Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
解説: Metadata Normalization
Search
Naoto Inoue
August 01, 2021
Research
750
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
解説: Metadata Normalization
CVPR2021論文読み会(後編)
Naoto Inoue
August 01, 2021
More Decks by Naoto Inoue
See All by Naoto Inoue
Graphic design generation by multimodal models
naoto0804
6
1.2k
解説: VisProg (CVPR2023 best paper)
naoto0804
0
1k
Other Decks in Research
See All in Research
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
110
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
550
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.5k
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
580
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
Harness Engineering and Al Agent
kzinmr
3
1.8k
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
Featured
See All Featured
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
900
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Claude Code のすすめ
schroneko
67
230k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Transcript
Metadata Normalization CVPR2021読み会(後編)2021/07/31 井上 直⼈ (Naoto Inoue) 0
⾃⼰紹介 1 現職: CyberAgent AI Lab 研究員 (2021.4~) 現研究:広告クリエティブの制作⽀援と⾃動⽣成 •
Multi-modal data, vector format data • CVPR2021論⽂まとめブログ を書きました 前職(?):博⼠@相澤⼭﨑松井研(東⼤) (~2021.3) Domain adaptation や image-to-image translation 周りの研究 • Domain adaptation for object detection [Inoue+, CVPR’18] • Reinforcement learning for low-level image processing [Furuta+, AAAI‘19] • Line drawing generation from a single RGB image [Inoue+, Pacific Graphics’19] • Ambient occlusion generation from a single RGB image [Inoue+, EuroGraphics’20]
概要 2 [project] / [paper] メタデータを⽤いた正規化層の提案
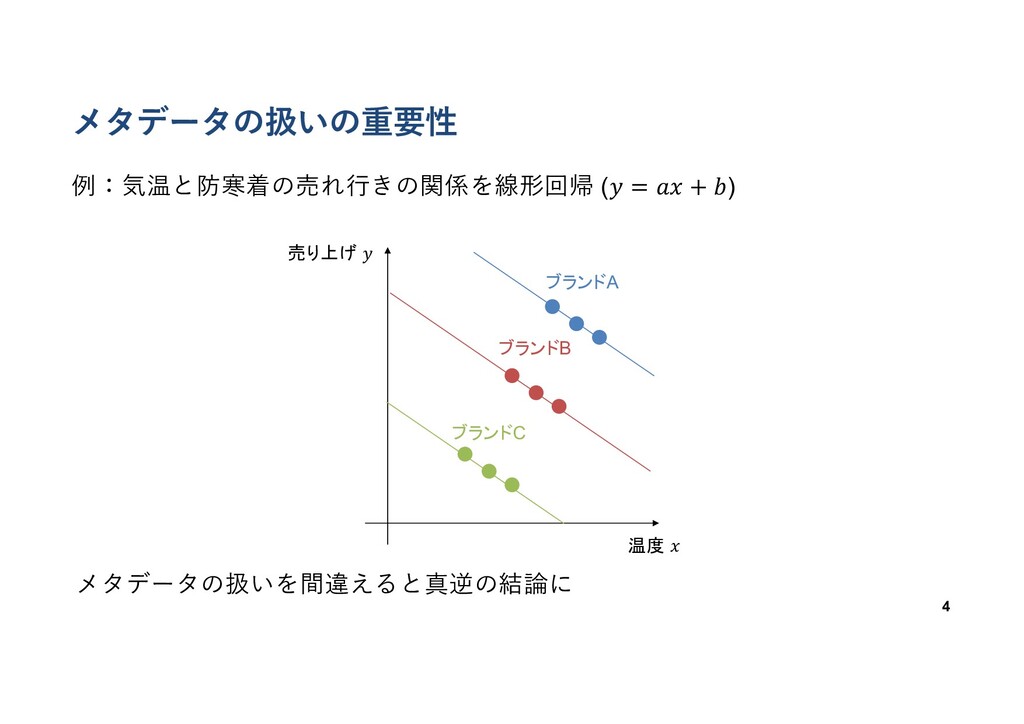
