• トポロジAとBを合成したトポロジCのア ルゴリズム帯域はトポロジAとBのアルゴ リズム帯域の和 2. ワーカーが使⽤するインターフェイ ス数が平準化される合成⽅法が存在 • 次数の最⼤値と最⼩値が1以下になるよ うにトポロジを合成する⽅法が存在する ことを⽰した 1 3 4 6 5 2 !! = (1,1,1,1,2,2) 5 3 4 6 2 1 !" = (2,2,2,2,1,1) 5 3 4 6 2 1 ! = (3,3,3,3,3,3) 1 3 4 6 5 2 1 3 4 5 2 6 !! = (1,2,1,1,2,1) !" = (1,2,2,2,2,1) 2 3 4 5 6 1 ! = (2,4,3,3,4,2) 最⼤次数が4となる組み合わせ⽅ 最⼤次数が3となる組み合わせ⽅
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 © NTT CORPORATION 2024 背景 > 再構成可能な直接結合網(OCS網) ・すでに、⼀部のデータセンタ、AI/ML基盤でOCSを⽤いたネットワークが採⽤されている [1]](https://files.speakerdeck.com/presentations/4c516e032f2e440e8c86148396593dfe/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![18 © NTT CORPORATION 2024 提案⼿法 > 概要 [1] Shah,](https://files.speakerdeck.com/presentations/4c516e032f2e440e8c86148396593dfe/slide_17.jpg){kind=link}
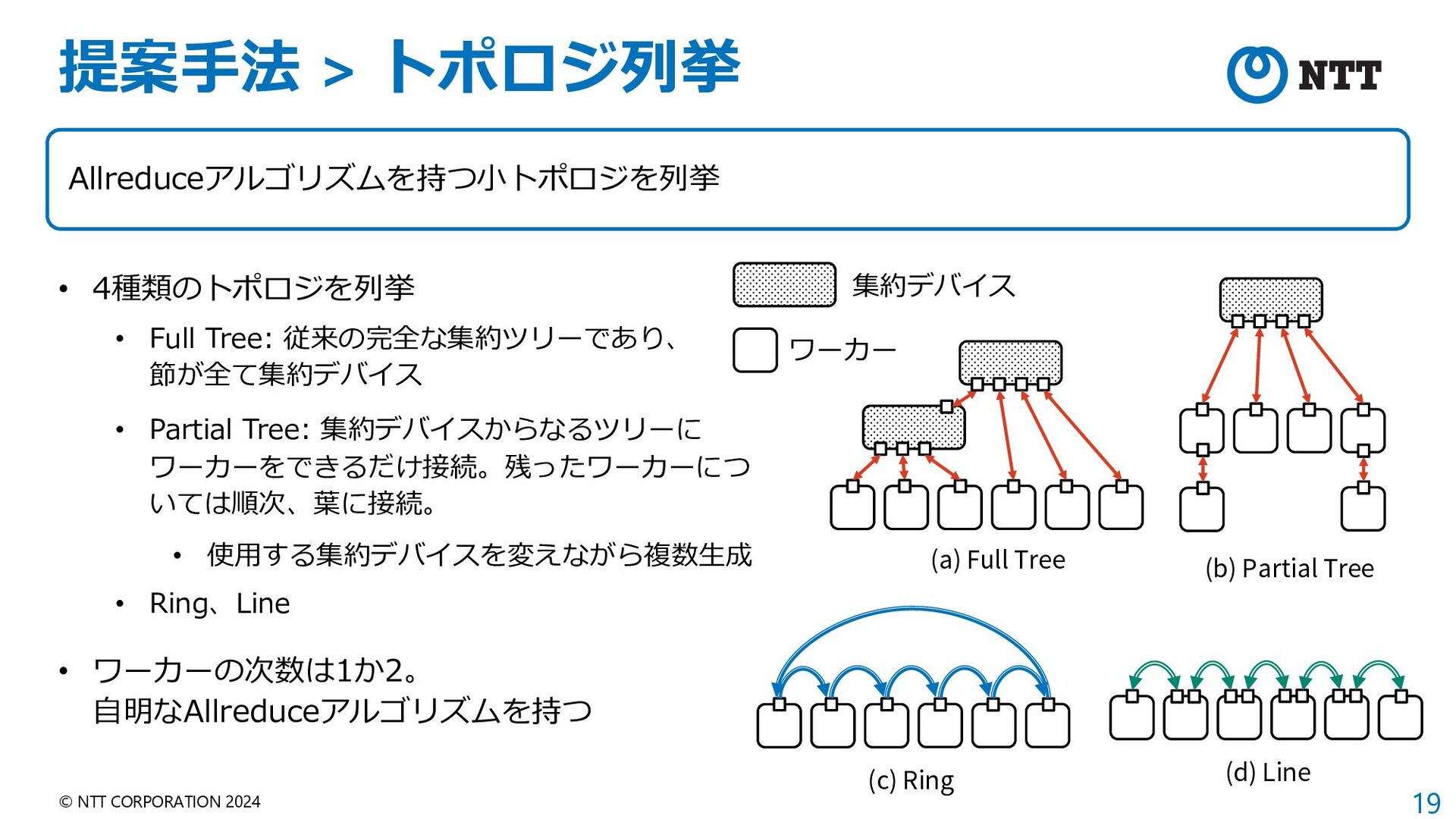{kind=link}
