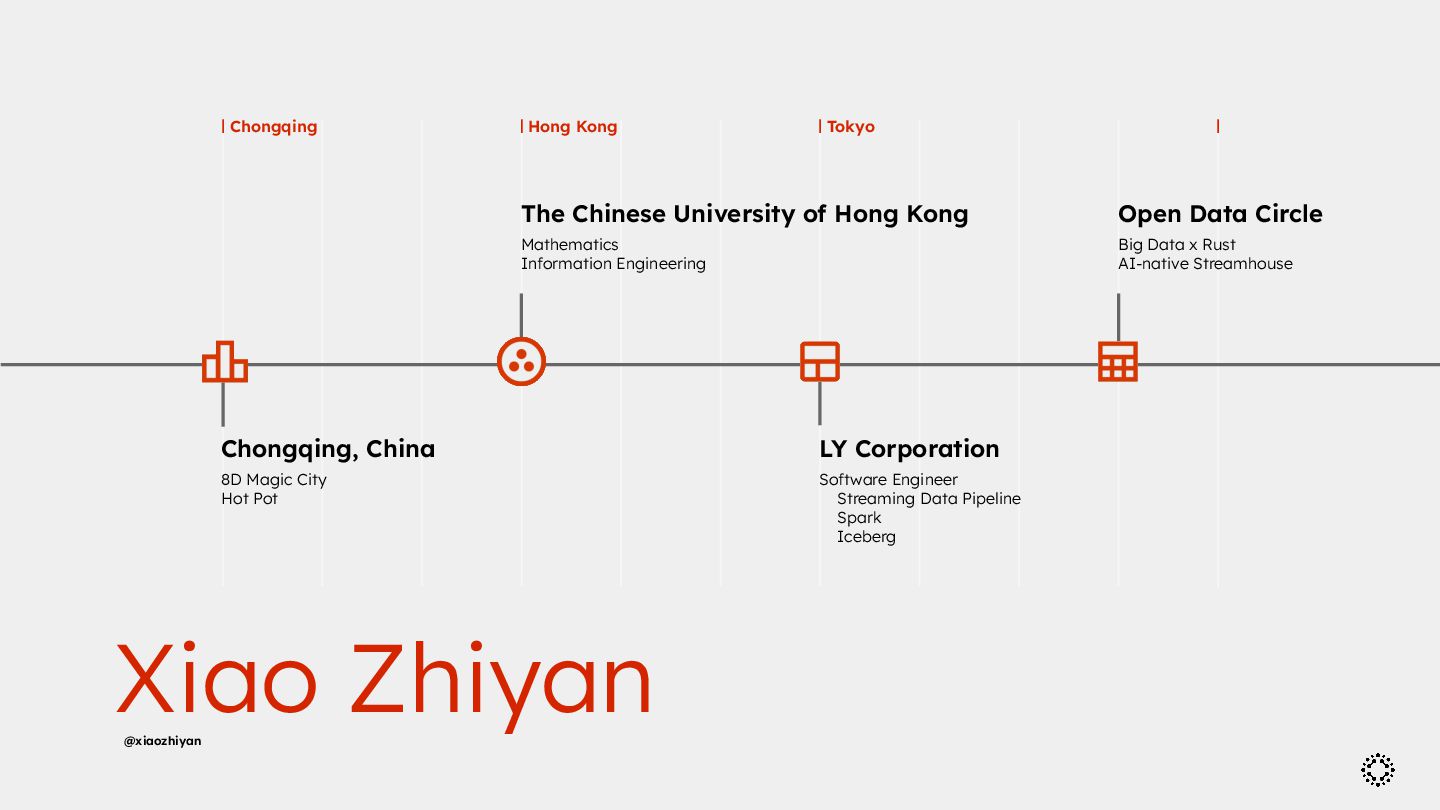
of Hong Kong Mathematics Information Engineering LY Corporation Software Engineer Streaming Data Pipeline Spark Iceberg Open Data Circle Big Data x Rust AI-native Streamhouse Chongqing Hong Kong Tokyo Xiao Zhiyan @xiaozhiyan
tools or features • Not a fixed architecture proposal • A practical exploration of AI-native directions for lakehouse • Grounded in real systems and production constraints • Focused on patterns, trade-offs, and evolution paths What this talk is What this talk is not What This Talk Is (and Is Not)
search / AI agents are moving from demos to production • “Freshness” and “retrieval latency” are now product requirements • Batch-only assumptions start to break (e.g. user-facing AI) • Random access + low-latency reads (not just scans) • Index-aware data layout: vectors / embeddings / multimodal • Continuous updates + lifecycle ops (re-embed / re-index) The pressure is already here What AI workloads demand
patterns • Indexing is optional, external, or delayed • Metadata focuses on snapshots, not semantics • Maintenance is offline and human-triggered • Retrieval-heavy, latency-sensitive access • Index is part of the data, not an afterthought • Semantics (embeddings, etc.) are first-class • Maintenance must be continuous and automated Traditional lakehouse assumptions AI workload reality
vector search • Add another service • Add another pipeline → Complexity grows faster than capability • Rewrite everything • Bet on a single new stack → High risk, low adoption Reaction 1: Add more features Reaction 2: Jump to a brand-new system
systems actually evolving under AI and streaming pressure?” What we’ll do next • Look at representative solutions (production & frontier) • Treat them as coordinate points, not winners • Connect them into a coherent architectural map Takeaway • A framework you can reuse internally • A roadmap you can start from tomorrow
change propagation (Batch → Streaming) • Access & indexing model (Scan-based → Index/Vector-aware) • Not a ranking • Not a recommendation • Coordinate points to reason about evolution paths under AI pressure How to read this landscape Two dimensions