メタデータの扱いの重要性 例:気温と防寒着の売れ⾏きの関係を線形回帰 (𝑦 = 𝑎𝑥 + 𝑏) 3 温度 𝑥
売り上げ 𝑦 → 暑いほど売れる..? (常識的におかしい)
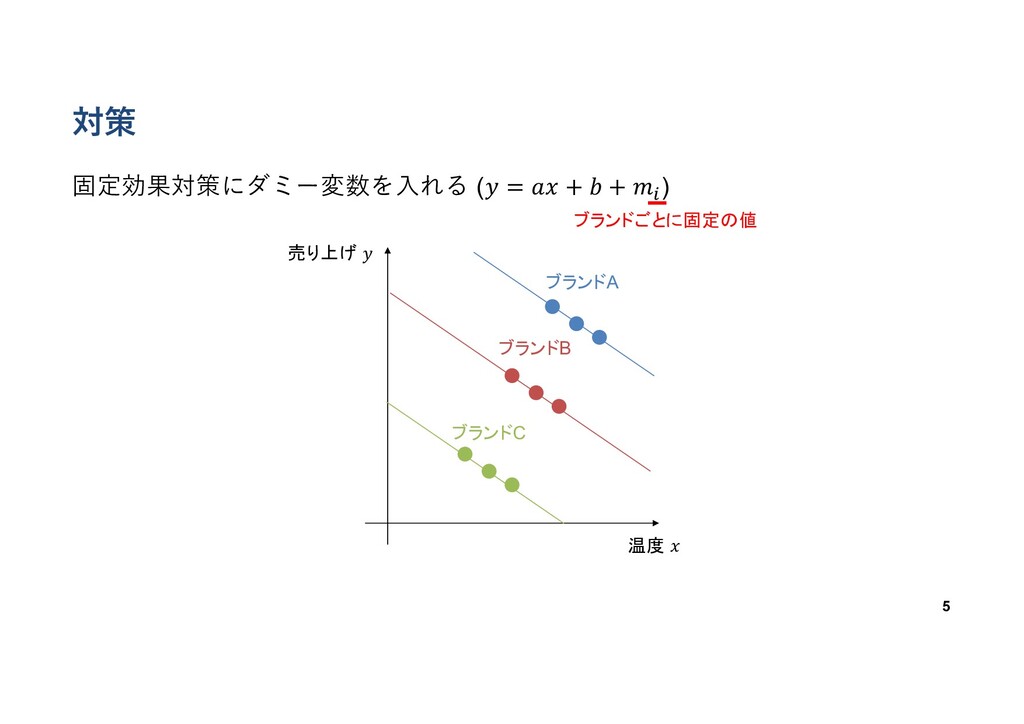
メタデータの扱いの重要性 例:気温と防寒着の売れ⾏きの関係を線形回帰 (𝑦 = 𝑎𝑥 + 𝑏) 4 メタデータの扱いを間違えると真逆の結論に ブランドA
ブランドB ブランドC 温度 𝑥 売り上げ 𝑦
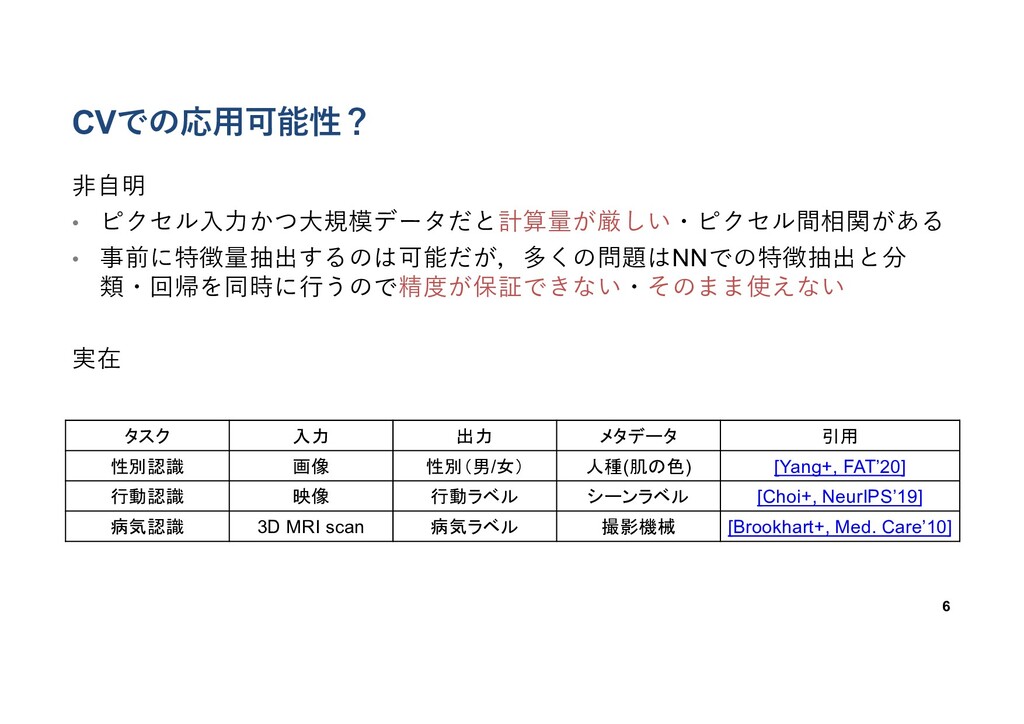
対策 固定効果対策にダミー変数を⼊れる (𝑦 = 𝑎𝑥 + 𝑏 + 𝑚# )
5 ブランドA ブランドB ブランドC 温度 𝑥 売り上げ 𝑦 ブランドごとに固定の値
CVでの応⽤可能性? ⾮⾃明 • ピクセル⼊⼒かつ⼤規模データだと計算量が厳しい・ピクセル間相関がある • 事前に特徴量抽出するのは可能だが,多くの問題はNNでの特徴抽出と分 類・回帰を同時に⾏うので精度が保証できない・そのまま使えない 実在 6 タスク
入力 出力 メタデータ 引用 性別認識 画像 性別(男/女) 人種(肌の色) [Yang+, FAT’20] 行動認識 映像 行動ラベル シーンラベル [Choi+, NeurIPS’19] 病気認識 3D MRI scan 病気ラベル 撮影機械 [Brookhart+, Med. Care’10]
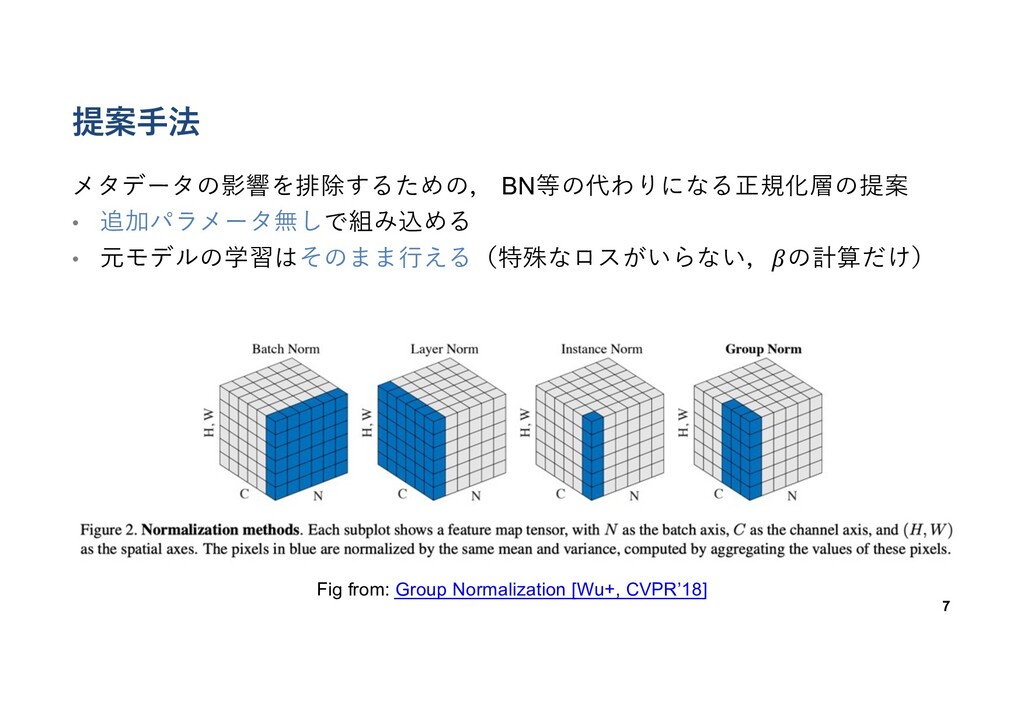
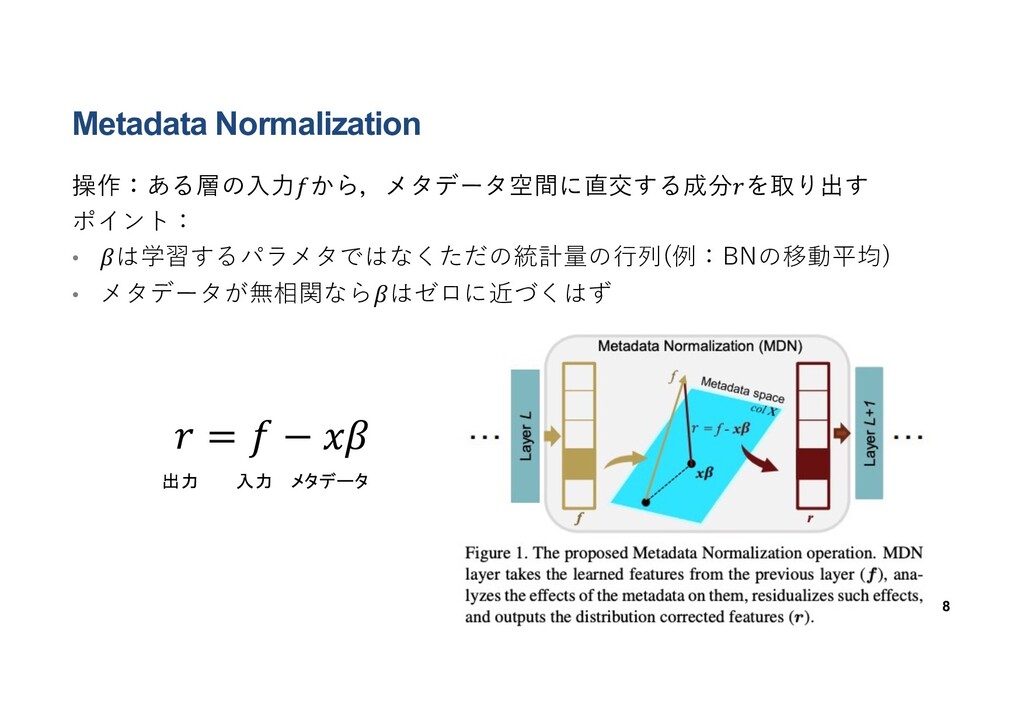
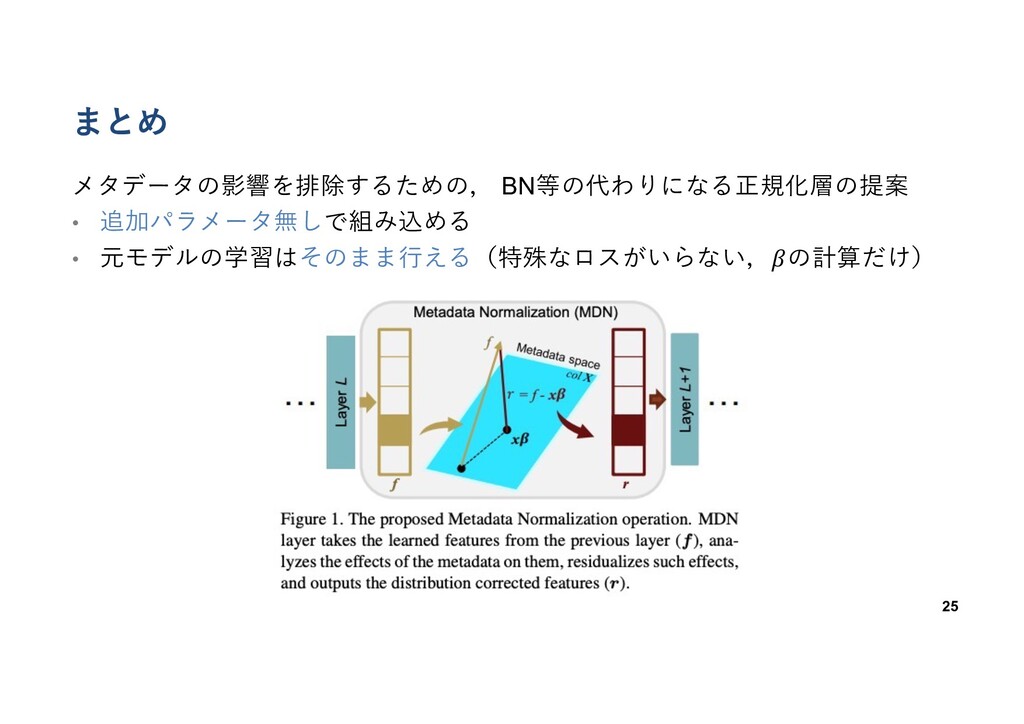
提案⼿法 メタデータの影響を排除するための, BN等の代わりになる正規化層の提案 • 追加パラメータ無しで組み込める • 元モデルの学習はそのまま⾏える(特殊なロスがいらない,𝛽の計算だけ) 7 Fig from:
Group Normalization [Wu+, CVPR’18]
