Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ニジエチューニング2014-11
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ニジエインフラ
December 02, 2014
Programming
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ニジエチューニング2014-11
ニジエインフラ
December 02, 2014
More Decks by ニジエインフラ
See All by ニジエインフラ
ニジエチューニング2023-12
nijieinfra
0
990
ニジエチューニング2017-12
nijieinfra
0
2.6k
ニジエチューニング2016-12
nijieinfra
0
1k
ニジエチューニング2014-12
nijieinfra
0
680
ニジエチューニング2014-10
nijieinfra
0
510
ニジエチューニング2014-04
nijieinfra
0
360
ニジエチューニング2014-03
nijieinfra
0
600
Other Decks in Programming
See All in Programming
えっ!!コードを読まずに開発を!?
hananouchi
0
190
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
310
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
250
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
310
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
190
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
260
継続モナドとリアクティブプログラミング
yukikurage
3
490
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.4k
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
480
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
170
Featured
See All Featured
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Building Applications with DynamoDB
mza
96
7.1k
The Cult of Friendly URLs
andyhume
79
6.9k
Designing for Performance
lara
611
70k
Abbi's Birthday
coloredviolet
3
8.6k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
320
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
30 Presentation Tips
portentint
PRO
1
350
Marketing to machines
jonoalderson
1
5.6k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Transcript
ニジエチューニング11月 2014/12/02 インフラボランティア:
あんただれ • 名前 ◦ ٩( )( )۶とか₍₍⁽⁽(◌ી( ・◡・ )ʃ)とか ◦
匿名ボードだとインちゃんと呼ばれてる • インフラ・バックエンドのボランティアスタッフです • 2014/03/18にJoin • 最近ニジエオフィスで絵を教えてもらいました ◦ みんなうまくてやばい TwitterID作ったんでフォローしてね!@nijieinfra
