Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
解説: VisProg (CVPR2023 best paper)
Search
Naoto Inoue
July 23, 2023
Research
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
解説: VisProg (CVPR2023 best paper)
Naoto Inoue
July 23, 2023
More Decks by Naoto Inoue
See All by Naoto Inoue
Graphic design generation by multimodal models
naoto0804
6
1.2k
解説: Metadata Normalization
naoto0804
2
750
Other Decks in Research
See All in Research
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
480
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
610
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
260
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
560
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
130
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
SLAMはどこまで解決されたのか?
tomonom
0
840
Fukui Shibiten 39 - AI Art
butchi
0
150
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
280
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.3k
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
480
Featured
See All Featured
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
New Earth Scene 8
popppiees
3
2.4k
The SEO Collaboration Effect
kristinabergwall1
1
510
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
610
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Abbi's Birthday
coloredviolet
3
8.7k
WCS-LA-2024
lcolladotor
0
730
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Building Applications with DynamoDB
mza
96
7.1k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Transcript
Visual Programming: Compositional visual reasoning without training CVPR2023読み会 (前編) 2023/07/23
井上 直人
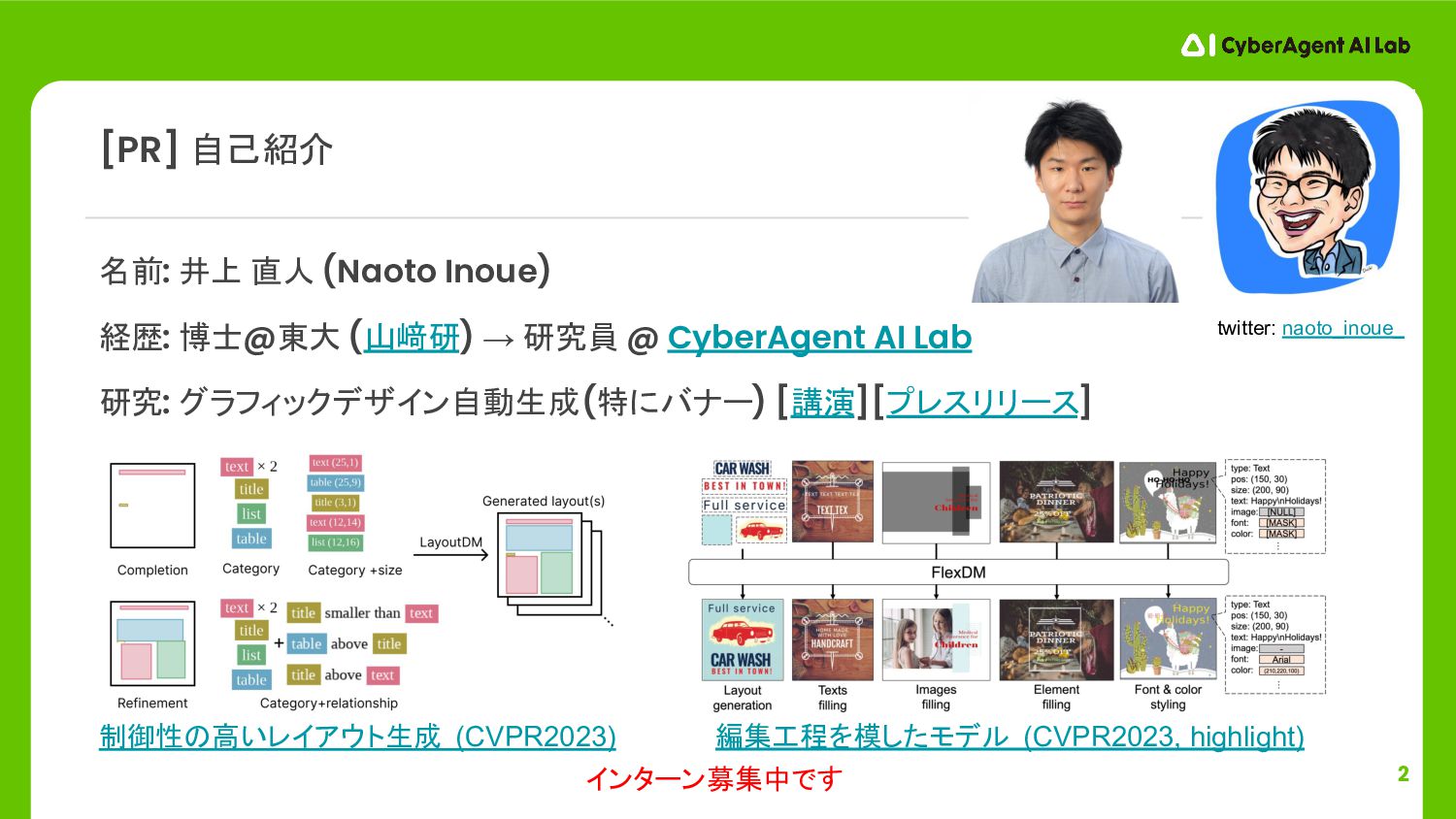
2 名前: 井上 直人 (Naoto Inoue) 経歴: 博士@東大 (山﨑研) →
研究員 @ CyberAgent AI Lab 研究: グラフィックデザイン自動生成 (特にバナー) [講演][プレスリリース] [PR] 自己紹介 制御性の高いレイアウト生成 (CVPR2023) 編集工程を模したモデル (CVPR2023, highlight) インターン募集中です twitter: naoto_inoue_
3 紹介する論文 Visual Programming: Compositional visual reasoning without training •
著者: Tanmay Gupta and Ani Kembhavi • project page / code / blog • Best paper (もう一本がUniAD)
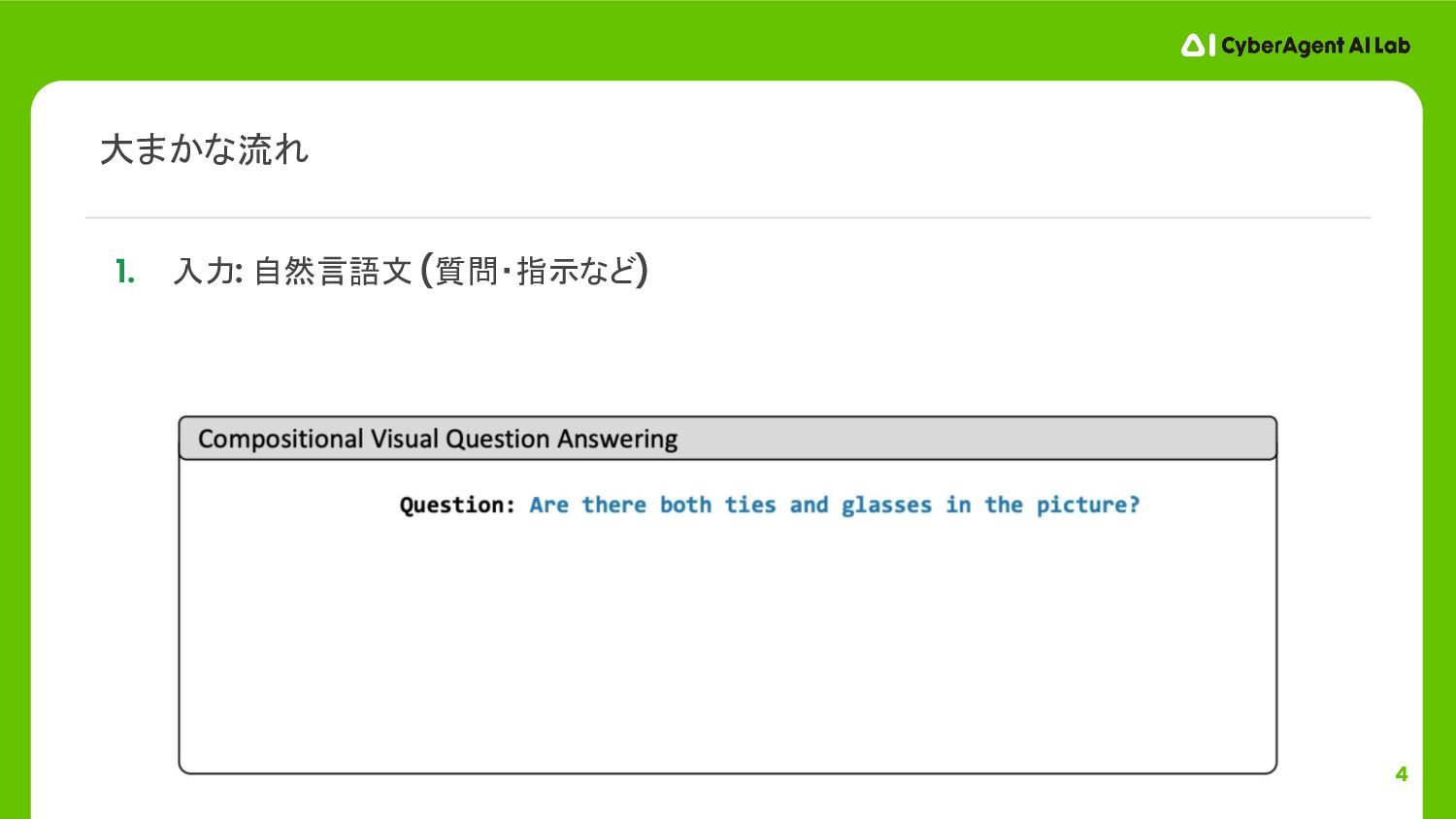
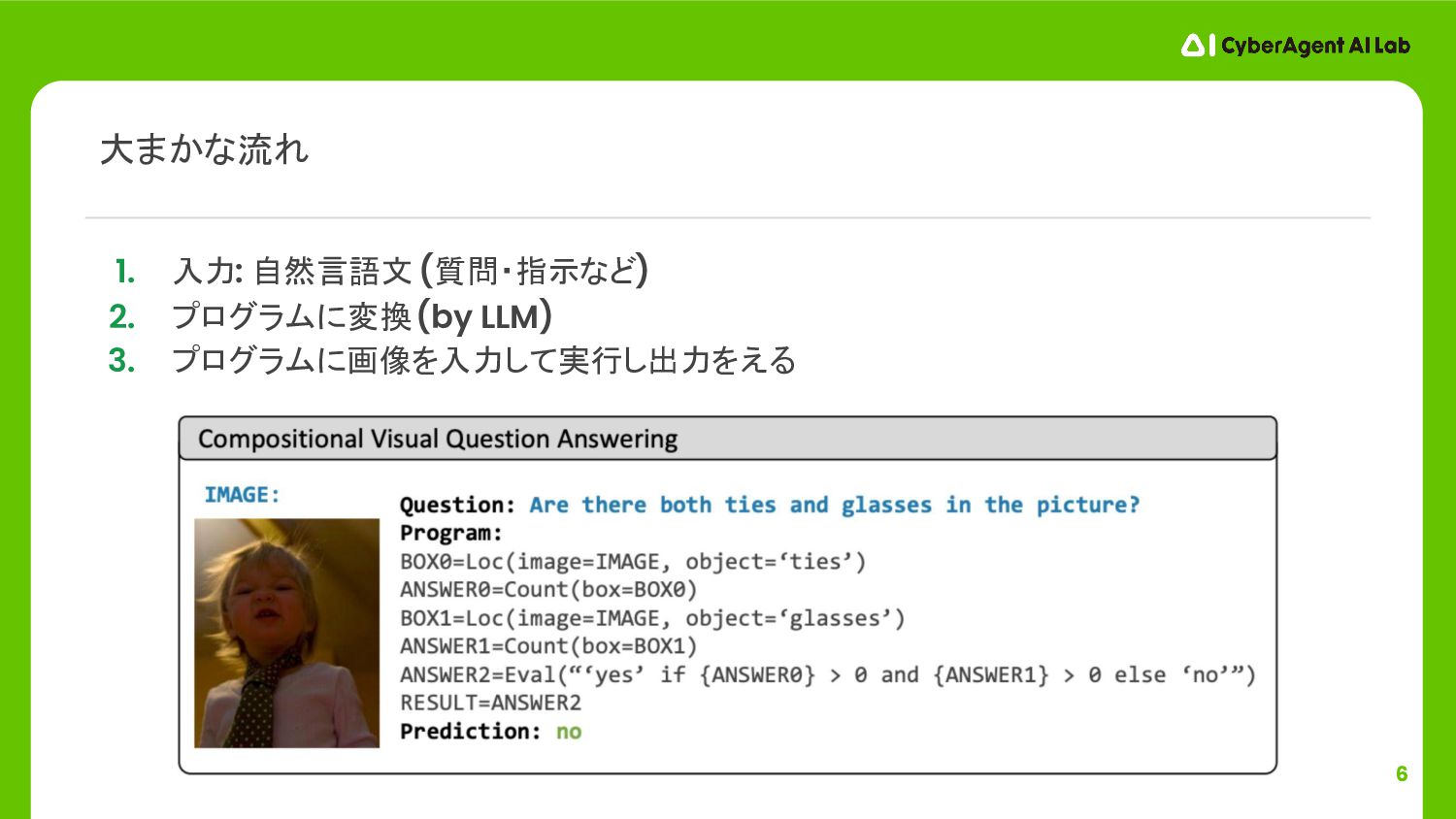
4 1. 入力: 自然言語文 (質問・指示など) 大まかな流れ
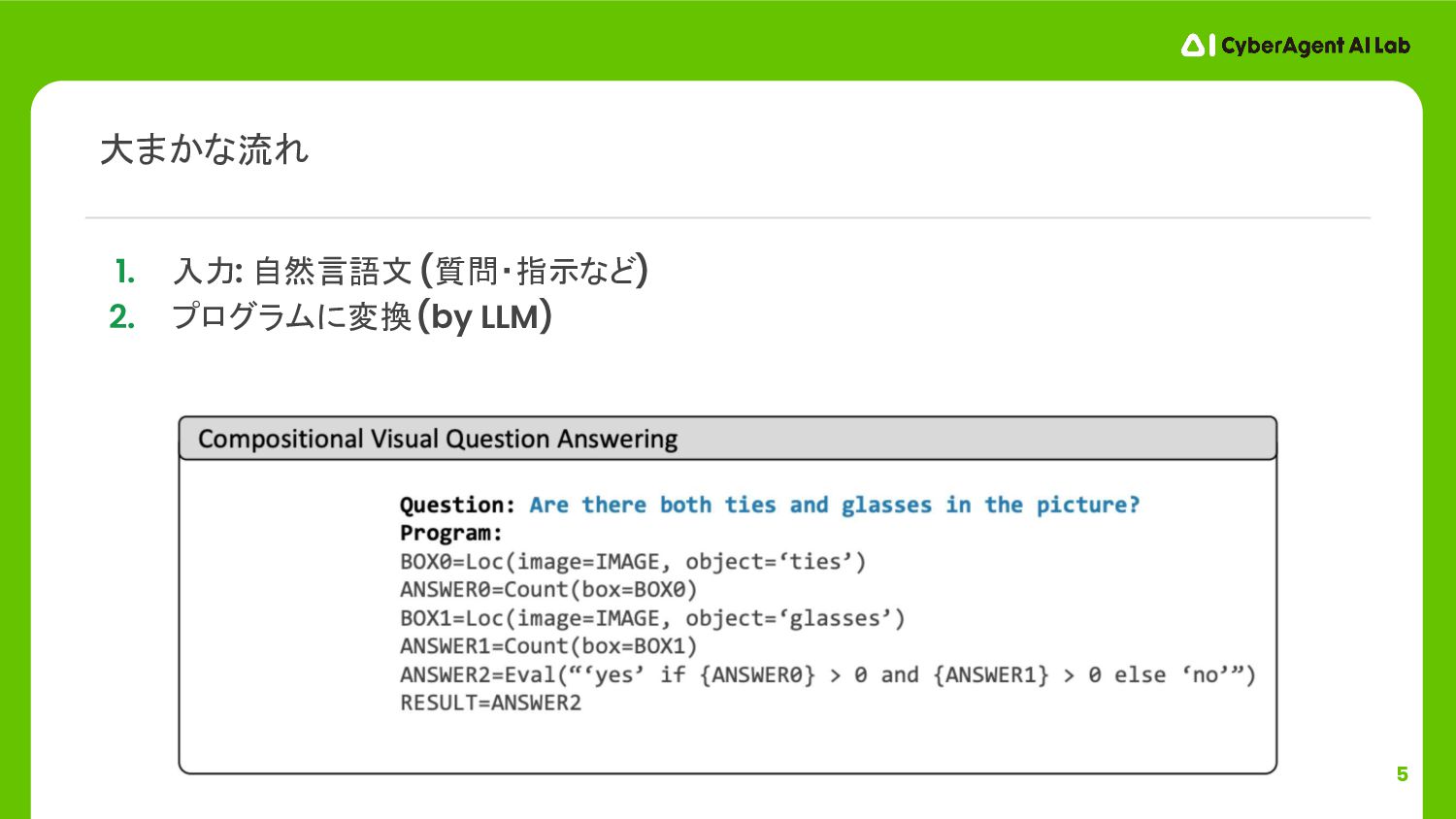
5 1. 入力: 自然言語文 (質問・指示など) 2. プログラムに変換 (by LLM) 大まかな流れ
6 1. 入力: 自然言語文 (質問・指示など) 2. プログラムに変換 (by LLM) 3.
