Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
5分で分かるBloom Filter
Search
neo-nanikaka
July 22, 2014
Programming
4.1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
5分で分かるBloom Filter
neo-nanikaka
July 22, 2014
More Decks by neo-nanikaka
See All by neo-nanikaka
クリエイタープラットフォーム BOOTH、FANBOXでの 銀行口座支払いとペイアウトの事例 / PayPal Tech Meetup 11 pixiv
neo_nanikaka
0
2k
Other Decks in Programming
See All in Programming
Lessons from Spec-Driven Development
simas
PRO
0
180
セキュリティの専門家じゃなくてもできる。「セキュリティ意識」をアップデートして サプライチェーン攻撃への耐性を高めよう。
tk3fftk
5
730
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
540
作って学ぶ、 JSX (TSX) ランタイムの基本
syumai
7
1.6k
その問い、本当に正しいですか?AI時代のエンジニアに必要な哲学と認知科学 / ai-philosophy-cognitive-science
minodriven
7
4.1k
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
130
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
190
DynamoDBには集計系のクエリがないけどなんとかしたい
musan
1
140
LLM Plugin for Node-REDの利用方法と開発について
404background
0
170
技術記事、AIに書かせるか、自分で書くか? 〜それでも私が自分の手で書く理由〜 / #QiitaConference
jnchito
2
1.4k
Inside Stream API
skrb
1
690
AI時代のUIはどこへ行く?その2!
yusukebe
21
7.1k
Featured
See All Featured
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
570
Embracing the Ebb and Flow
colly
88
5.1k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
A designer walks into a library…
pauljervisheath
211
24k
Producing Creativity
orderedlist
PRO
348
40k
Test your architecture with Archunit
thirion
1
2.3k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
250
Building Adaptive Systems
keathley
44
3k
Transcript
5分でわかる Bloom Filter ※個人差があります
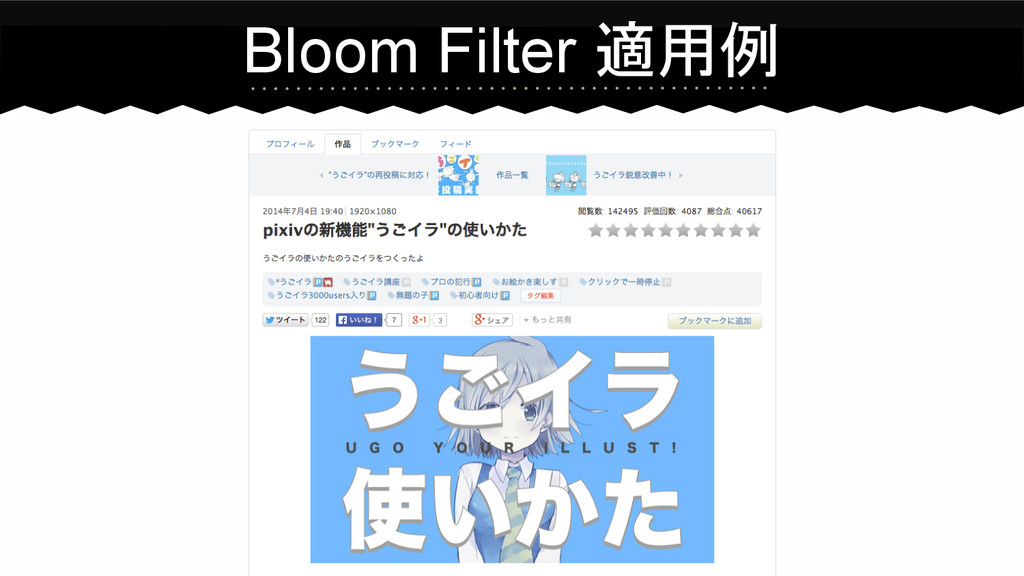
Bloom Filter 適用例
BOOTHアイコン BOOTHに商品が存在するタグ集合に 作品についたタグが含まれているかを判定 百科事典アイコン pixiv百科事典に記事が存在するタグ集合に 作品についたタグが含まれているかを判定 Bloom Filter 適用例
Burton H. Bloom (1970) 要素が集合の要素に含まれるかを判定する確率的アルゴリズム その他の要素判定アルゴリズム 探索木、ハッシュテーブル、線形リスト etc... Bloom Filter
準備 m ビットの配列 (初期値は0) 値が一様に分布する k 個のハッシュ関数 Bloom Filter 0
0 0 0 0 0 0 0 0 0 m = 10
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) Bloom Filter 0 0 0 0 0 0 0 0 0 0 m = 10
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 0 0 0 0 0 0 0 0 0 m = 10
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 0 0 0 0 0 0 0 0 0 m = 10 2 6 f(x) % m g(x) % m
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 0 0 0 0 0 0 0 0 0 m = 10 2 6 f(x) % m 4 g(x) % m 8
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 0 0 1 0 0 0 1 0 0 m = 10 2 6 f(x) % m 4 g(x) % m 8
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 0 0 1 0 0 0 1 0 0 m = 10 2 6 f(x) % m 4 2 g(x) % m 8 4
要素 x を追加する O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す1箇所のビットに1を立てる hi % m ( 1 <= i <= k ) 例: 2 と 6 を追加する f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 6 f(x) % m 4 2 g(x) % m 8 4 2回目だけど気にしたら負け ↑
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 10 f(x) % m 4 g(x) % m 8
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 10 f(x) % m 4 g(x) % m 8 4番目と8番目のビットが1なので 2 は集合に存在する!!
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 10 f(x) % m 4 2 g(x) % m 8 4
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 10 f(x) % m 4 2 g(x) % m 8 4 2番目と4番目のビットが1なので 10 は集合に存在する!?
要素 x の存在判定をする O (k) x をk 個のハッシュ関数に渡して得られた値をh1, h2, …
, hk とする ハッシュ値の示す全てのビットが1であれば true 例: 2 と 10 をチェックする f(x) = 2 * x g(x) = 4 * x Bloom Filter 0 1 0 1 0 0 0 1 0 0 m = 10 2 10 f(x) % m 4 2 g(x) % m 8 4 10 は偽陽性の誤検出
特徴 必要メモリ量が集合要素数に比例しない 追加したい要素そのものを保持するわけではない 要素を追加しても使用メモリ量が増えない 追加・判定処理に必要な時間が集合要素数と無関係 要素の削除はできない => CountingFilter 要素を追加しすぎると誤検出の確率が上がる 偽陽性誤検出
偽陰性誤検出は絶対に起きない Bloom Filter
気になる誤検出確率: m : ビット数 n : 想定される登録要素の最大数 k: 誤検出確率を最小にする最適ハッシュ関数の数 (近似)
k ≒ 0.7 * m / n Bloom Filter
備考: BloomFilterの性能は明らかにハッシュ関数の性能に左右される 誤検出確率は一様に分布する優秀なハッシュ関数を想定している Bloom Filter
初期実装: 2,000,000ビットくらいの1本のブルームフィルタ でかすぎて(250KBくらい) apc_fetchに 6ms かかる →メッチャ重い →ブルームフィルタ要らない子 BOOTHアイコン適用裏話
リベンジ: 8192ビットのブルームフィルタを100本用意する →あるタグの存在判定に必要なのは1本だけ どのブルームフィルタを使えばいいのか? →タグ名をハッシュ化して求める 1本当たり1KBなのでapc_fetch問題もクリア (0.01ms) 誤検出確率は 0.1% →ブルームフィルタはやれば出来る子
BOOTHアイコン適用裏話
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}