Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介:Mine the Easy, Classify the Hard: A Semi-S...
Search
Shohei Okada
July 03, 2014
Research
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介:Mine the Easy, Classify the Hard: A Semi-Supervised Approach to Automatic Sentiment Classification
動画
http://youtu.be/QbsMuMRXxWY?list=UUhwtfJp9l_thFbFDWXoGWEQ
Shohei Okada
July 03, 2014
More Decks by Shohei Okada
See All by Shohei Okada
Symfony + NelmioApiDocBundle を使った スキーマ駆動開発 / Schema Driven Development with NelmioApiDocBundle
okashoi
0
330
たった 1 枚の PHP ファイルで実装する MCP サーバ / MCP Server with Vanilla PHP
okashoi
1
1k
どうして手を動かすよりもチーム内のコードレビューを優先するべきなのか
okashoi
3
2.3k
パスワードのハッシュ、ソルトってなに? - What is hash and salt for password?
okashoi
3
410
設計の考え方 - インターフェースと腐敗防止層編 #phpconfuk / Interface and Anti Corruption Layer
okashoi
11
6.3k
"config" ってなんだ? / What is "config"?
okashoi
0
1.9k
ファイル先頭の use の意味、説明できますか? 〜PHP の namespace と autoloading の関係を正しく理解しよう〜 / namespace and autoloading in php
okashoi
4
2.2k
MySQL のインデックスの種類をおさらいしよう! / overviewing indexes in MySQL
okashoi
0
1.4k
PHP における静的解析(あるいはそもそも静的解析とは) / #phpcondo_yasai static analysis for PHP
okashoi
1
1.5k
Other Decks in Research
See All in Research
論文紹介:HalluCitation Matters
wasyro
0
130
typst の使い方:言語学を研究する学生のために
gitomochang
0
520
NLP colloquium: AI Safety Survey
kanekomasahiro
0
870
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
750
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
