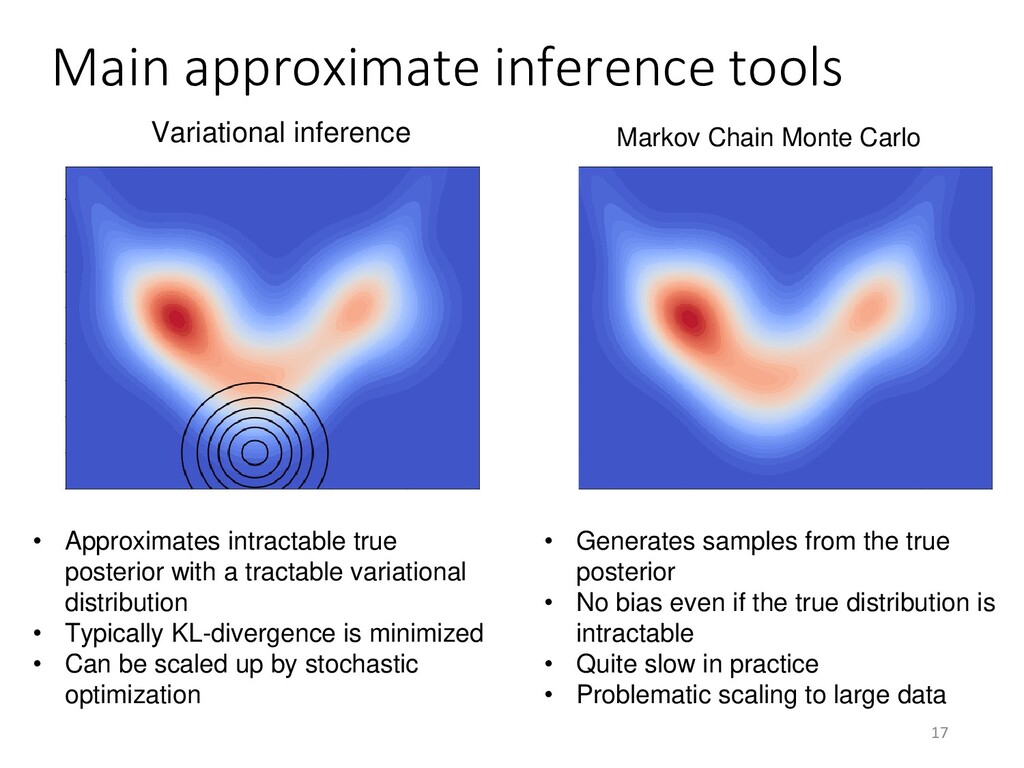
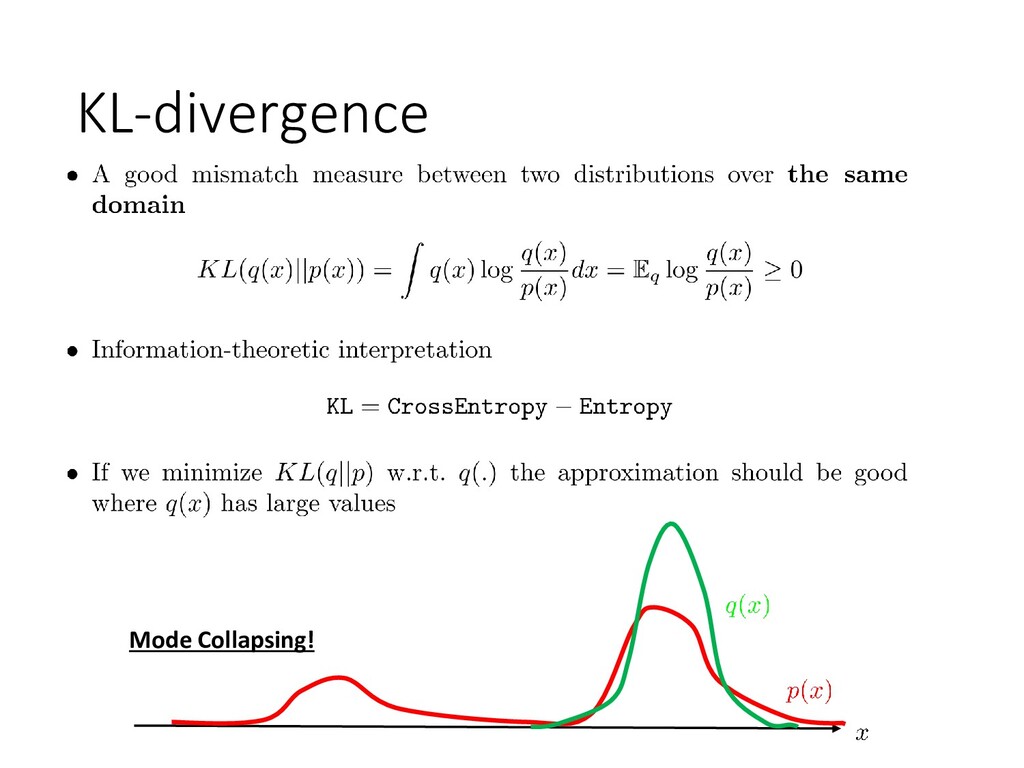
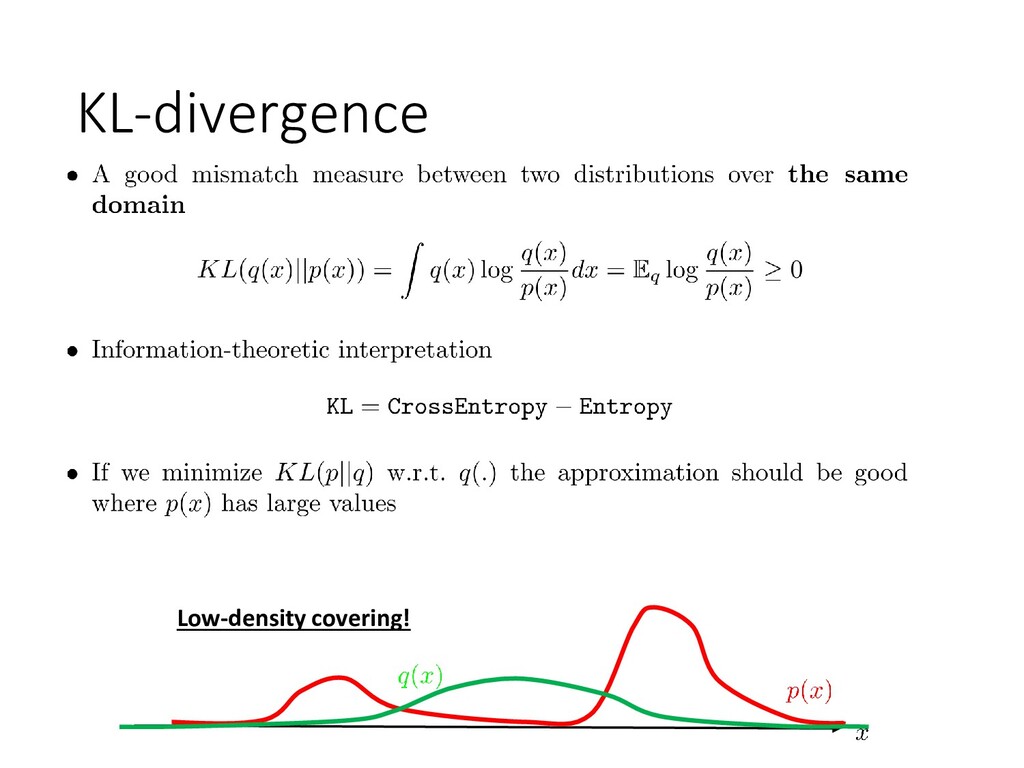
• Typically KL-divergence is minimized • Can be scaled up by stochastic optimization • Generates samples from the true posterior • No bias even if the true distribution is intractable • Quite slow