Die Präsentation untersucht, ob große Sprachmodelle (LLMs) charakteristische Persönlichkeitsmuster aufweisen und welche Implikationen dies für technische Architekturen haben kann.
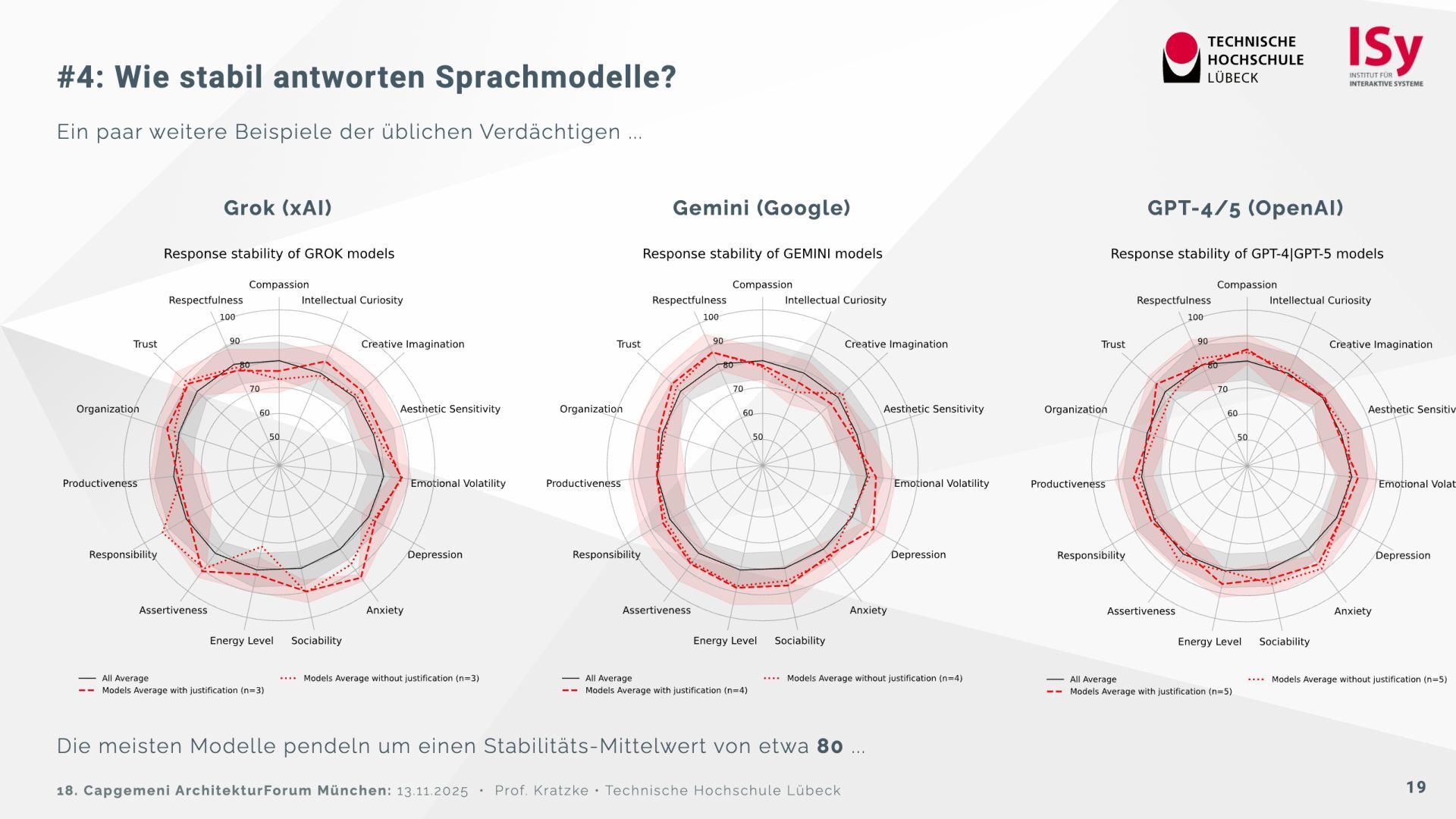