プログラムに画像を入力して実行し出力をえる 大まかな流れ
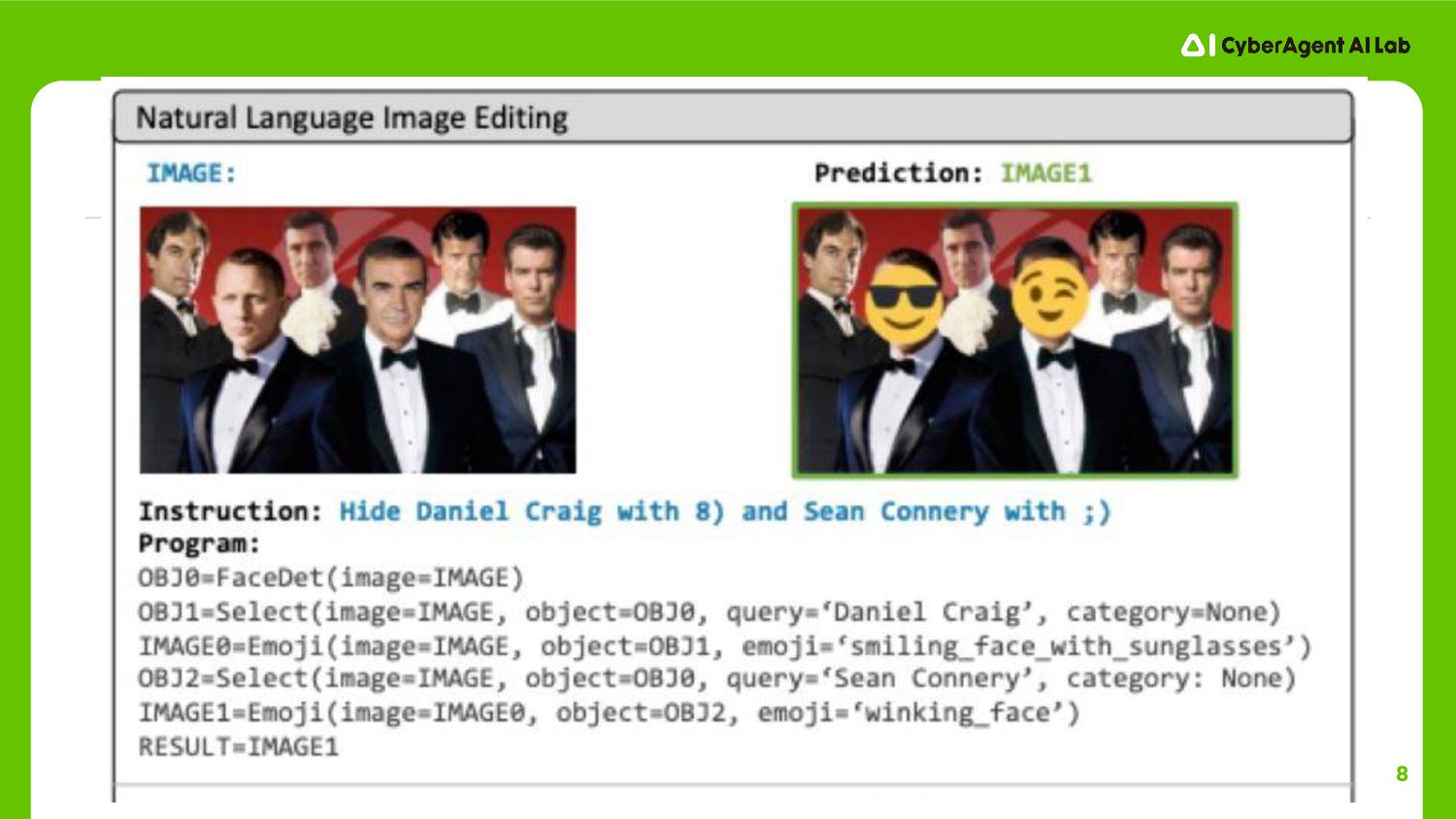
7
8
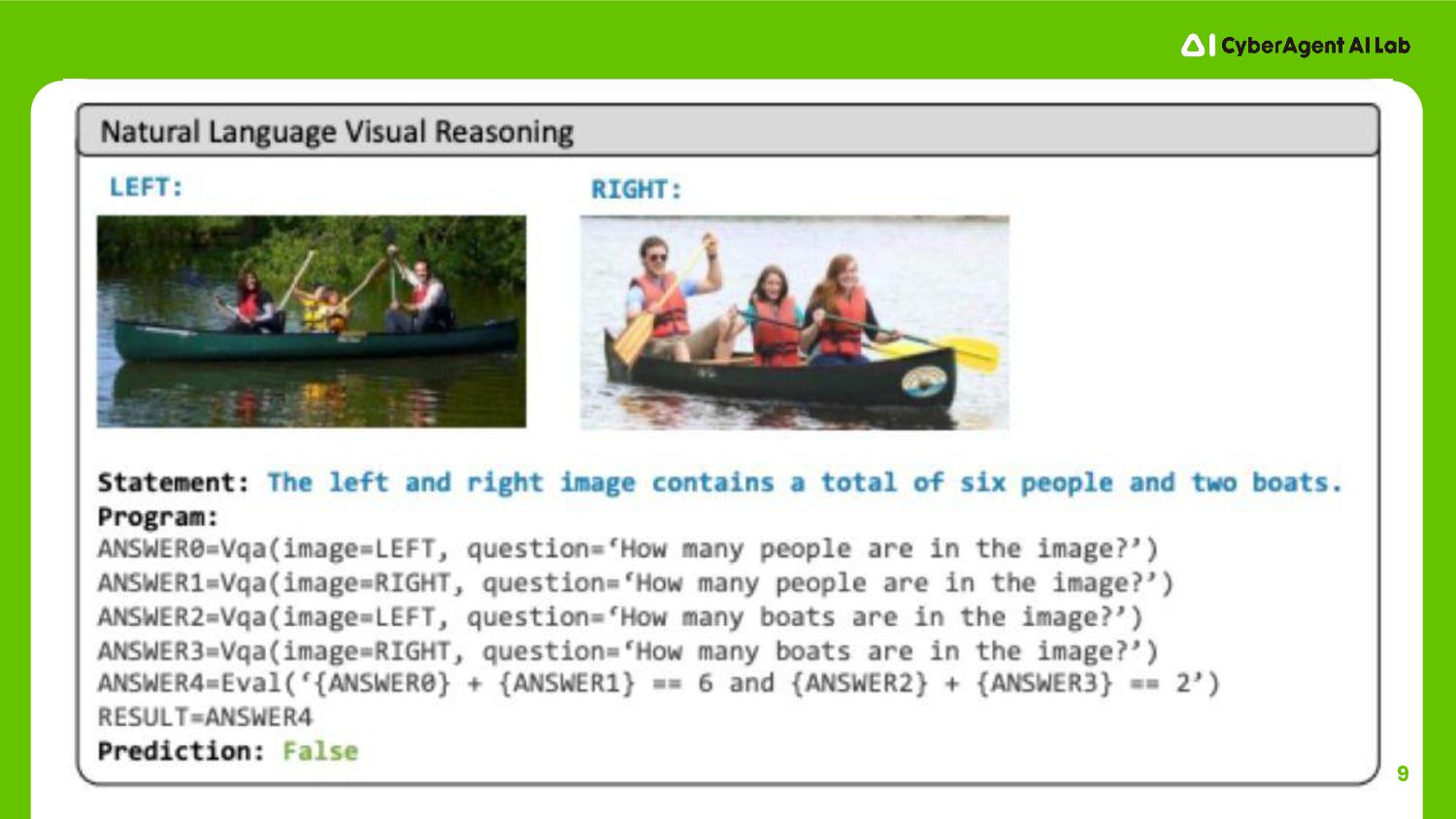
9
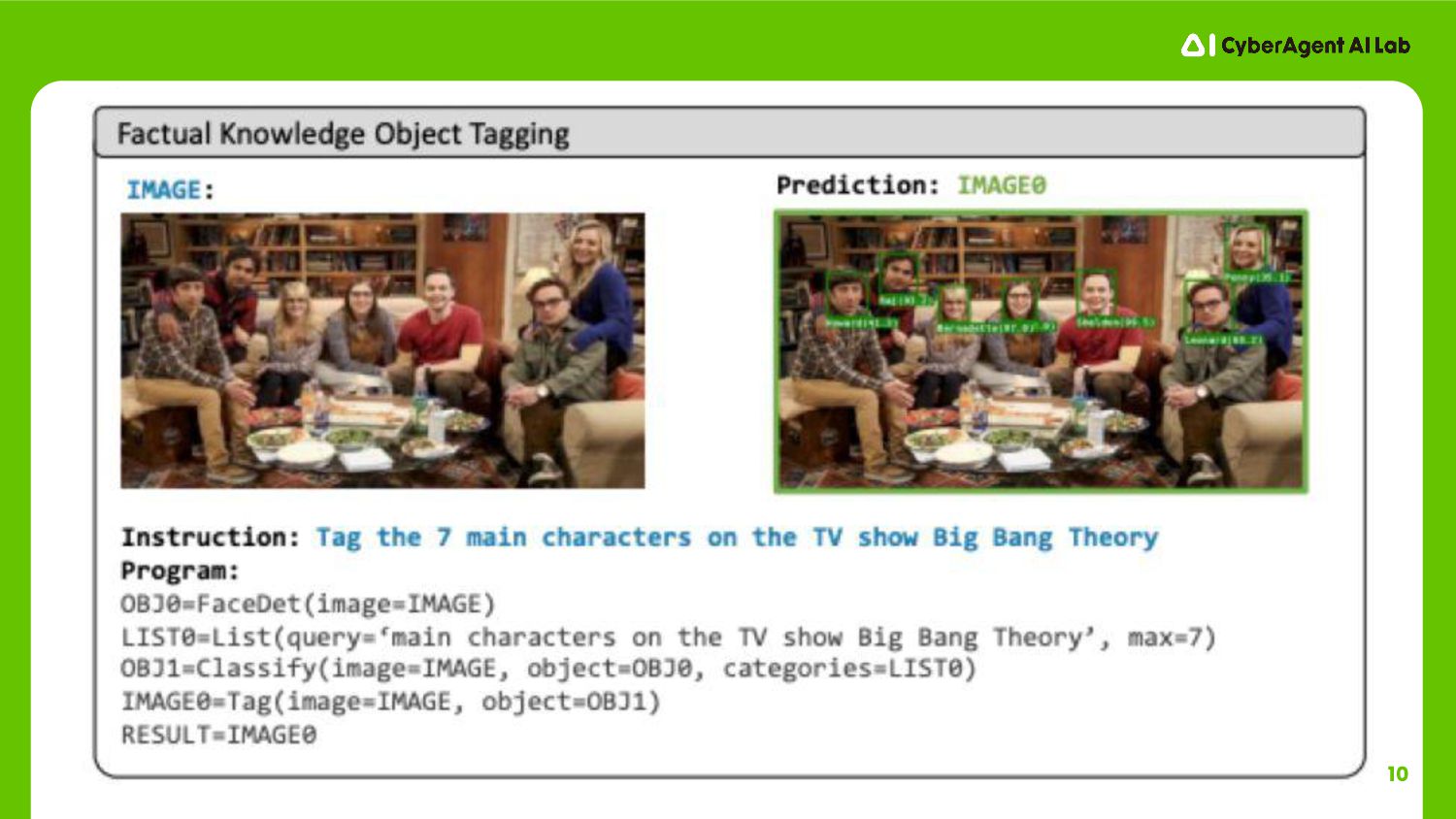
10
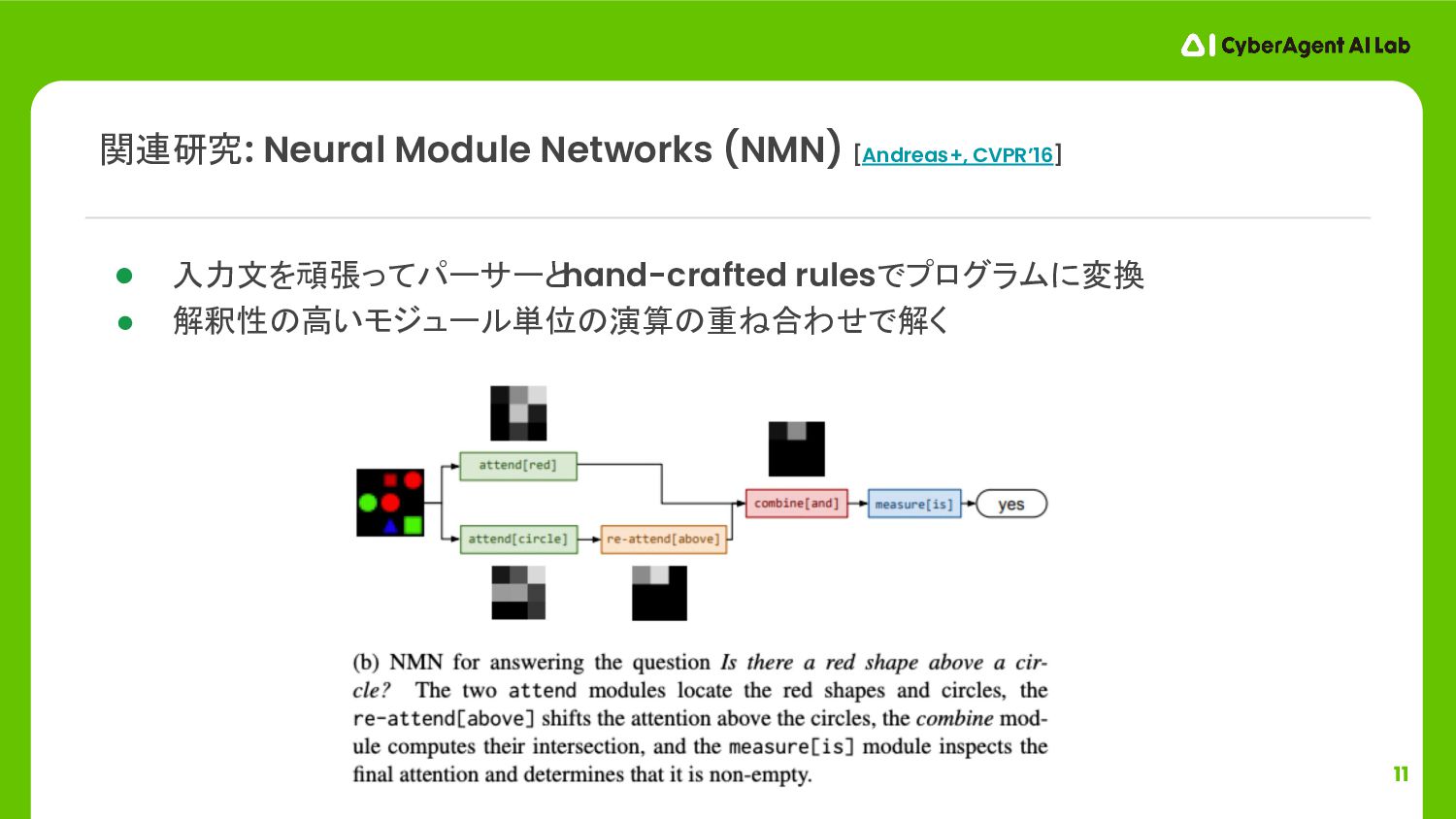
11 • 入力文を頑張ってパーサーとhand-crafted rulesでプログラムに変換 • 解釈性の高いモジュール単位の演算の重ね合わせで解く 関連研究: Neural Module Networks
(NMN) [Andreas+, CVPR’16]
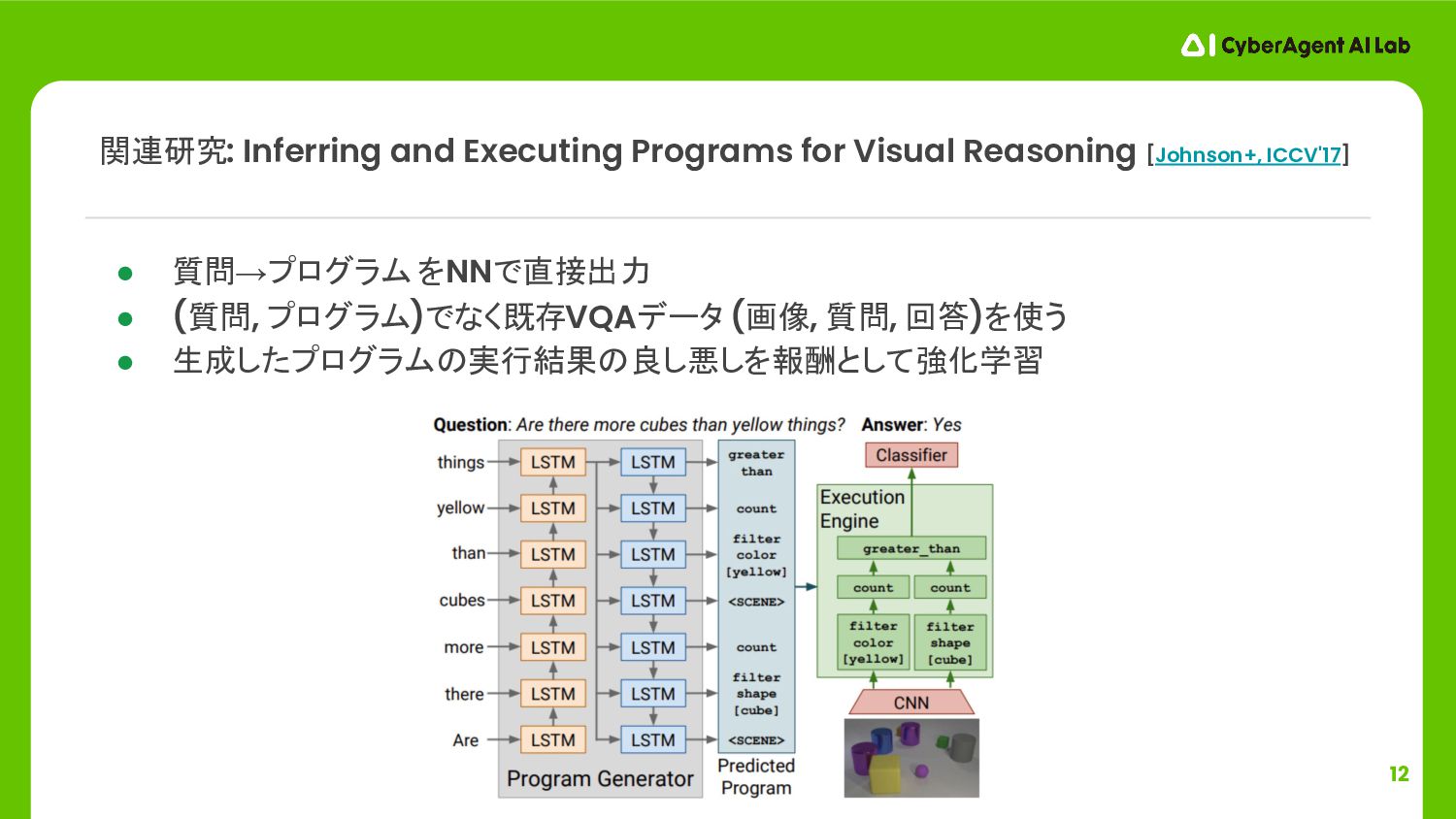
12 • 質問→プログラム をNNで直接出力 • (質問, プログラム)でなく既存VQAデータ (画像, 質問, 回答)を使う