in practice • Problematic scaling to large data Markov Chain Monte Carlo Variational inference 17 Main approximate inference tools
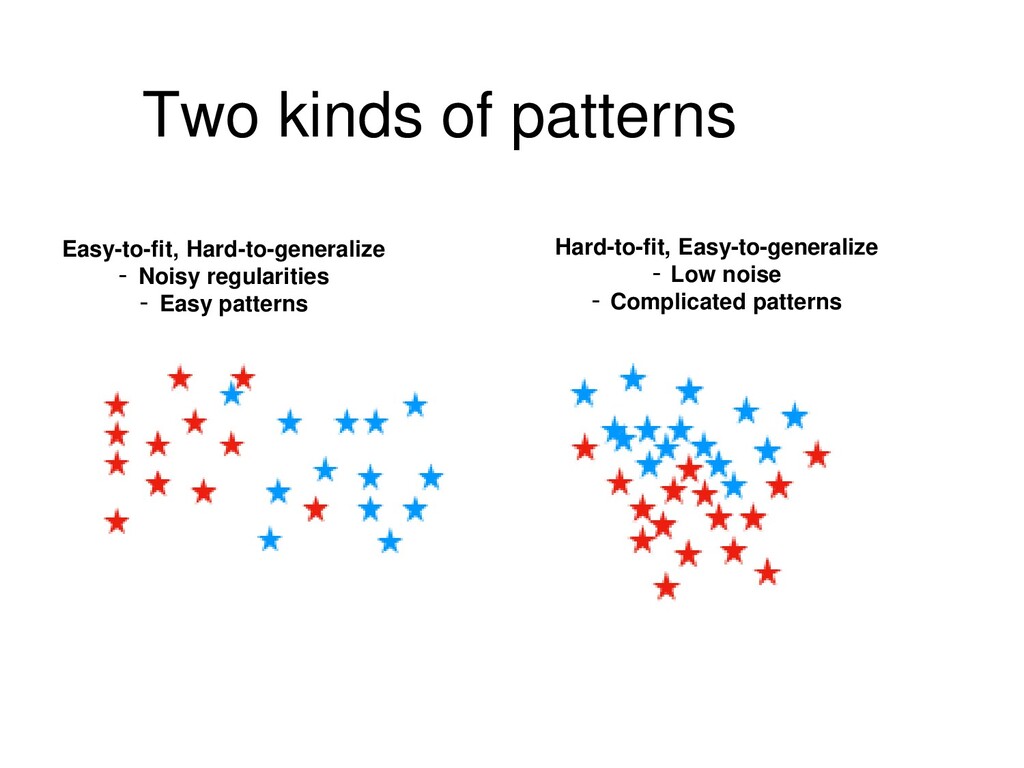
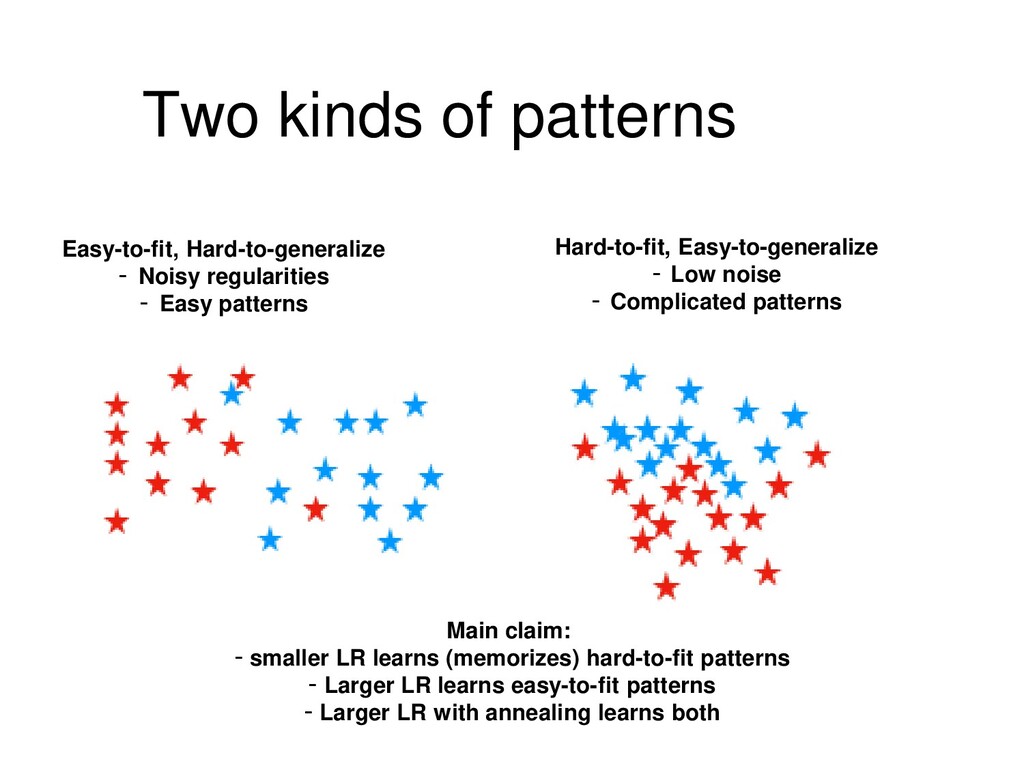
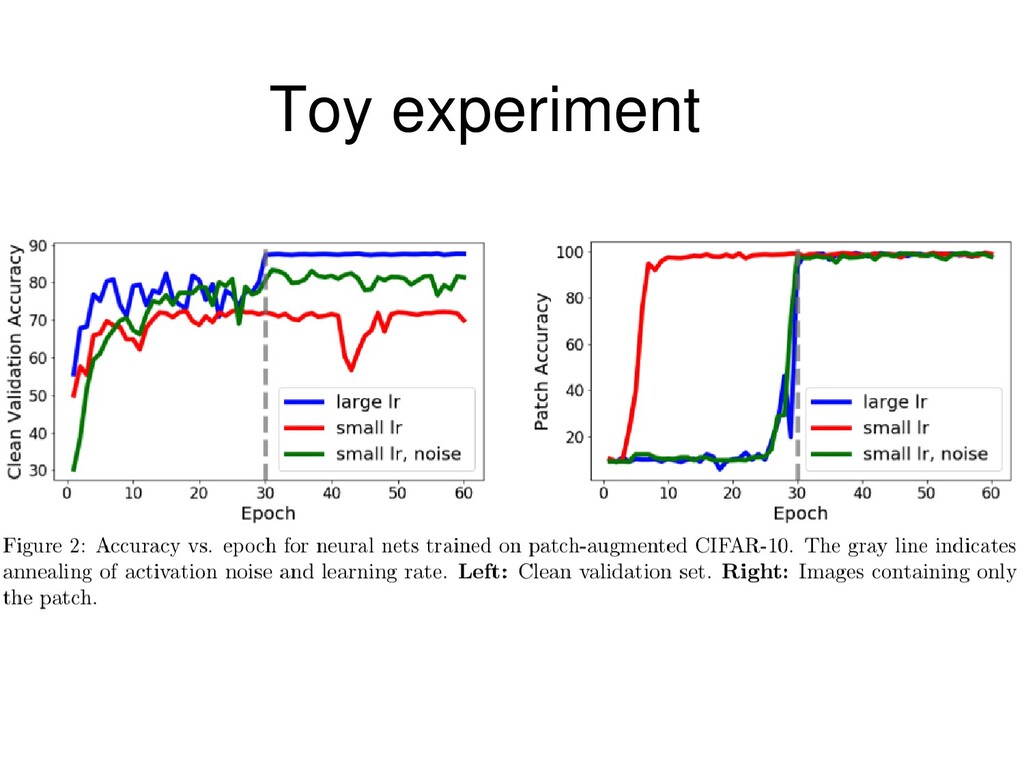
patterns using less data Large LR Learns noisy flexible patterns