Servey: Alpa: Automating Inter- and Intra- Operator Parallelism for Distributed Deep Learning
servey of Zheng, Lianmin, et al. "Alpa: Automating Inter-and Intra-Operator Parallelism for Distributed Deep Learning." arXiv preprint arXiv:2201.12023 (2022).
machine learning. In 2019 IEEE 39th International Con ference on Distributed Computing Systems (ICDCS), pages 2057–2067. IEEE, 2019. [31] Dmitry Lepikhin, et al. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020. [17] Shiqing Fan, et al. Dapple: A pipelined data parallel approach for training large models. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 431–445, 2021. [38] Deepak Narayanan, et al. Pipedream: generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, pages 1–15, 2019. [55] Minjie Wang, et al. Supporting very large models using automatic dataflow graph partitioning. In Proceedings of the Fourteenth EuroSys Conference 2019, pages 1–17, 2019. 8
mesh 1: ("PipeDream: generalized pipeline parallelism for DNN training.", "Automatic graph partitioning for very large-scale deep learning.") 2: 4 XPU Stage M 2 mesh 10
(2022): arXiv-2211. [17] Dapple: A pipelined data parallel approach for training large models, 2021. [38] Pipedream: generalized pipeline parallelism for dnn training, 2019. [55] Supporting very large models using automatic dataflow graph partitioning, 2019. 17
{kind=link}
{kind=link}
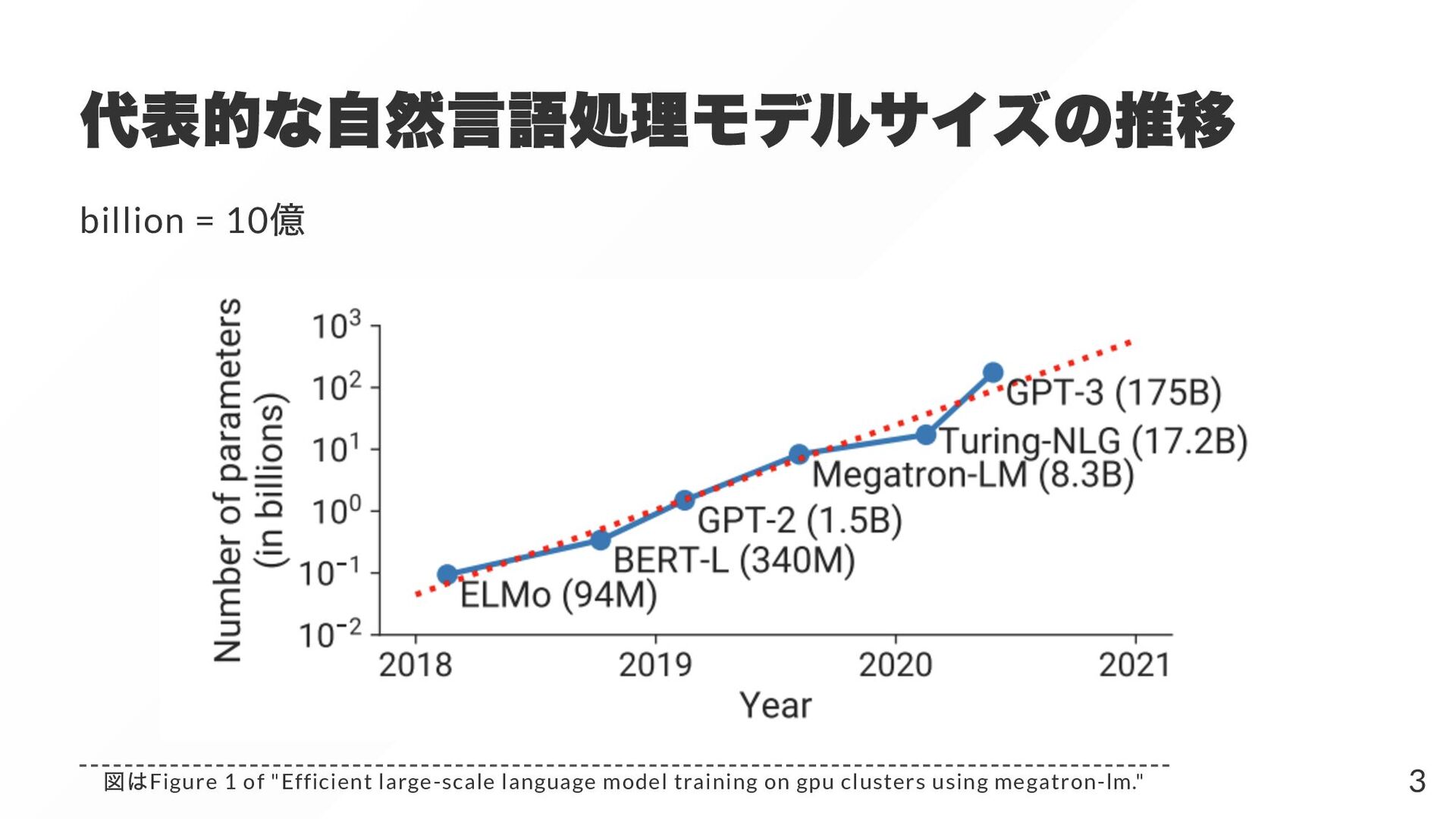{kind=link}
{kind=link}
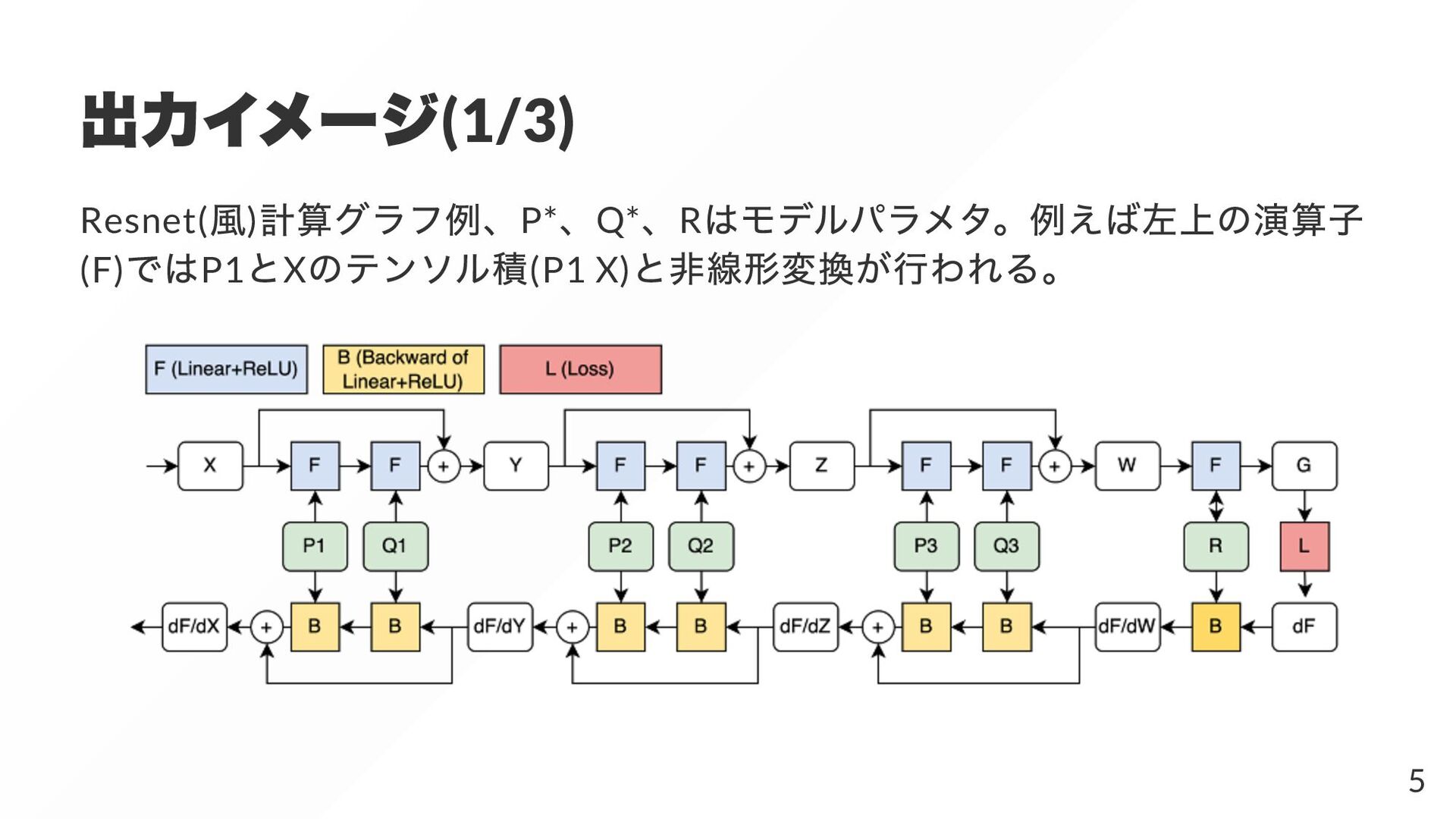{kind=link}
