part of all organisation 🛠 • Data ingestion, transformation and storage of huge data sets 🔥🔥🔥 • Observability gives greater control over system 🧐 • Let’s talk about Observability in Data ingestion 🔎
contributing at Gitpod 🛠 Previously worked at Zeotap, Grofers developing solutions for software reliability. 🧡 I Love open source ✏ I love writing about tech at nancychauhan.in
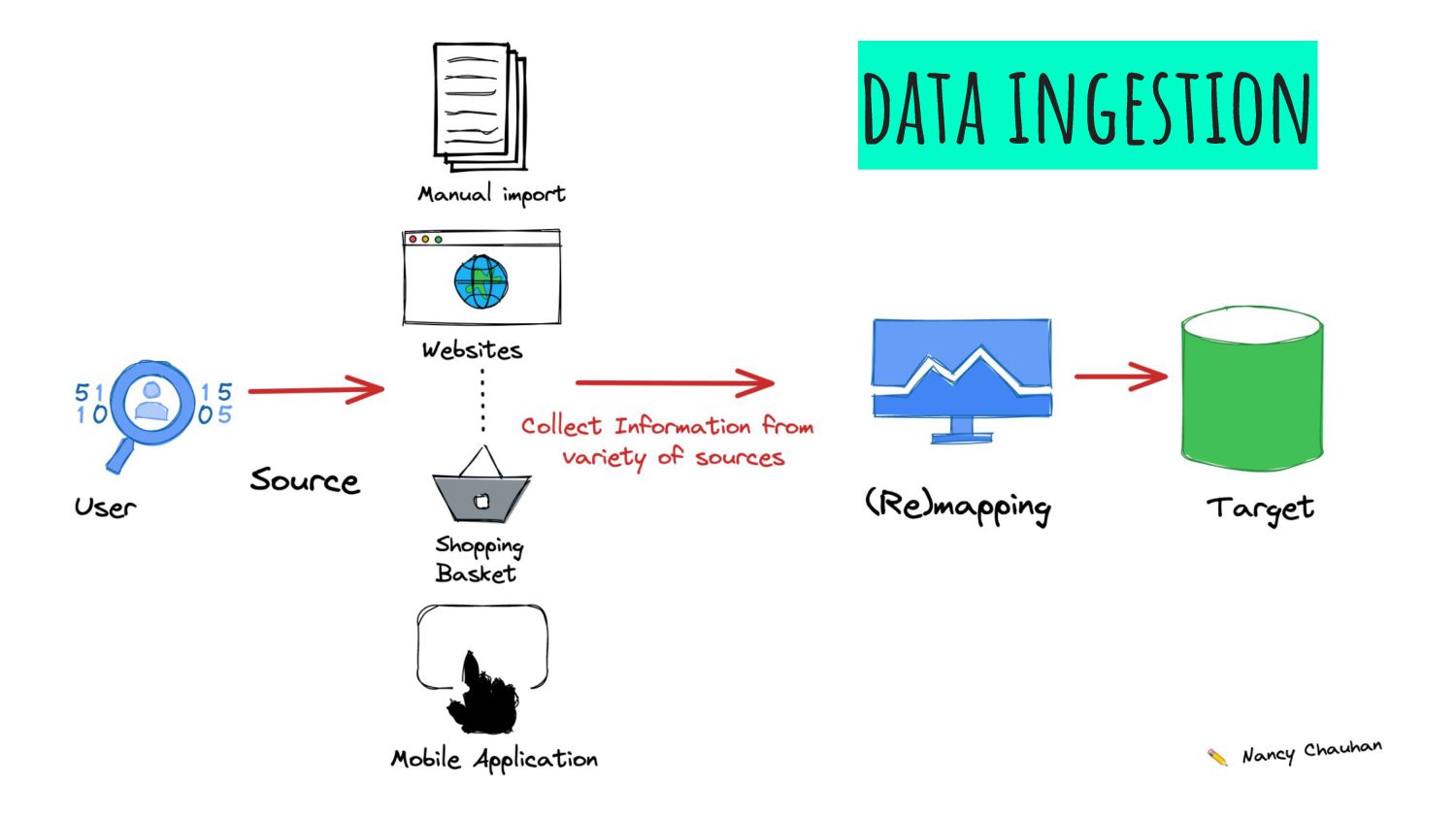
production environment 📦 Focus 🎯 Get data into any systems that require data in a particular structure/format for operation use of the data downstream It addresses the need to process huge amount of data 🚀 Main use case of Data ingestion is for Business Analytics 📈📊
of data can not always be 100% error-free.🐛 • All plans are futile if unreliable data is ingested, transformed and pushed downstream. • If there is failure, your data pipeline should handle it gracefully, it should log so that we can take action ⚙
are somewhat interconnected and non-intuitive ⛓ • Internal and External data could become faulty, inconsistent, inaccurate, missing, change abruptly eventually affect the correctness of other dependent data assets.