130
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
250
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
280
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
490
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
170
HAKARI-Bench - 実運用視点での情報検索モデル評価ベンチマーク
hotchpotch
0
120
EIRによる不正端末のブロッキング 5G時代におけるデバイス識別と不正対策の進化
stellarcraft
0
100
Featured
See All Featured
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
YesSQL, Process and Tooling at Scale
rocio
174
15k
My Coaching Mixtape
mlcsv
0
180
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Code Reviewing Like a Champion
maltzj
528
40k
Context Engineering - Making Every Token Count
addyosmani
9
1k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
BBQ
matthewcrist
89
10k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Transcript
文献紹介 2014/07/03 長岡技術科学大学 自然言語処理研究室 岡田 正平
文献情報 Sajib Dasgupta and Vincent Ng Mine the Easy, Classify
the Hard: A semi- Supervised Approach to Automatic Sentiment Classification In Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, pp 701-709. 2009 2014/7/3 文献紹介 2
概要 • semi-supervised approach to sentiment classification • はじめに曖昧でないデータだけを分けて,その 結果を利用して曖昧なデータを分類する手法
2014/7/3 文献紹介 3
背景 2014/7/3 文献紹介 4
背景 polarity classification は topic-based text classification と比べ曖昧性が多い • 1つのレビュー内で良い部分と悪い部分の両方に
言及する • 長々と解説して,最後にちょっとだけ自分の 意見を言う 2014/7/3 文献紹介 5
