
lara
611
70k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
Visualization
eitanlees
152
17k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
360
Transcript
AI Community 2025.10.23 nagiss 株式会社ディー・エヌ・エー Fujitsuの量子化技術を 完全理解する あー そーゆーことね 完全に理解した
2 項目 01|概要 02|QEP: 目的関数を上手く定義する 03|QQA: 目的関数に対して最適化する 04|まとめ
3 01 概要
4 ▪ 1bit 量子化らしい ▪ 気になる! ▪ → 読みました ▪
かなり面白い 概要 引用: https://global.fujitsu/ja-jp/pr/news/2025/09/08-01
5 ▪ 2 つの手法で構成される ▪ QEP (Quantization Error Propagation) ▪
学習済みの NN をナイーブに層ごとに量子化すると、後続の層の計 算を経るごとに誤差の影響が指数関数的に増大する ▪ これを防ぐ目的関数を提案 ▪ QQA (Quasi-Quantum Annealing) ▪ 目的関数を最小化する {0, 1} の配置を GPU で効率的に探索する方法 ▪ 両方紹介します ▪ 手法中心、理論はあまり説明しません 概要 文献 Yamato Arai and Yuma Ichikawa. “Quantization Error Propagation: Revisiting Layer-Wise Post-Training Quantization,” https://arxiv.org/abs/2504.09629, 2025 Yuma Ichikawa and Yamato Arai. “Optimization by Parallel Quasi-Quantum Annealing with Gradient-Based Sampling,” https://openreview.net/forum?id=9EfBeXaXf0, 2025