前回までのあらすじ • DBのリソースが食いつぶされる • 負荷・速度対策として ◦ (極めて不本意ながら)サーバ増設・スケールアップ ◦ ESIを始めとしたアグレッシブなキャッシュ ◦
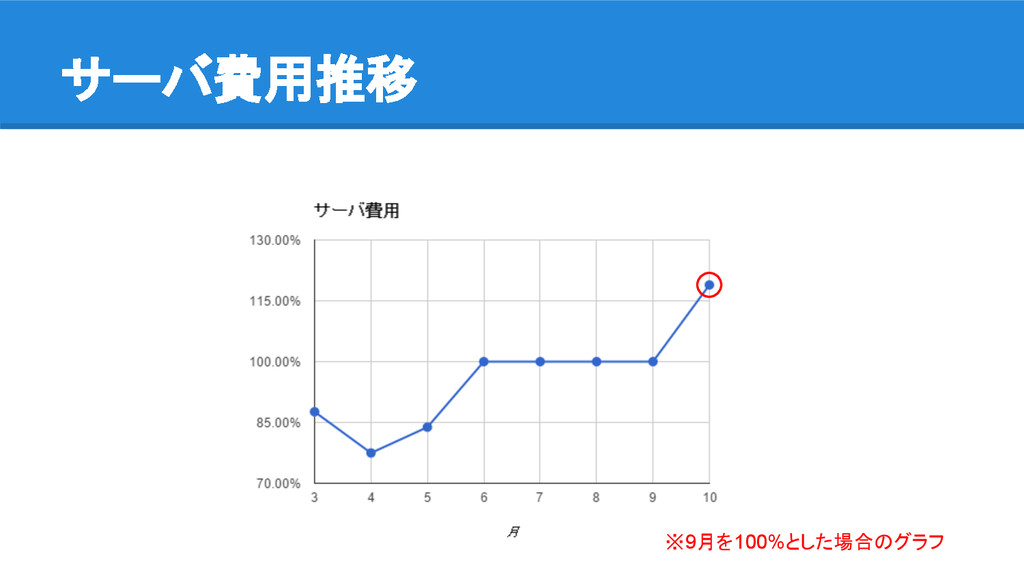
slowqueryつぶし ◦ などなど • 10月のサーバ費用は前月比で18.9%増
サーバ費用推移 ※9月を100%とした場合のグラフ
前月比18.9%増(!) 遺憾の意を表する。
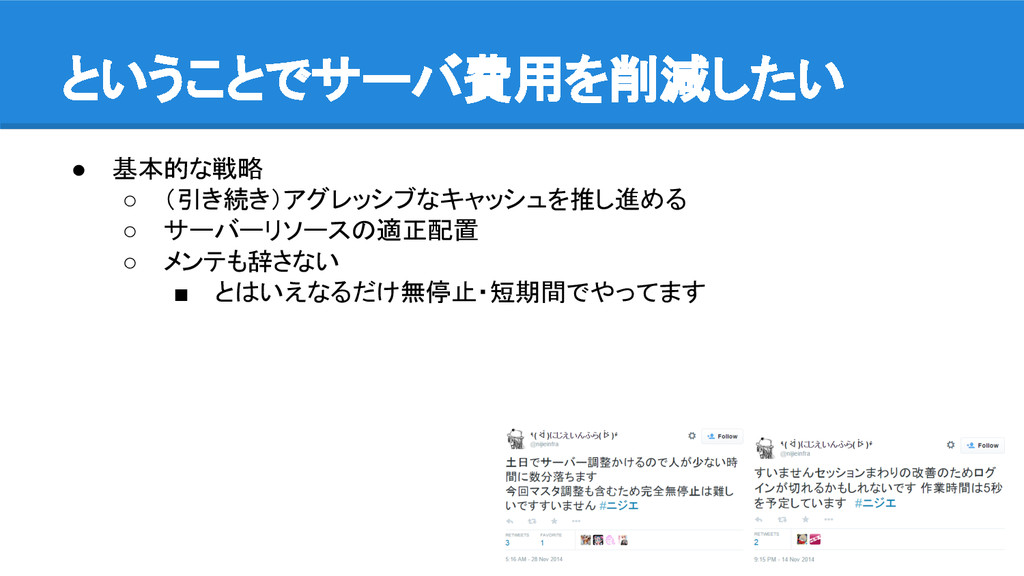
ということでサーバ費用を削減したい • 基本的な戦略 ◦ (引き続き)アグレッシブなキャッシュを推し進める ◦ サーバーリソースの適正配置 ◦ メンテも辞さない ▪
とはいえなるだけ無停止・短期間でやってます
サーバリソースの適正配置ってなに? • たとえばレスポンスタイムが遅延している場合 ◦ webサーバ(ws)を増やせばいいのか? ◦ dbサーバ(db)増やせばいいのか? ◦ キャッシュサーバを増やす? いくつかのシナリオで考えてみよう
wsを増やした場合 • 実際はdbサーバがボトルネックだった場合 ◦ 例えると高速が事故渋滞 (slowquery頻発)していて詰まっているのに 更に車(ws)を増やせば目的地(レスポンス)に速くつくだろう(?) ▪ そんなわけない ◦
slowqueryが頻発している状態で更にリクエストを受け付けるような事をすれば更にパフォーマ ンスは落ちる ▪ 単純にリソースの食いあい ▪ 更に遅くなる ▪ connection数がいっぱいいっぱいに
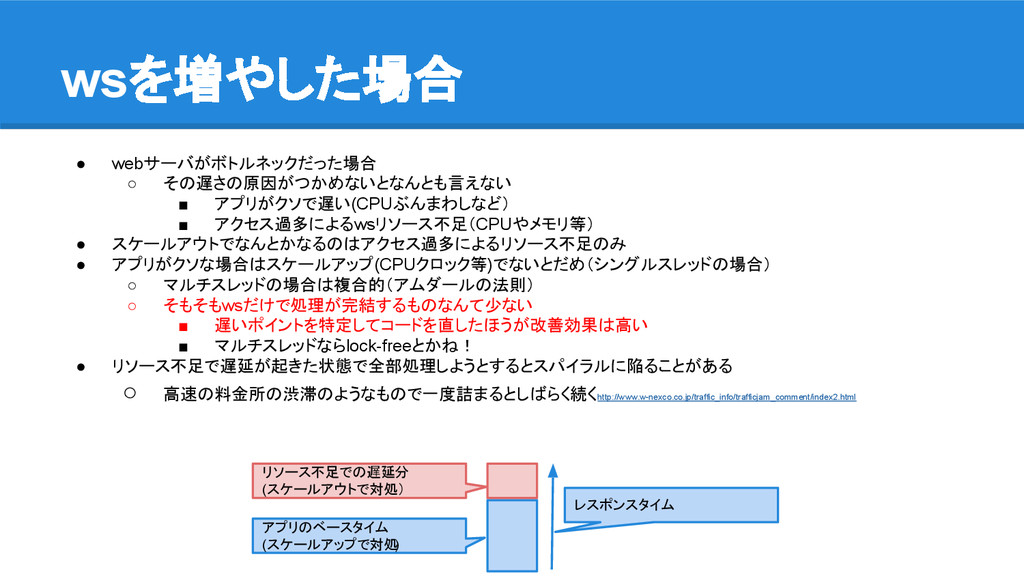
wsを増やした場合 • webサーバがボトルネックだった場合 ◦ その遅さの原因がつかめないとなんとも言えない ▪ アプリがクソで遅い(CPUぶんまわしなど) ▪ アクセス過多によるwsリソース不足(CPUやメモリ等) •