背景 過去に行われた研究 (supervised approach) • 客観的な部分を独立に学習・分類 • positive/negativeの他にneutralも用いる • sentence-
and document-level sentiment analysis を同時に扱うモデル 大量の手動アノテーションが必要 2014/7/3 文献紹介 6
背景 unsupervised approach は意義は大きいが 難しい • domain-specific なことが一因 • 一般的なクラスタリング手法では,有効な素性
を同定できない 2014/7/3 文献紹介 7
背景 提案手法 (semi-supervised) “mine the easy, classify the hard” approach
• 最初に曖昧でないレビュー(i.e., “easy”)を同定し ラベル付けを行う • 次に曖昧なレビュー(i.e., “hard”)を扱う 2014/7/3 文献紹介 8
Spectral Clustering
Spectral Clustering k-means法では線形分離不可能なデータに 対応不可 Spectral Clusteringを適用 – 情報を保ちつつ低次元空間に移してから クラスタリングを行う
2014/7/3 文献紹介 10
Spectral Clustering : 各データ間の類似度行列 : (, )の要素がの番目の行の総和である 対角行列 : ラプラシアン行列
= 1/2−1/2 2014/7/3 文献紹介 11
Spectral Clustering • について,固有値の大きい方から個の固有ベ クトルで新しい行列をつくる – 各データ点が次元空間に移される • 各行を単位長に正規化(各符号は保持) •
k-means法によりクラスタリングを行う 2014/7/3 文献紹介 12
Spectral Clustering ※ 各次元は1つの固有ベクトルにより定義される • 固有値の大きい固有ベクトルはデータに対して 大きい分散を持つ (クラスタリングのために)重要な次元が選択 されると考えられる
2014/7/3 文献紹介 13
Spectral Clustering 1 1 1 0 0 1 1 1
0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 14
提案手法
提案手法 • spectral clustering を用いても,うまく 分離できるとは限らない – 曖昧なレビューが存在するため 一度に全てクラスタリングせず,曖昧なレ
ビューは別で扱う 2014/7/3 文献紹介 16
提案手法 1. spectral clustering を用いて曖昧でない(i.e., “easy”)レビューを同定・分類 2. 少数の曖昧な(i.e., “hard”)レビューに対し手動で ラベリング
3. これらを使って残りのレビューを分類 2014/7/3 文献紹介 17
提案手法 1. spectral clustering を用いて曖昧でない(i.e., “easy”)レビューを同定・分類 2. 少数の曖昧な(i.e., “hard”)レビューに対し手動で ラベリング
3. これらを使って残りのレビューを分類 2014/7/3 文献紹介 18
提案手法 | step 1 • 素性ベクトルはBOW – 句読点, 長さ1の単語,単一のレビューにしか 現れない語を除去
