Web Page Layout Optimization (PG’21) Constrained Graphic Layout Generation via Latent Optimization (ACMMM’21) CanvasVAE: Learning To Generate Vector Graphic Documents (ICCV’21) De-Rendering Stylized Texts (ICCV’21) An intelligent color recommendation tool for landing page design (IUI’22) Color Recommendation for Vector Graphic Documents Based on Multi-Palette Representation (WACV’23) Generative Colorization of Structured Mobile Web Pages (WACV’23) Coarse-to-fine font recommendation for banner designs (IUI’23) LayoutDM: Discrete Diffusion Model for Controllable Layout Generation (CVPR’23) Towards Flexible Multi-modal Document Models (CVPR’23) Multimodal Color Recommendation in Vector Graphic Documents (ACMMM’23) Towards Diverse and Consistent Typography Generation (WACV’24) Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation (CVPR’24) OpenCOLE: Towards Reproducible Automatic Graphic Design Generation (CVPRW’24) Visual Explanation for Advertising Creative Workflow (CHI’24) LayoutFlow: Flow Matching for Layout Generation (ECCV’24) Fast Sprite Decomposition from Animated Graphics (ECCV’24) Can GPT Evaluate Graphic Designs Based on Design Principles? (SIGGRAPHASIA TC’24) LTSim: Layout Transportation-based Similarity Measure for Evaluating Layout Generation (arXiv’24) Multimodal Markup Document Models for Graphic Design Completion (arXiv’24) Type-R: Automatically Retouching Typos for Text-to-Image Generation (arXiv’24)
a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy https://stability.ai/news/stable-diffusion-3
(Waseda U.) CA みなさん 共同研究先 先生・学生・インターン みなさん W. Shimoda K. Masui R. Togashi D. Horita (UTokyo) K. Aizawa (UTokyo) J. Guerreiro (UTokyo) H. Nakayama (UTokyo) S. Uchida (Kyushu U.) D. Haraguchi H. Mitani (Kyushu U.)
{kind=link}
![2 専門: 生成モデル 実世界応用 [HP] • 最近 グラフィックデザインに注力 経歴: •](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
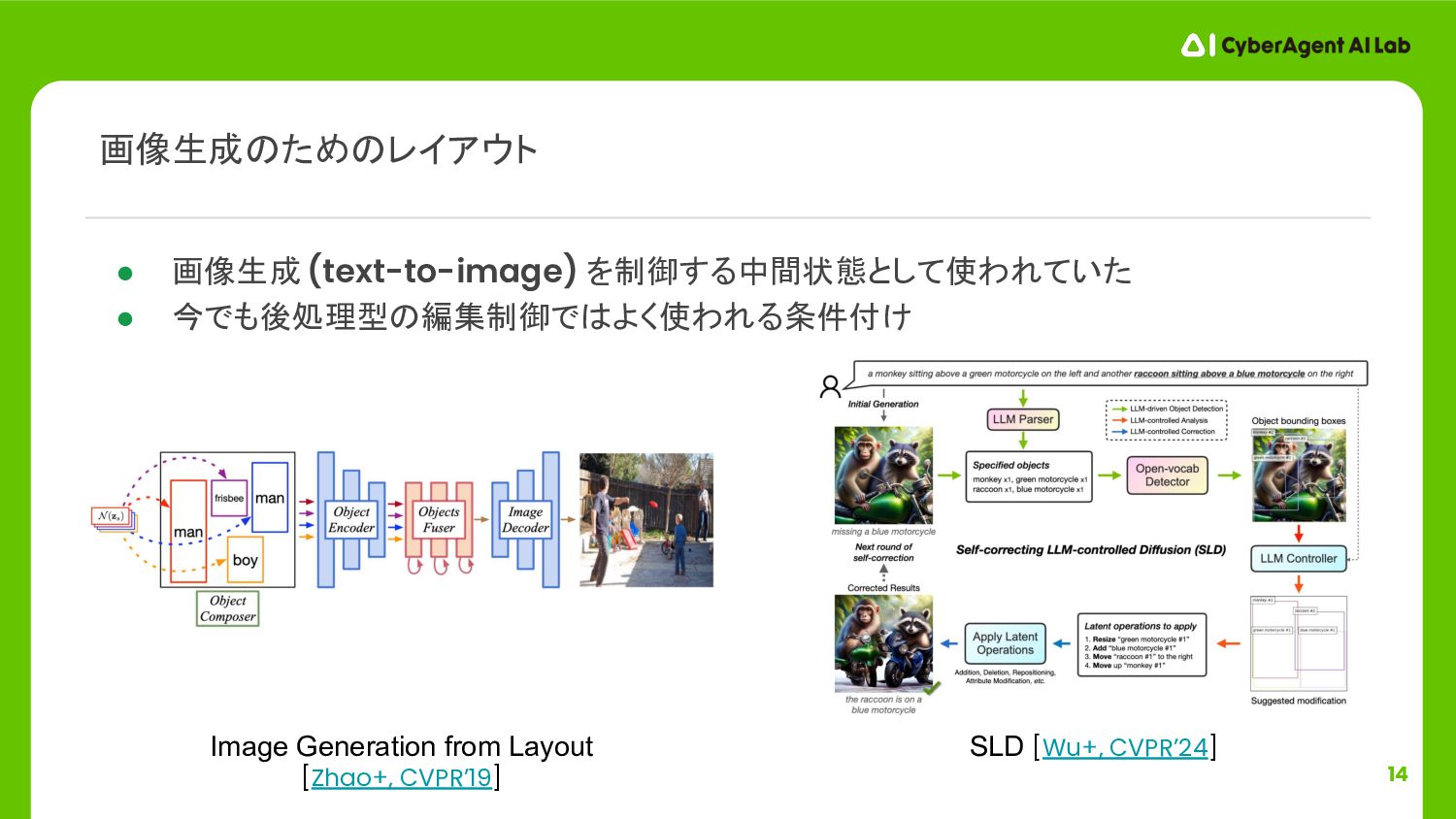
{kind=link}
{kind=link}
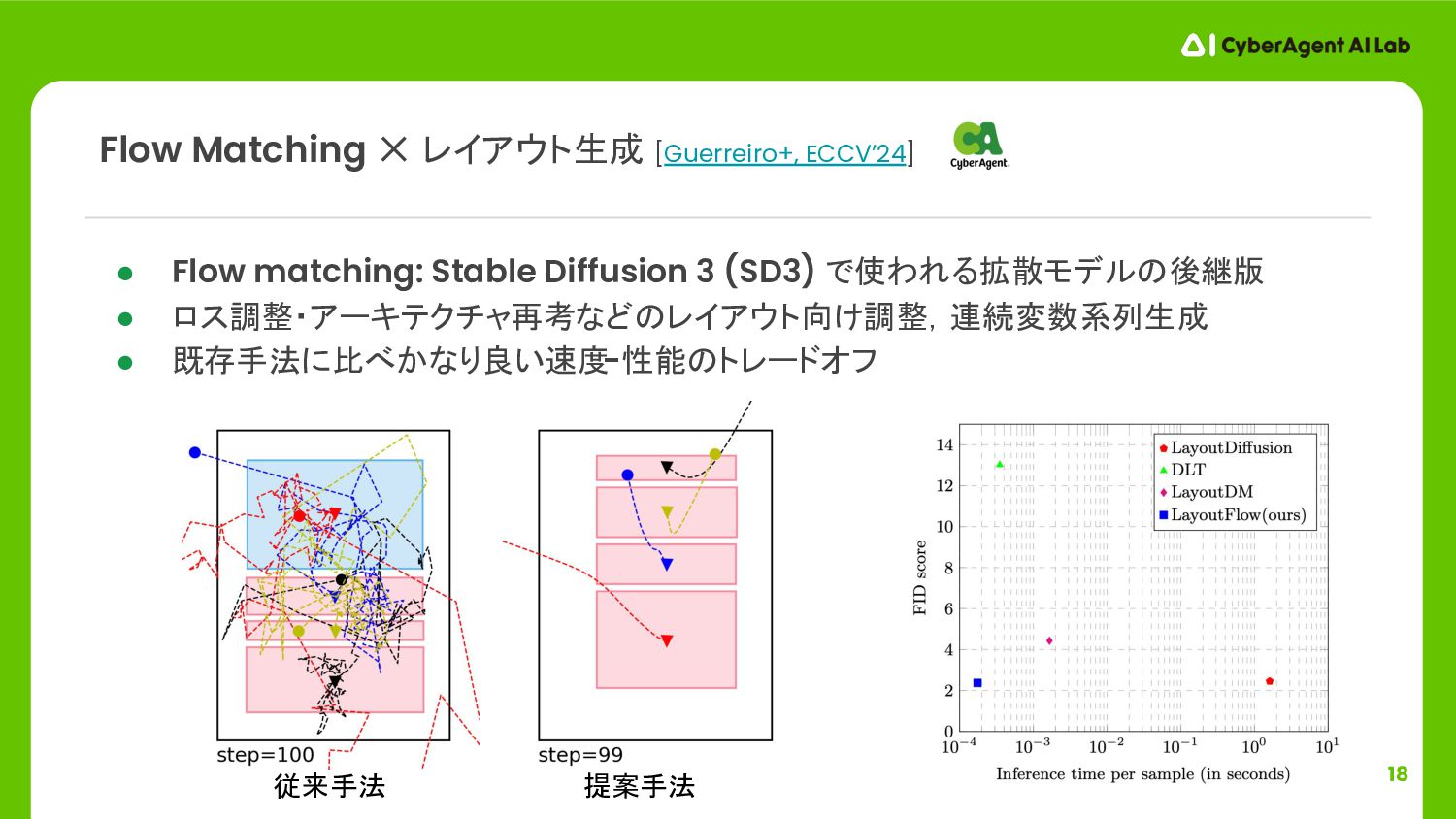
{kind=link}
{kind=link}
{kind=link}
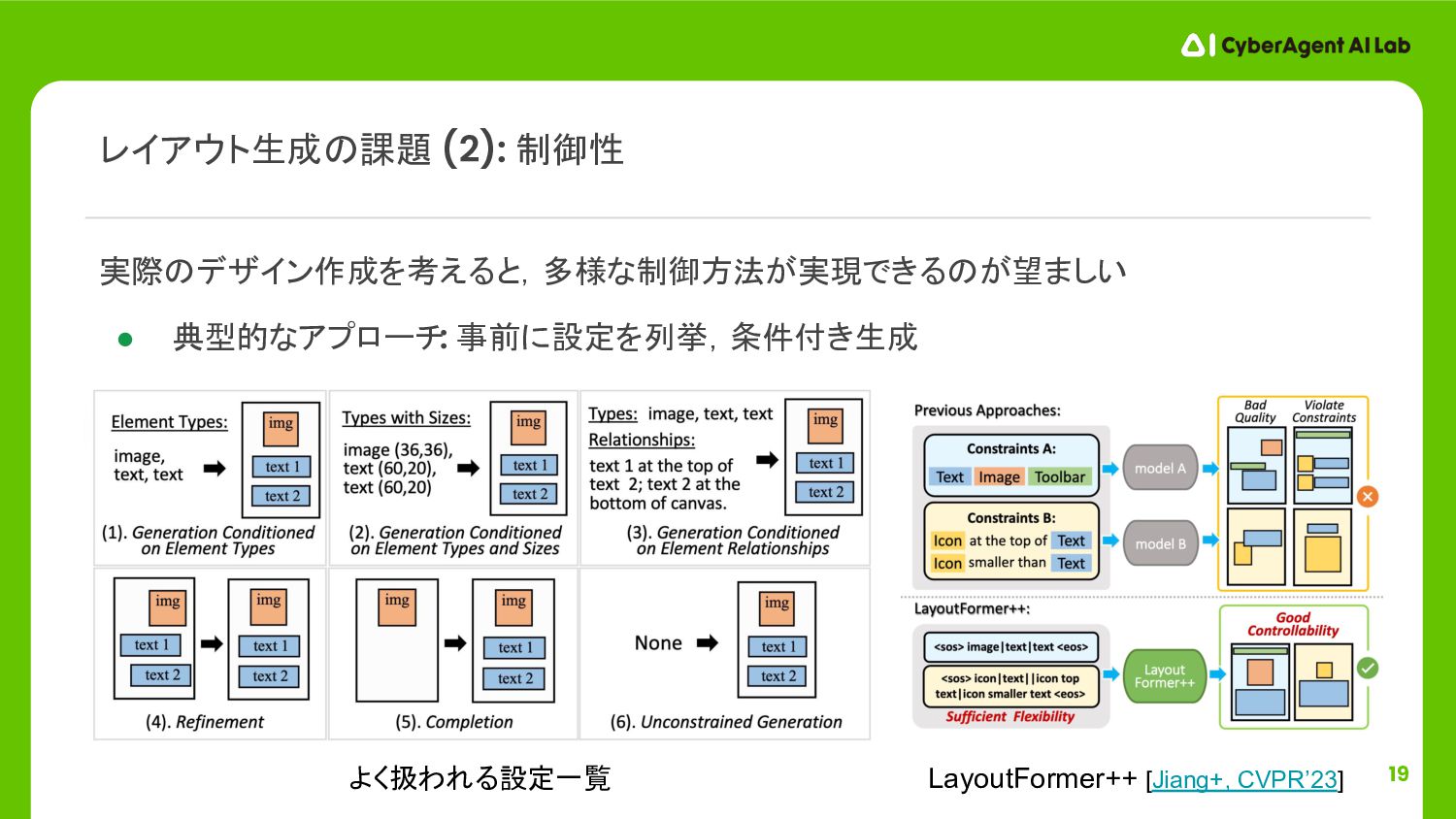
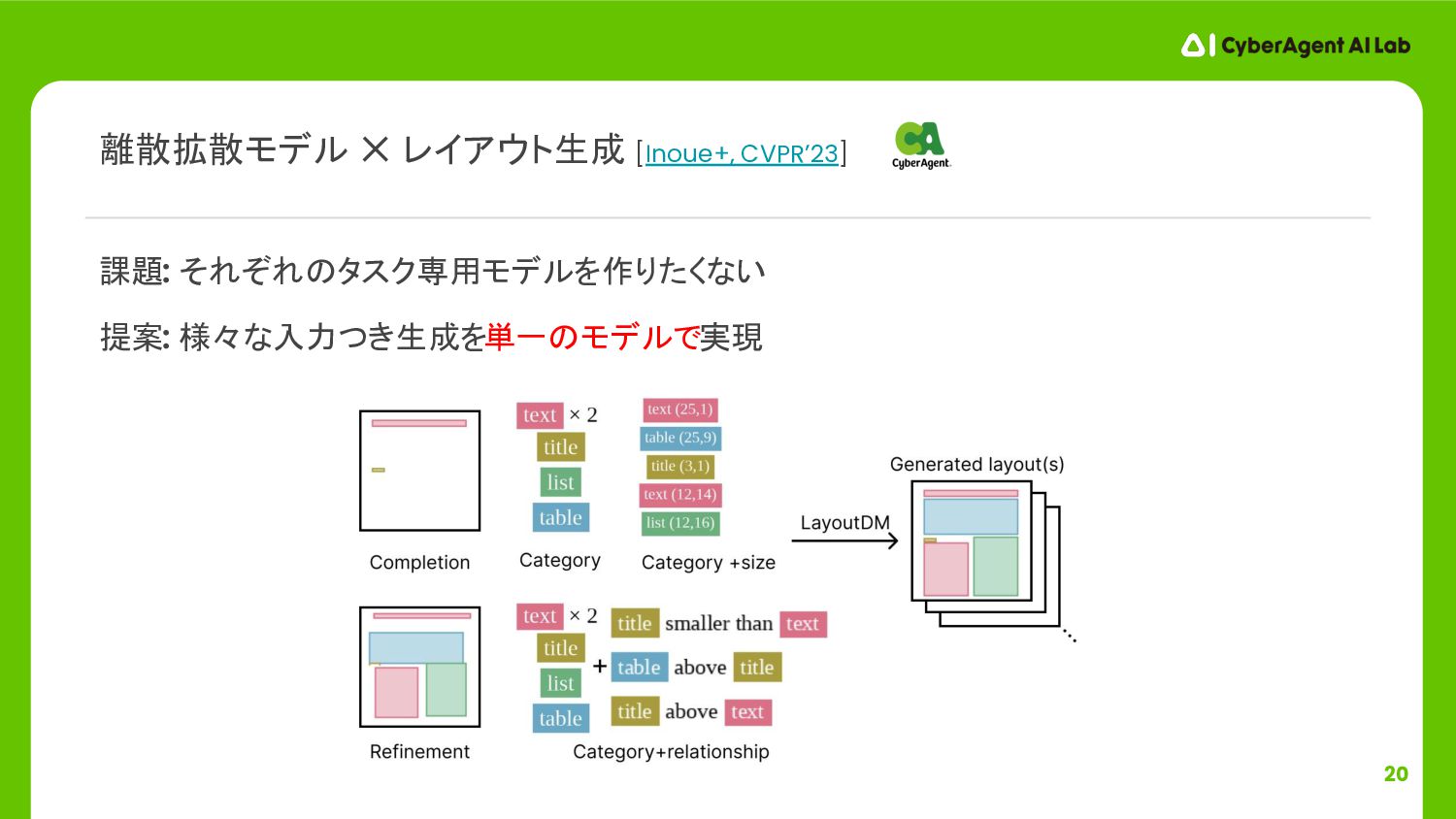
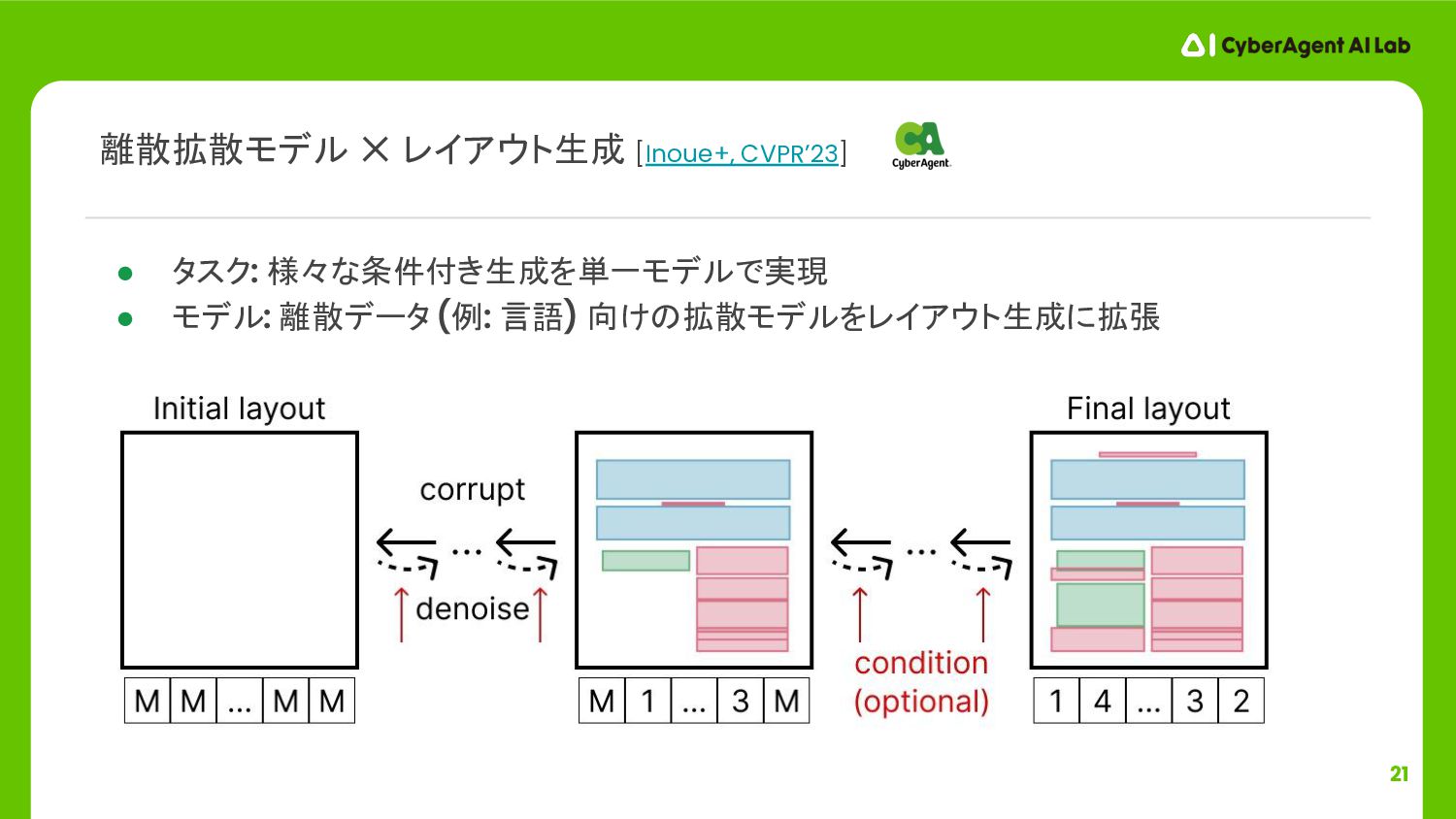
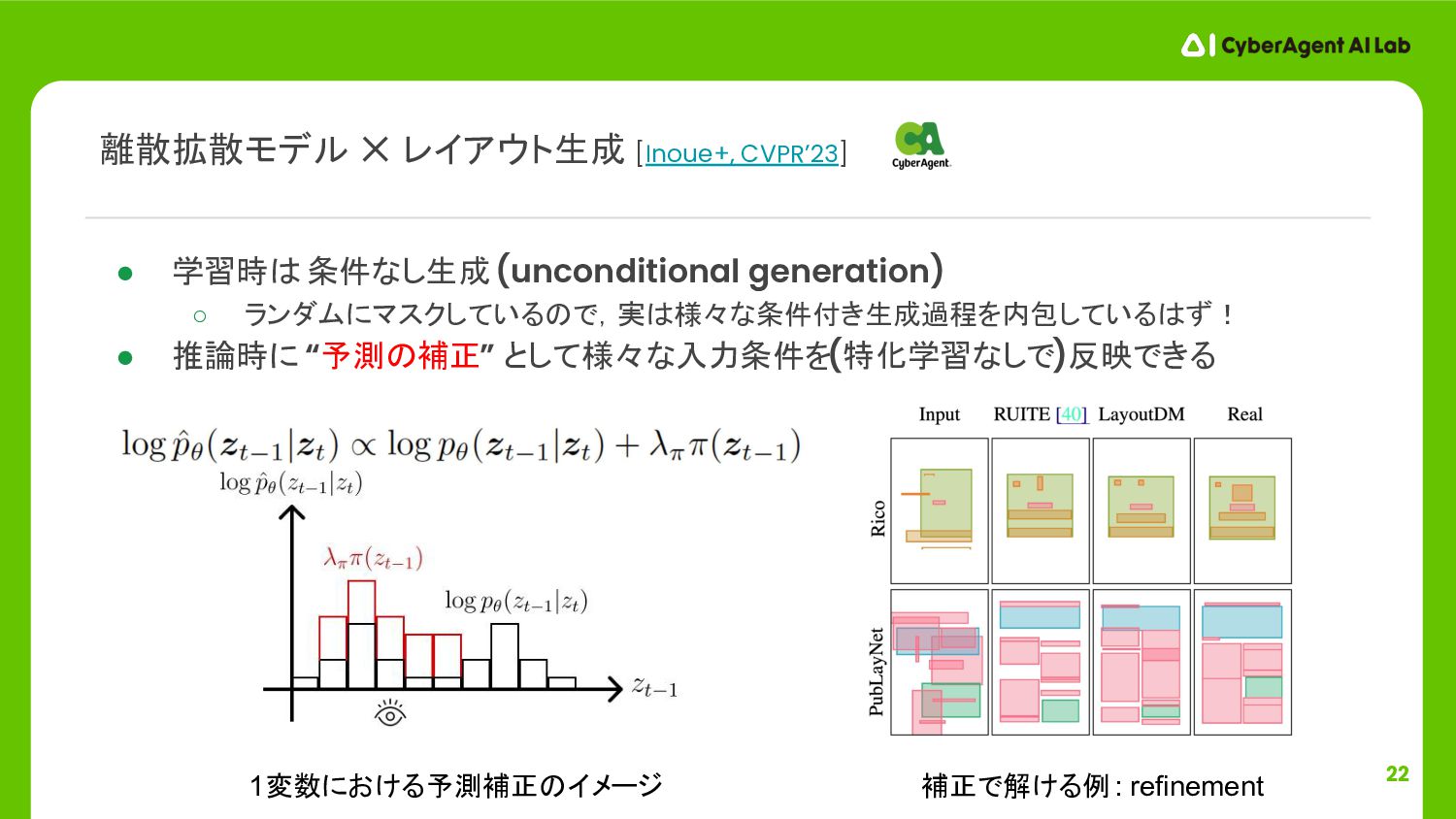
