Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
実践的データ基盤への処方箋 輪読会 / round-reading-jissennteki-d...
Search
Shuichi Ohsawa
February 18, 2022
Technology
270
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
実践的データ基盤への処方箋 輪読会 / round-reading-jissennteki-data-kiban
2022/02/18 「実践的データ基盤への処方箋」 輪読会の資料です。
Shuichi Ohsawa
February 18, 2022
More Decks by Shuichi Ohsawa
See All by Shuichi Ohsawa
datatech-jp Casual Talks #1 「BigQueryのネイティブJSON型がサポートされたので触ってみた」 / support-bigquery-native-json-and-try-it
ohsawa0515
0
2.7k
技書博後夜祭 第一夜「AWSのコスト最適化を はじめよう!」 / gishohaku5-koyasai-starting-aws-cost-optimization
ohsawa0515
0
430
JAWS-UG 初心者支部#36 「AWSで高額請求やらかした話」 / story-about-high-billing-on-aws
ohsawa0515
0
1.4k
インフラエンジニアBooks #7 「Amazon Web Servicesコスト最適化入門」 / infra-engineer-books-aws-cost-optimization
ohsawa0515
12
5.2k
ECSでGPUを使う 2020年版 / jawsug-container18-lt-using-gpu-on-ecs-2020
ohsawa0515
0
2.4k
急成長するシステムに追いつくためのインフラ改善への取り組み / sansan-m3-tech-night-improve-infrastructure
ohsawa0515
0
3k
AWS SDK for GoのContextパターン / aws sdk for go context pattern
ohsawa0515
3
820
インフラエンジニアがConsulとStretcherをつかったデプロイ改善で開発効率の向上に貢献した話(短縮版 + α) / omotesando.rb #33
ohsawa0515
0
1.1k
サーバレスVulsアーキテクチャ再び / serverless-vuls-again
ohsawa0515
1
4.2k
Other Decks in Technology