スケールアウトでなんとかなるのはアクセス過多によるリソース不足のみ • アプリがクソな場合はスケールアップ(CPUクロック等)でないとだめ(シングルスレッドの場合) ◦ マルチスレッドの場合は複合的(アムダールの法則) ◦ そもそもwsだけで処理が完結するものなんて少ない ▪ 遅いポイントを特定してコードを直したほうが改善効果は高い ▪ マルチスレッドならlock-freeとかね! • リソース不足で遅延が起きた状態で全部処理しようとするとスパイラルに陥ることがある ◦ 高速の料金所の渋滞のようなもので一度詰まるとしばらく続くhttp://www.w-nexco.co.jp/traffic_info/trafficjam_comment/index2.html リソース不足での遅延分 (スケールアウトで対処) アプリのベースタイム (スケールアップで対処 ) レスポンスタイム
• 表のように一度「リクエスト数>処理可能数」が起きると その後「リクエスト数<処理可能数」となっても しばらくキューが捌けない ◦ 場合によっては飽和してしまってどうしようもなくなる=スパイラル • この状態に陥ると他サーバのリソースを食いつぶして 連鎖障害になることもある ◦
db接続を維持すればコネクション数等を消費 ◦ 更に他のwsやbatchでMaxConエラーでFailしていく • ついでにいうとCPU不足でこの状態に陥った場合に 処理数をあわてて増やそうと MaxClientを増やすと処理可能数はより減る事が多い ◦ prefork動作時のコンテキストスイッチのコストなど • なるだけこういうのを避けるためにも適切な設定・予備リソースの読みが必要 • 一瞬「リクエスト数>処理可能数」になるのを許容するにしてもどれだけ耐えるか検討するべき ◦ リクエストを細かくみてみると結構スパイクしている ◦ このような突発的な負荷を緩和するのにキャッシュは非常に有効 スパイラル、避けたい オーバーした時間 実際遅延した時間
