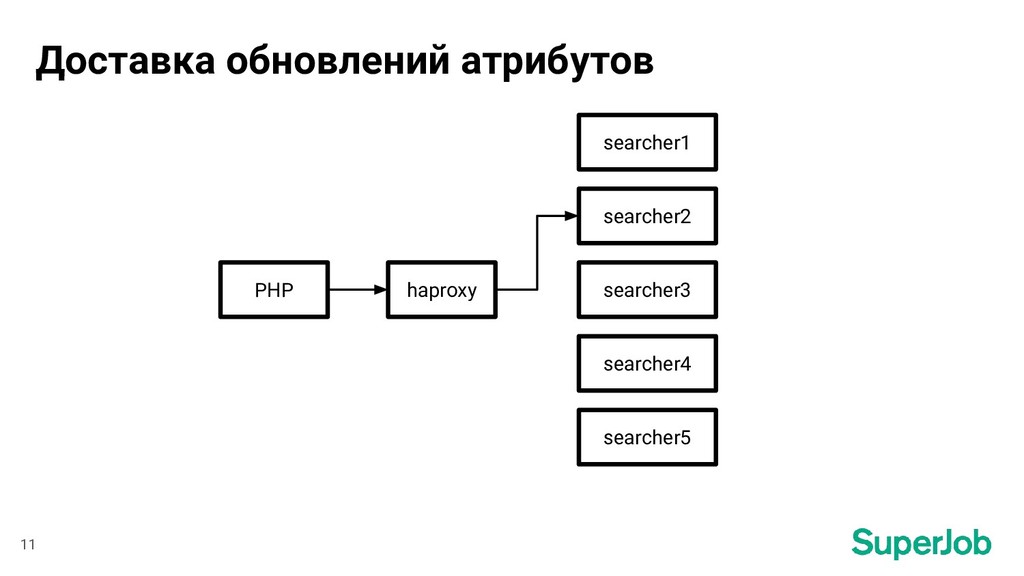
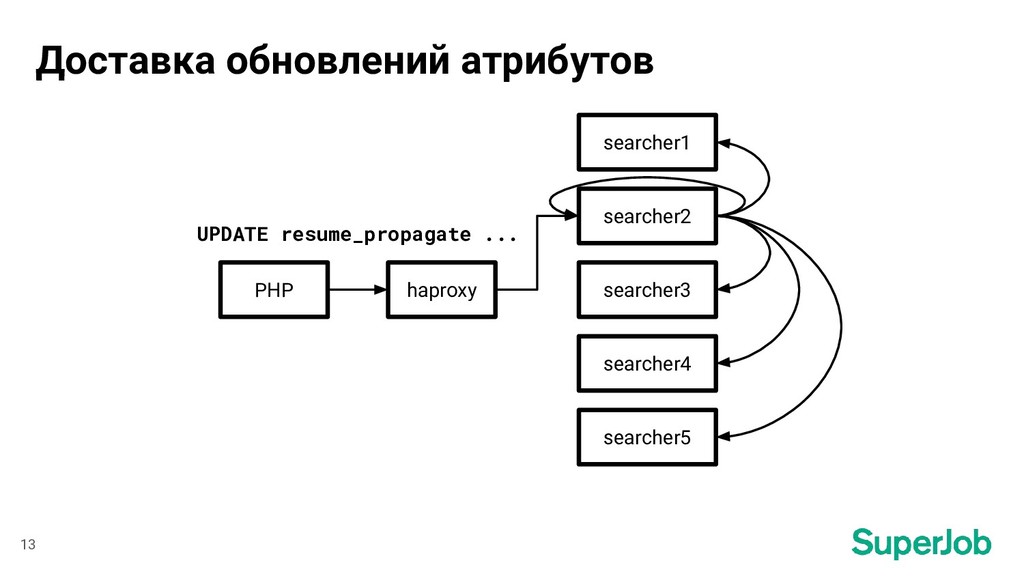
Как и зачем мы пришли от регулярного перестроения индексов для полнотекстового поиска и отправки обновлений в коде «по месту» к realtime-индексам и автоматической синхронизации состояния индекса и базы данных MariaDB.
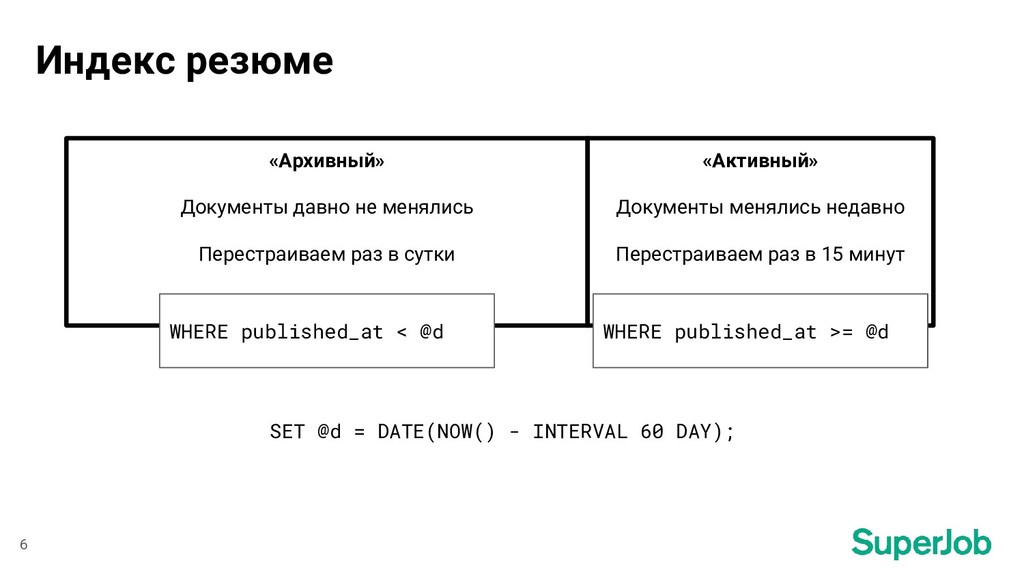
сутки «Активный» Документы менялись недавно Перестраиваем раз в 15 минут 6 WHERE published_at < @d SET @d = DATE(NOW() - INTERVAL 60 DAY); WHERE published_at >= @d
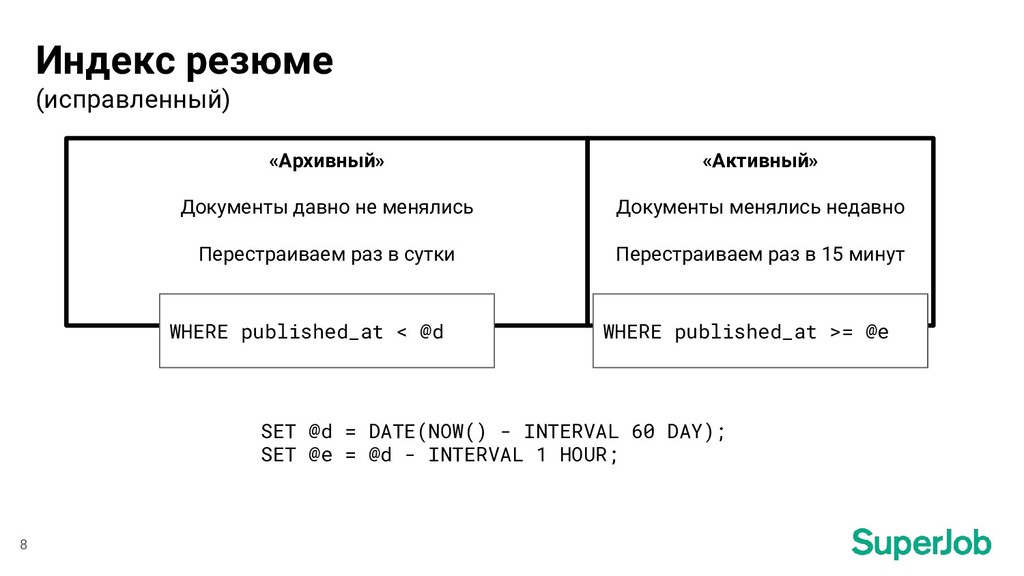
