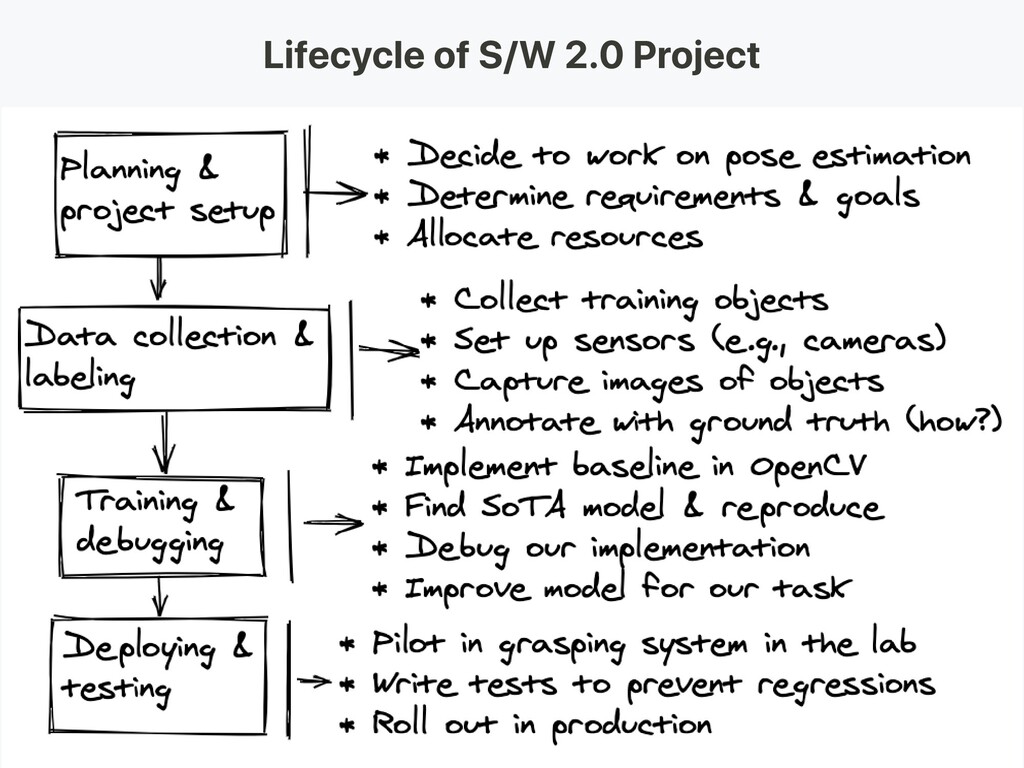
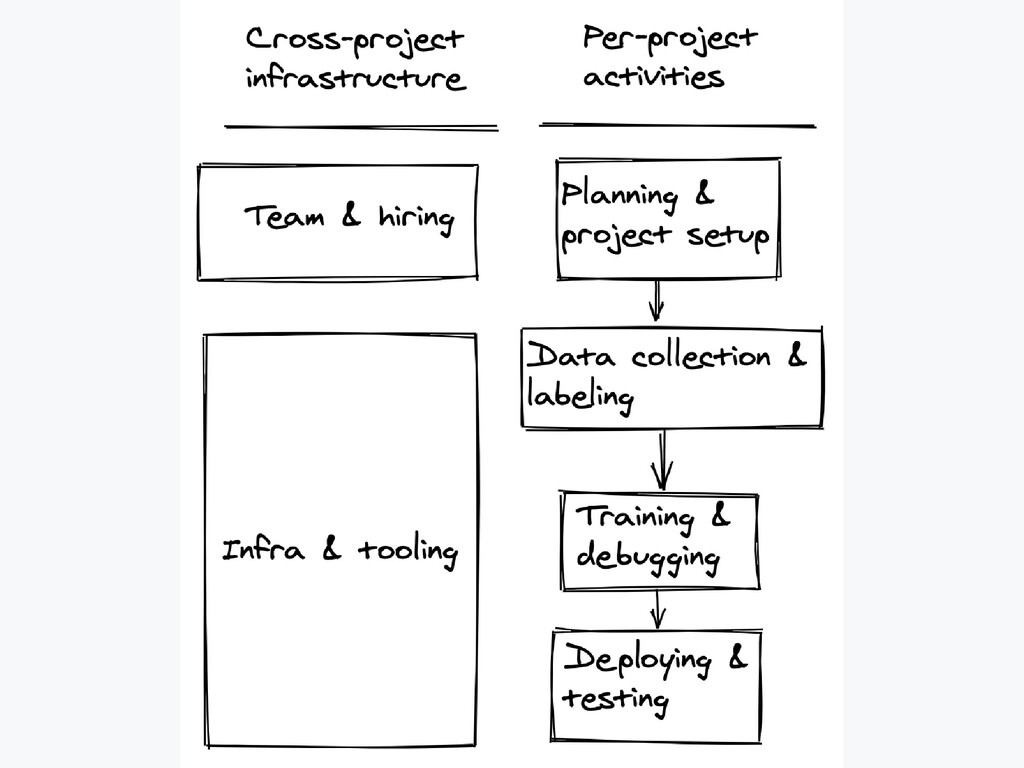
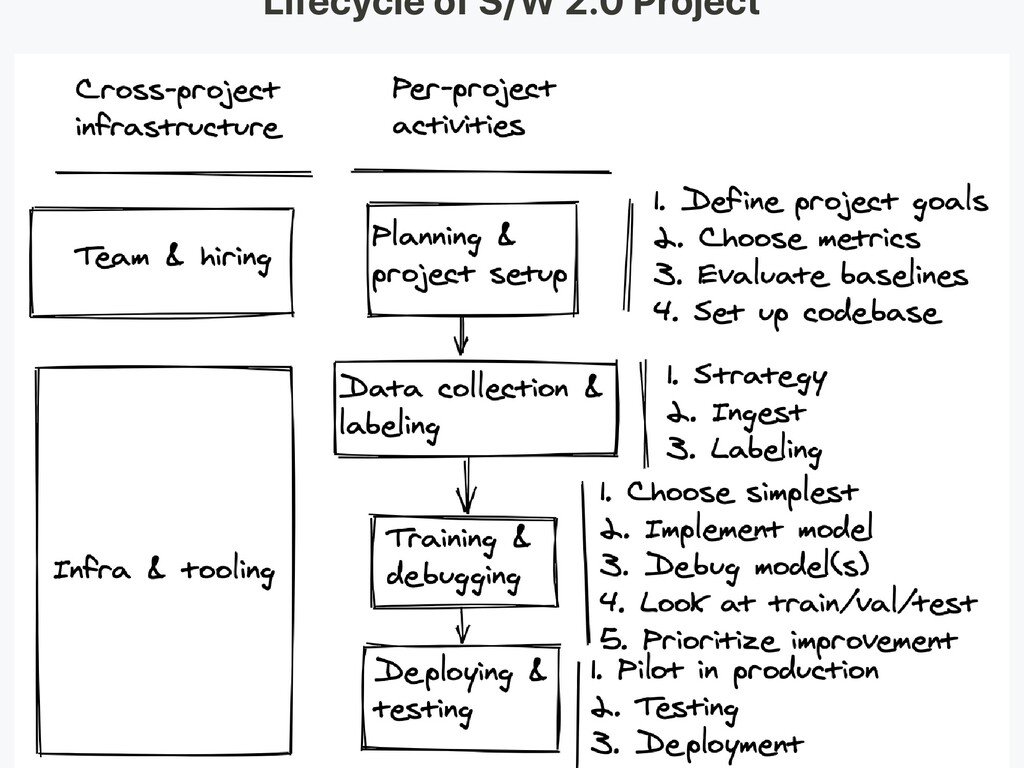
-> Software 2.0 . Lifecycle of Software 2.0 Project . Infrastructure and Tooling . Python is the King, Go can be the Minister . Go Case Study: Data Processing Pipeline
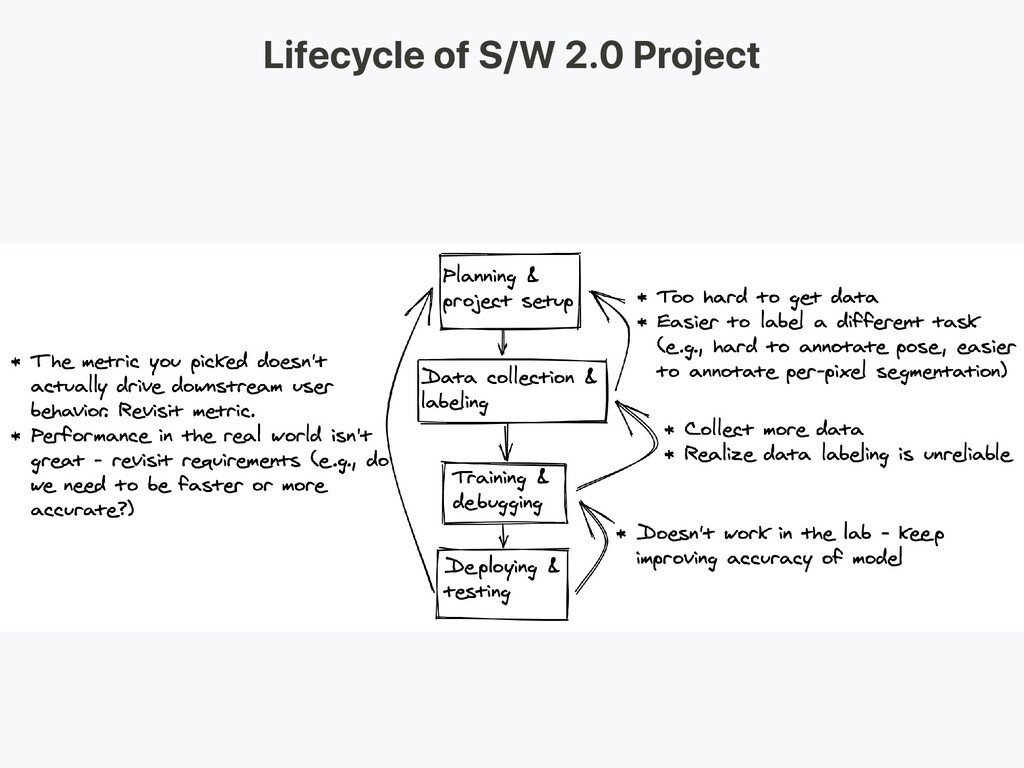
express how system achieve goal S/@ 2.0 -> Curating training data, spec-by-example of what system should do Toolchain 1.0 -> Create + Validate Logic Toolchain 2.0 -> Create / Curate + Validate Data
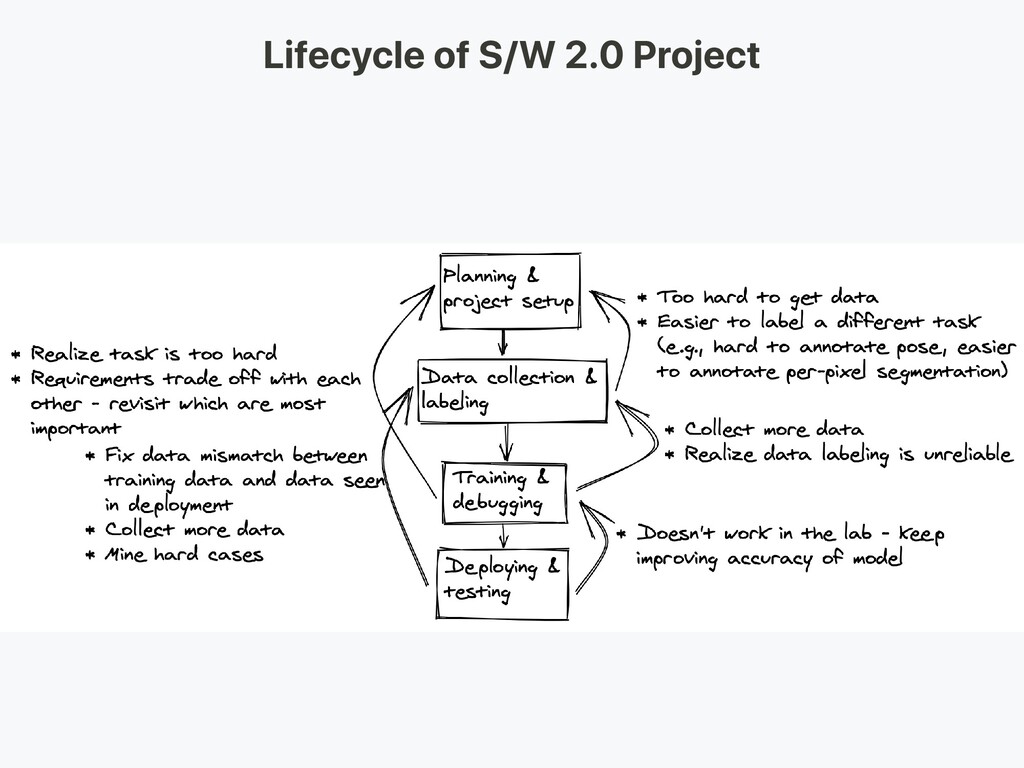
Use template to extract info (order number / travel date) Use heuristic based with handcrafted rule Lesson Learned -> Coverage of heuristic based extraction system flat for several month because too brittle to improve without introducing error
surpassed result from S/W 1.0 Google delete 45k line of code New system is easier to maintain Old system is brittle, difficult to debug error difficult to make further accuracy improvement New possibility -> Cross-language word embedding to learn extraction model across several languages
