Parallelism on GPUs Model Parallelism Types of Model Parallelism and their implementation Code Example Parallelizing Linear layer with Tensor Parallel technique AGENDA
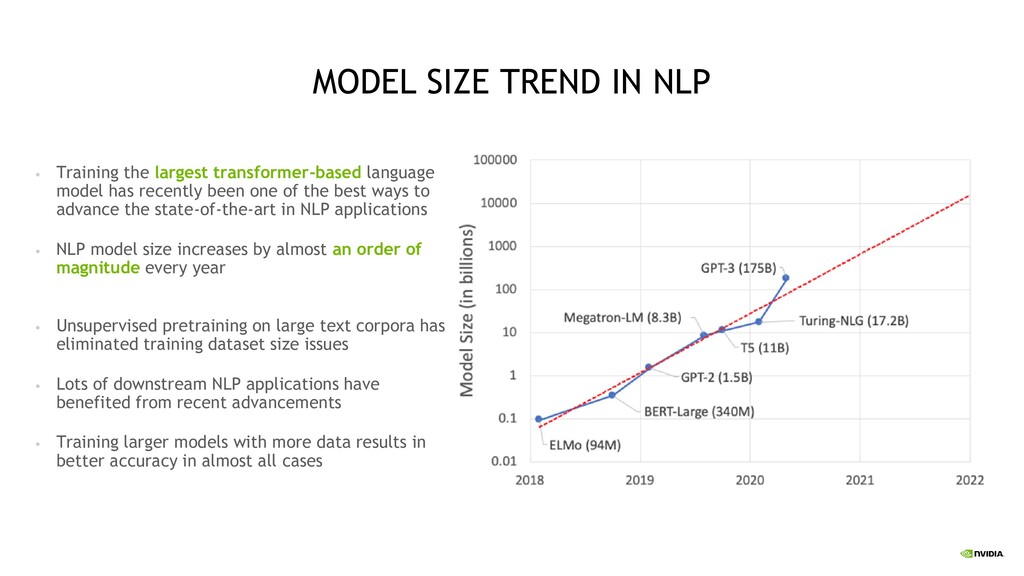
transformer-based language model has recently been one of the best ways to advance the state-of-the-art in NLP applications • NLP model size increases by almost an order of magnitude every year • Unsupervised pretraining on large text corpora has eliminated training dataset size issues • Lots of downstream NLP applications have benefited from recent advancements • Training larger models with more data results in better accuracy in almost all cases
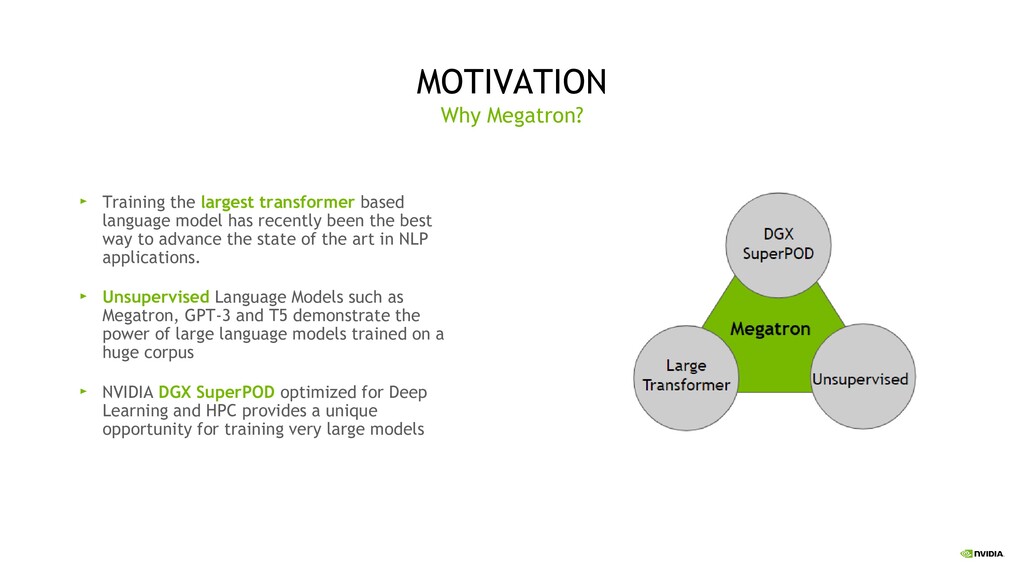