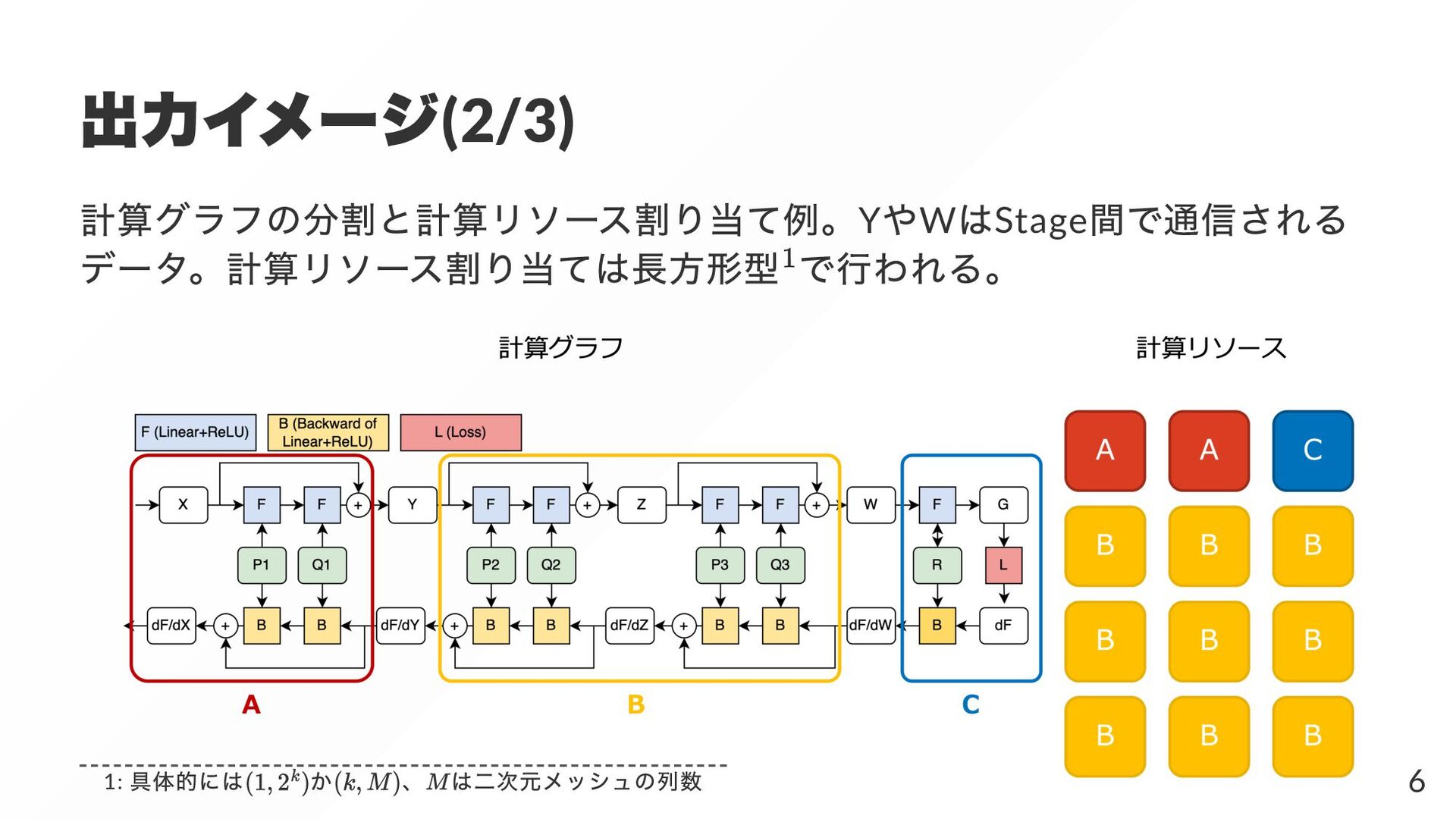{kind=link}
{kind=link}
![[30] Woo-Yeon Lee, et al. Automating system configuration of distributed](https://files.speakerdeck.com/presentations/5e50f88886d6438794626ee8db4ec2b1/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
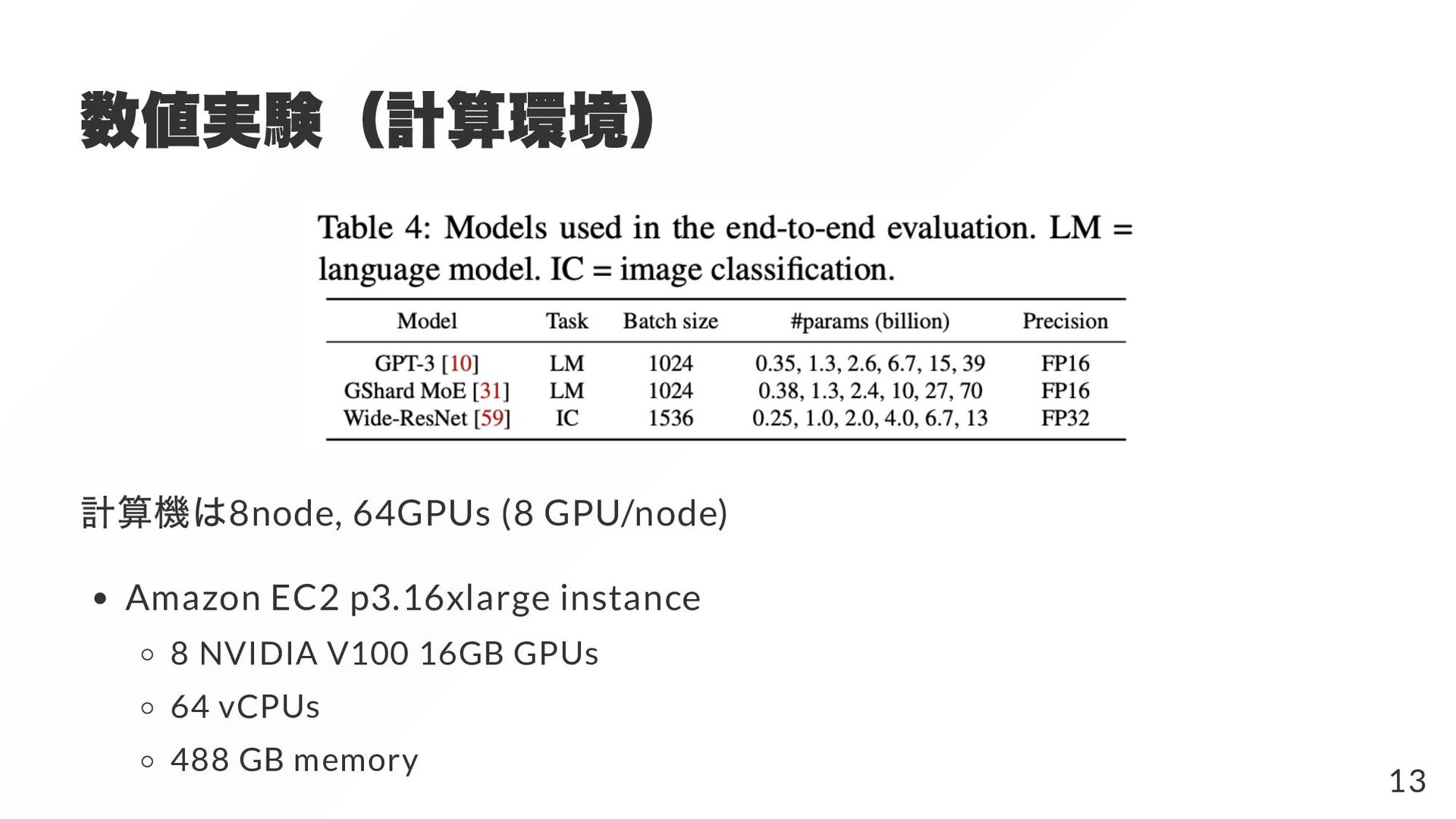{kind=link}
