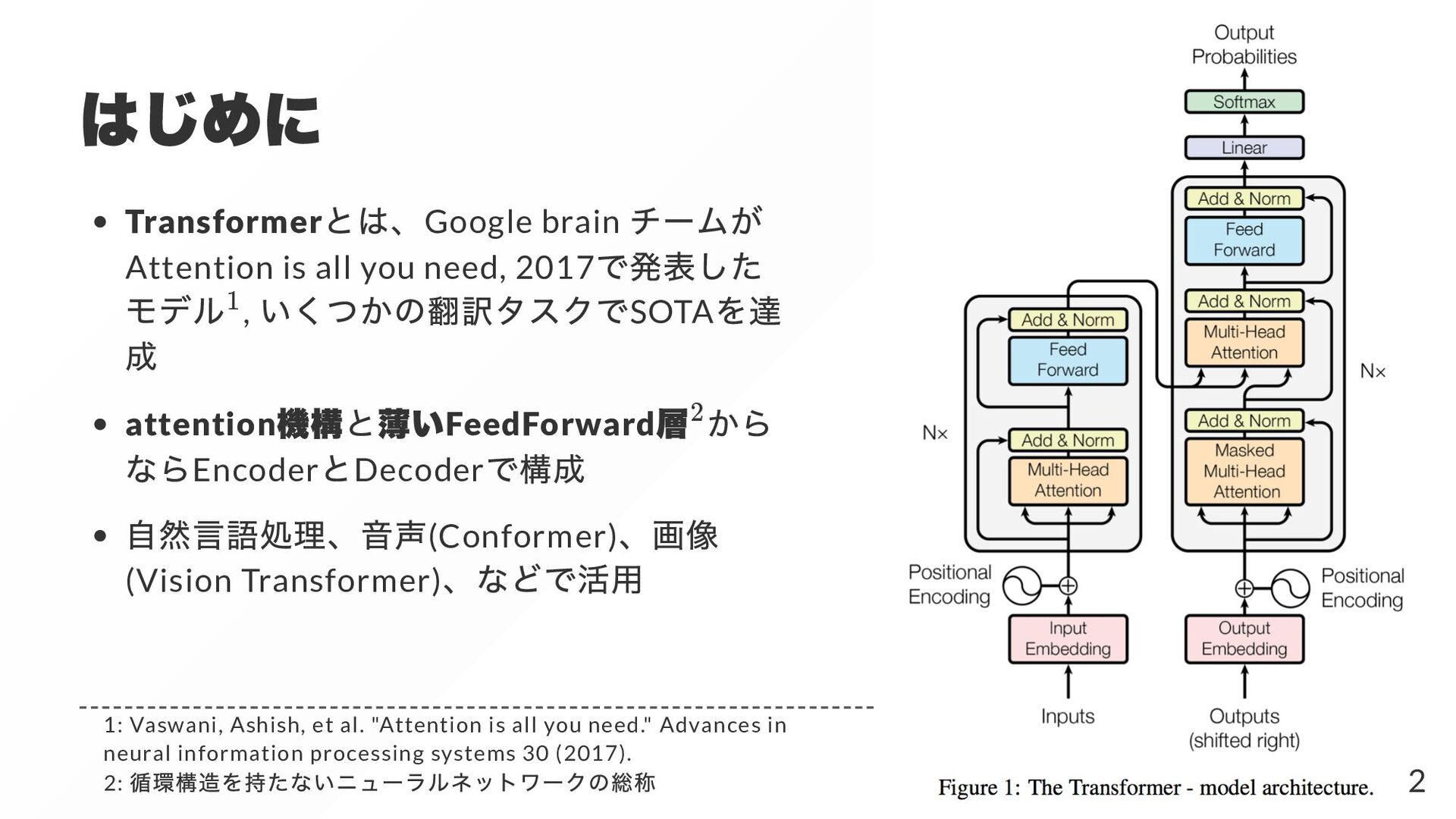
SOTA attention FeedForward Encoder Decoder (Conformer) (Vision Transformer) 1 2 1: Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017). 2: 2
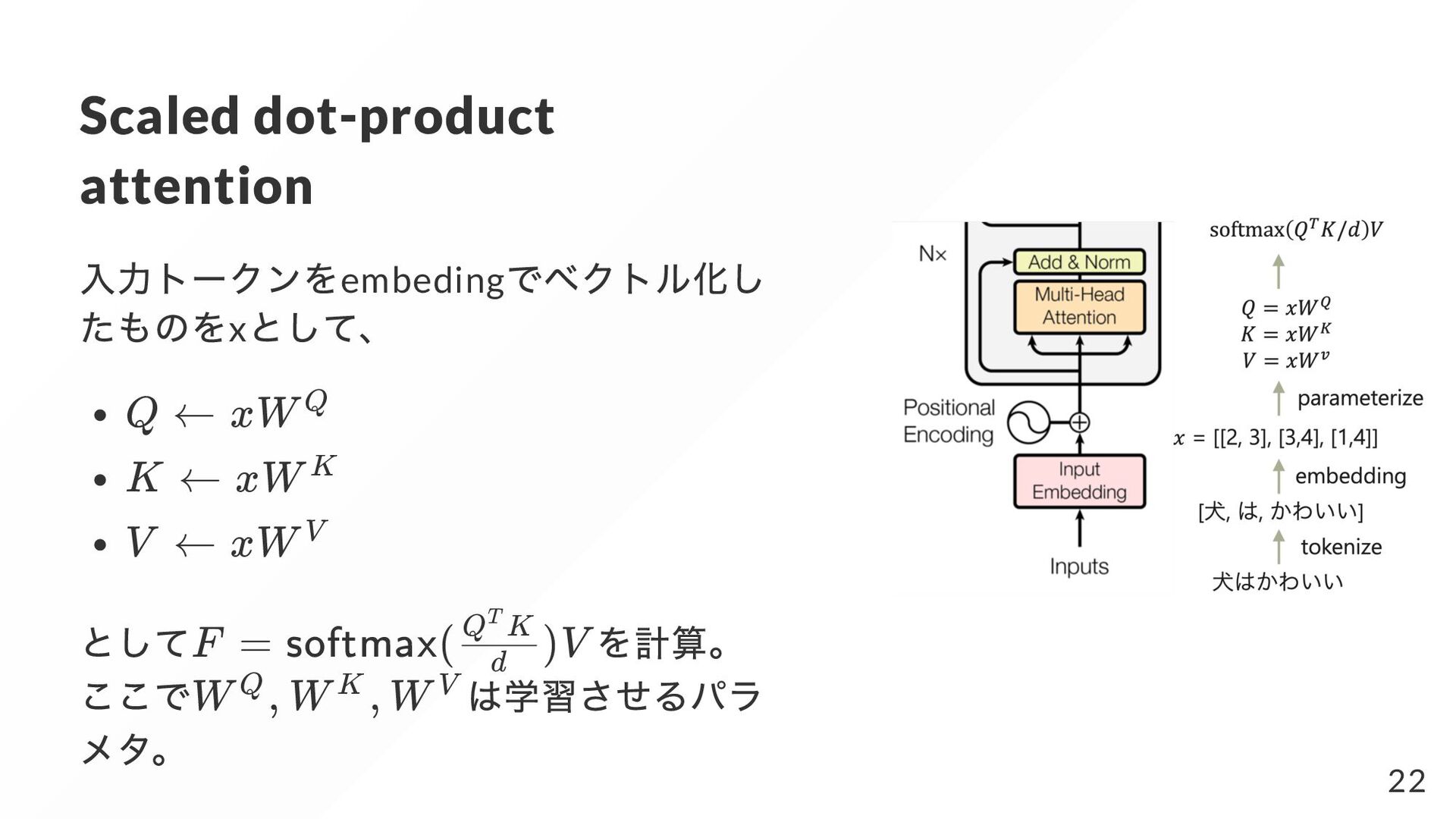
