Atlas 500 AI edge station Model 3000/3010 Atlas 300 AI accelerator card Model 3000 Atlas 200 AI accelerator module Model 3000 Atlas 800 AI server Model 3000/3010 Ascend 910 AI processor Atlas 300 AI accelerator card Model 9000 Atlas 800 AI server Model 9000/9010 Atlas 900 AI cluster
Convolution Full-mesh 10% Vector operation Pooling Relu AI computing characteristics • The GPU is not designed for AI computing. Therefore, it is inefficient in matrix multiply computing. Da Vinci architecture: best-fit for AI computing • The Da Vinci architecture is specially designed for AI computing. • Provides cube, vector, and scalar computing units for AI computing • The Da Vinci architecture has a large proportion of cubes, enabling high matrix multiply computing efficiency, and optimal area-to-efficiency ratio. 16 x 16 x 16 cubes Vector Scalar Other AI Chip Architectures Da Vinci Architecture Chip area (12nm) 5.x mm2 13.x mm2 Computing power 1.7 TOPS FP16 8 TOPS FP16 Area-to-efficiency ratio ~0.3 ~0.6 ~90% are matrix multiply operation • AI computing is mainly based on the convolutional neural network (CNN) model. • About 90% of the CNN model is based on matrix multiply operations. • The cube computing unit is the most suitable. GPU NPU Applicab le only to HPC, not AI Scalar 4 x 4 x 4 cubes 2x area-to- efficiency ratio On the same area, the Da Vinci architecture delivers 2x computing power.
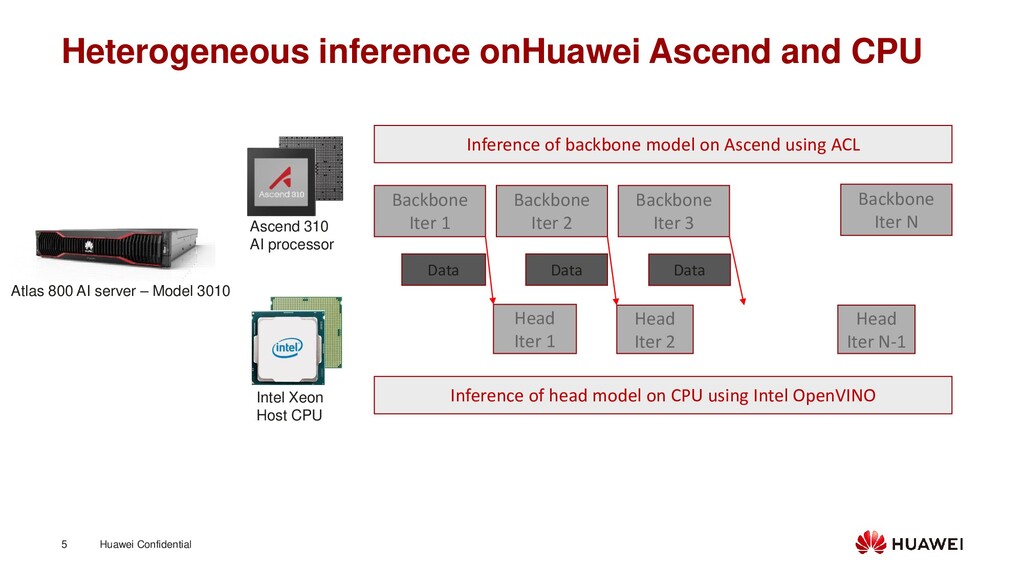
310 AI processor Atlas 800 AI server – Model 3010 Intel Xeon Host CPU Backbone Iter 1 Head Iter 1 Backbone Iter 2 Backbone Iter 3 Head Iter 2 Backbone Iter N Head Iter N-1 Data Data Data Inference of backbone model on Ascend using ACL Inference of head model on CPU using Intel OpenVINO
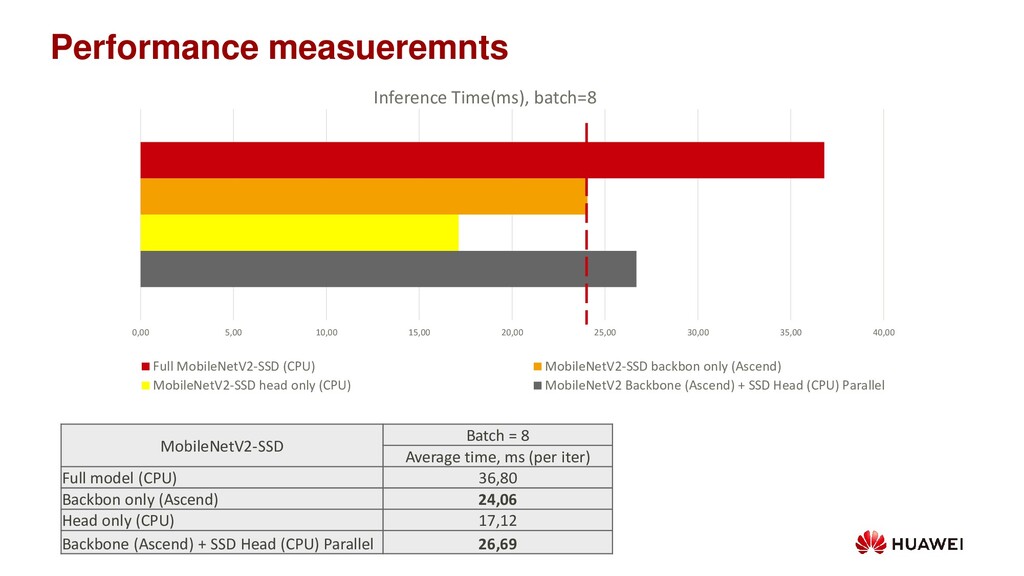
25,00 30,00 35,00 40,00 Inference Time(ms), batch=8 Full MobileNetV2-SSD (CPU) MobileNetV2-SSD backbon only (Ascend) MobileNetV2-SSD head only (CPU) MobileNetV2 Backbone (Ascend) + SSD Head (CPU) Parallel MobileNetV2-SSD Batch = 8 Average time, ms (per iter) Full model (CPU) 36,80 Backbon only (Ascend) 24,06 Head only (CPU) 17,12 Backbone (Ascend) + SSD Head (CPU) Parallel 26,69
in this document may contain predictive statements including, without limitation, statements regarding the future financial and operating results, future product portfolio, new technology, etc. There are a number of factors that could cause actual results and developments to differ materially from those expressed or implied in the predictive statements. Therefore, such information is provided for reference purpose only and constitutes neither an offer nor an acceptance. Huawei may change the information at any time without notice. 把数字世界带入每个人、每个家庭、 每个组织,构建万物互联的智能世界。 Bring digital to every person, home, and organization for a fully connected, intelligent world. Thank you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}