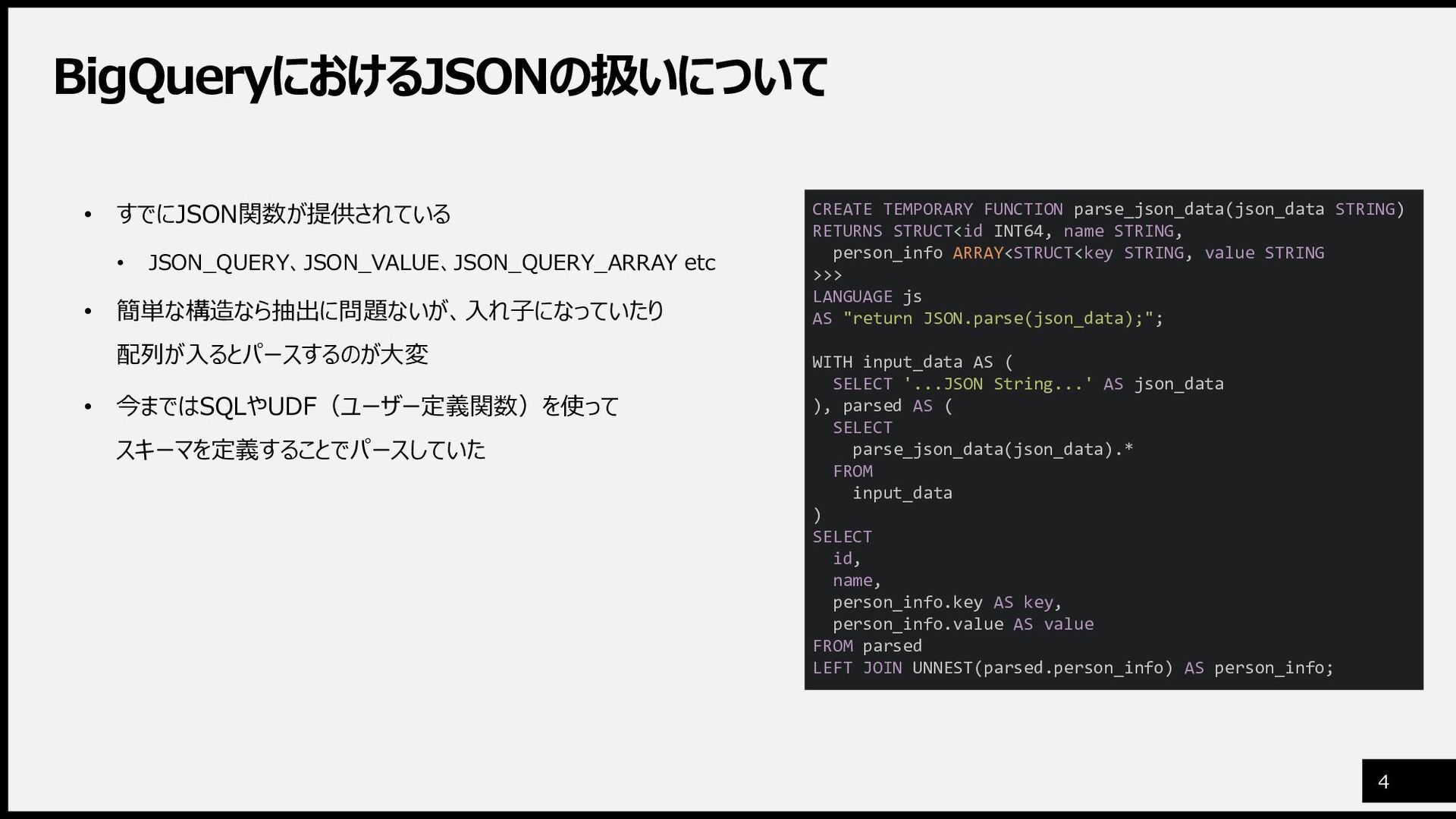
• 今まではSQLやUDF(ユーザー定義関数)を使って スキーマを定義することでパースしていた CREATE TEMPORARY FUNCTION parse_json_data(json_data STRING) RETURNS STRUCT<id INT64, name STRING, person_info ARRAY<STRUCT<key STRING, value STRING >>> LANGUAGE js AS "return JSON.parse(json_data);"; WITH input_data AS ( SELECT '...JSON String...' AS json_data ), parsed AS ( SELECT parse_json_data(json_data).* FROM input_data ) SELECT id, name, person_info.key AS key, person_info.value AS value FROM parsed LEFT JOIN UNNEST(parsed.person_info) AS person_info;
SAFE.PARSE_JSONはパースできない場合NULLを返す • ドット表記でアクセス可能 • 空白などドット表記できない場合は “[ ]” で指定可能 • 例:person.info[“User Name”] WITH input_data AS ( SELECT SAFE.PARSE_JSON('...JSON String...') AS json_data ) SELECT json_data.id, JSON_VALUE(json_data.name) AS name, JSON_VALUE(person_info.key) AS key, JSON_VALUE(person_info.value) AS value FROM input_data LEFT JOIN UNNEST(JSON_QUERY_ARRAY(json_data.person_info)) AS person_info;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}