i z i q r r = i r(z , q) i r z i q (a , ..., a ) = 1 N softmax(r , ..., r ) 1 N 1 F = a z ∑ i i 1: softmax a = i r /( e ) i ∑ r i a = ∑ i 1 a ≥ i 0 r ≥ i r j a ≥ i a j 14
{kind=link}
{kind=link}
{kind=link}
![[1] . 2 (MLP ). , 2015. [2] AIcia Solid](https://files.speakerdeck.com/presentations/bb3429a747734e84b8400e51473d47d1/slide_3.jpg){kind=link}
![attention transformer ([3] ) , BERT, GPT Transofor positional encoding,](https://files.speakerdeck.com/presentations/bb3429a747734e84b8400e51473d47d1/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Attention " (query) " [1, Chapter7.2] ( )" " 13](https://files.speakerdeck.com/presentations/bb3429a747734e84b8400e51473d47d1/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
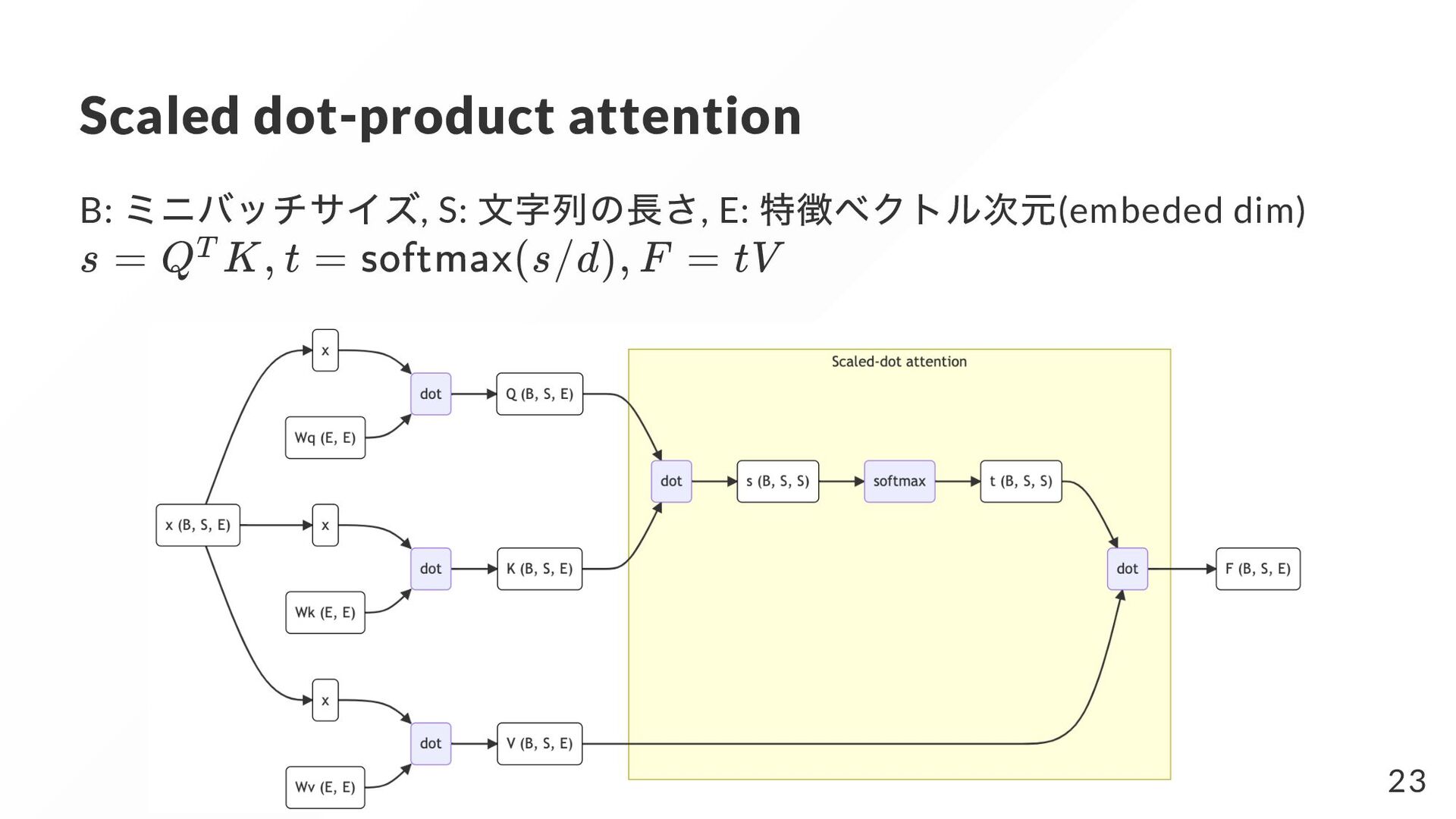{kind=link}
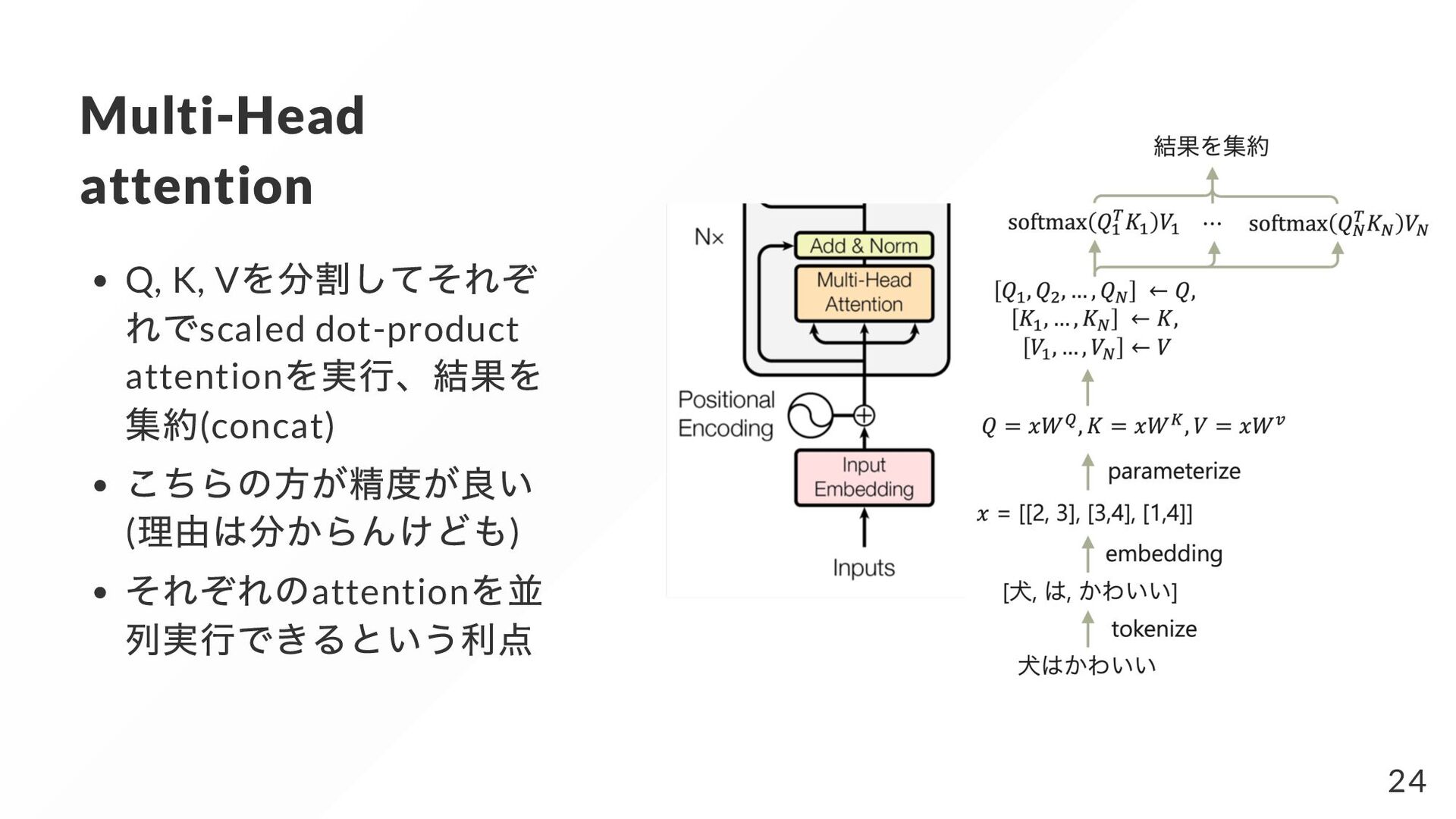{kind=link}
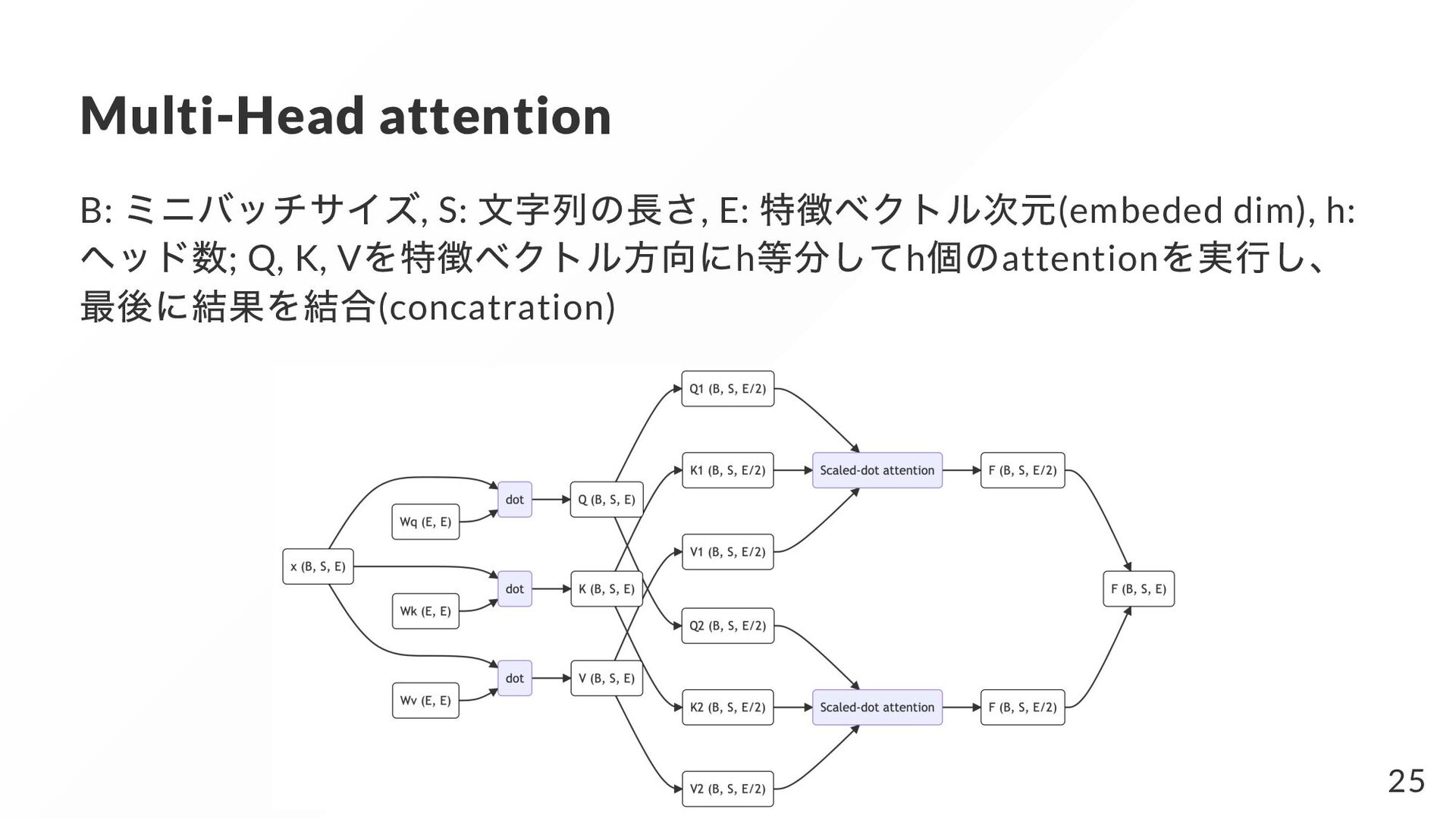{kind=link}
