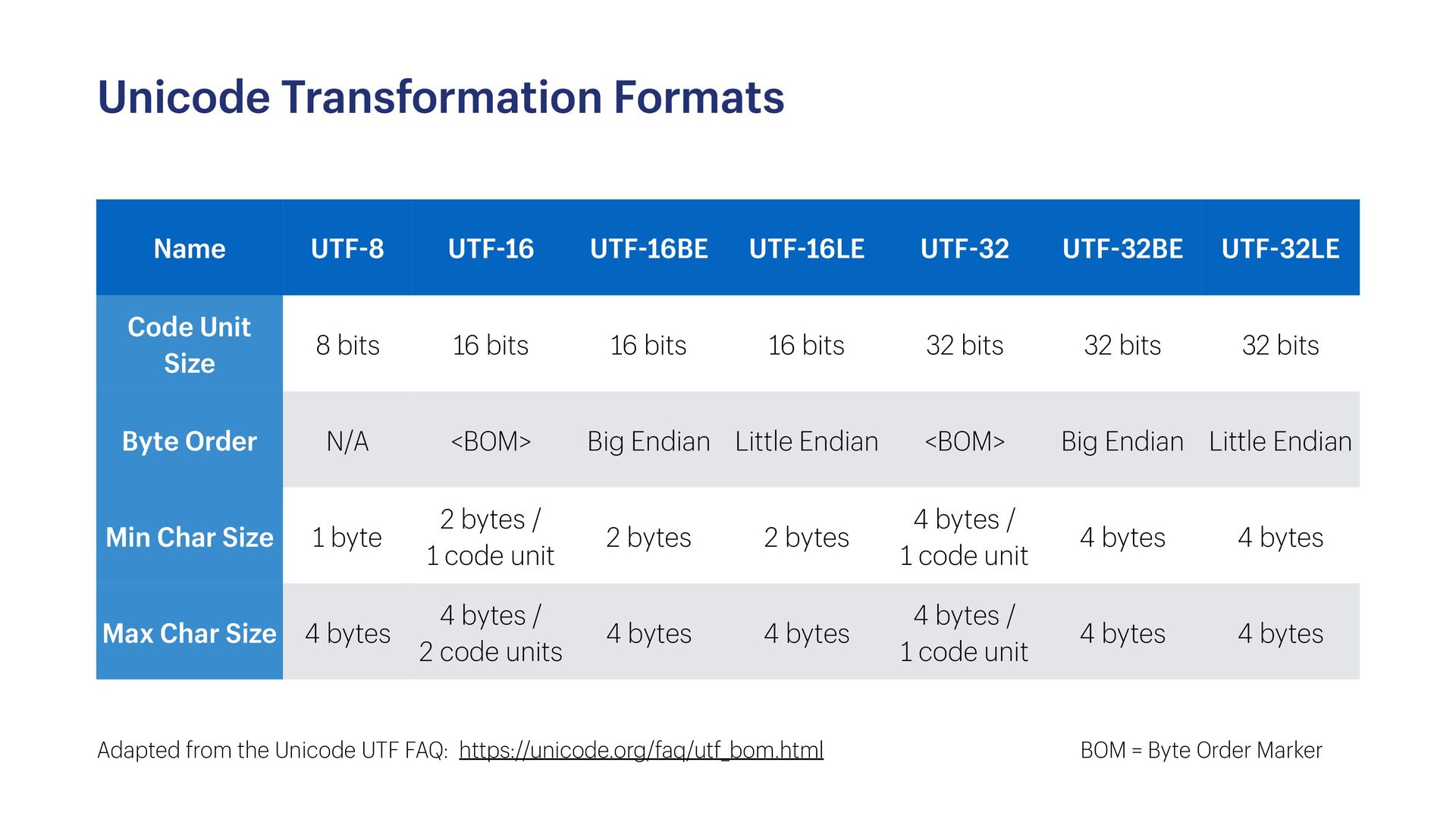
You’ve probably heard of UTF-8 and know about strings, but did you know that Ruby supports more than 100 other encodings? In fact, your application probably uses three encodings without you realizing it. Moreover, encodings apply to more than just strings. In this talk, we’ll take a look at Ruby’s fairly unique approach to encodings and better understand the impact they have on the correctness and performance of our applications. We’ll take a look at the rich encoding APIs Ruby provides and by the end of the talk, you won’t just reach for force_encoding when you see an encoding exception.