Metadata Normalization 操作:ある層の⼊⼒𝑓から,メタデータ空間に直交する成分𝑟を取り出す ポイント: • 𝛽は学習するパラメタではなくただの統計量の⾏列(例:BNの移動平均) • メタデータが無相関なら𝛽はゼロに近づくはず 8 𝑟
= 𝑓 − 𝑥𝛽 出力 入力 メタデータ
簡単な場合 (Full-batch) Full-batch (全データを⼀気に⾒ることができる) 𝒙# ∈ ℝ$: 𝑖番⽬のサンプルが持つメタデータ 𝑿 =
[𝒙% , 𝒙& , … , 𝒙' ](:全Nサンプルのメタデータの⾏列 𝒇 = [𝑓%, 𝑓&, … , 𝑓'] ∈ ℝ':あるレイヤで抽出された全Nサンプルの特徴 𝒇 = 𝑿𝛽 + 𝒓で 𝒓 𝟐 を最⼩化する𝛽を求める(ordinary least square estimator for GLM) → 閉形式の解が解析的に求まり,𝛽と𝒓が簡単に計算できる 9 𝒓 = 𝒇 − 𝑿𝛽 出力 入力 メタデータ
難しい場合 (Mini-batch) Mini-batch (NNと組み合わせる場合⼤体これ) 𝑀:ミニバッチ内のデータ数 (𝑀 ≪ 𝑁) ; 𝑿
∈ ℝ*×$:ミニバッチ内のメタデータの⾏列 < 𝒇 ∈ ℝ*:あるレイヤで抽出された全Mサンプルの特徴 逆⾏列(K×K)計算が重い・𝛽の推定が不正確 10 𝒓 = 𝒇 − 𝑿𝛽 出力 入力 メタデータ
式変形(最重要) 11 NNに非依存 ∑ = 𝑿,𝑿 は学習と関係ないので事前に全データで計算できる NNに依存
交絡効果 (Confounding Effects) メタデータ𝑿が⼊⼒𝒇だけでなく出⼒𝒚とも相関してしまうケース 12 𝑿, 𝒚のそれぞれに対して𝛽𝑿, 𝛽𝒚 を⽤意して解析 メタデータの影響分だけを除去する
実装詳細 Q. どのレイヤに⼊れるか? A. 後ろの⽅(⾼次元特徴が抽出されている段階で) Q. テスト時の𝛽はどうする? A. 学習時にバッチ毎に推定した値から移動平均を計算しておく Q.
