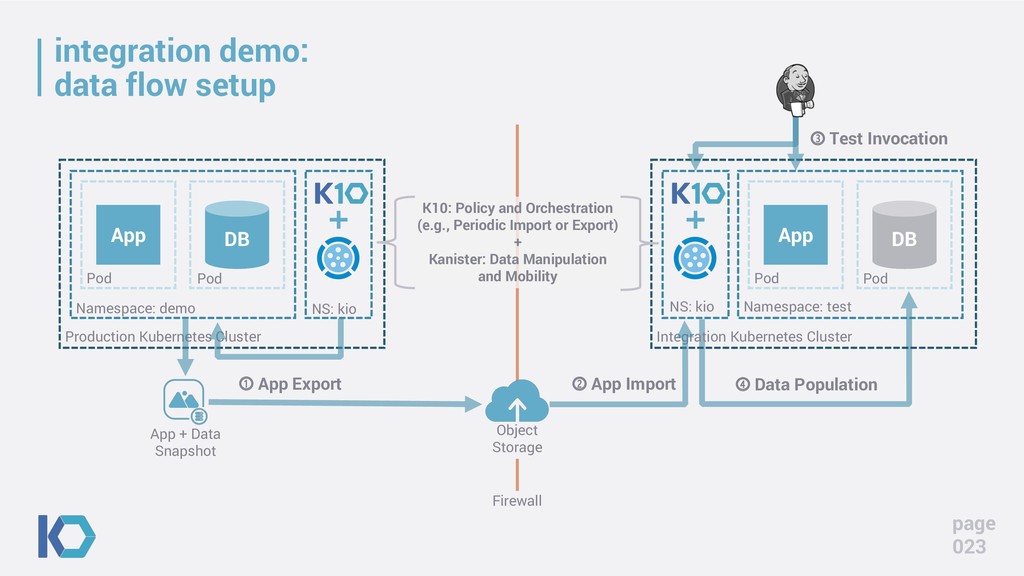
Adding data to both your CI and CD pipeline is one of the last steps of the DevOps journey and probably the scariest given the impact of getting it wrong. This talk covers how one can safely combine Kubernetes, Databases, and the CI/CD pipeline to actually make the process safer and more stable that the status quo today and, in today’s rapid deployment culture, make databases “shift left” and reduces DBA burnout. This includes leveraging techniques and building an open-source toolkit to deliver automated schema changes, cloning, sandboxing, masking for production-like data in staging, and rapid data movement for fast database creation. More importantly, this talk will show how these benefits can help with internal culture shift by breaking down silos and bringing in a traditionally conservative database group more fully into the automation fold.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}