See All in Technology
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.5k
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.3k
ゼロをイチにする仕事が終わったあと
smasato
0
330
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
350
最近評価が難しくなった
maroon8021
0
330
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
830
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.4k
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.3k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
170
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
Featured
See All Featured
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
The browser strikes back
jonoalderson
0
1.4k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
HDC tutorial
michielstock
2
740
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
680
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Chasing Engaging Ingredients in Design
codingconduct
0
230
Transcript
実践的データ基盤への処方箋 輪読会 大澤 秀一 @ohsawa0515 ~
2 @ohsawa0515 https://blog.jicoman.info/about @ohsawa0515
目次 3 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
目次 4 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
オペレーショナルDBではなく分析用DBを採用する 5 • オペレーショナルDBと分析用DB、2種類のデータベースがある • オペレーショナルDBの例:Amazon Aurora • 分析用DBの例:Amazon Redshift
• どちらもデータをテーブルに格納、SQLでクエリ実行、GROUP BY、MIN/MAXなどの集計関数も使えるが、Redshiftはデータの抽出や 集計といった処理に特化している • データ基盤のデータウェアハウスには分析用DBを採用する • オペレーショナルDBを採用してしまうと、データ抽出や集計が遅くて使い物にならないか、コストが高くつく • オペレーショナルDBと分析用DBの違いは次ページ以降 (コメント) • OLTP、OLAPではなくオペレーショナルDBと分析用DBと表記した理由はなんだろう
オペレーショナルDBはデータ操作に強い 6 • 例:Webサイトのバックエンドに、ユーザが行ったデータの参照・更新・挿入・削除といった操作 • 製品例:Oracle、SQL Server、MySQL、PostgreSQL etc • マネージドサービス例:AWS
RDS、GCP Cloud SQL etc • オペレーショナルDBの特徴・性質 • 応答速度を重視、少量のデータを頻繁に操作することが求められる • 例:1,000万行10GBの全データの中の、1行1KBのデータを、10ミリ秒で操作する • テーブルのデータを行ごとに格納し、行へのアクセスが 高速になるように作られている(行指向) • 列の値の平均をとったり、合計するといった集計操作は苦手 P.127 図2-32より
分析用DBはデータの抽出と集計に強い 7 • 例:オペレーショナルDBのデータやCSVを夜間バッチでロード、BIツールに抽出、レポート作成ジョブで全件集計 • 製品例:Amazon Redshift、GCP BigQuery、Snowflake • 分析用DBの特徴・性質
• 応答速度よりもスループット(単位時間あたりの処理速度)を重視する • 例:オペレーショナルDBにある売上テーブルを30分かけてロードし、その後1時間かけて全件集計、売上レポートをつくる • テーブルのデータを列方向に格納し、抽出や集計の計算に最適化 • 少量のデータへの素早い操作や、特定の1行だけを更新する処理は苦手 • 列方向の操作に強い分析DBを 「列指向データベース」「カラムナデータベース」とも呼ばれる P.129 図2-34より
目次 8 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
分析用DBの製品選定が最も重要 9 • 分析用DBはデータ基盤の中でも重要なコンポーネントの一つ • 処理性能やデータ基盤の利用者にとって使いやすいかなどの観点で考慮する必要がある • 多くの分析用DBがある中で、自社に最適な製品を選ぶ必要がある
分析用DBの一覧 10 • 提供形態(クラウド or オンプレミス)× Hadoopベースかどうかで分類できる • ① :