раз в сутки «Активный» Документы менялись недавно Перестраиваем раз в 15 минут WHERE published_at < @d SET @d = DATE(NOW() - INTERVAL 60 DAY); SET @e = @d - INTERVAL 1 HOUR; WHERE published_at >= @e
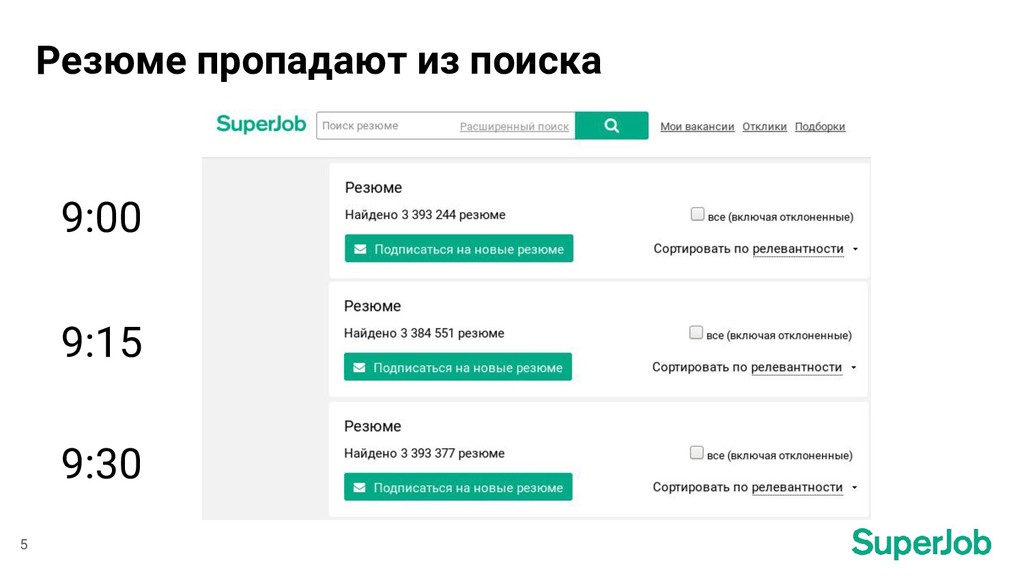
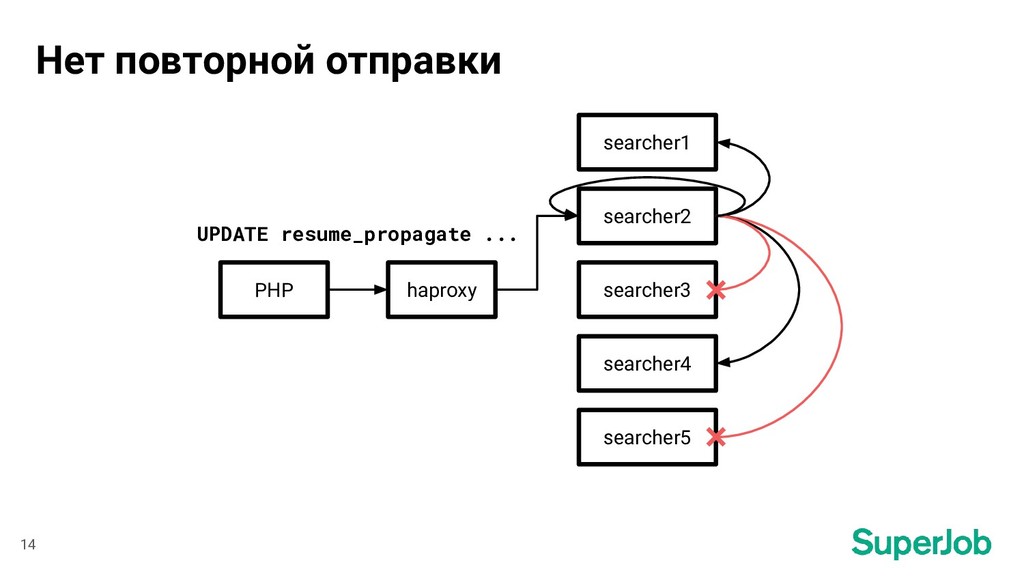
медленно 2. Сложности с синхронизацией MySQL - Sphinx • Резюме иногда пропадают из поиска • Резюме перенесли в закрытый доступ, а оно все равно показывается в поиске
= 0 WHERE id = ?; UPDATE resume_archive SET published = 0 WHERE id = ?; SELECT id, WEIGHT() FROM resume_archive,resume_active WHERE ... AND published = 1
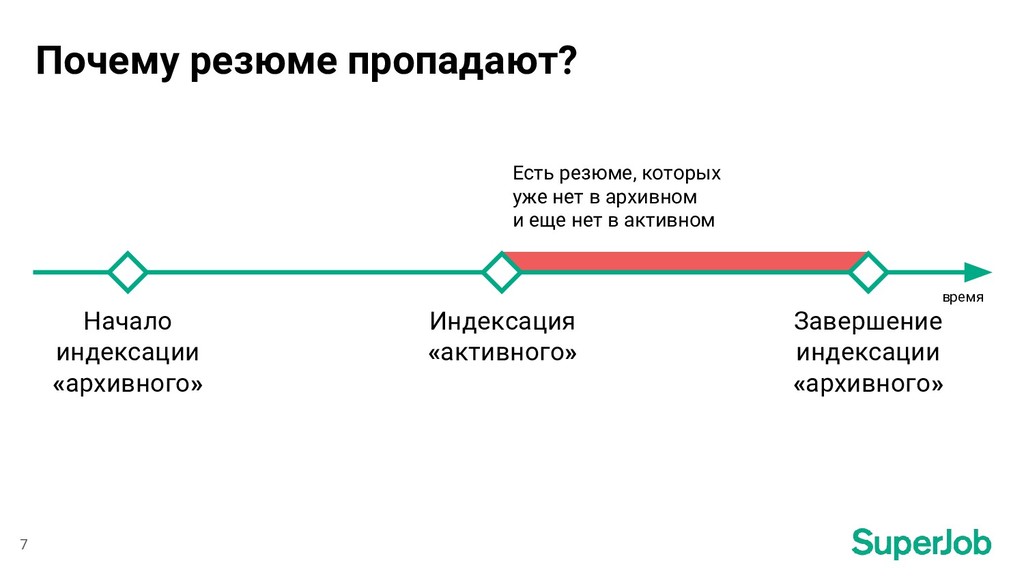
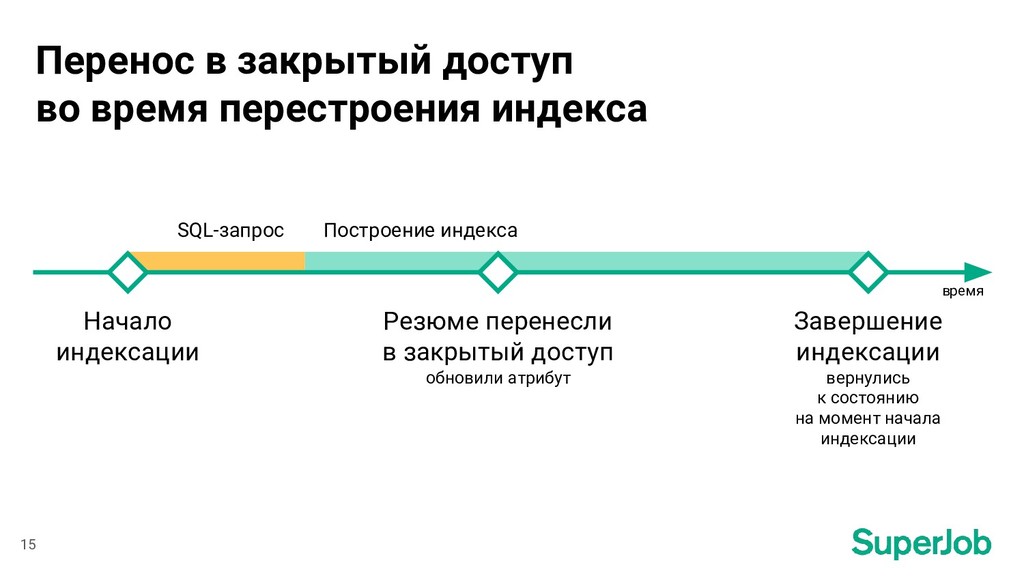
