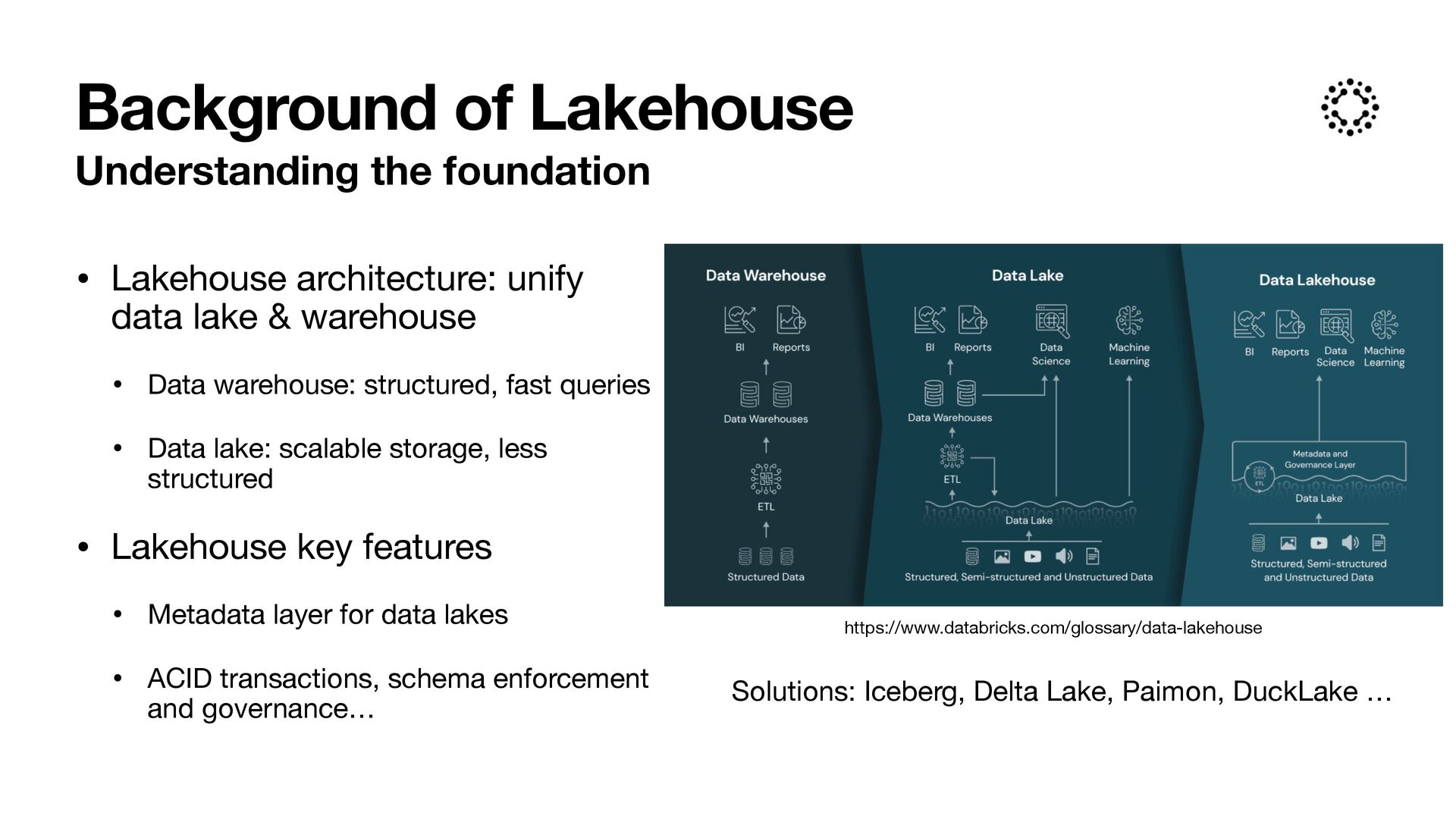
warehouse • Data warehouse: structured, fast queries • Data lake: scalable storage, less structured • Lakehouse key features • Metadata layer for data lakes • ACID transactions, schema enforcement and governance… Background of Lakehouse https://www.databricks.com/glossary/data-lakehouse Solutions: Iceberg, Delta Lake, Paimon, DuckLake …
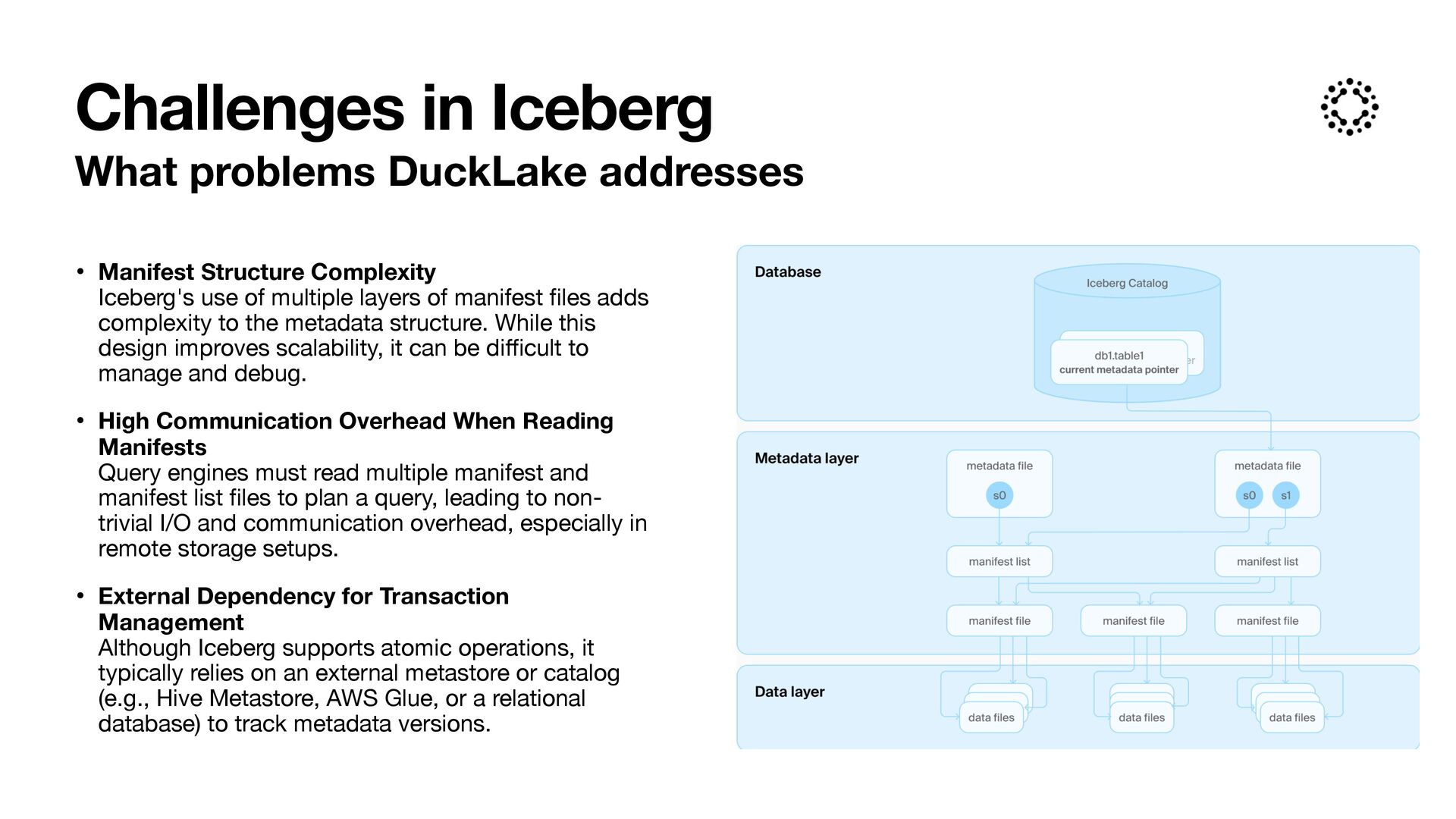
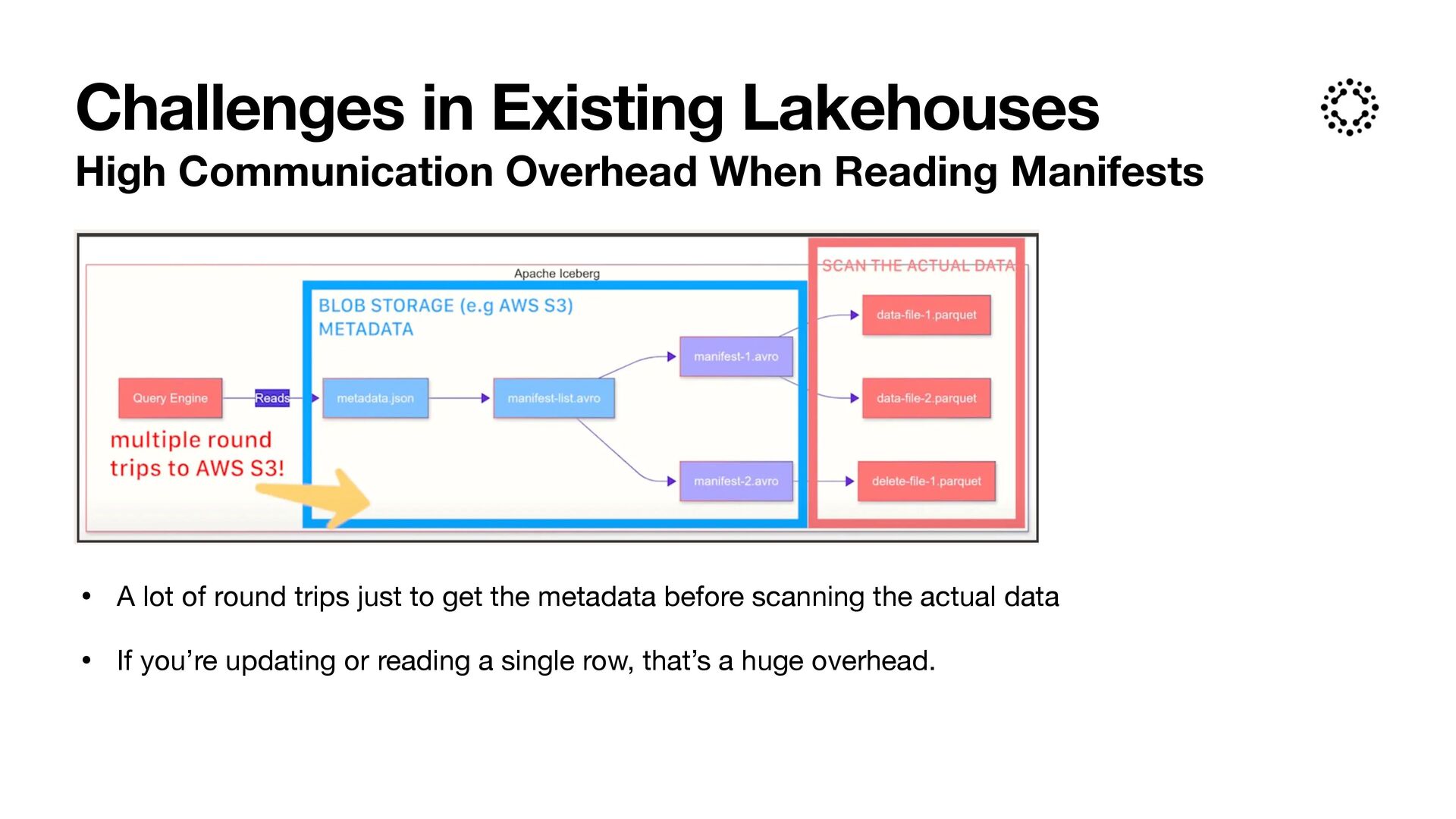
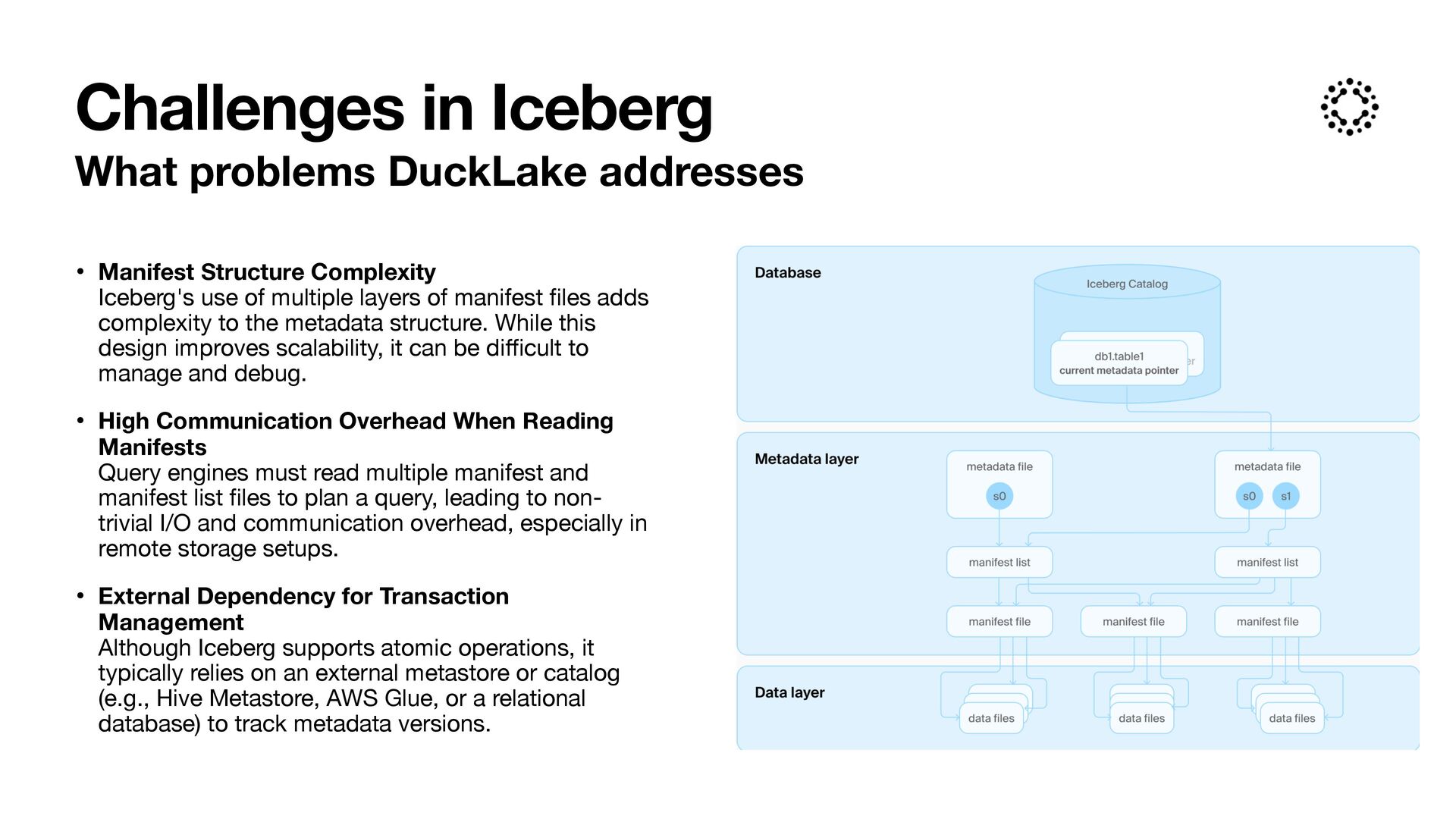
of multiple layers of manifest fi les adds complexity to the metadata structure. While this design improves