Physical AI システム。 各エージェントは独自の 「性格」と行動戦略を持ち、 DINOv2 による視覚認識と ONNX 推論モデルで動作します。 🗺 Rex Explorer Persona Agent 🏠 Lily Homebody Persona Agent 👥 Marco Social Persona Agent 💼 Cole Businessman Persona Agent 📸 Elena Tourist Persona Agent
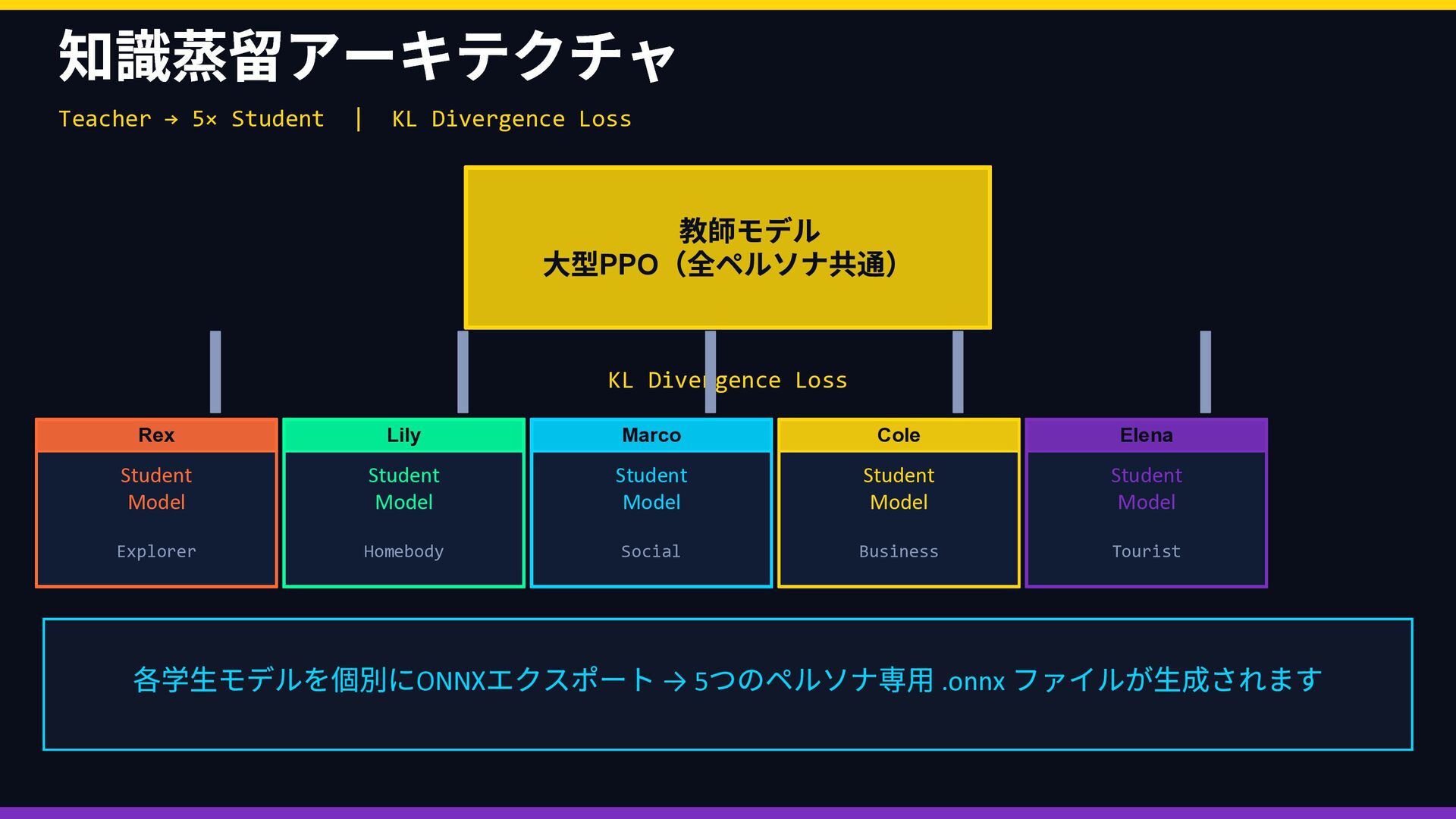
教師モデル 大型PPO (全ペルソナ共通) KL Divergence Loss Rex Student Model Explorer Lily Student Model Homebody Marco Student Model Social Cole Student Model Business Elena Student Model Tourist 各学生モデルを個別にONNX エクスポート → 5 つのペルソナ専⽤ .onnx ファイルが⽣成されます
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}