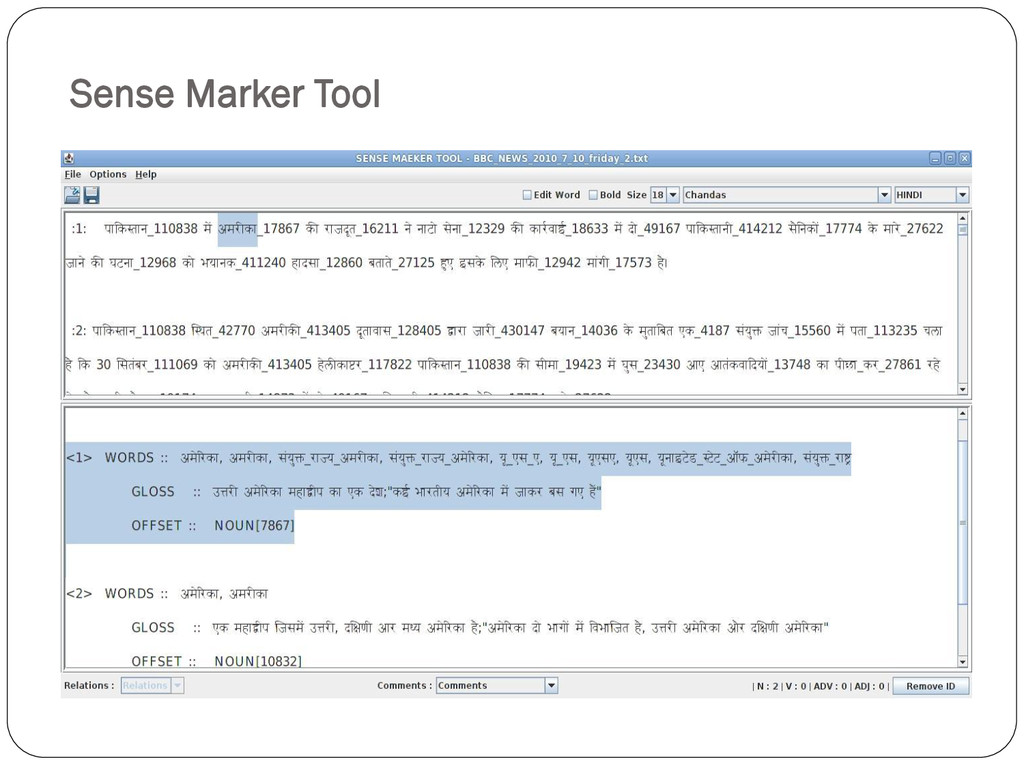
marked corpora. Sense marked corpora is essential for supervised Word Sense Disambiguation. The sense annotation task is done by Sense Marker Tool, which allows the manual marking of each word of a given corpora with the correct sense of the word. Words in corpora appear in morphed form, while wordnets store lemma. This situation calls for accurate lemmatizers.
and this problem is not easy to solve, since rule based lemmatizers take time and require highly skilled linguists. Statistical stemmers on the other hand do not return legitimate lemma. Our focus is to integrate our Lemmatizer with Sense Marker Tool.
to lemmatization which is quick, takes user help and is exact.These lemmatizers are human mediated. The key idea is that a trie is created out of the vocabulary of the language.Our approach is neither rule based nor statistical. The lemmatizing process consists in navigating the trie, trying to find a match between the input word and an entry in the trie. At the point of first mismatch- i.e., maximum prefix matching, the yield of the subtree rooted at the partially matched node is output as the list of possible lemma.
lemma for a given word. For example, in English, the verb 'to walk' may appear as 'walk', 'walked', 'walks', 'walking'. The base form, 'walk', that one might look up in a dictionary, is called the lemma for the word. Stemming aims to reduce a set of words into a canonical form which may or may not be a dictionary word of the language. Lemmatization, on the other hand, always produces a legal root word of the language.
which was developed specifically for IR/NLP applications. His approach consisted of the use of a manually developed list of 294 suffixes, each linked to 29 conditions, plus 35 transformation rules. For an input word, the suffix with an appropriate condition is checked and removed. Porter stemmer (Porter,1980): The most widely used algorithm for English language. Plisson (Plisson et,2008). proposed the most accepted rule based approach for lemmatization.
