Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
シン・Kafka / shin-kafka
Search
oracle4engineer
PRO
April 10, 2024
Video
Technology
4.1k
20
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
シン・Kafka / shin-kafka
2024/04/10に行われたOCHaCafe Season 8-3「シン・Kafka」で使用したスライドです
oracle4engineer
PRO
April 10, 2024
Video
More Decks by oracle4engineer
See All by oracle4engineer
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Deep Data Security 機能解説
oracle4engineer
PRO
2
310
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
640
Oracle AI Databaseデータベース・サービスのメンテナンス(BaseDB/ExaDB-D/ExaDB-XS)
oracle4engineer
PRO
4
2k
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.6k
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
2.2k
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3.2k
CrossplaneによるCloud Native Control Plane
oracle4engineer
PRO
0
130
Other Decks in Technology
See All in Technology
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
110
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
140
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
280
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
130
CIで使うClaude
iwatatomoya
0
290
はじめてのWDM
miyukichi_ospf
1
150
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
14
2.1k
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
360
穢れた技術選定について
watany
17
5.4k
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
420
Featured
See All Featured
Claude Code のすすめ
schroneko
67
230k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
The Invisible Side of Design
smashingmag
301
52k
Typedesign – Prime Four
hannesfritz
42
3.1k
We Have a Design System, Now What?
morganepeng