of your pipeline Where "cheap prediction" is valuable Where automatic complicated manual process is valuable Low Cost Cost is driven by: Data availability Performance requirements Problem difficulty
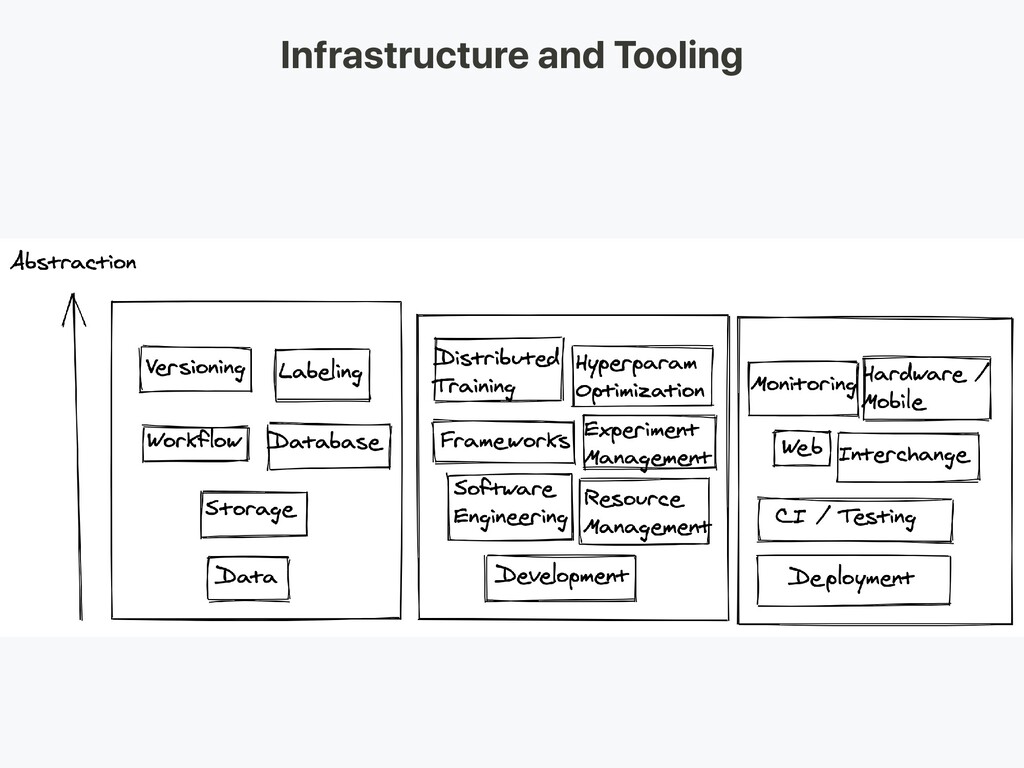
data Labeling own data is costly Here are some resources for data Open source data (good to start with, not an advantage) Data augmentation (a MUST for CV, optional for NLP) Synthetic data (worth starting with, esp. in NLP)
of labor: Crowdsourcing: cheap and scalable, less reliable, needs QC Hiring own annotators: less QC needed, expensive, slow to scale Data labeling service companies: FigureEight
Annotation tool powered by active learning (Text + Image) HIVE: AI as a Service platform for CV Supervisely: entire CV platform Labelbox: CV Scale: AI data platform (CV & NLP)
compressed texts) Amazon S3 Ceph Object Store Database: Store metadata (file paths, labels, user activity, etc) Postgres: right choice for most applications, best-in-class SQL and great support for unstructured JSON
from database (e.g. logs) Amazon Redshift Feature Store: store, access, and share ML features FEAST Michelangelo Palette At training time, copy data into local or networked filesystem (NFS)