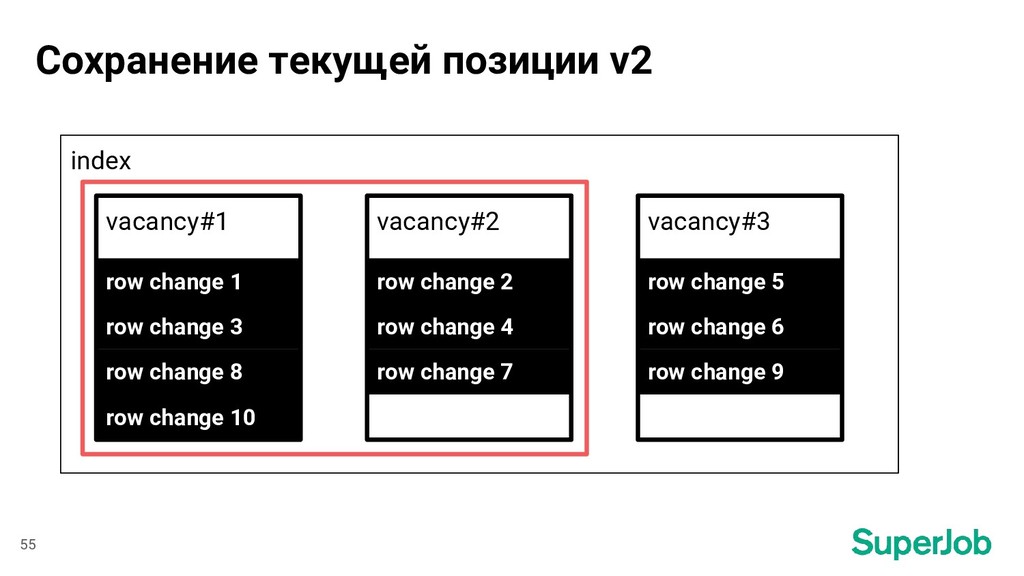
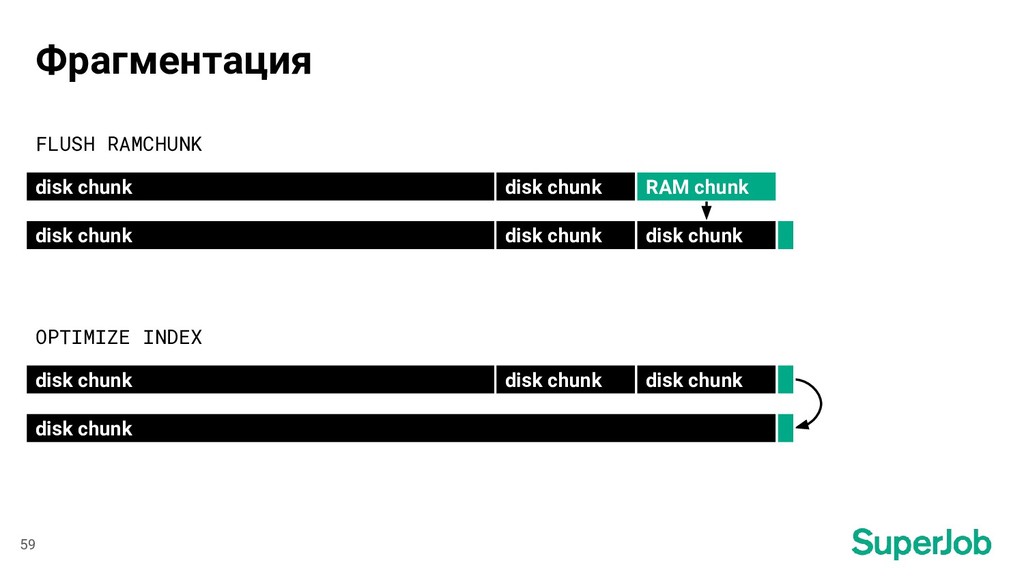
индексации Завершение индексации вернулись к состоянию на момент начала индексации Резюме перенесли в закрытый доступ обновили атрибут SQL-запрос Построение индекса время
медленно 2. Сложности с синхронизацией MySQL - Sphinx • Резюме иногда пропадают из поиска • Резюме перенесли в закрытый доступ, а оно все равно показывается в поиске 3. End-to-end тесты с участием поиска
синхронизацию базы данных и индекса • Предотвратить ошибки • Сделать так, чтобы для тестов не надо было перестраивать индекс 19 Надо что-то менять, но что мы хотим?