メタデータの形式は? A. Categorical / continuous どちらでもOK (categoricalはone-hotにする(はず)) 13
評価指標 dcor2↓ • ⾼次元な変数間の⾮線形な依存関係を測る,メイン指標 • ⼩さいほど良くて0.0だと完全に独⽴ • 抽出した特徴とメタデータ変数(どちらも⾼次元)を⼊れる bAcc •
Balanced accuracy, class毎にaccuracyを計算した平均 • 理論的な上限の値に近いほど良い 14
実験(合成データ) 15 最後のFC層の所”だけ” Conv層にも追加
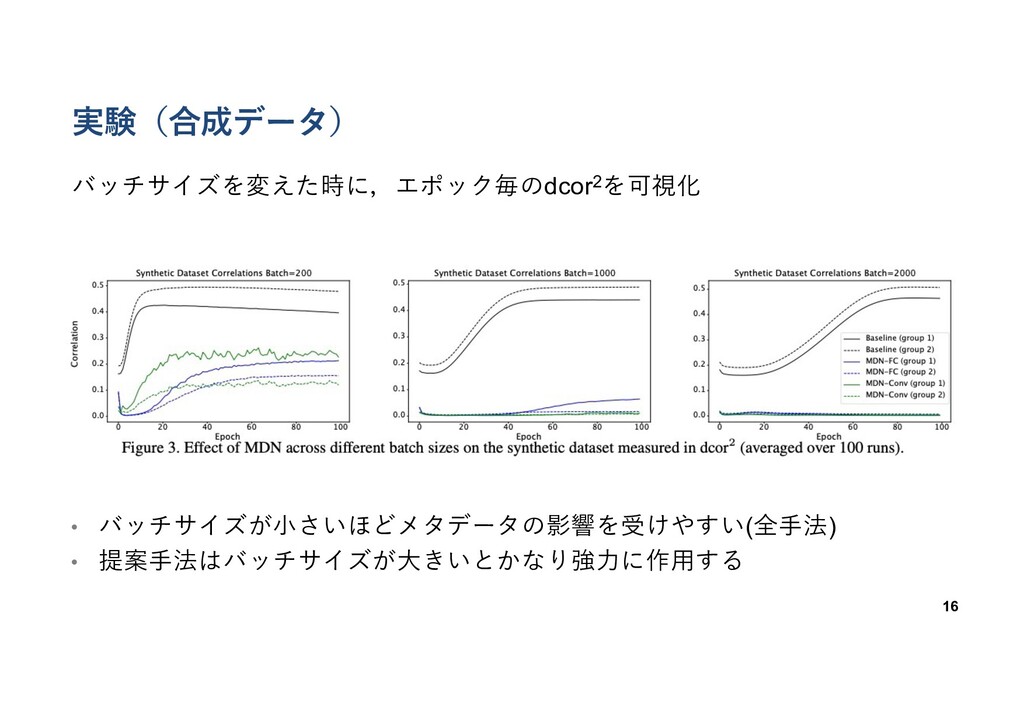
実験(合成データ) 16 バッチサイズを変えた時に,エポック毎のdcor2を可視化 • バッチサイズが⼩さいほどメタデータの影響を受けやすい(全⼿法) • 提案⼿法はバッチサイズが⼤きいとかなり強⼒に作⽤する
実験(合成データ) 17 提案⼿法はメタデータ情報をより無視して特徴を埋め込める
実験(実データ,GS-PPB) 18 データ:GS-PPB dataset • サンプル数:1.2k • ⼊⼒:顔画像 • 出⼒:性別(男・⼥)
• メタデータ:明暗情報 1 (lighter) to type 6 (darker) モデル:ImageNet-pretrained VGG16 • Shadeバイアスがかかっていることが知られている [Yang+, FAT’20]
実験(実データ,GS-PPB) 19 データ:GS-PPB dataset Shadingに非頑健
実験(実データ,HVU) 20 データ:GS-PPB dataset • サンプル数:572k clips of 882 actions
• ⼊⼒:ビデオ • 出⼒:⾏動認識のラベル(882種) • メタデータ:シーンラベル(282個) モデル:3D-resnet18 • 背景情報だけでそこそこ解けてしまう=バイアスがある [Choi+, NeurIPS’19]