歴史的に登場が古い、重厚長大で敷居が高い • ② : Hadoopによって導入の敷居が低くなった、システムの複雑さ・運用の難しさが課題 • ③ : マネージドHadoopによって複雑な環境構築が自動化、データ増加に対してスケーラブルに対応 • ④ : Hadoopの欠点を克服したクラウドDWH製品が現在の主流 P.130 表2-4より
初期コストの低いクラウド上の分析用DBがおすすめ 11 • 「初期コストの低さ」を第一に優先すべき • 最初からシステム規模を推定することはほぼ不可能 • ① オンプレミスDWH製品は、高額(数千万円~億単位)の初期投資が必要になる •
② オンプレミスHadoopは、サーバの購入が必要で高額(数千万円程度)の初期投資が必要になる • ③ or ④(クラウド上の分析DB)は基本的に従量課金であり、初期費用を必要としない
クラウド上の分析用DBはデータソースと同じクラウド上の製品が自然な選択肢 12 • 「データソースがどのクラウドにあるか」がクラウドの分析用DBの中から選ぶ判断基準の一つ データソースと分析用DBが同じクラウドにあることのメリット 1. ネットワーク通信が同一クラウド内で完結 • データ転送速度が高速 •
データ転送料金がかからない(同一リージョンの場合) 2. クラウドにあるデータ転送・共有サービスの恩恵を受けられる • クラウドによってはデータソースから分析用DBに簡単にデータ転送できる仕組みを持っている • 例:AWS Glue、Cloud Data Fusion • フェデレーション機能を利用することで、分析用DBからデータソースに直接クエリすることができる
クラウド上の分析用DBの選び方 13 • AWSにおいてどの分析用DBを選択したらよいか • Redshift、Athena、EMR、Snowflake、Cloudera • データ基盤構築の初期段階、S3にデータがあり気軽に分析したい場合 → Athena
• データ基盤を拡大していく場合 • 他AWSサービスとの連携しやすさを重視する場合 → Redshift • 処理単位の課金モデルやWebブラウザでの使いやすさを重視する場合 → Snowflake • GCPの場合は、基本的にBigQueryを採用する • データソースがAWSにあるが、BigQueryを採用する事例が多く見られる (コメント) Redshiftでの今までのつらさと、BigQueryのパフォーマンスや事例の多さから採用することが多そう(自分もそう)
使い勝手も考慮する 14 P.136 表2-5より
目次 15 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
列指向圧縮を理解していないと分析用DBを正しく使えない 16 • 分析用DBはデータを列指向圧縮して格納しているため、データの一部だけの更新・削除が苦手 • データ加工のために大量のUPDATE文を投げると大変 • 一度テーブルをDROPしてから再作成するのが正解
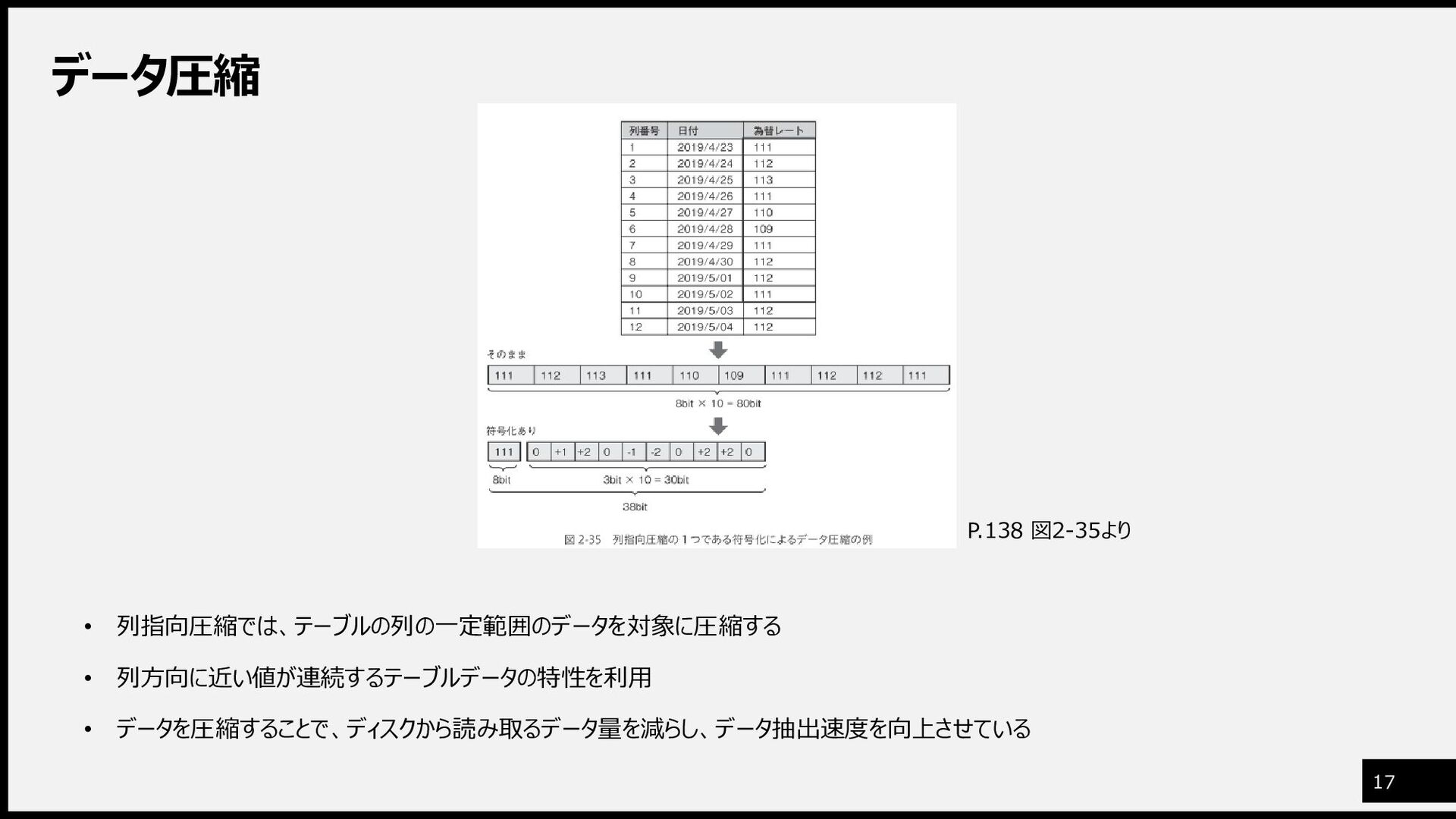