55
8.2k
Building AI with AI
inesmontani
PRO
1
1.1k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Designing Experiences People Love
moore
143
24k
The agentic SEO stack - context over prompts
schlessera
0
850
From π to Pie charts
rasagy
0
240
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Transcript
シン・Kafka Oracle Cloud Hangout Café – Season 8#3 Shuhei Kawamura
Cloud Architect Oracle Digital, Oracle Corporation Japan April 10, 2024
Copyright © 2024, Oracle and/or its affiliates 2 • 所属
• オラクルデジタル本部/⽇本オラクル株式会社 • コミュニティ • OCHaCafe • CloudNative Days – Observability 川村 修平 (Shuhei Kawamura) @shukawam X/GitHub/Qiita
Copyright © 2024, Oracle and/or its affiliates 3 Agenda 1.
⼊⾨編 – Apache Kafkaとは︖ 2. 実践編 – Apache Kafka w/ CLI, Java Client 3. 応⽤編 – Cloud Native x Apache Kafka • KRaft – Kafka without ZooKeeper • Strimzi – Kafka Kubernetes Operator • Kafkaと分散トレーシング(OpenTelemetry)
Copyright © 2024, Oracle and/or its affiliates 4 ⼊⾨編 –
Apache Kafkaとは︖
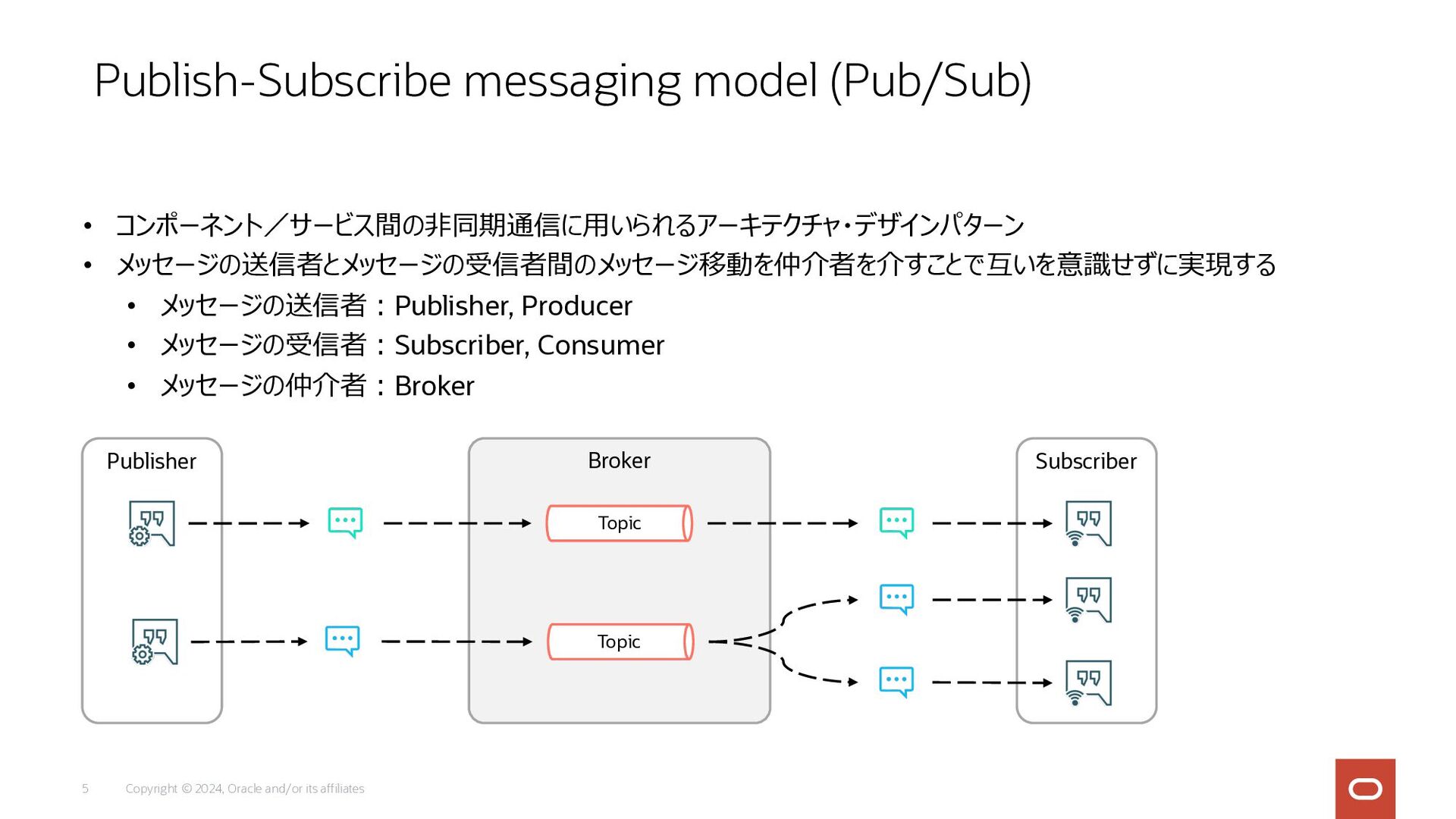
Copyright © 2024, Oracle and/or its affiliates 5 • コンポーネント/サービス間の⾮同期通信に⽤いられるアーキテクチャ・デザインパターン
• メッセージの送信者とメッセージの受信者間のメッセージ移動を仲介者を介すことで互いを意識せずに実現する • メッセージの送信者︓Publisher, Producer • メッセージの受信者︓Subscriber, Consumer • メッセージの仲介者︓Broker Publish-Subscribe messaging model (Pub/Sub) Publisher Broker Subscriber Topic Topic
Copyright © 2024, Oracle and/or its affiliates 6 コンポーネント/サービス間の疎結合化 •
通信ロジックとビジネスロジックを切り離すことで、コンポーネントの分離が可能 ⾼いスケーラビリティ • (理論的には)任意の数のPublisherが任意の数のSubscriberと通信可能 • 急激な負荷上昇をBrokerが介在することで対応 • Subscriberの都合の良いタイミングで読み込めば良い ⾔語に⾮依存 • コンポーネント/サービス間の相互通信は、Pub/Subを介して⾏う • Pub/Subがコンポーネント間の接続周りを担う Pub/Sub modelのメリット