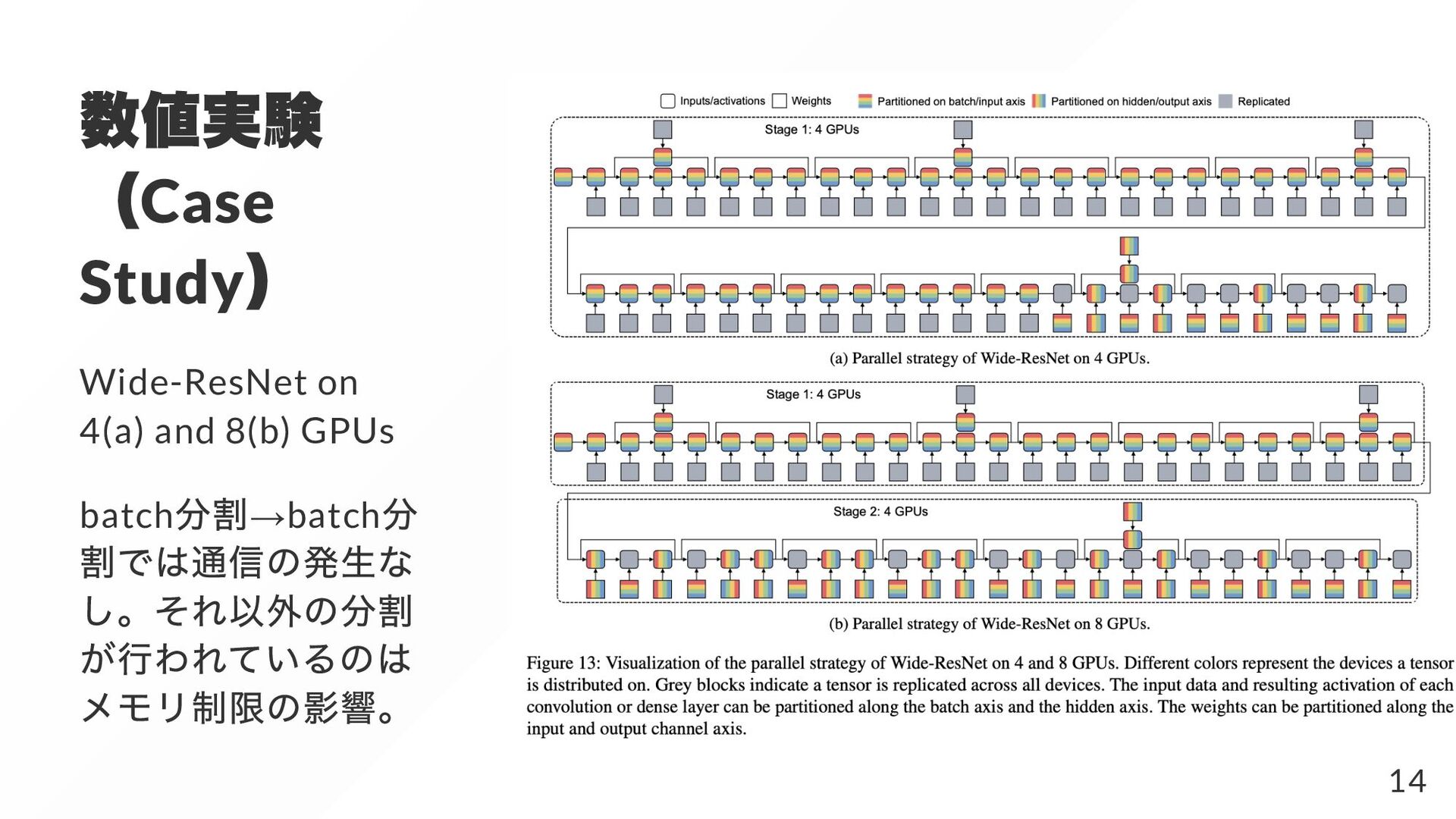{kind=link}
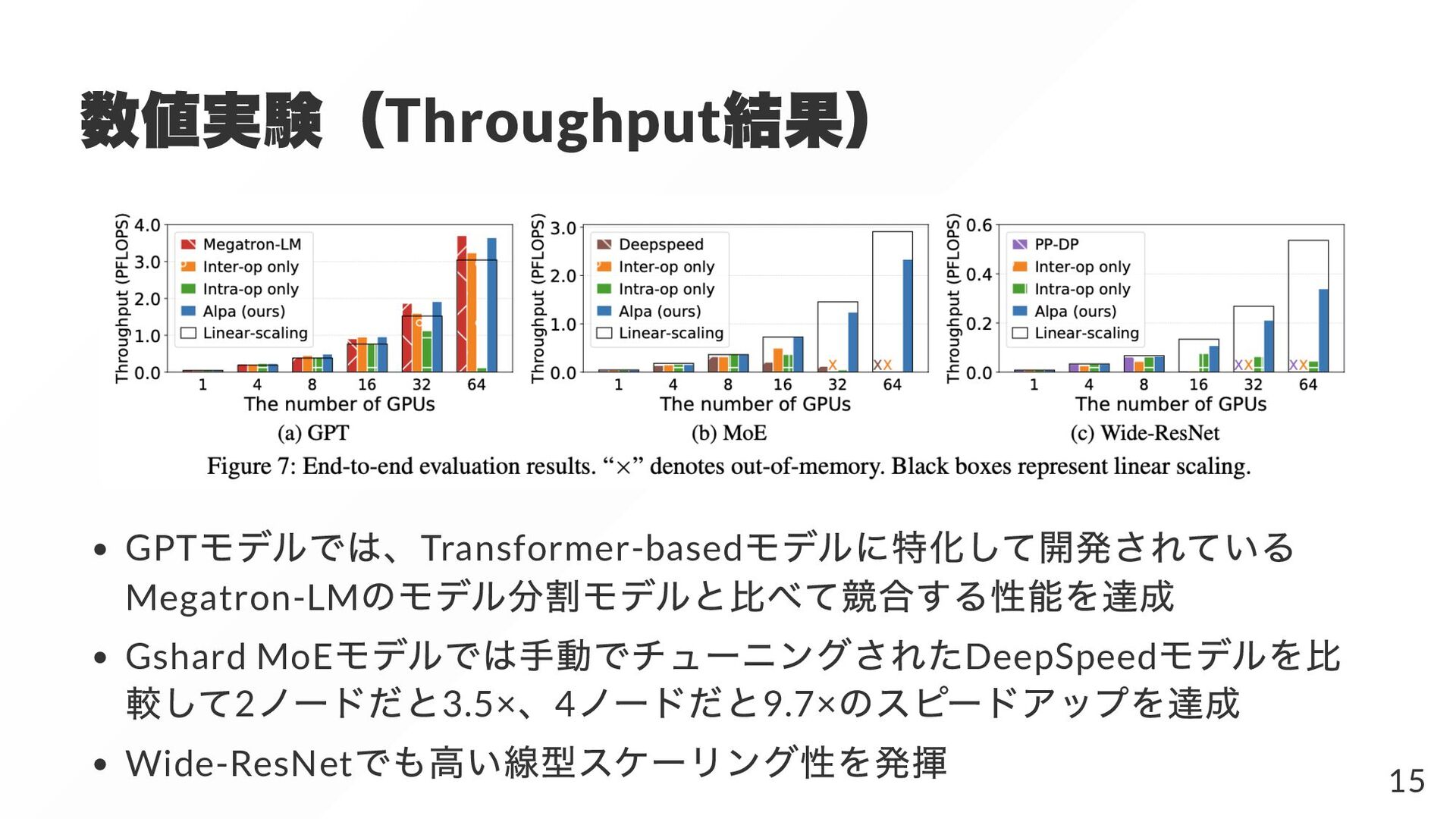{kind=link}
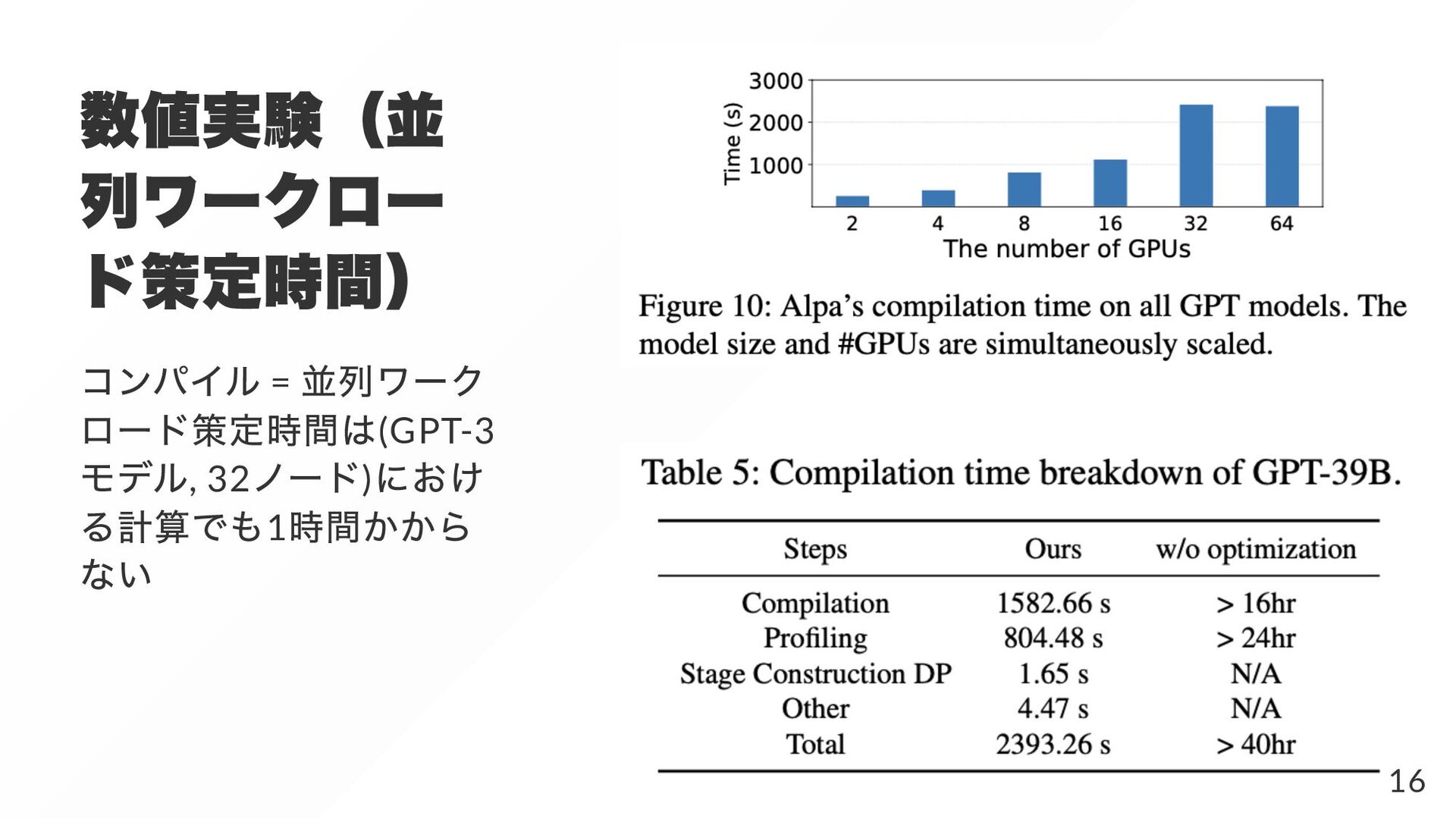{kind=link}
{kind=link}
{kind=link}
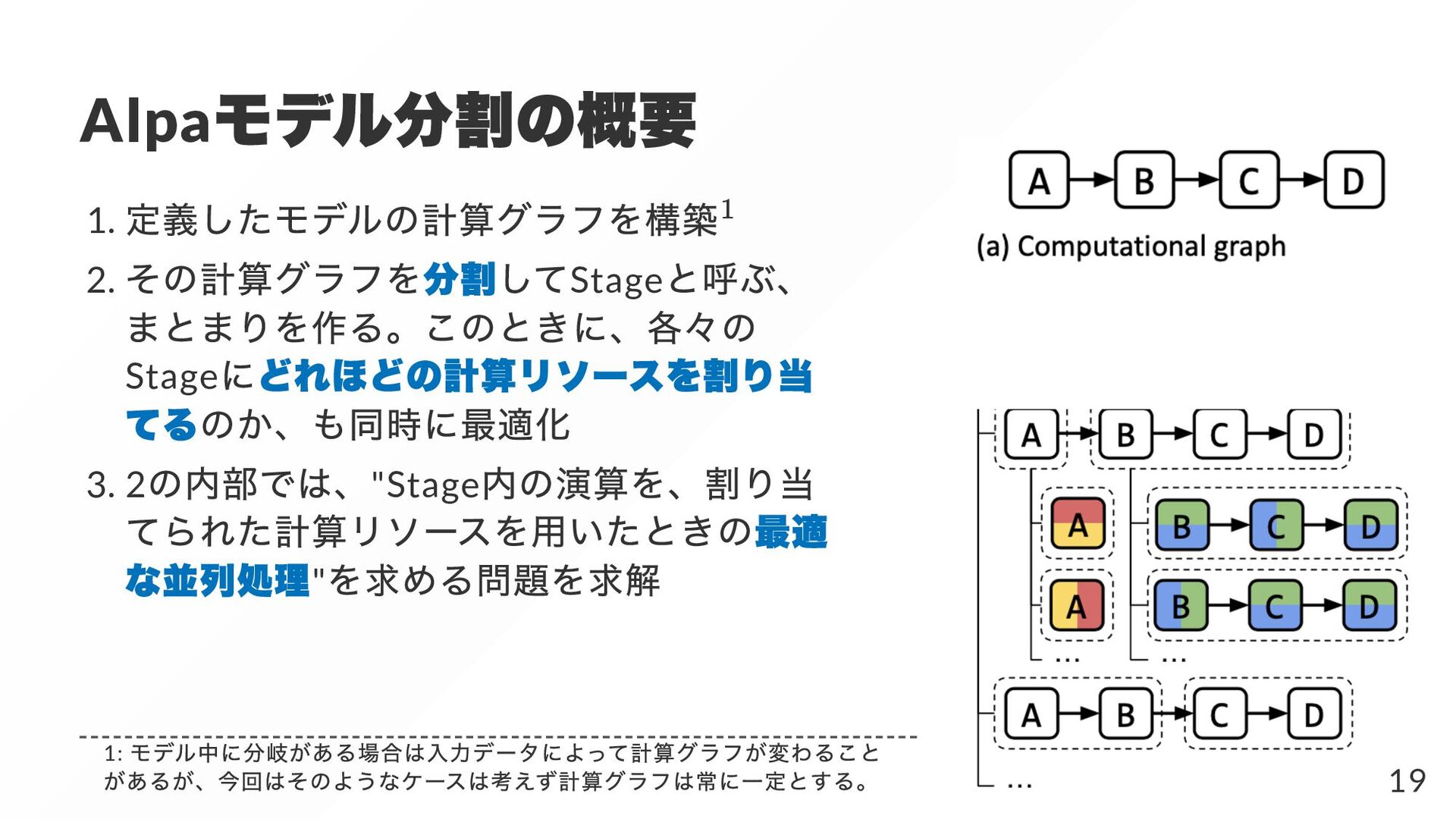{kind=link}
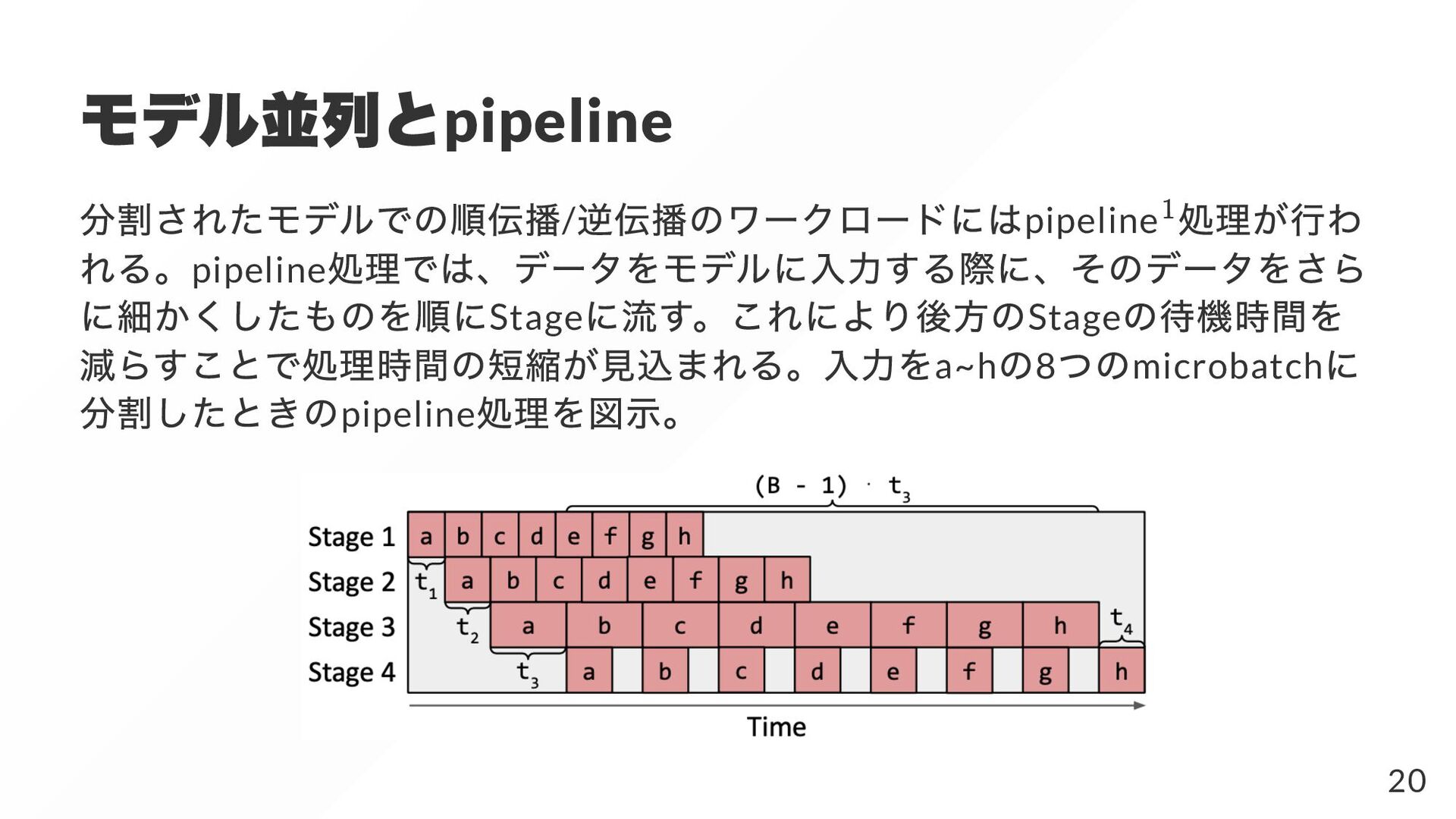{kind=link}