![17 LayoutGAN [Li+, ICLR’19], LayoutVAE [Jyothi+, ICCV’19], LayoutTrans. [Gupta+, ICCV’21]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 レイアウト生成 発展: 画像や文章を入力条件に考慮 Background-to-layout [Zhou+, IJCAI’22] Text-to-layout [Lin+, ICCV’23]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_22.jpg){kind=link}
{kind=link}
![25 レイアウト検索: 画像ベース,画像が似ていれ レイアウトも似る ず RAG ✕ レイアウト生成 [Horita+, CVPR’24]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_24.jpg){kind=link}
![26 検索結果 使い道: 学習ベースで近そうなレイアウト 特徴を抽出・融合 RAG ✕ レイアウト生成 [Horita+, CVPR’24]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_25.jpg){kind=link}
![27 集合レベル • 画像生成モデル 評価を真似たも : Layout-FID [Kikuchi+, ACMMM’21] ◦](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_26.jpg){kind=link}
{kind=link}
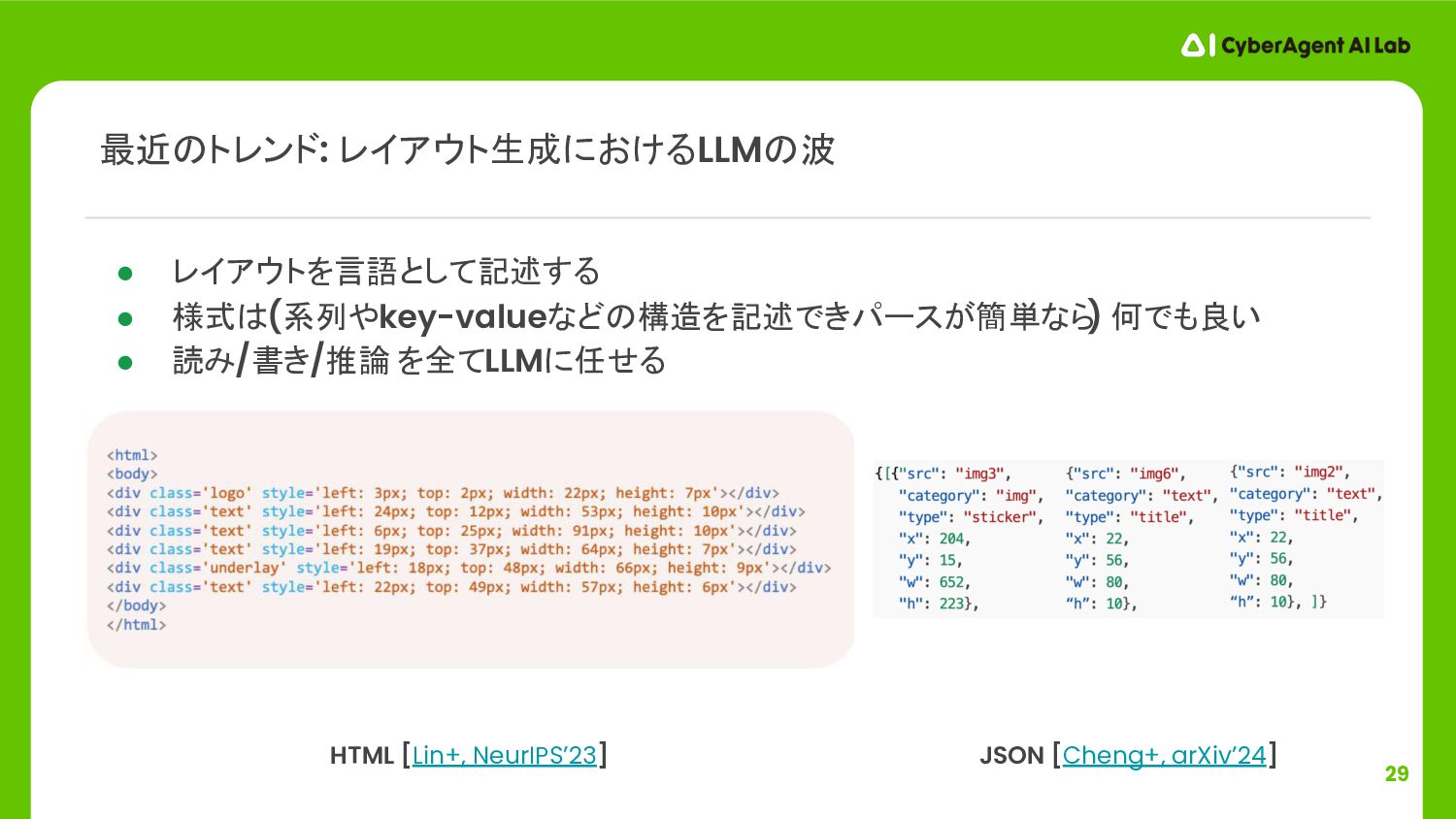{kind=link}
![30 制約条件・追加入力なども自然言語で表現し,適応範囲 広さがとにかく魅力 レイアウト生成で LLM 活用例: LayoutPrompter [Lin+, NeurIPS’23]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
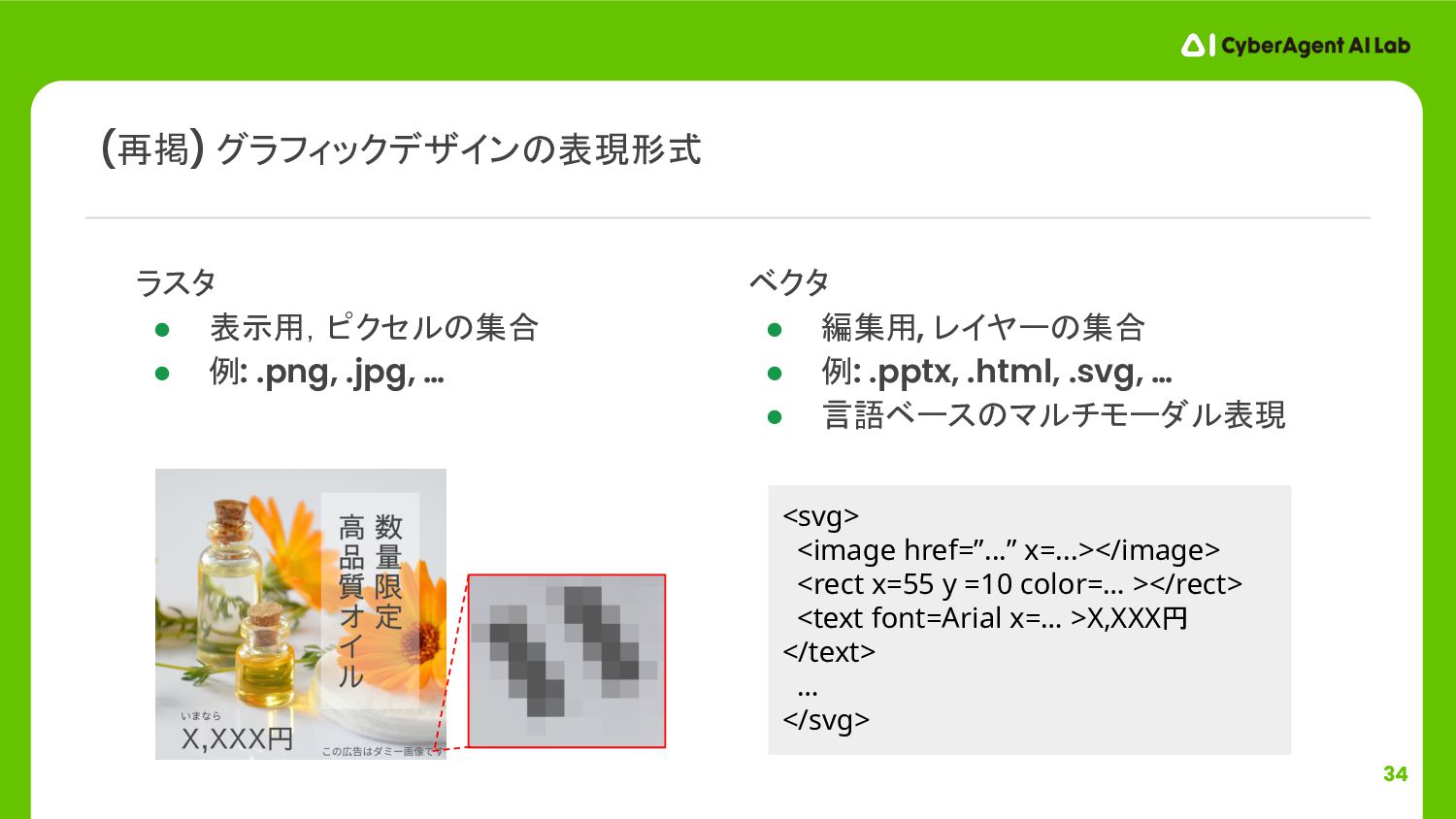{kind=link}
{kind=link}