level morphological analyzer. OMA(Ozturkmenoglu,2012) is a Turkish morphological Analyzer. Tarek EI-Shishtawy(El-Shishtawy,2012) proposed the first non statistical Arabic Lemmatizer. For Indian Languages, Ramanathan and Rao(Rao,2003) used manually sorted suffix list and performed longest match stripping for building a Hindi stemmer. GRALE(Loponen,2013) is a graph based lemmatizer for Bengali language. A Hindi Lemmatizer is proposed, where suffixes are stripped according to various rules and necessary addition of character(s) is done to get a proper root form (Paul, 2013).
is suffix based morphology. First or Direct Variant: We first setup the data structure “Trie” using the words in the wordnet of a specific language. Next, we match byte by byte, input word form and wordnet words. The output is all wordnet words retrieved after the maximum substring match.
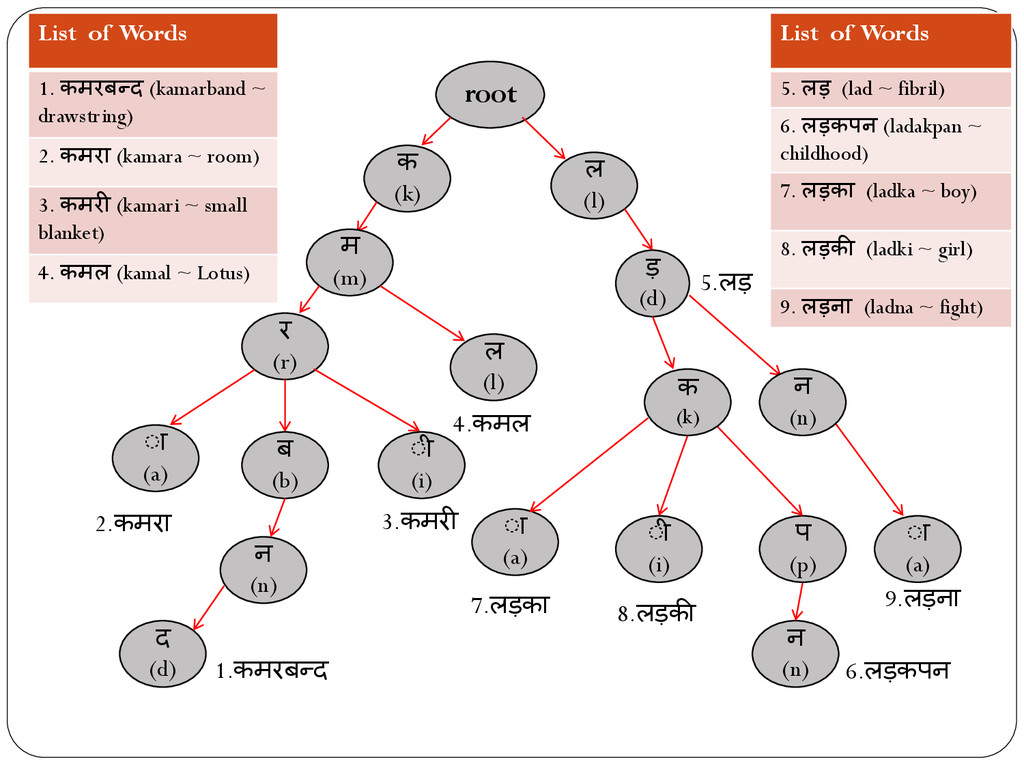
The backtrack variant prints the results “n” level previous to the maximum matched prefix obtained in the “direct” variant of our lemmatizer. The value of “n” is user controlled. Next slide, we see a figure of sample trie diagram which consists of hindi words for first variant.
trie with the example of inflected word “लड़ककय ाँ” (ladkiyan, i.e., girls).Our lemmatizer gives the following results: ( ल लड़ लड़क लड़की लड़कपन लड़कोरी लड़कौरी ). From this result set, a trained lexicographer can pick up the root word as “लड़की” (ladki, i.e., girl).