Mostly append-heavy data • Batch or micro-batch processing Underlying assumptions What they solve well • ACID transactions & snapshot isolation • Schema evolution & time travel • Metadata-driven architecture (separate storage & compute) • Index lifecycle stays external to the table • Random access becomes inefficient • Continuous updates are not first-class #1 Open Table Formats (Baseline) Representative What starts to break under AI
• Embeddings generated & synced externally • Fast to prototype • Flexible ecosystem • Production-proven today • Consistency & sync pipelines • Re-embedding & re-indexing over time • Reproducibility becomes hard (time travel vs. index state) Typical pattern Hidden cost Why it works #2 Lakehouse + External Vector DB (Pattern)
aligned with table updates (CDC / batch / hybrid) • Re-embed: data changes, model upgrades, prompt changes → embeddings must be regenerated • Re-index: incremental updates vs full rebuild; compaction/merge effects • Rollback & time travel: can you reproduce results from an earlier snapshot? • Drift management: data/model/version drift becomes a continuous problem Why this becomes painful • Complexity scales with (data change rate × model iteration rate × index types) • Most “AI-ready” incidents are lifecycle issues, not vector search queries The Real Cost: Index Lifecycle
the dataset • Efficient reads beyond scans (random access patterns) • Dataset-level reproducibility with versions + index metadata • Vectors & multimodal data are first-class citizens • Index-aware + versioned + random-access friendly • Index lifecycle is treated as part of the dataset story (not “an external sync pipeline you own”) • Designed for AI/ML access patterns from day one (embeddings, reranking, multimodal features) #4 — AI-native Table Format (Lance) Representative What it enables (in practice) What’s fundamentally different Core idea
/ agents / monitoring) • AI workloads amplify the cost of stale data and delayed propagation • “Index lifecycle” is meaningless if your underlying data isn’t continuously updated • Maintenance must be automated and continuous (not a nightly job) • Streaming-first ingestion • Upserts / changelog as first-class data • LSM-style storage + compaction for continuous writes • Efficient incremental consumption for downstream pipelines #5 — Streaming-native Table (Paimon) Representative Why it matters for AI What it focuses on