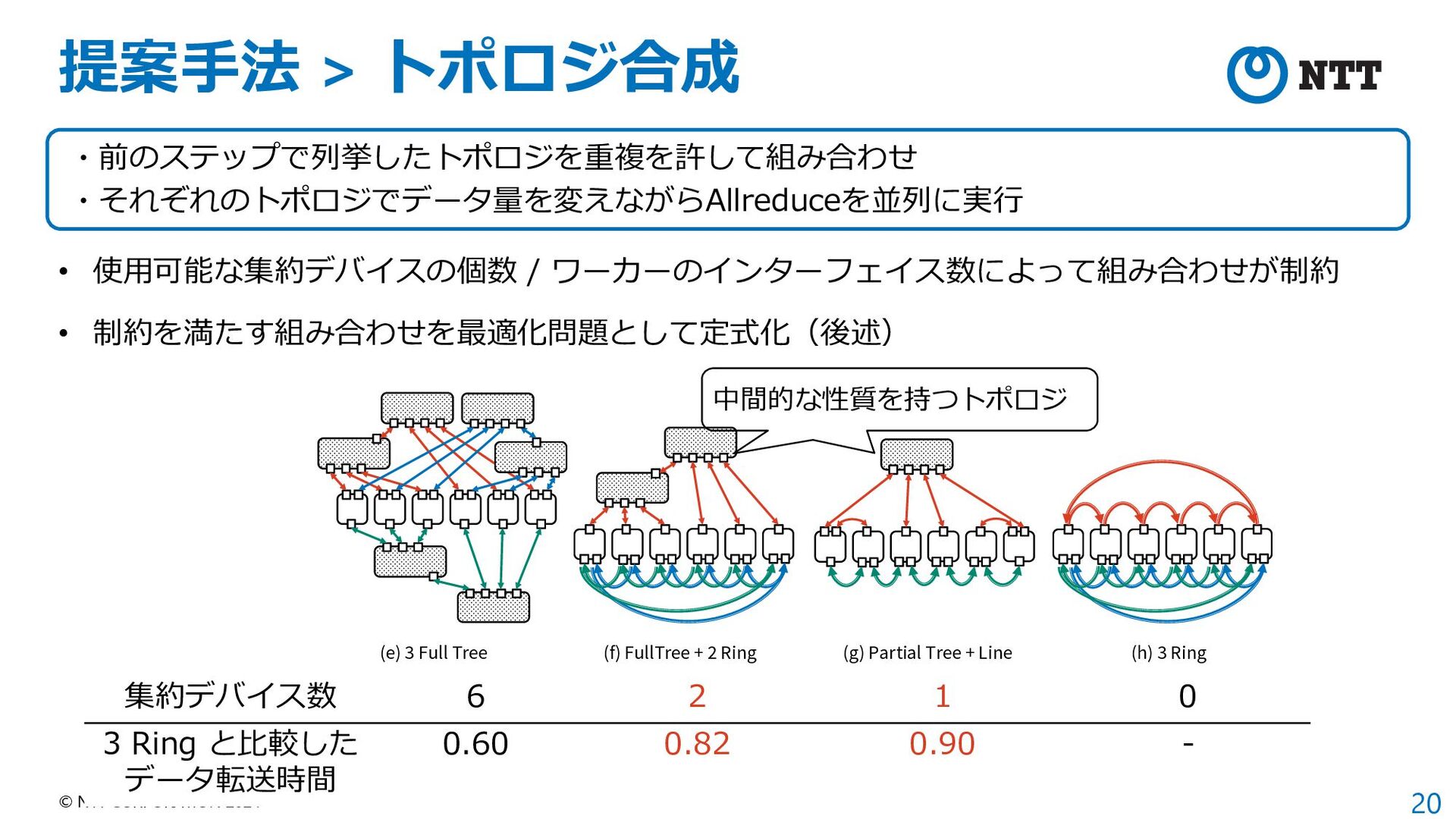{kind=link}
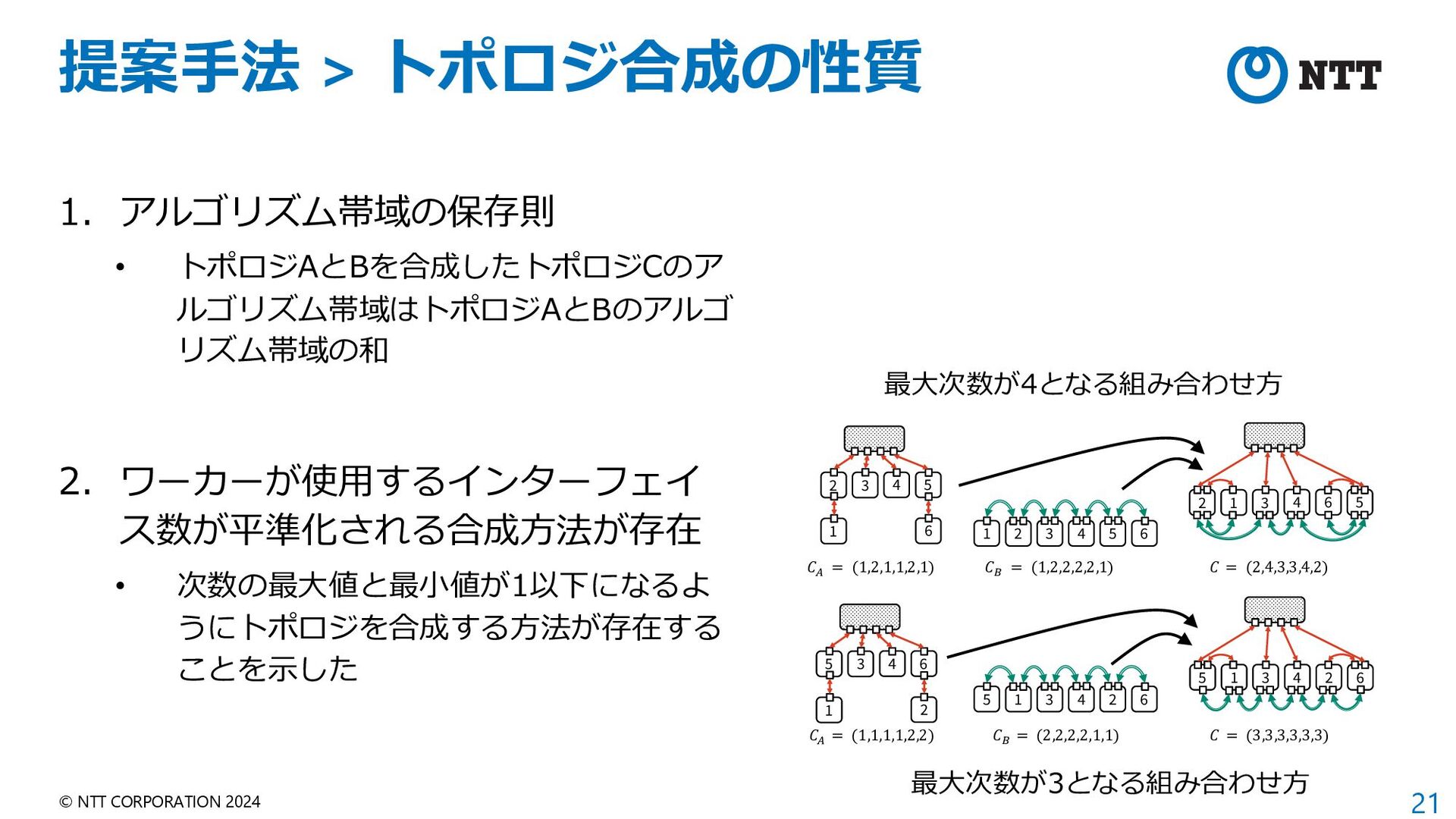{kind=link}
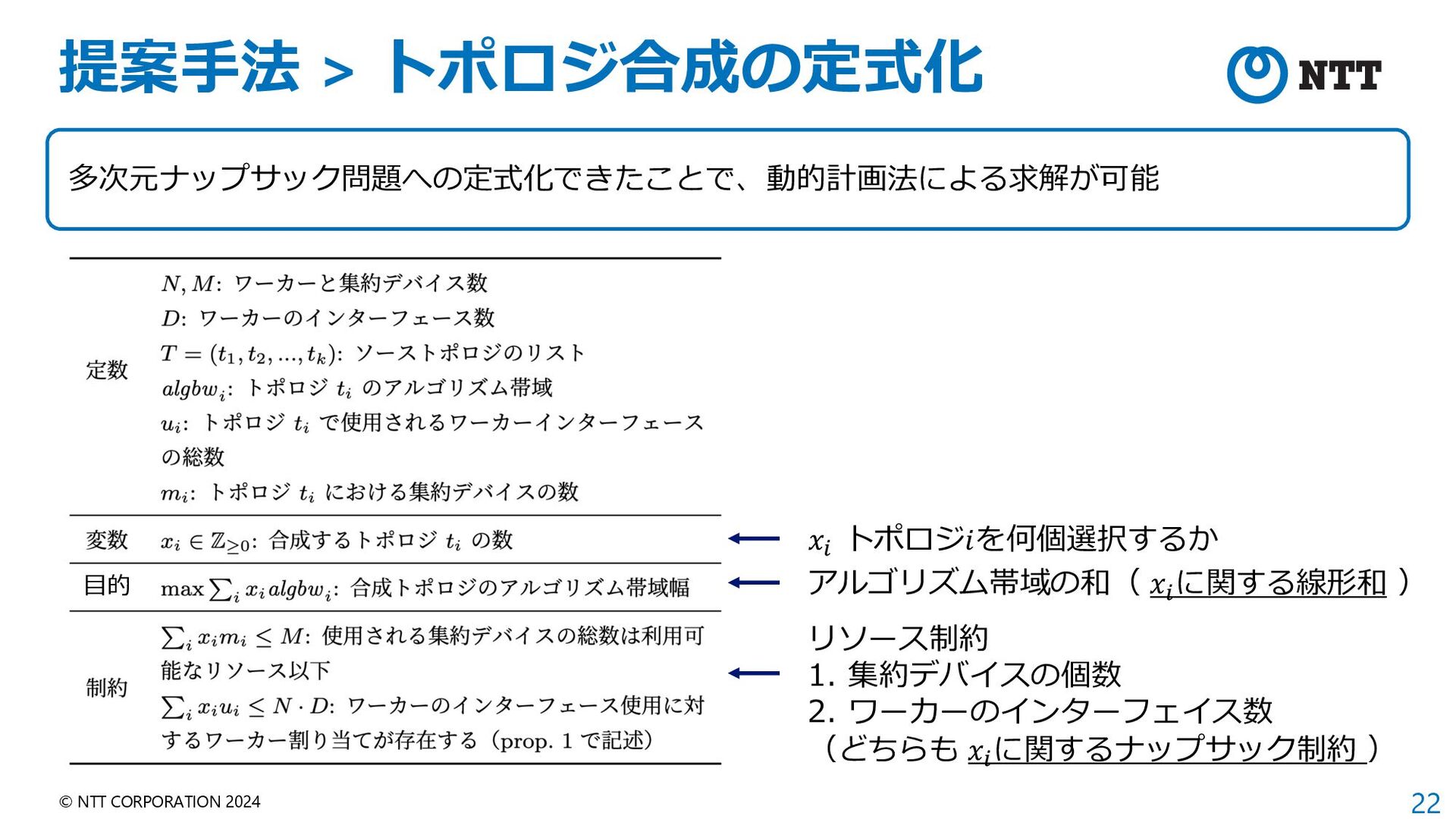{kind=link}
{kind=link}