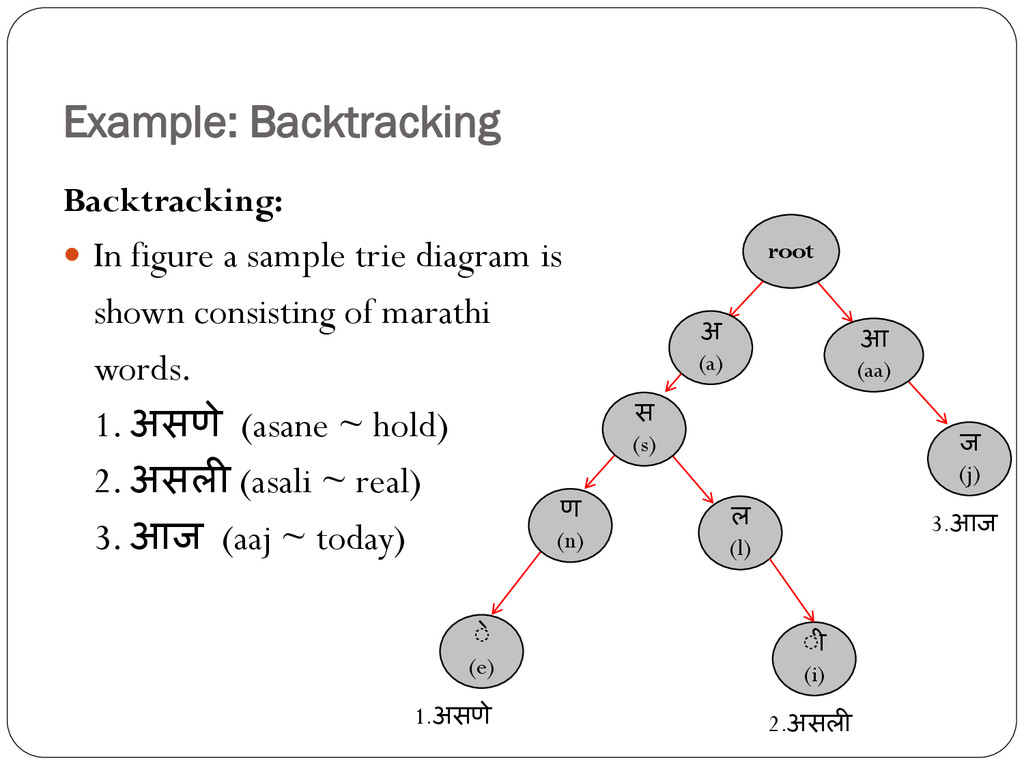
is shown consisting of marathi words. 1. असणे (asane ~ hold) 2. असली (asali ~ real) 3. आज (aaj ~ today) 1.असणे 2.असली 3.आज ल (l) ज (j) root अ (a) स (s) आ (aa) ीे (e) ण (n) ी (i)
an inflected form of the Marathi word “असणे” (asane). In the first iterative procedure the word “असली”(asali) is given as output.But it is not the correct result. So we perform backtracking and it gives the following results: (असणे असंभव असंयत असंयम असंख्य असंगत असंमत असंयम असतेपण असंतोष असंबद्ध असंयममत)
possible root forms of a given word. For simplicity, we have applied a heuristic to filter the result set. 1. Only those results are displayed whose length is less than or equal to inflected word. 2. The filtered results are sorted on the basis of length.