Copyright © 2024, Oracle and/or its affiliates 7 Apache Kafka®
is an event streaming platform • by https://kafka.apache.org/documentation/ - gettingStarted LinkedInで開発されOSSへ(現在、Apache Software Foundation管理) • Java/Scalaで実装されている • ちなみに、名前の由来は⼩説家である“Franz Kafka” よく使われる領域 • イベント駆動アーキテクチャにおけるメッセージ・ブローカー • Streaming ETL(= OLTPをOLAPに繋ぐ) • アクティビティトラッキング • ログ、メトリクス等のテレメトリー・データの収集/集計 • … Apache Kafka https://kafka.apache.org/
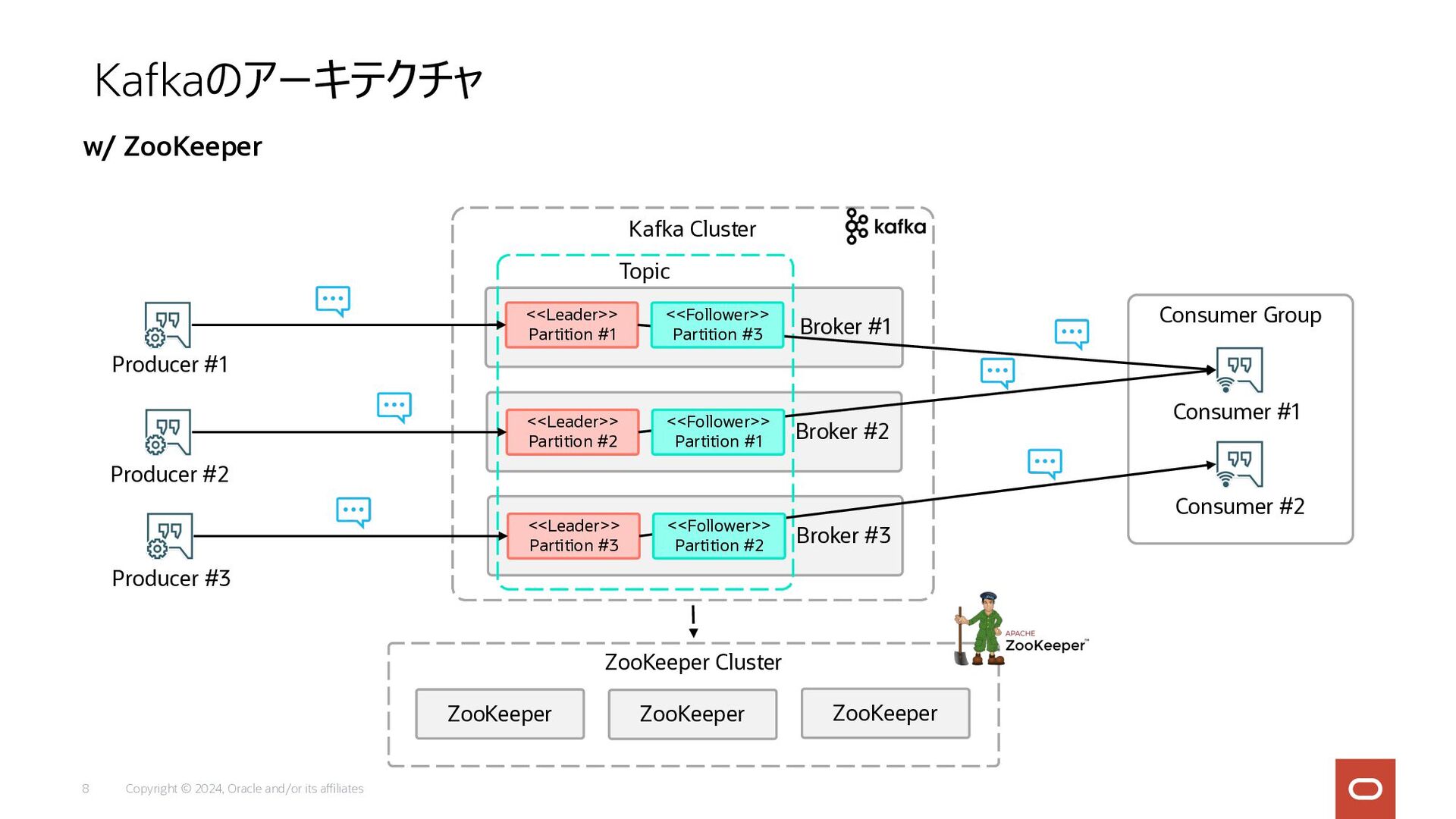
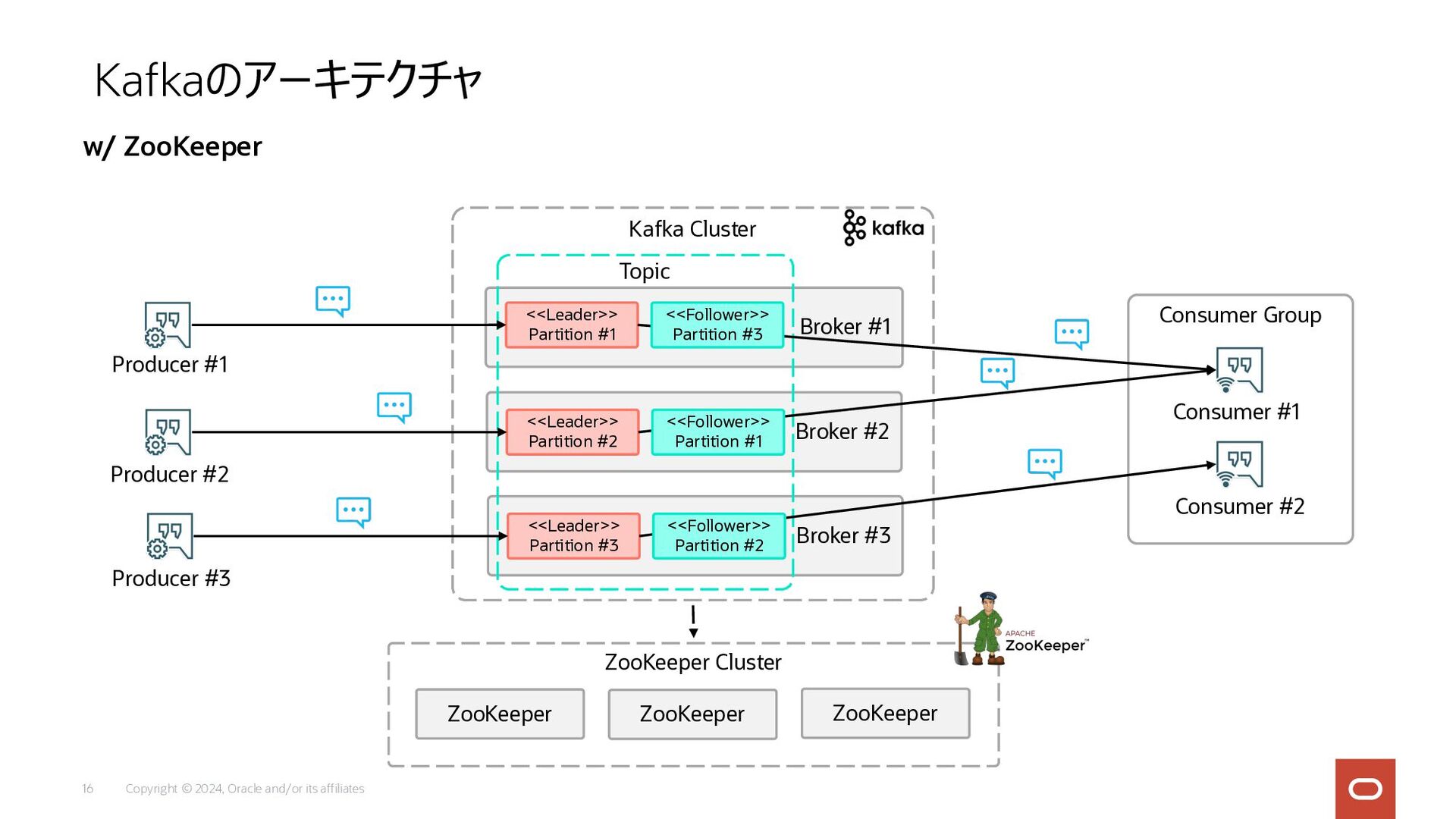
Copyright © 2024, Oracle and/or its affiliates 8 Kafkaのアーキテクチャ w/
ZooKeeper Broker #1 Broker #2 Kafka Cluster Producer #2 Consumer #2 Producer #1 Producer #3 Consumer #1 Consumer Group <<Leader>> Partition #1 <<Leader>> Partition #2 ZooKeeper Cluster ZooKeeper ZooKeeper ZooKeeper Broker #3 <<Leader>> Partition #3 Topic <<Follower>> Partition #3 <<Follower>> Partition #1 <<Follower>> Partition #2
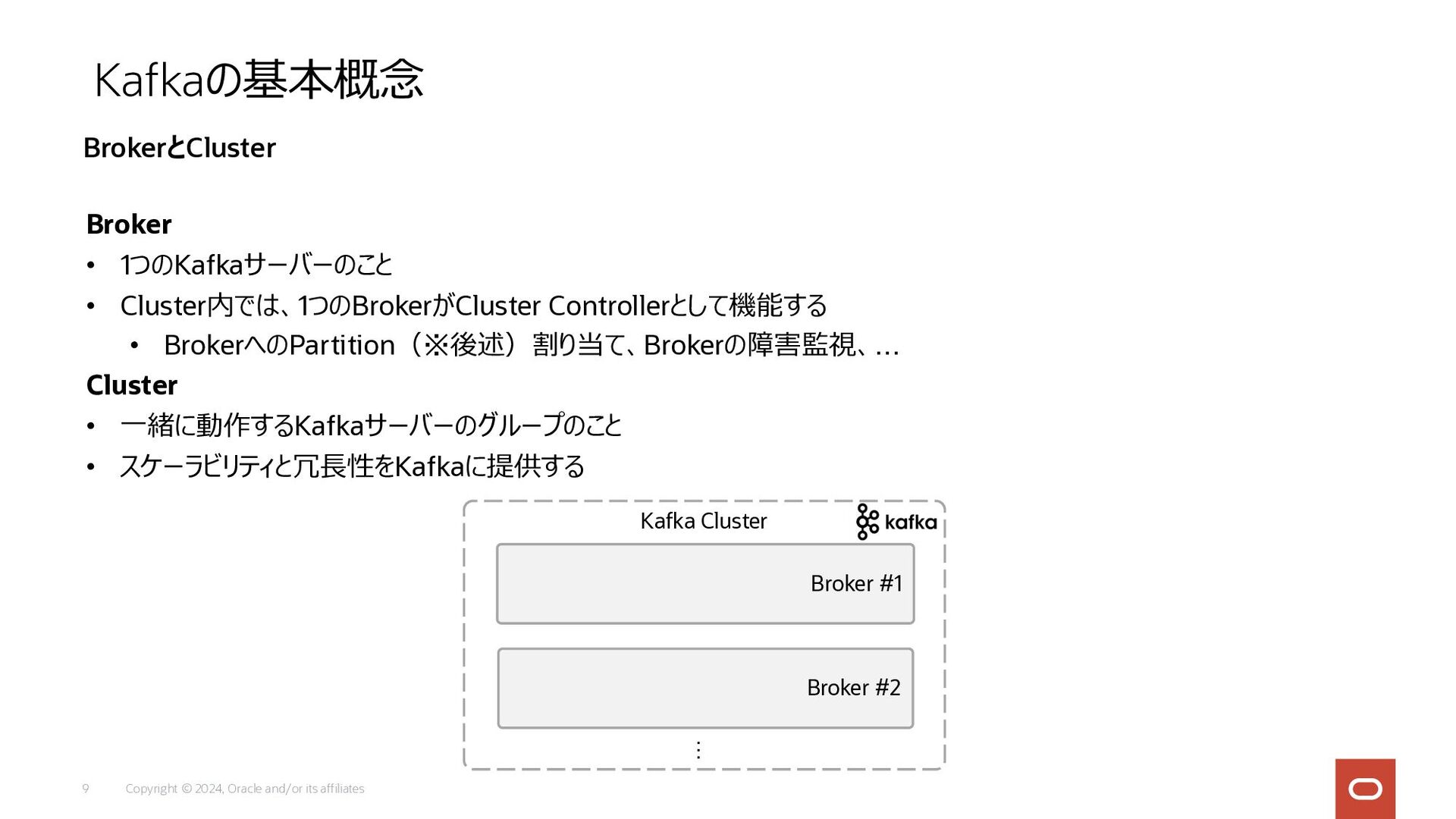
Copyright © 2024, Oracle and/or its affiliates 9 Broker •
1つのKafkaサーバーのこと • Cluster内では、1つのBrokerがCluster Controllerとして機能する • BrokerへのPartition(※後述)割り当て、Brokerの障害監視、… Cluster • ⼀緒に動作するKafkaサーバーのグループのこと • スケーラビリティと冗⻑性をKafkaに提供する Kafkaの基本概念 BrokerとCluster Broker #1 Broker #2 Kafka Cluster …
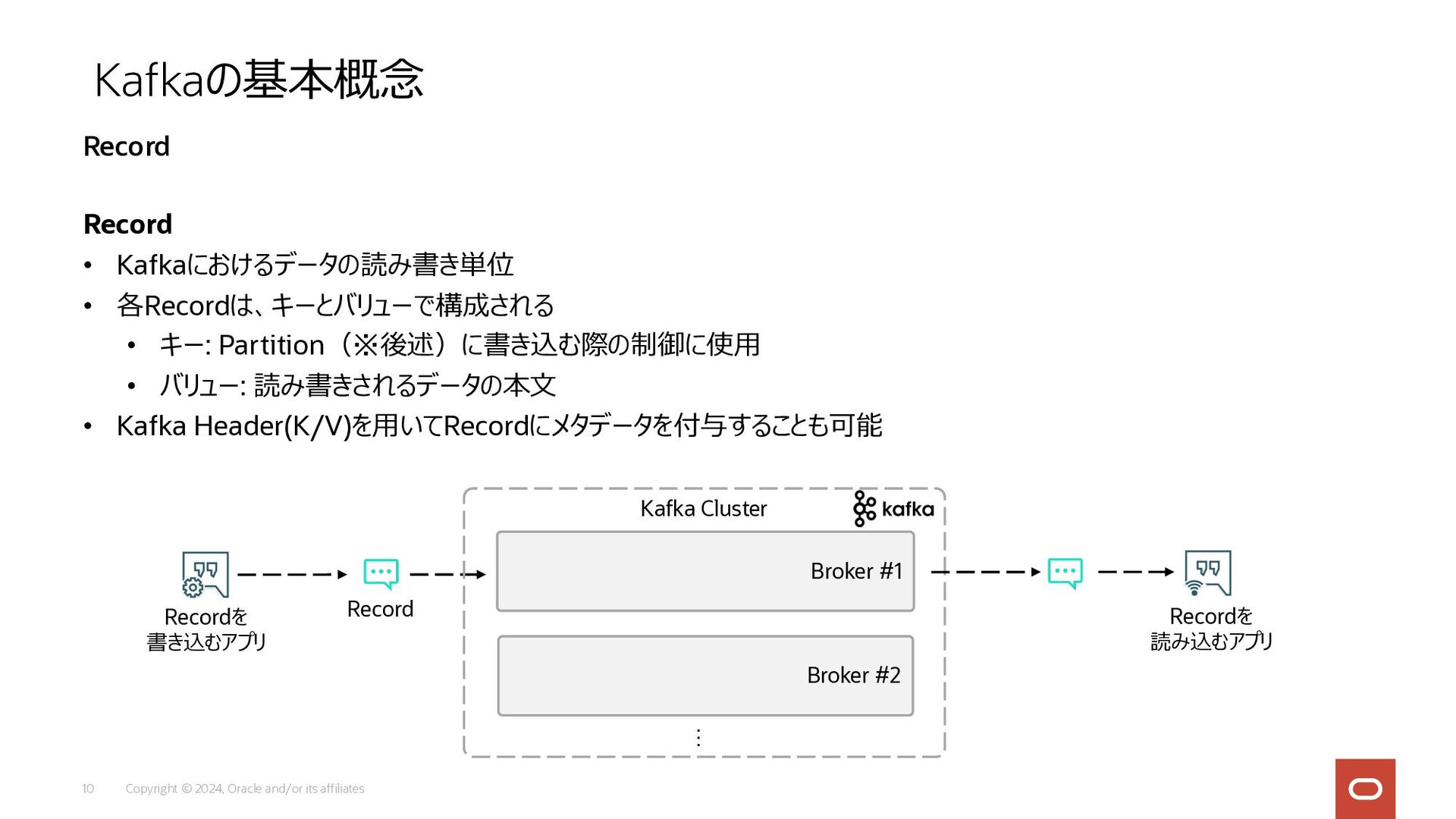
Copyright © 2024, Oracle and/or its affiliates 10 Record •
Kafkaにおけるデータの読み書き単位 • 各Recordは、キーとバリューで構成される • キー: Partition(※後述)に書き込む際の制御に使⽤ • バリュー: 読み書きされるデータの本⽂ • Kafka Header(K/V)を⽤いてRecordにメタデータを付与することも可能 Kafkaの基本概念 Record Recordを 書き込むアプリ Record Broker #1 Broker #2 Kafka Cluster … Recordを 読み込むアプリ
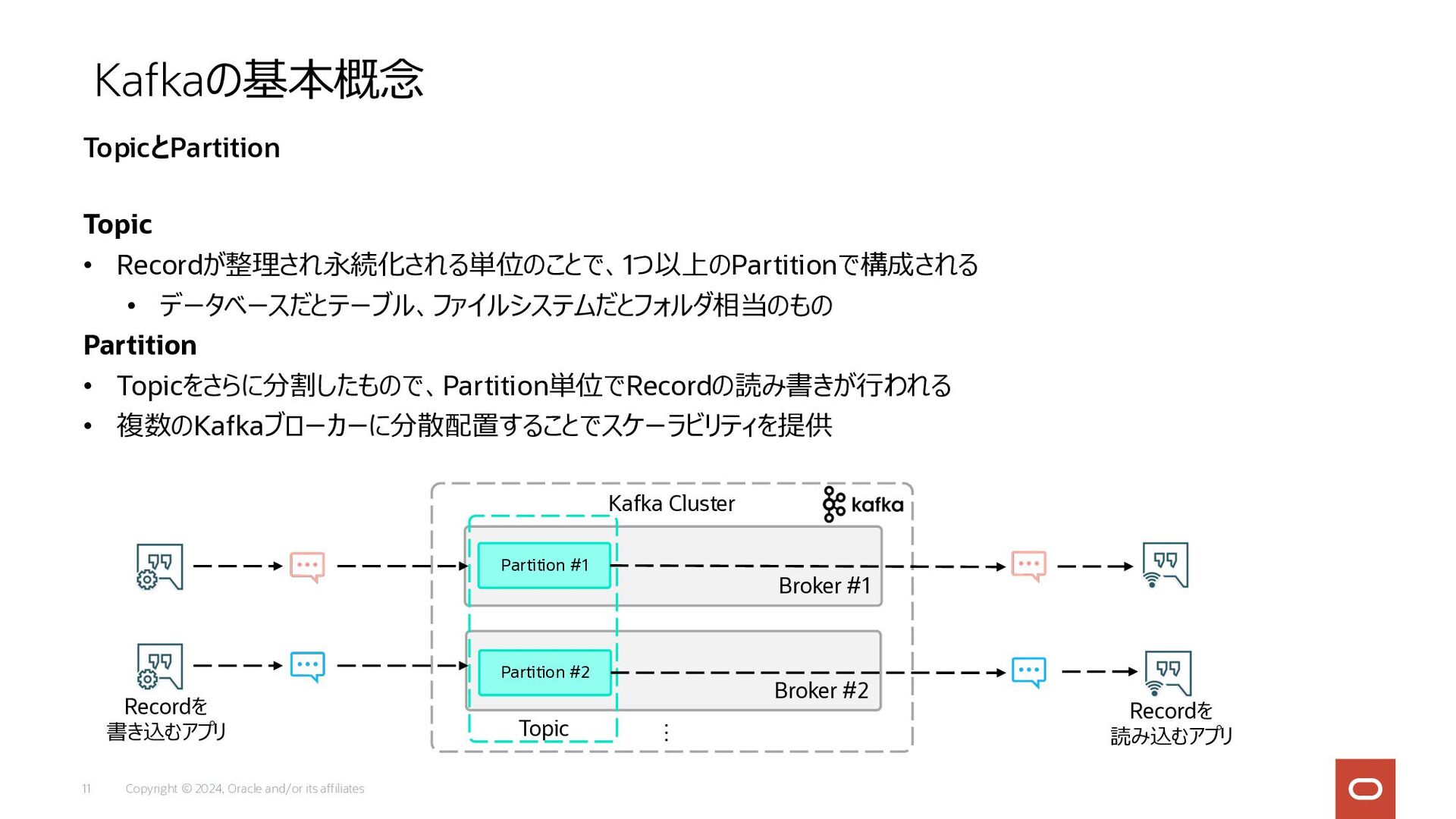
Copyright © 2024, Oracle and/or its affiliates 11 Topic •