• 生成したプログラムの実行結果の良し悪しを報酬として強化学習 関連研究: Inferring and Executing Programs for Visual Reasoning [Johnson+, ICCV'17]
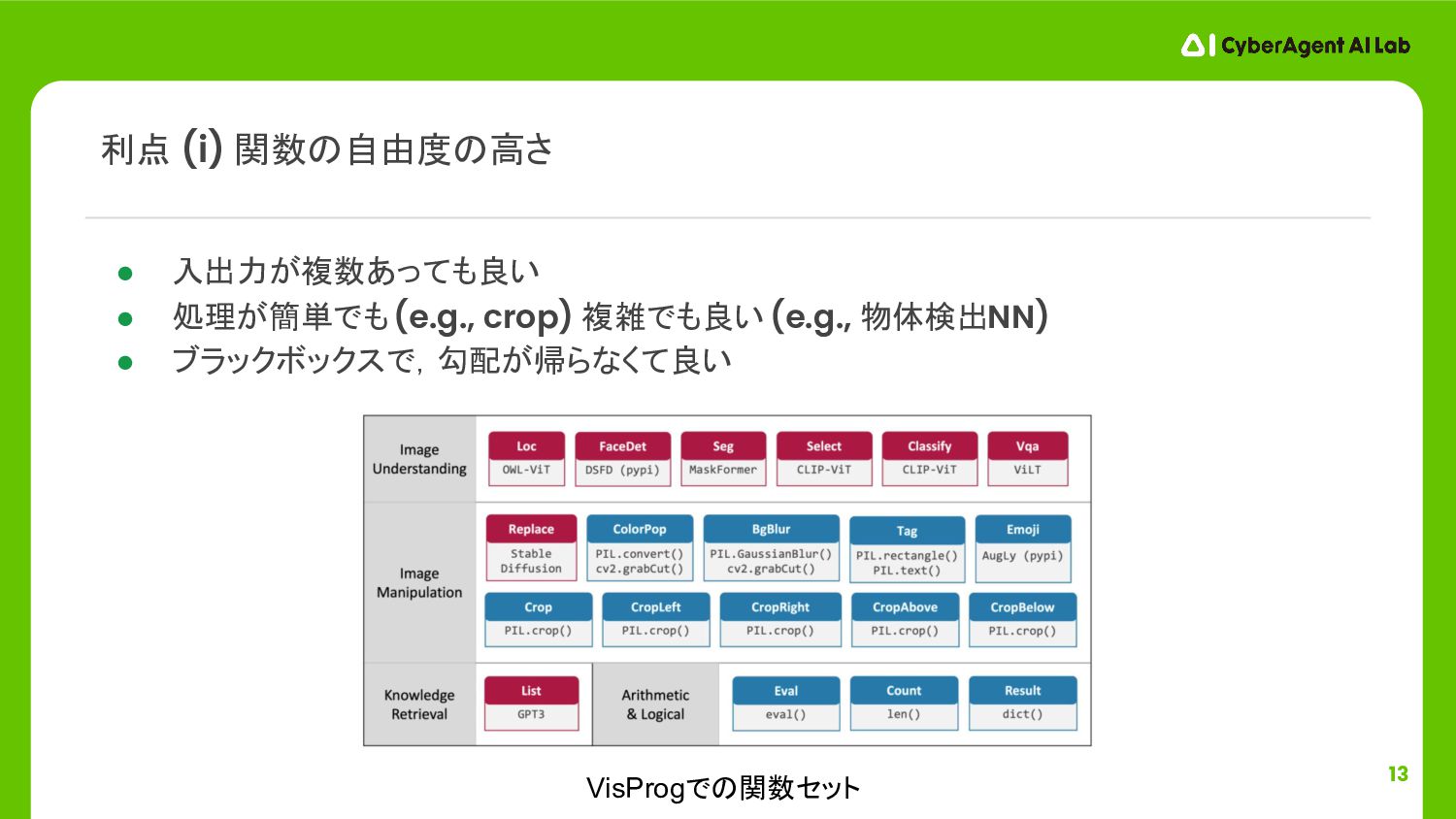
13 • 入出力が複数あっても良い • 処理が簡単でも (e.g., crop) 複雑でも良い (e.g., 物体検出NN)
• ブラックボックスで,勾配が帰らなくて良い 利点 (i) 関数の自由度の高さ VisProgでの関数セット
14 既存LLMのin-context learningで動く • “Training-free” 利点 (ii) 学習不要
15 実験
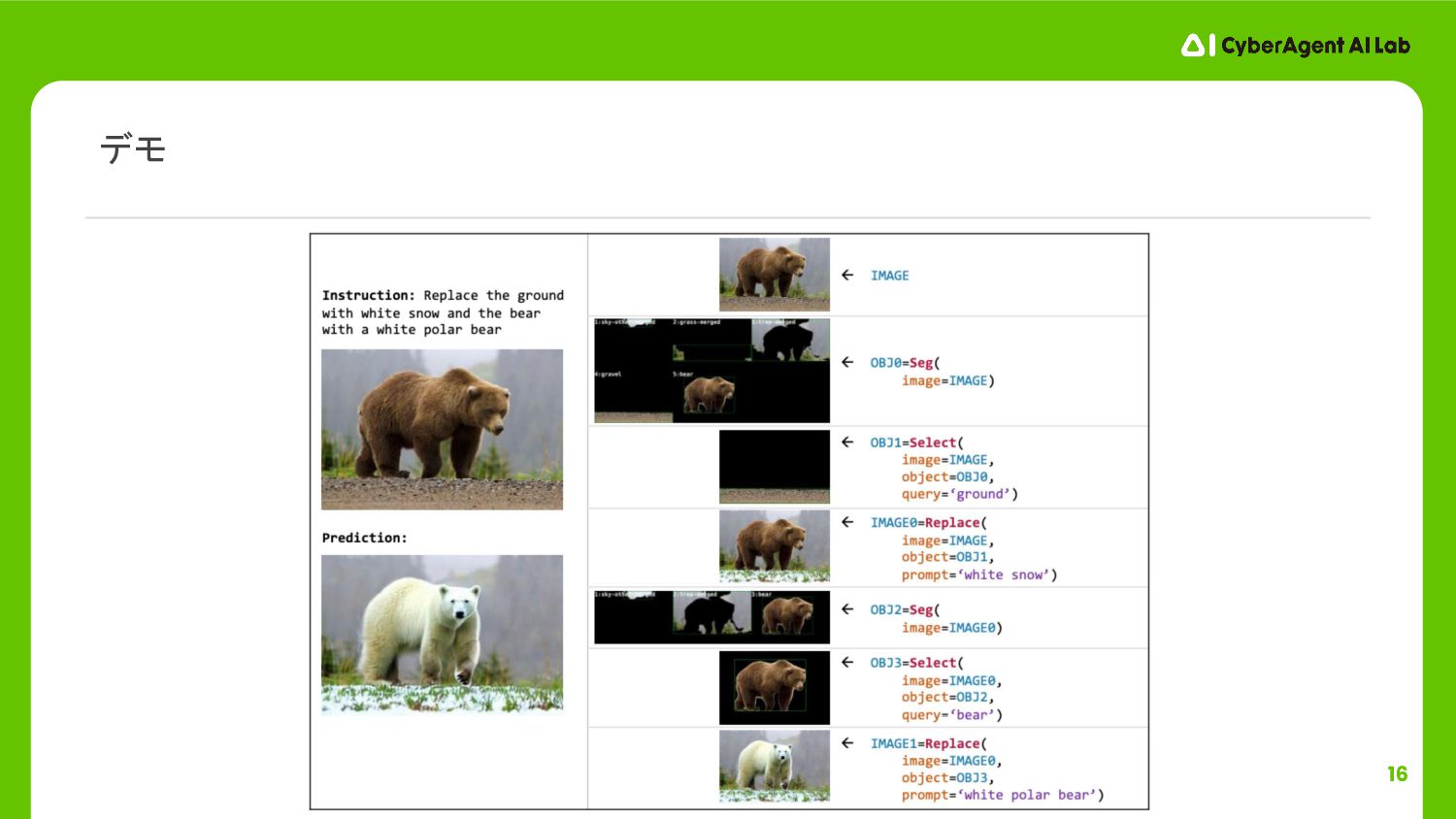
16 デモ
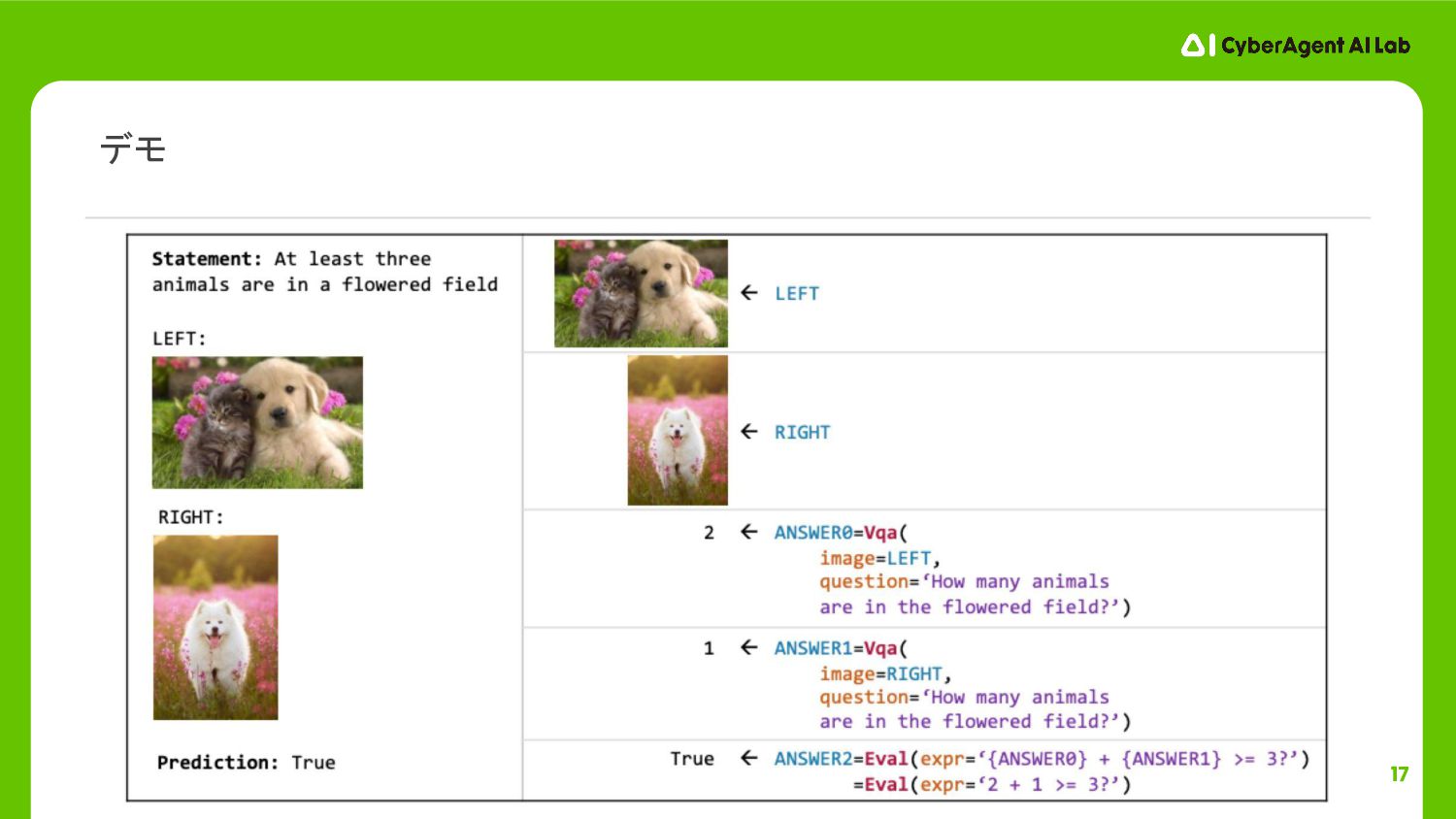
17 デモ
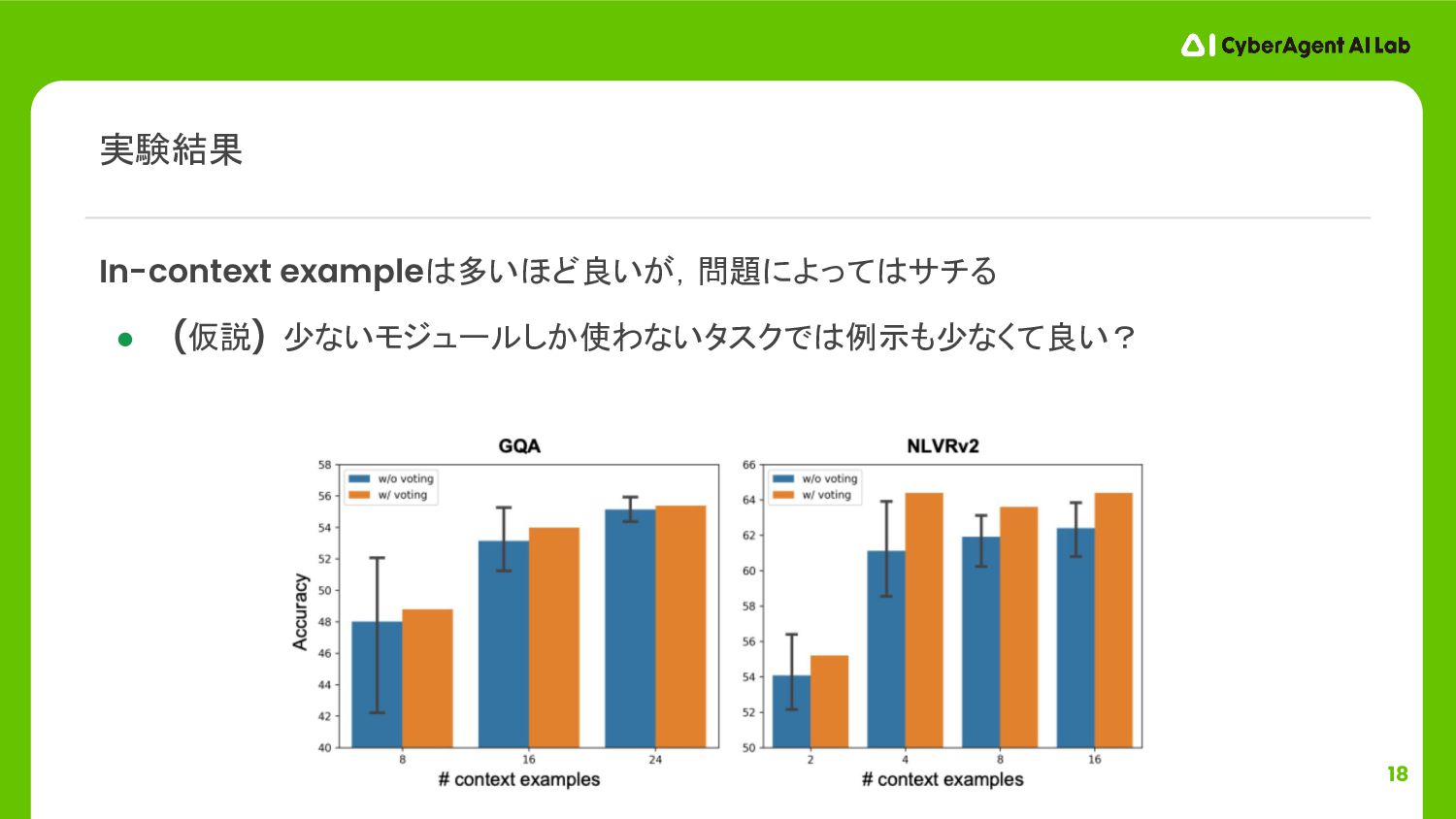