model has recently been the best way to advance the state of the art in NLP applications. Unsupervised Language Models such as Megatron, GPT-3 and T5 demonstrate the power of large language models trained on a huge corpus NVIDIA DGX SuperPOD optimized for Deep Learning and HPC provides a unique opportunity for training very large models
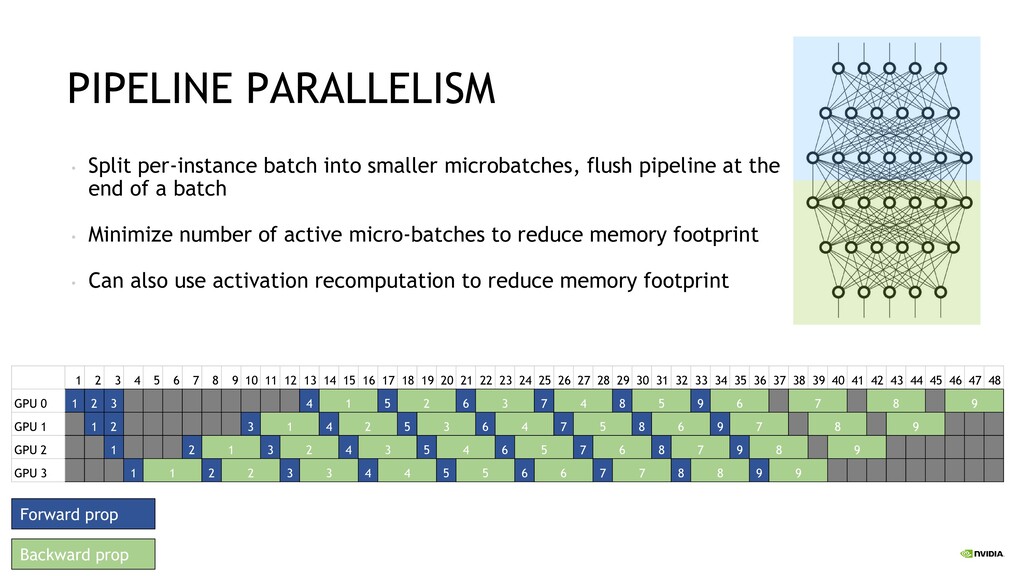
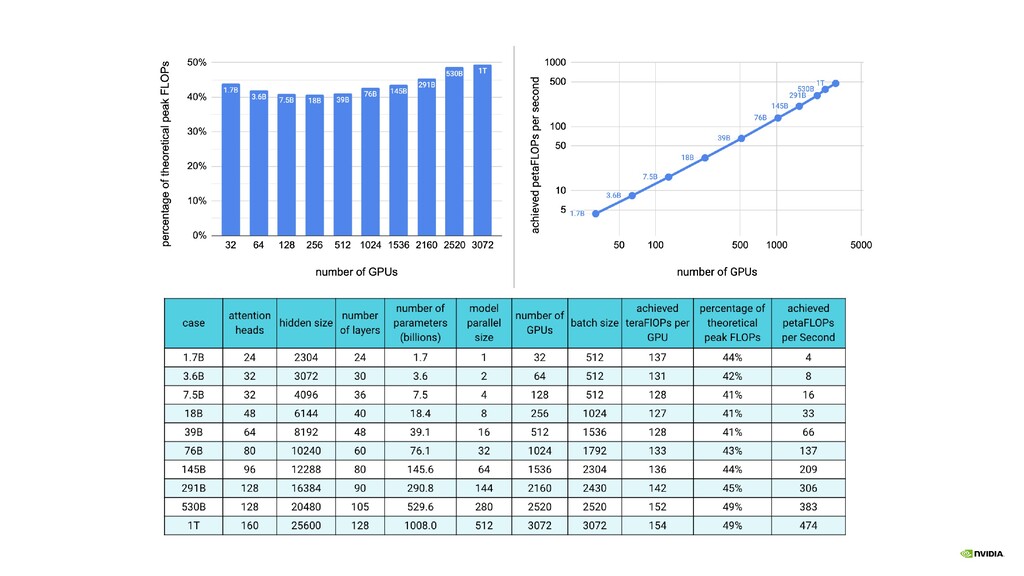
billions and trillions of parameters Requires model parallelism to fit in GPU memory Achieving high utilization and scaling up to thousands of GPUs Devising simple methods that require minimal changes to our existing code-base (reducing barrier to entry) Using the developed methodology to scale out Transformer language models such as GPT-3 and BERT and to explore their representation capabilities What would we like to do with Megatron?