scalability, it can be di ff i cult to manage and debug. • High Communication Overhead When Reading Manifests Query engines must read multiple manifest and manifest list fi les to plan a query, leading to non- trivial I/O and communication overhead, especially in remote storage setups. • External Dependency for Transaction Management Although Iceberg supports atomic operations, it typically relies on an external metastore or catalog (e.g., Hive Metastore, AWS Glue, or a relational database) to track metadata versions. Challenges in Iceberg
of multiple layers of manifest fi les adds complexity to the metadata structure. While this design improves scalability, it can be di ff i cult to manage and debug. • High Communication Overhead When Reading Manifests Query engines must read multiple manifest and manifest list fi les to plan a query, leading to non- trivial I/O and communication overhead, especially in remote storage setups. • External Dependency for Transaction Management Although Iceberg supports atomic operations, it typically relies on an external metastore or catalog (e.g., Hive Metastore, AWS Glue, or a relational database) to track metadata versions. Challenges in Iceberg
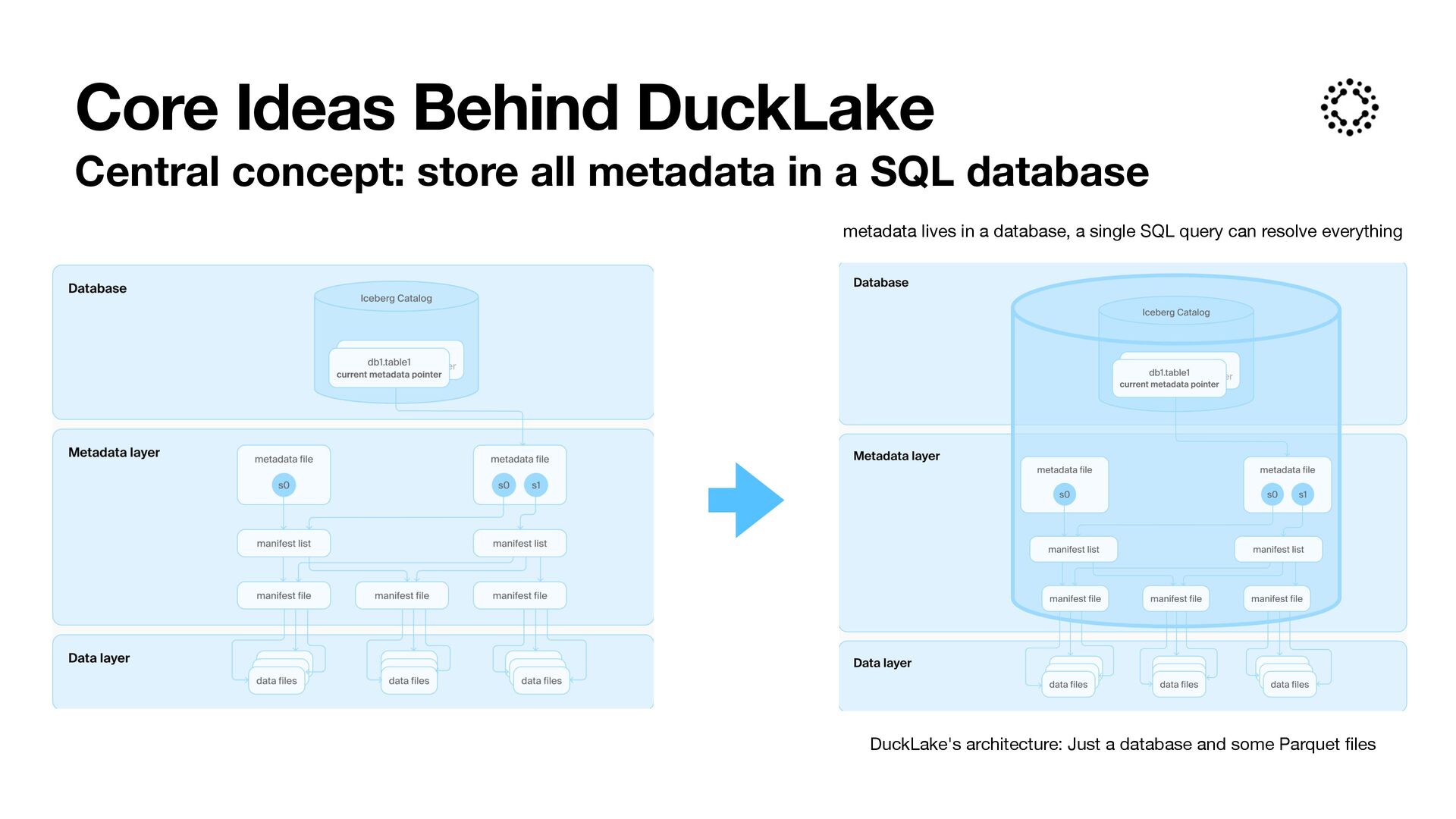