データ圧縮 17 • 列指向圧縮では、テーブルの列の一定範囲のデータを対象に圧縮する • 列方向に近い値が連続するテーブルデータの特性を利用 • データを圧縮することで、ディスクから読み取るデータ量を減らし、データ抽出速度を向上させている P.138 図2-35より
データの読み飛ばし 18 • テーブルの列の統計情報を事前に計算してデータと一緒に格納しておくことで、 抽出や集計でデータを読み飛ばすことができる • データの読み飛ばしによって、取得するデータ量を削減し高速化を実現している P.139 図2-36より
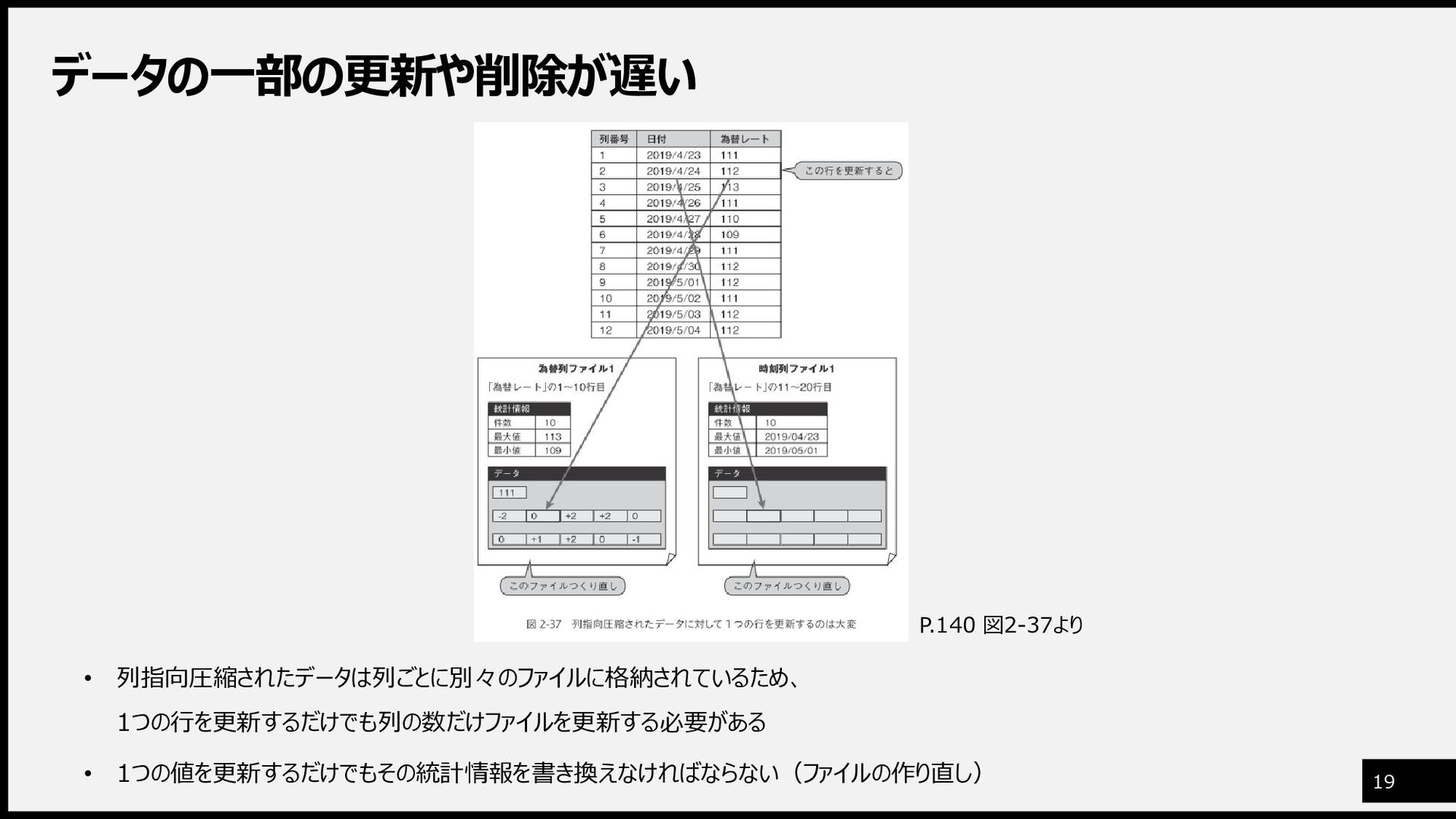
データの一部の更新や削除が遅い 19 • 列指向圧縮されたデータは列ごとに別々のファイルに格納されているため、 1つの行を更新するだけでも列の数だけファイルを更新する必要がある • 1つの値を更新するだけでもその統計情報を書き換えなければならない(ファイルの作り直し) P.140 図2-37より
分析用DBに優しいSQLを書こう 20 • 全件を削除する場合は、DELETEではなくDROPする • DELETEは列指向圧縮されたファイルの書き換えを発生させる • テーブルの一部を更新する場合は、更新した内容を持つ新たなテーブルを用意し、置き換える • UPDATE、DELETEは列指向圧縮されたファイルの書き換えを発生させる
• CTAS(CREATE TABLE AS SELECT)構文を用いて、新たにテーブルを作り、テーブル名をリネームする • データを入れるときは、1件ずつINSERTするのではなく、複数件まとめてロードする • 1件ずつINSERTされると、列指向圧縮のデータを作り変える必要がある • INSERTではなくロードする機能を使う (コメント) データ利用の観点から SELECT * ~を止めるようにしたい
目次 21 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
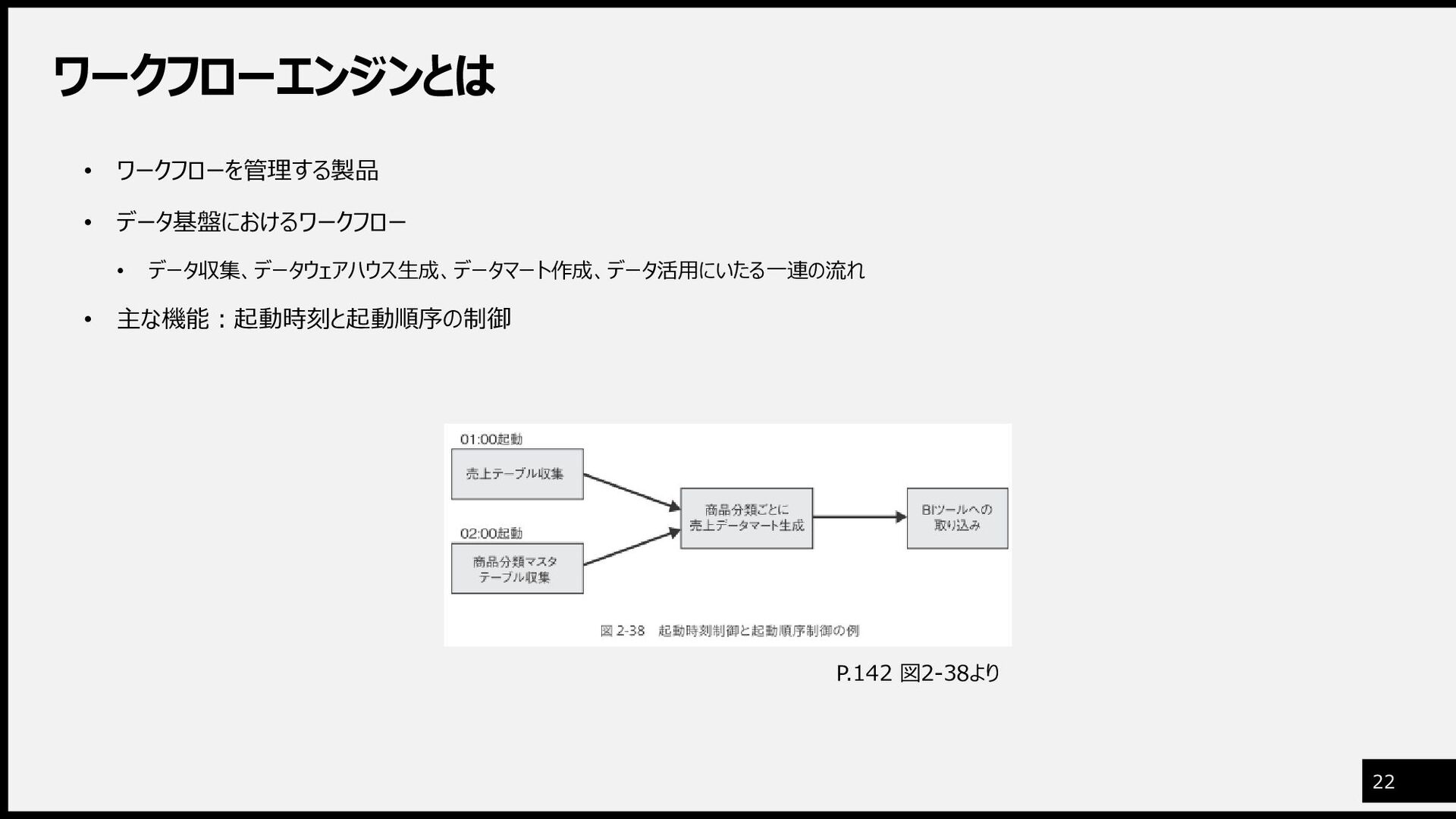
ワークフローエンジンとは 22 • ワークフローを管理する製品 • データ基盤におけるワークフロー • データ収集、データウェアハウス生成、データマート作成、データ活用にいたる一連の流れ • 主な機能:起動時刻と起動順序の制御
P.142 図2-38より
自前でワークフローを制御するのは大変 23 • ワークフローエンジンを使わずに、WindowsのタスクスケジューラやLinuxのcrontabなどを 使うこともできるが大変 • スケジュールそのものが動かなかった場合の制御 • スクリプト言語で実行順序を列挙して起動順序を制御する場合 •