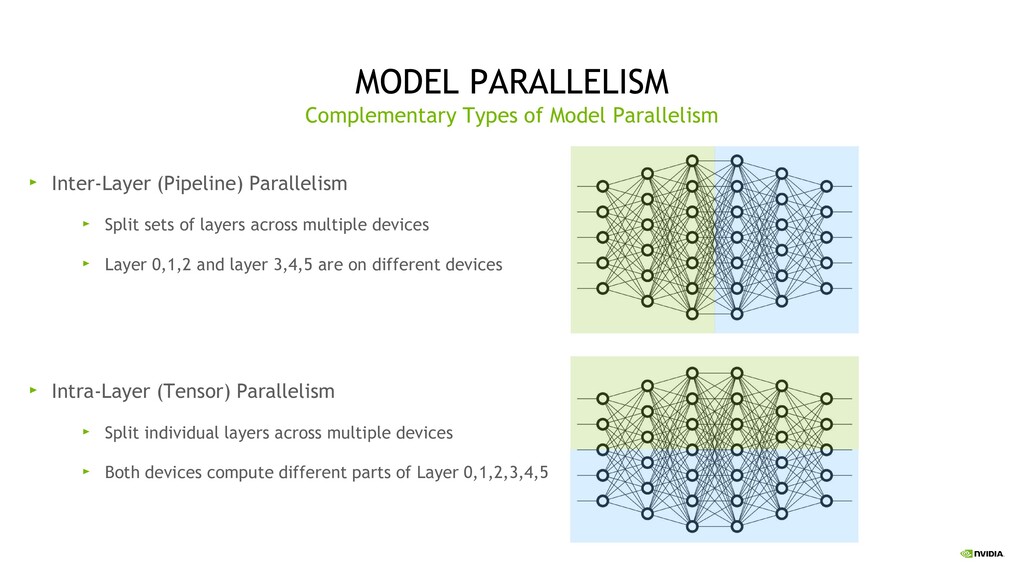
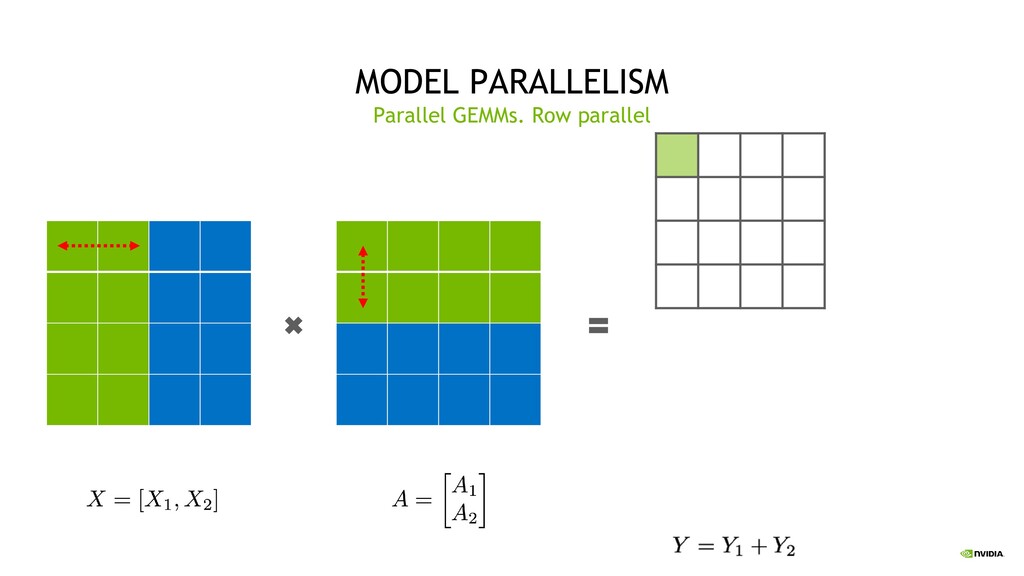
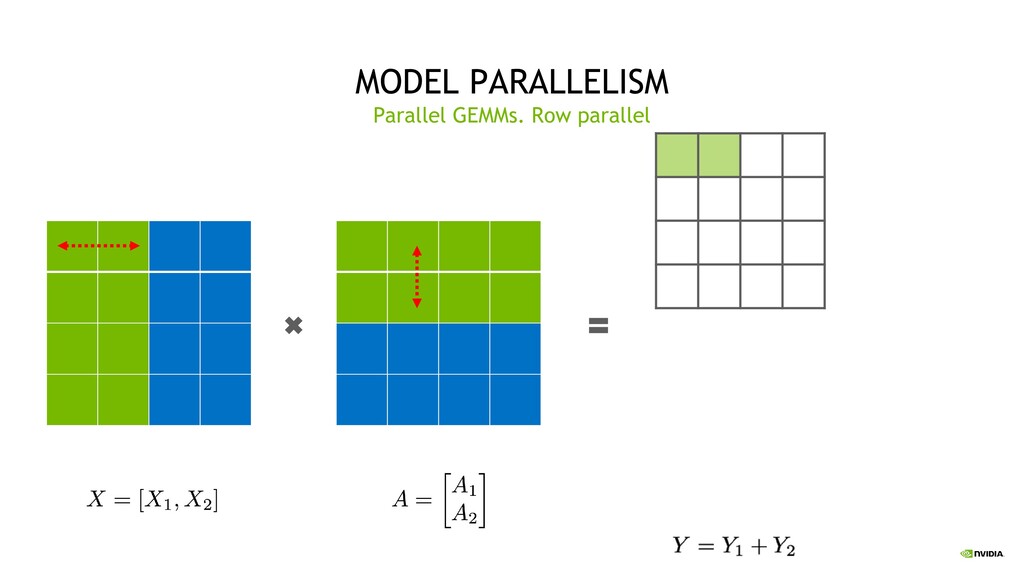
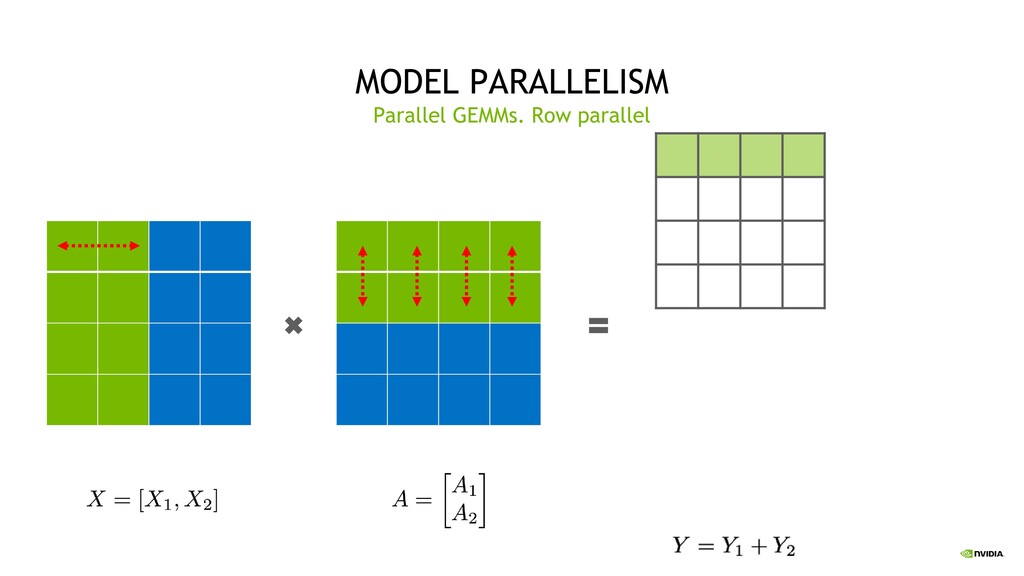
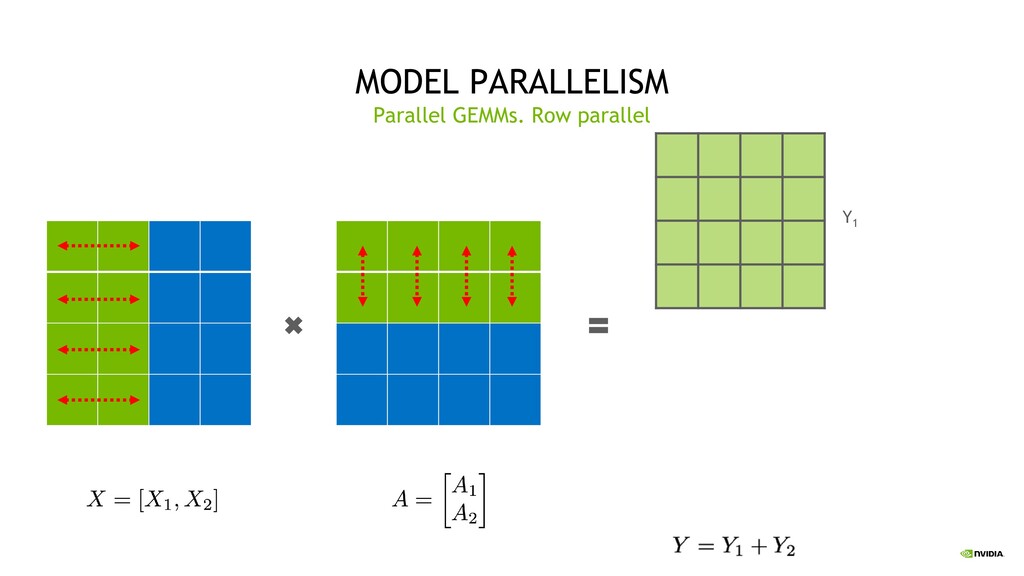
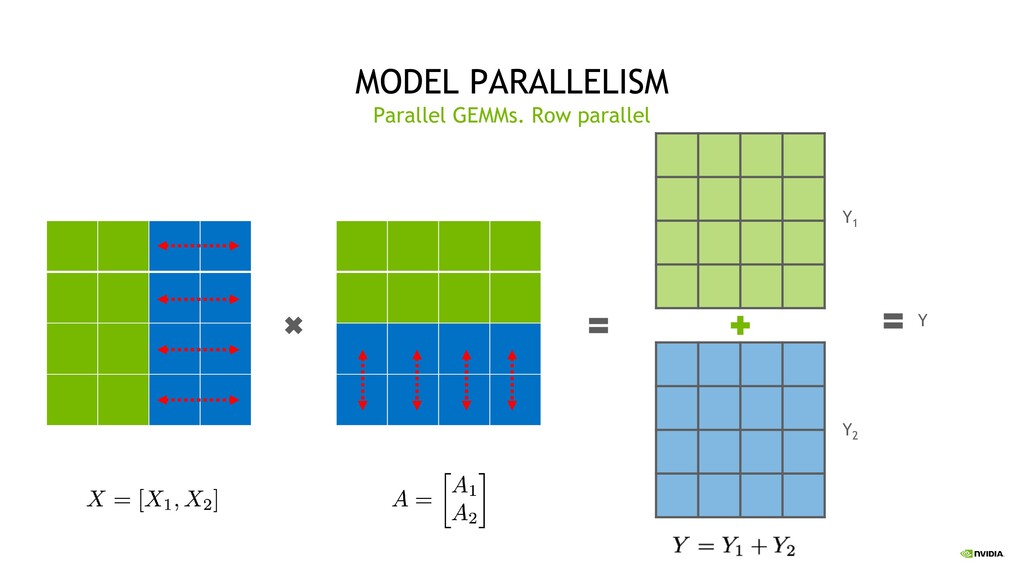
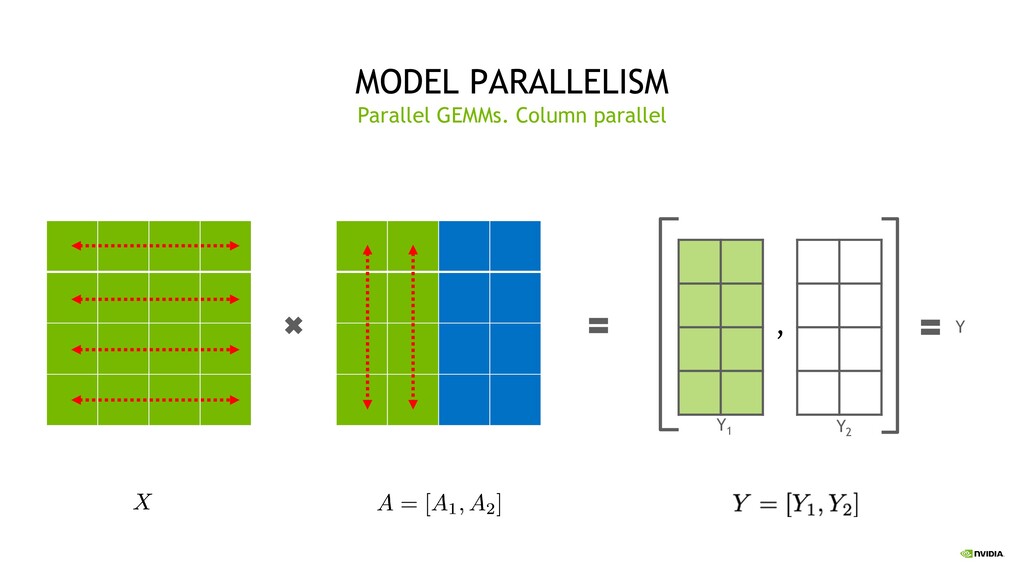
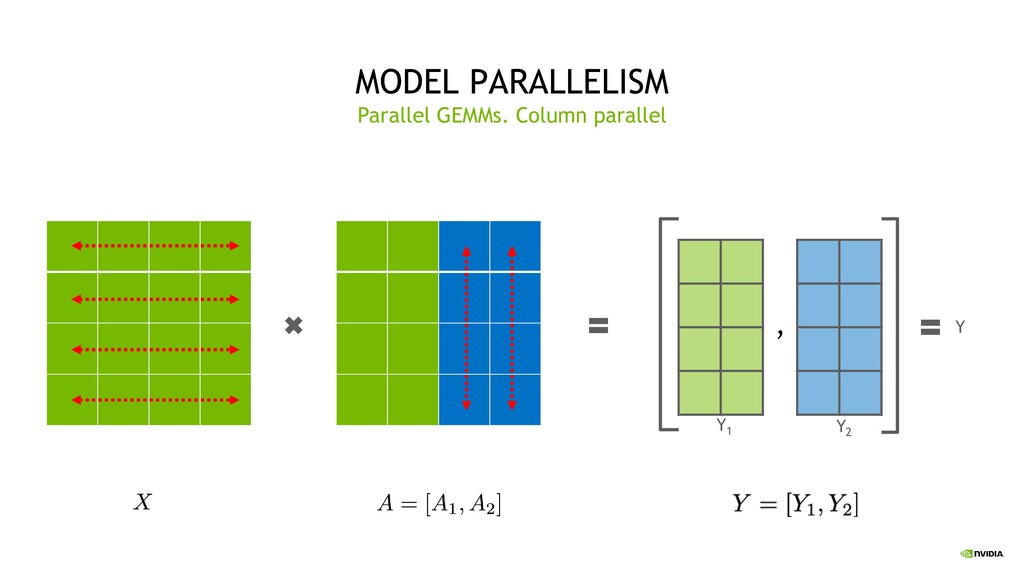
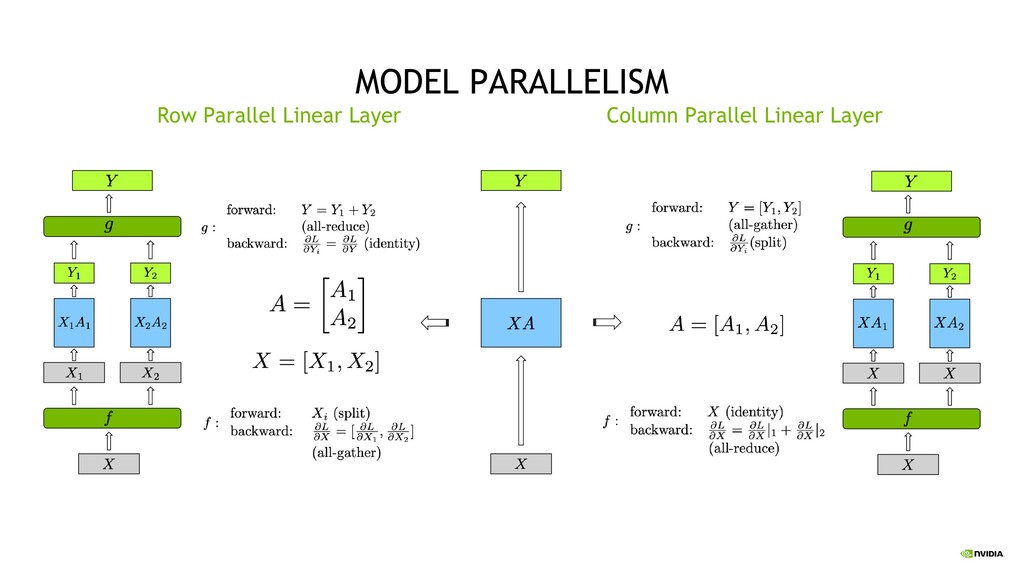
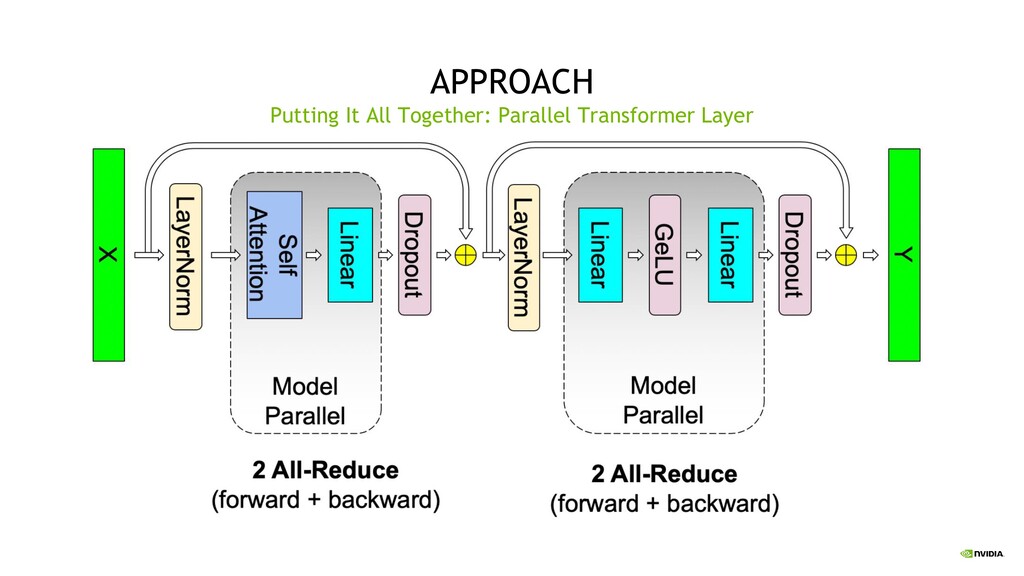