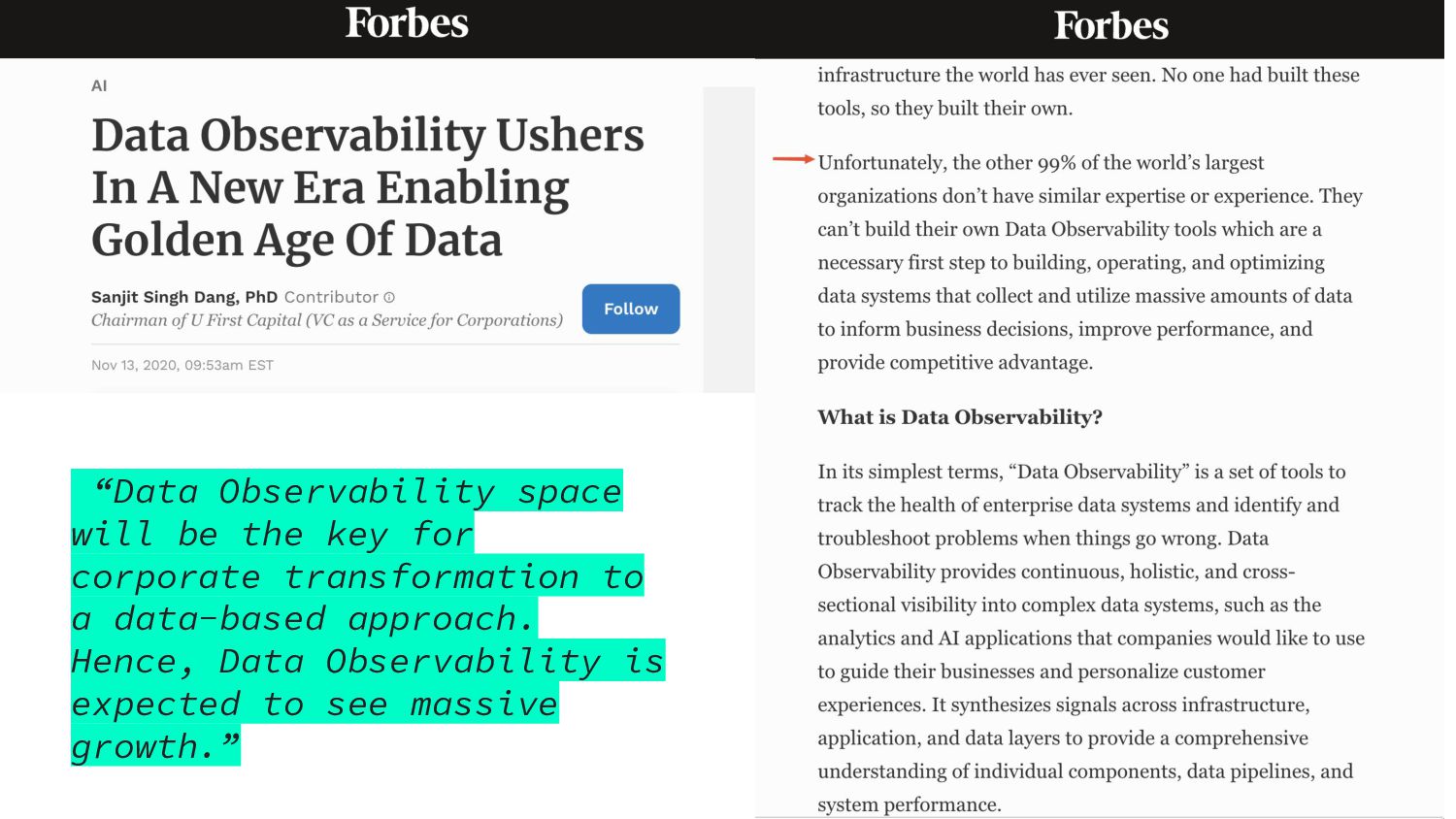
and infrastructures, data and analytics teams would be merely flying blind (i.e., they can’t fully understand the health of the pipeline and/or understand what’s happening between data inputs and outputs).
and is up to date? Volume: Are the data tables complete and correct? Distribution: Is data reliable? Do data values fall within an acceptable range Lineage: Who is generating data? Who will use the data for making business decisions. Schema: Is the data in correct format? Did the data schema change? Who made changes? How can we correct it?