Единый канал передачи изменений между MariaDB и Sphinx - соединение к MariaDB по протоколу репликации • Список изменений, произошедших с момента перестроения индекса - binlog MariaDB
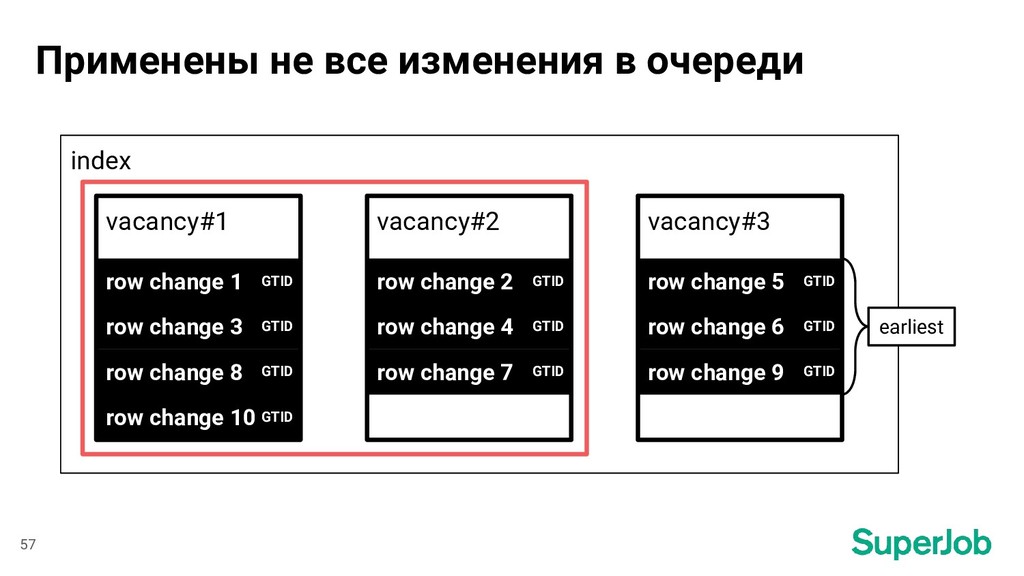
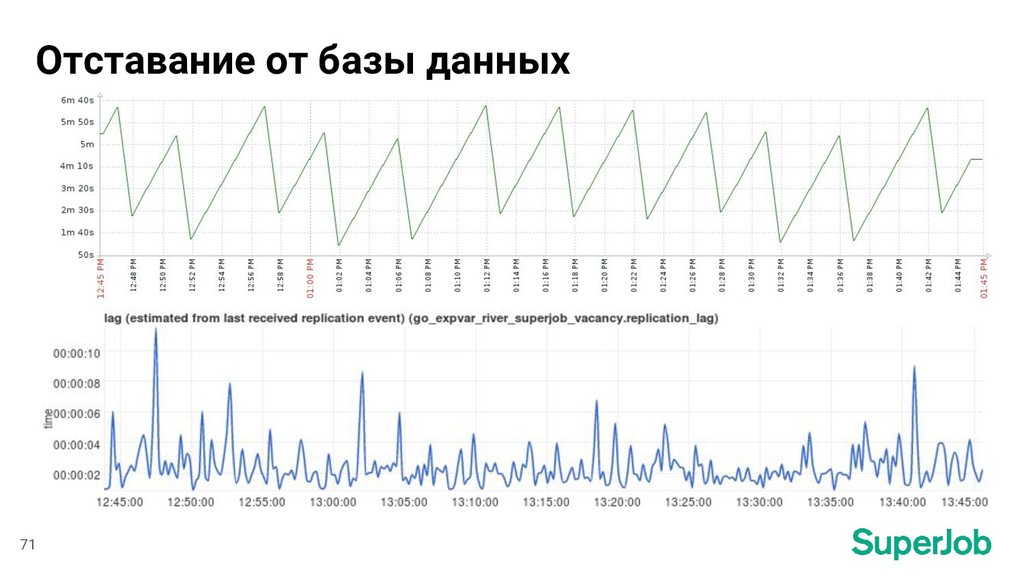
текущей позиции • Выяснение, какие документы нужно обновить в индексе • Запрос недостающих данных из MariaDB • Формирование и выполнение запросов на обновление индекса 23
потенциальных контрибьюторов среди наших разработчиков • Хорошая поддержка конкурентного и параллельного исполнения кода • Отсутствие необходимости управлять памятью 25
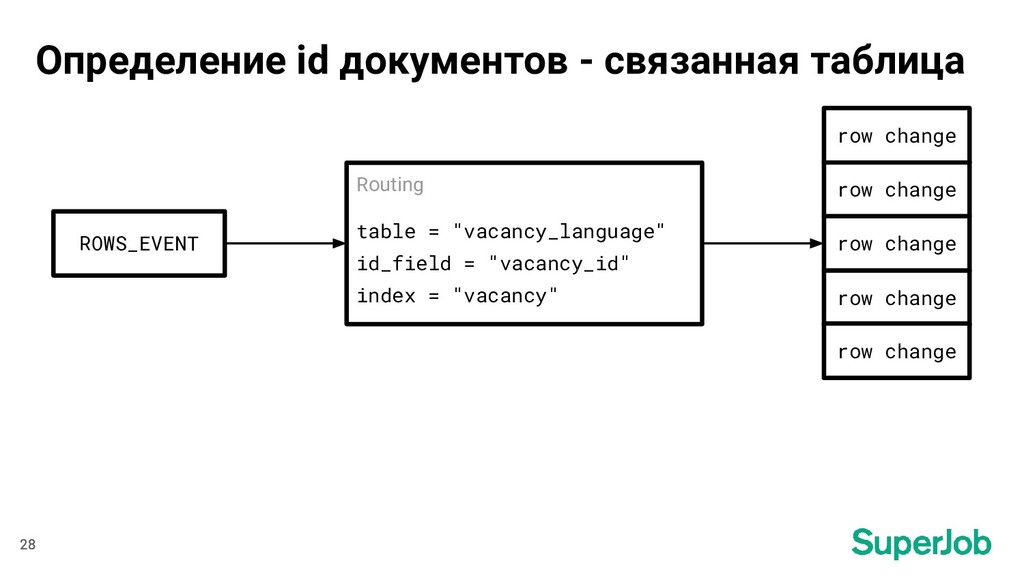
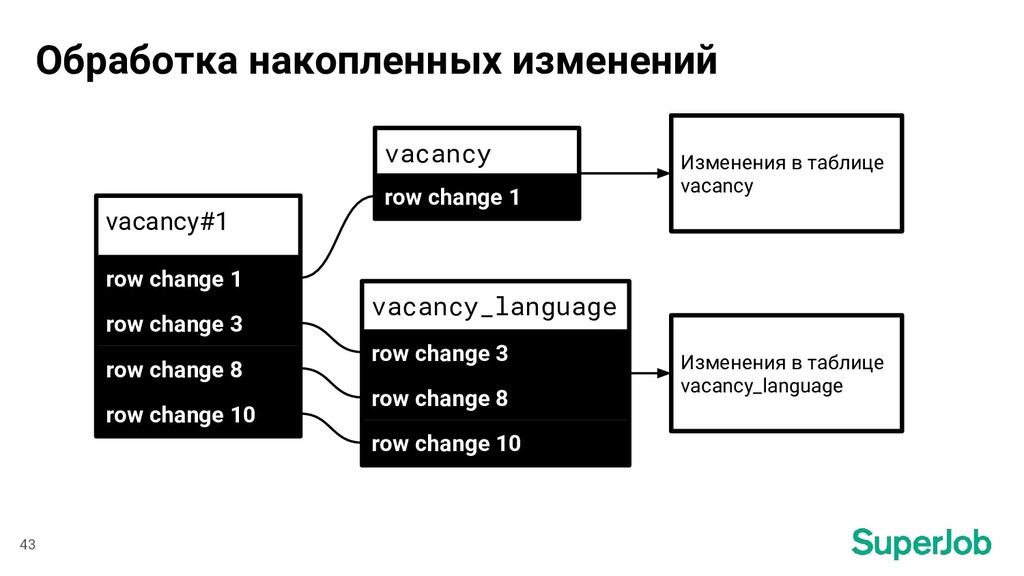
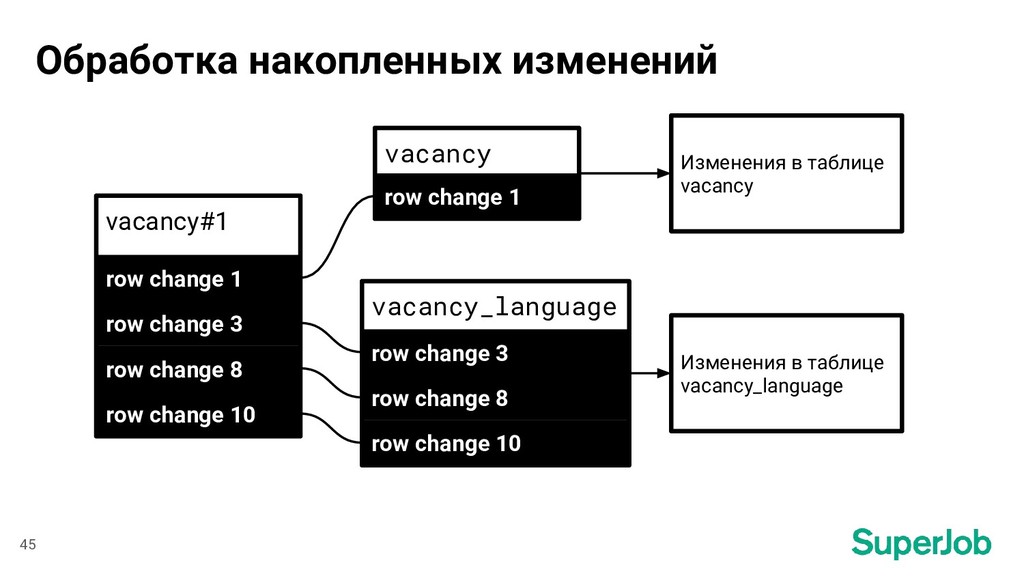
Header *replication.EventHeader ROWS_EVENT Routing table = "vacancy" id_field = "id" index = "vacancy" row change 27 Определение id документов - основная таблица
query = """ SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
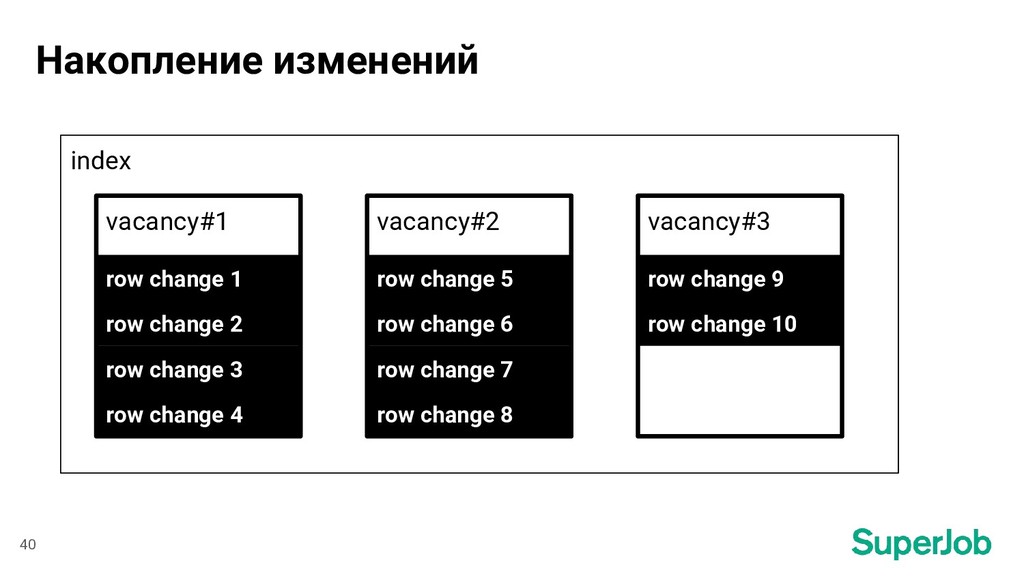
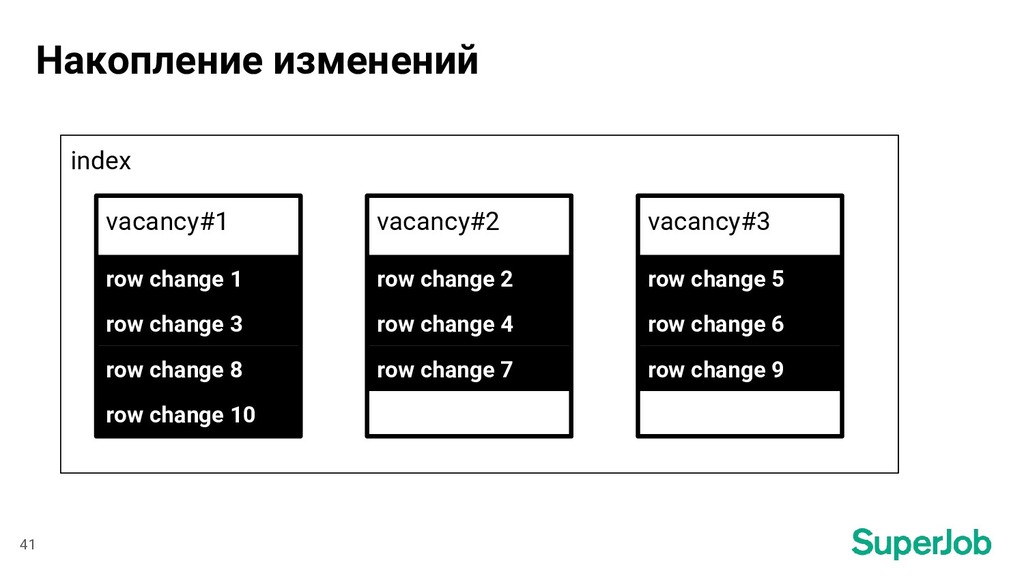
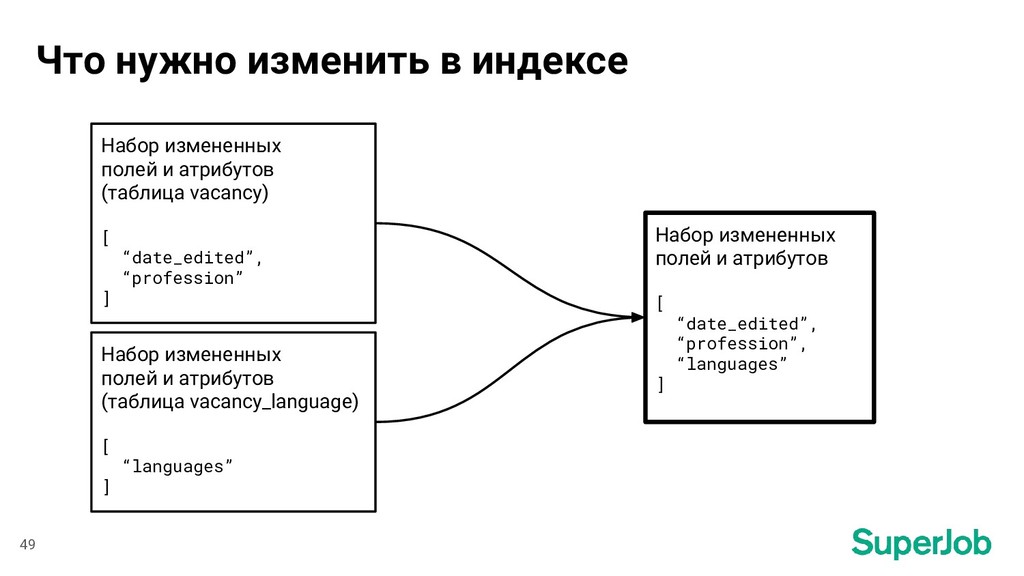