ML models are part code, part data. No data versioning means no model versioning. Data versioning platforms: DVC: Open source version control system for ML projects Pachyderm: version control for data Dolt: versioning for SQL database
different sources, Stored data in db and object stores, log processing, and outputs of other classifiers. There are dependencies between tasks, each needs to be kicked off after its dependencies are finished. For example, training on new log data, requires a preprocessing step before training. Makefiles are not scalable. "Workflow manager"s become pretty essential in this regard.
Dynamic, extensible, elegant, and scalable (the most widely used) DAG workflow Robust conditional execution: retry in case of failure Pusher supports docker images with tensorflow serving Whole workflow in a single .py file
VS Code Notebooks: Great as starting point of the projects, hard to scale nteract: a next-gen React-based UI for Jupyter notebooks Papermill: is an nteract library built for parameterizing, executing, and analyzing Jupyter Notebooks. Commuter: another nteract project which provides a read-only display of notebooks (e.g. from S3 buckets). Streamlit: interactive data science tool with applets
a 4x Turing-architecture PC Training/Evaluation: Use the same 4x GPU PC. When running many experiments, either buy shared servers or use cloud instances. For large companies: Development: Buy a 4x Turing-architecture PC per ML scientist or let them use V100 instances Training/Evaluation: Use cloud instances with proper provisioning and handling of failures
tooling needed for ML experimentation Losswise (Monitoring for ML) Comet: lets you track code, experiments, and results on ML projects Weights & Biases: Record and visualize every detail of your research with easy collaboration
and output files as well as visualization of the results. Automatic experiment tracking with one line of code in python Side by side comparison of experiments Hyper parameter tuning Supports Kubernetes based jobs
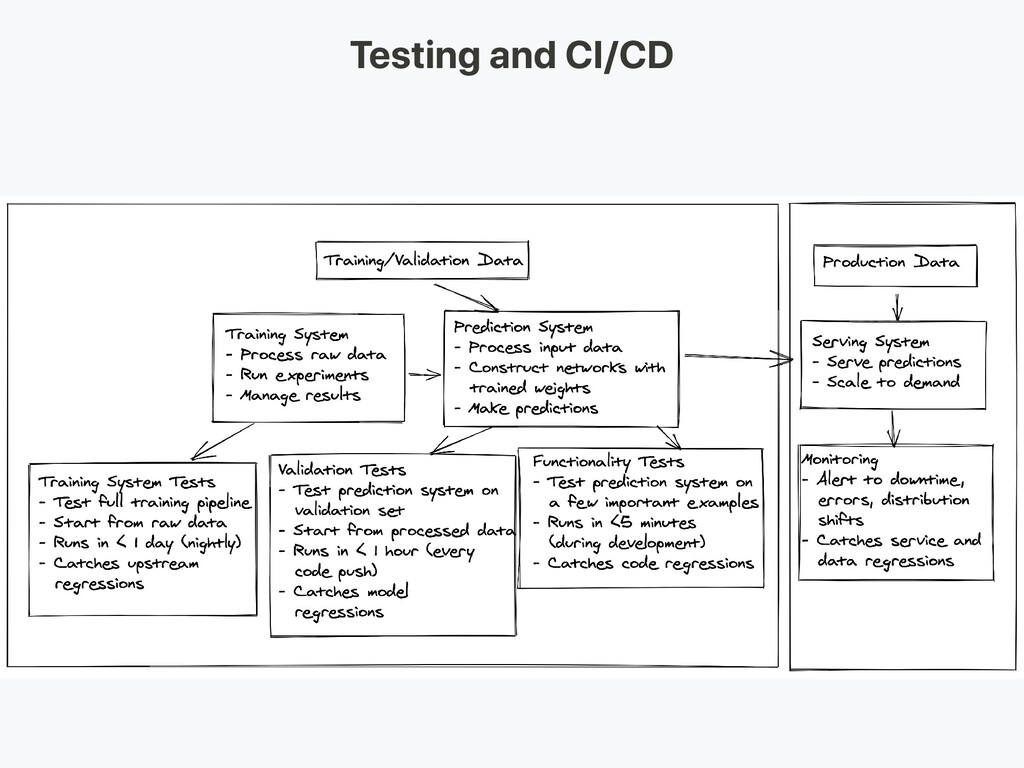
Training system tests: testing training pipeline Validation tests: testing prediction system on validation set Functionality tests: testing prediction system on few important examples Continuous Integration: Running tests after each new code change pushed to the repo