into lake files immediately • Ordered log + retention as a first-class storage primitive • Continuous materialization / tiering into Iceberg / Paimon / etc. • Streaming storage as a hot tier • Built for low latency and high throughput • Lakehouse tables become the cold / historical tier #6 — Streaming Storage (Fluss) Representative What it enables Positioning
index-aware formats • Freshness shifts downward Pipeline concern → table concern → storage-tier concern • Systems move from “features” to “loops” • Embed → index → serve → monitor → re-embed/re-index becomes the new default • Don’t ask “which one is best?” — ask where your pain sits (freshness, retrieval, or lifecycle cost) • Avoid extremes: more glue vs full rewrite • Choose an evolution path with clear trade-offs • Treat each coordinate as a capability package, not a brand Patterns we saw How to use the patterns Landscape Summary — Patterns, Not Winners
cost, reproducibility) • Identify who owns the index lifecycle today (scripts? teams? nobody?) • Measure how often data & models change • Accept current constraints (skills, budget, ecosystem) • Reduce glue before adding features (fewer sync pipelines > faster vector search) • Make freshness & lifecycle explicit design goals • Evolve layer by layer, not by big rewrites • Choose components that align with your next step Start with reality (not architecture) Practical Guidance — For Platform Teams Move with direction (not perfection)
Random access, retrieval latency, and lifecycle become “always-on” concerns • The hard part is not vector search — it’s the lifecycle loop Embed → index → serve → monitor → re-embed / re-index / rollback • There is no single winner — but there is a clear direction Streaming-first freshness + index-aware access + loop-driven operations
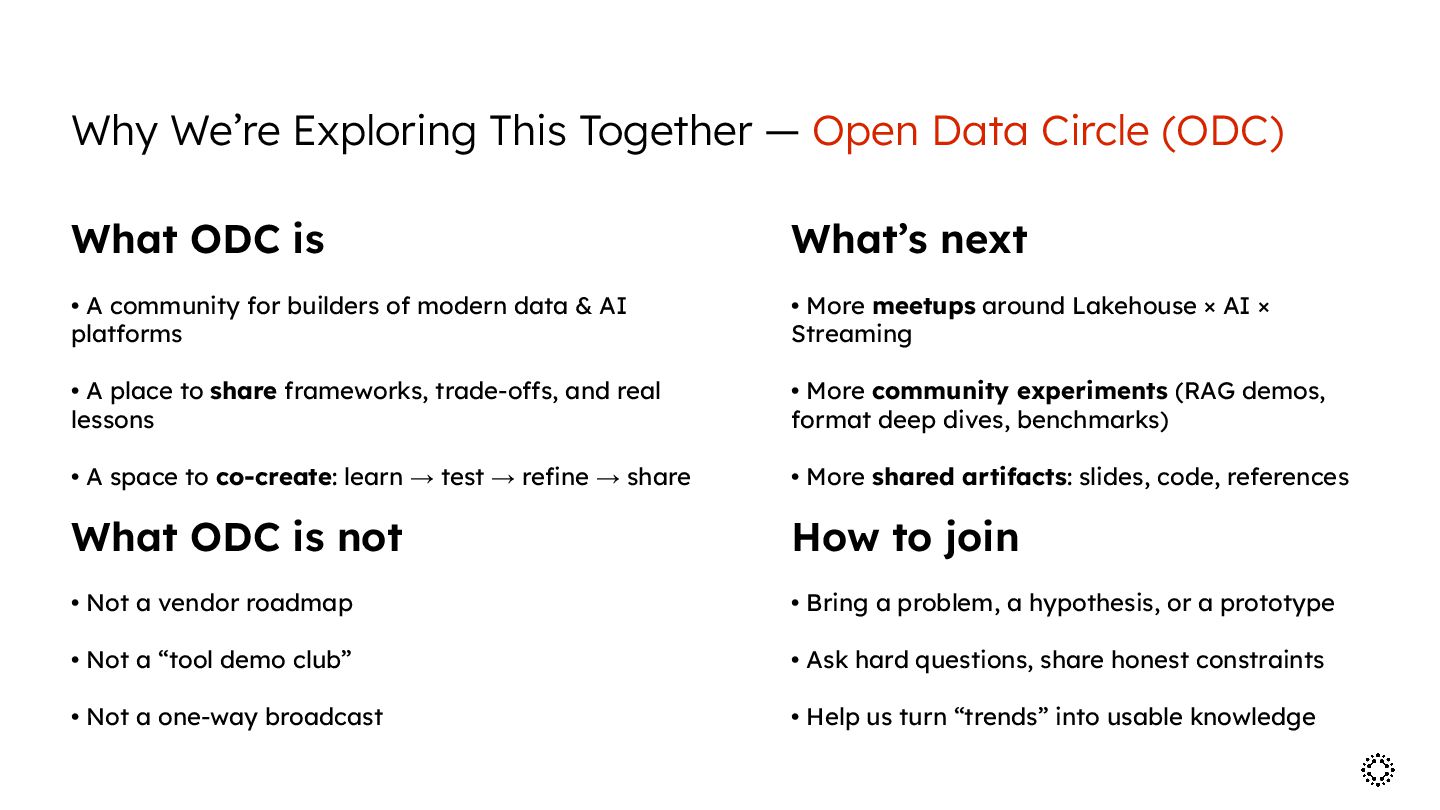
More community experiments (RAG demos, format deep dives, benchmarks) • More shared artifacts: slides, code, references • A community for builders of modern data & AI platforms • A place to share frameworks, trade-offs, and real lessons • A space to co-create: learn → test → refine → share What’s next What ODC is not • Not a vendor roadmap • Not a “tool demo club” • Not a one-way broadcast • Bring a problem, a hypothesis, or a prototype • Ask hard questions, share honest constraints • Help us turn “trends” into usable knowledge Why We’re Exploring This Together — Open Data Circle (ODC) What ODC is How to join
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}