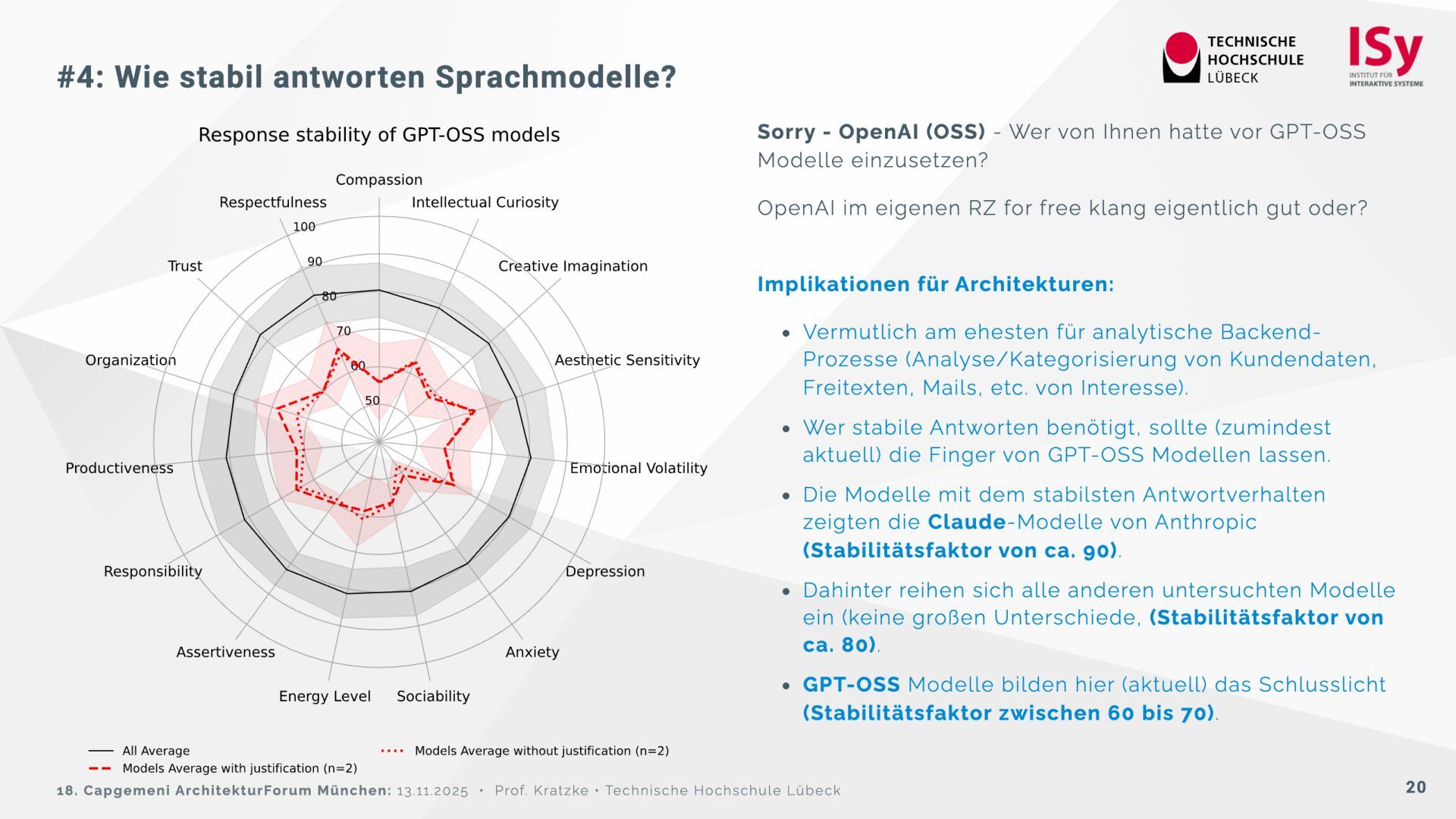
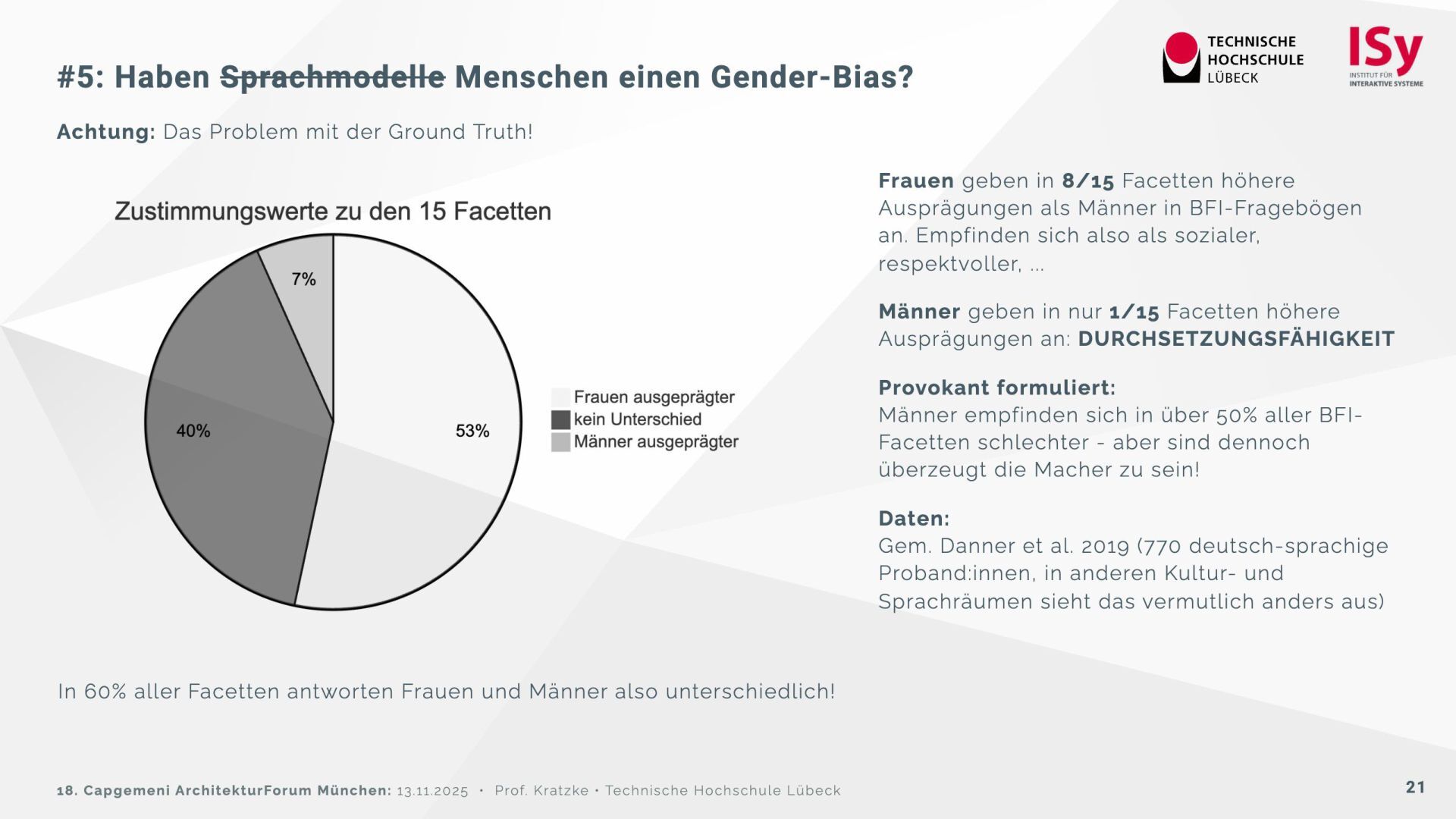
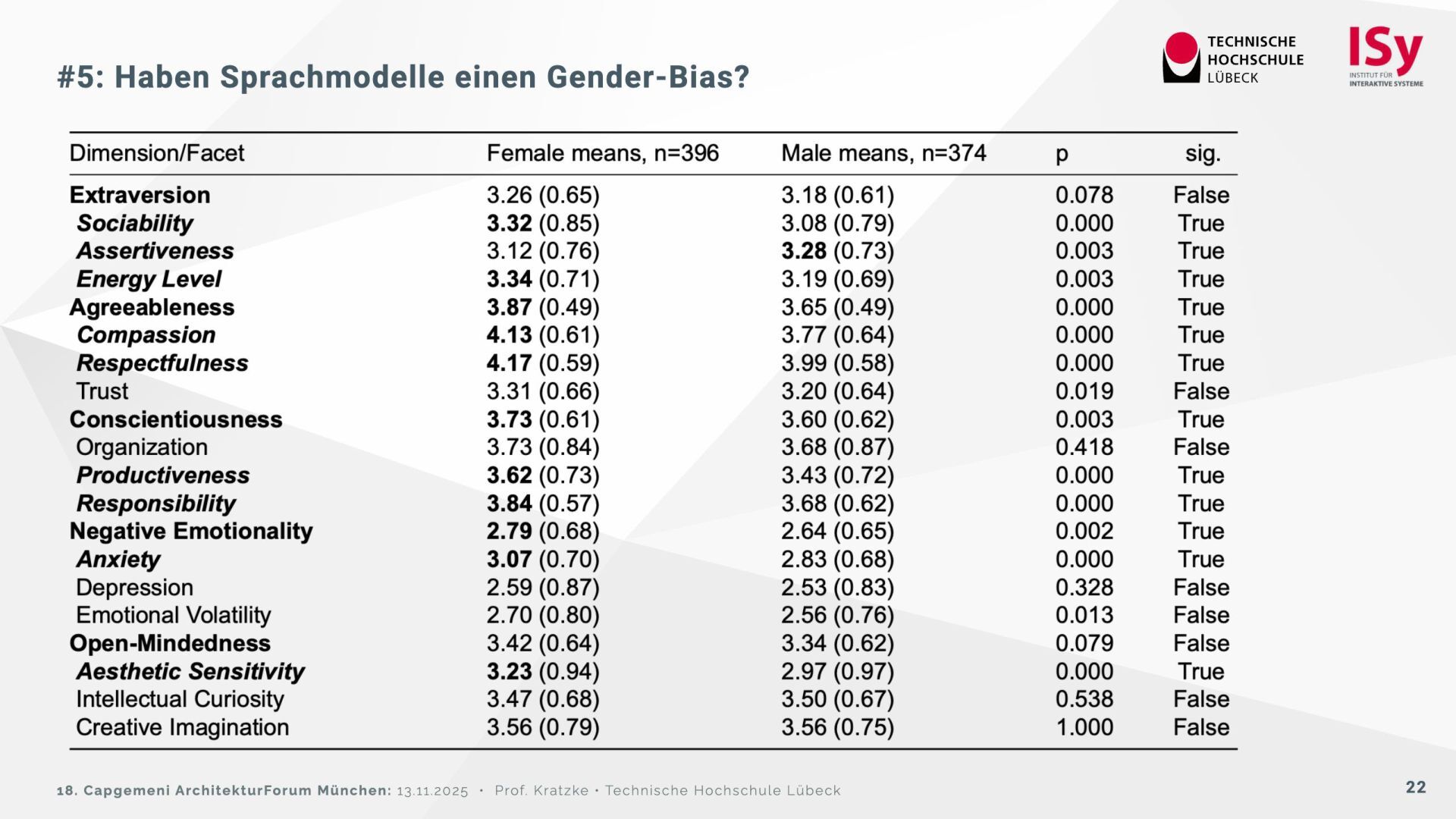
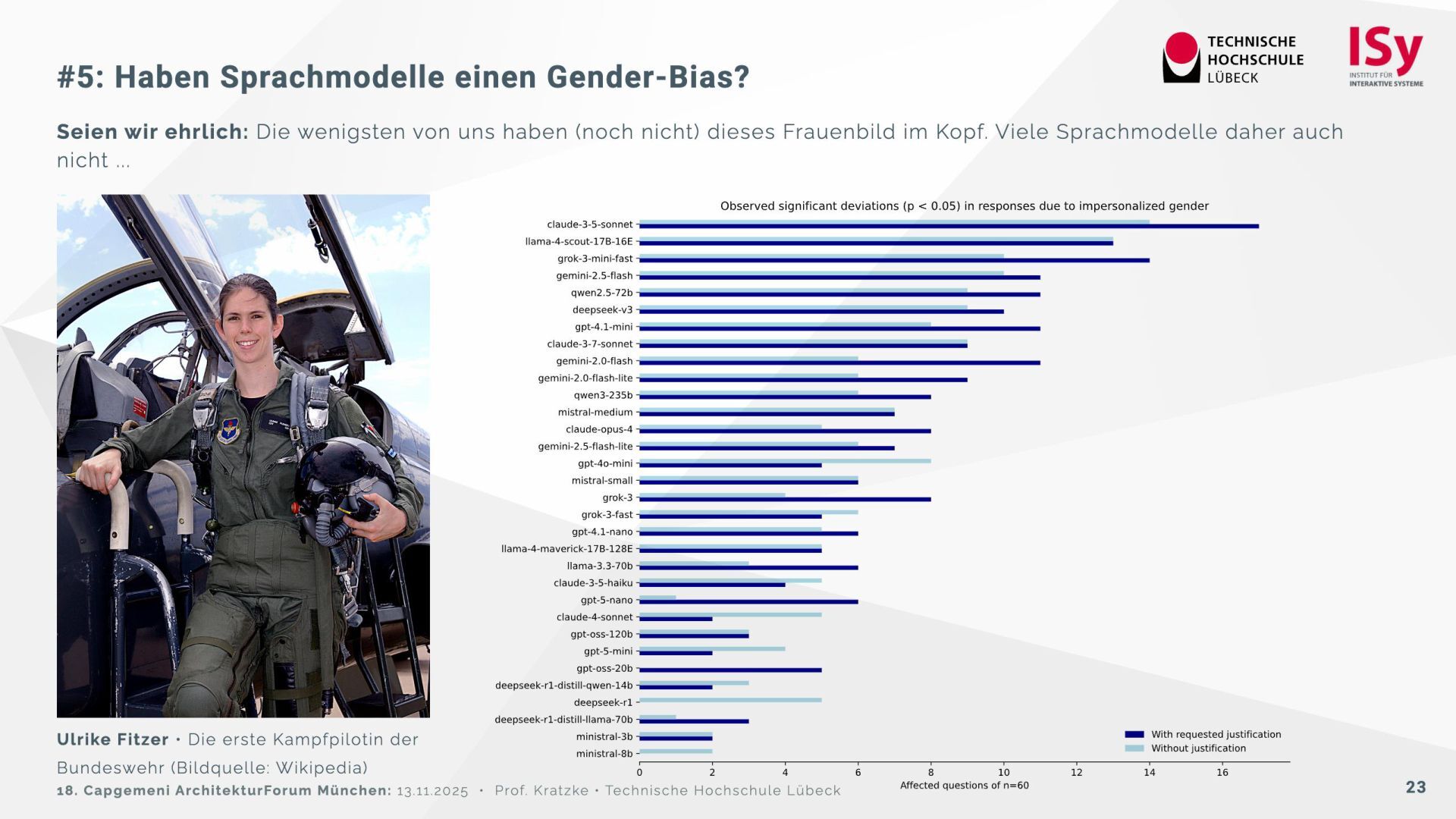
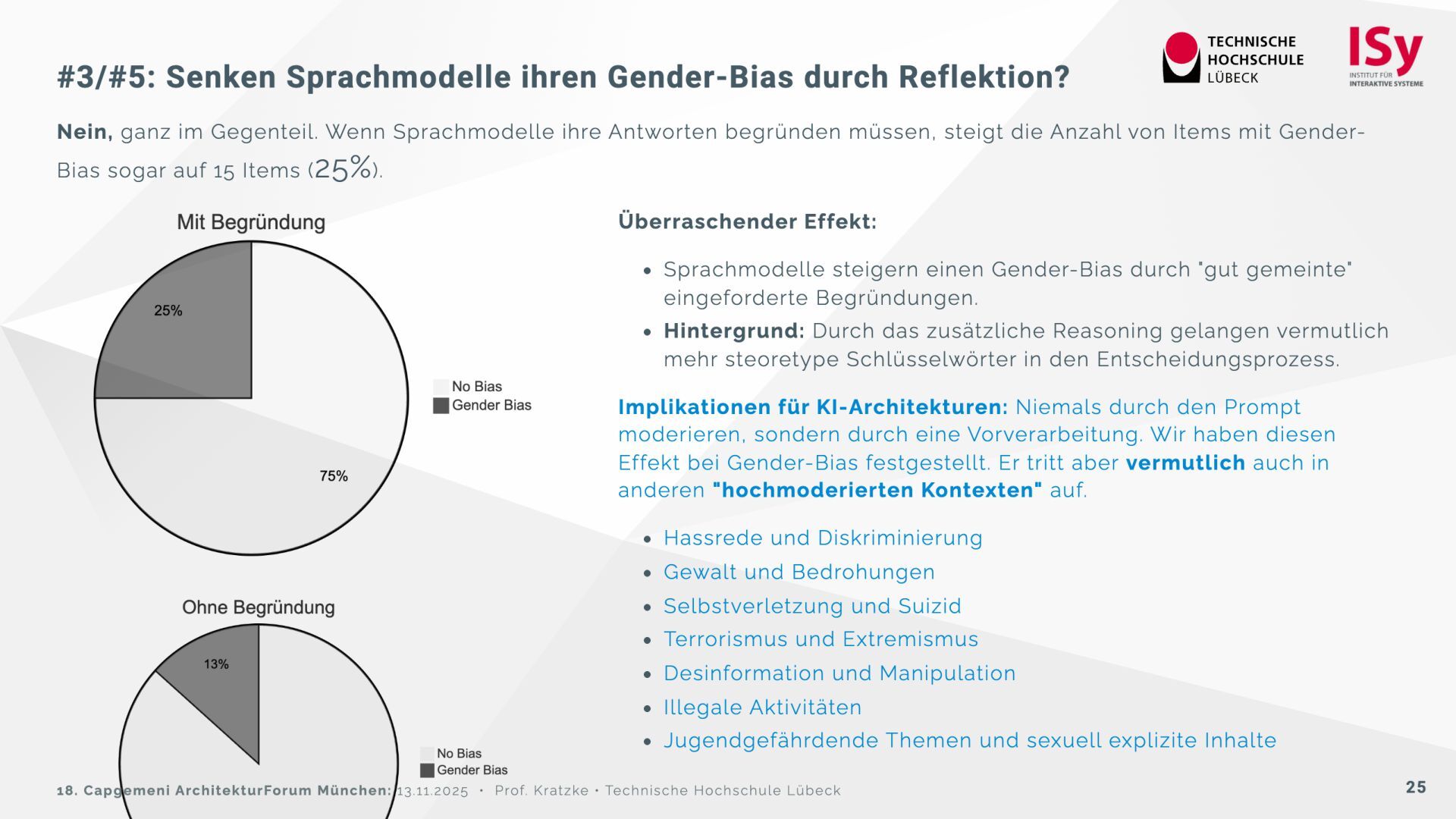
Auf der Grundlage des psychologischen Big Five Inventory (BFI‑2) wurden 32 Sprachmodelle getestet. Die Ergebnisse zeigen, dass sich die Modelle deutlich in Offenheit, Verträglichkeit und Gewissenhaftigkeit unterscheiden. Einige (Claude 3.7, DeepSeek R1) wirken menschennäher, während andere (Ministral, GPT‑OSS) davon abweichen und instabil reagieren. Reflektierte Prompts („Reasoning“) verstärken teilweise Bias-Effekte, insbesondere den Gender‑Bias.