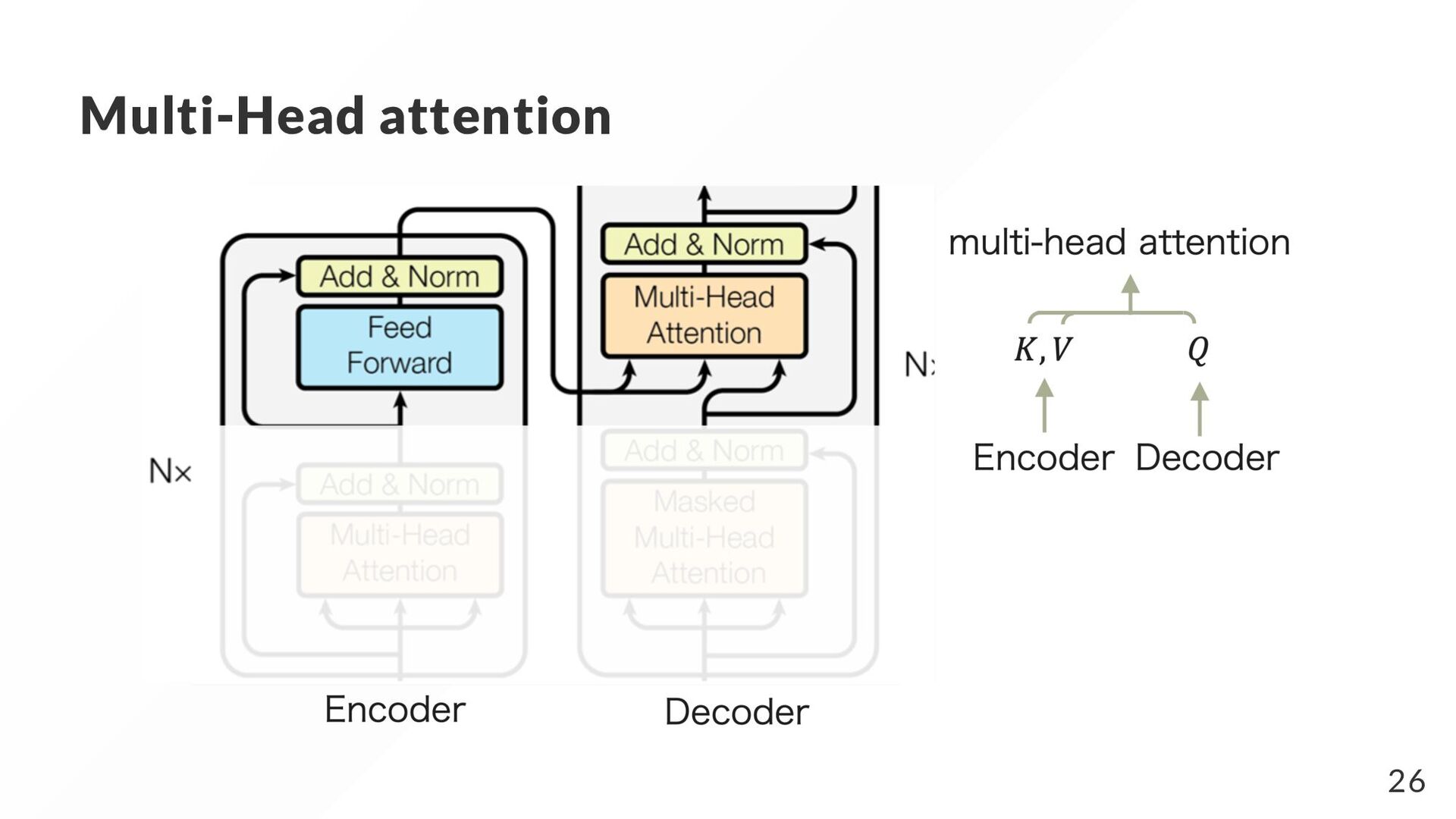{kind=link}
![Residual connection "ReLU "[1] z = f(x) + x ,](https://files.speakerdeck.com/presentations/bb3429a747734e84b8400e51473d47d1/slide_26.jpg){kind=link}