• 実際はwsがボトルネックだった場合 ◦ 単純に無意味 ◦ システムは川のようなもので上流(ws)で詰まってしまえば下流(db)を如何 に豪華にしてもコストが掛かるだけで無意味 ◦ 他にもニジエの規模だとまず無いんですが・・・ ▪
dbは通常master-slaveで動かしていて増やす場合はslaveを増やす ▪ slaveの台数がめっちゃ多くなるとレプリケーションのトラフィックで masterがアップアップに・・・・なんてこともありうります dbを増やした場合
• dbがボトルネックだった場合 ◦ 基本的には改善される ◦ もちろんwsと同じようにぶんまわしな slowqueryはスケールアウトでは難しい ▪ さっさとslowqueryを直すべき dbを増やした場合
• キャッシュを増やしてよくなるのはキャッシュが足りてない時のみ • 1GB中100MBしかつかってないのに更に 1GB増やしても全くの無意味 • そもそもキャッシュというものはなくても動くのが理想的 キャッシュサーバを増やした場合
• あくまで僕の考えですが・・・ • 負荷を下げるためというのがそうですがその負荷の性質を見誤ってはいけない ◦ ピークタイムで更に突発的に更に負荷が上がった時のアブソーバー的役割 ▪ キャッシュによる負荷軽減のお陰でピークでの予備リソースを少なくすることが出来る ◦ 通常負荷を吸収して劇的なコスト削減をするためのものではない
• キャッシュは吹き飛ぶもの ◦ キャッシュが無いとまともに動かないシステムだとキャッシュが温まるまで断続的に障害が起きる ◦ ピークで吹き飛んでも多少レスポンスが遅くなる程度でサービスが出来る必要がある ▪ 高ヒット率のキャッシュだと吹き飛んでも復帰までの時間が短いためリスクが低い(温まる時間が短い) • スパイラルに陥る前に掃ける ▪ つまりある程度キャッシュが温まるまで耐えられるキャパシティプランニングをするだけでよい ▪ 今のニジエはピークタイム中にキャッシュ吹き飛んでも問題なく耐える(遅くなるけど) • というか偶に飛ばしてる(昼間のお仕事の都合上作業できる時間が限られてる) ▪ 