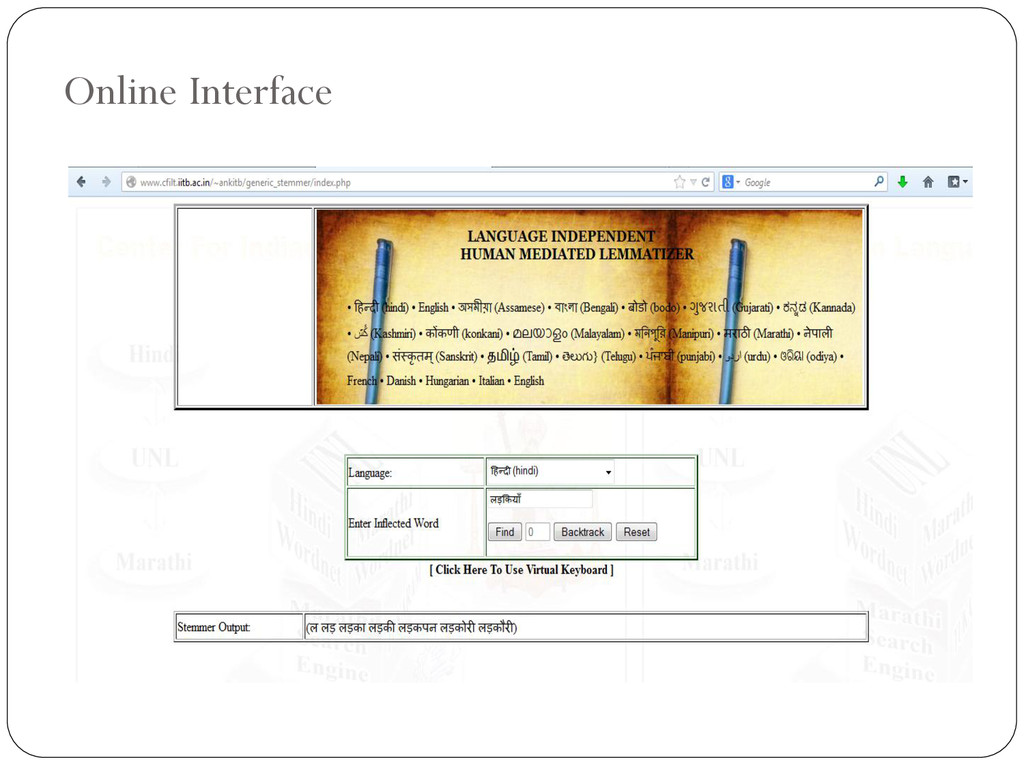
downloadable Java based executable jar. The interface allows input from 18 different Indian languages and 5 European languages. The “Backtrack” feature allows us to backtrack up to 8 levels. The interface also has a facility to upload a text document related to specific language, to perform lemmatization over the whole document.
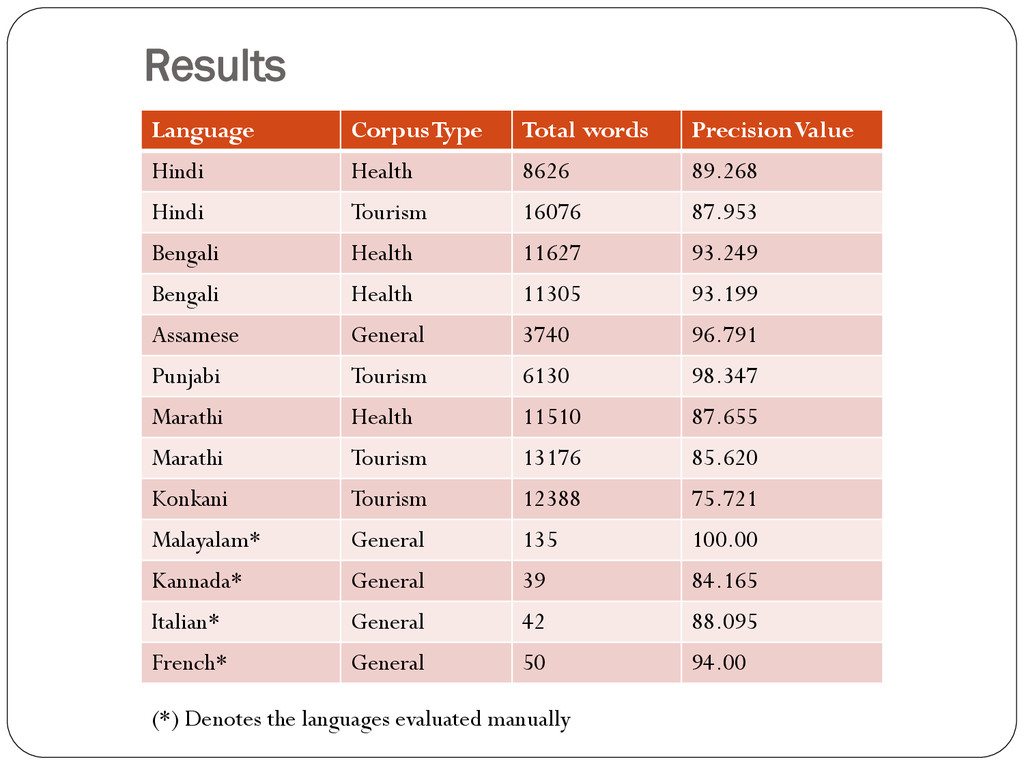
the result in the top 10 from the set of results matches the root in the gold standard, then we consider our result to be correct. For Hindi, Marathi, Bengali, Assamese, Punjabi and Konkani we used sense marked corpus. For Dravidian languages and European languages we had to perform manual evaluation.