6 02 QEP: 目的関数を上手く定義する
7 ▪ 背景 1: LLM の高速な推論には量子化が不可欠 ▪ 背景 2: 学習後に層ごとに量子化するのが色々と良い
▪ 計算効率が良い ▪ 同じモデルを複数の精度で量子化して提供できる ▪ 課題: ナイーブな方法では層ごとに誤差が増大 ▪ 提案手法: 誤差の増大を抑える目的関数を使う ▪ QuIP など多くの既存の工夫と併用可能 QEP 概要 BitNet などは学習時から量子化の影響を 加味している (QAT: Quantization-Aware Training) ところで BitNet は TritNet に改名してくれ 優良誤認表示だろ layer-wise PTQ (PTQ: Post-Training Quantization)
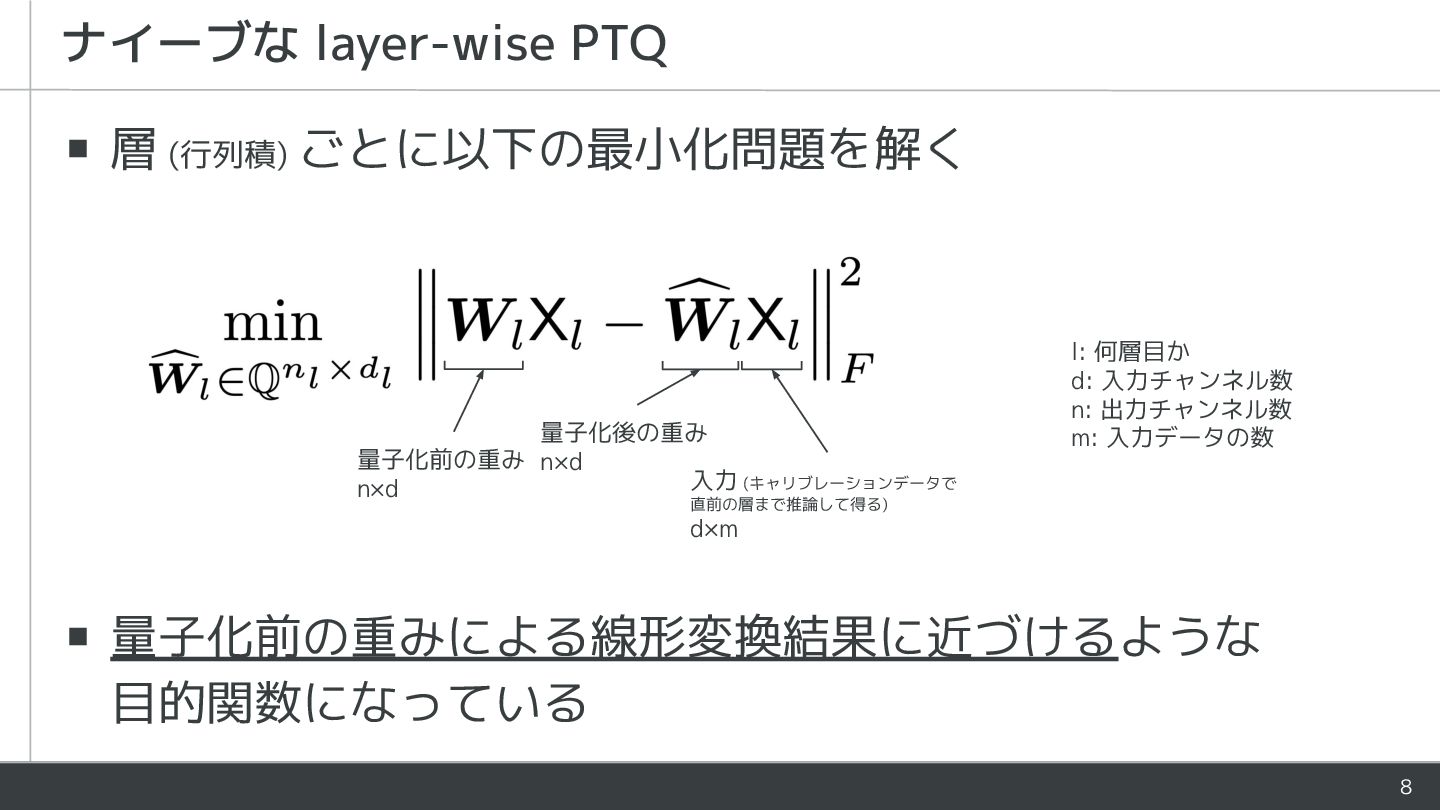
8 ▪ 層 (行列積) ごとに以下の最小化問題を解く ▪ 量子化前の重みによる線形変換結果に近づけるような 目的関数になっている ナイーブな layer-wise
PTQ l: 何層目か d: 入力チャンネル数 n: 出力チャンネル数 m: 入力データの数 量子化前の重み n×d 量子化後の重み n×d 入力 (キャリブレーションデータで 直前の層まで推論して得る) d×m
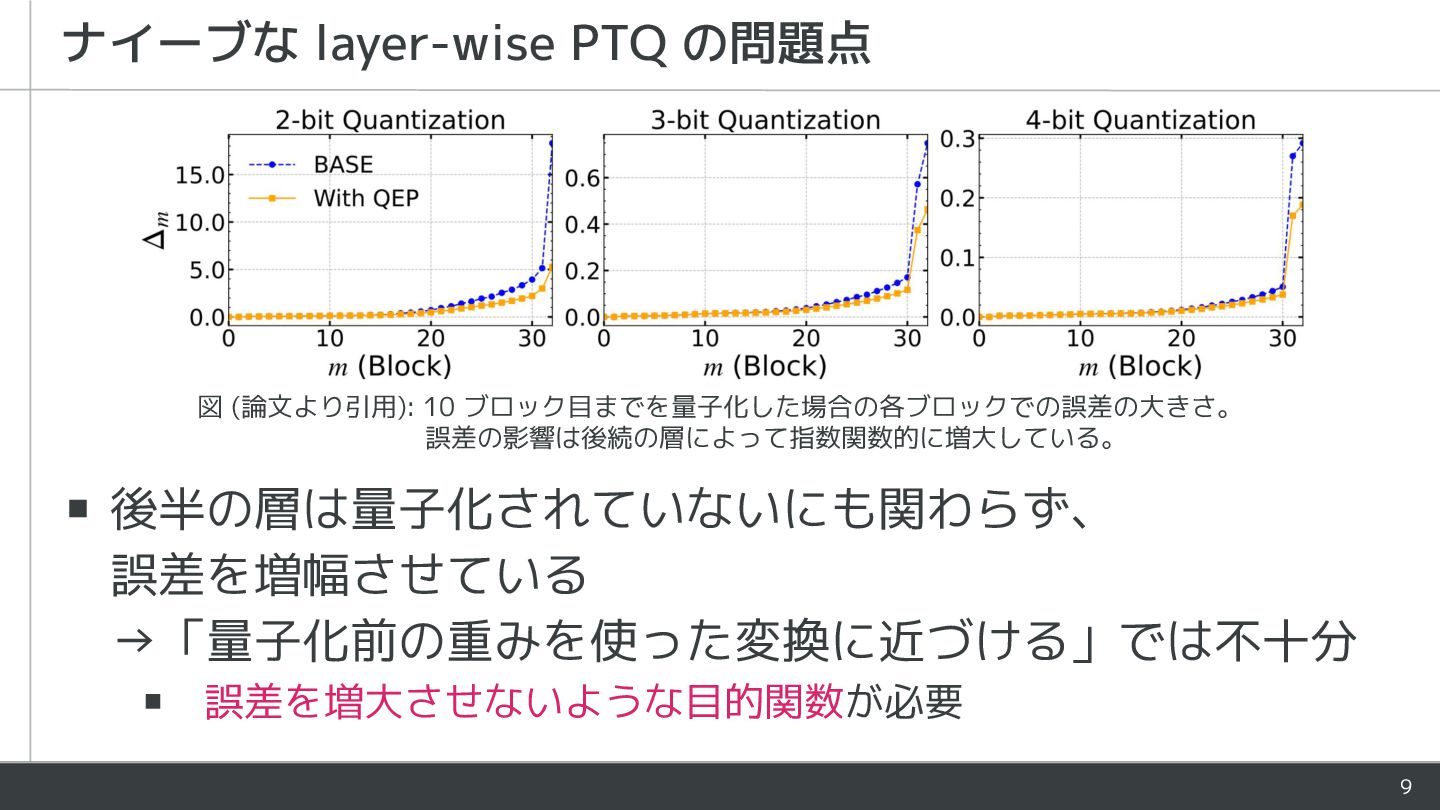
9 ▪ 後半の層は量子化されていないにも関わらず、 誤差を増幅させている →「量子化前の重みを使った変換に近づける」では不十分 ▪ 誤差を増大させないような目的関数が必要 ナイーブな layer-wise PTQ
の問題点 図 (論文より引用): 10 ブロック目までを量子化した場合の各ブロックでの誤差の大きさ。 誤差の影響は後続の層によって指数関数的に増大している。
10 ▪ そこで、目的関数を次のように変更 ▪ 直前の層までに発生した誤差が加味されている ▪ しかし 1 つ問題が…… 目的関数の改善