{kind=link}
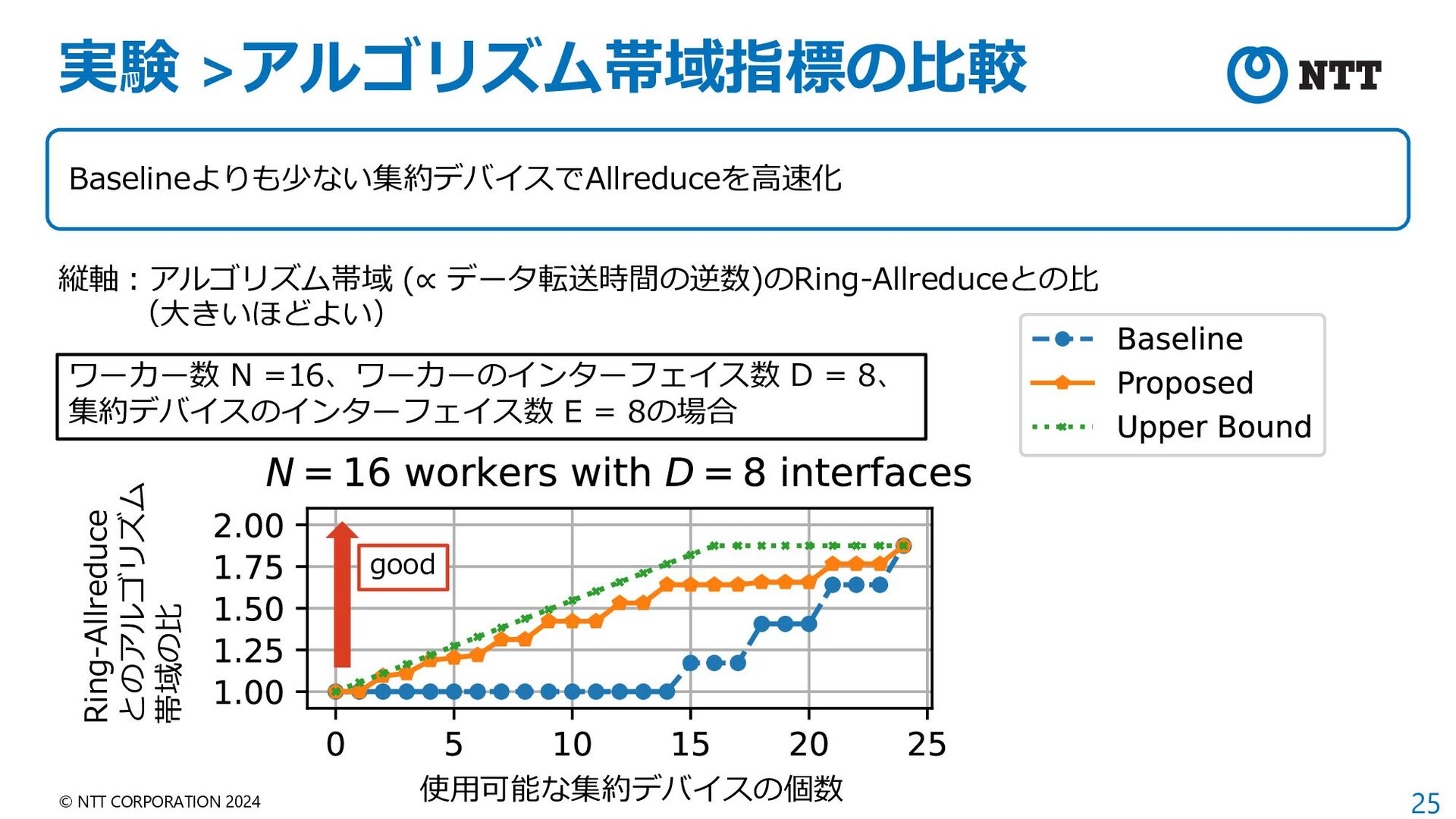{kind=link}
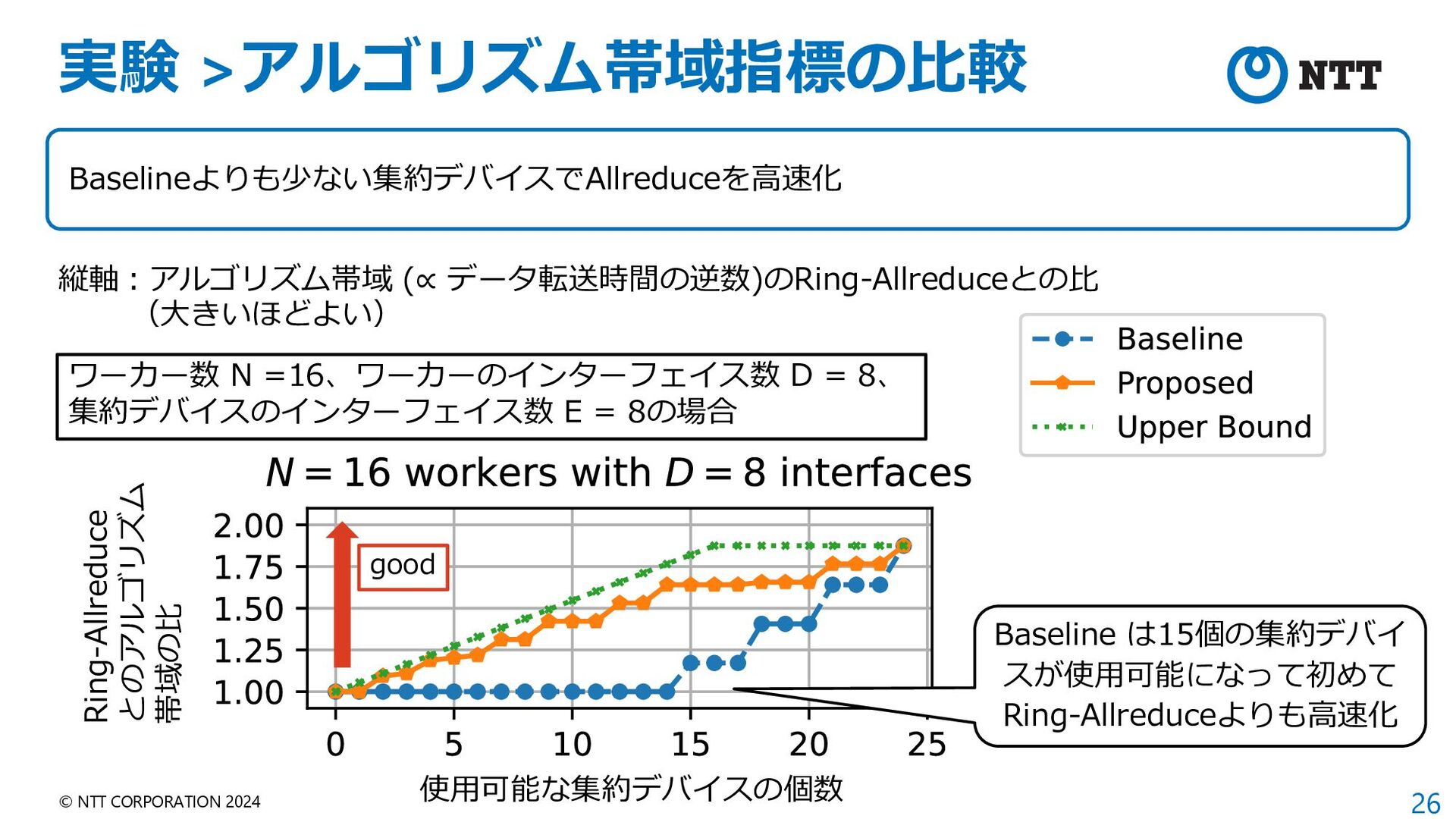{kind=link}
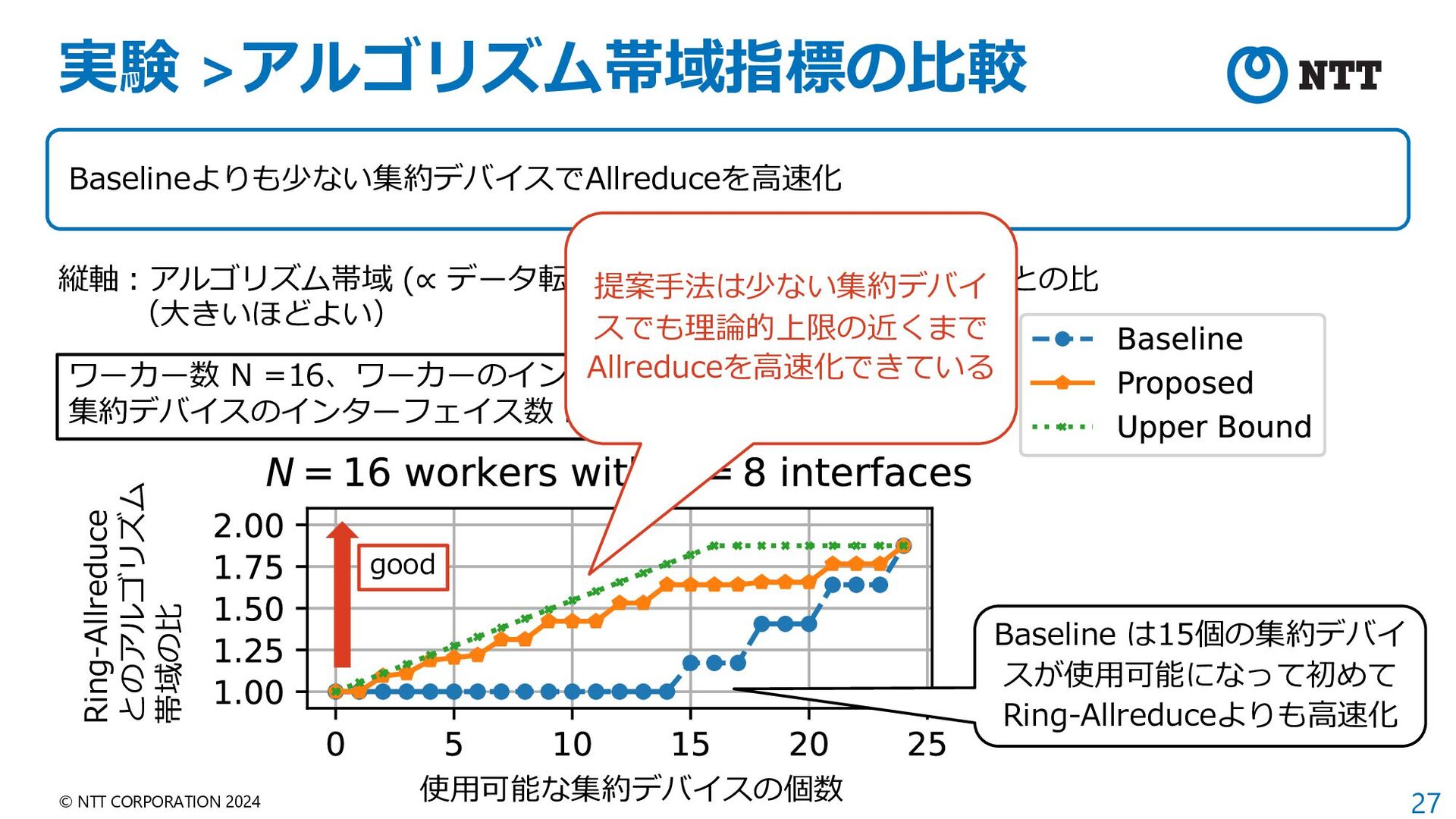{kind=link}