8626 89.268 Hindi Tourism 16076 87.953 Bengali Health 11627 93.249 Bengali Health 11305 93.199 Assamese General 3740 96.791 Punjabi Tourism 6130 98.347 Marathi Health 11510 87.655 Marathi Tourism 13176 85.620 Konkani Tourism 12388 75.721 Malayalam* General 135 100.00 Kannada* General 39 84.165 Italian* General 42 88.095 French* General 50 94.00 (*) Denotes the languages evaluated manually
in Marathi and Dravidian languages: Marathi and Dravidian languages like Kannada and Malayalam show the process of agglutination. 2. Suppletion: For example the word “go ” has an irregular past tense form “went”.
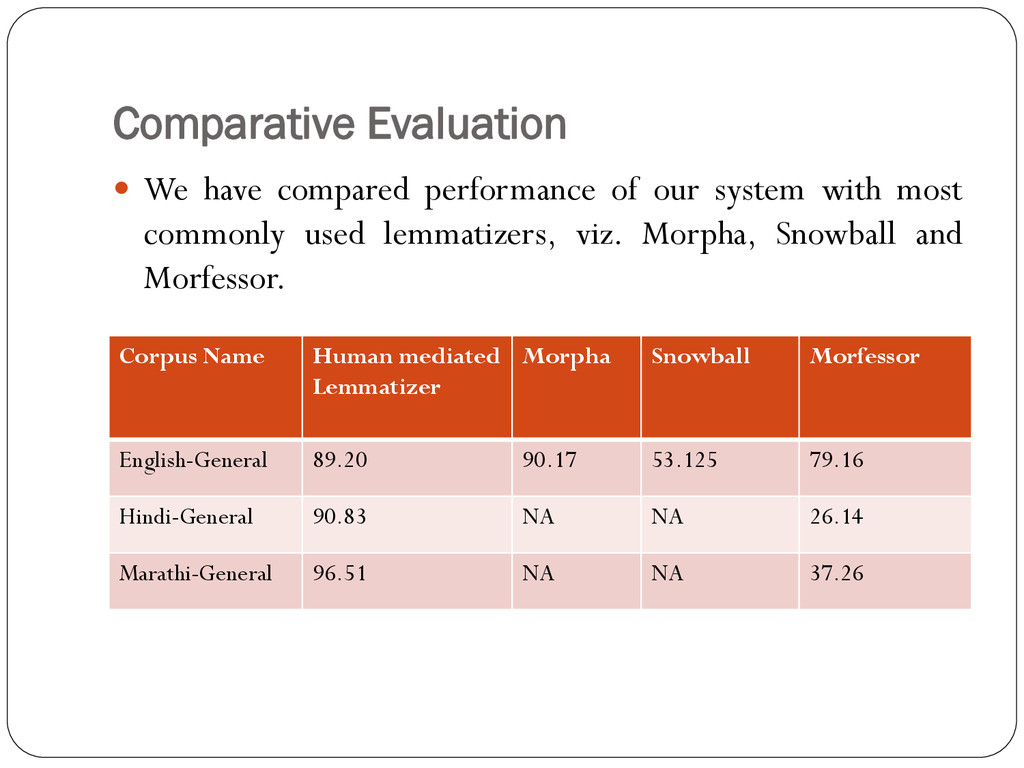
with most commonly used lemmatizers, viz. Morpha, Snowball and Morfessor. Corpus Name Human mediated Lemmatizer Morpha Snowball Morfessor English-General 89.20 90.17 53.125 79.16 Hindi-General 90.83 NA NA 26.14 Marathi-General 96.51 NA NA 37.26
weight and quick to create. . The human annotator can chose the result to sense mark the corpus. Thus it helps in Machine Translations and Word Sense Disambiguation. Future Work: Improvement of the ranking algorithm so the we can get the correct lemma within top 2 results. Integration of Human mediated lemmatizer to all languages sense marking tasks.