量子化前の重み n×d 量子化後の重み n×d 量子化された入力 (量子化後の重みを使い、キャリブレーショ ンデータで直前の層まで推論して得る) d×m 量子化されていない入力 (量子化前の重みを使い、キャリブレーショ ンデータで直前の層まで推論して得る) d×m l: 何層目か d: 入力チャンネル数 n: 出力チャンネル数 m: 入力データの数
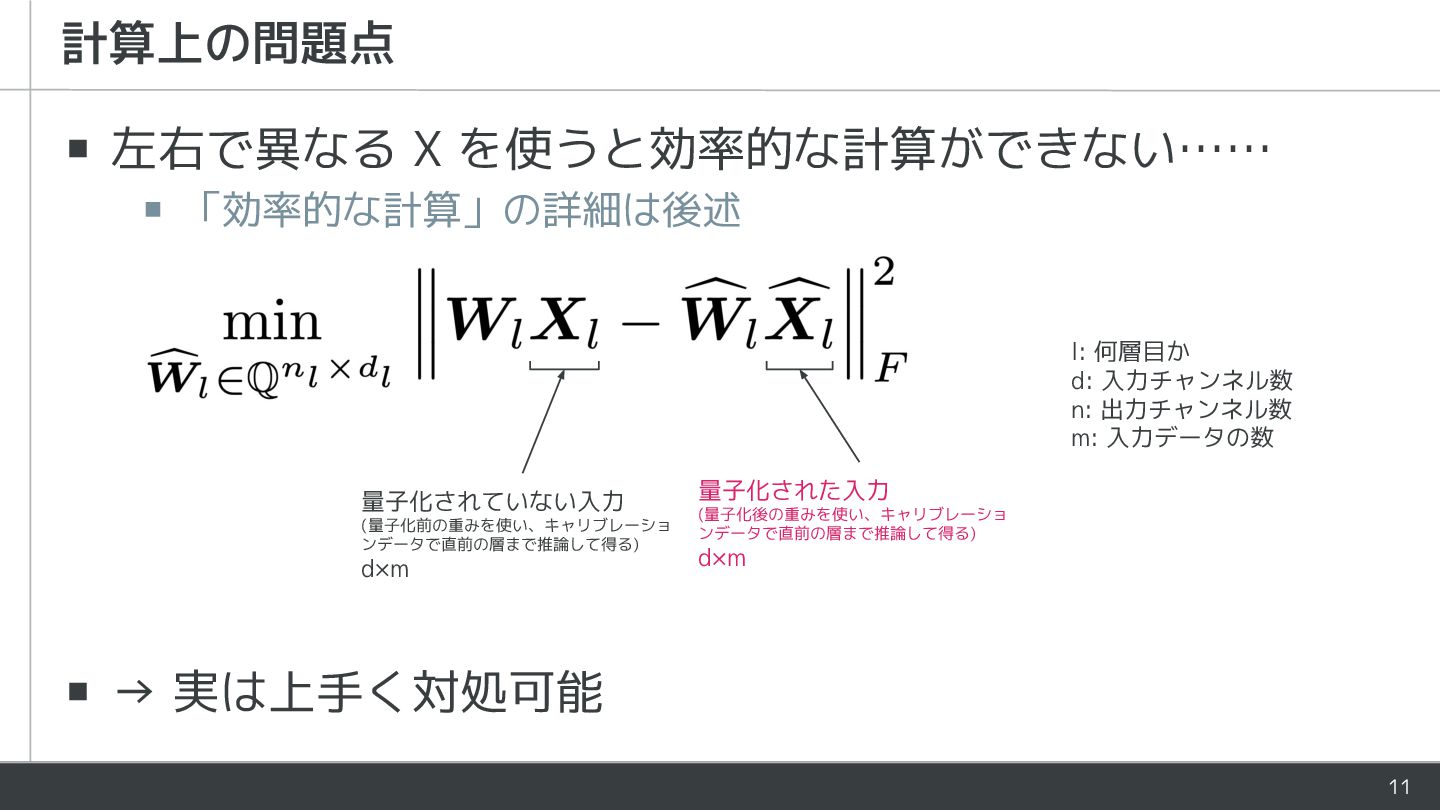
11 ▪ 左右で異なる X を使うと効率的な計算ができない…… ▪ 「効率的な計算」の詳細は後述 ▪ → 実は上手く対処可能
計算上の問題点 量子化された入力 (量子化後の重みを使い、キャリブレーショ ンデータで直前の層まで推論して得る) d×m 量子化されていない入力 (量子化前の重みを使い、キャリブレーショ ンデータで直前の層まで推論して得る) d×m l: 何層目か d: 入力チャンネル数 n: 出力チャンネル数 m: 入力データの数
12 ▪ もし が連続値を取るなら、目的関数を最小化する は 解析的に得られる ▪ すなわち、 による線形変換結果に近づけるような 目的関数で十分
計算上の問題点への対処 ただし 第 2 項は元の重みを補正する項となっている。 キャリブレーションデータへの overfit を防ぐため、 これに [0, 1] の係数を掛けることもできる
13 ▪ つまり、目的関数をこうすれば良い ▪ 2 つの X が一致したことで効率的な計算が可能に 提案手法 量子化後の重み
n×d 量子化された入力 (量子化後の重みを使い、キャリブレーショ ンデータで直前の層まで推論して得る) d×m さっき求めた値 n×d 賢い〜〜 l: 何層目か d: 入力チャンネル数 n: 出力チャンネル数 m: 入力データの数
14 ▪ 目的関数は次のように変形できる ▪ を更新した際、キャリブレーションデータの長さに 非依存な計算量で目的関数を再計算可能 効率的な計算 n×d d×d
W* を求める際に 計算済 d: 入力チャンネル数 n: 出力チャンネル数
15 ▪ AWQ や QuIP などで 2 ~ 4 bit