![x[i][j] i ID j 28](https://files.speakerdeck.com/presentations/bb3429a747734e84b8400e51473d47d1/slide_27.jpg){kind=link}
{kind=link}
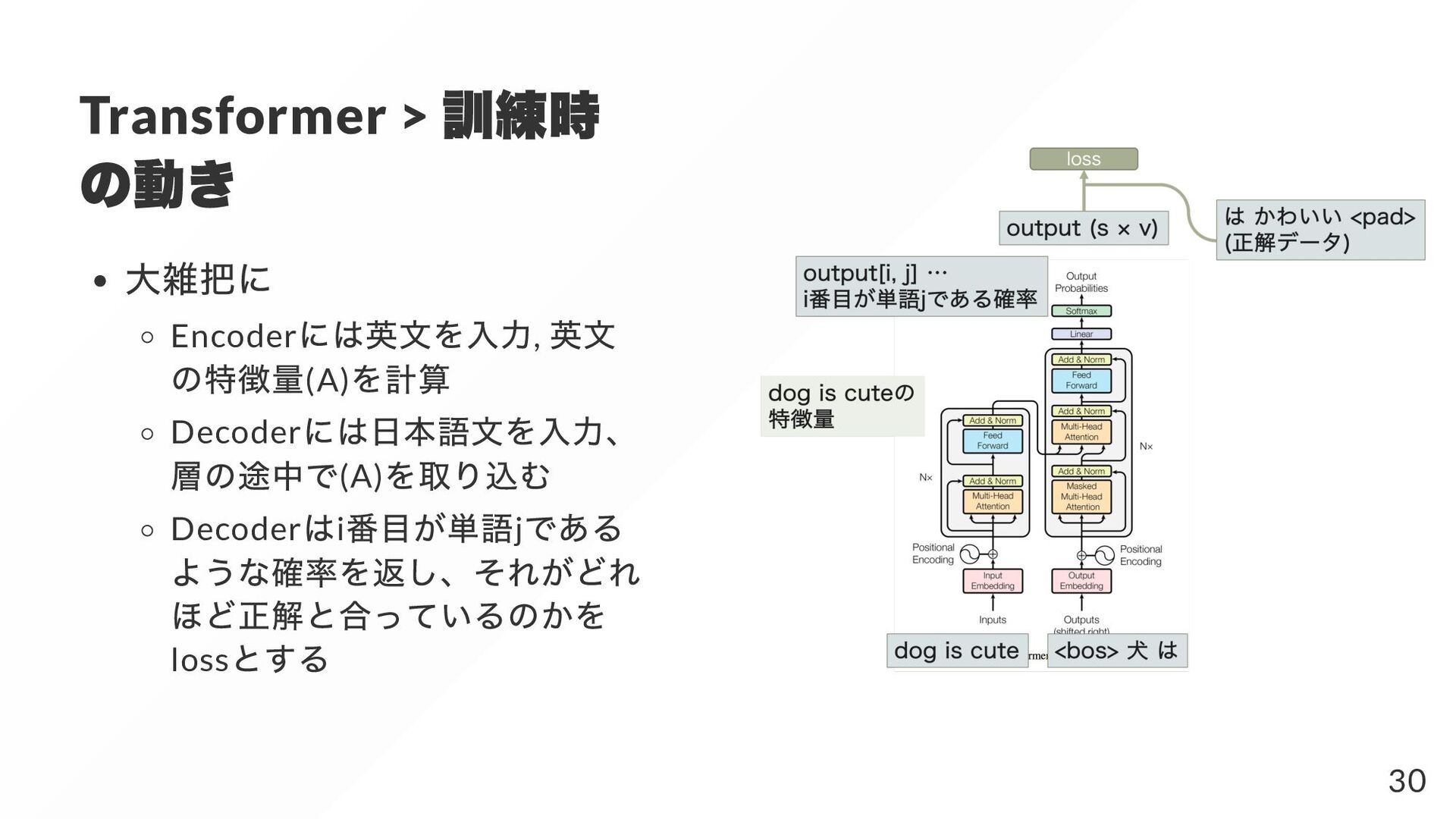{kind=link}
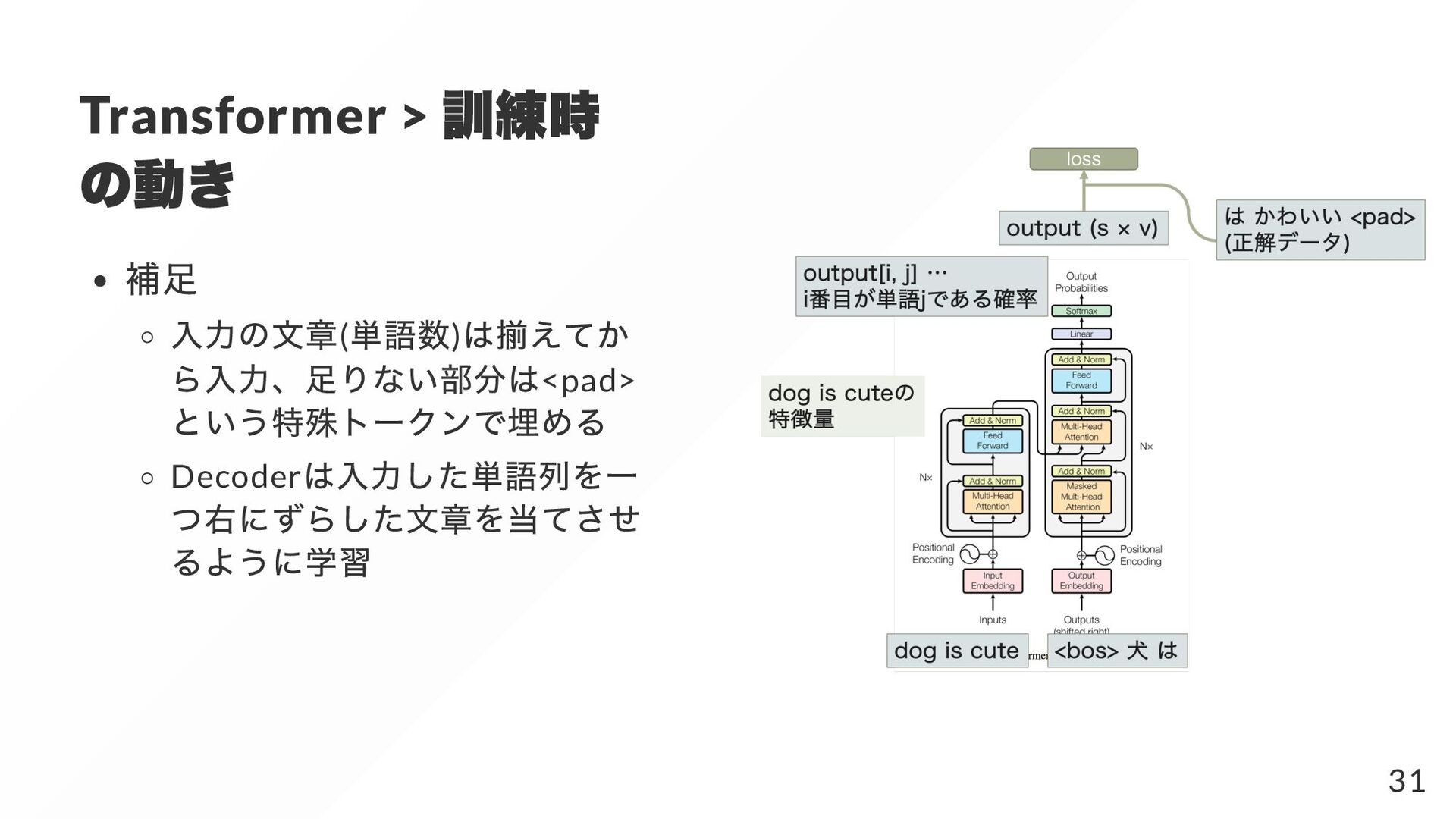{kind=link}
