の関連度を、ある関数 を用いて と表す。( 関 数 は と の関連度が高いほど正に大きい値を取るような関数であれば何で も良い) そして、 と正規化する 。このとき をquery と関連の高い特徴量とみなし、これを出力する。 {z } i z i q r r = i r(z , q) i r z i q (a , ..., a ) = 1 N softmax(r , ..., r ) 1 N 1 F = a z ∑ i i 1: softmax によって と変換される。このとき かつ をみたす。また のとき で あり変換前の大小関係を保つ。 a = i r /( e ) i ∑ r i a = ∑ i 1 a ≥ i 0 r ≥ i r j a ≥ i a j 3
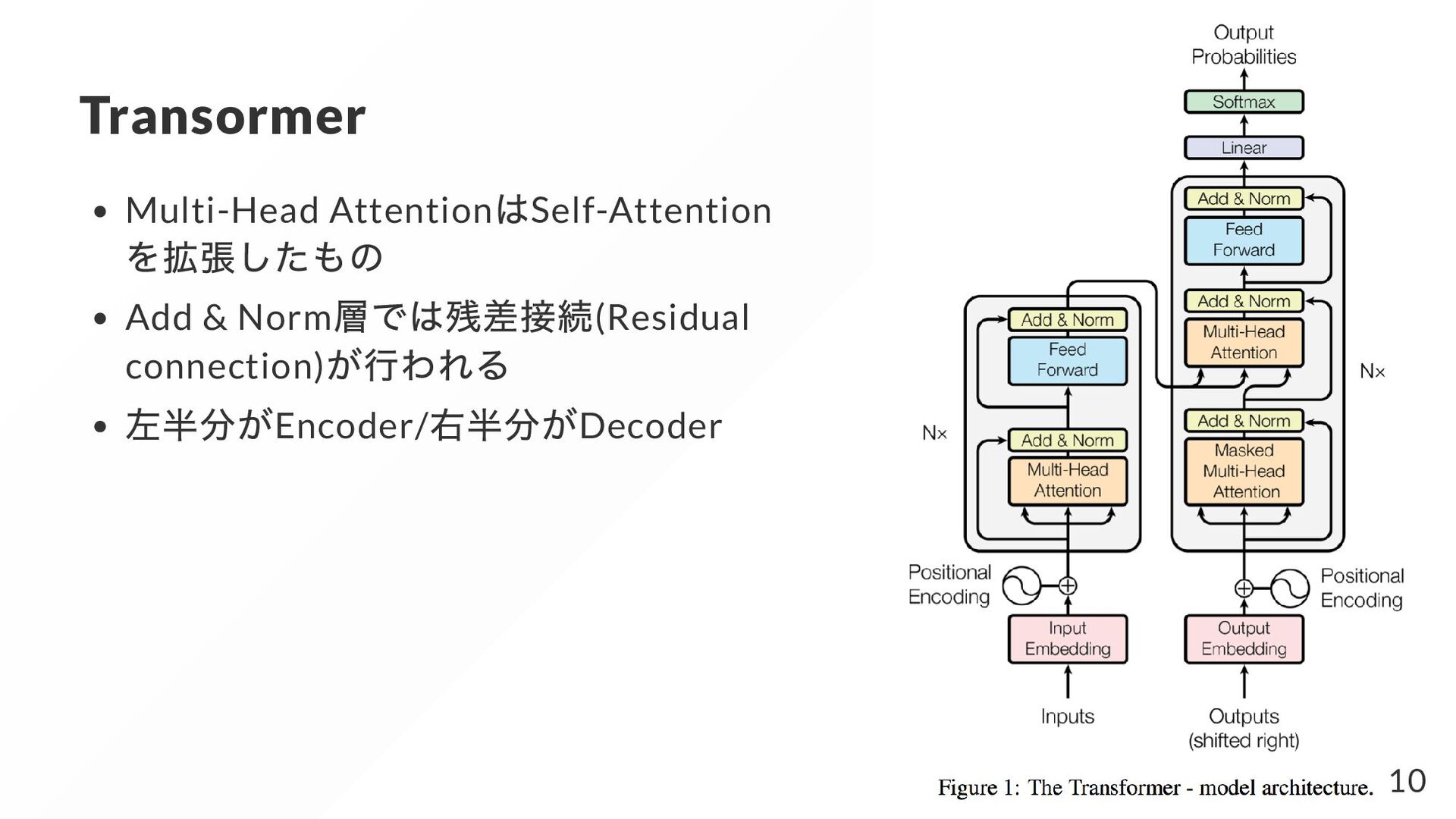
これを用いてquery に必要な処理を行う( モデルの入力にするとか) と精度が 良くなることが期待される! a i z i F = a z ∑ i i z i 特徴量 をsource, query をtarget と呼び、上記の計算手続きをsource-to-target attention と呼ぶ。特にsource とtarget が同じ 場合はself-attention と呼ぶ。 z i 4
→ 一般的に、単語a の埋め込みベクトル と単語b の埋め込みベクトル が類 似しているならばその内積 は大きく、そうでないならば小さくなる z a z b ⟨v , v ⟩ a n 1 1: これは多少乱暴な言い方で、なぜなら内積は二つのベクトルの方向とその大きさ( ノルム) によって値が決まるから( すなわちベ クトル空間上で近くになくても、どちらかのベクトルノルムが大きければ内積は大きくなり得る。。。) 。しかし、少なくとも その正負をみれば大雑把に類似しているか否かの判定はできる( はず) 。 6
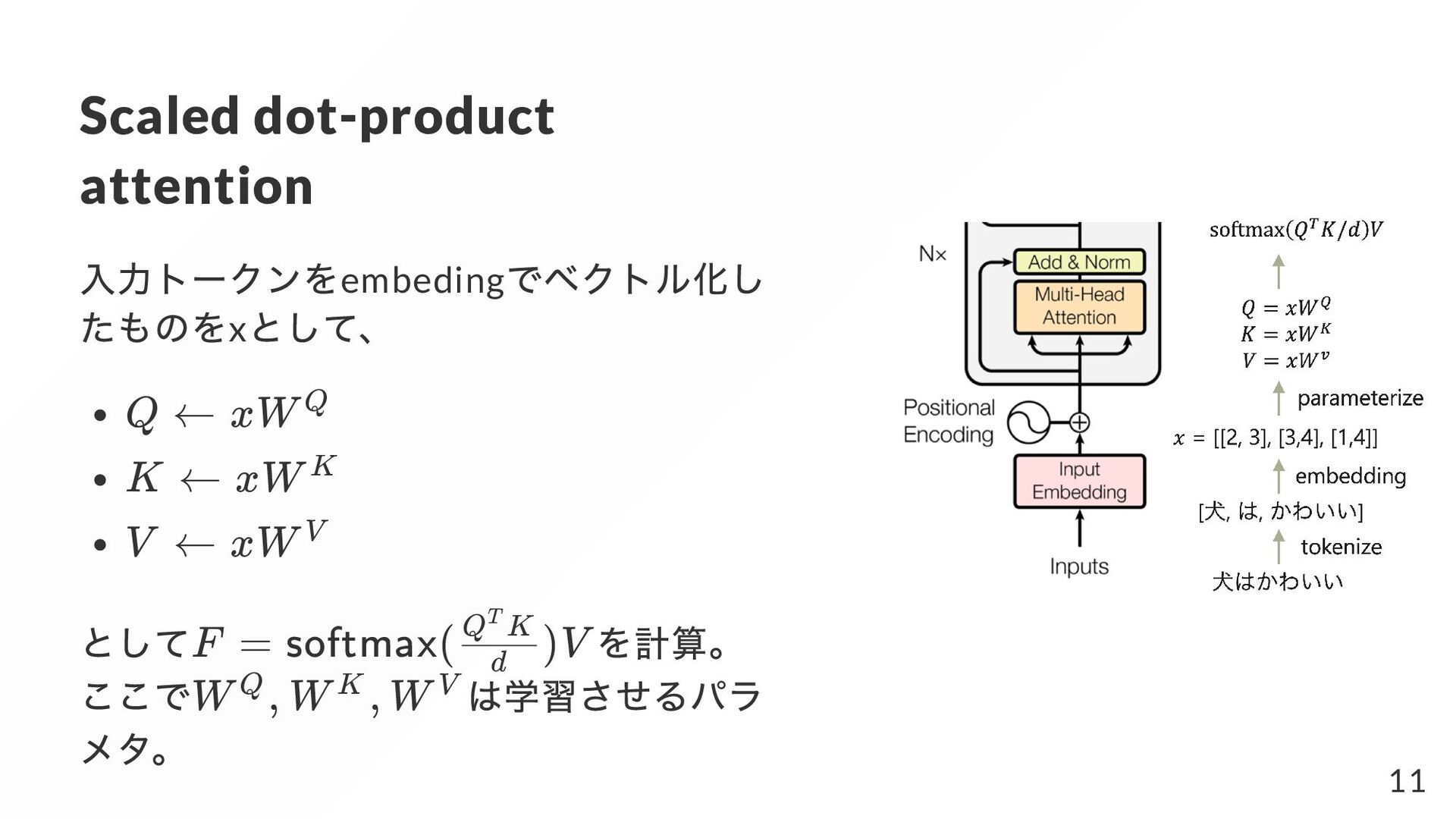