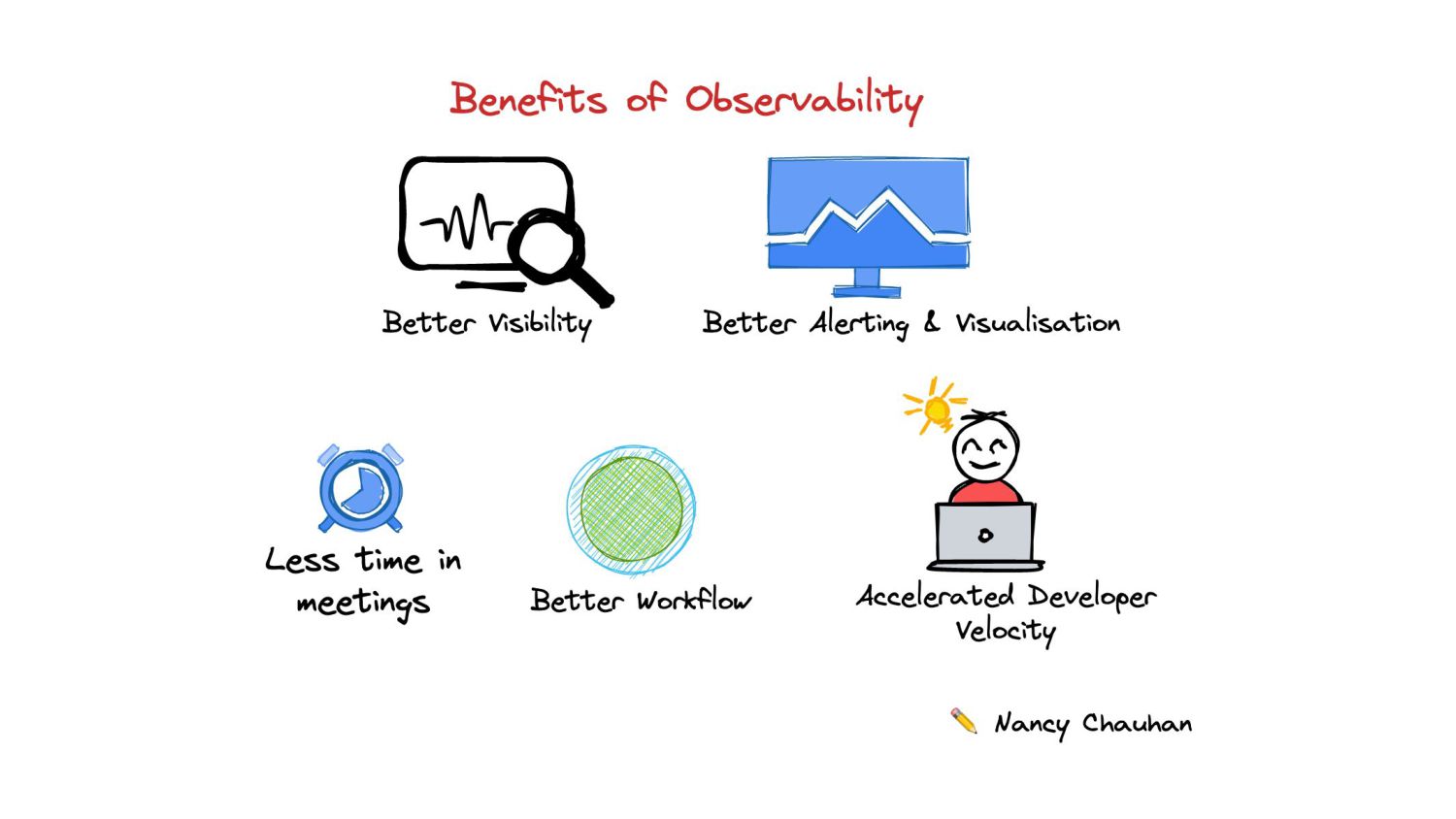
Capture errors 🐛, build control system, single access/dashboard to show all failures, show % of errors. -> Create transparency in data pipelines ✨ -> Enable alerting: Take quick action
pipeline • Total no of records processed • Total no of failures • % of failures • Duration of pipeline • Count of unique data (deduplication) • Data related error (error message -> getting integer in string column) • Data ingestion rate and efficiency • Alerting and Visualisation • Error rate • Error messages