に量子化する際、 提案手法を併用することで精度向上すると示されている ▪ 詳細は割愛 実験結果
16 ▪ 背景 1: LLM の高速な推論には量子化が不可欠 ▪ 背景 2: 学習後に層ごとに量子化するのが色々と良い
▪ 計算効率が良い ▪ 同じモデルを複数の精度で量子化して提供できる ▪ 課題: ナイーブな方法では層ごとに誤差が増大 ▪ 提案手法: 誤差の増大を抑える目的関数を使う ▪ QuIP など多くの既存の工夫と併用可能 QEP まとめ (概要の再掲) BitNet などは学習時から量子化の影響を 加味している (QAT: Quantization-Aware Training) layer-wise PTQ (PTQ: Post-Training Quantization)
17 03 QQA: 目的関数に対して最適化する
18 ▪ 次を満たす組合せ最適化問題を GPU で効率的に解く ▪ 最適化対象の変数が全てブール値 ▪ と言いつつ、一般の整数に拡張する方法も記載されているし、 連続変数が混ざっても問題ない
▪ 変数に連続値を入れても目的関数を計算可能 (連続緩和を上手く定義可能) ▪ 等式制約や不等式制約が無い ▪ あれば代わりに目的関数にペナルティ項として追加する (layer-wise PTQ は概ね これを満たす) QQA 概要 多分実際は同時にスケーリング係数 (連続値) とかも最適化する必要がある 論文中でベンチマークに使われた問題は最大独立集合問題、最大クリーク問題、 最大カット問題、グラフ分割問題、グラフ彩色問題 1bit の
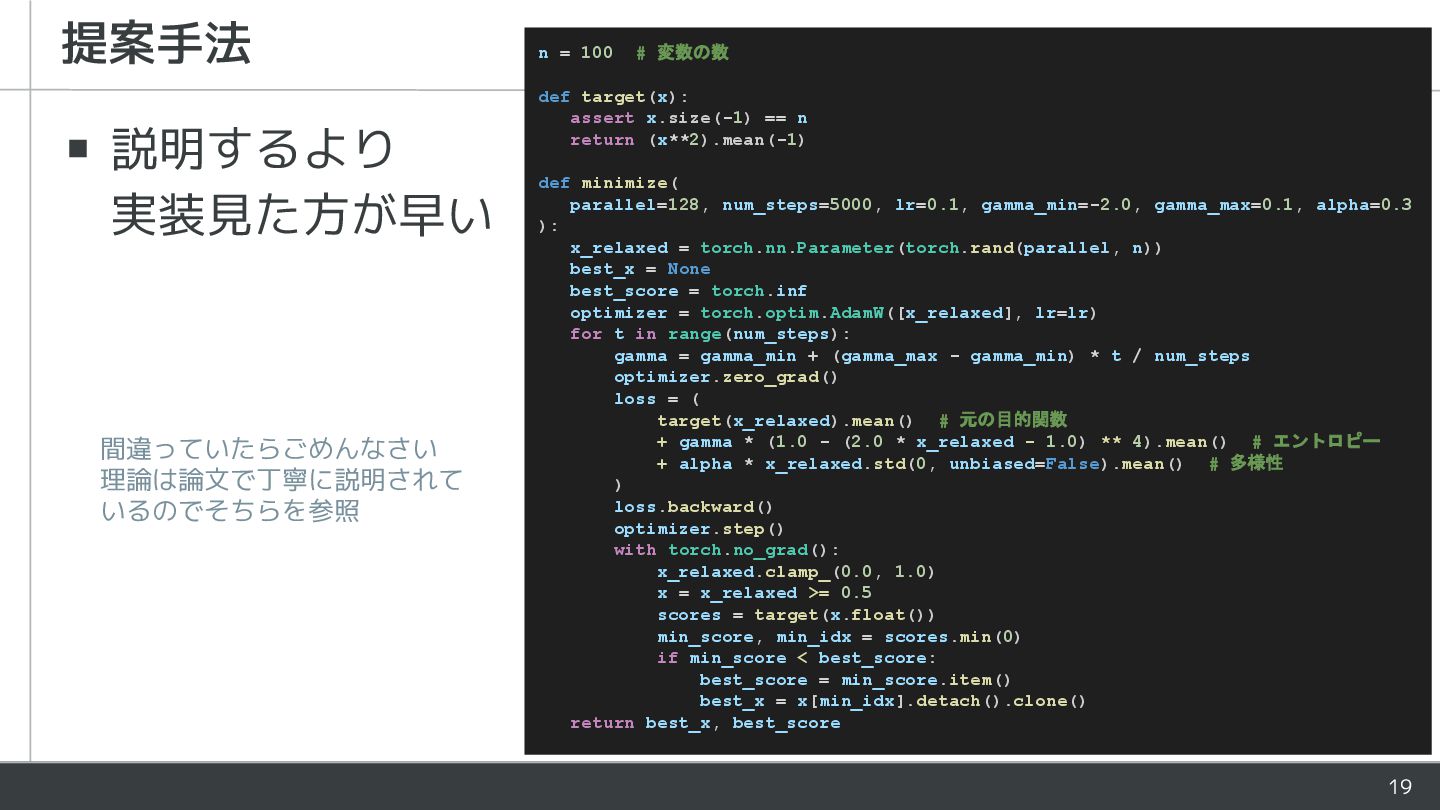
19 ▪ 説明するより 実装見た方が早い 提案手法 n = 100 # 変数の数
def target(x): assert x.size(-1) == n return (x**2).mean(-1) def minimize( parallel=128, num_steps=5000, lr=0.1, gamma_min=-2.0, gamma_max=0.1, alpha=0.3 ): x_relaxed = torch.nn.Parameter(torch.rand(parallel, n)) best_x = None best_score = torch.inf optimizer = torch.optim.AdamW([x_relaxed], lr=lr) for t in range(num_steps): gamma = gamma_min + (gamma_max - gamma_min) * t / num_steps optimizer.zero_grad() loss = ( target(x_relaxed).mean() # 元の目的関数 + gamma * (1.0 - (2.0 * x_relaxed - 1.0) ** 4).mean() # エントロピー + alpha * x_relaxed.std(0, unbiased=False).mean() # 多様性 ) loss.backward() optimizer.step() with torch.no_grad(): x_relaxed.clamp_(0.0, 1.0) x = x_relaxed >= 0.5 scores = target(x.float()) min_score, min_idx = scores.min(0) if min_score < best_score: best_score = min_score.item() best_x = x[min_idx].detach().clone() return best_x, best_score 間違っていたらごめんなさい 理論は論文で丁寧に説明されて いるのでそちらを参照
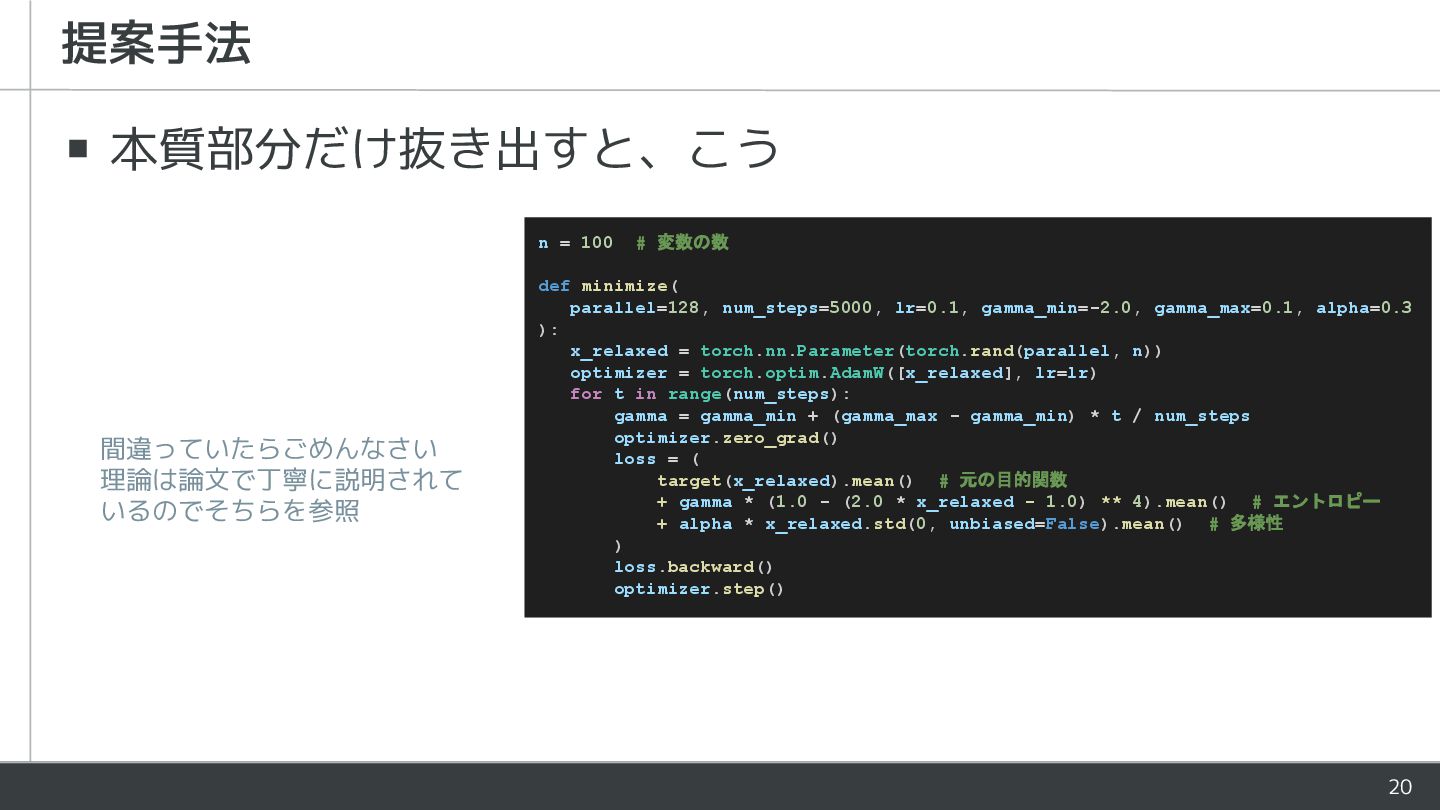
20 ▪ 本質部分だけ抜き出すと、こう 提案手法 n = 100 # 変数の数 def