Recordが整理され永続化される単位のことで、1つ以上のPartitionで構成される • データベースだとテーブル、ファイルシステムだとフォルダ相当のもの Partition • Topicをさらに分割したもので、Partition単位でRecordの読み書きが⾏われる • 複数のKafkaブローカーに分散配置することでスケーラビリティを提供 Kafkaの基本概念 TopicとPartition Broker #1 Broker #2 Kafka Cluster … Partition #1 Partition #2 Topic Recordを 書き込むアプリ Recordを 読み込むアプリ
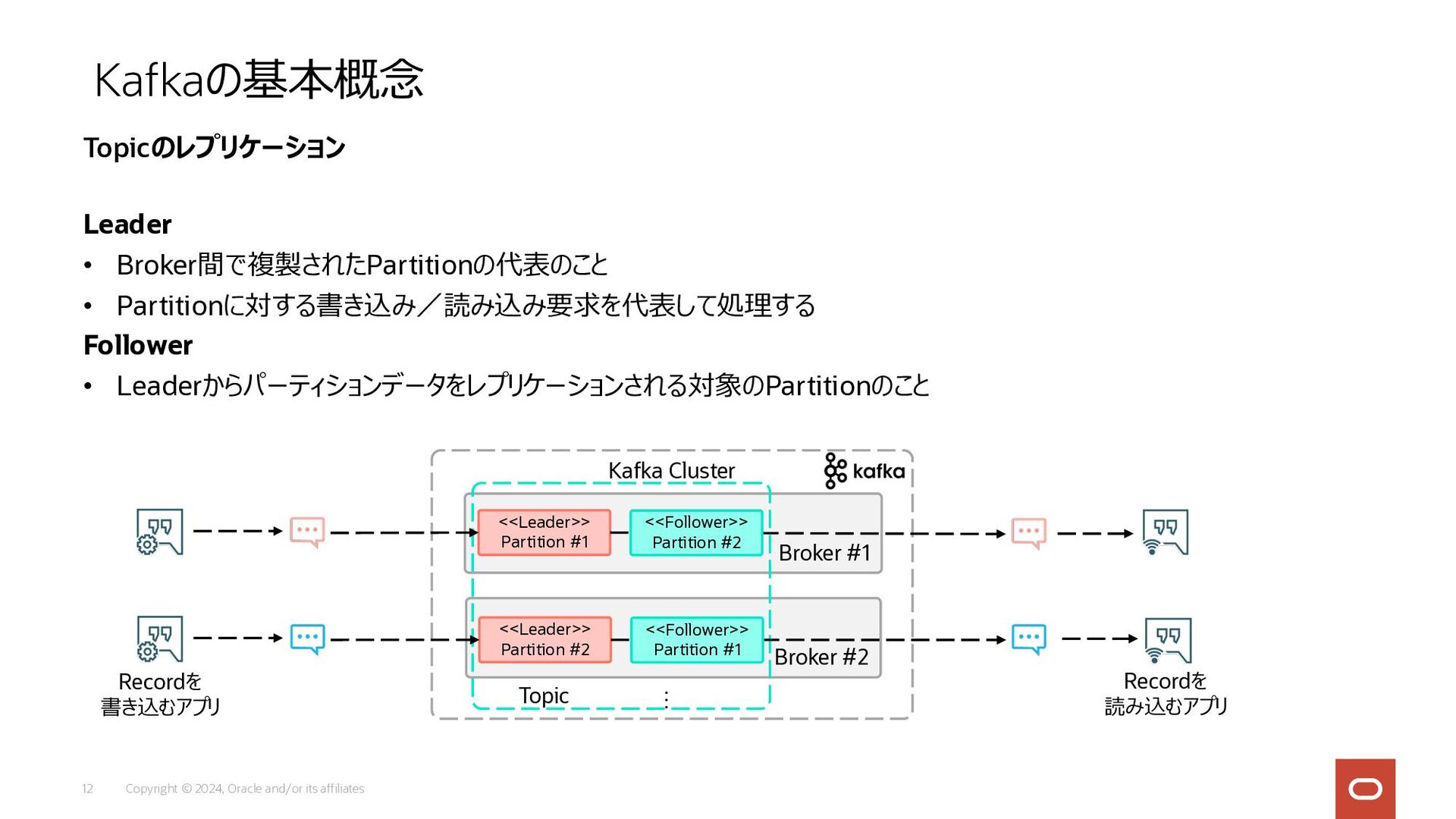
Copyright © 2024, Oracle and/or its affiliates 12 Leader •
Broker間で複製されたPartitionの代表のこと • Partitionに対する書き込み/読み込み要求を代表して処理する Follower • Leaderからパーティションデータをレプリケーションされる対象のPartitionのこと Kafkaの基本概念 Topicのレプリケーション Broker #1 Broker #2 Kafka Cluster … <<Leader>> Partition #1 <<Leader>> Partition #2 Topic Recordを 書き込むアプリ Recordを 読み込むアプリ <<Follower>> Partition #2 <<Follower>> Partition #1
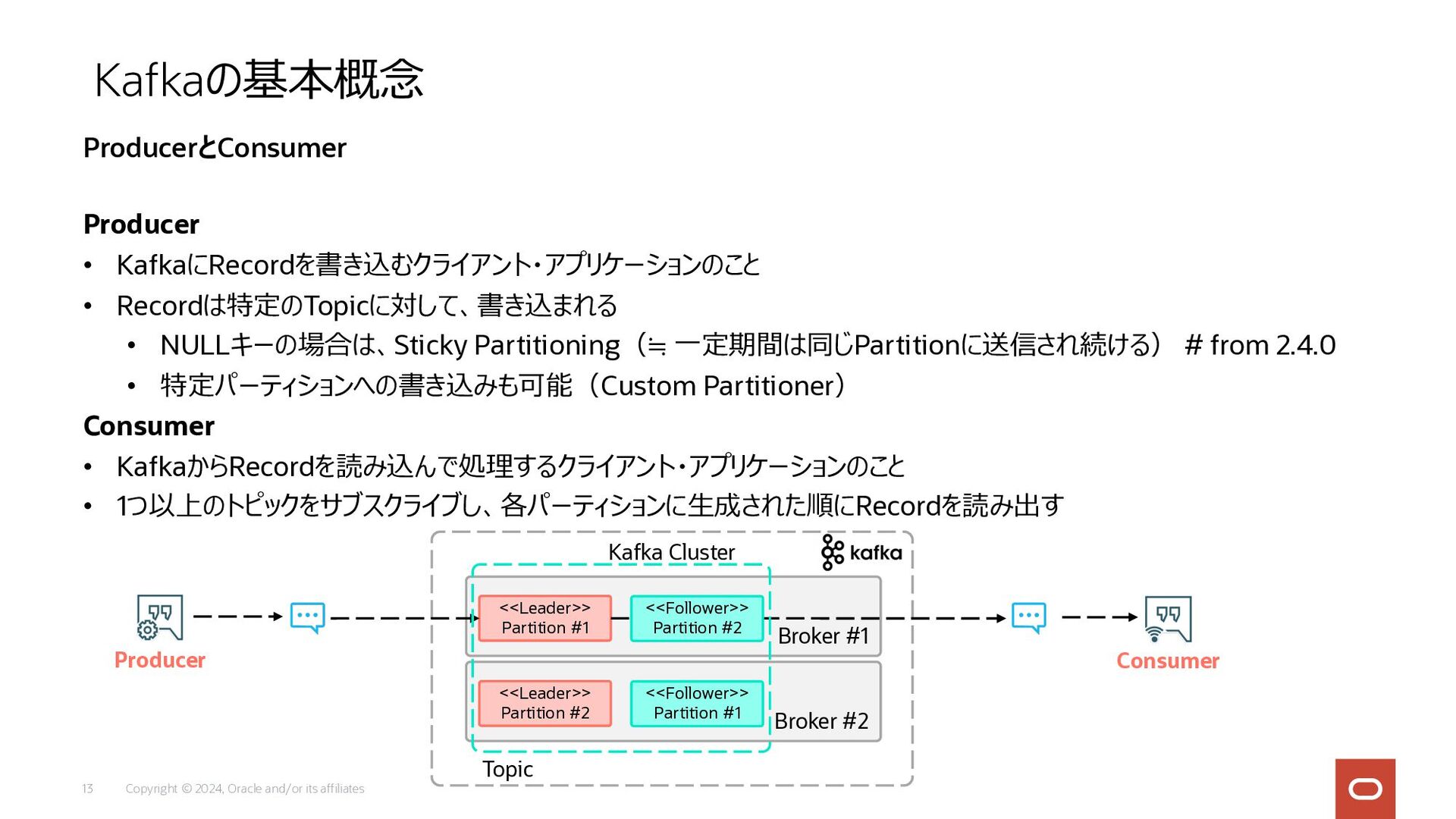
Copyright © 2024, Oracle and/or its affiliates 13 Producer •
KafkaにRecordを書き込むクライアント・アプリケーションのこと • Recordは特定のTopicに対して、書き込まれる • NULLキーの場合は、Sticky Partitioning(≒ ⼀定期間は同じPartitionに送信され続ける) # from 2.4.0 • 特定パーティションへの書き込みも可能(Custom Partitioner) Consumer • KafkaからRecordを読み込んで処理するクライアント・アプリケーションのこと • 1つ以上のトピックをサブスクライブし、各パーティションに⽣成された順にRecordを読み出す Kafkaの基本概念 ProducerとConsumer Broker #1 Kafka Cluster <<Leader>> Partition #1 Producer Consumer <<Follower>> Partition #2 Broker #2 <<Leader>> Partition #2 Topic <<Follower>> Partition #1
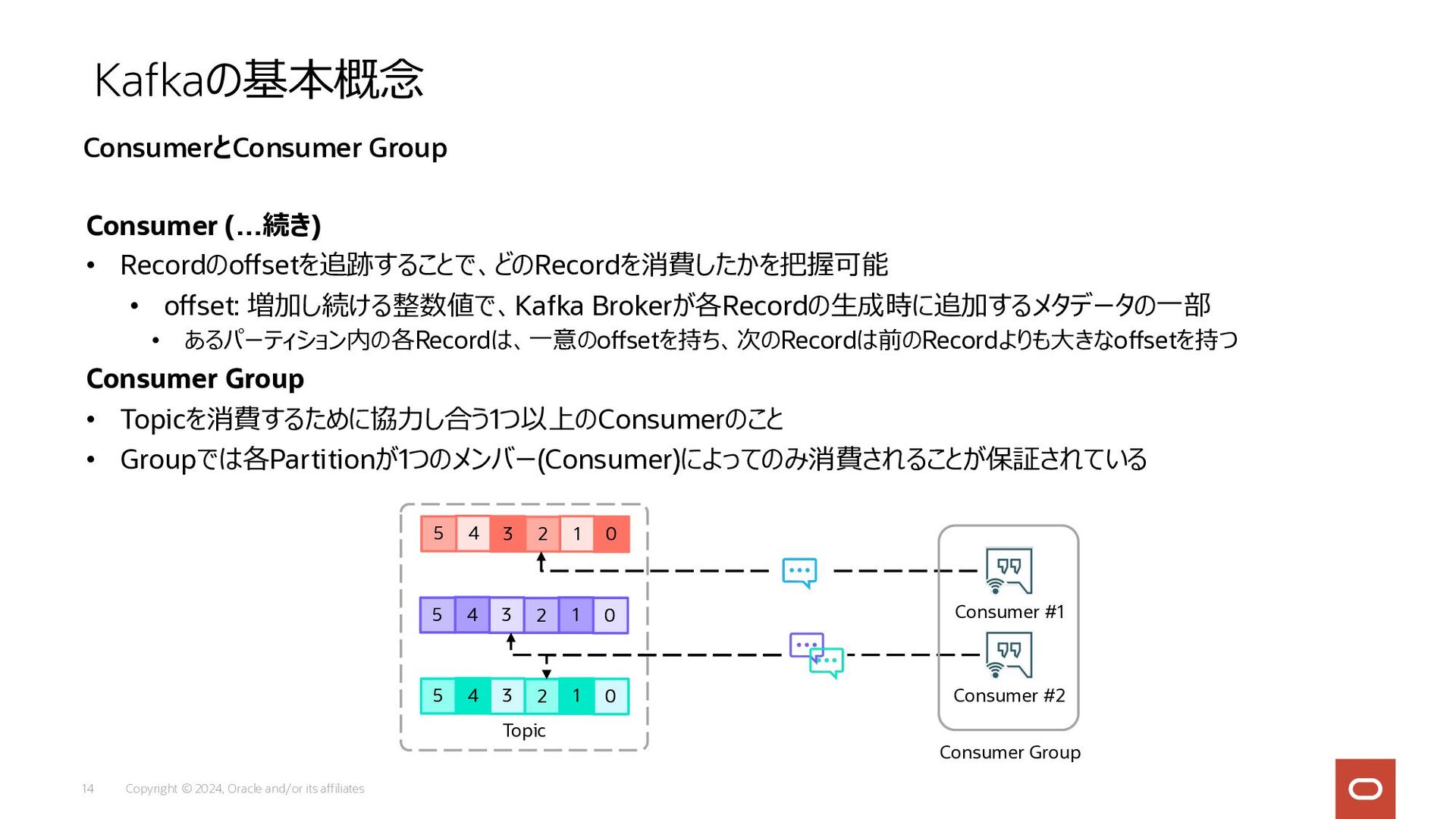
Copyright © 2024, Oracle and/or its affiliates 14 Consumer (…続き)
• Recordのoffsetを追跡することで、どのRecordを消費したかを把握可能 • offset: 増加し続ける整数値で、Kafka Brokerが各Recordの⽣成時に追加するメタデータの⼀部 • あるパーティション内の各Recordは、⼀意のoffsetを持ち、次のRecordは前のRecordよりも⼤きなoffsetを持つ Consumer Group • Topicを消費するために協⼒し合う1つ以上のConsumerのこと • Groupでは各Partitionが1つのメンバー(Consumer)によってのみ消費されることが保証されている Kafkaの基本概念 ConsumerとConsumer Group Topic Consumer #2 0 1 2 3 4 5 0 1 2 3 4 5 0 1 2 3 4 5 Consumer #1 Consumer Group