Kubernetes native workflow engine for orchestrating parallel jobs (incudes workflows, events, CI and CD). CircleCI: Language-Inclusive Support, Custom Environments, Flexible Resource Allocation, used by instacart, Lyft, and StackShare. Travis CI Buildkite: Fast and stable builds, Open source agent runs on almost any machine and architecture, Freedom to use your own tools and services Jenkins: Old school build system
System Prediction System: Process input data, make predictions Serving System (Web server): Serve prediction with scale in mind Use REST API to serve prediction HTTP requests Calls the prediction system to respond
instances Deploy as containers, scale via orchestration Containers Docker Container Orchestration: Kubernetes (the most popular now) MESOS Marathon Deploy code as a "serverless function" Deploy via a model serving solution
Batches request for GPU inference Frameworks: Tensorflow serving MXNet Model server Clipper (Berkeley) SaaS solutions Seldon: serve and scale models built in any framework on Kubernetes Algorithmia Deploying Jupyter Notebooks: Kubeflow Fairing is a hybrid deployment package that let's you deploy your Jupyter notebook codes!
inference is preferable if it meets the requirements. Scale by adding more servers, or going serverless. GPU inference: TF serving or Clipper Adaptive batching is useful
a distributed microservice architecture could be challenging. A Service mesh (consisting of a network of microservices) reduces the complexity of such deployments, and eases the strain on development teams. Istio: a service mesh to ease creation of a network of deployed services load balancing service-to-service authentication monitoring with few or no code changes in service code.
shifts Catching service and data regressions Cloud providers solutions are decent Kiali: observability console for Istio with service mesh configuration capabilities. It answers these questions: How are the microservices connected? How are they performing?
Tensorflow Lite PyTorch Mobile Core ML ML Kit FRITZ OpenVINO Model Conversion: Open Neural Network Exchange (ONNX): open-source format for deep learning models
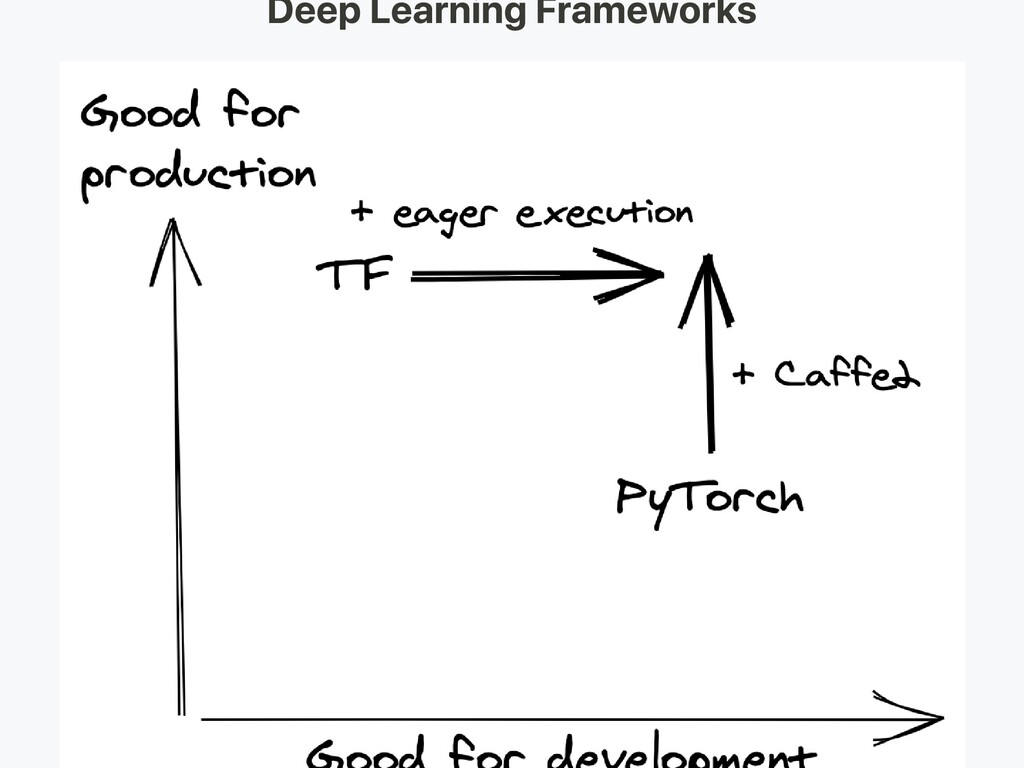
Python is the King for S/W 2.0 To actually run a production system at scale -> need infra that implement Autoscaling -> traffic fluctuation don't break API API management -> handle simultaneous API deployment Rolling update -> update models while still serving user Logging Cost optimization