Parallelism Split sets of layers across multiple devices Layer 0,1,2 and layer 3,4,5 are on different devices Intra-Layer (Tensor) Parallelism Split individual layers across multiple devices Both devices compute different parts of Layer 0,1,2,3,4,5
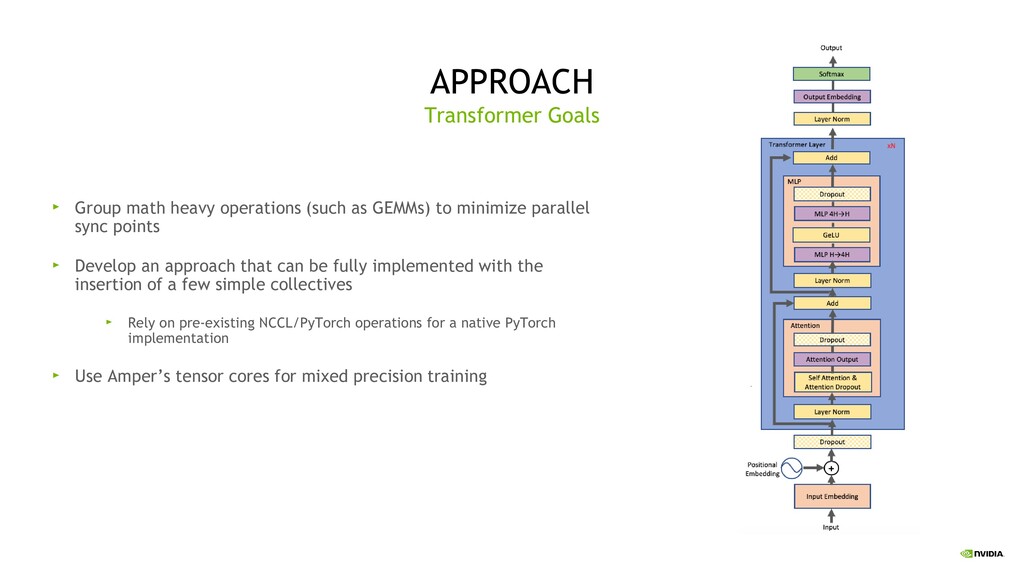
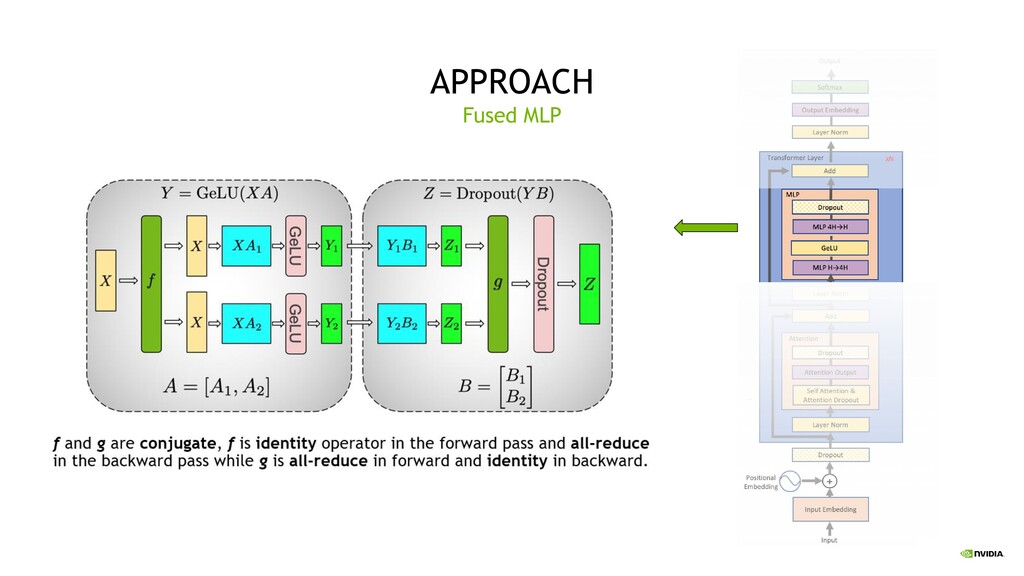
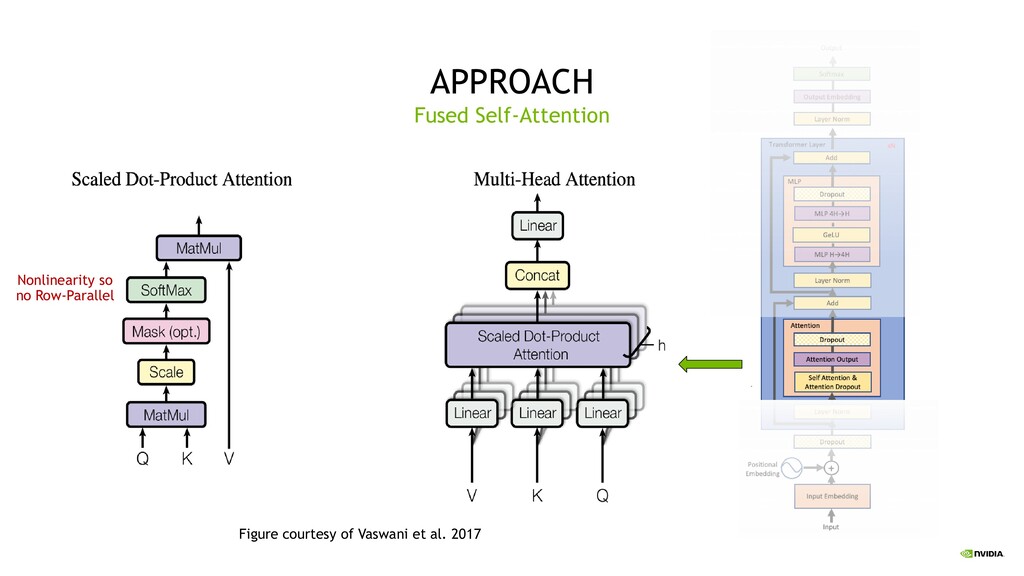
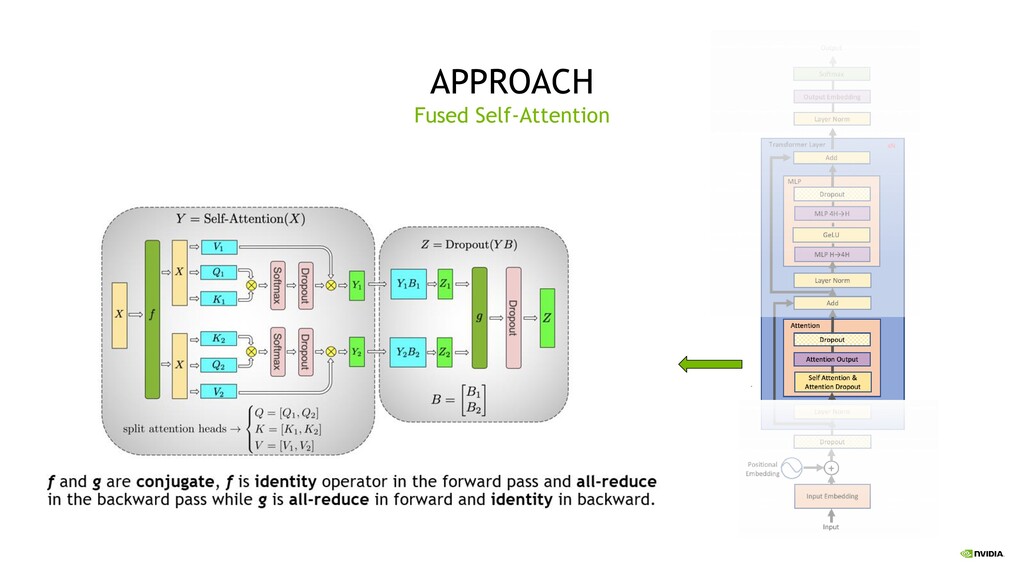