using full data Unable to memorize objects/patterns Large LR + Annealing First: Learns noisy flexible patterns using full data Second: Memorizes fixed patterns using less data
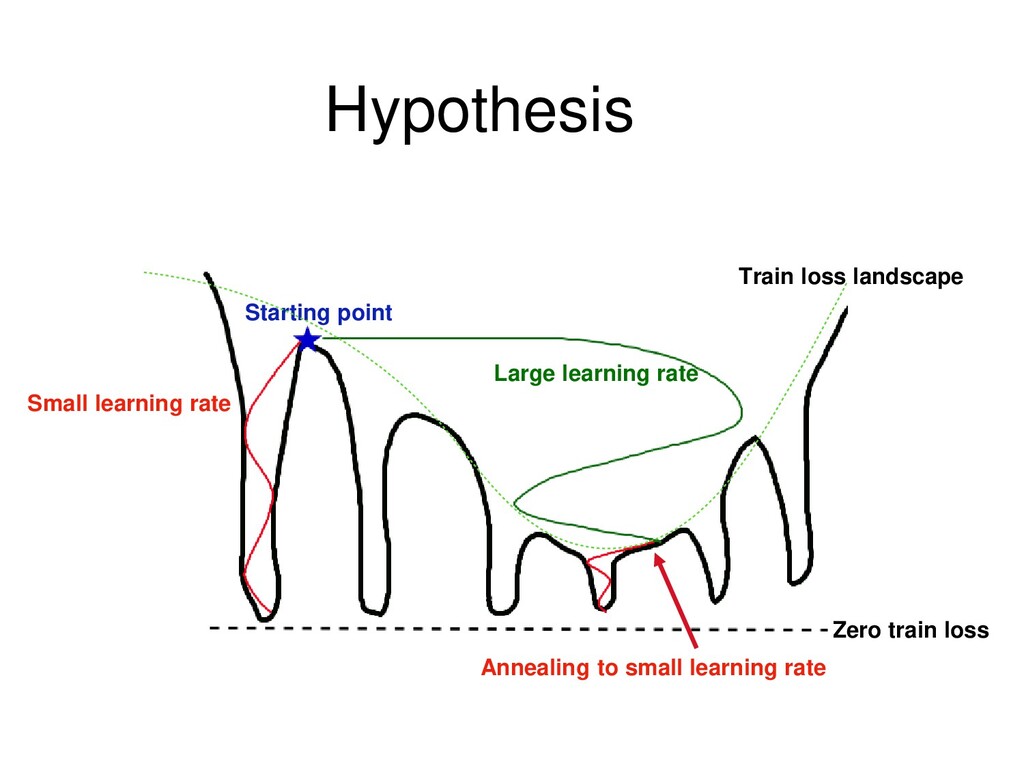
patterns using less data Large LR Learns noisy flexible patterns using full data Unable to memorize