実験(実データ,HVU) 21 提案⼿法でdcor2は⼤幅に改善,が精度としては落ちる • (感想) Out-of-context actions とかで検証できるともっと説得⼒が増しそう
実験(実データ,Multi-site Medical Data) 22 データ: Multi-site Medical Data • ⼊⼒:3D
MRI scans • 出⼒:病気ラベル(2種 × {yes, no} → 4通り) • メタデータ:どのマシンで取得したか
実験(実データ,Multi-site Medical Data) 23 提案⼿法でdcor2が改善
議論(個⼈の感想) ⼊⼒にconcatじゃだめ? • CNNでは⼤変そうだけどTransformerだとtokenで素直に表現出来る気も? • 実験結果が欲しかった 回帰問題では使えるのか? • 丁度良いデータがなかったのか不都合なのか読み取れなかった Invariant
feature learning (e.g., [Moyer+, NeurIPS’18])との⽐較実験がないのは何故? • バイアスを明⽰的に使ってるし↑なので多分⼤丈夫とは思うが.. Domain adaptation / generalization系との⽐較実験がないのは何故? • これも⼿法毎に適切な実装とチューニングがいるので⼤変かつ微妙そうだが 24
まとめ 25 メタデータの影響を排除するための, BN等の代わりになる正規化層の提案 • 追加パラメータ無しで組み込める • 元モデルの学習はそのまま⾏える(特殊なロスがいらない,𝛽の計算だけ)
{kind=link}
{kind=link}
![概要 2 [project] / [paper] メタデータを⽤いた正規化層の提案](https://files.speakerdeck.com/presentations/1dc382b70ebc421f96997ee22607e6e2/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}