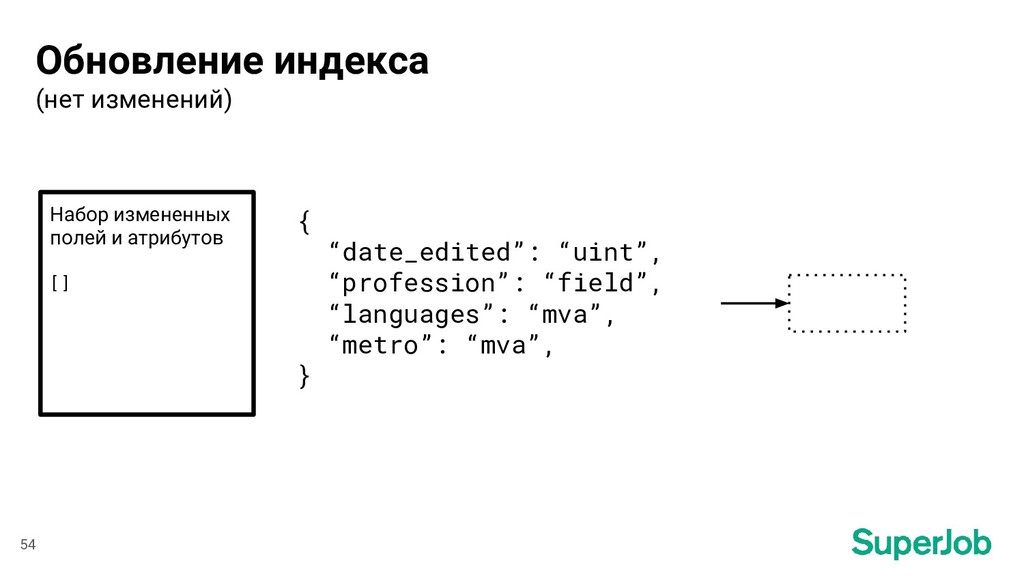
profession = ["profession"] lat = ["lat_deg", "lat_rad"] lon = ["lon_deg", "lon_rad"] ... 47 Поля в БД ⟶ Поля в индексе Изменения в таблице vacancy Набор измененных полей и атрибутов [ “date_edited”, “profession”, ] [ “edited_at”, “profession” ]
= [ "languages" ] 48 Поля в БД ⟶ Поля в индексе Изменения в таблице vacancy_language Набор измененных полей и атрибутов [ “languages” ] [ “language_id”, “level” ]
`:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """ 51 Типы полей в индексе
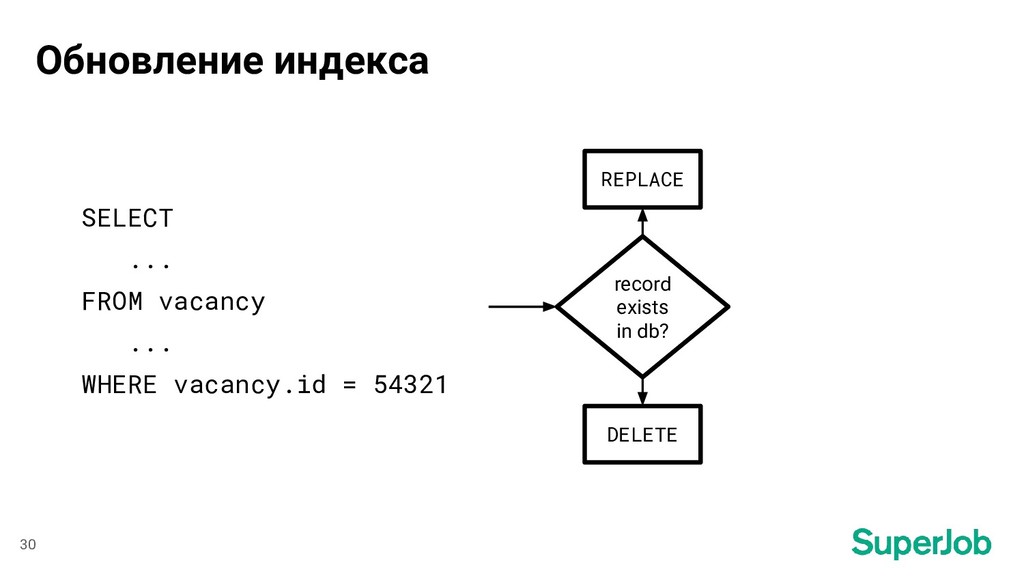
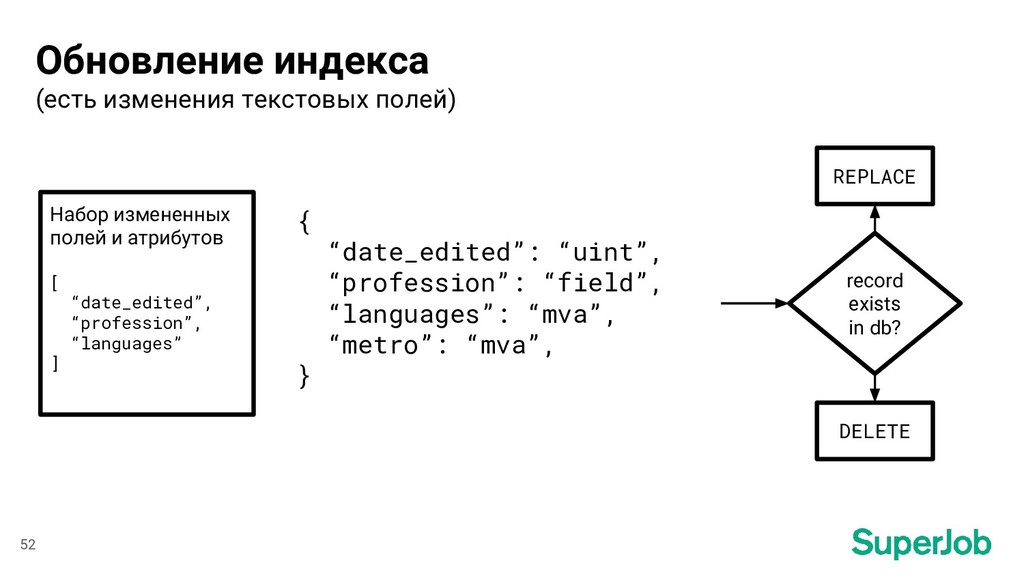
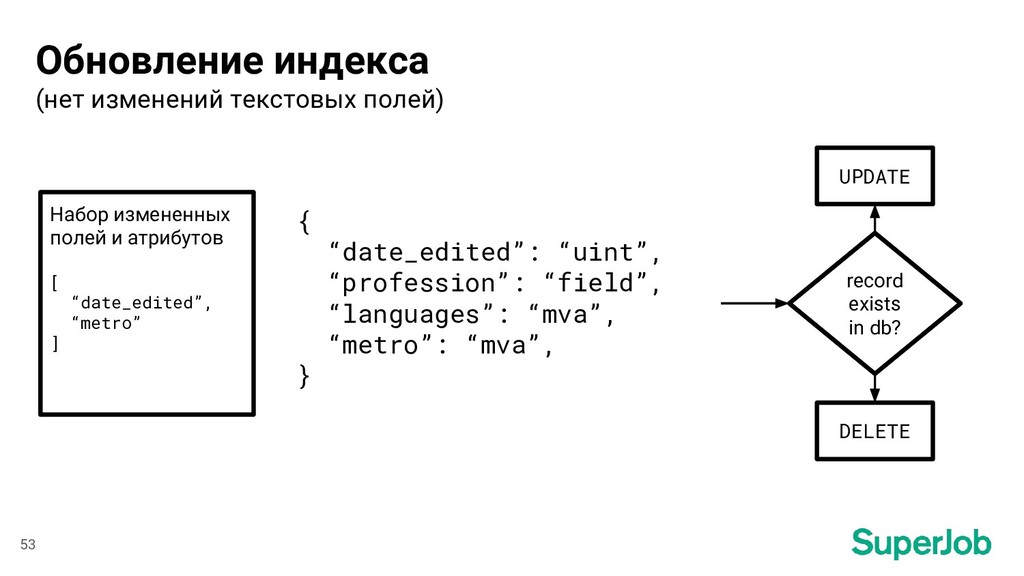
Набор измененных полей и атрибутов [ “date_edited”, “profession”, “languages” ] REPLACE DELETE record exists in db? 52 Обновление индекса (есть изменения текстовых полей)
backtrace begins here --------------- Program compiled with gcc 4.8.5 Configured with flags: '--build=x86_64-redhat-linux-gnu' '--host=x86_64-redhat-l 'LDFLAGS=-Wl,-z,relro ' 'CXXFLAGS=-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fex