同時にwsが死んだりとかの多重障害はまた話は別ですが可能性は低い(そこまでコストは・・) • どうしてもコストの都合上全部吹き飛ぶと困るものもある ◦ 画像のサムネ生成がそれに当てはまる ◦ キャッシュを多段構成にすることでひとつ吹き飛んでもほかで吸収するような仕組みにしている ◦ もちろんリスクは有る ▪ 全段吹き飛んだ場合は復帰まで時間がかかる ◦ ただその可能性を勘案した場合十分負えるリスクであることが重要 • もちろん速くするためというのもあります なぜキャッシュするのか
• 例えばwsを増やしたことで下流のdbによりリクエストが行くことになって 今度はdbが詰まってしまうということもありうる • エンジンだけめっちゃ高性能にしてタイヤそのままとかを想像してみてください ◦ 一点豪華主義はコスパが悪い上にシステム性能が悪くなる可能性がある ◦ ほかもきちんと見る必要がある •
システムは連続している 複合的な要因
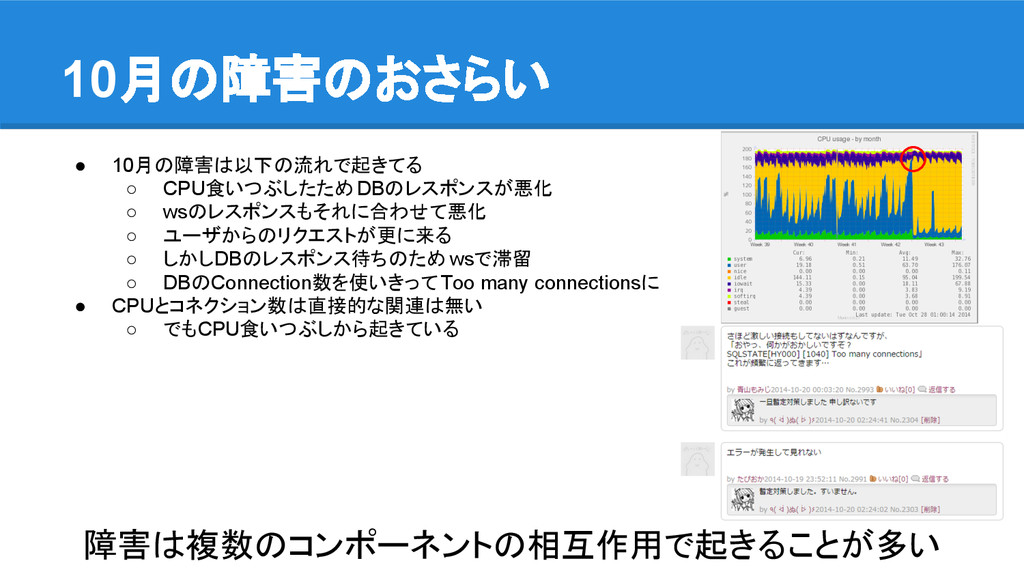
10月の障害のおさらい • 10月の障害は以下の流れで起きてる ◦ CPU食いつぶしたためDBのレスポンスが悪化 ◦ wsのレスポンスもそれに合わせて悪化 ◦ ユーザからのリクエストが更に来る ◦
しかしDBのレスポンス待ちのため wsで滞留 ◦ DBのConnection数を使いきってToo many connectionsに • CPUとコネクション数は直接的な関連は無い ◦ でもCPU食いつぶしから起きている 障害は複数のコンポーネントの相互作用で起きることが多い
• 結局のところシステムは非常に複雑に絡み合った有機体のようなものである • さっきのエンジンの話 • 一体どこが原初のボトルネックでそこを解決すると何処の負荷が上がるか といった検討が必要 • その上でwsを増やす、dbを増やすなどを行う必要がある •