すなわち ) また、関連度関数 を内積 とする 。ここで 。 するとquery に対する特徴量は これはTransformer の文脈でscaled dot-product attention と呼ばれる。 z i q i i n z = i q i r(z , q ) i j ⟨z , q ⟩/d i j 1 d = n q j F = j a z = ∑ i i softmax( )Z d q Z j T 2 1: つまりこれはi 番目の単語とj 番目の単語の類似度を計算している 2: は列 ベクトルを行方向にまとめた行列 Z z i 7
番目の単語 の特徴ベクトル( 次元) とする。 ここでのkey-value の名称について一考。 マップ構造(python のdict やc++ のmap など) ではkey に対応するvalue を取り出 すが、それと同様にquery に対する重要度をkey で計算し、その重みに応じた 対応するvalue で特徴量を算出する? 感じ。 k , q , v i i i i n F = j softmax( )V d q K j T 8
{kind=link}
![Attention " 複数の要素からなる集合に対し、今持っている関心(query) に応じた重要度に 従って、各要素を重み付けすること。" [1, Chapter7.2] 。 集合とは、( ある規則からなる)"](https://files.speakerdeck.com/presentations/f38f7c74196c46df937073d957e14b7a/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![最終層 それぞれのベクトルの次元を埋 め込み次元から語彙数次元まで 拡げる 例えば、x[i][j] を文頭からi 番目 の単語がID j である確率 とみ](https://files.speakerdeck.com/presentations/f38f7c74196c46df937073d957e14b7a/slide_11.jpg){kind=link}