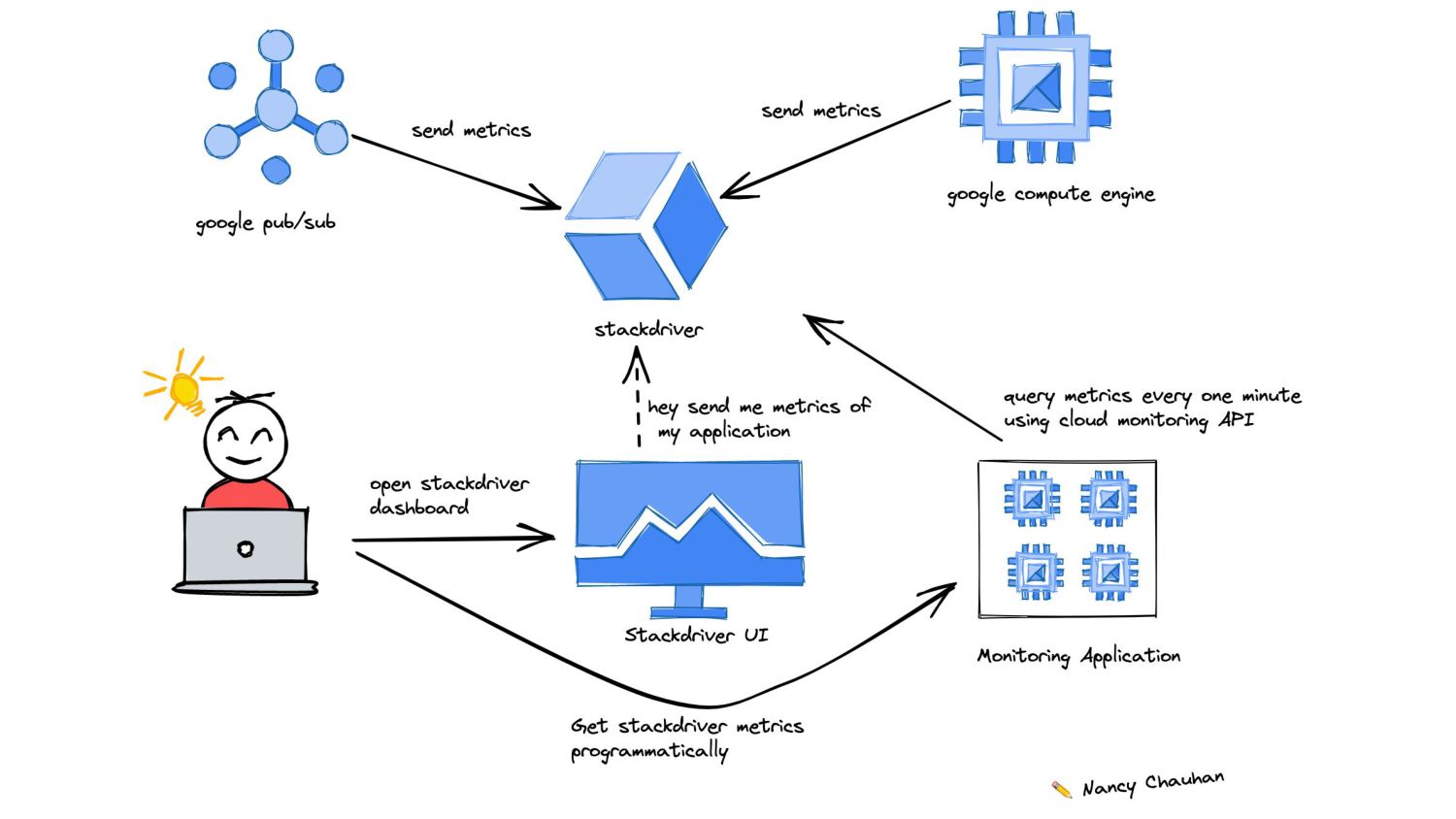
case: Get the count of messages published in a pub/sub topic for streaming sources to calculate ingestion efficiency % • One of the quickest ways I found was using Stackdriver. 🚀 • Demo 💻 https://github.com/Nancy-Chauhan/stackdriver-example • Here is the Blog link: https://nancy-chauhan.medium.com/improve-observability-us ing-stackdriver-metrics-programmatically-a29bfd7051e0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}