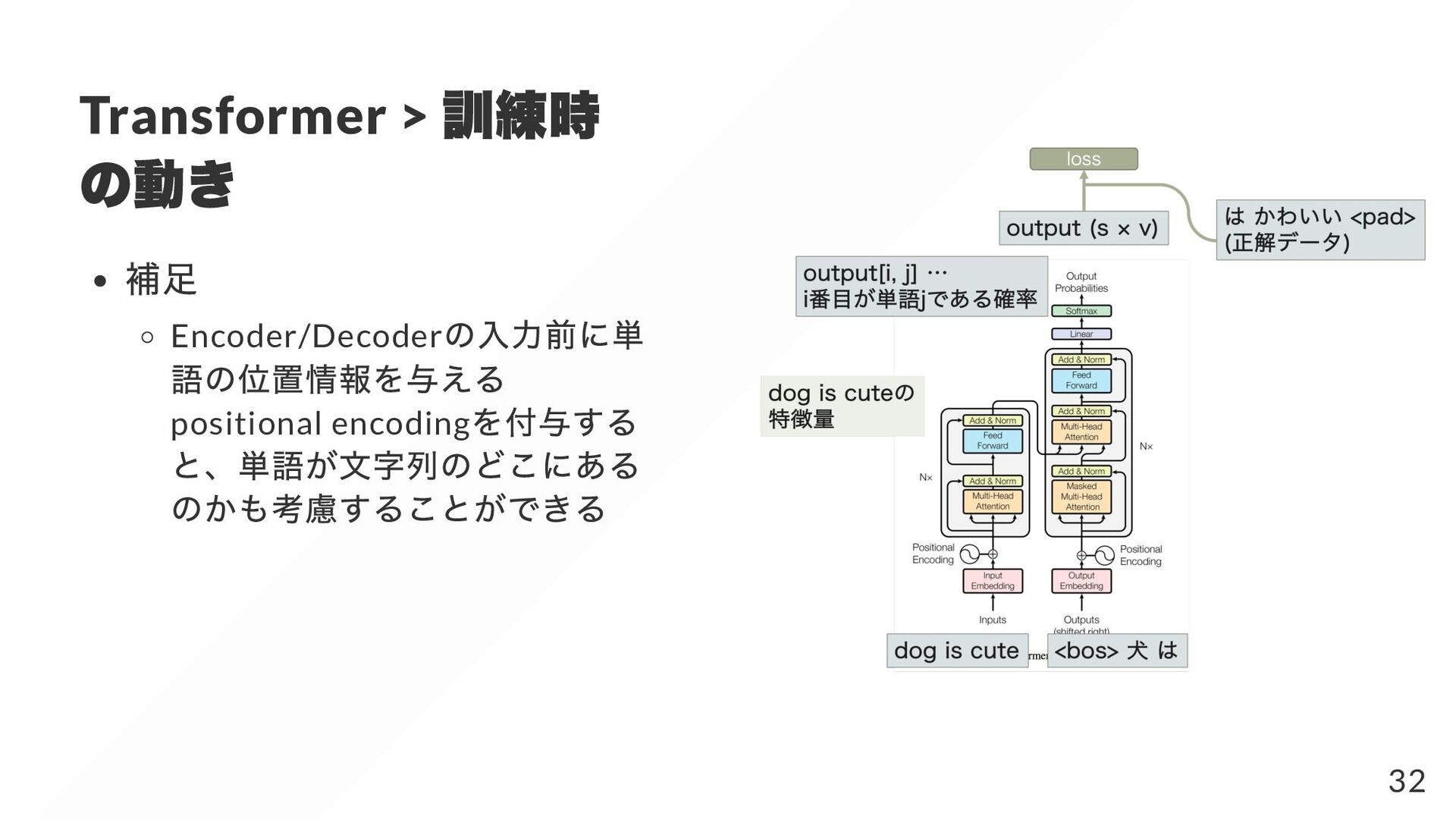{kind=link}
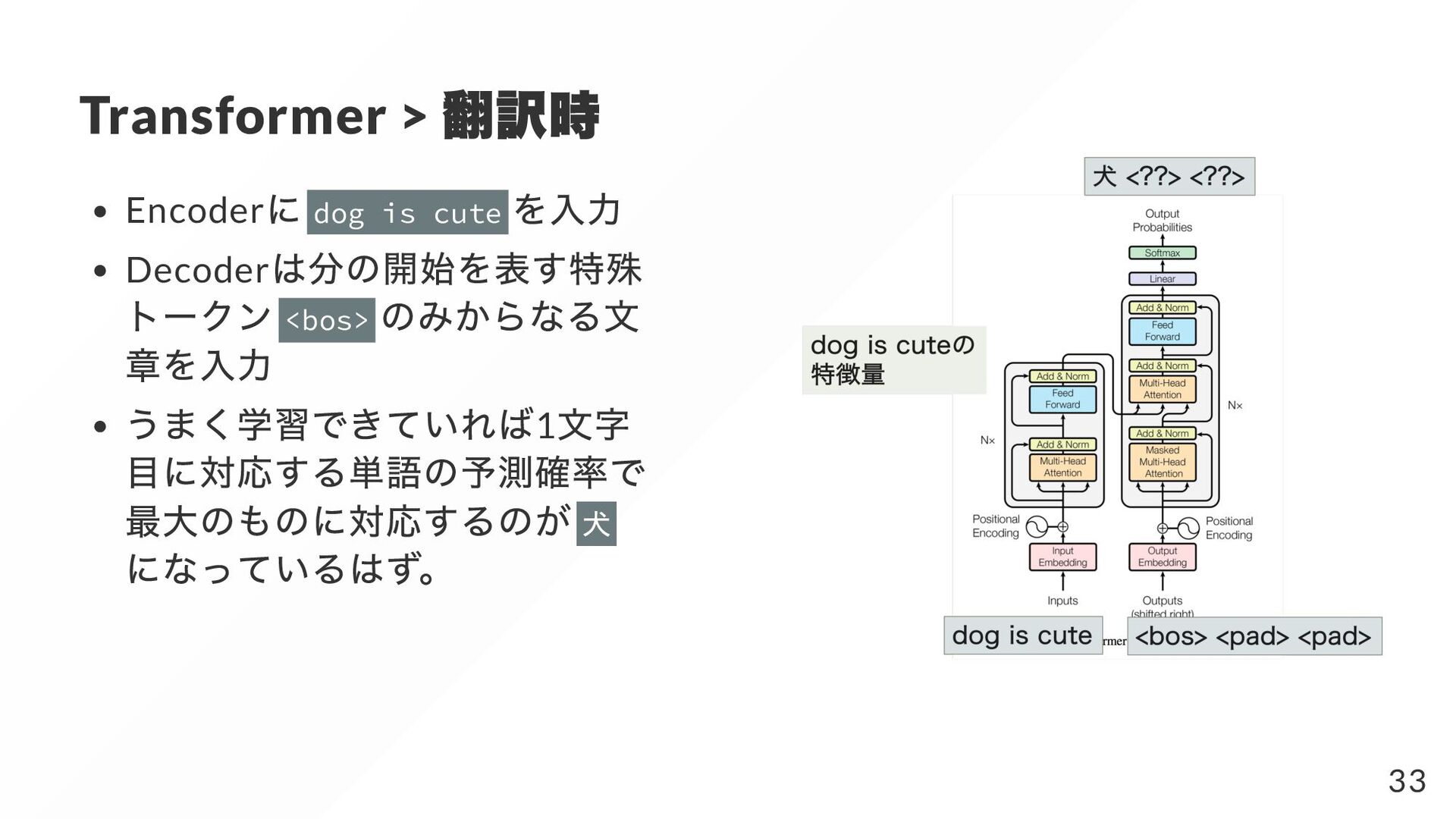{kind=link}
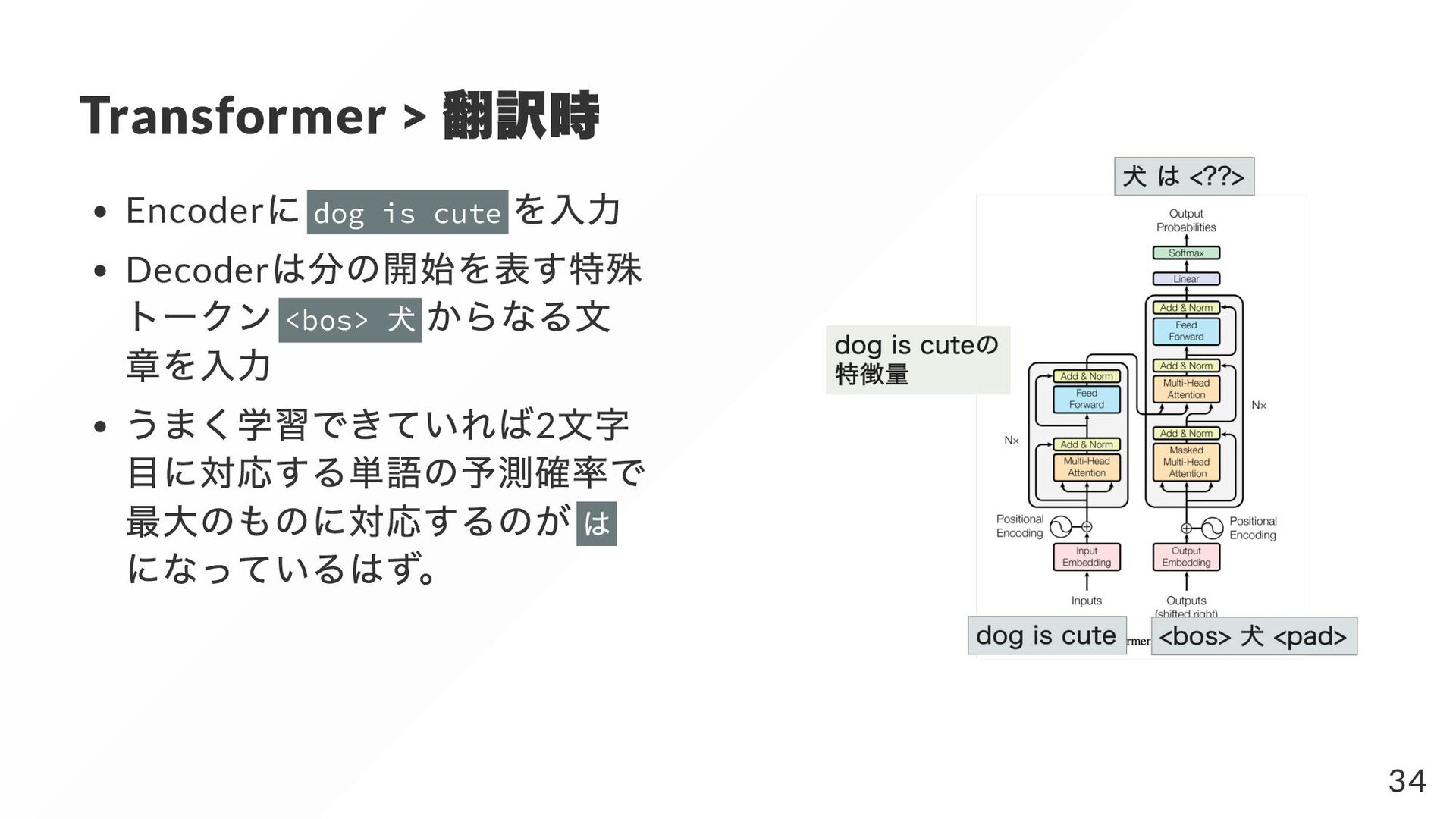{kind=link}
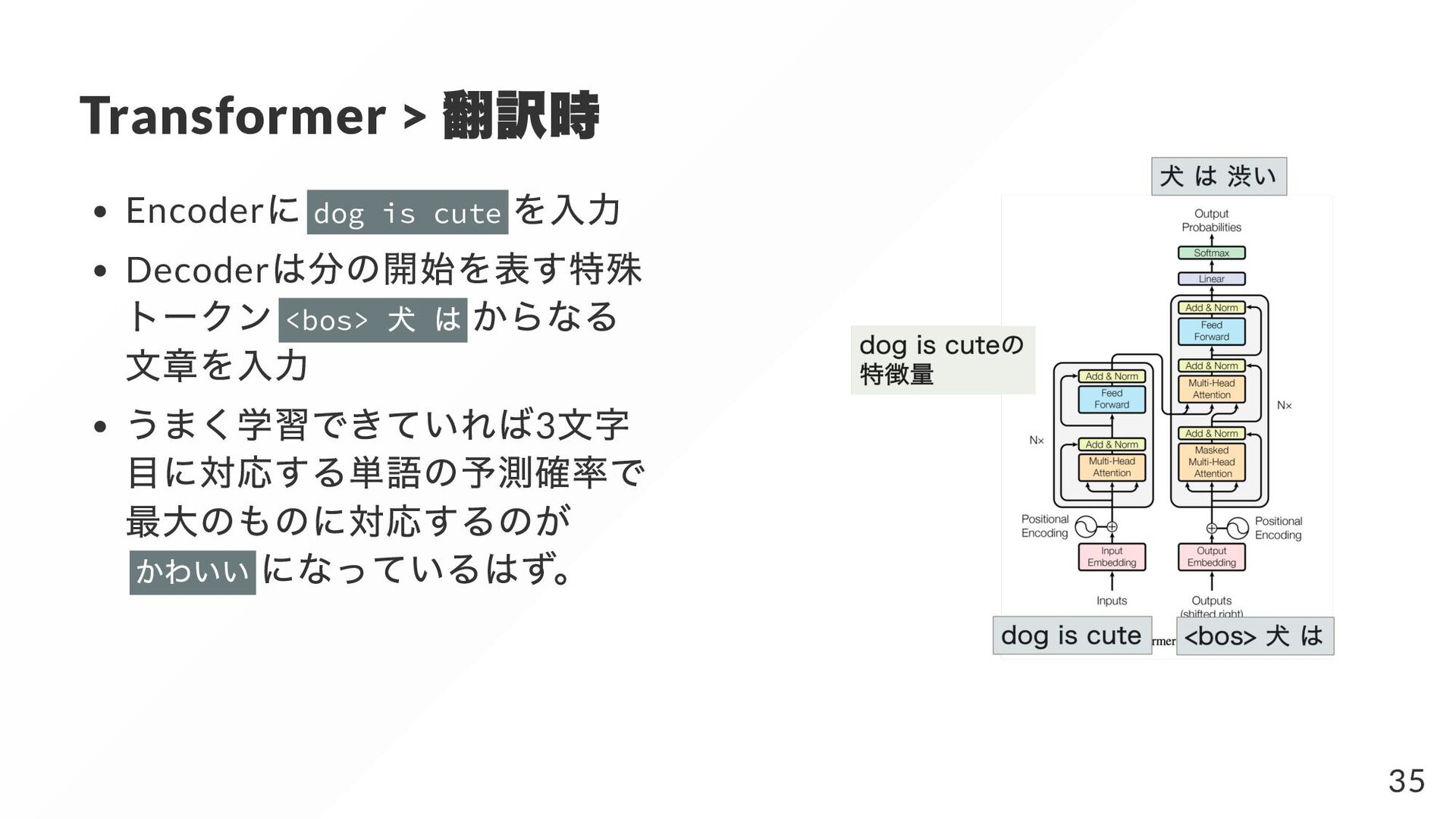{kind=link}
{kind=link}