– 文書頻度の高い方から1.5%の語も除去 • 類似度行列の計算には,内積を用いる – ただし,対角成分は0とする 2014/7/3 文献紹介 19
提案手法 | step 1 どの固有ベクトルを用いるか? • 一般に2番目の固有ベクトルのみを用いるのが良 いと言われている • 提案手法の場合は必ずしもそうではない
5番目までの固有ベクトルを用いる (→次ページに続く) 2014/7/3 文献紹介 20
提案手法 | step 1 各固有ベクトルに対して 1. 個の要素それぞれを閾値として扱う (通りの分割方法が存在することになる) 2. 各分割方法についてcut-valueを計算する
3. 最小のcut-valueを選ぶ 最小のcut-valueを持つ固有ベクトルを用いる 2014/7/3 文献紹介 21
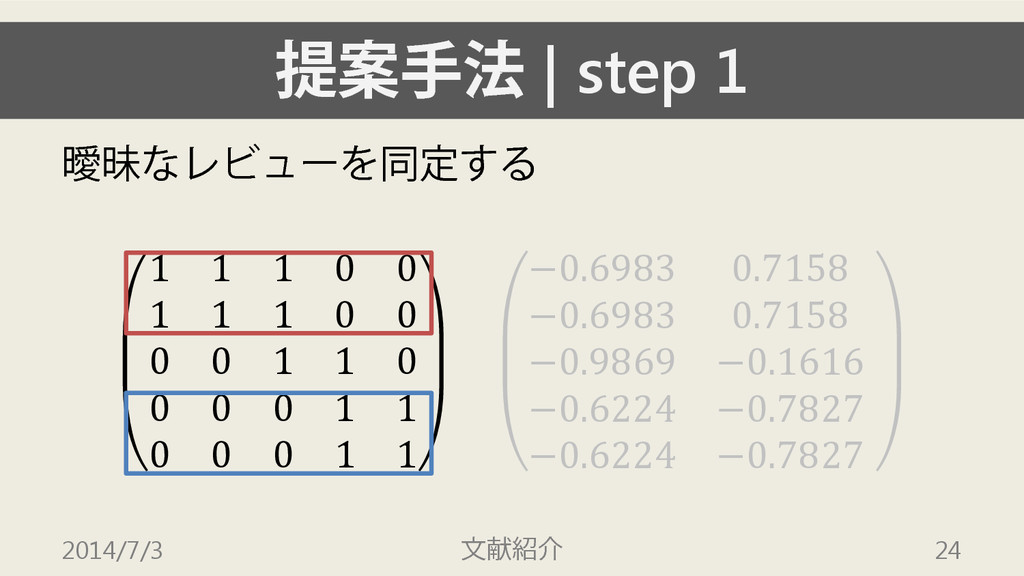
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 22
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 23
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 24
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
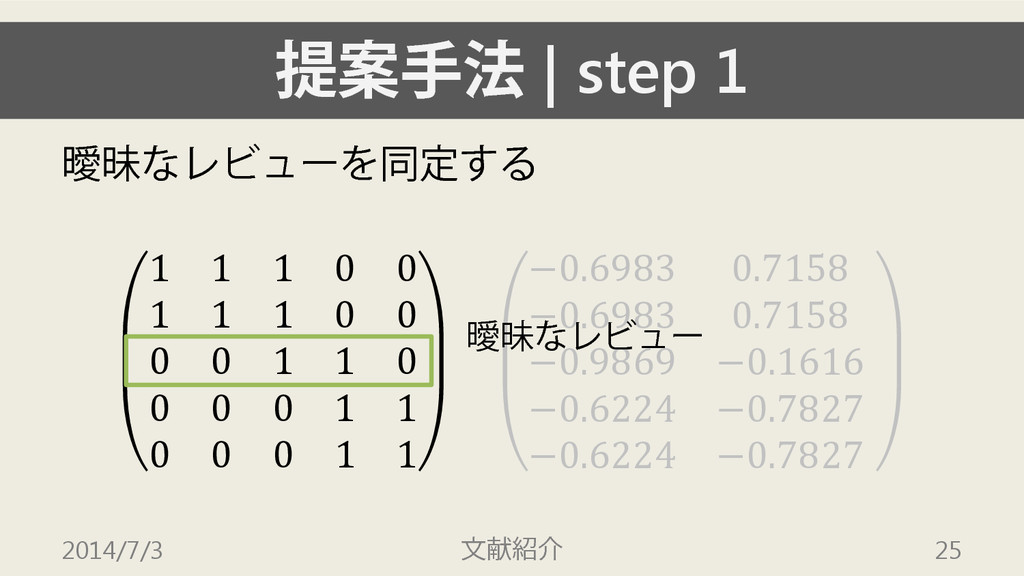
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 25 曖昧なレビュー
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 26
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 27
提案手法 | step 1 曖昧なレビューを同定する 1 1 1 0 0
1 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 −0.6983 0.7158 −0.6983 0.7158 −0.9869 −0.1616 −0.6224 −0.7827 −0.6224 −0.7827 2014/7/3 文献紹介 28
提案手法 | step 1 1. データ点集合から先述の手順に従って ラプラシアン行列の固有ベクトルを選ぶ 2. 固有ベクトルにしたがってをソートし 中央の個のデータを取り除く
3. データ点の数が個になるまで1,2を繰り返す 4. 固有ベクトルを用いて,2-meansによる クラスタリングを行う 2014/7/3 文献紹介 29
提案手法 | step 1 筆者らの実験では • = 50 • =
500 2014/7/3 文献紹介 30
提案手法 | step 1 得られた2クラスタに対してラベルを付ける • 10点ずつランダムサンプリングし手動で positive/negative のタグ付け •
半数より多くpositiveが付けられたら そのクラスタはpositive,それ以外はnegative 2014/7/3 文献紹介 31