![Kevin Menard [email protected] GitHub: @nirvdrum — Twitter: @nirvdrum Mastodon: @[email protected]](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![s.bytes #=> [97, 98, 99] # encoding: US-ASCII s =](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_7.jpg){kind=link}
{kind=link}
![s.bytes [97, 98, 99] s.encoding #<Encoding:US-ASCII> s = 'abc'](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_9.jpg){kind=link}
![s.chars ["a", "b", "c"] s.bytes [97, 98, 99] s.encoding #<Encoding:US-ASCII>](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![s = 'très' s.bytes #=> [116, 114, 195, 168, 115]](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
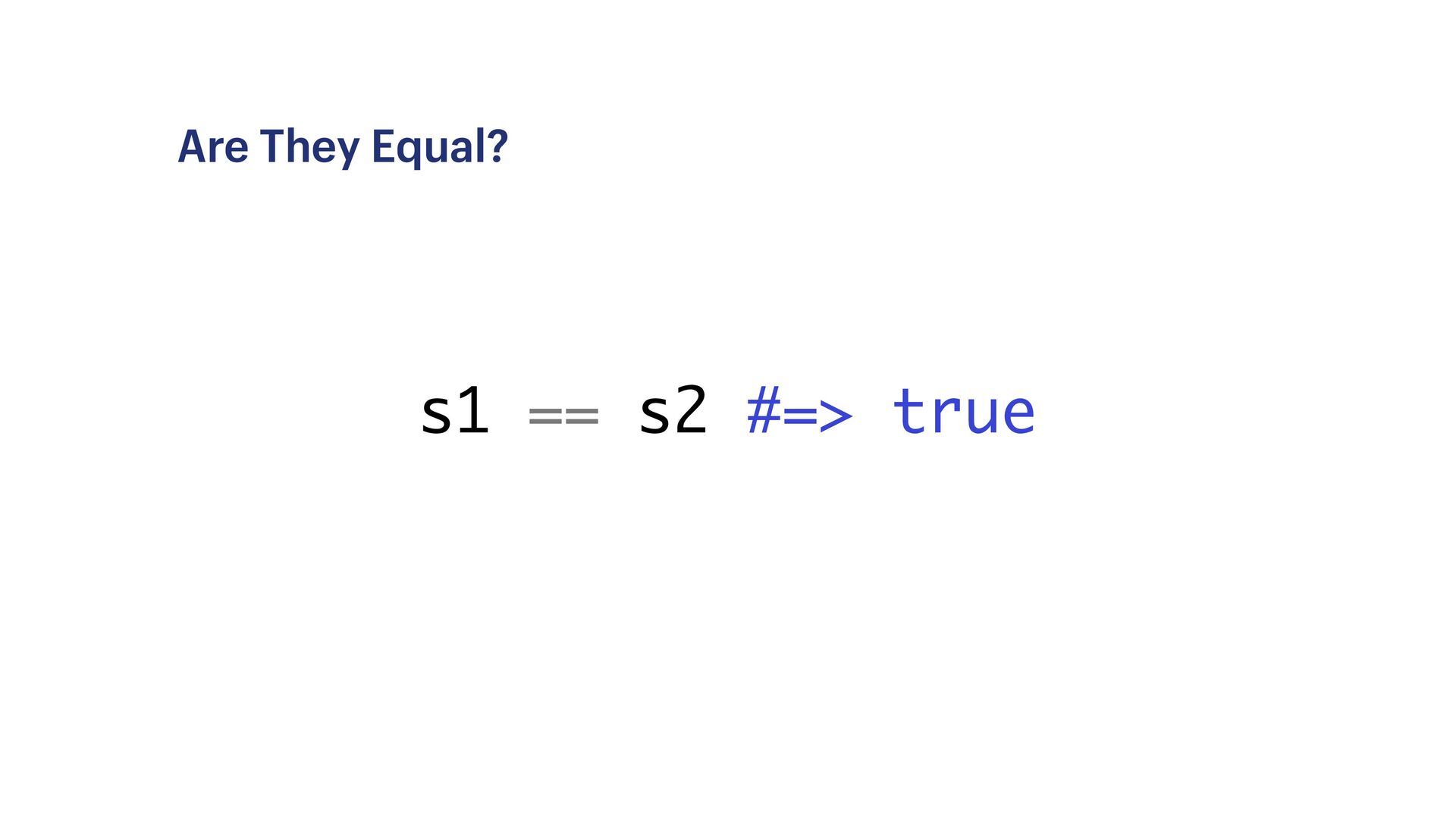{kind=link}
{kind=link}
{kind=link}
![Existential Dread s1.bytes #=> [194, 128] s2.bytes #=> [128]](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your time Kevin Menard [email protected] Twitter: @nirvdrum](https://files.speakerdeck.com/presentations/43cdb4102ed9424fa2a965c4c4d579a4/slide_67.jpg){kind=link}
{kind=link}