キャパシティプランニングは単一コンポーネントだけに着目してはダメ ◦ オンプレであればラックの uplinkやコアswが落ちた時の影響範囲とかも考える ◦ 本職のほうだとDCがまるごと落ちたらとか考えることも有ります ◦ 結局のところどこまでコストとリスクを考えて出来る範囲で最善を尽くす • インフラ的な対処だけでは費用対効果の面で限界があるので アプリ等の改善も並行でやる必要がある 結局の所
• ボトルネックの調査と対策 • コードの改善+ws削減 • (先月分)dbのスケールアップ及び台数増設 • batchの重いクエリを隔離 • などなどなど(細かいの結構やってます)
今回やったこと
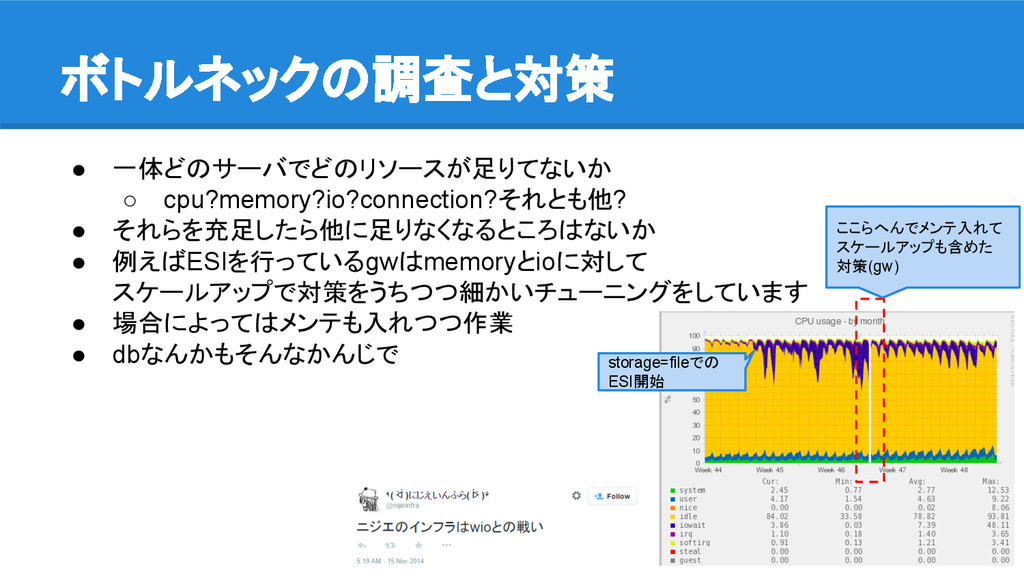
• 一体どのサーバでどのリソースが足りてないか ◦ cpu?memory?io?connection?それとも他? • それらを充足したら他に足りなくなるところはないか • 例えばESIを行っているgwはmemoryとioに対して スケールアップで対策をうちつつ細かいチューニングをしています •
場合によってはメンテも入れつつ作業 • dbなんかもそんなかんじで ボトルネックの調査と対策 ここらへんでメンテ入れて スケールアップも含めた 対策(gw) storage=fileでの ESI開始
• slowqueryの改善ももちろん • コードの改善とキャッシュを進めることでだいぶ軽くなった ◦ 高ヒット率のキャッシュを行うと吹き飛んでもすぐリカバリが出来る(重要) • もともとwsのリソースは足りていた+上記対策でピークタイムで-1台にしても 多少耐えれる程度の台数とした •
コスト削減おいしいです コードの改善+ws削減
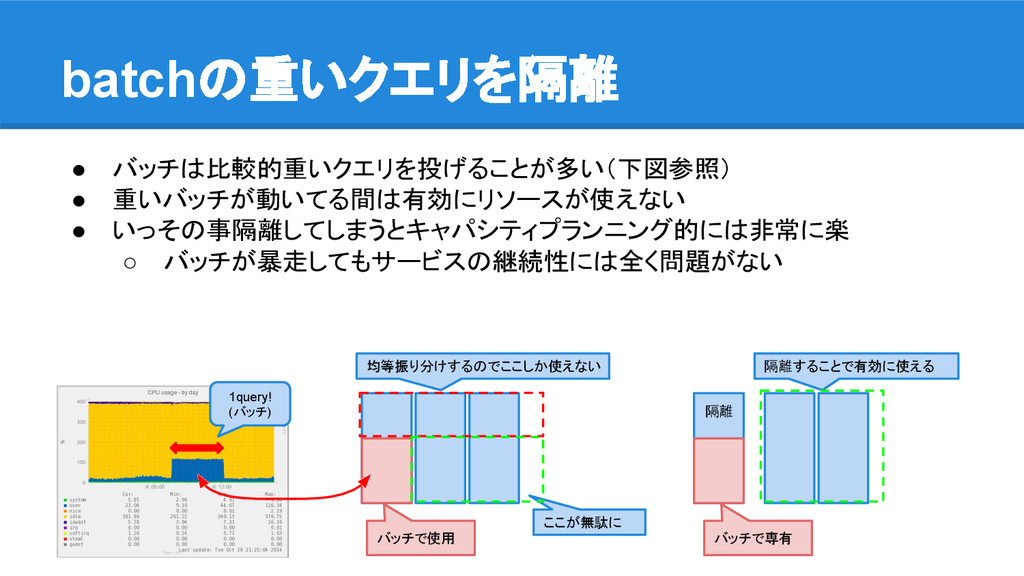
• バッチは比較的重いクエリを投げることが多い(下図参照) • 重いバッチが動いてる間は有効にリソースが使えない • いっその事隔離してしまうとキャパシティプランニング的には非常に楽 ◦ バッチが暴走してもサービスの継続性には全く問題がない batchの重いクエリを隔離 1query!