18 In-context exampleは多いほど良いが,問題によってはサチる • (仮説) 少ないモジュールしか使わないタスクでは例示も少なくて良い? 実験結果
19 汎用性に全振りしているので,特定のタスクにおいて強いかはケースバイケース • 勝敗は既存手法のモデルサイズや学習データセットサイズ次第 実験結果 実験結果 (reasoning on image pairs)
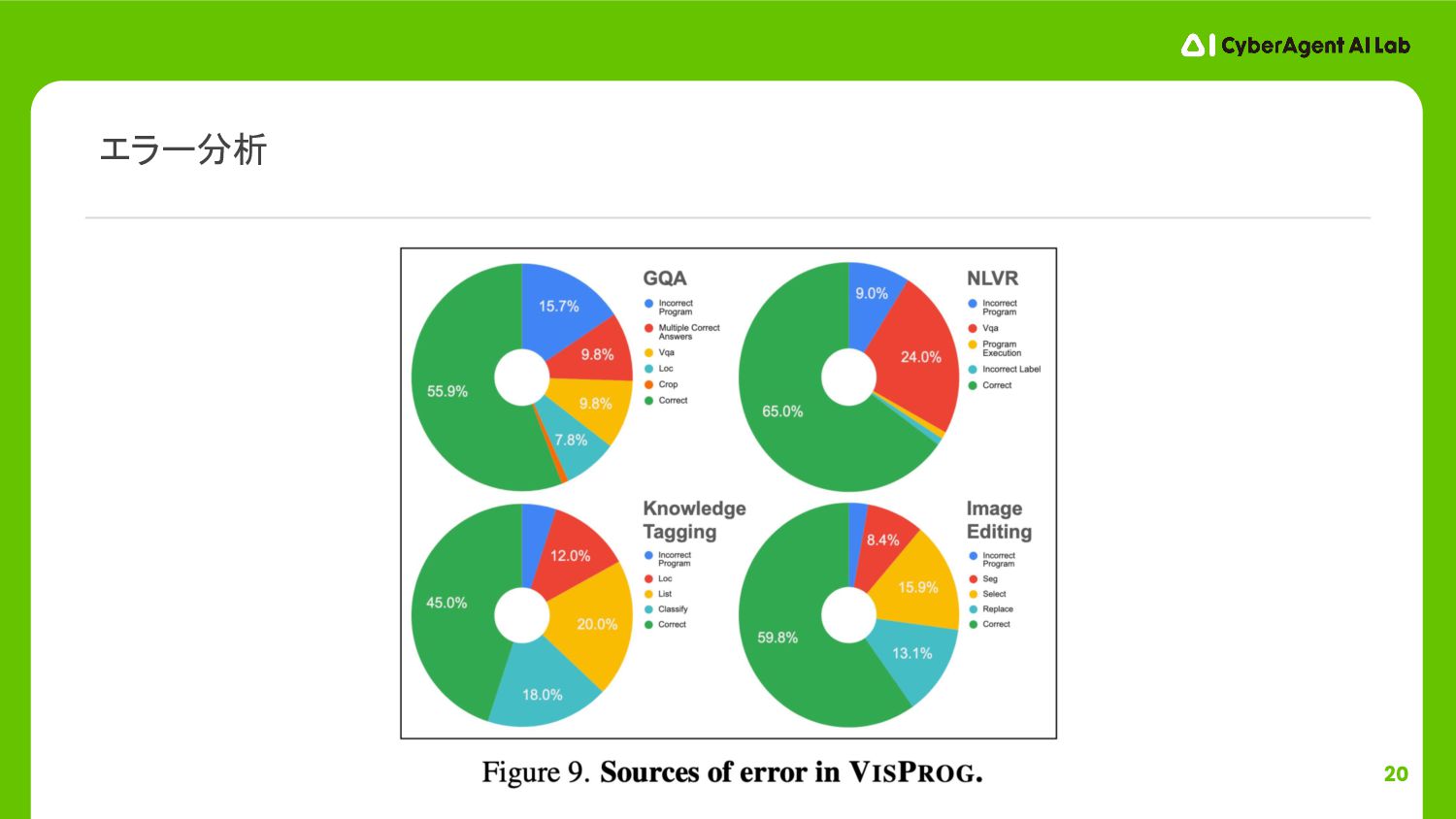
20 エラー分析
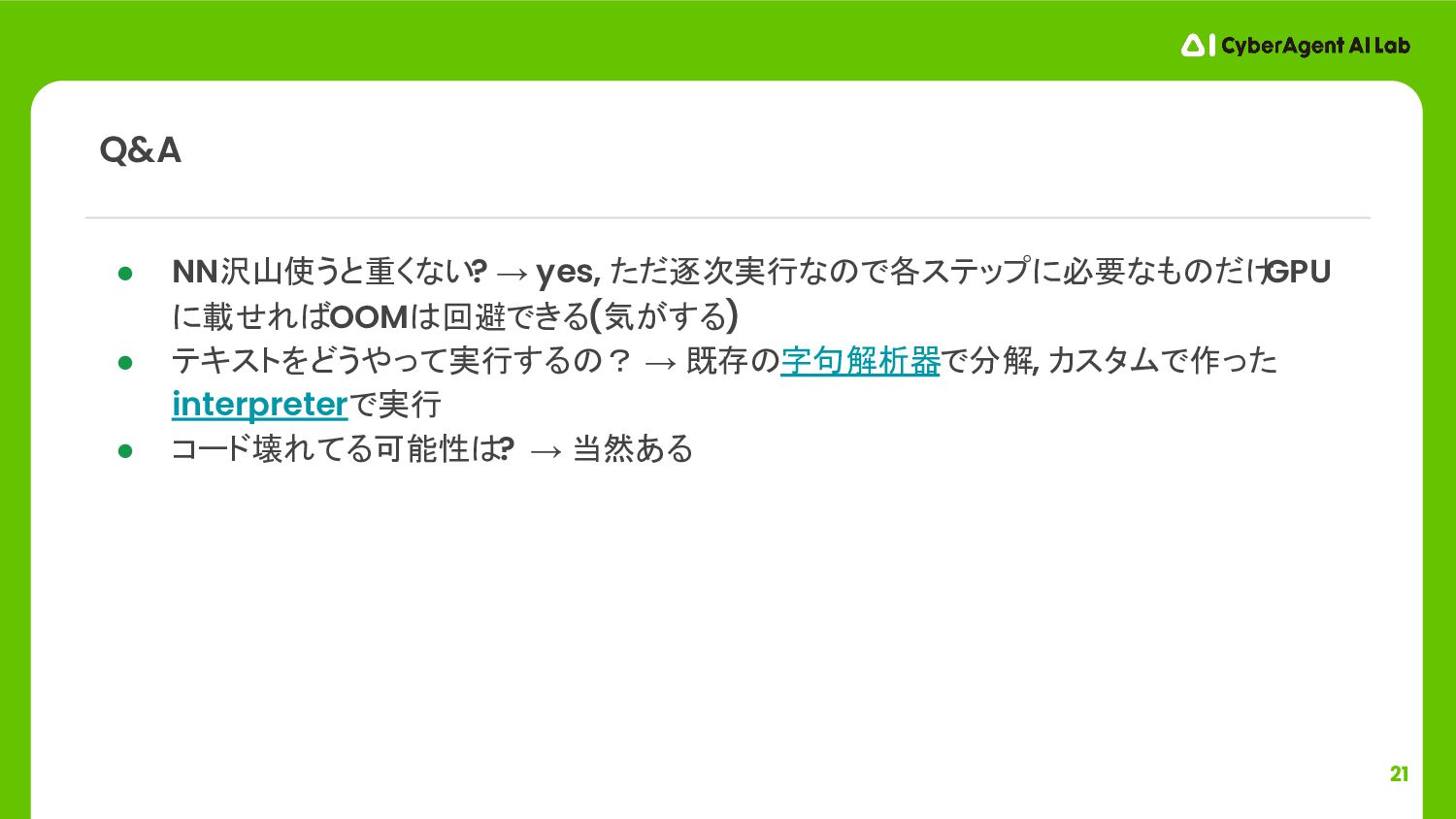
21 • NN沢山使うと重くない? → yes, ただ逐次実行なので各ステップに必要なものだけ GPU に載せればOOMは回避できる(気がする) • テキストをどうやって実行するの?
→ 既存の字句解析器で分解, カスタムで作った interpreterで実行 • コード壊れてる可能性は? → 当然ある Q&A