minimize parallel sync points Develop an approach that can be fully implemented with the insertion of a few simple collectives Rely on pre-existing NCCL/PyTorch operations for a native PyTorch implementation Use Amper’s tensor cores for mixed precision training Transformer Goals
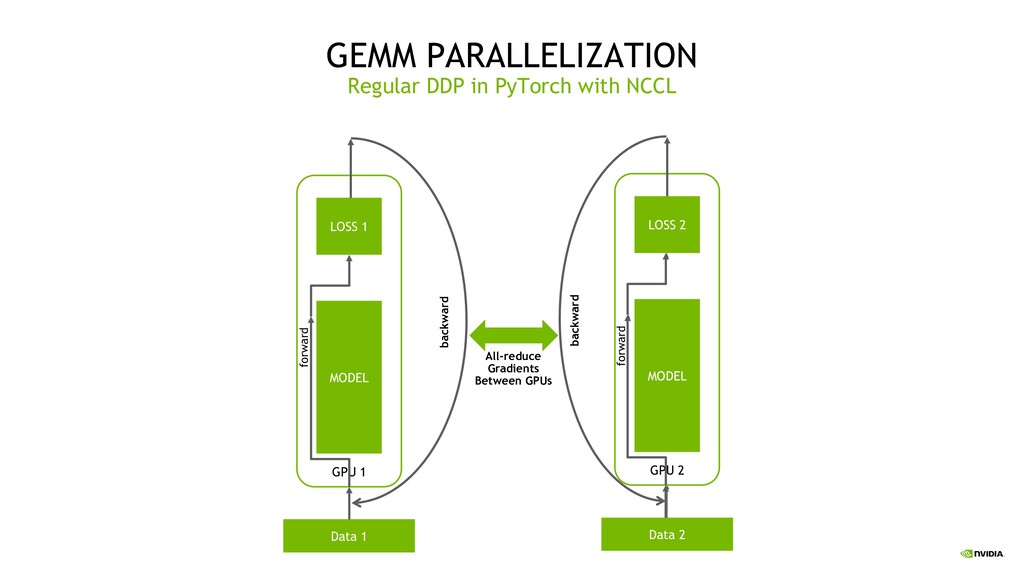
(Distributed Data parallel) We have multiple GPUs and each GPU has a full copy of the same model All distributed code for gradient reducing is