提案手法 | step 1 評価データセットに対するseedの分類精度 2014/7/3 文献紹介 32
提案手法 | step 1 • Book および DVD を除き,80%超え •
不完全なseedデータでも,よりよく分類器を 学習させる 2014/7/3 文献紹介 33
提案手法 1. spectral clustering を用いて曖昧でない(i.e., “easy”)レビューを同定・分類 2. 少数の曖昧な(i.e., “hard”)レビューに対し手動で ラベリング
3. これらを使って残りのレビューを分類 2014/7/3 文献紹介 34
提案手法 | step 2 クラスタリング手法だけでは各素性が有効か そうでないかを同定できない • seed set を用いて極性分類に有効な素性を同定
2014/7/3 文献紹介 35
提案手法 | step 2 seed set が高精度であっても,残りのデータを 精度よく分類できないことが予測される • 曖昧なレビューとそうでないレビューの両方で
学習しなければ高精度は達成できないと仮定 • 曖昧なレビューの中でも特に曖昧さが大きい ものから学習する方が効率がいい 2014/7/3 文献紹介 36
提案手法 | step 2 active learning を適用 • seed set
を用いてSVMを学習させる • SVMに残りのデータを入力 • SVMの分離超平面に近いデータ点(=曖昧な点) 10個ずつを人手でタグ付け,それを含めて再学習 繰り返すことで,計100個の人手によるラベル付き データを得る 2014/7/3 文献紹介 37
提案手法 1. spectral clustering を用いて曖昧でない(i.e., “easy”)レビューを同定・分類 2. 少数の曖昧な(i.e., “hard”)レビューに対し手動で ラベリング
3. これらを使って残りのレビューを分類 2014/7/3 文献紹介 38
提案手法 | step 3 transductive SVMを適用 • step 1で得られたラベル付きデータ(低精度) の数の方が大きい
(step 1: 500,step 2: 100) – 分離超平面の決定時に支配的に振る舞う 2014/7/3 文献紹介 39
提案手法 | step 3 step 2 で得られたラベル付きデータ(高精度)を 効率良く使い,またノイズに強い分類器を 構築したい
5つの分類器を別々に学習させる – それぞれ100個の高精度ラベル付きデータ (共通)と,100個の低精度ラベル付き データ(別々)で学習を行う 2014/7/3 文献紹介 40
提案手法 | step 3 データセットの分け方 • step 1 の最終的な固有値ベクトルの要素値に 基づき昇順にソート
• 番目のデータを( mod 5)番目のセットに含める ただ分けるだけでなく,信頼性の高い/低い データ点を等しく分ける 2014/7/3 文献紹介 41
提案手法 | step 3 最終的に,ラベル無しデータに対して • 5つの分類器の confidence value (符号付)の
総和をとる • 0以上ならpositive,それ以外ならnegative 2014/7/3 文献紹介 42
評価
評価 | データセット • movie (MOV), books (BOO), DVDs (DVD),