処理中に異常終了した場合の復旧作業として、途中から再開するのが大変 • 処理が増えてくると可読性が低くなり、全容を把握できなくなる • 異常終了に対する通知やカスタマイズ機能が欲しくなる • 異常終了したらSlack通知したい • 「この処理の異常終了は1週間無視」「この文字列を含む場合は無視」等 • ワークフローエンジンによって、これらの問題やスクリプト言語で対処できない複雑な作り込みに対応できる
ワークフローエンジンの特徴を理解し必要なタイミングで導入する 24 • ワークフローエンジンは複数台のサーバで冗長構成を組むことができる • 一部の処理が異常終了した場合、途中からやり直すことができる(再実行、re-run) • 処理の順序関係をグラフィカルに確認できる • ワークフローエンジンを導入するタイミング
• データ活用が進んで複雑なワークフローを処理するようになった • 複数人でワークフローをつくるようになった
目次 25 • 2-13 : データウェアハウスには抽出や集計に特化した分析用DBを採用する • 2-14 : 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
• 2-15 : 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける • 2-16 : 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する • 2-17 : ワークフローエンジンは「専用」か「相乗り」かをまず考える
ワークフローエンジン製品を選ぶ前にデータ基盤専用にするか相乗りするかを考える 26 • 事業システムにすでにワークフローエンジンが導入されている場合、相乗りするのが手っ取り早い 相乗りのメリット • ワークフローエンジンの実行環境を運用しなくてもよい • 事業システムの処理とデータ基盤の処理を一つのワークフローで制御できる 相乗りのデメリット
• 事業システムに影響を及ぼす可能性があるため、データ基盤のワークフローを気軽に変更できなくなる • 事業システム側のワークフローエンジンがレガシー過ぎて使いにくい可能性がある
データ基盤専用にする場合は使いやすいものを選ぶ 27 • データ分析は試行錯誤をどれだけ早く回せるかが鍵 • 普段SQLを書いて分析しているデータ基盤の利用者が、マニュアルを読めばワークフローを作って デプロイできる程度が目安 • 製品例 :
Apache Airflow • Airbnb社が中心となって開発したオープンソースのワークフローエンジン • Web画面やAPIなどを通じて操作可能 • Pythonで記述でき、プラグインも多数用意されている • マネージドサービス • GCP : Cloud Composer • AWS : Amazon Managed Workflows for Apache Airflow(MWAA)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}