![36 黎明期 ベクタ生成 試み: CanvasVAE [Yamaguchi+, ICCV’21] CanvasVAE 生成結果 (左:](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_35.jpg){kind=link}
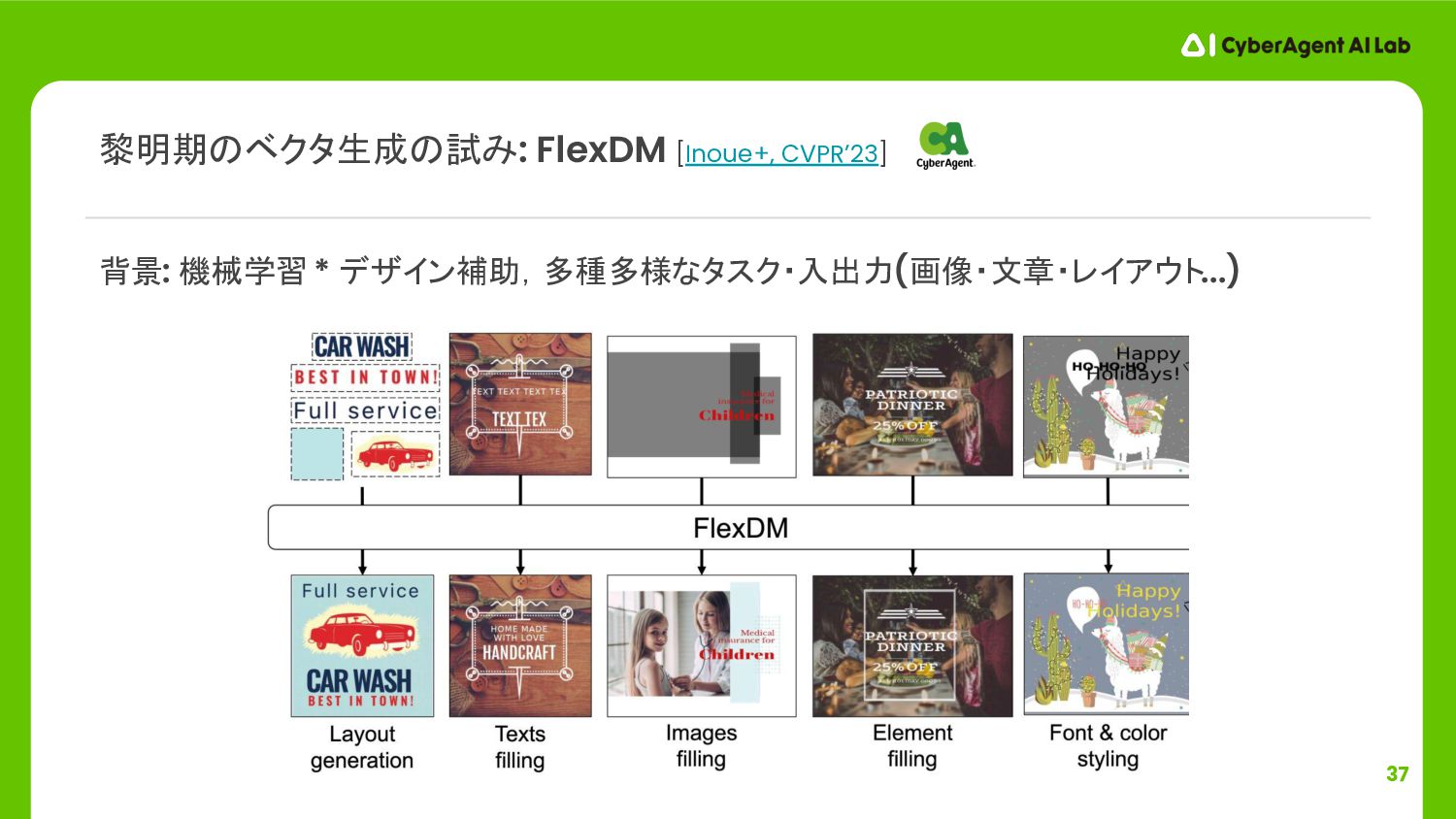{kind=link}
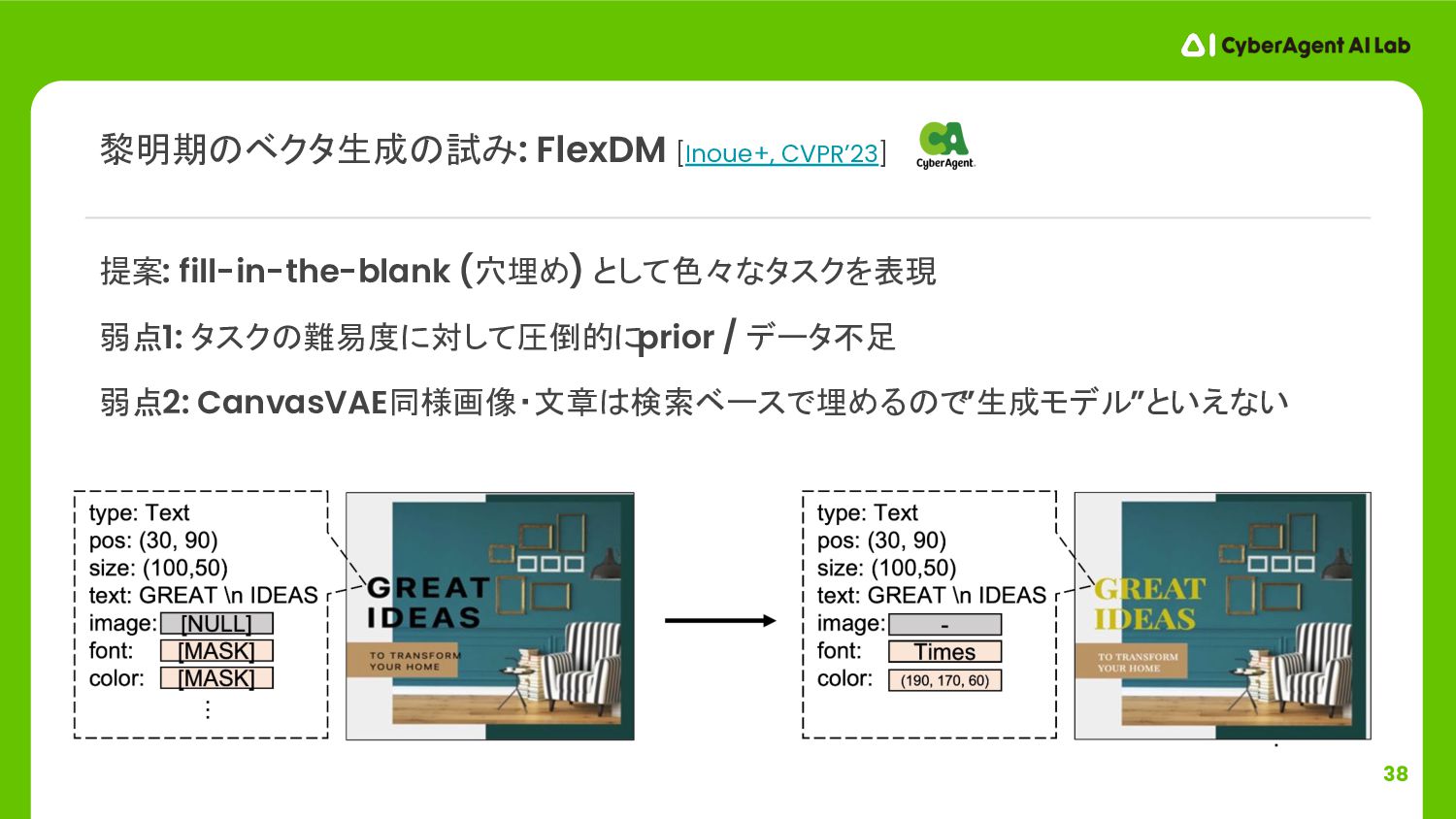{kind=link}
{kind=link}
{kind=link}
{kind=link}
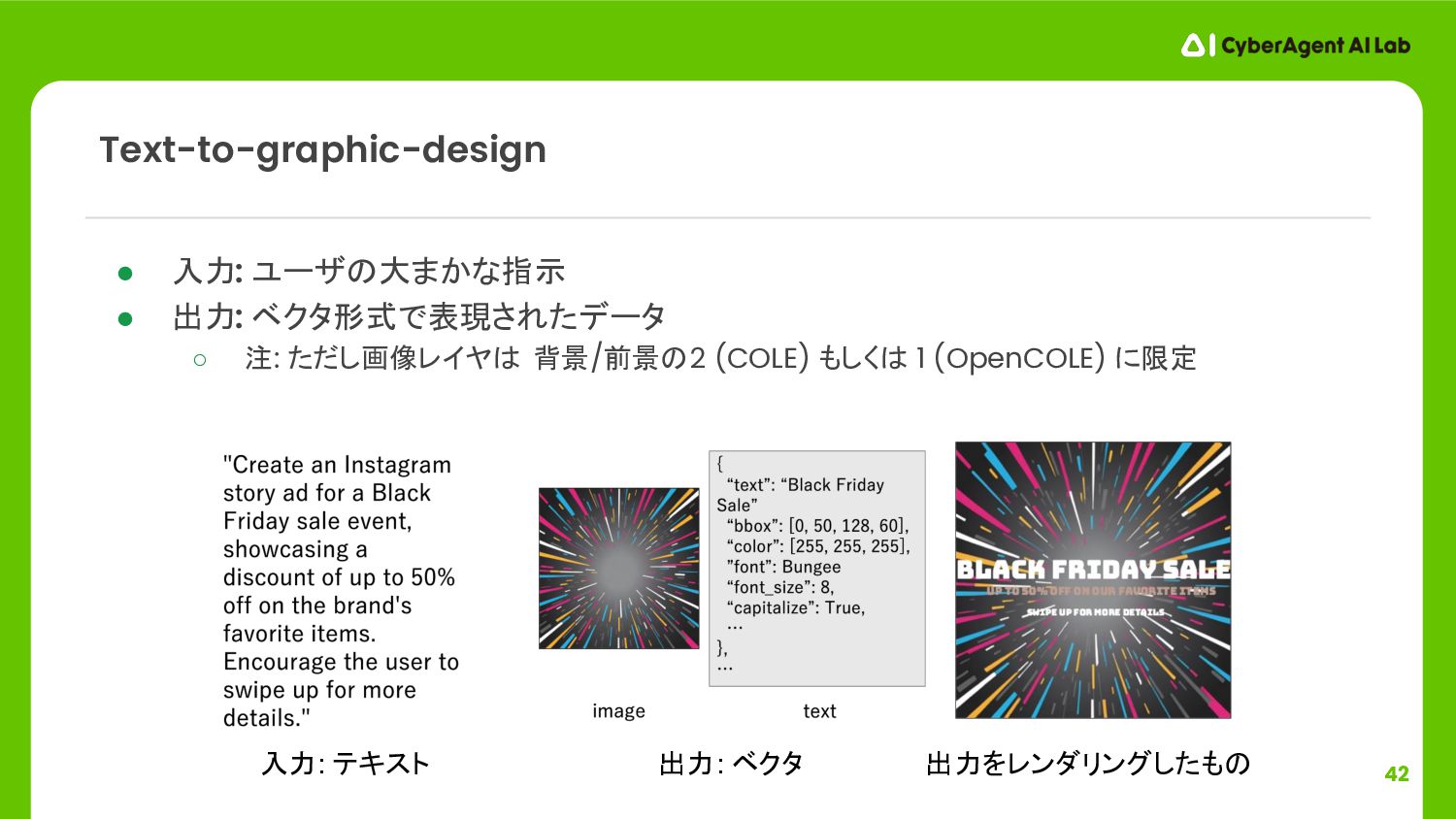{kind=link}
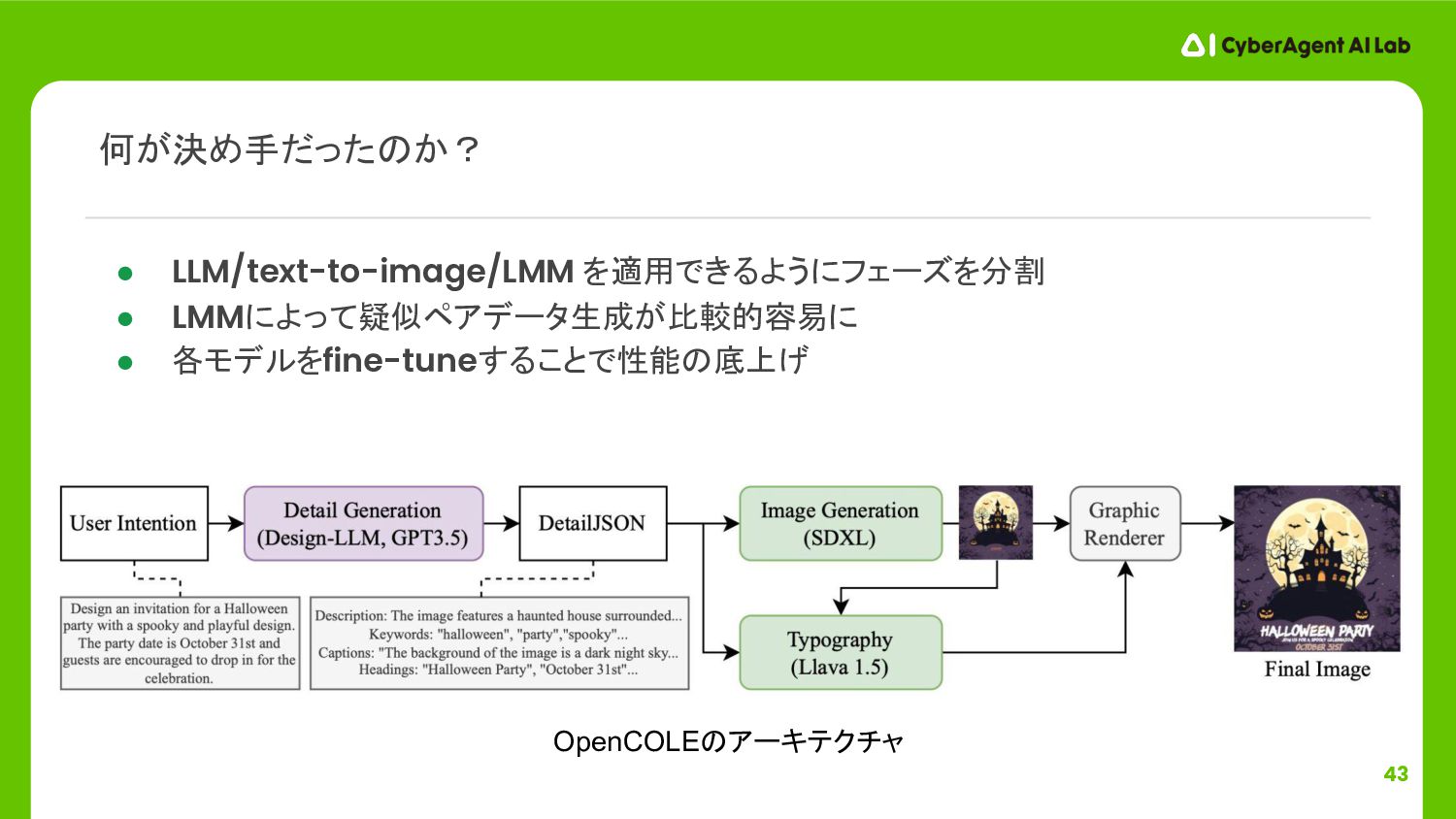{kind=link}
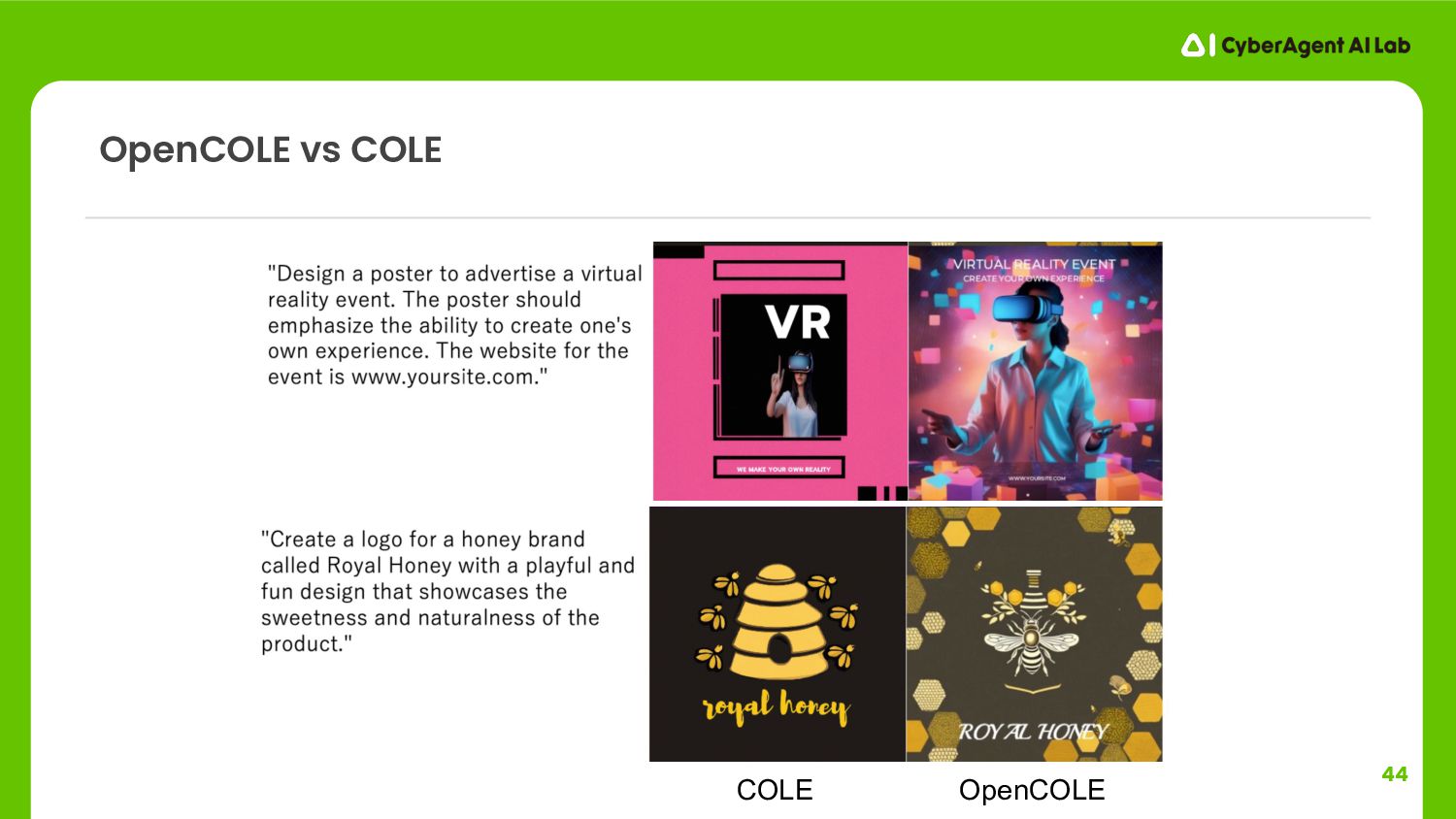{kind=link}
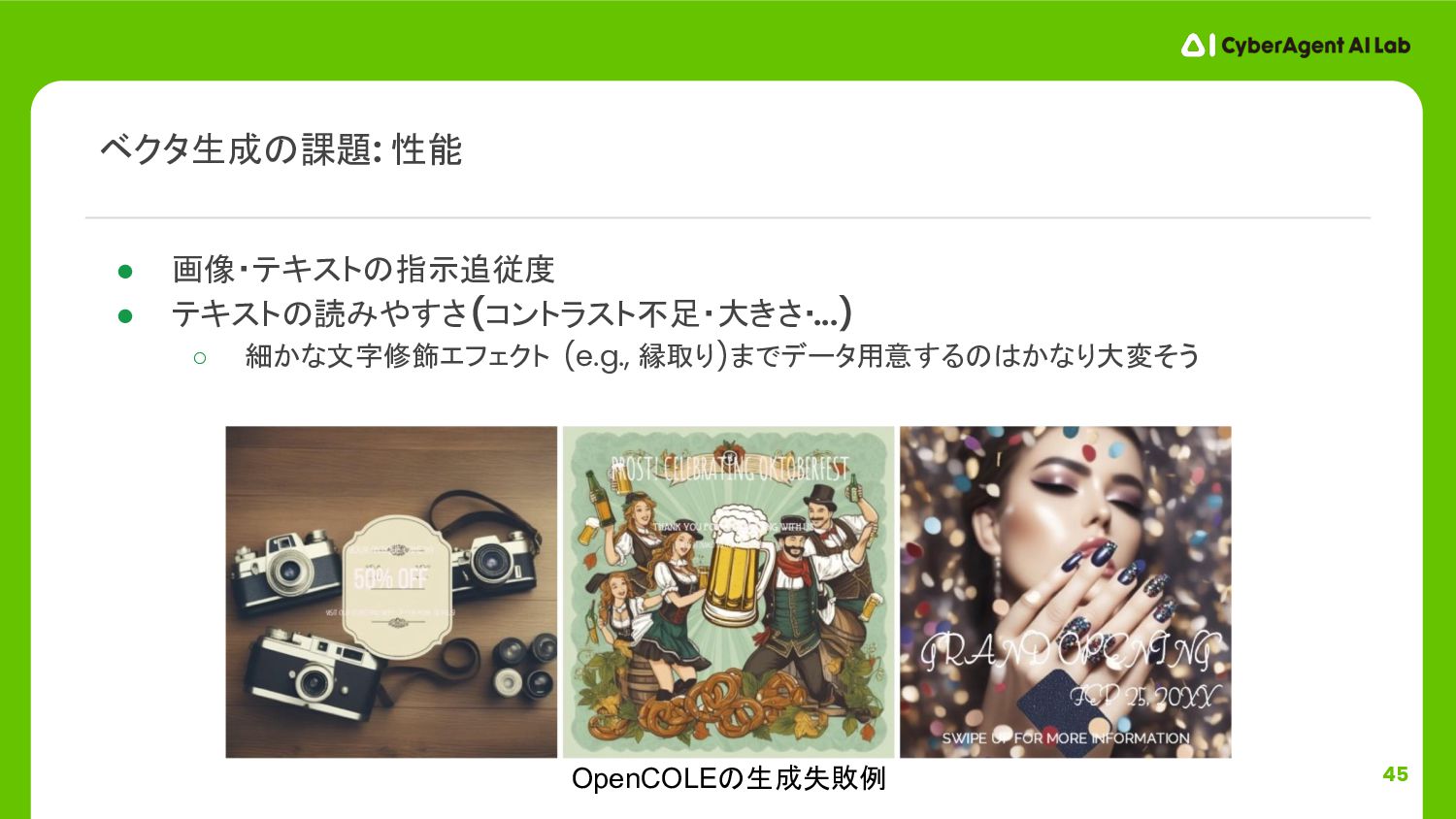{kind=link}
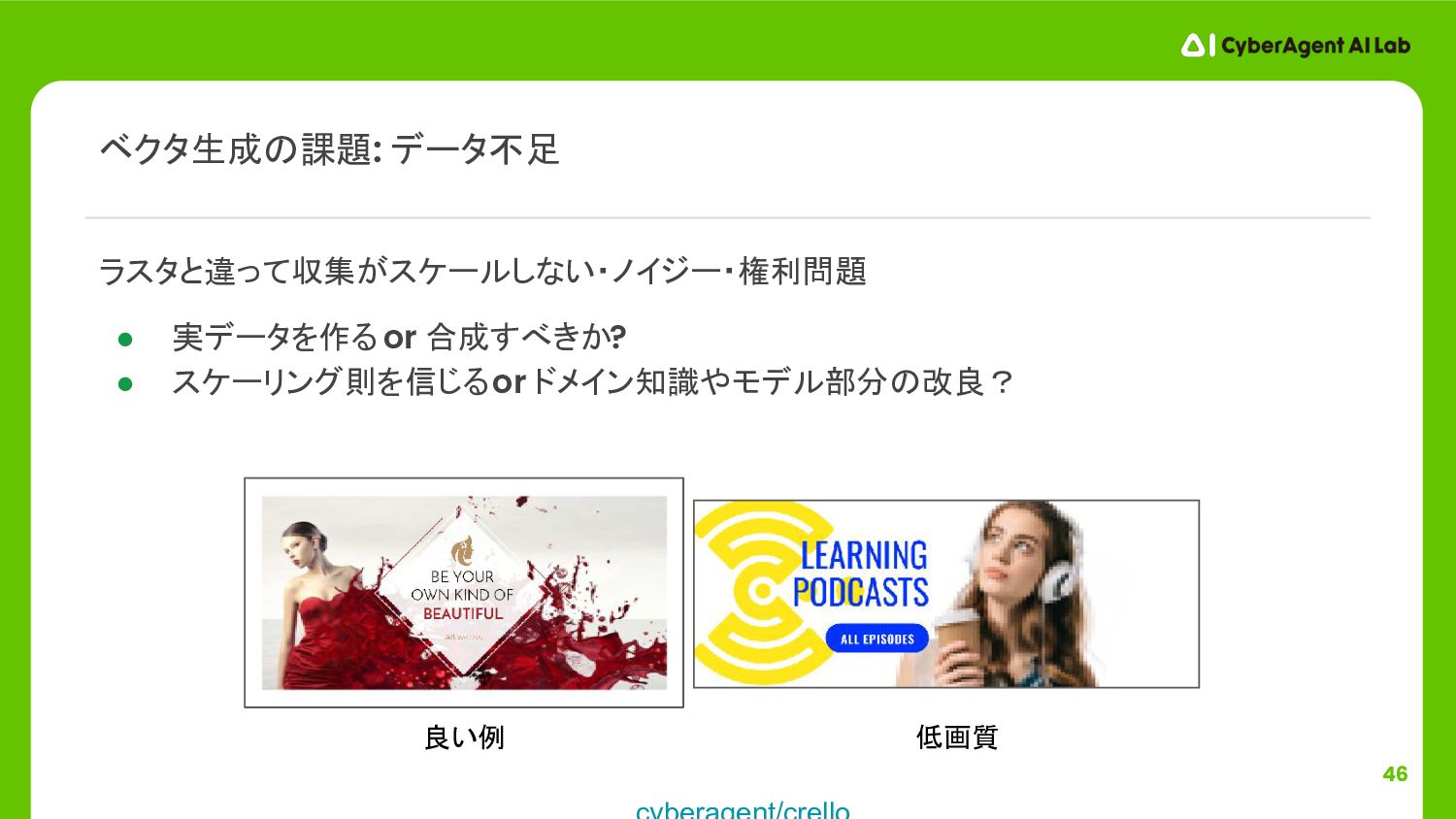{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![54 Type-R: Text-to-imageを起点としたワークフロー [Shimoda+, arXiv’24]](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_53.jpg){kind=link}
![55 より複雑な構 化: [Jingye+, arXiv’24] • VLMでレイヤ構 を予測 • SAM](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_54.jpg){kind=link}
![56 より複雑な構 化: [Jingye+, arXiv’24] • VLMでレイヤ構 を予測 • SAM](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
![59 • 2024年に第1回, 2025年もCVPRで企画中です (通れ ) • 投稿お待ちしております [PR] Workshop](https://files.speakerdeck.com/presentations/abd694b0b5a145ddb8d0746254aed616/slide_58.jpg){kind=link}
{kind=link}
{kind=link}