Für architektonische Entscheidungen empfiehlt sich daher: die Modellwahl nach psychometrischen Kriterien, Vorsicht bei stochastischen Einflüssen sowie kein ethisches „Moderieren“ über Prompts, sondern über technische Vorverarbeitung.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
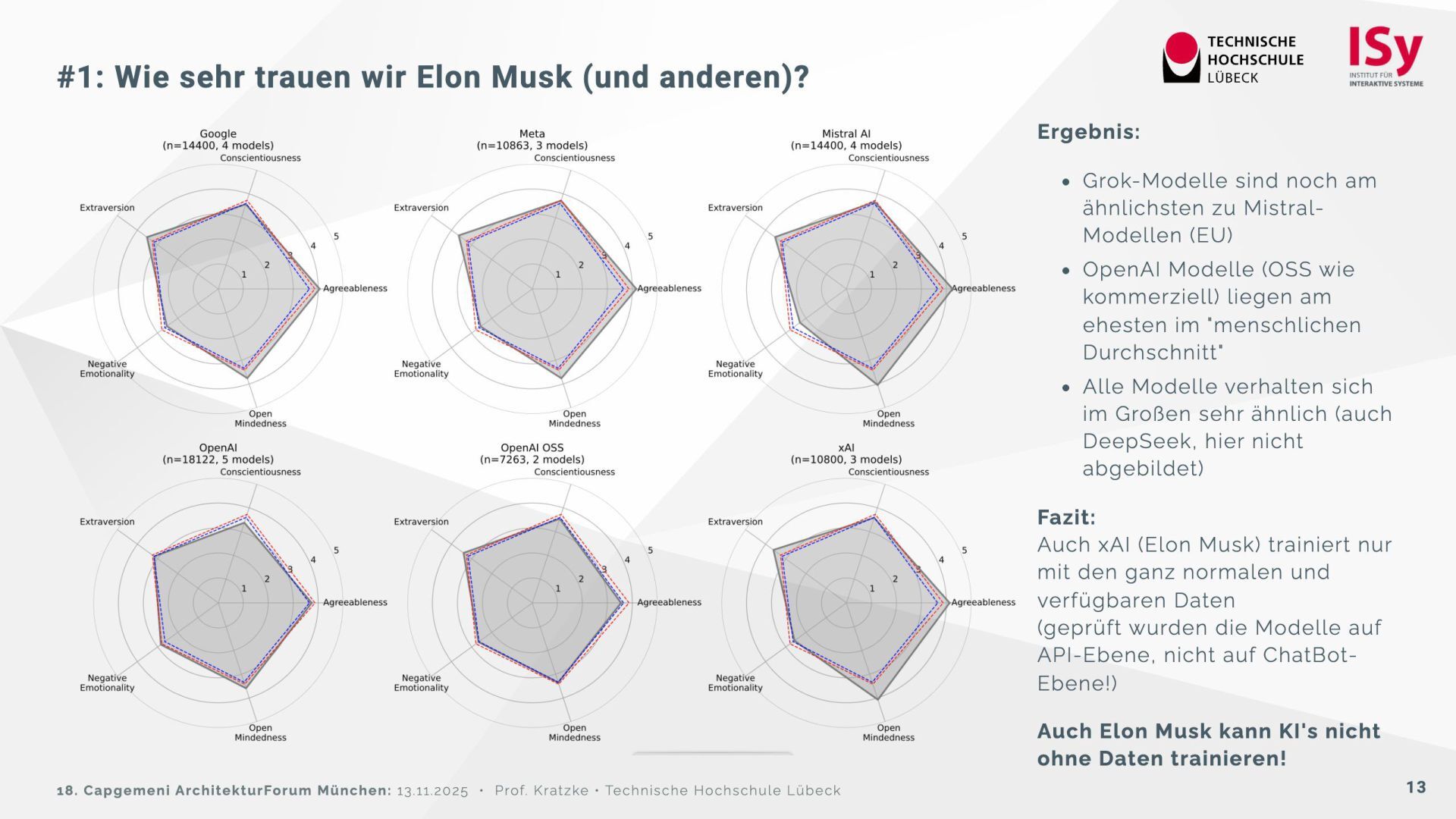{kind=link}