minimize( parallel=128, num_steps=5000, lr=0.1, gamma_min=-2.0, gamma_max=0.1, alpha=0.3 ): x_relaxed = torch.nn.Parameter(torch.rand(parallel, n)) optimizer = torch.optim.AdamW([x_relaxed], lr=lr) for t in range(num_steps): gamma = gamma_min + (gamma_max - gamma_min) * t / num_steps optimizer.zero_grad() loss = ( target(x_relaxed).mean() # 元の目的関数 + gamma * (1.0 - (2.0 * x_relaxed - 1.0) ** 4).mean() # エントロピー + alpha * x_relaxed.std(0, unbiased=False).mean() # 多様性 ) loss.backward() optimizer.step() 間違っていたらごめんなさい 理論は論文で丁寧に説明されて いるのでそちらを参照
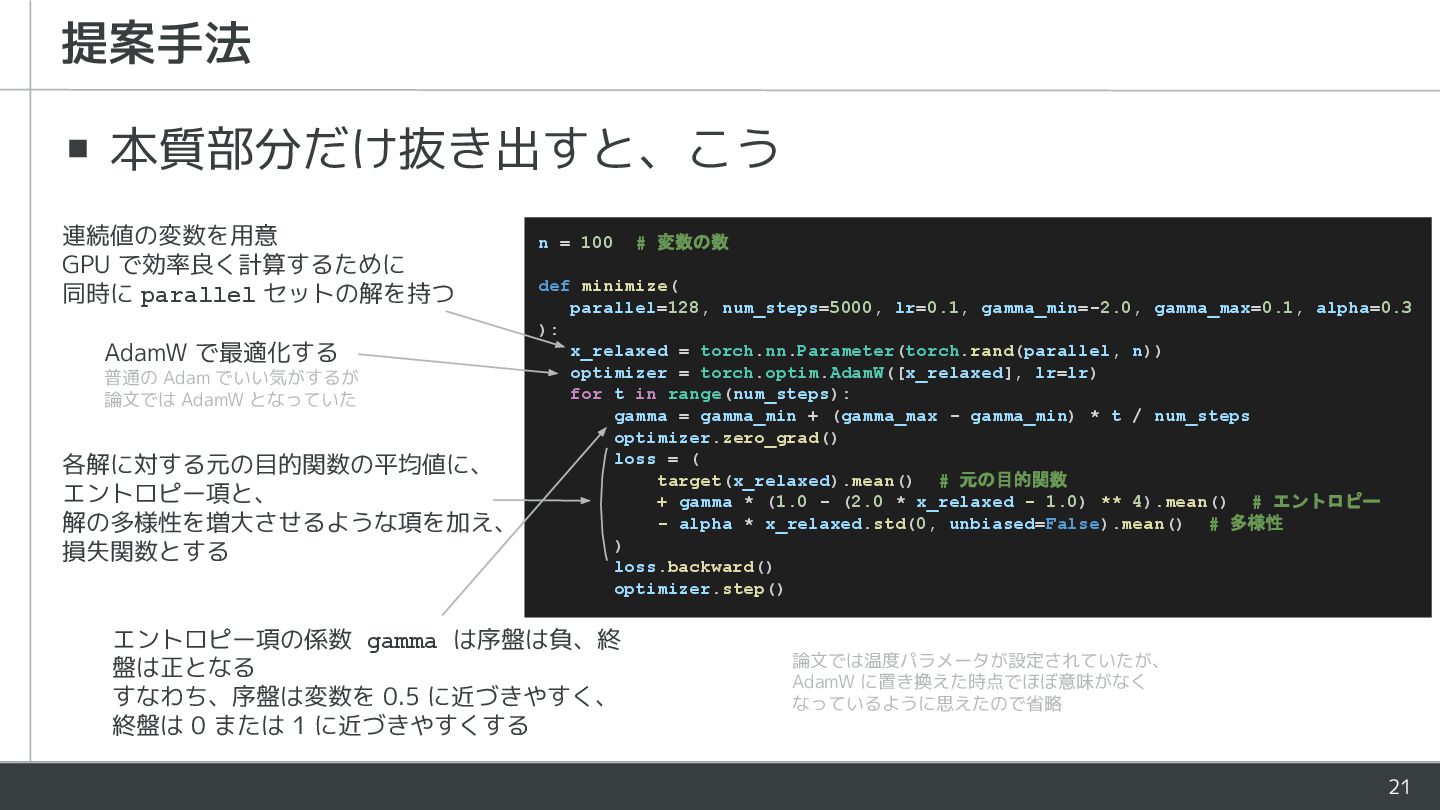
21 ▪ 本質部分だけ抜き出すと、こう 提案手法 n = 100 # 変数の数 def
minimize( parallel=128, num_steps=5000, lr=0.1, gamma_min=-2.0, gamma_max=0.1, alpha=0.3 ): x_relaxed = torch.nn.Parameter(torch.rand(parallel, n)) optimizer = torch.optim.AdamW([x_relaxed], lr=lr) for t in range(num_steps): gamma = gamma_min + (gamma_max - gamma_min) * t / num_steps optimizer.zero_grad() loss = ( target(x_relaxed).mean() # 元の目的関数 + gamma * (1.0 - (2.0 * x_relaxed - 1.0) ** 4).mean() # エントロピー - alpha * x_relaxed.std(0, unbiased=False).mean() # 多様性 ) loss.backward() optimizer.step() 連続値の変数を用意 GPU で効率良く計算するために 同時に parallel セットの解を持つ AdamW で最適化する 普通の Adam でいい気がするが 論文では AdamW となっていた エントロピー項の係数 gamma は序盤は負、終 盤は正となる すなわち、序盤は変数を 0.5 に近づきやすく、 終盤は 0 または 1 に近づきやすくする 各解に対する元の目的関数の平均値に、 エントロピー項と、 解の多様性を増大させるような項を加え、 損失関数とする 論文では温度パラメータが設定されていたが、 AdamW に置き換えた時点でほぼ意味がなく なっているように思えたので省略
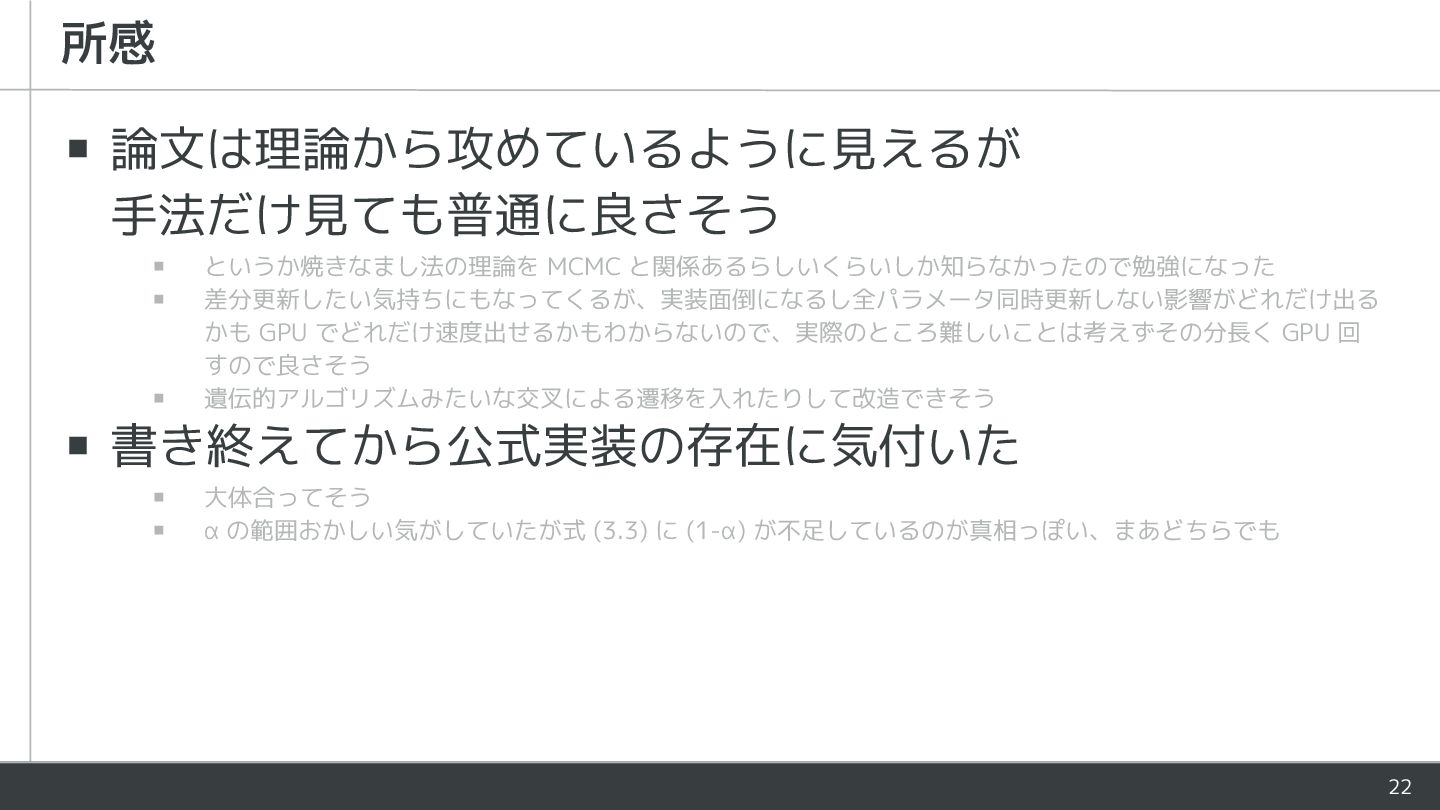
22 ▪ 論文は理論から攻めているように見えるが 手法だけ見ても普通に良さそう ▪ というか焼きなまし法の理論を MCMC と関係あるらしいくらいしか知らなかったので勉強になった ▪ 差分更新したい気持ちにもなってくるが、実装面倒になるし全パラメータ同時更新しない影響がどれだけ出る
かも GPU でどれだけ速度出せるかもわからないので、実際のところ難しいことは考えずその分長く GPU 回 すので良さそう ▪ 遺伝的アルゴリズムみたいな交叉による遷移を入れたりして改造できそう ▪ 書き終えてから公式実装の存在に気付いた ▪ 大体合ってそう ▪ α の範囲おかしい気がしていたが式 (3.3) に (1-α) が不足しているのが真相っぽい、まあどちらでも 所感
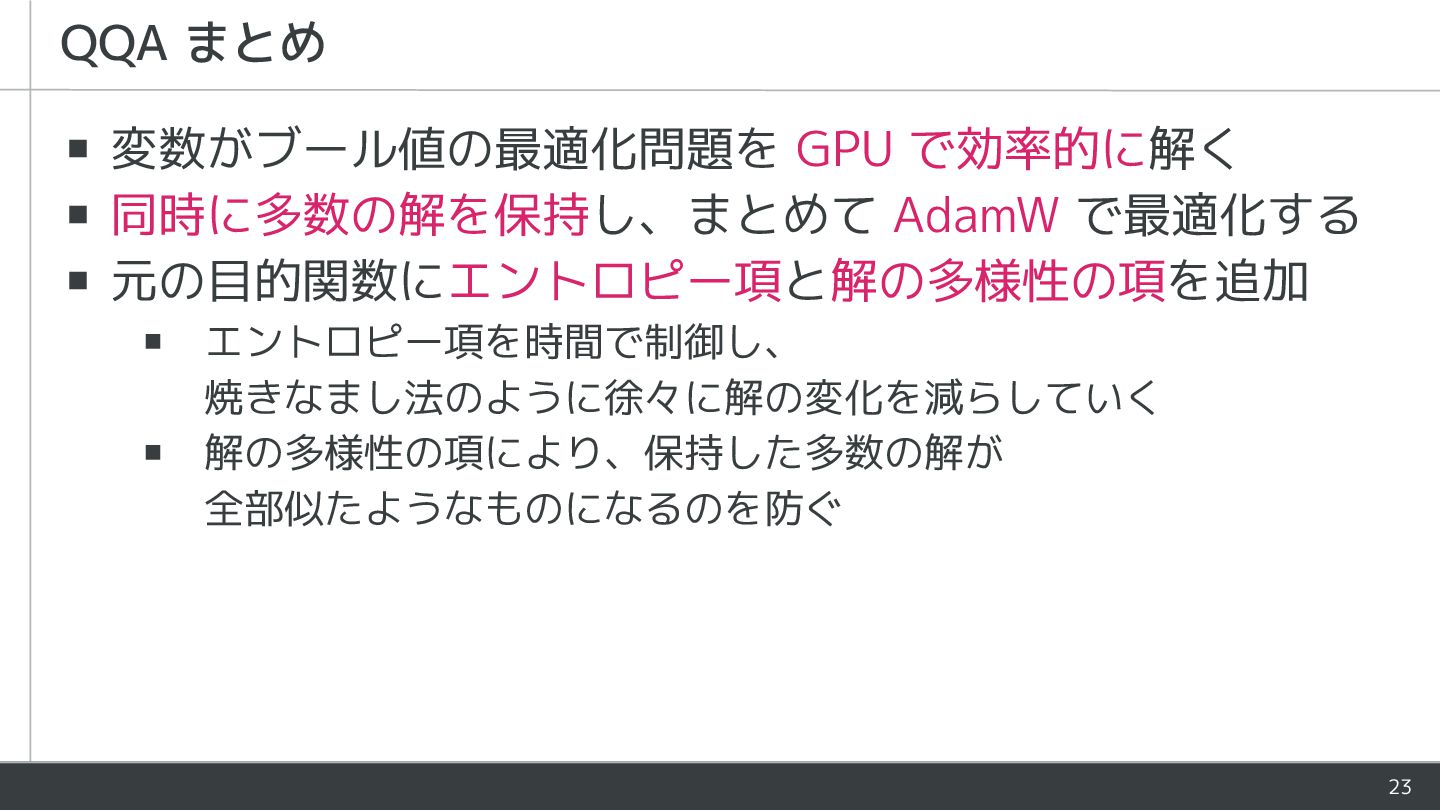
23 ▪ 変数がブール値の最適化問題を GPU で効率的に解く ▪ 同時に多数の解を保持し、まとめて AdamW で最適化する ▪