Copyright © 2024, Oracle and/or its affiliates 15 分散システムを構築する上で必要となる機能を提供するソフトウェア •
設定情報の維持、同期、名前管理、etc. • 3台以上の奇数台(3, 5, 7)でアンサンブルと呼ばれるクラスタ構成を組む • Leader(書き込み代表)/Follower(リードレプリカ) KafkaにおけるZooKeeperの使われ⽅ • PartitionとBrokerに関するメタデータの保存 • Controllerの選挙 • HeatbeatによるBrokerの死活監視 • Brokerに対するクォータ設定 • メタデータに対するアクセス制御 • … Kafkaの基本概念 ZooKeeper
Copyright © 2024, Oracle and/or its affiliates 16 Kafkaのアーキテクチャ w/
ZooKeeper Broker #1 Broker #2 Kafka Cluster Producer #2 Consumer #2 Producer #1 Producer #3 Consumer #1 Consumer Group <<Leader>> Partition #1 <<Leader>> Partition #2 ZooKeeper Cluster ZooKeeper ZooKeeper ZooKeeper Broker #3 <<Leader>> Partition #3 Topic <<Follower>> Partition #3 <<Follower>> Partition #1 <<Follower>> Partition #2
Copyright © 2024, Oracle and/or its affiliates 17 • Producer
API • Kafka cluster内のトピックに対してデータ・ストリームを書き込むためのAPI • Consumer API • Kafka cluster内のトピックからデータ・ストリームを読み込むためのAPI • Streams API • データ・ストリームをあるトピックから別のトピックへ変換するためのAPI • Connect API • Kafka Connector実装のためのAPI • Admin API • トピック、ブローカー、その他のKafkaオブジェクトを管理するためのAPI KafkaのコアAPI
Copyright © 2024, Oracle and/or its affiliates 18 Kafka Connect
• Kafkaとの間でデータのストリーミングを⾏うためのフレームワーク • Connectorの⼀覧: https://www.confluent.io/hub/ • Syslog Source Connector, MQTT Source/Sink Connector, Elasticsearch Source/Sink Connector, etc. Distribution & Packaging • Confluent Cloud(SaaS, Full-managed), Confluent Platform(Self-managed) • Strimzi: Kubernetes Operator for Kafka Stream Processing • Kafka Streams: Kafka組み込みのストリーム処理ライブラリ • Spark Streaming, Apache Flink, … Management Console • Kafka Manager, Tools for Apache Kafka(VSCode), Kafkat, … その他、エコシステムはこちら >> https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem Kafkaの主要なエコシステム