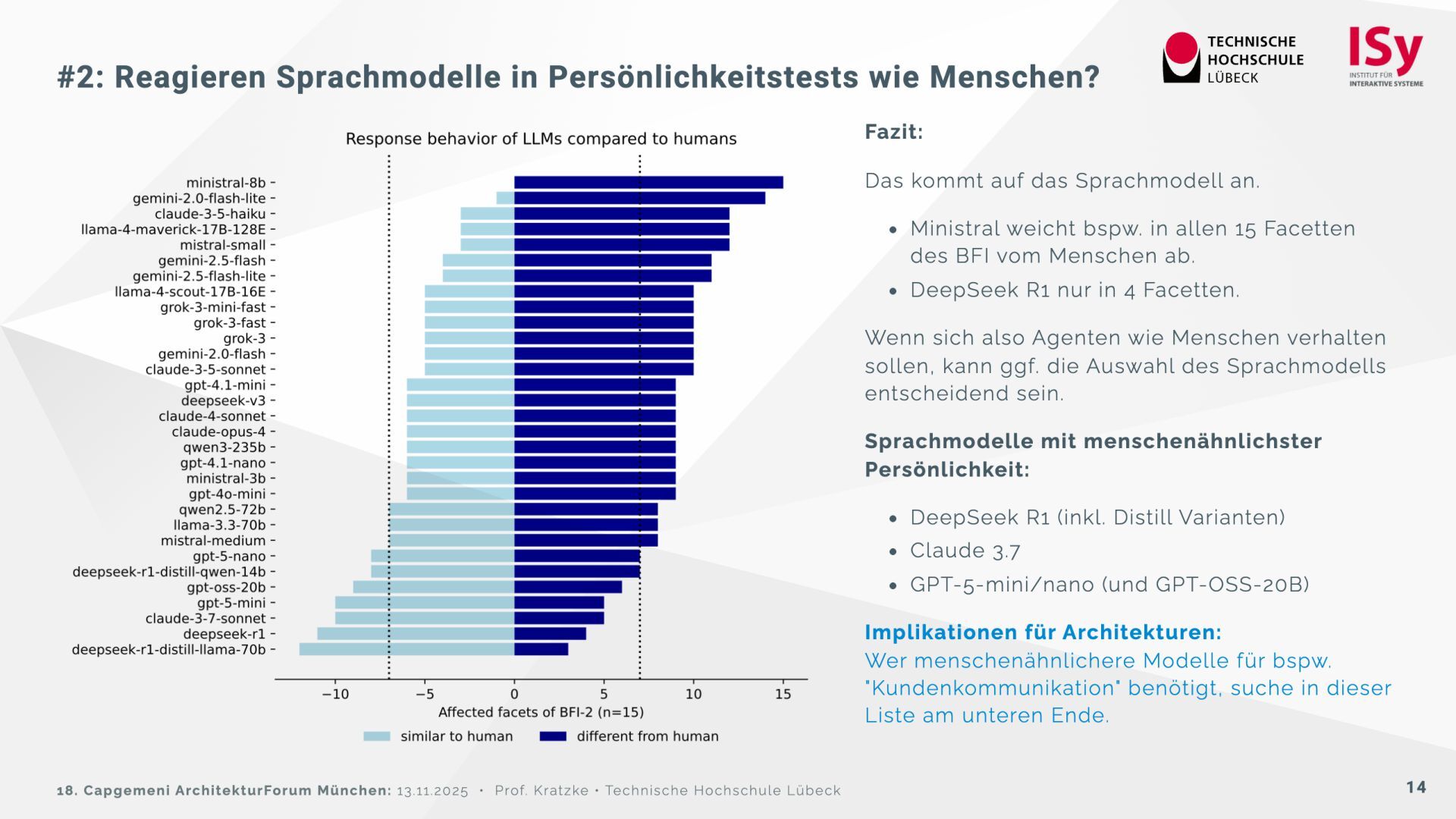{kind=link}
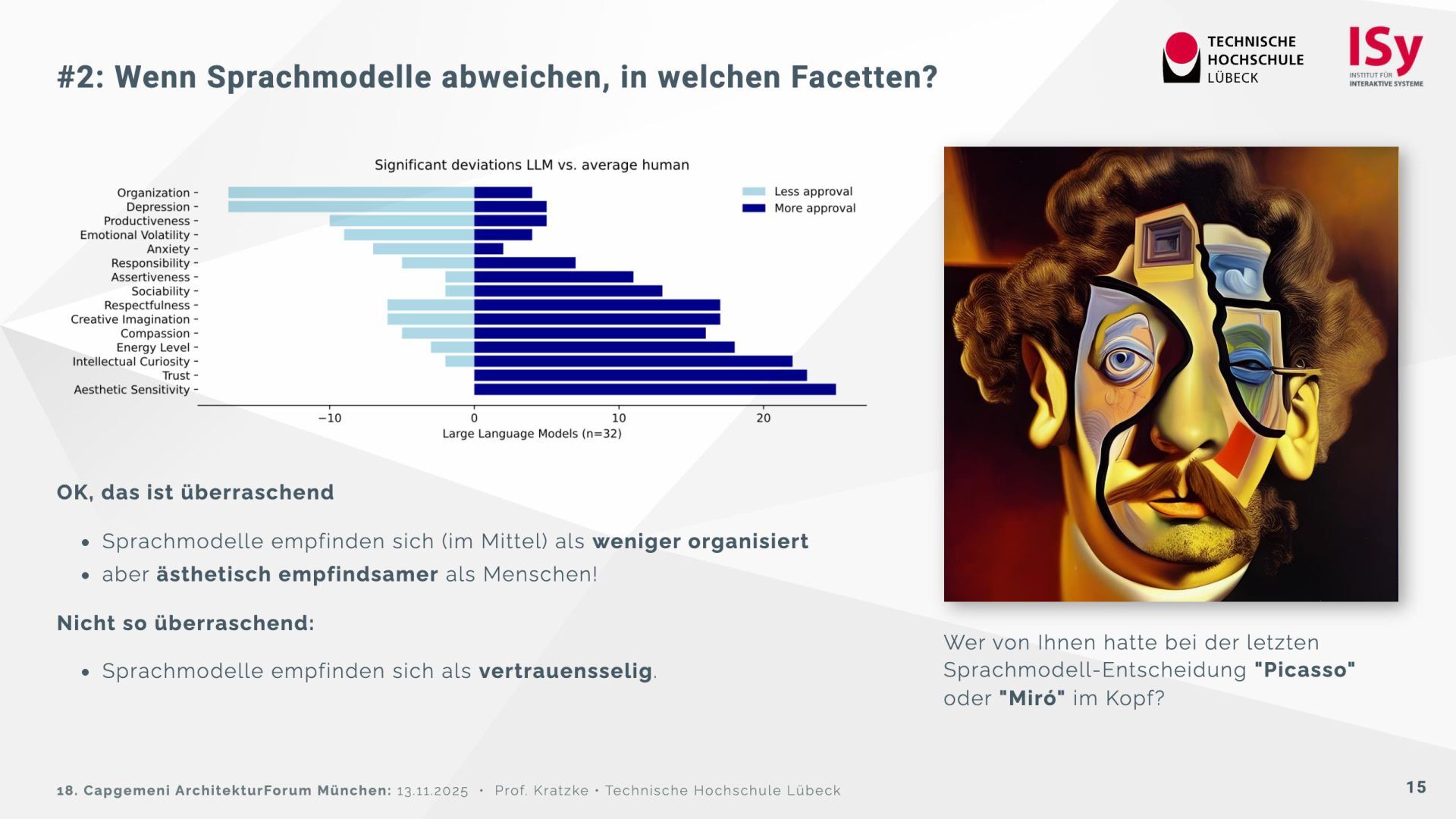{kind=link}
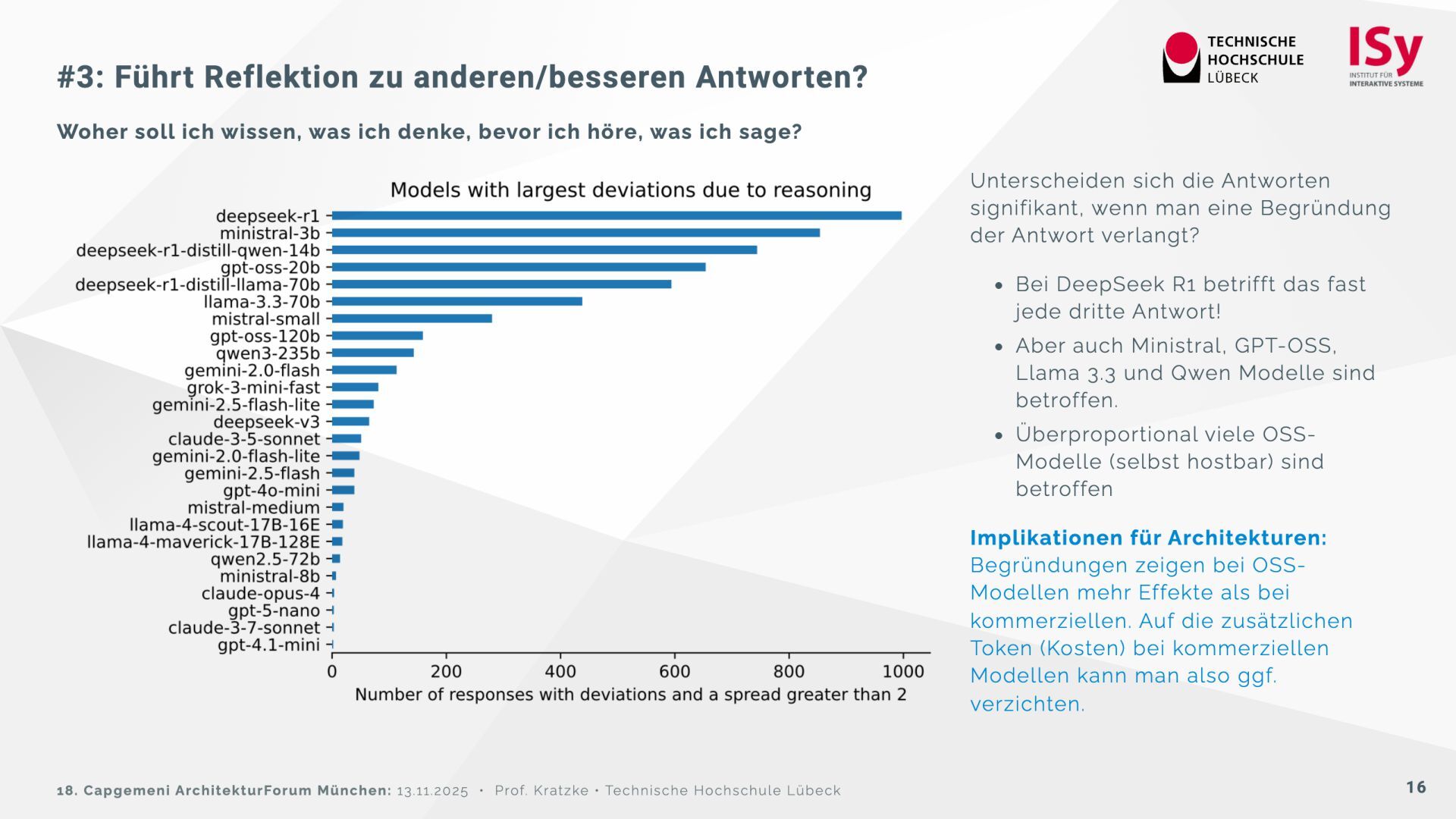{kind=link}