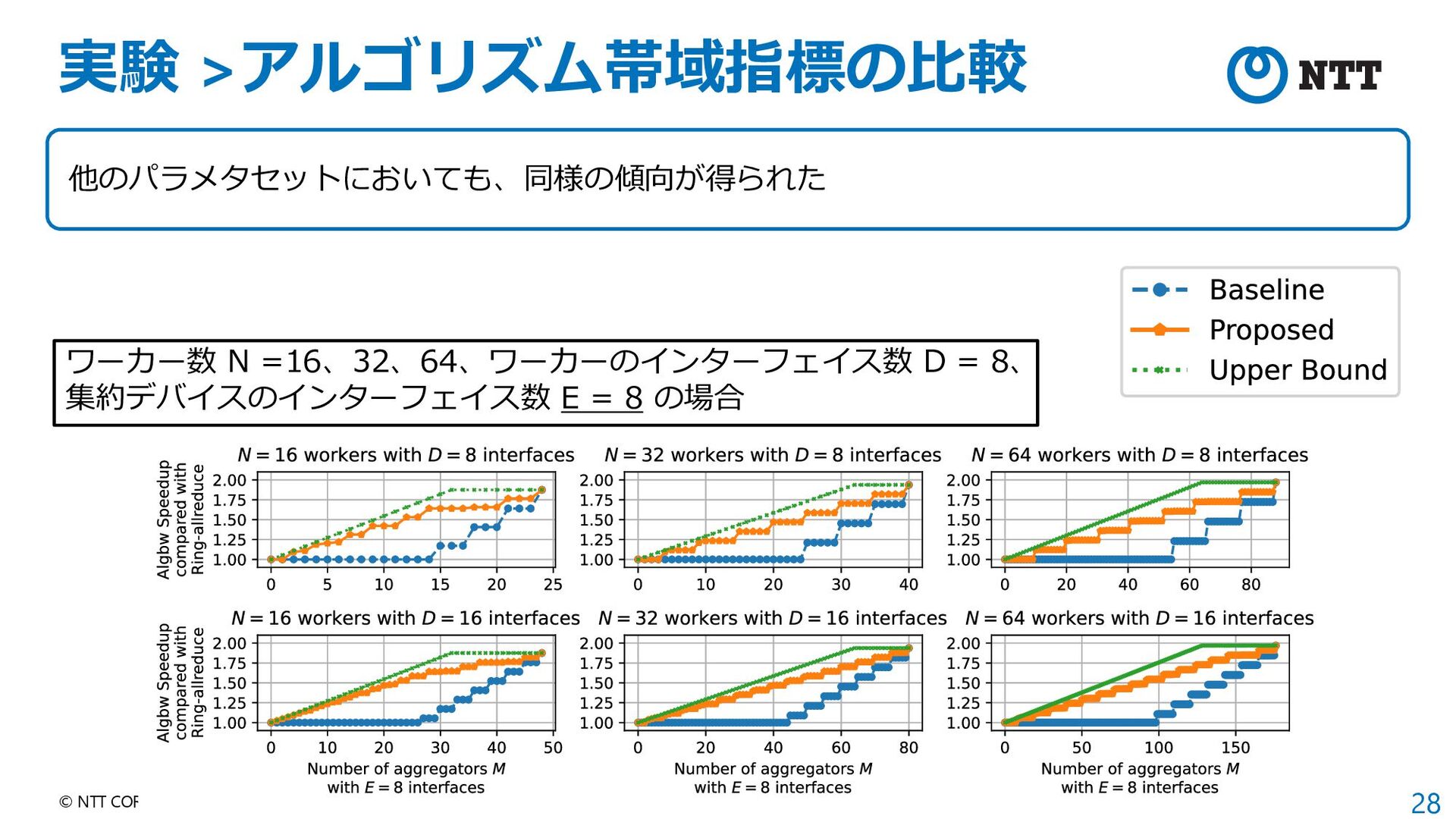{kind=link}
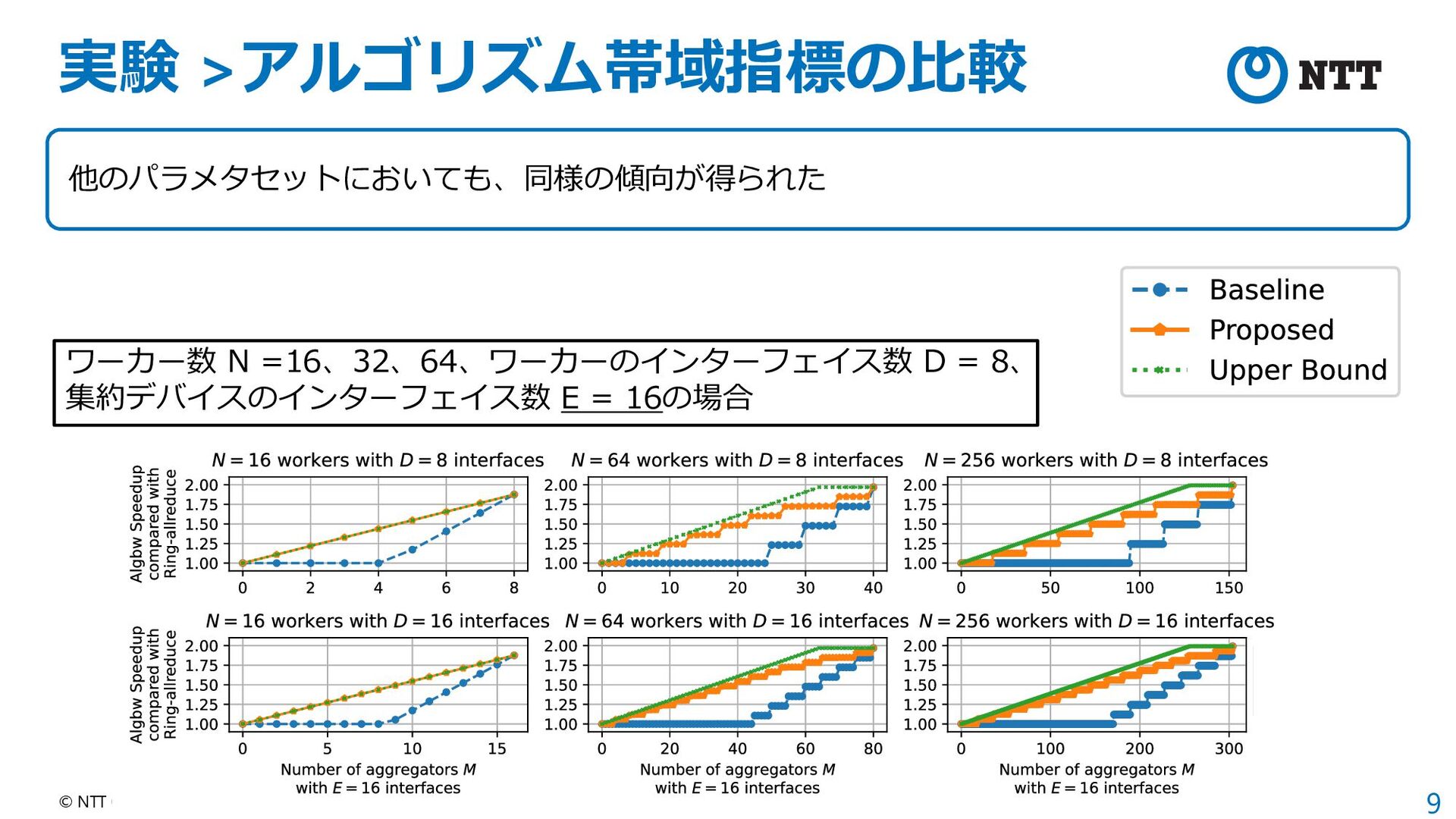{kind=link}
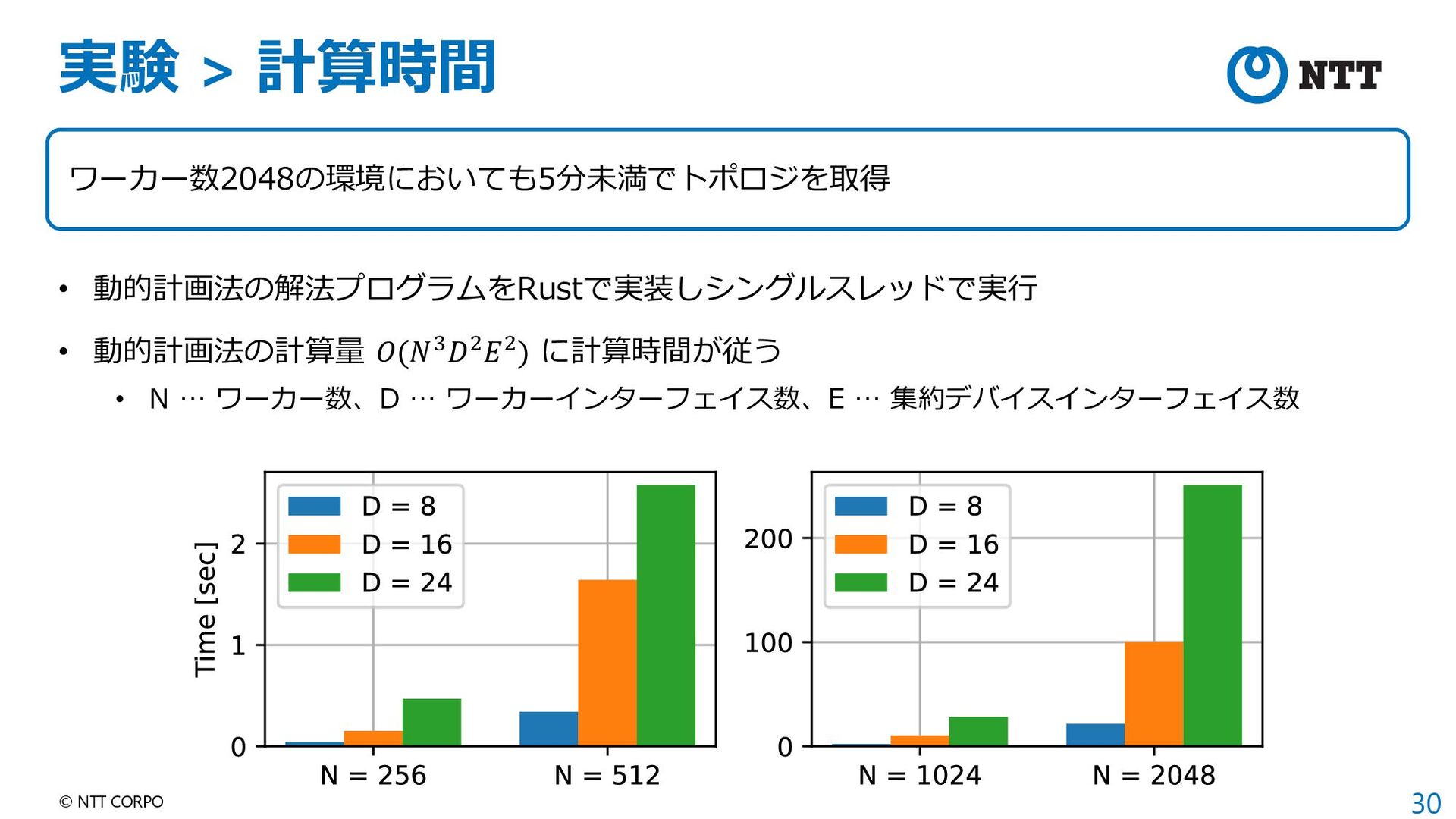{kind=link}
{kind=link}