Copyright © 2024, Oracle and/or its affiliates 19 実践編 –
Apache Kafka w/ CLI, Java Client
Copyright © 2024, Oracle and/or its affiliates 20 動作環境 •
Java 21 • Kafka 3.7.0 動作環境
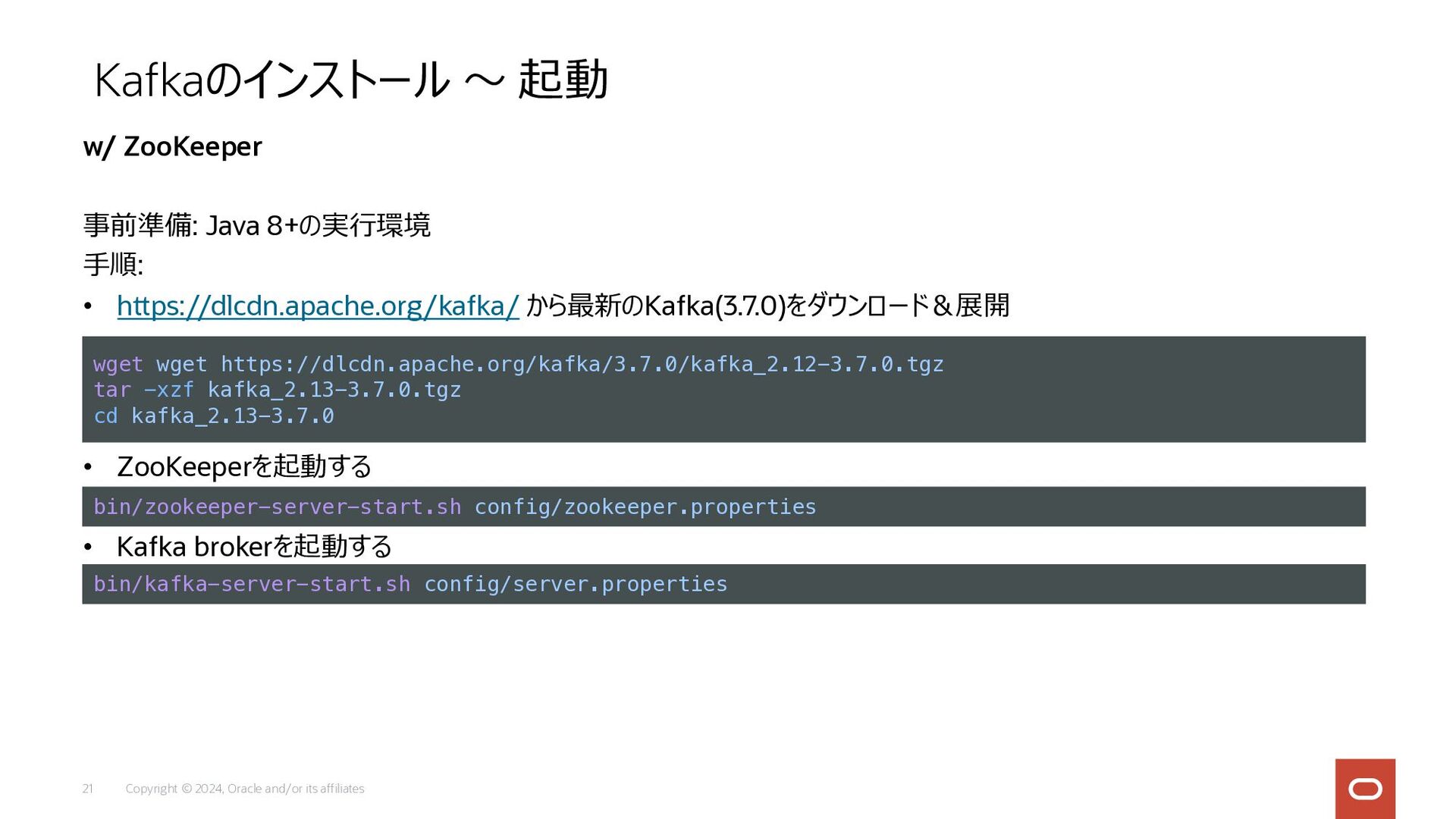
Copyright © 2024, Oracle and/or its affiliates 21 事前準備: Java
8+の実⾏環境 ⼿順: • https://dlcdn.apache.org/kafka/ から最新のKafka(3.7.0)をダウンロード&展開 • ZooKeeperを起動する • Kafka brokerを起動する Kafkaのインストール 〜 起動 w/ ZooKeeper wget wget https://dlcdn.apache.org/kafka/3.7.0/kafka_2.12-3.7.0.tgz tar -xzf kafka_2.13-3.7.0.tgz cd kafka_2.13-3.7.0 bin/zookeeper-server-start.sh config/zookeeper.properties bin/kafka-server-start.sh config/server.properties
Copyright © 2024, Oracle and/or its affiliates 22 ⼿順: •
トピックを作成する • 作成したトピックの詳細を確認する • トピックにレコードを書き込む • トピックからレコードを読み込む • パーティション、オフセットを指定した読み込み トピックの作成 〜 レコードの読み書き w/ CLI bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092 bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 bin/kafka-console-consumer.sh --topic quickstart-events ¥ --from-beginning --bootstrap-server localhost:9092 bin/kafka-console-consumer.sh --topic quickstart-event ¥ --partition 0 --offset 2 --bootstrap-server localhost:9092
Copyright © 2024, Oracle and/or its affiliates 23 引⽤︓https://kafka.apache.org/37/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html レコードの読み書き