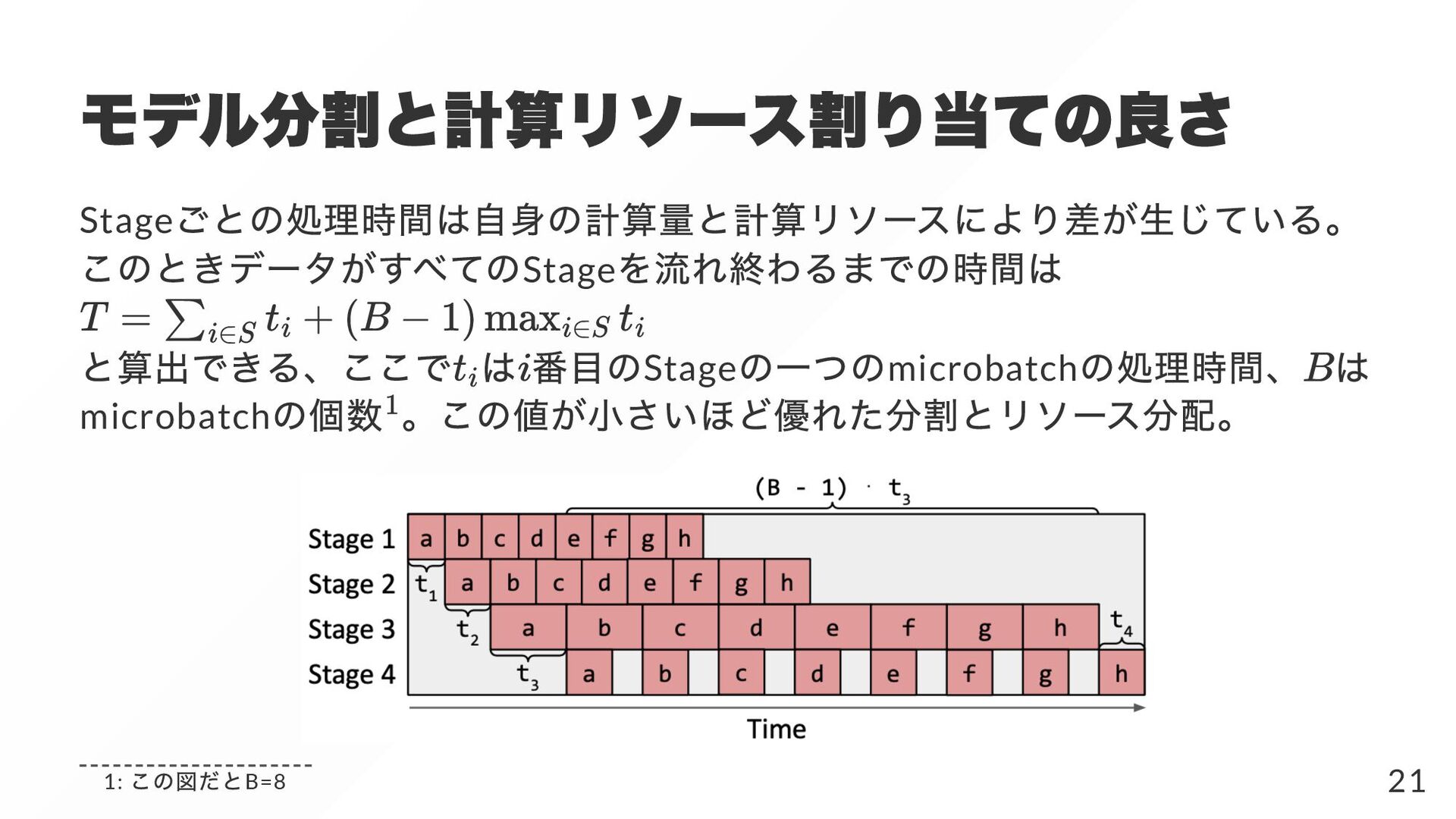{kind=link}
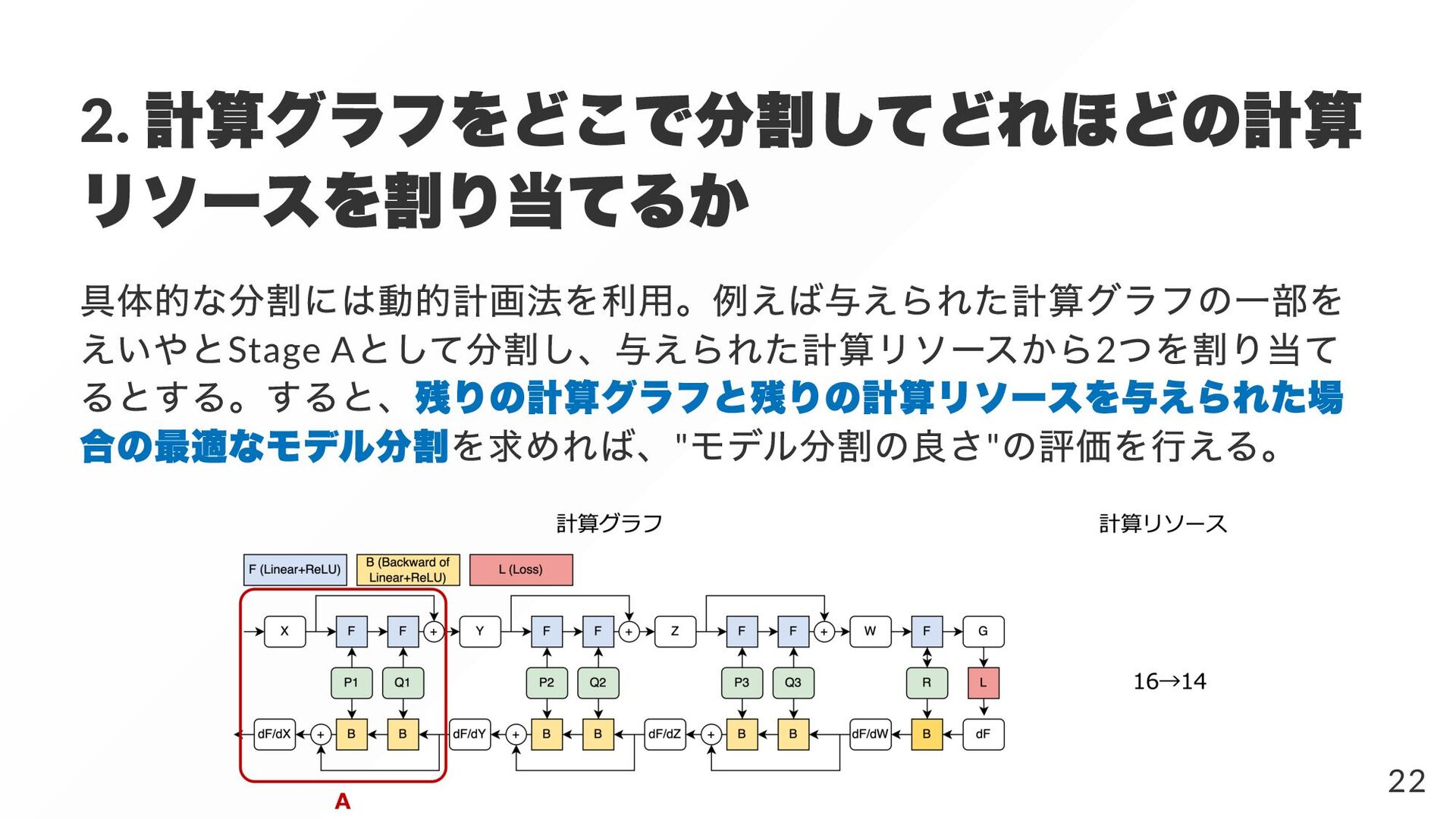{kind=link}
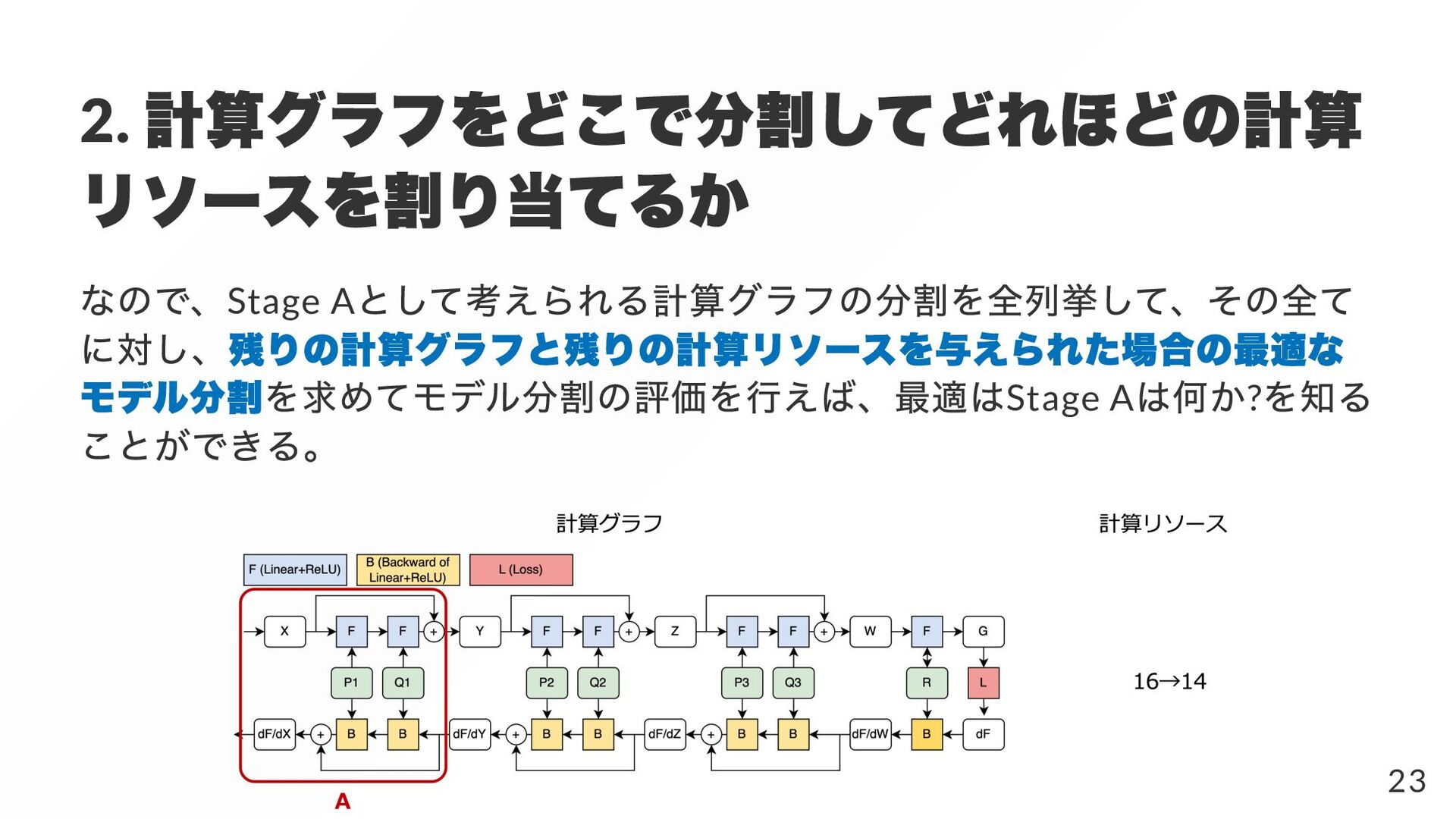{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
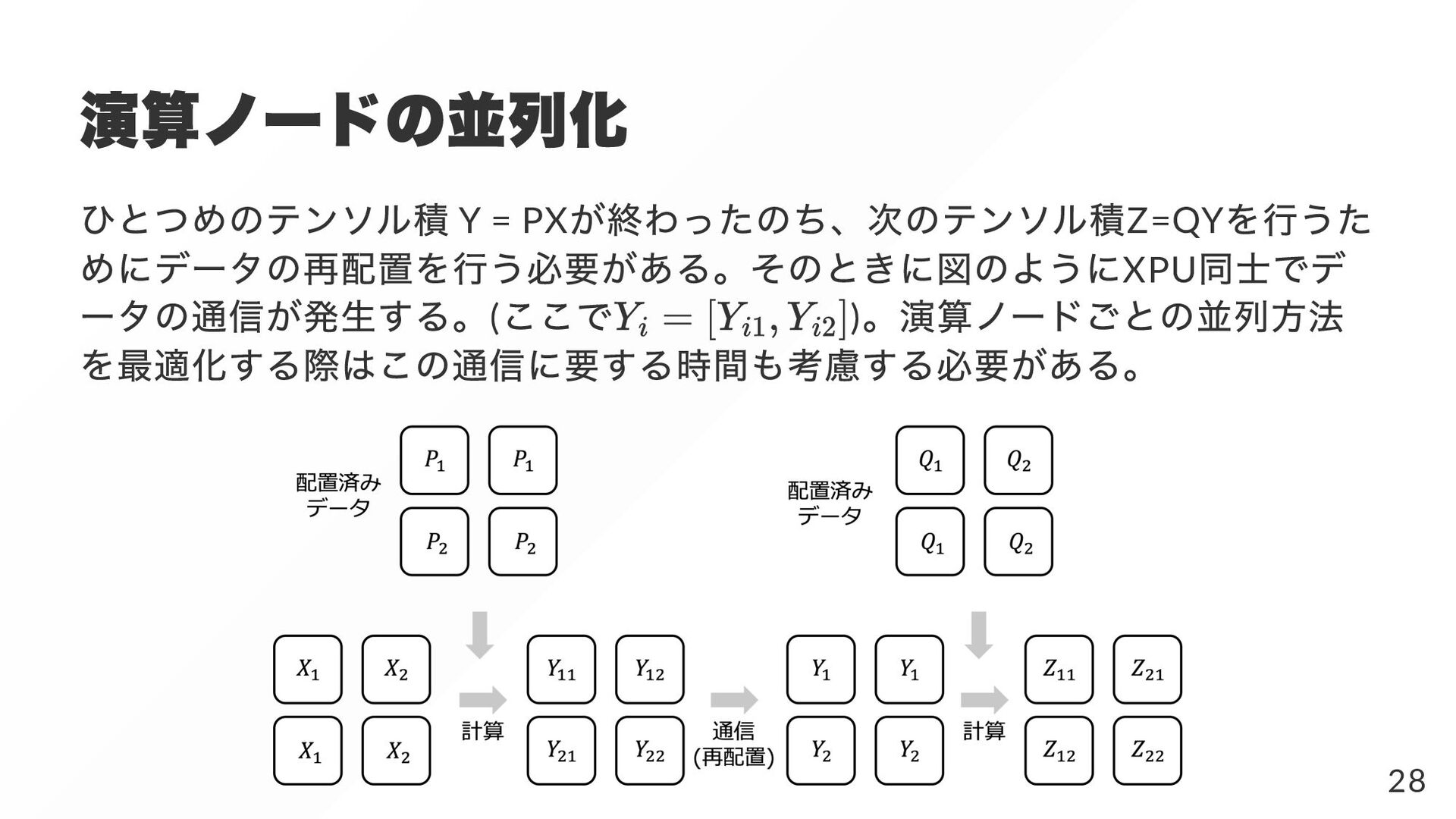{kind=link}
{kind=link}
{kind=link}
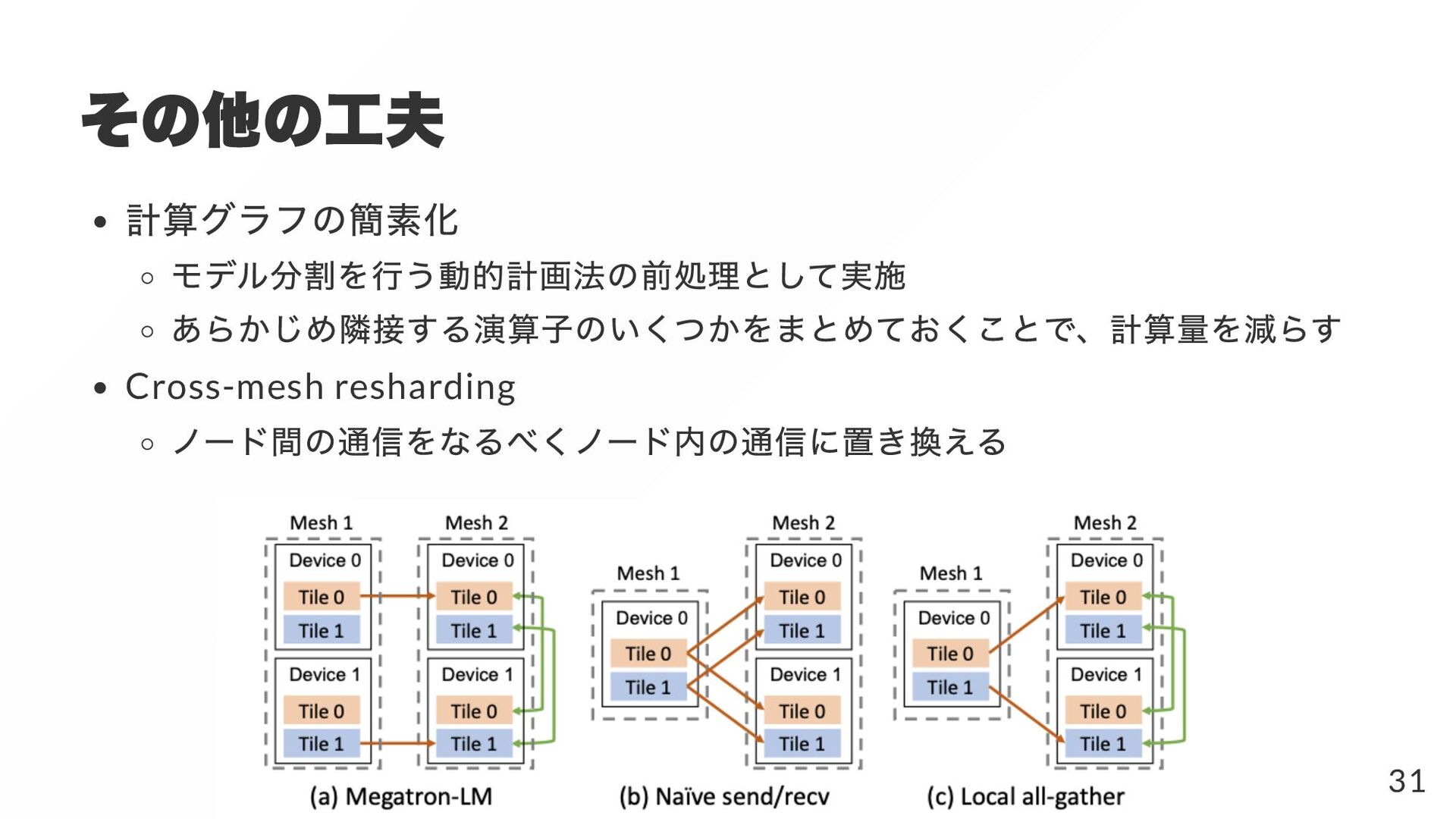{kind=link}