a SQL database DuckLake's architecture: Just a database and some Parquet fi les metadata lives in a database, a single SQL query can resolve everything
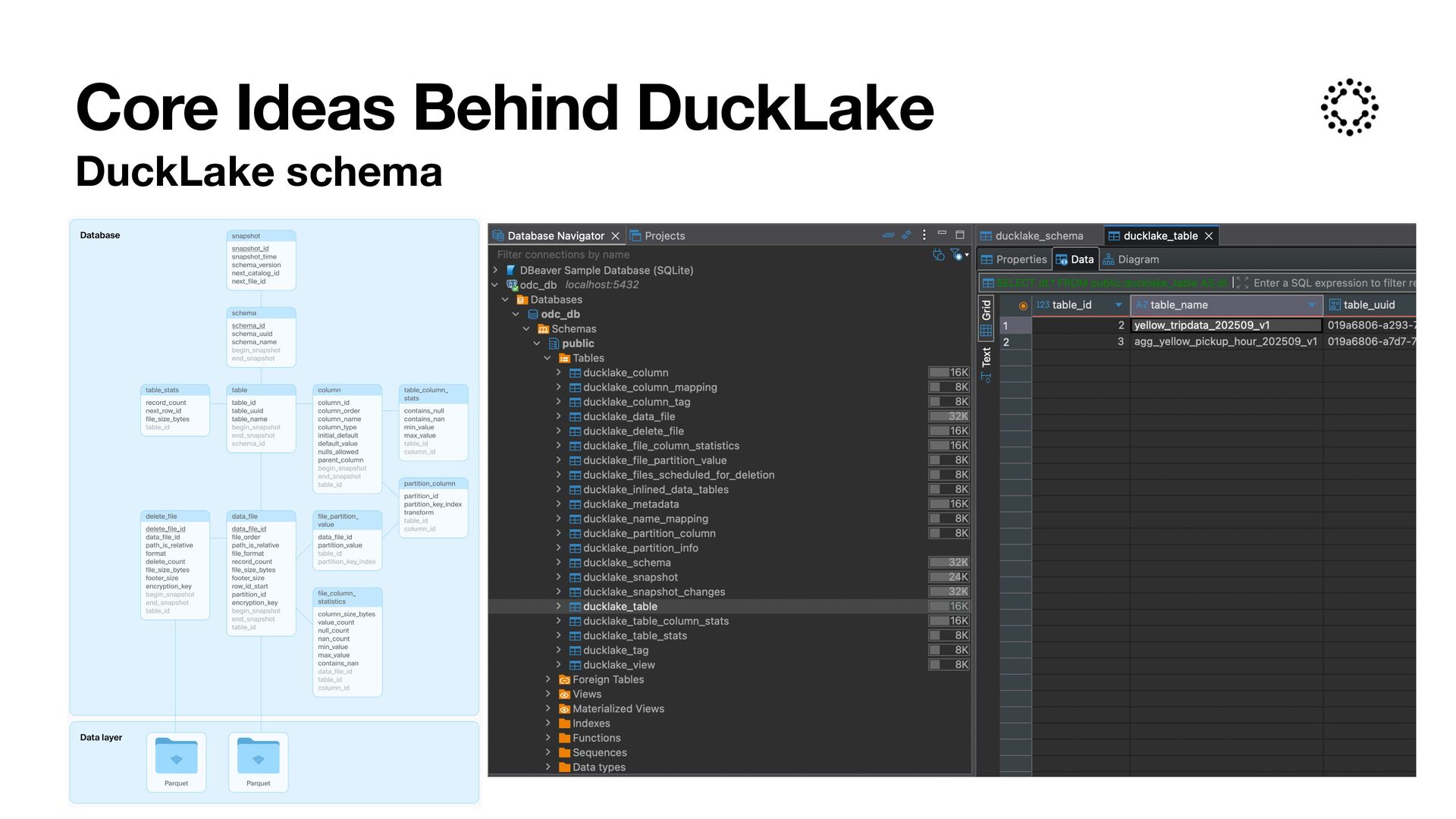
fi le storage (e.g., blob storage), allowing virtually unlimited scalability • Metadata (Catalog): The catalog handles only lightweight metadata transactions, making it highly e ffi cient. DuckLake is not tied to a speci fi c database—though PostgreSQL can already scale to hundreds of terabytes and thousands of compute nodes • Compute: Any number of compute nodes can independently read and write data while coordinating through the catalog, enabling in fi nite compute scaling Core Ideas Behind DuckLake (source: https://motherduck.com/blog/redshift- fi les-hunt-for-big-data/) Big Data queries are pretty rare
– Demonstrate how DuckDB e ff i ciently queries large Parquet fi les and serves as a lightweight, high-performance alternative to pandas for analytical workloads. • Introducing DuckLake – Use the DuckDB CLI to explore DuckLake features, including data versioning and time travel capabilities. • Spark–DuckLake Integration – Show how PySpark can seamlessly write to and read from DuckLake using Spark APIs for data processing
Use Python DuckDB to convert a raw Parquet fi le into a DuckLake table. • Use SparkSQL to query the DuckLake table and perform analytics. • Use PySpark Dataframe API to write the result as a new DuckLake table. • Use PySpark Dataframe API to verify and inspect the output. The integration fl ow: PySpark APP → DuckDB JDBC Driver → JNI → DuckDB (native lib) → DuckLake extension → data fi les on S3 (MinIO)
the database • Files are the storage • Fast query planning and simpli fi ed operations • Still maturing for production use • Tight coupling with DuckDB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}