元の目的関数にエントロピー項と解の多様性の項を追加 ▪ エントロピー項を時間で制御し、 焼きなまし法のように徐々に解の変化を減らしていく ▪ 解の多様性の項により、保持した多数の解が 全部似たようなものになるのを防ぐ QQA まとめ
24 04 まとめ
25 ▪ 2 つの手法で LLM の 1 bit での量子化を実現していた ▪
QEP (Quantization Error Propagation) ▪ 学習済みの NN をナイーブに層ごとに量子化すると、後続の層の計 算を経るごとに誤差の影響が指数関数的に増大する ▪ これを防ぐ目的関数を提案 ▪ QQA (Quasi-Quantum Annealing) ▪ 目的関数を最小化する {0, 1} の配置を GPU で効率的に探索する方法 まとめ
26 ▪ 面倒な部分は色々残っている ▪ QEP は他の手法と併用可能だったが、何と併用する? ▪ 公開された Command-A の
1bit 量子化モデルは OneBit という 手法と併用されている ▪ どこをどれ程量子化する?各種ハイパーパラメータはどうする? ▪ 上記モデルは最後の 2 ブロックが FP16 ▪ 1bit まで縮めると少数の FP16 の容量が無視できなくなりそう ▪ 上記モデルは 30.2GB あると記載されているので平均 2.3bit ▪ etc... 補遺 (1) Embedding 層は量子化の意味が薄いのでその部分は考えなくて良いが、 恐らくそれ抜きにしても無視できない容量がありそう
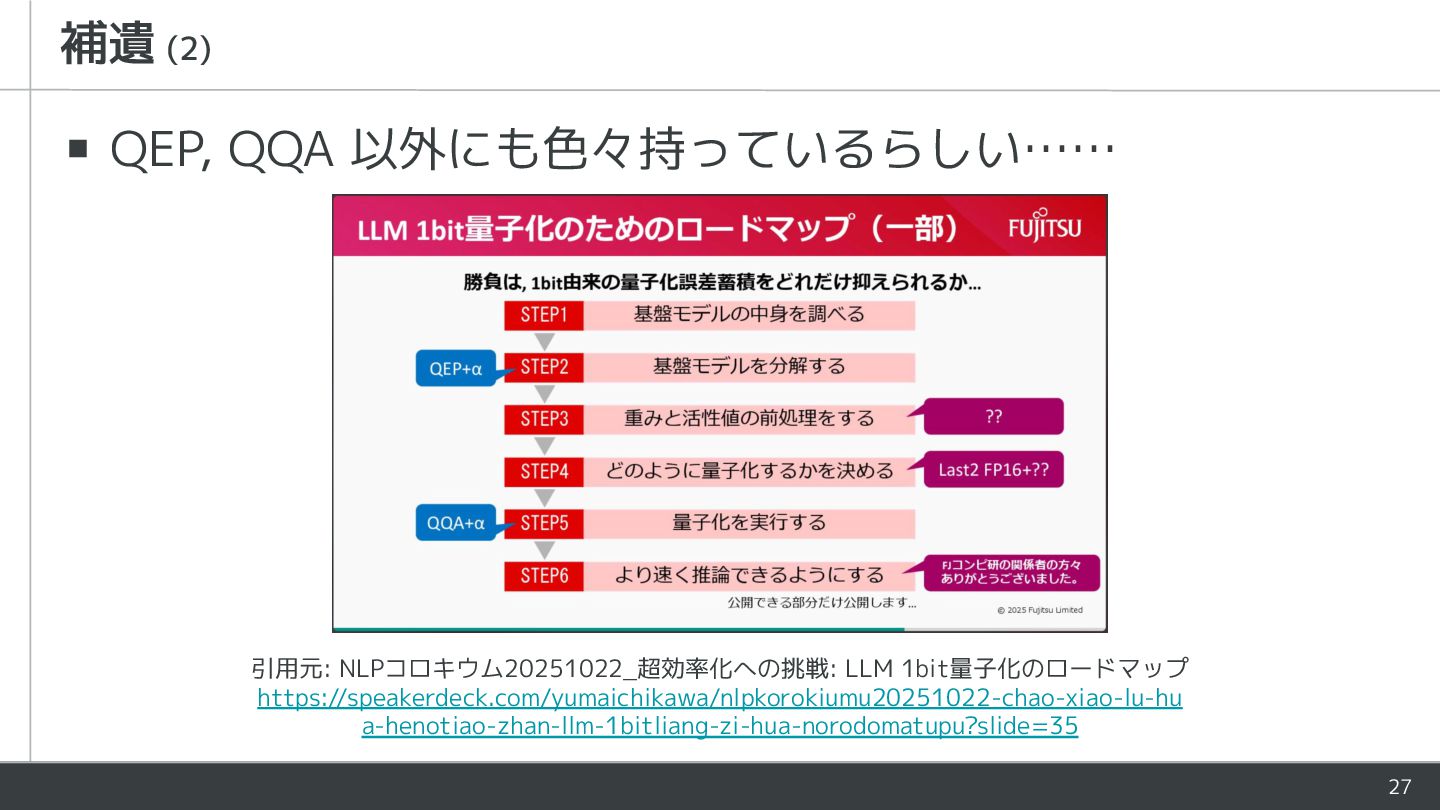
27 ▪ QEP, QQA 以外にも色々持っているらしい…… 補遺 (2) 引用元: NLPコロキウム20251022_超効率化への挑戦: LLM
1bit量子化のロードマップ https://speakerdeck.com/yumaichikawa/nlpkorokiumu20251022-chao-xiao-lu-hu a-henotiao-zhan-llm-1bitliang-zi-hua-norodomatupu?slide=35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}