Host OS is Linux druj-ts2.sj-dev.local 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 22 Stack bottom = 0x7fffce1024a7, thread stack size = 0x100000 Trying manual backtrace: Frame pointer is null, manual backtrace failed (did you build with -fomit-frame-p Trying system backtrace: begin of system symbols: searchd[0x58c5de] searchd[0x40eb19] /lib64/libpthread.so.0(+0xf5d0)[0x7fd30f1da5d0] /lib64/libc.so.6(__select+0x33)[0x7fd30d31df73] searchd[0x4944d4] searchd[0x43b26c] searchd[0x45d82a]
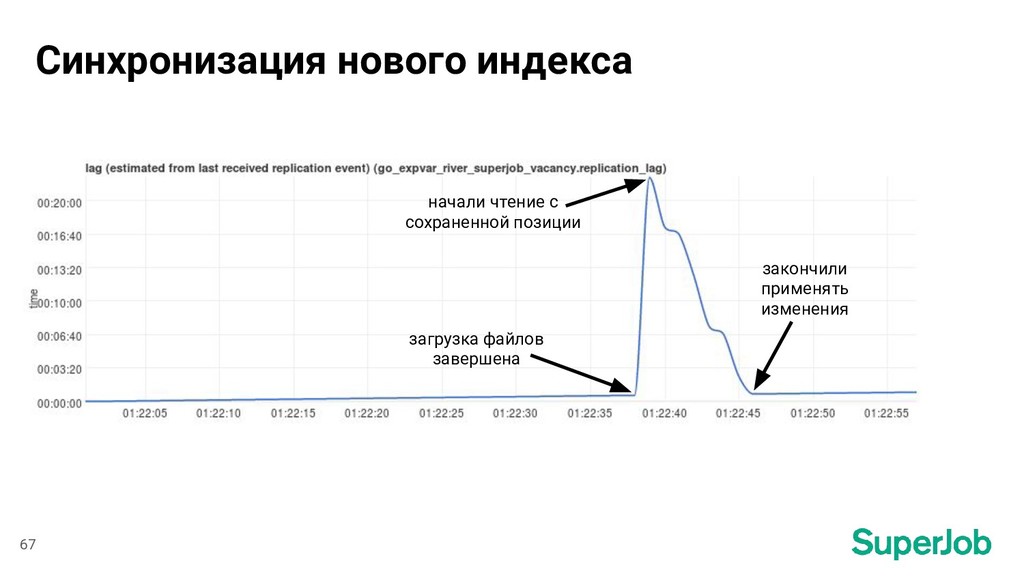
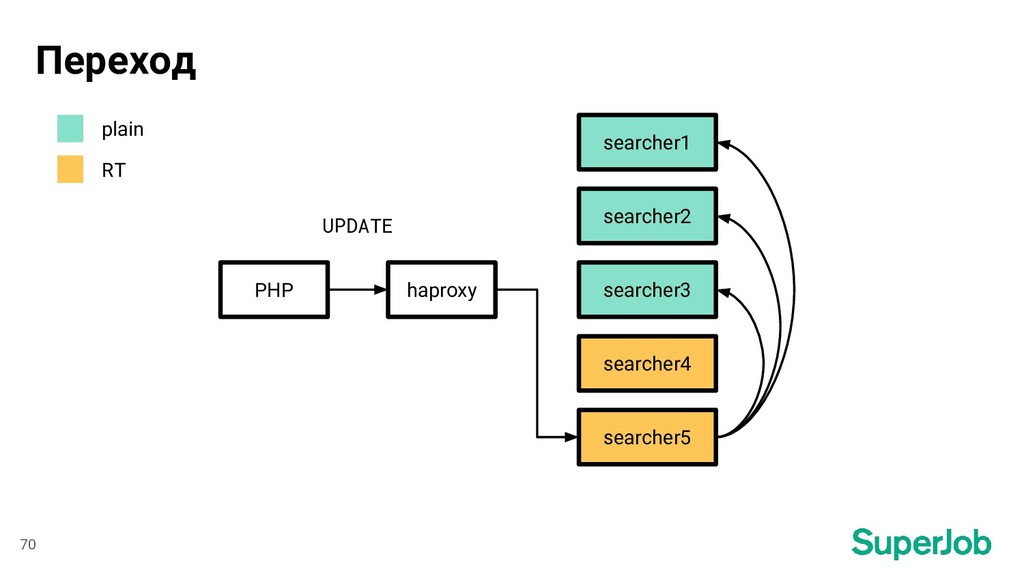
MariaDB 3. Запускаем indexer 4. Загружаем файлы индекса по серверам 5. Останавливаем синхронизацию 6. Заменяем старый индекс на новый 7. Возобновляем синхронизацию с сохраненной позиции 61
vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """ 62
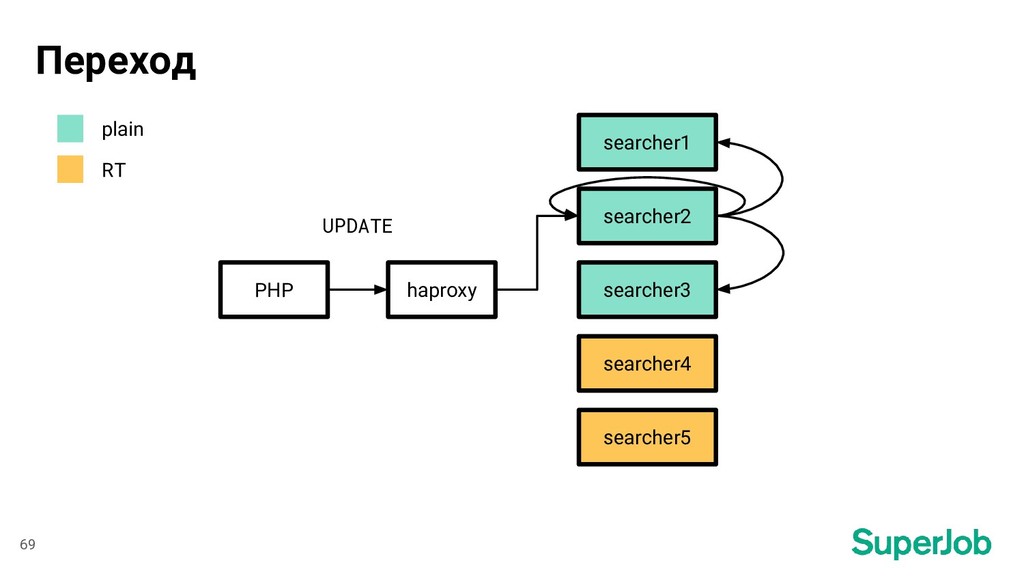
Sphinx: RELOAD INDEX vacancy_plain_part_0; TRUNCATE INDEX vacancy_part_0; ATTACH INDEX vacancy_plain_part_0 TO vacancy_part_0; ... 3. Haproxy: set server sphinx/sphinx01 state ready для каждого сервера 66