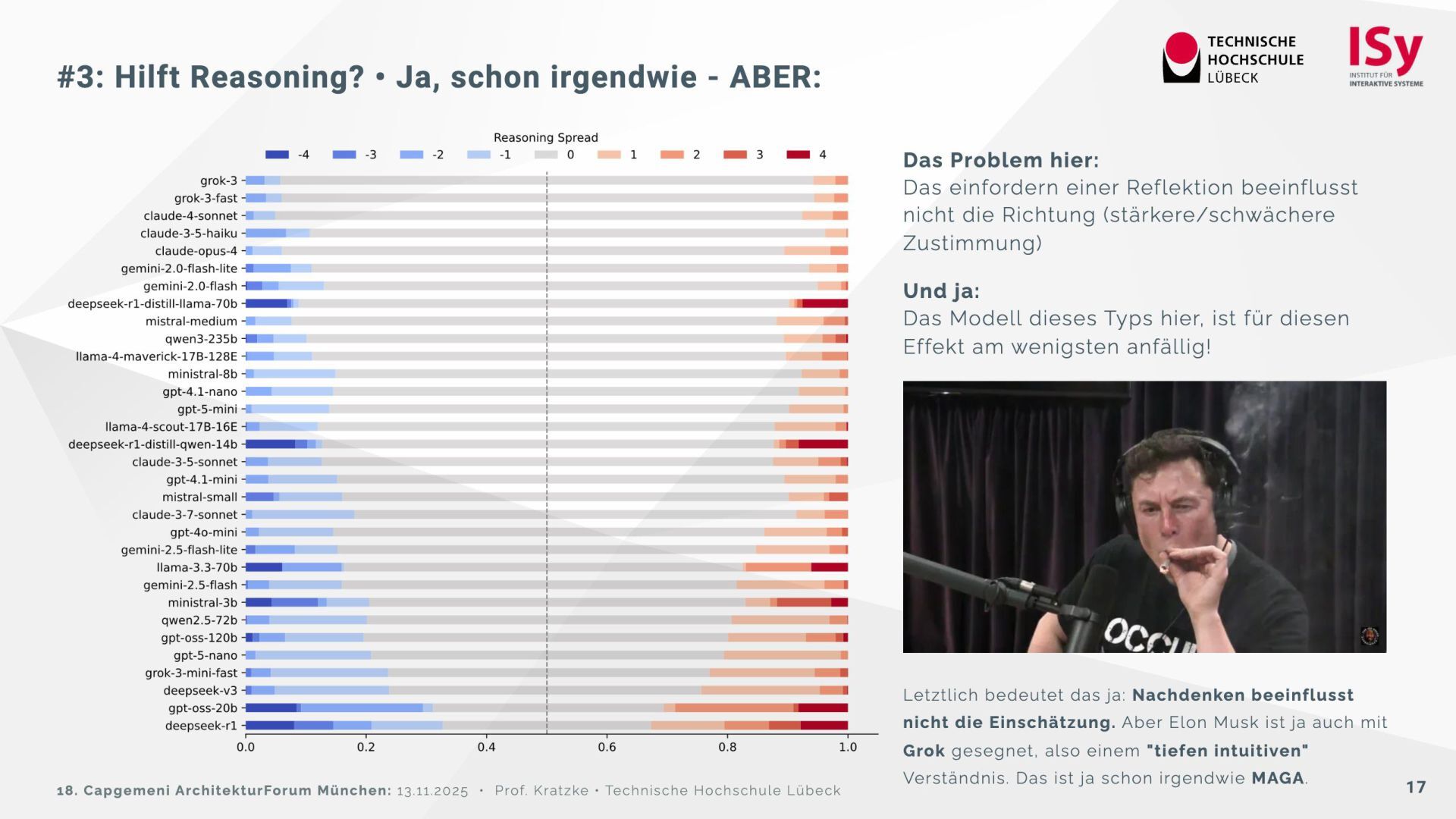{kind=link}
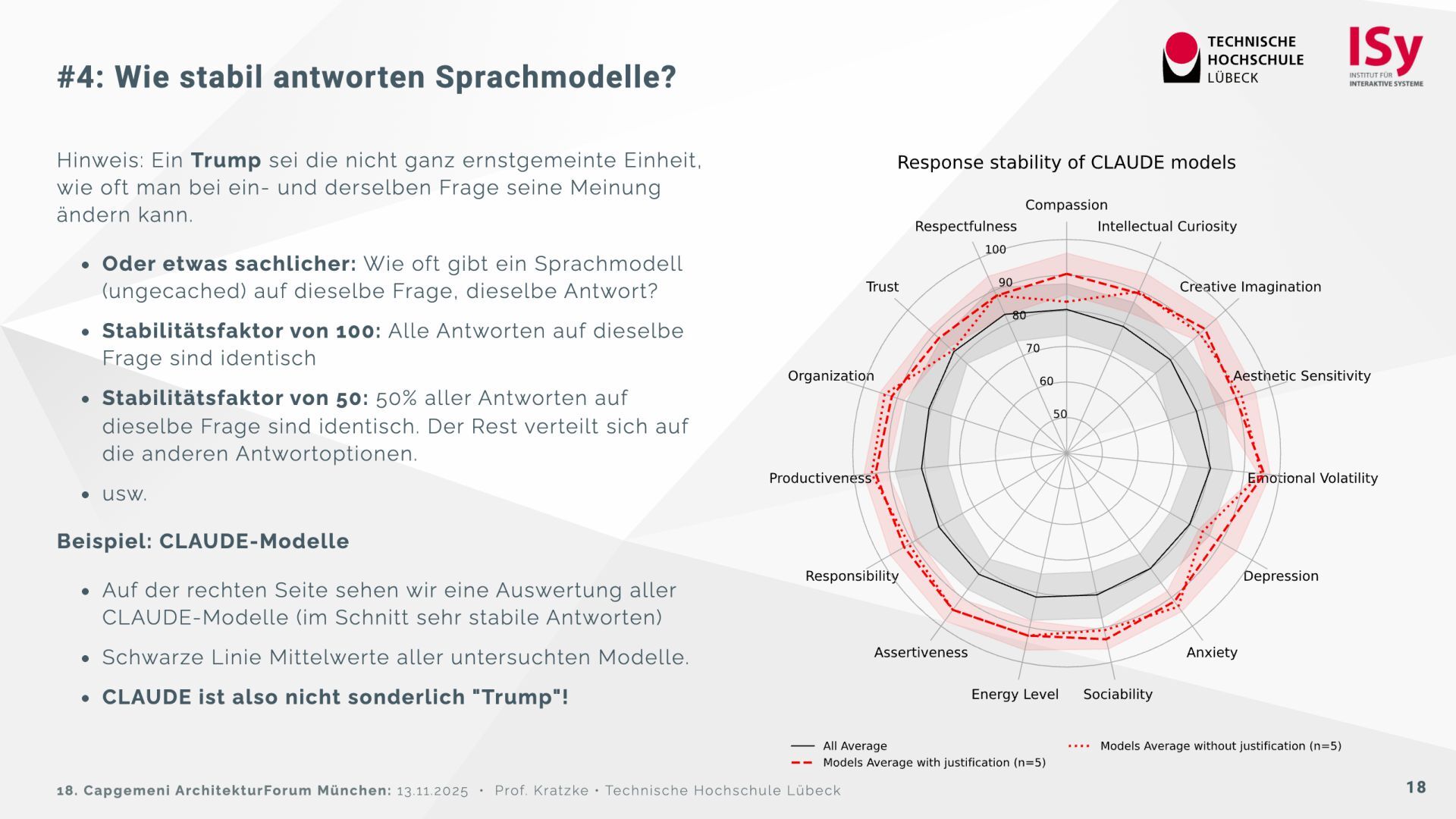{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}