electronics (ELE), kitchen appliances (KIT) の 5種類のレビューデータセット(ラベル付き) を使用 • 各データセットのサイズは2000 (positive, negative それぞれが1000ずつ) 2014/7/3 文献紹介 44
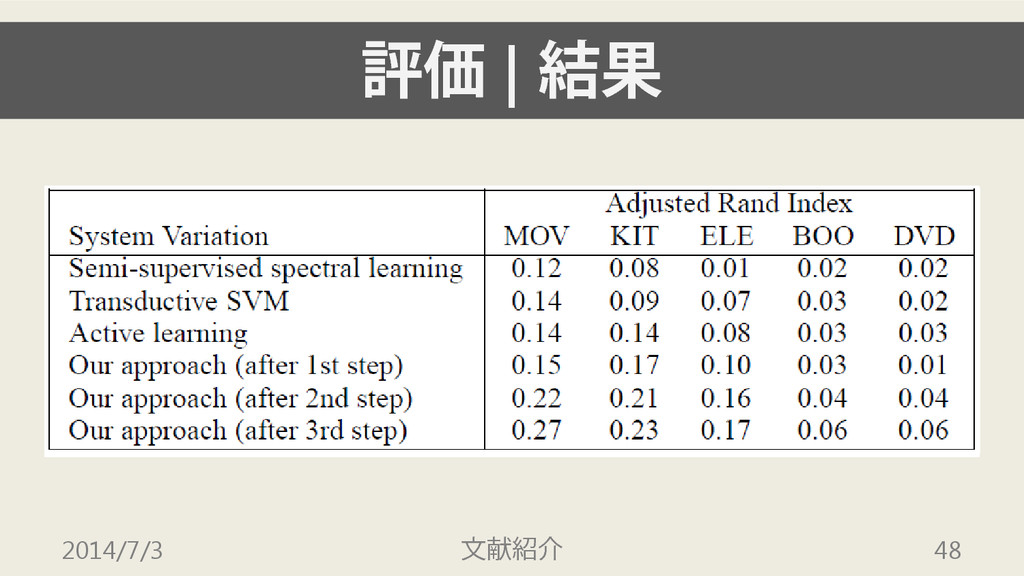
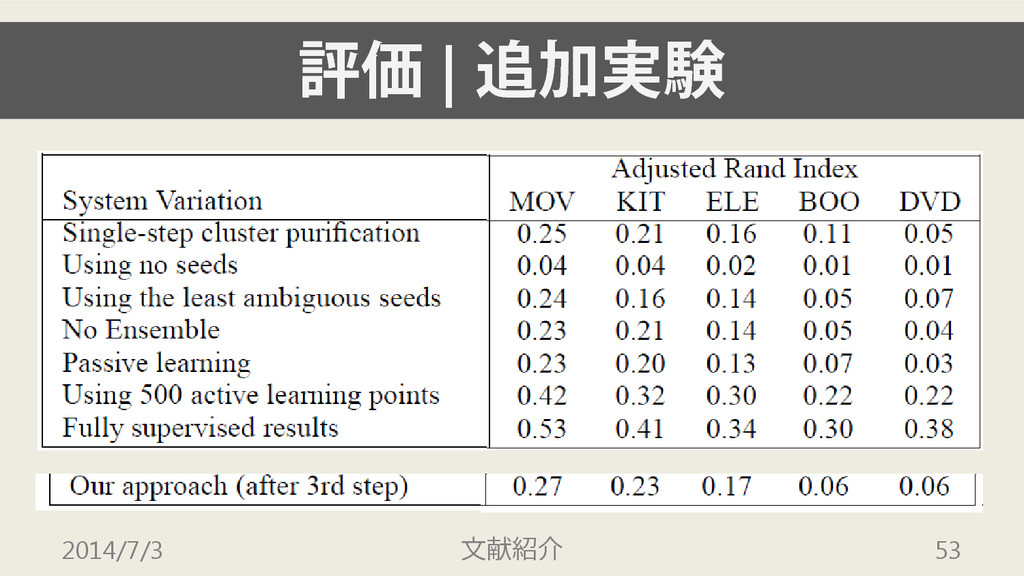
評価 | 指標 • 10分割交差検定を用いて精度を評価 • Adjusted Rand Index でも評価
– −1 から 1 の値を取り,大きいほど良い指標 2014/7/3 文献紹介 45
評価 | ベースライン 公平を期すため,各ベースラインは 100個のデータのラベルを使用できる • Semi-supervised spectral clustering •
Transductive SVM • Active learning 2014/7/3 文献紹介 46
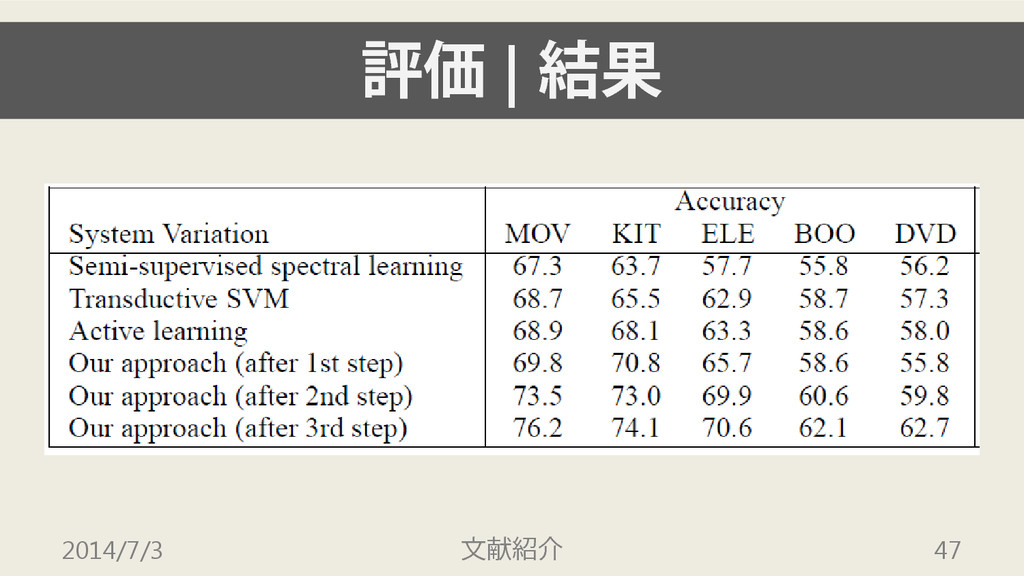
評価 | 結果 2014/7/3 文献紹介 47
評価 | 結果 2014/7/3 文献紹介 48
評価 | 結果 • いずれのデータセット・評価指標でも, 提案手法が最高結果を達成 • step 1 の段階でも,ベースラインに匹敵する
精度を達成 • ステップを追うごとに精度は向上していく 2014/7/3 文献紹介 49
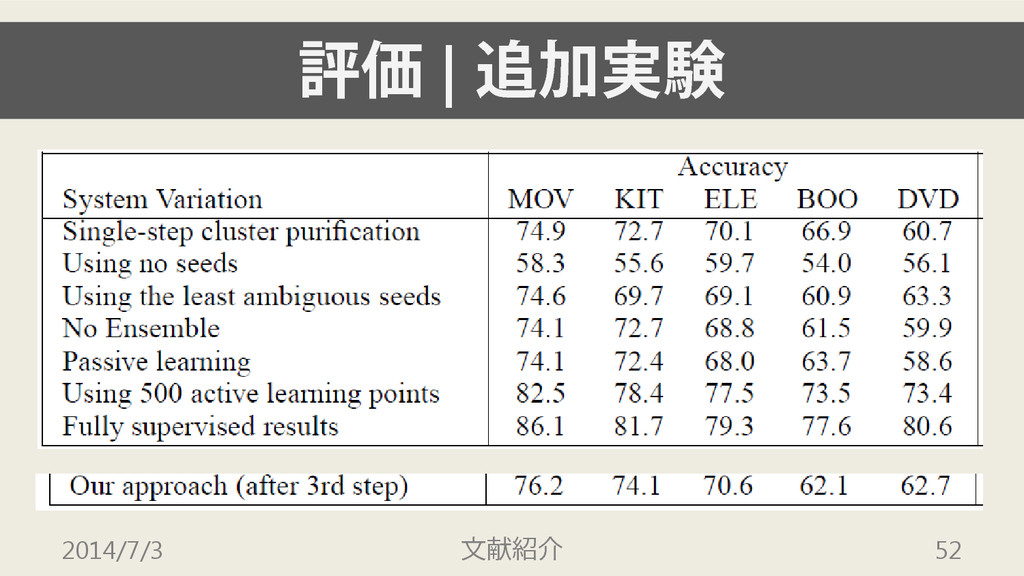
評価 | 追加実験 どの部分が性能に影響を与えているのかを調べる 次の7つの手法を評価する 2014/7/3 文献紹介 50
評価 | 追加実験 • seeds を得る際に single step で行う •
seeds を用いない • 曖昧さの小さい方から100個のみを seeds とする • 分類器を5つに分けない • passive learningを用いる(100個をランダムに選ぶ) • active learning で500個のデータを得る • fully supervised 2014/7/3 文献紹介 51
評価 | 追加実験 2014/7/3 文献紹介 52
評価 | 追加実験 2014/7/3 文献紹介 53
評価 | 追加実験 • seeds, ensemble, active learningのいずれも精度 向上に貢献している •
seedsは低精度であっても貢献している • 3つのデータセットについては,人手による ラベル付きデータを500個程度用意することで, fully-supervised の精度をほぼ達成している 2014/7/3 文献紹介 54
結論
結論 • 感情極性分類のsemi-supervised なアプローチ • “mine the easy, classify the
hard” apprach • 高い精度を達成 • 次の観点から拡張可能 – この手法は感情の分類に特化していない – 素性はBOWしか使っていない 2014/7/3 文献紹介 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}