Ждем синхронизации i. SELECT @@gtid_current_pos; ii. Передаем результат в endpoint сервиса iii. Ждем соответствующего GTID 3. Выполняем поиск 4. Проверяем, что вакансия есть в выдаче 75
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DocID uint64 Index string Table *schema.Table Action string Rows [][]interface{}](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_26.jpg){kind=link}
{kind=link}
![Получение недостающих данных из MariaDB 29 [data_source.vacancy] parts = 4](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MySQL [(none)]> desc sync_state; +-----------------+--------+ | Field | Type |](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![39 Action string Columns []string DocID uint64 Index string OldRow](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![table = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"]](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_46.jpg){kind=link}
![table = "vacancy_language" [ingest.column_map] language_id = [ "languages" ] level](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_47.jpg){kind=link}
{kind=link}
![index vacancy#1 vacancy#2 vacancy#3 [ “date_edited”, “profession”, “languages” ] [](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_49.jpg){kind=link}
![[data_source.vacancy] parts = 4 query = """ SELECT vacancy.id AS](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![56 Action string Columns []string DocID uint64 GTID mysql.GTIDSet Index](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Indexer config [data_source.vacancy] parts = 4 query = """ SELECT](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_61.jpg){kind=link}
![[data_source.vacancy.indexer] mem_limit = ... write_buffer = ... group_concat_max_len = ...](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_62.jpg){kind=link}
{kind=link}
![[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative",](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! [email protected] https://github.com/superjobru/go-mysql-sphinx narkq 78](https://files.speakerdeck.com/presentations/e958759d1ca64464ad76bcdf707d9976/slide_77.jpg){kind=link}