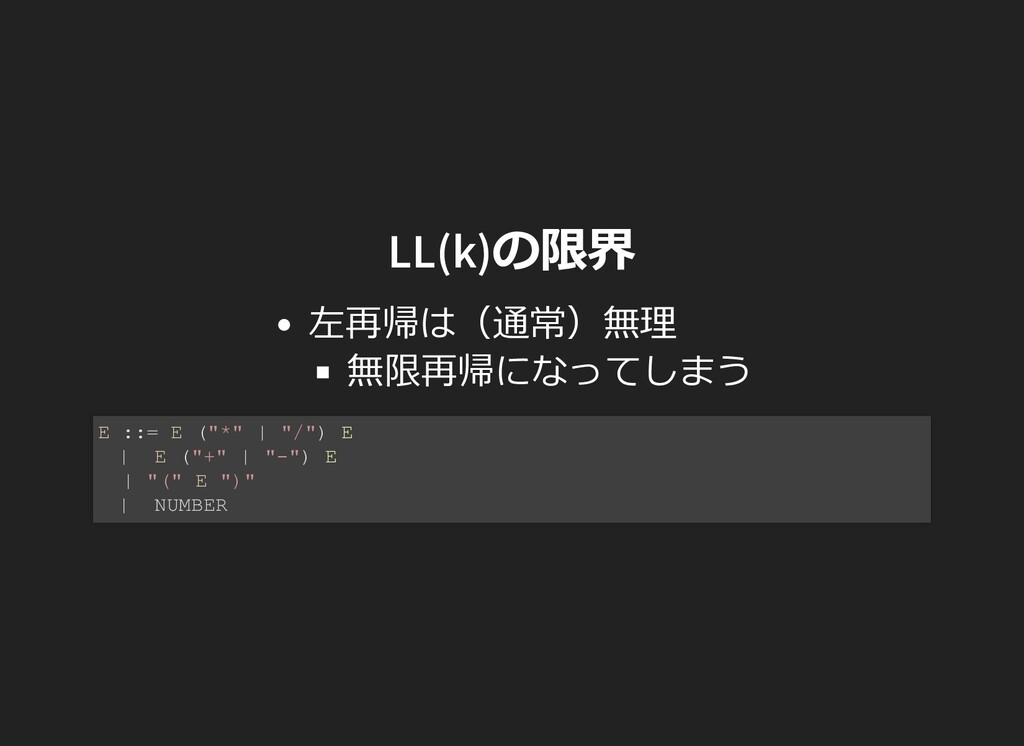
..., "9"} FIRST("(") = {"("} N が選択される → ⼊⼒が「消費される」 E ::= /* => */ A ("+" E | "-" E | ""); A ::= /* => */ P ("*" A | "/" A | ""); P ::= /* -> */ "(" E ")" | N;
= {"/"} FOLLOW("") = {"+", "-"} ""が選択される → ⼊⼒が「消費されない」 E ::= /* => */ A ("+" E | "-" E | ""); A ::= P /* -> */ ("*" A | "/" A | ""); P ::= | "(" E ")" | N;
..., "9"} FIRST("(" E ")") = {"("} N が選択される → ⼊⼒が「消費される」 E ::= /* => */ A ("+" E | "-" E | ""); A ::= /* => */ P ("*" A | "/" A | ""); P ::= /* -> */ "(" E ")" | N;
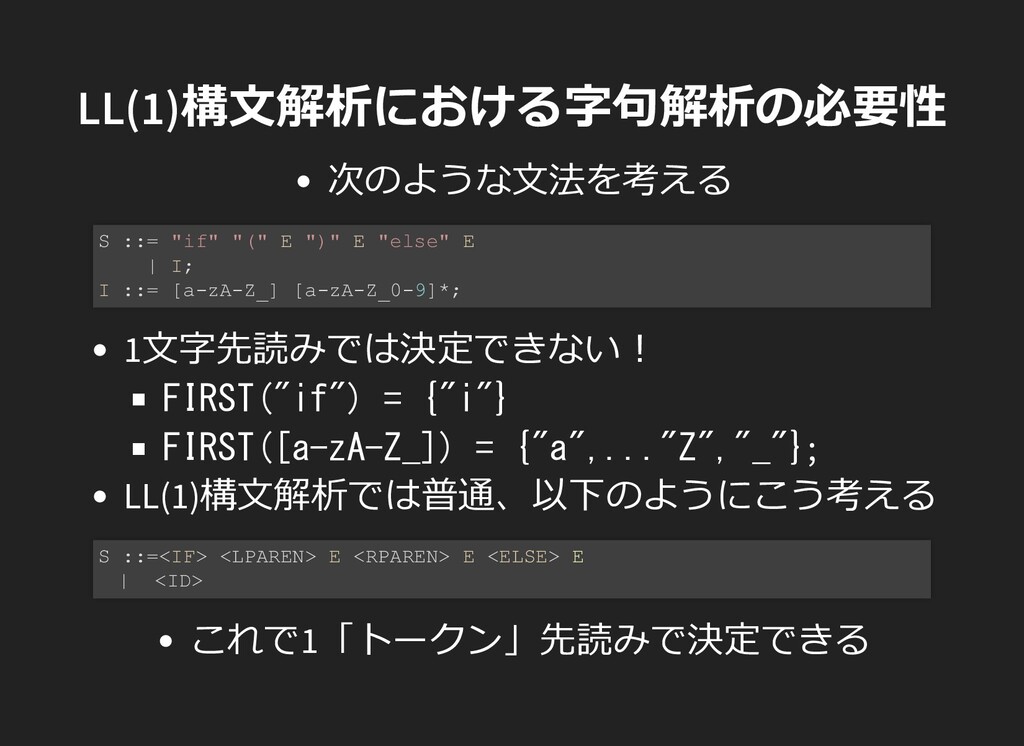
"else" E | I; I ::= [a-zA-Z_] [a-zA-Z_0-9]*; 1⽂字先読みでは決定できない︕ FIRST("if") = {"i"} FIRST([a-zA-Z_]) = {"a",..."Z","_"}; LL(1)構⽂解析では普通、以下のようにこう考える S ::=<IF> <LPAREN> E <RPAREN> E <ELSE> E | <ID> これで1「トークン」先読みで決定できる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}