22 実装大変じゃない? Q&A
23 • 結局タスク数が増えるとin-context examplesの必要数増えて辛いのでは ◦ VQAはモジュール扱い,結果の信頼性がある限りはある程度汎用なモジュールが良い ◦ 結局各モジュールの改善は必須 • エラー訂正,
もしくは実行結果を見てのfeedbackは可能か 議論
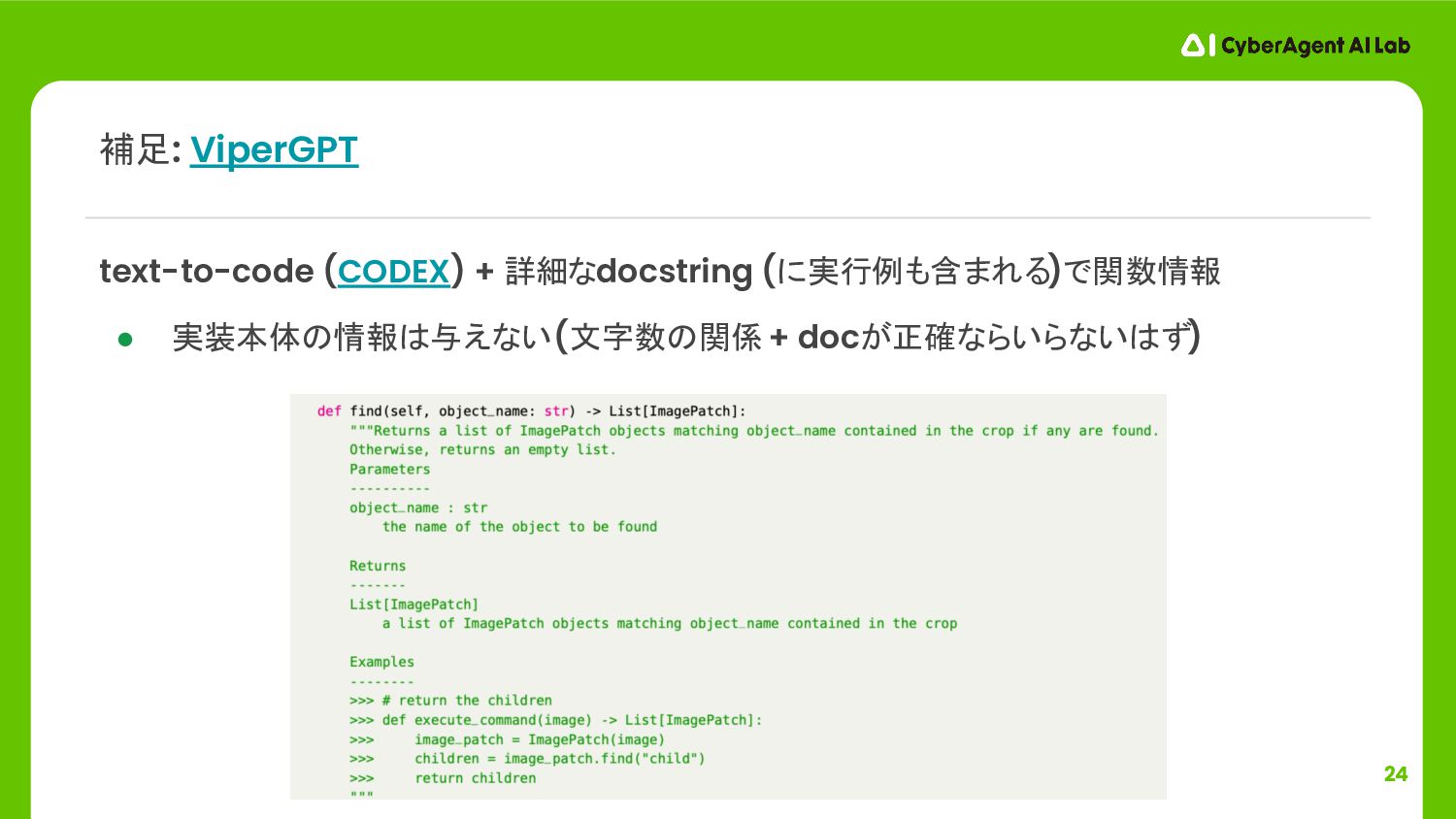
24 text-to-code (CODEX) + 詳細なdocstring (に実行例も含まれる)で関数情報 • 実装本体の情報は与えない (文字数の関係 +
docが正確ならいらないはず) 補足: ViperGPT
25 これも関数定義をpromptとして与えてLLMに使ってもらう試み 補足: Function Calling (OpenAI)
26 Ideas are cheap, execution is everything (≃ 素人発想玄人実行?) Revisiting