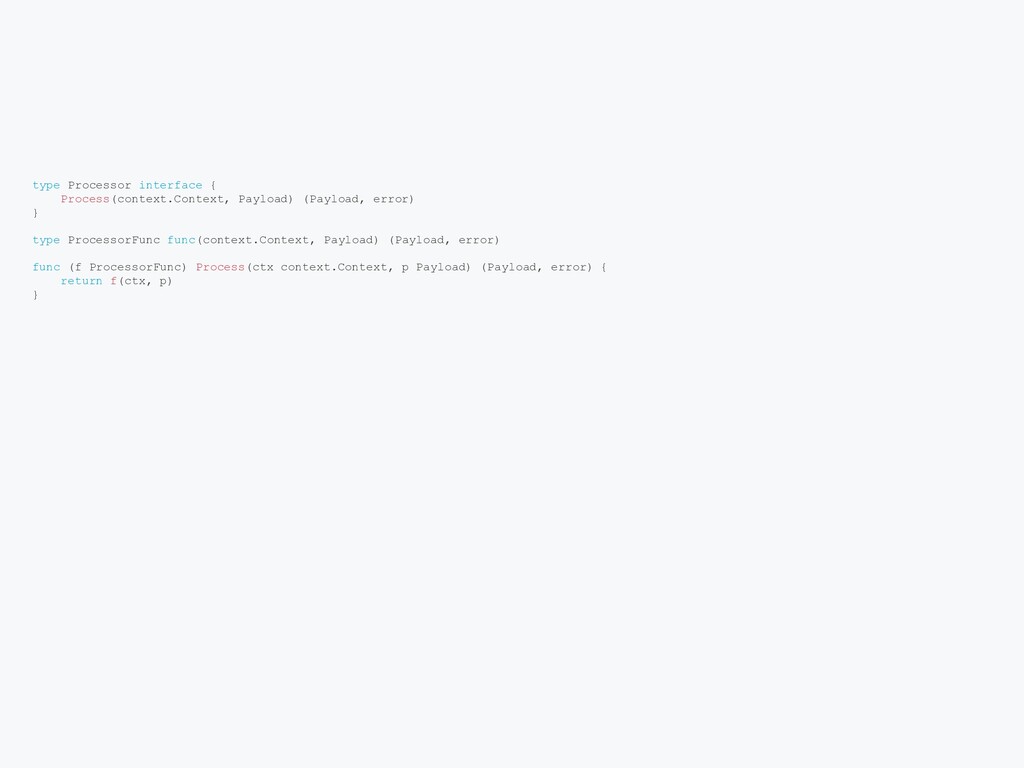
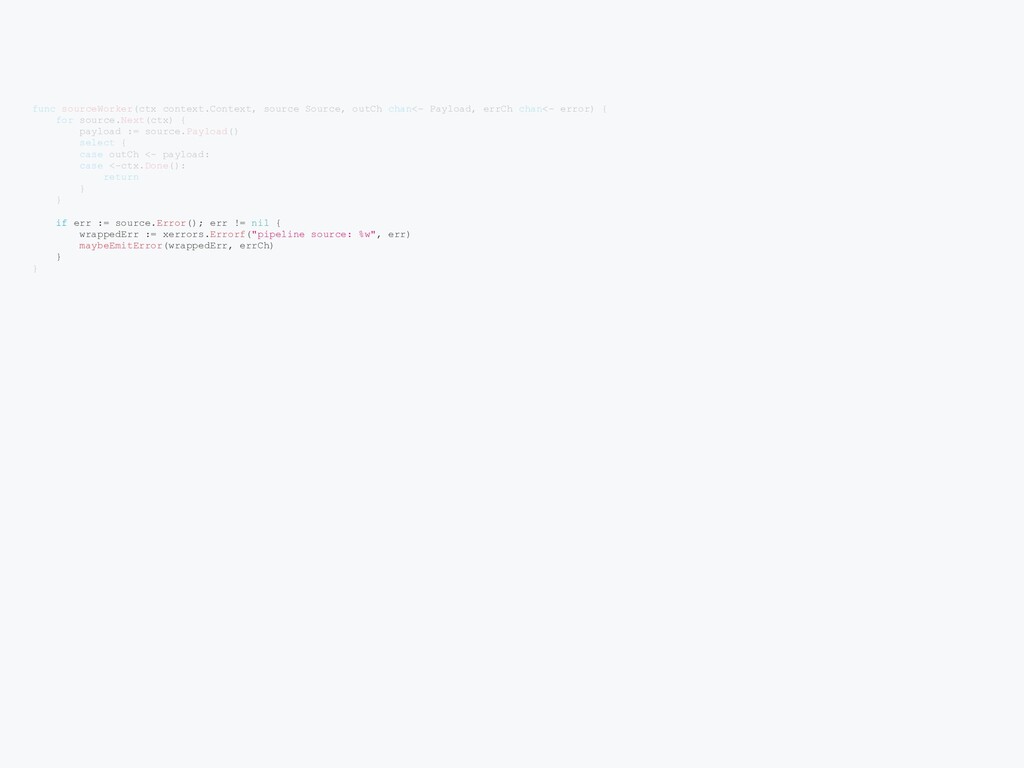
few different APIs Can be used to programmatically calls these APIs to provision cluster, launch deployment, and monitor APIs Challenging to have performant, reliable. Go has goroutines + channels Build cross-platform CLI is easier in Go Go ecosystem is great for infrastructure projects Go is just a pleasure to work with Good for large project Fast compilation, static typing and great tooling
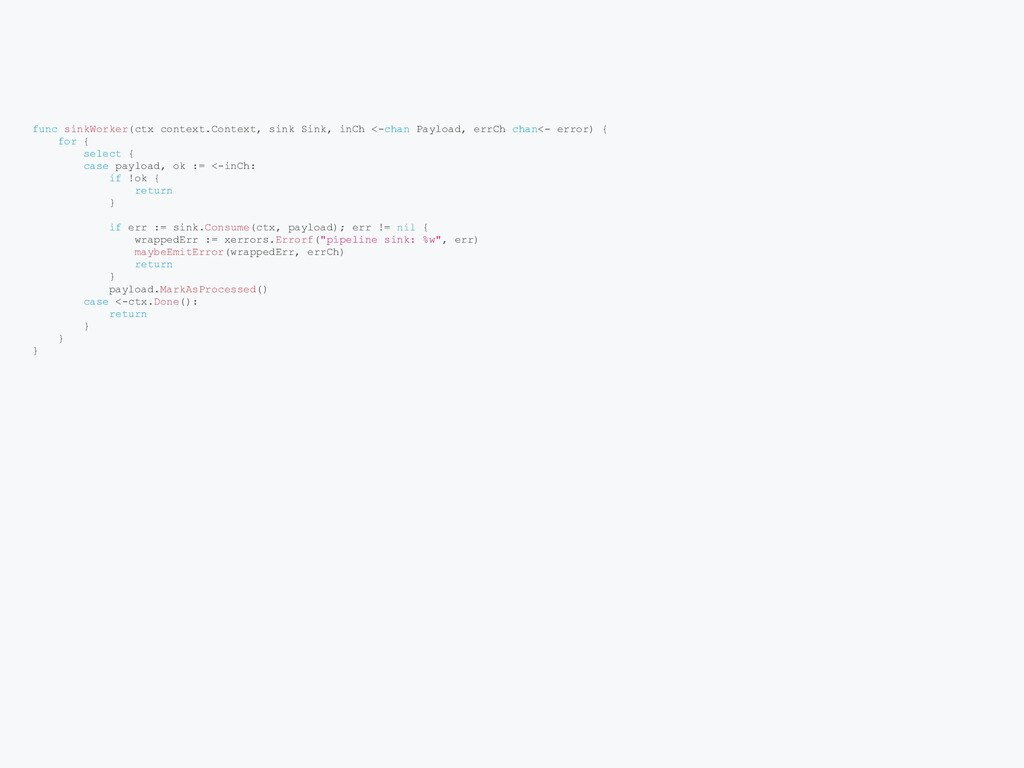
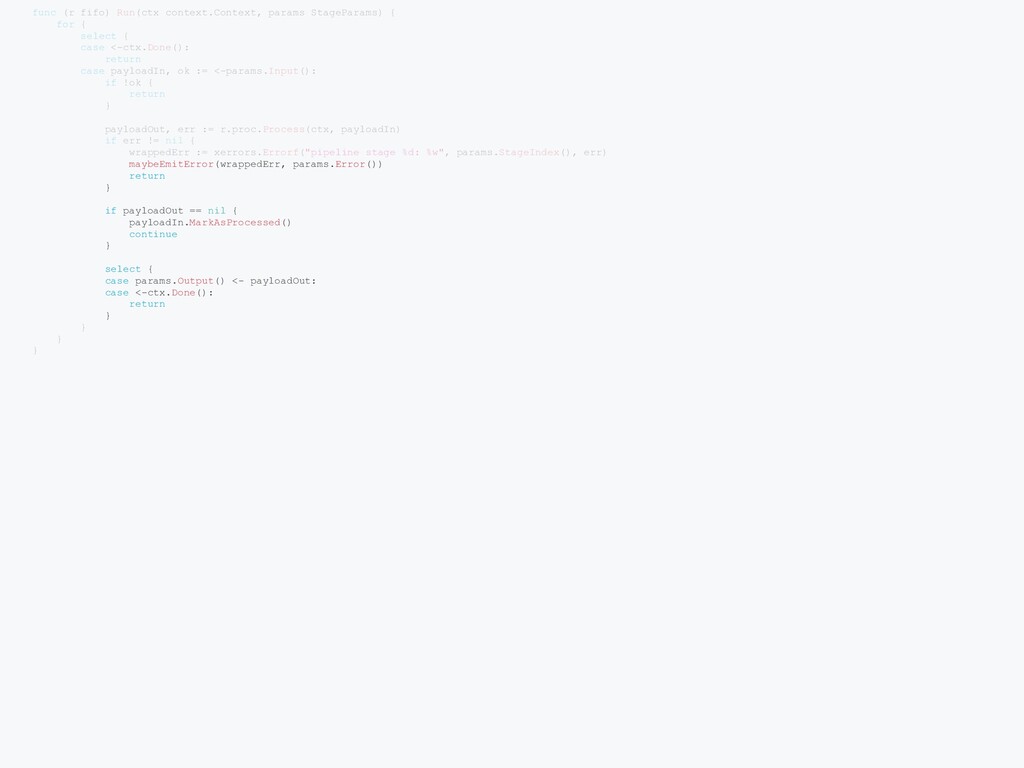
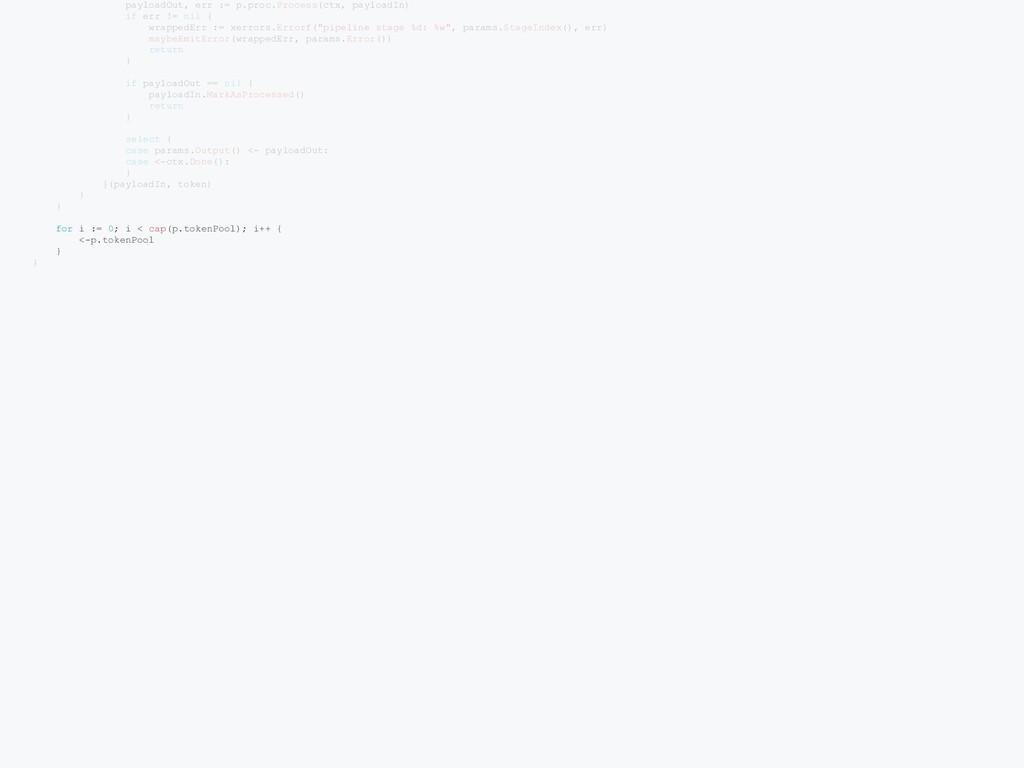
StageRunner { if len(procs) == 0 { panic("Broadcast: at least one processor must be specified") } fifos := make([]StageRunner, len(procs)) for i, p := range procs { fifos[i] = FIFO(p) } return &broadcast{fifos: fifos} } func (b *broadcast) Run(ctx context.Context, params StageParams) { var ( wg sync.WaitGroup inCh = make([]chan Payload, len(b.fifos)) ) for i := 0; i < len(b.fifos); i++ { wg.Add(1) inCh[i] = make(chan Payload) go func(fifoIndex int) { fifoParams := &workerParams{ stage: params.StageIndex(), inCh: inCh[fifoIndex], outCh: params.Output(), errCh: params.Error(), } b.fifos[fifoIndex].Run(ctx, fifoParams) wg.Done() }(i) } done: for { select { case <-ctx.Done(): break done case payload, ok := <-params.Input(): if !ok { break done } for i := len(b.fifos) - 1; i >= 0; i-- { var fifoPayload = payload if i != 0 { fifoPayload = payload.Clone() } select { case <-ctx.Done(): break done case inCh[i] <- fifoPayload: } } } } for _, ch := range inCh { close(ch) } wg.Wait() }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![type Pipeline struct { stages []StageRunner } func New(stages ...StageRunner)](https://files.speakerdeck.com/presentations/99c6a30ac74d4fa29d55c8922d1e5cc5/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
![fifos := make([]StageRunner, numWorkers) for i := 0; i <](https://files.speakerdeck.com/presentations/99c6a30ac74d4fa29d55c8922d1e5cc5/slide_70.jpg){kind=link}
{kind=link}
![type broadcast struct { fifos []StageRunner } func Broadcast(procs ...Processor)](https://files.speakerdeck.com/presentations/99c6a30ac74d4fa29d55c8922d1e5cc5/slide_72.jpg){kind=link}
{kind=link}
{kind=link}