incapsulated into DDP We can run this code with: python -m torch.distributed.launch --nproc_per_node=2 train.py `rank` - variable that shows what GPU do this process have to use With NCCL backend all-reduce operations happens directly between GPUs (p2p) Regular DDP in PyTorch with NCCL
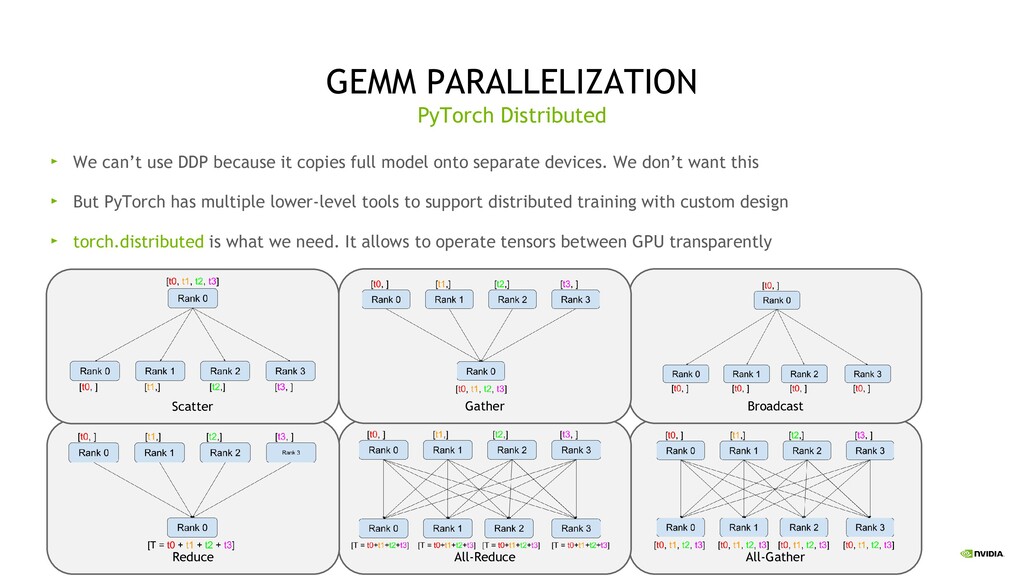
can’t use DDP because it copies full model onto separate devices. We don’t want this But PyTorch has multiple lower-level tools to support distributed training with custom design torch.distributed is what we need. It allows to operate tensors between GPU transparently PyTorch Distributed
researchers, engineers, and innovators to experience global innovation and collaboration. Don’t miss out on the exclusive GTC keynote by Jensen Huang on April 12, available to everyone. Visit www.nvidia.com/gtc to learn more and be notified when registration opens. THE CONFERENCE FOR AI INNOVATORS, TECHNOLOGISTS, AND CREATIVES Join us at GTC 2021 on April 12 - 16 for the latest in AI, HPC, healthcare, game developing, networking, and more.
![Denis Timonin, DL/ML Solutions Architect NVIDIA [email protected] February 2021 MEGATRON-LM:](https://files.speakerdeck.com/presentations/fa43a493038b4f7298671c2c9fa755bd/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}