objects/patterns Large LR + Annealing First: Learns noisy flexible patterns using full data Second: Memorizes fixed patterns using less data Both noisy and fixed patterns are present in real data Larger LR corresponds to wider local optima (see Khan 2019) E. Khan. Deep learning with Bayesian principles. NeurIPS 2019 tutorial
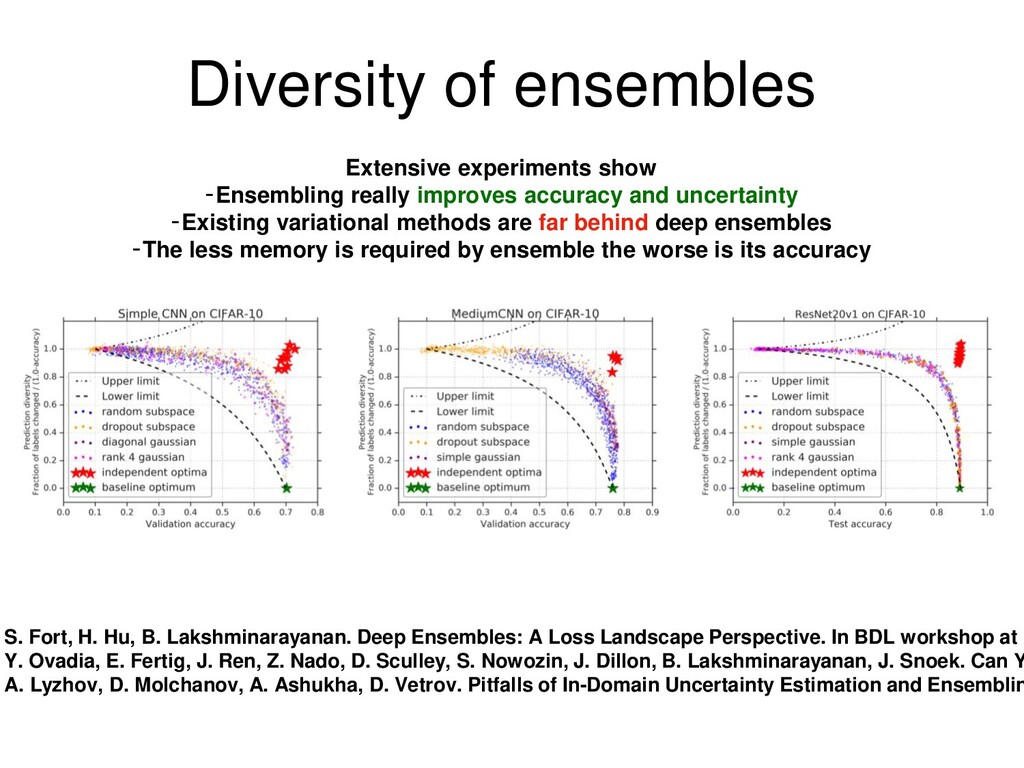
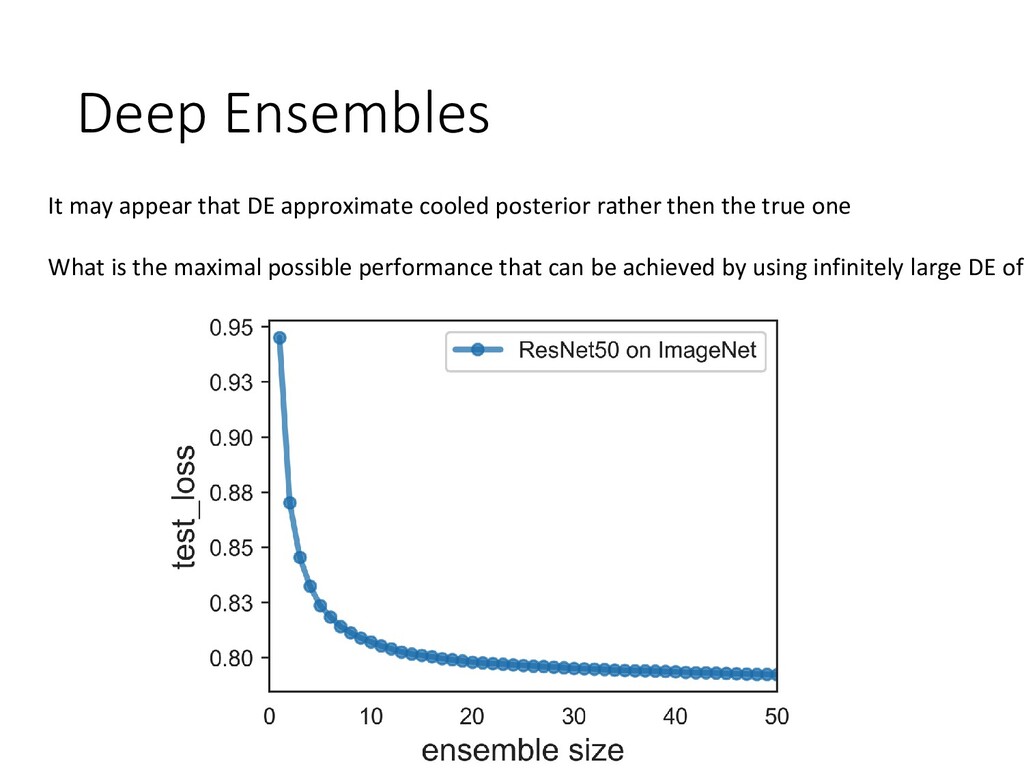
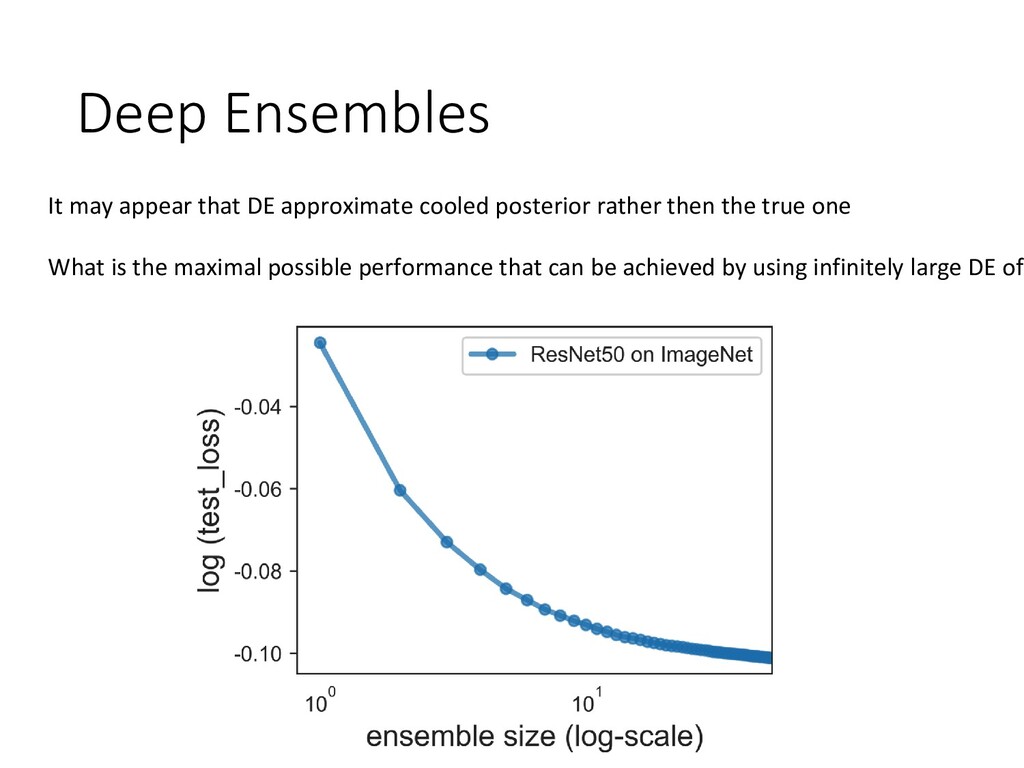
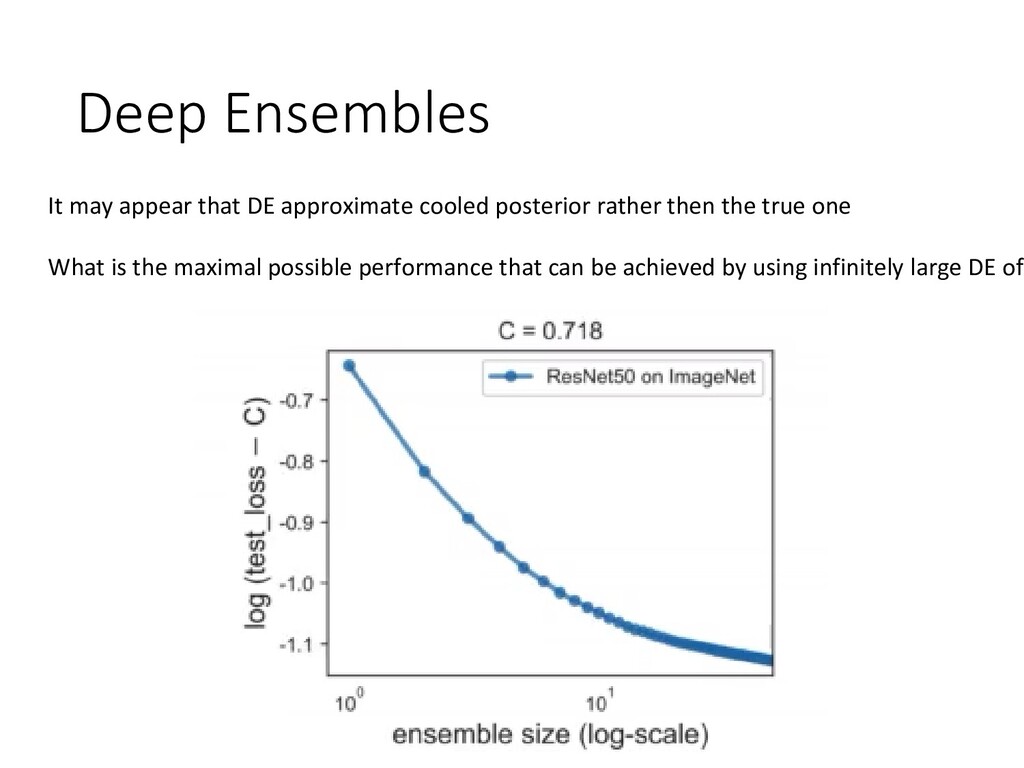
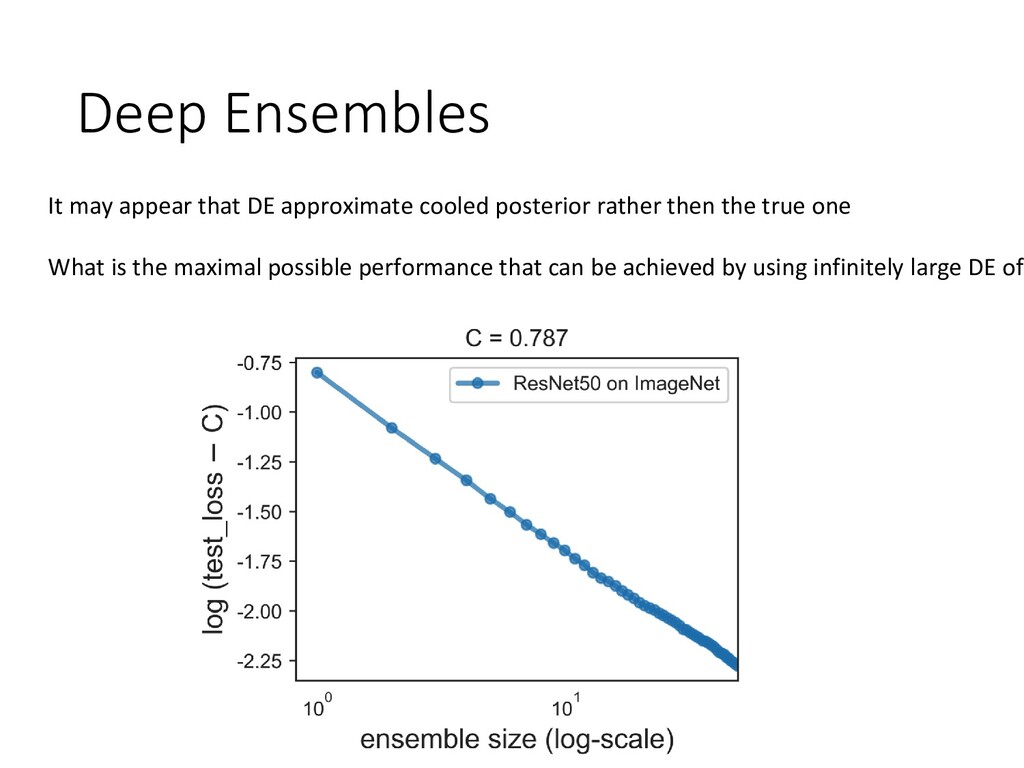
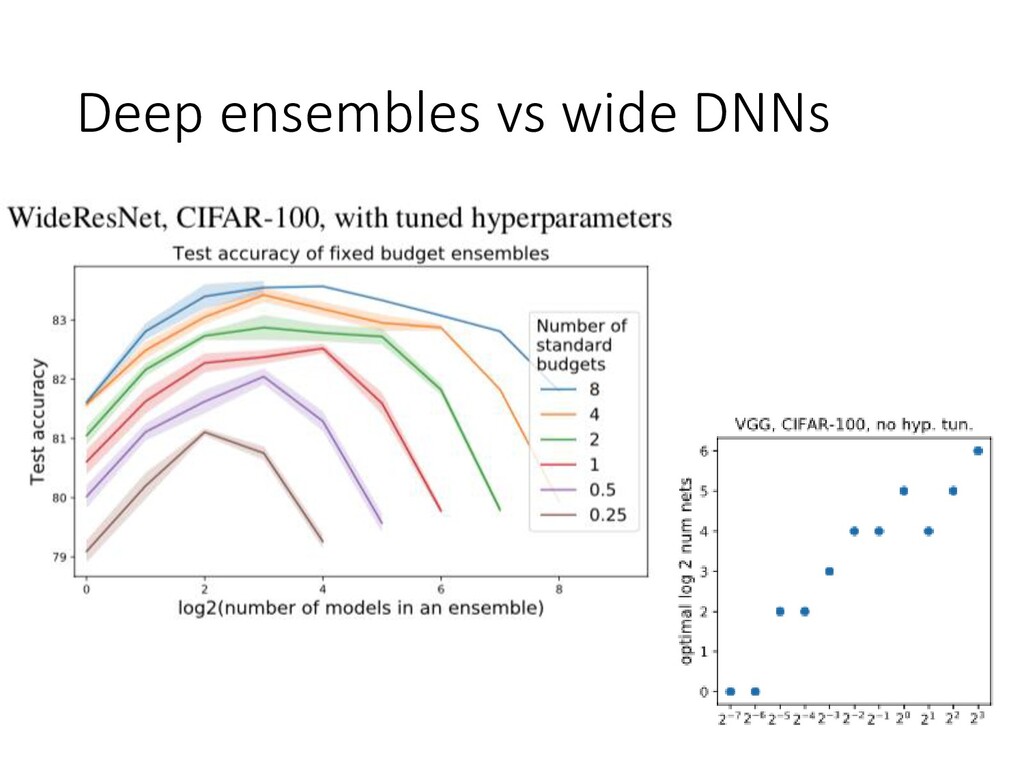
and uncertainty -Existing variational methods are far behind deep ensembles -The less memory is required by ensemble the worse is its accuracy S. Fort, H. Hu, B. Lakshminarayanan. Deep Ensembles: A Loss Landscape Perspective. In BDL workshop at N Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. Dillon, B. Lakshminarayanan, J. Snoek. Can Y A. Lyzhov, D. Molchanov, A. Ashukha, D. Vetrov. Pitfalls of In-Domain Uncertainty Estimation and Ensemblin
• Deep MCMC techniques can become a new probabilistic tool • Loss landscapes (and the corresponding posteriors) are extremely complicated and require further study • Ensembles are highly under-estimated by community • Those and many other topics on Deep|Bayes 2020
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
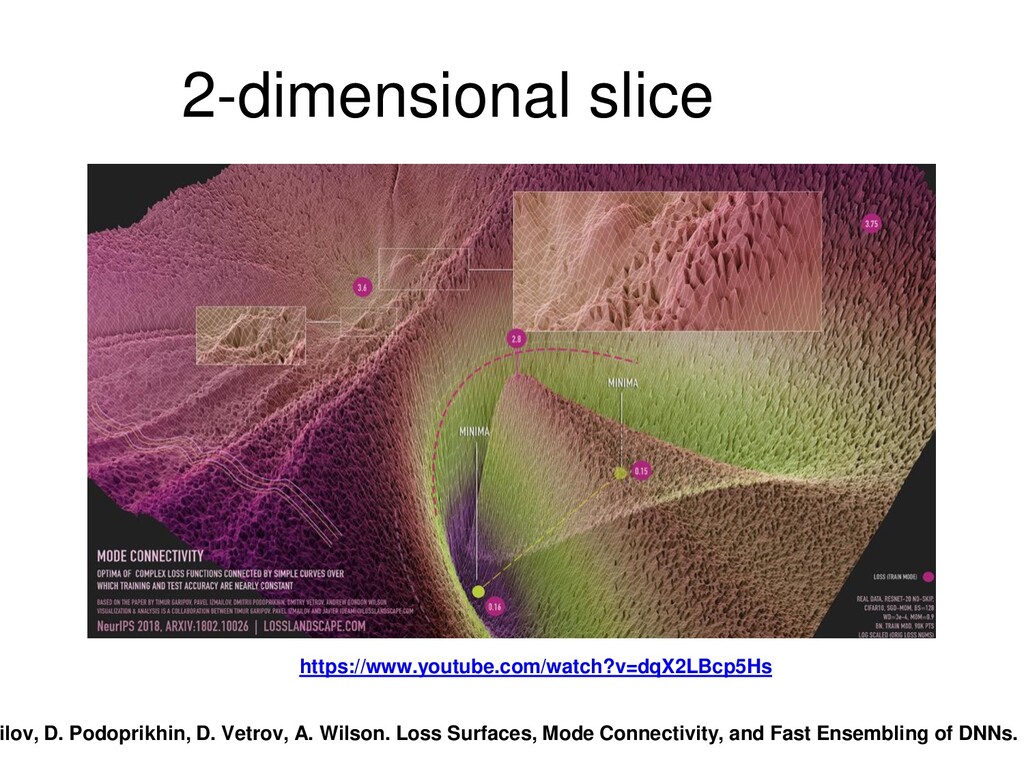{kind=link}
{kind=link}
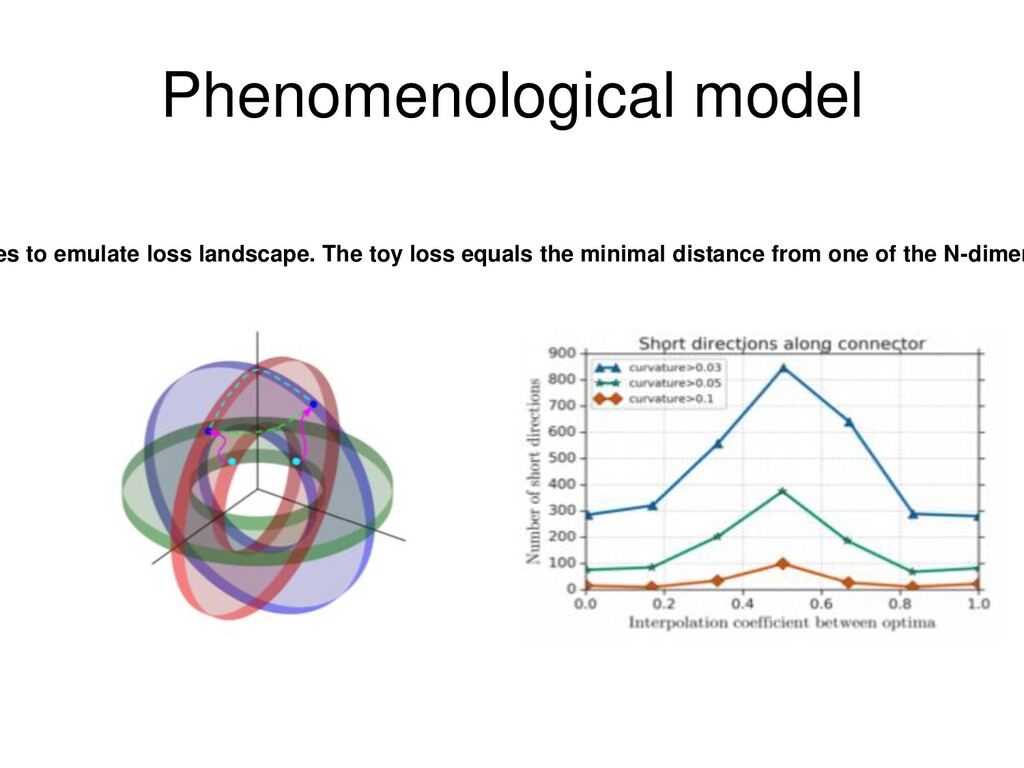{kind=link}
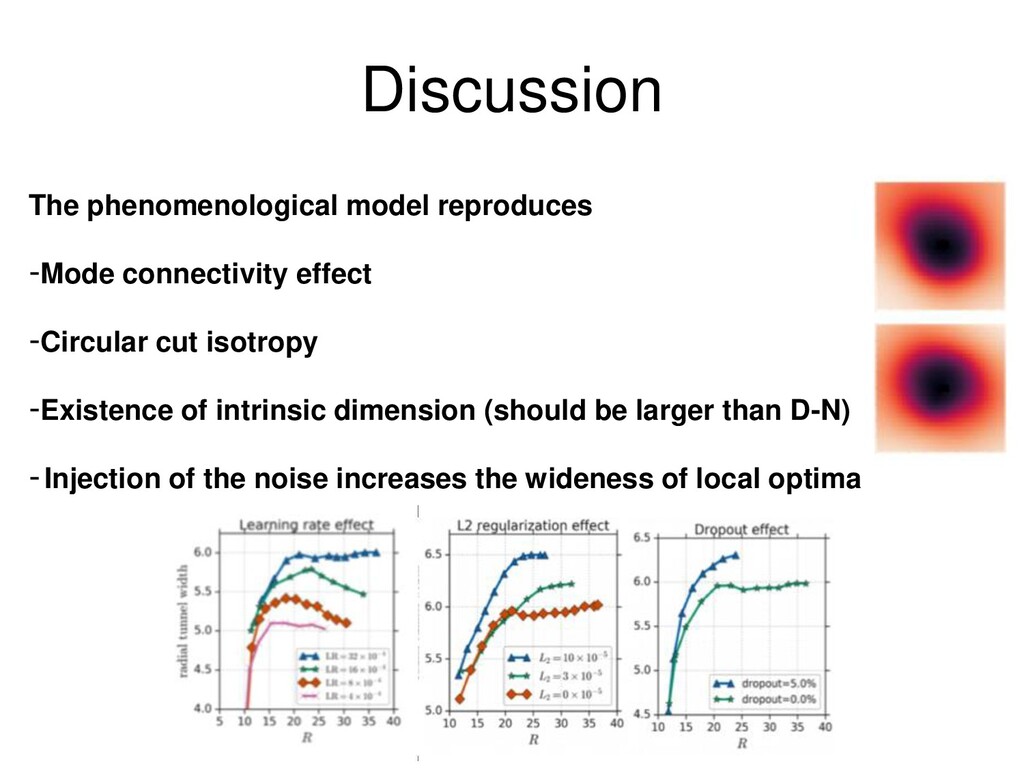{kind=link}
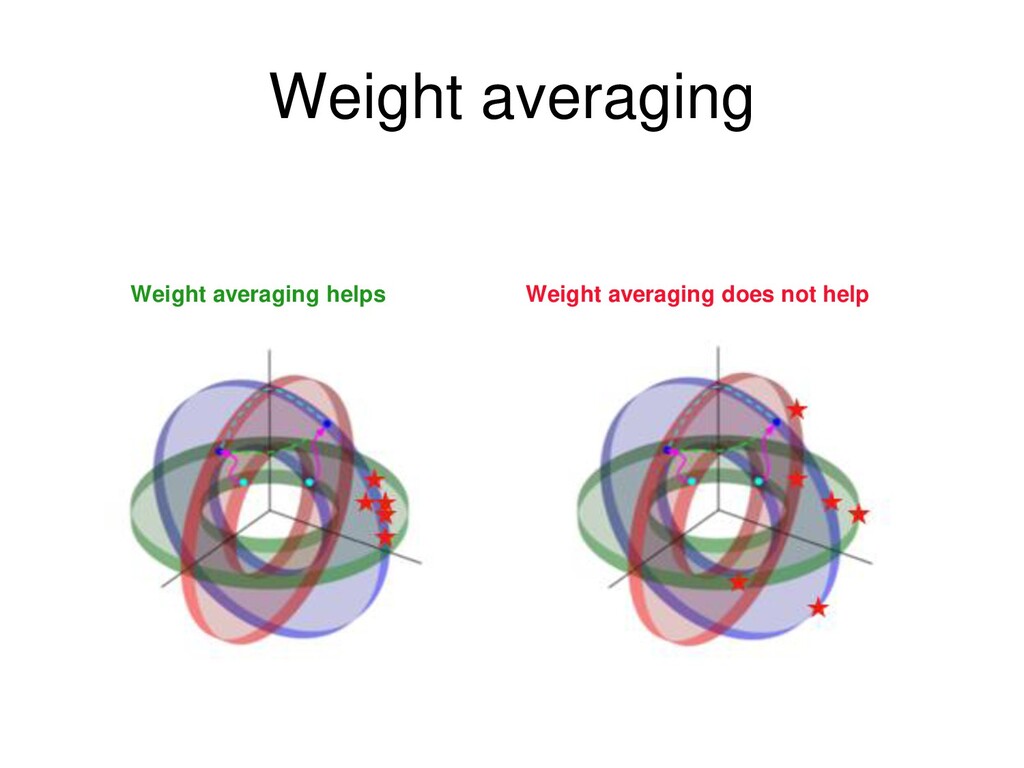{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}