old ideas の典型例? • LLMが強くて思想にモデルが追いついてきた感じ • ここ5年くらいは,大規模データで V&L学習 → fine-tune が非常に多かった • Symbolic learningは Jiayuan Mao が地道に掘ってたけど有名とまでは言えない 雰囲気 アカデミアっぽい発想? • 企業だとlong-tailというよりはやっぱボリュームゾーンのタスクを教師あり学習で詰める のがやっぱり王道 所感
27 Scholars & Big Models: How Can Academics Adapt? •
Workshop in CVPR’23, スライドが全公開されている • 大規模モデル時代にどう戦うか?をテーマに大物がトーク ◦ 個人的なおすすめ: Jon Barron / Derek Hoiem 余談
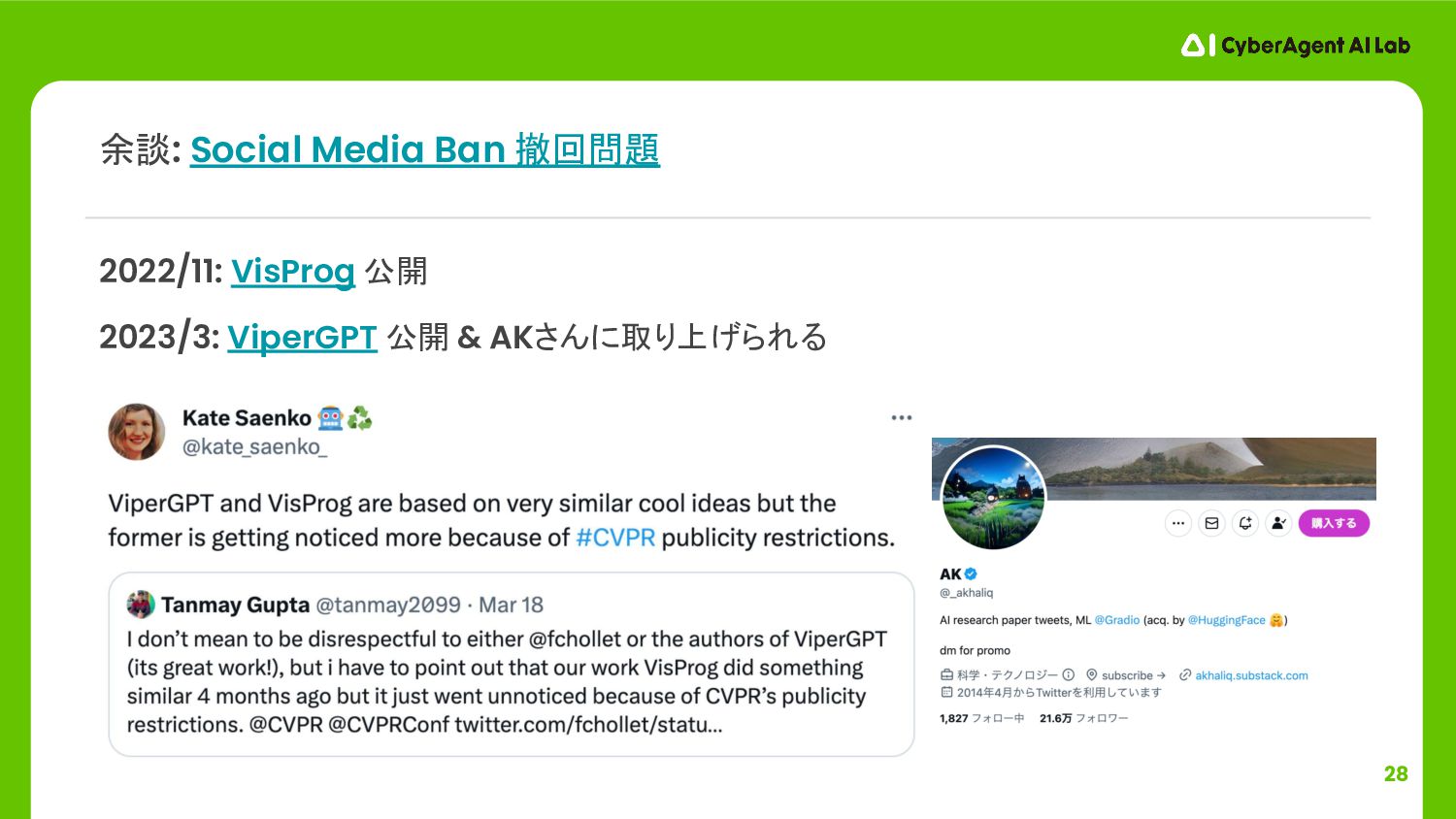
28 2022/11: VisProg 公開 2023/3: ViperGPT 公開 & AKさんに取り上げられる 余談:
Social Media Ban 撤回問題
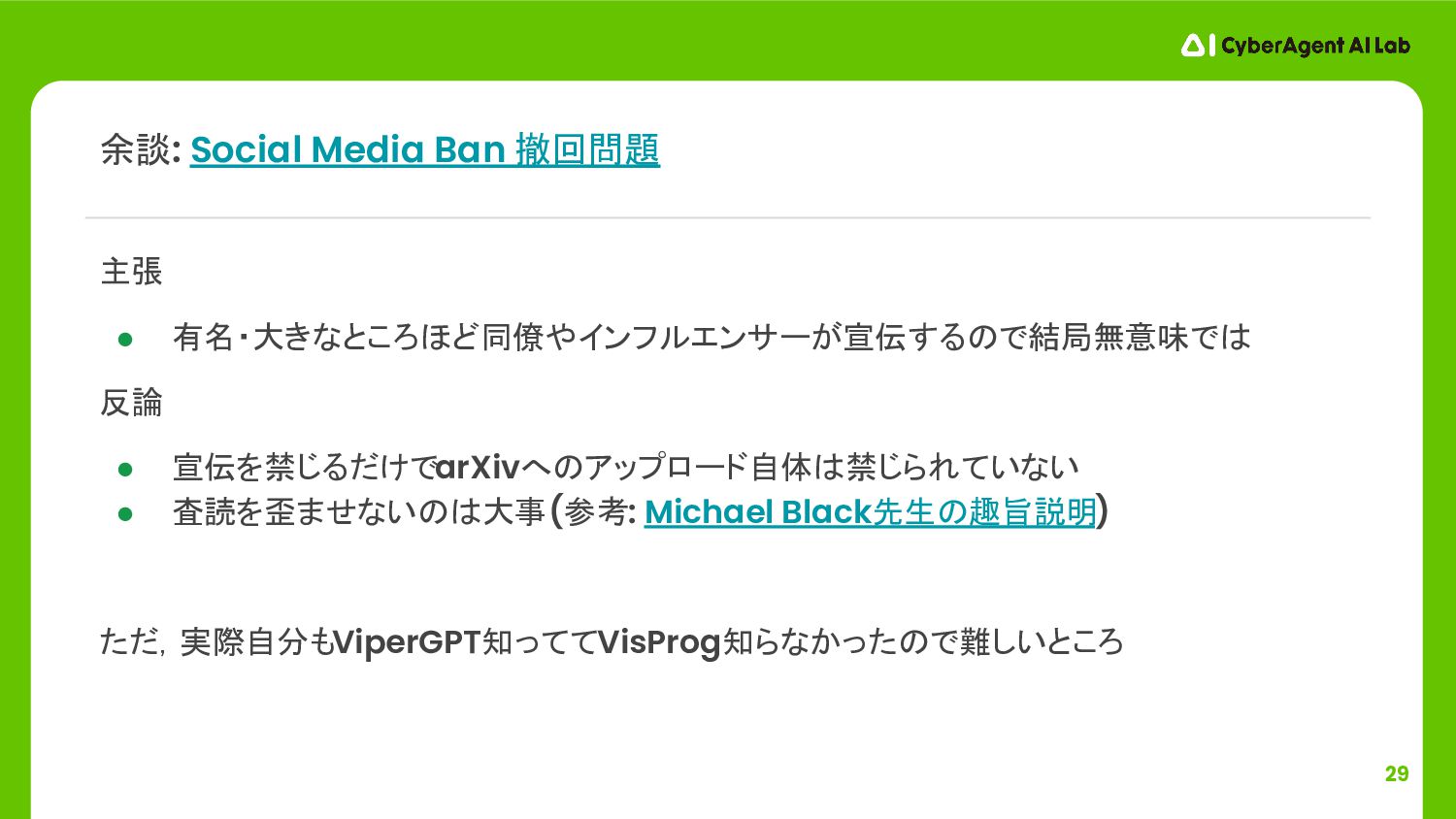
29 主張 • 有名・大きなところほど同僚やインフルエンサーが宣伝するので結局無意味では 反論 • 宣伝を禁じるだけでarXivへのアップロード自体は禁じられていない • 査読を歪ませないのは大事 (参考:
Michael Black先生の趣旨説明) ただ,実際自分もViperGPT知っててVisProg知らなかったので難しいところ 余談: Social Media Ban 撤回問題
30 • 学習 (勾配降下) 不要で多種多様なタスクを解く • LLMのin-context learning能力をフル活用して,neuro-symbolic approachの アップデート
• ロングテール性・解釈性・拡張性などのメリット まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}