(バッチ) バッチで使用 均等振り分けするのでここしか使えない ここが無駄に 隔離することで有効に使える 隔離 バッチで専有
とまぁこんなことをやりました 他にも細々した改善をたくさん
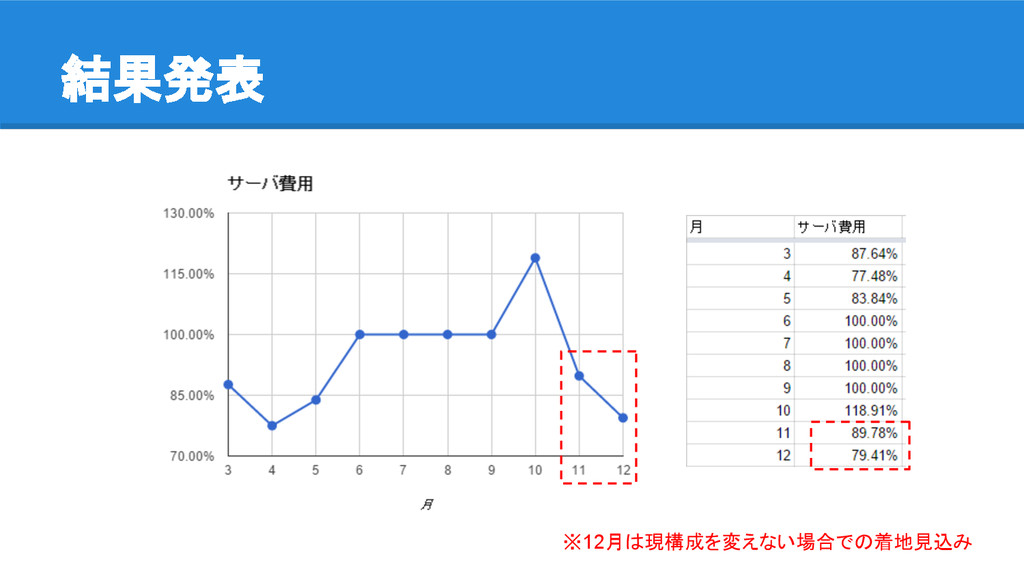
結果発表 ※12月は現構成を変えない場合での着地見込み
9月比10.2%削減 12月見込みだと20.6%削減
• 一時的に使ってる検証サーバや集約可能なのを考えると26.6%まで減る • 更に今見通しがほぼ立っている事をやれば30%以上の削減も可能 ◦ 単純に自分の手が足りてない・・・ ◦ 本業が今めっちゃ忙しいです わーいコスト減ったよー さらに
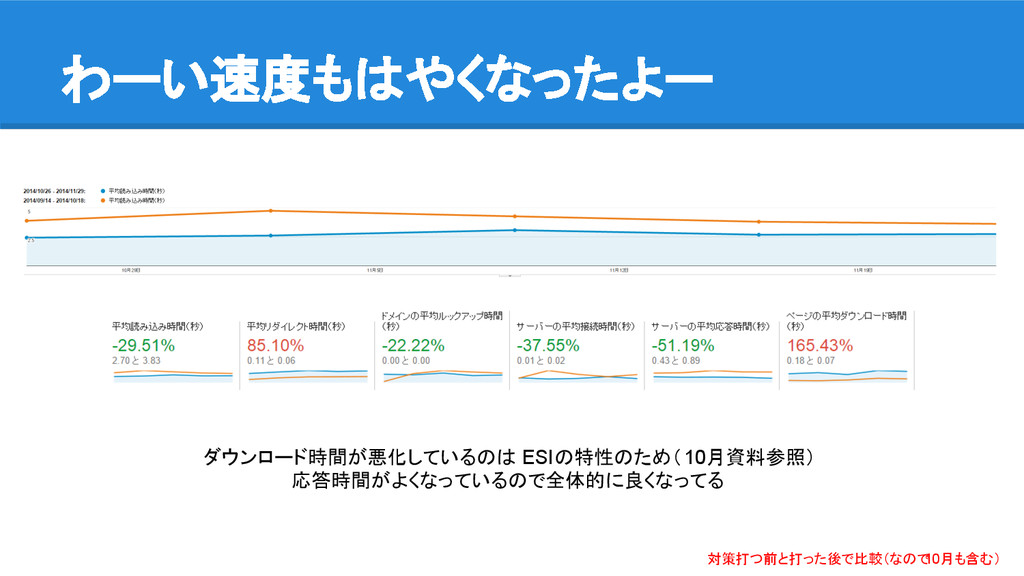
わーい速度もはやくなったよー 対策打つ前と打った後で比較(なので 10月も含む) ダウンロード時間が悪化しているのは ESIの特性のため(10月資料参照) 応答時間がよくなっているので全体的に良くなってる
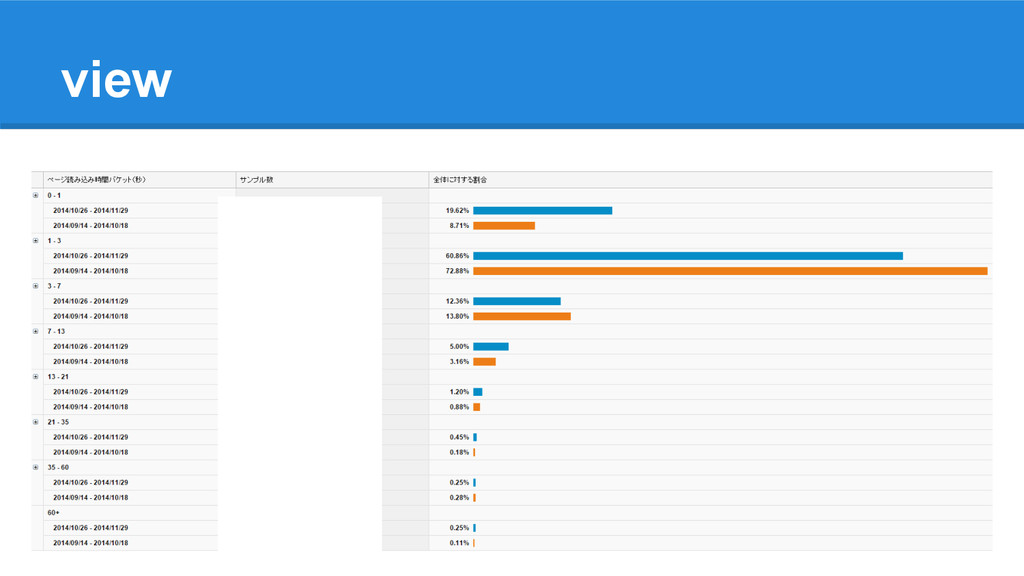
view
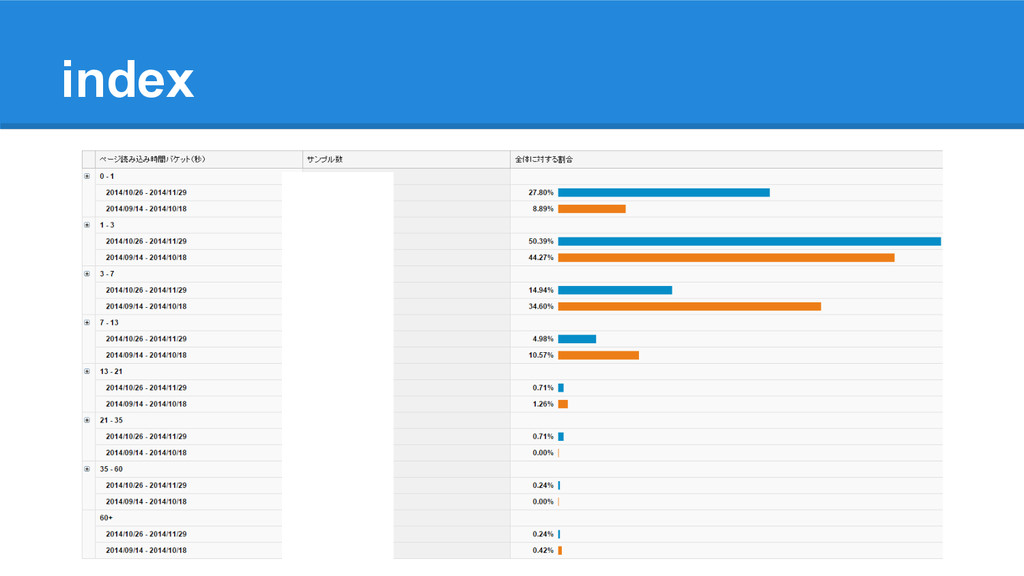
index
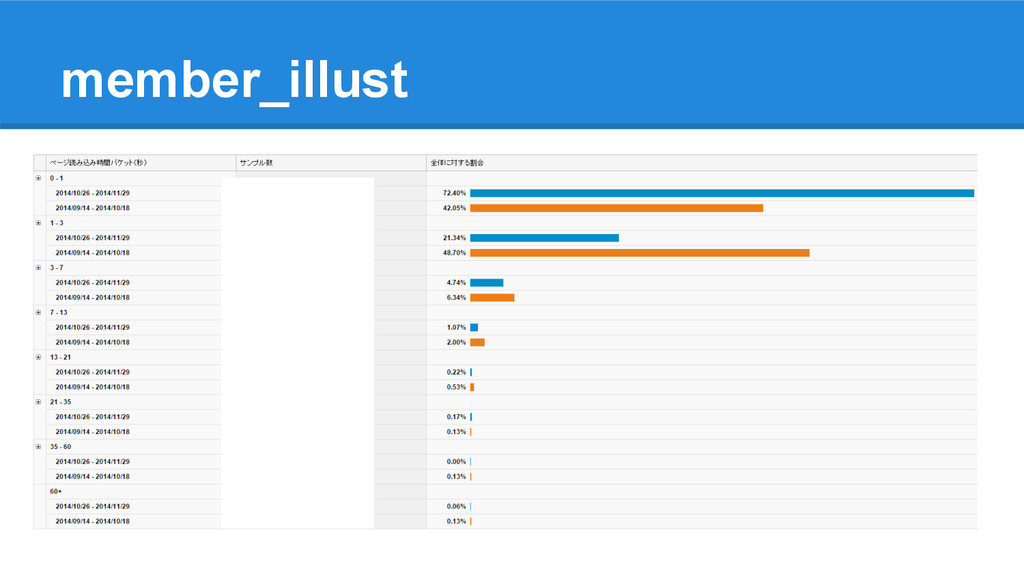
member_illust
• ほぼすべてのページで速くなった ◦ PVも増えてる • ただ一つだけ遅くなったページがあったが面白い結果に わぁい! よく言われるようにページ速度とPVは関係あるよ! 速くなったページ(抜粋) 遅くなったページ
やっぱ戦いはまだまだ続く
• もちろん今回もインフラ的な対策だけじゃできなかったよ! ◦ みんなありがとう! • ミドルウェアのバージョンアップによるパフォーマンス向上 • 構成管理 • 更なるコスト削減
• そろっとリファクタリングしたい まとめとかこのあとやりたいこととか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}