and Bhattacharyya Pushpak 2010. Introduction to Tools for IndoWordnet and Word Sense Disambiguation, The 3rd IndoWordnet Workshop, Eighth International Conference on Natural Language Processing (ICON 2010), IIT Kharagpur, India. Chrupala Grzegorz 2006. Simple data-driven context sensitive lemmatization , Chrupaa, Grzegorz (2006) Simple data-driven context-sensitive lemmatization. In: SEPLN 2006, 13-15 September 2006, Zaragoza,Spain. Cormen, Thomas H. and Stein, Clifford and Rivest, Ronald L. and Leiserson, Charles E. 2001. Introduction to Algorithms, 2nd Edition, ISBN:0070131511, McGraw-Hill Higher Education. Creutz Mathis, and Krista Lagus. 2005. Unsupervised morpheme segmentation and morphology induction from text corpora using Morfessor 1.0., Technical Report A81, Publications in Computer and Information Science, Helsinki University of Technology. Creutz Mathis, and Krista Lagus. 2007. Unsupervised models for morpheme
on Speech and Language Processing, 4(1):1-34 Dabre Raj,Amberkar Archana and Bhattacharyya Pushpak 2012. Morphology Analyser for Affix Stacking Languages: a case study in Marathi, COLING 2012, Mumbai, India, 10-14 Dec, 2012. El-Shishtawy Tarek and El-Ghannam Fatma 2012. An Accurate Arabic Root- Based Lemmatizer for Information Retrieval Purposes, IJCSI International Journal of Computer Science Issues, Vol. 9, Issue 1, No 3, January 2012 ISSN (Online): 1694-0814. Goldsmith John A. 2001. Unsupervised Learning of the morphology of a Natural Language, Computational Linguistics, 27(2): 153-198. Goldsmith John A. 2006. An algorithm for the unsupervised Learning of morphology, Natural Language Engineering, 12(4): 353-371. Guido Minnen, John Carroll and Darren Pearce. 2001. Applied morphological processing of English, Natural Language Engineering, 7(3). 207-223.
rule based approach to word lemmatization, Proceedings of 7th International Multi-conference Information Society, IS 2004, Institute Jozef Stefen, Ljubljana, pp.83-86, 2008. Jongejan Bart and Dalianis Hercules 2009. Automatic training of lemmatization rules that handle morphological changes in pre-, in- and suffixes alike, Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, pages 145 - 153, Suntec, Singapore, 2-7 August 2009 Lauri Karttunen 1983. KIMMO: A General Morphological Processor , Texas Linguistic Forum, 22 (1983), 163-186. Loponen Aki, Paik Jiaul H. and Jrvelin Kalervo 2013. UTA Stemming and Lemmatization Experiments in the FIRE Bengali Ad Hoc Task , Multilingual Information Access in South Asian Languages Lecture Notes in Computer Science Volume 7536, 2013, pp 258-268. Lovins, J.B. 1968. Development of a stemming algorithm, Mechanical Translations and Computational Linguistics Vol.11 Nos 1 and 2, pp. 22-31.
Kole Gobinda, Mitra Pabitra, and Datta Kalyankumar. 2007. YASS: Yet another suffix stripper, Association for Computing Machinery Transactions on Information Systems, 25(4):18-38. Majumder, Prasenjit and Mitra, Mandar and Datta, Kalyankumar 2007. Statistical vs Rule-Based Stemming for Monolingual French Retrieval, Evaluation of Multilingual and Multi-modal Information Retrieval, Lecture Notes in Computer Science vol. 4370, ISBN 978-3-540-74998-1, Springer, Berlin, Heidelberg. Massimo Melucci and Nicola Orio 2003. A novel method of Stemmer Generation Based on Hidden Markov Models, CIKM ‘03, New Orleans, Louisiana, USA. Mayfield James and McNamee Paul 2003. Single Ngram Stemming, SIGIR ‘03, Toronto, Canada. Porter M.F. 1980. An algorithm for suffix stripping, Program; 14, 130-137.
different lemmatization approaches for information retrieval on Turkish text collection , Innovations in Intelligent Systems and Applications (INISTA), 2012 International Symposium on. Porter M.F. 2006. Stemming algorithms for various European languages, Available at [URL] http://snowball.tartarus.org/texts/stemmersoverview.html As seen on May 16, 2013. Ramanathan Ananthakrishnan, and Durgesh D. Rao, 2003. A Lightweight Stemmer for Hindi. , Workshop on Computational Linguistics for South-Asian Languages, EACL Snigdha Paul, Nisheeth Joshi and Iti Mathur 2013. Development of a Hindi Lemmatizer, CoRR, DBLP:journals/corr/abs/1305.6211 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}