w/ Java Client Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("linger.ms", 1); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); IntStream.range(0, 100).forEach(i -> { producer.send(new ProducerRecord<String, String>("my-topic", String.format("key-%s", Integer.toString(i)), String.format("value-%s", Integer.toString(i)))); }); producer.close(); 100件のレコードを”my-topic”に書き込む例
Copyright © 2024, Oracle and/or its affiliates 24 引⽤︓https://kafka.apache.org/37/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html レコードの読み書き
w/ Java Client Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); records.forEach(record -> { logger.info(String.format("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value())); }); } “my-topic”から、100ミリ秒ごとにレコードをポーリングする例
Copyright © 2024, Oracle and/or its affiliates 25 応⽤編 –
Cloud Native x Apache Kafka
Copyright © 2024, Oracle and/or its affiliates 26 KRaft –
Kafka without ZooKeeper
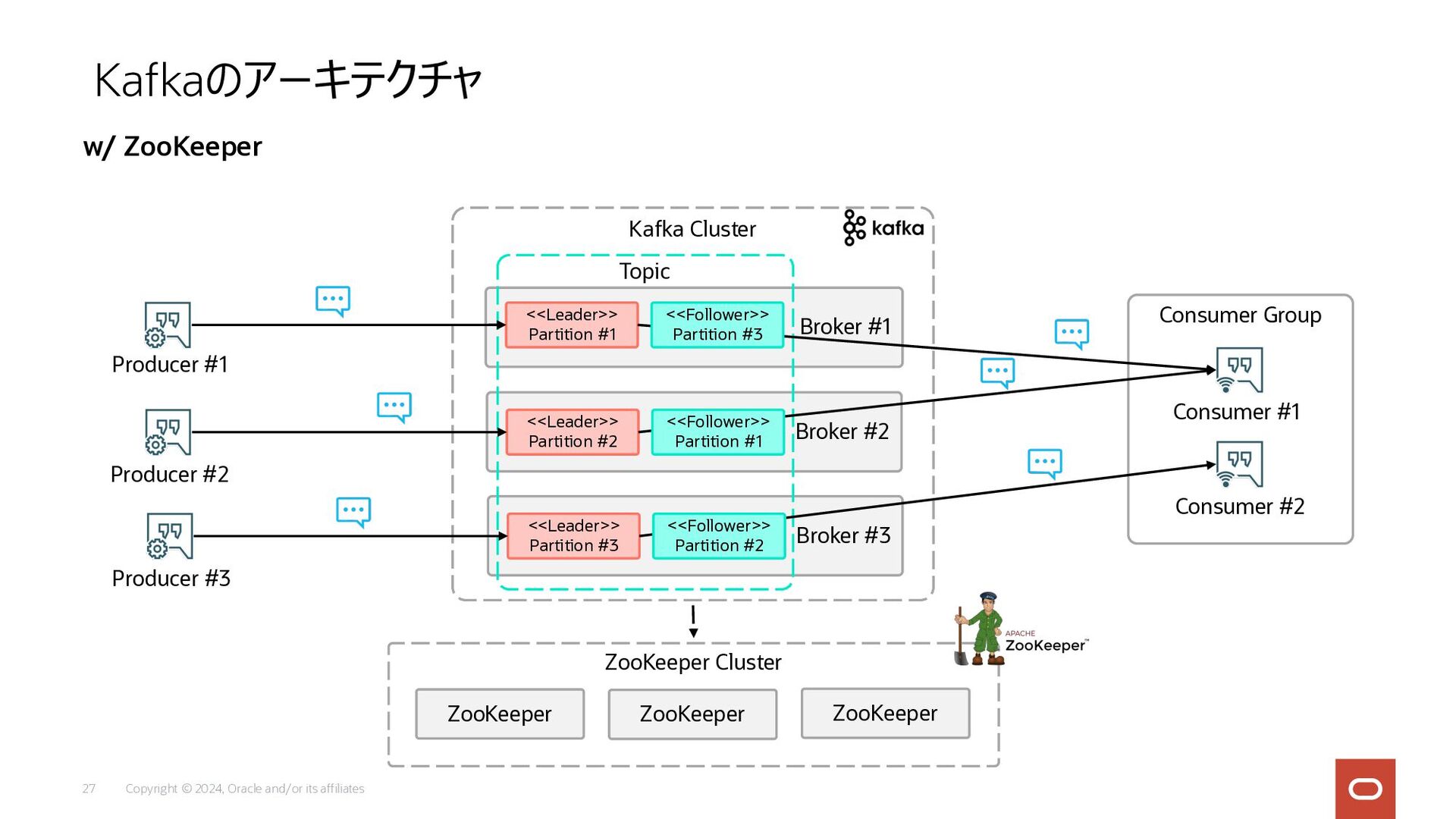
Copyright © 2024, Oracle and/or its affiliates 27 Kafkaのアーキテクチャ w/
ZooKeeper Broker #1 Broker #2 Kafka Cluster Producer #2 Consumer #2 Producer #1 Producer #3 Consumer #1 Consumer Group <<Leader>> Partition #1 <<Leader>> Partition #2 ZooKeeper Cluster ZooKeeper ZooKeeper ZooKeeper Broker #3 <<Leader>> Partition #3 Topic <<Follower>> Partition #3 <<Follower>> Partition #1 <<Follower>> Partition #2
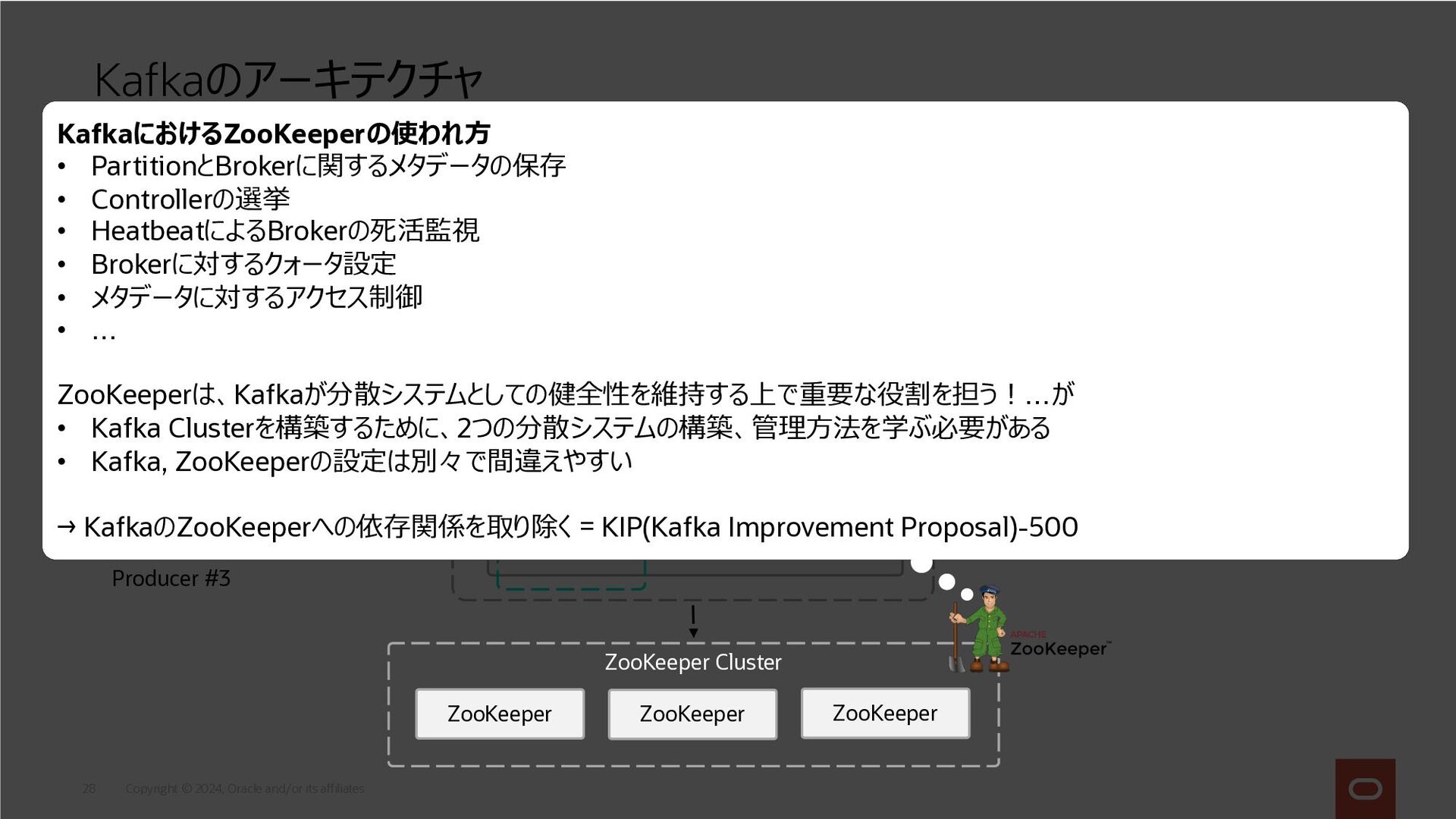
Copyright © 2024, Oracle and/or its affiliates 28 Kafkaのアーキテクチャ w/
ZooKeeper Broker #1 Broker #2 Kafka Cluster Producer #2 Consumer #2 Producer #1 Producer #3 Consumer #1 Consumer Group Partition #1 Partition #2 Broker #3 Partition #3 Topic Partition #2 (Replica) Partition #3 (Replica) Partition #1 (Replica) ZooKeeper Cluster ZooKeeper ZooKeeper ZooKeeper KafkaにおけるZooKeeperの使われ⽅ • PartitionとBrokerに関するメタデータの保存 • Controllerの選挙 • HeatbeatによるBrokerの死活監視 • Brokerに対するクォータ設定 • メタデータに対するアクセス制御 • … ZooKeeperは、Kafkaが分散システムとしての健全性を維持する上で重要な役割を担う︕…が • Kafka Clusterを構築するために、2つの分散システムの構築、管理⽅法を学ぶ必要がある • Kafka, ZooKeeperの設定は別々で間違えやすい → KafkaのZooKeeperへの依存関係を取り除く = KIP(Kafka Improvement Proposal)-500
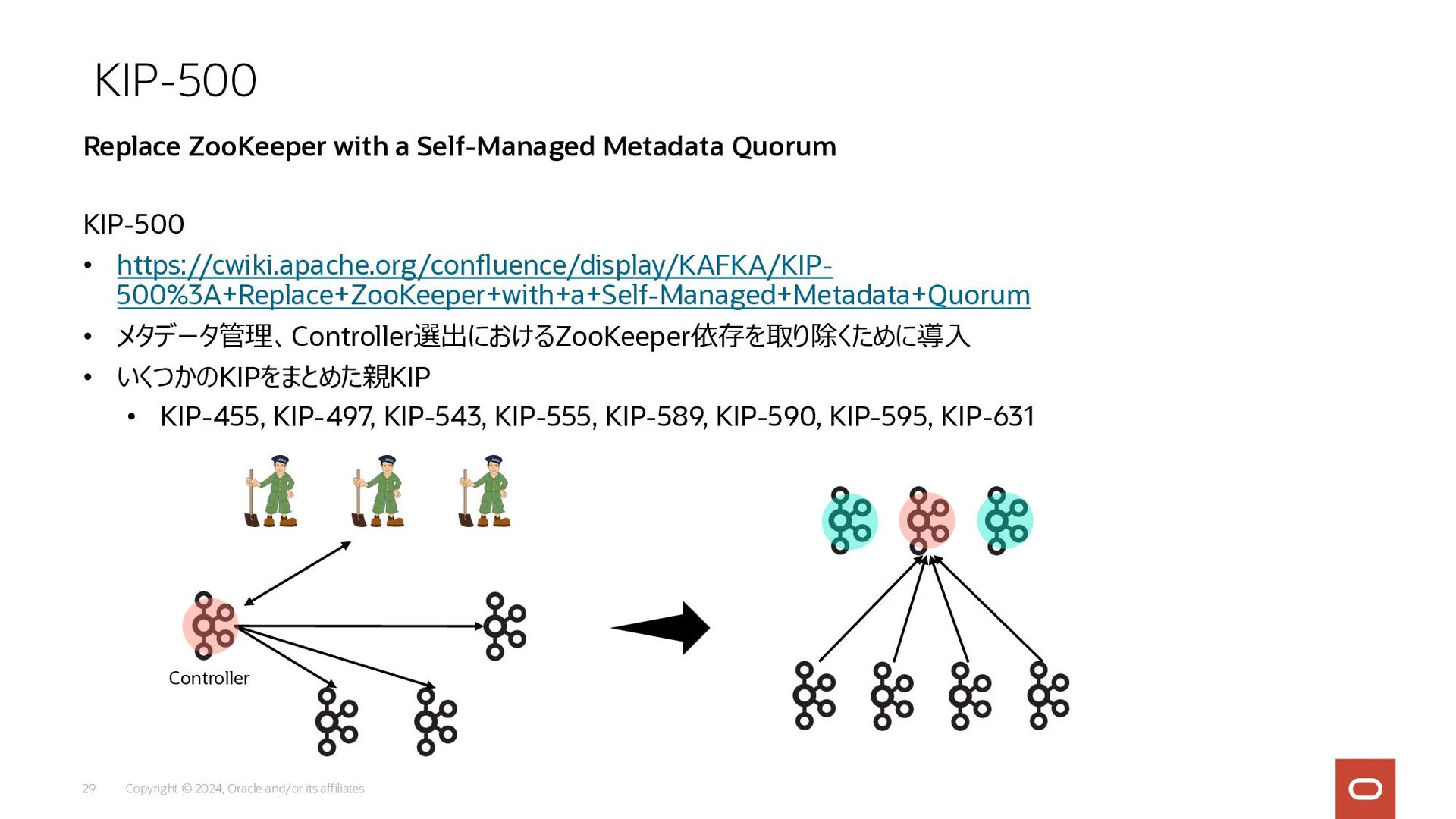
Copyright © 2024, Oracle and/or its affiliates 29 KIP-500 •
https://cwiki.apache.org/confluence/display/KAFKA/KIP- 500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum • メタデータ管理、Controller選出におけるZooKeeper依存を取り除くために導⼊ • いくつかのKIPをまとめた親KIP • KIP-455, KIP-497, KIP-543, KIP-555, KIP-589, KIP-590, KIP-595, KIP-631 KIP-500 Replace ZooKeeper with a Self-Managed Metadata Quorum Controller
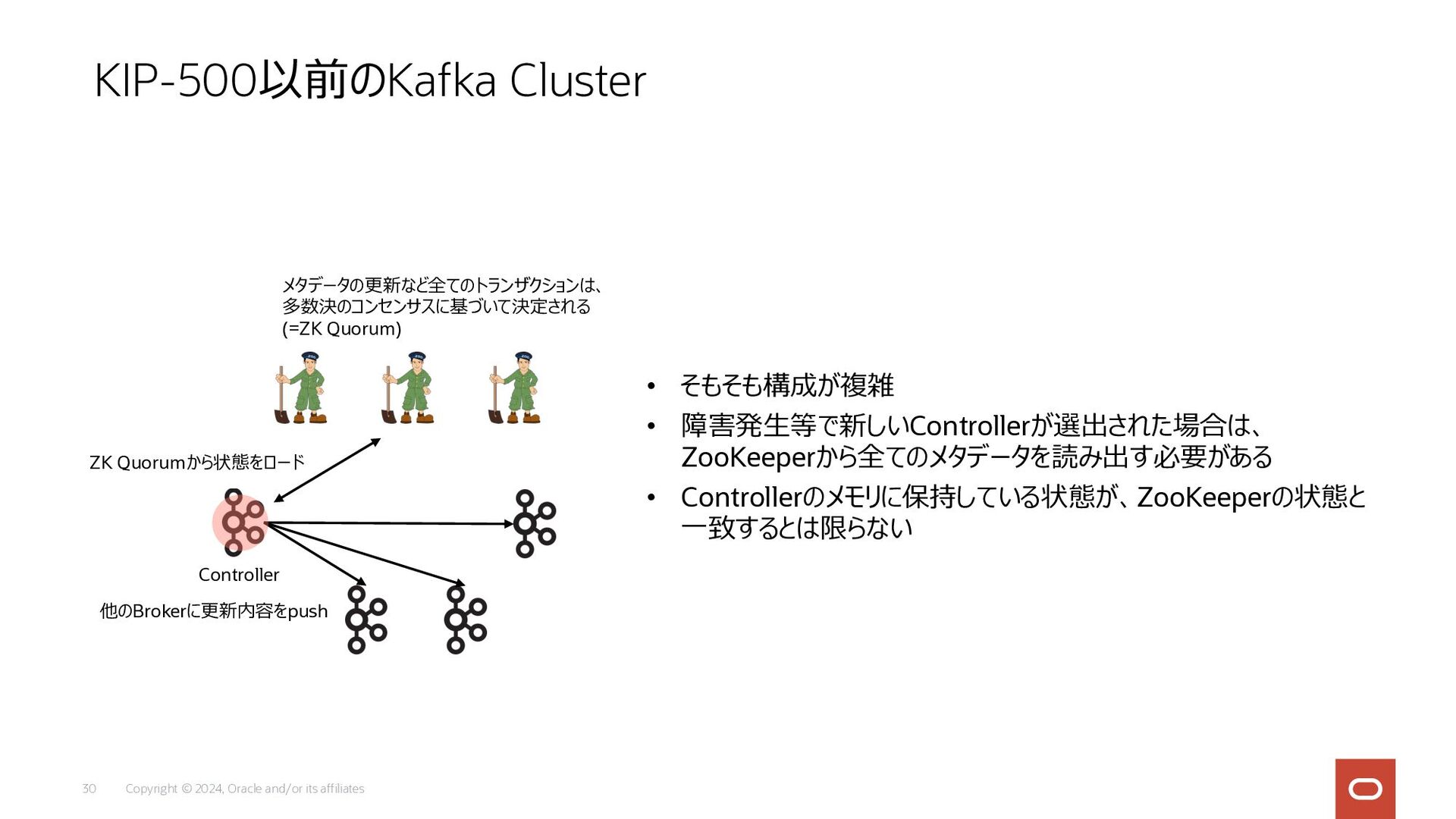
Copyright © 2024, Oracle and/or its affiliates 30 • そもそも構成が複雑
• 障害発⽣等で新しいControllerが選出された場合は、 ZooKeeperから全てのメタデータを読み出す必要がある • Controllerのメモリに保持している状態が、ZooKeeperの状態と ⼀致するとは限らない KIP-500以前のKafka Cluster Controller メタデータの更新など全てのトランザクションは、 多数決のコンセンサスに基づいて決定される (=ZK Quorum) ZK Quorumから状態をロード 他のBrokerに更新内容をpush
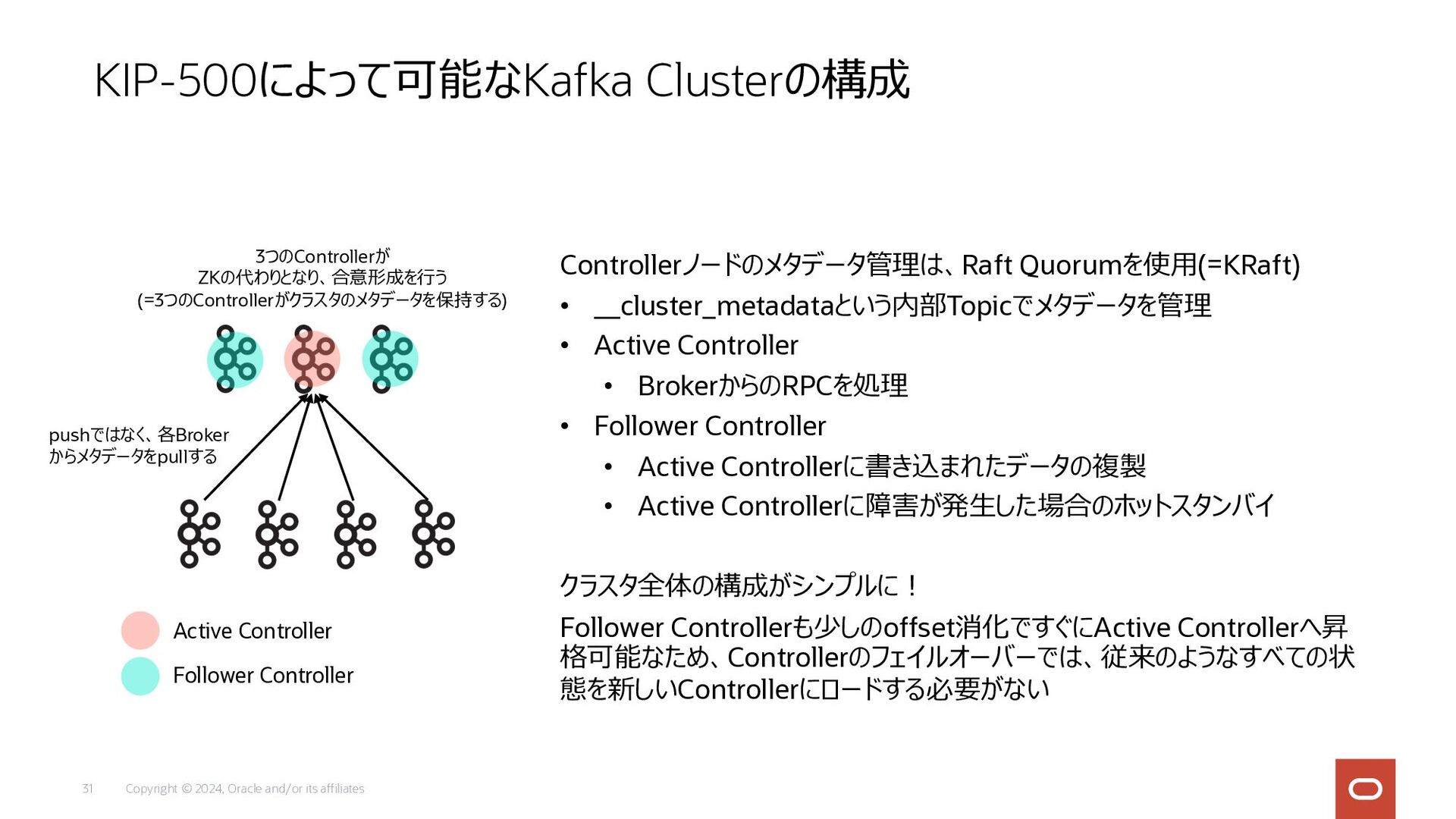
Copyright © 2024, Oracle and/or its affiliates 31 Controllerノードのメタデータ管理は、Raft Quorumを使⽤(=KRaft)
• __cluster_metadataという内部Topicでメタデータを管理 • Active Controller • BrokerからのRPCを処理 • Follower Controller • Active Controllerに書き込まれたデータの複製 • Active Controllerに障害が発⽣した場合のホットスタンバイ クラスタ全体の構成がシンプルに︕ Follower Controllerも少しのoffset消化ですぐにActive Controllerへ昇 格可能なため、Controllerのフェイルオーバーでは、従来のようなすべての状 態を新しいControllerにロードする必要がない KIP-500によって可能なKafka Clusterの構成 3つのControllerが ZKの代わりとなり、合意形成を⾏う (=3つのControllerがクラスタのメタデータを保持する) pushではなく、各Broker からメタデータをpullする Active Controller Follower Controller
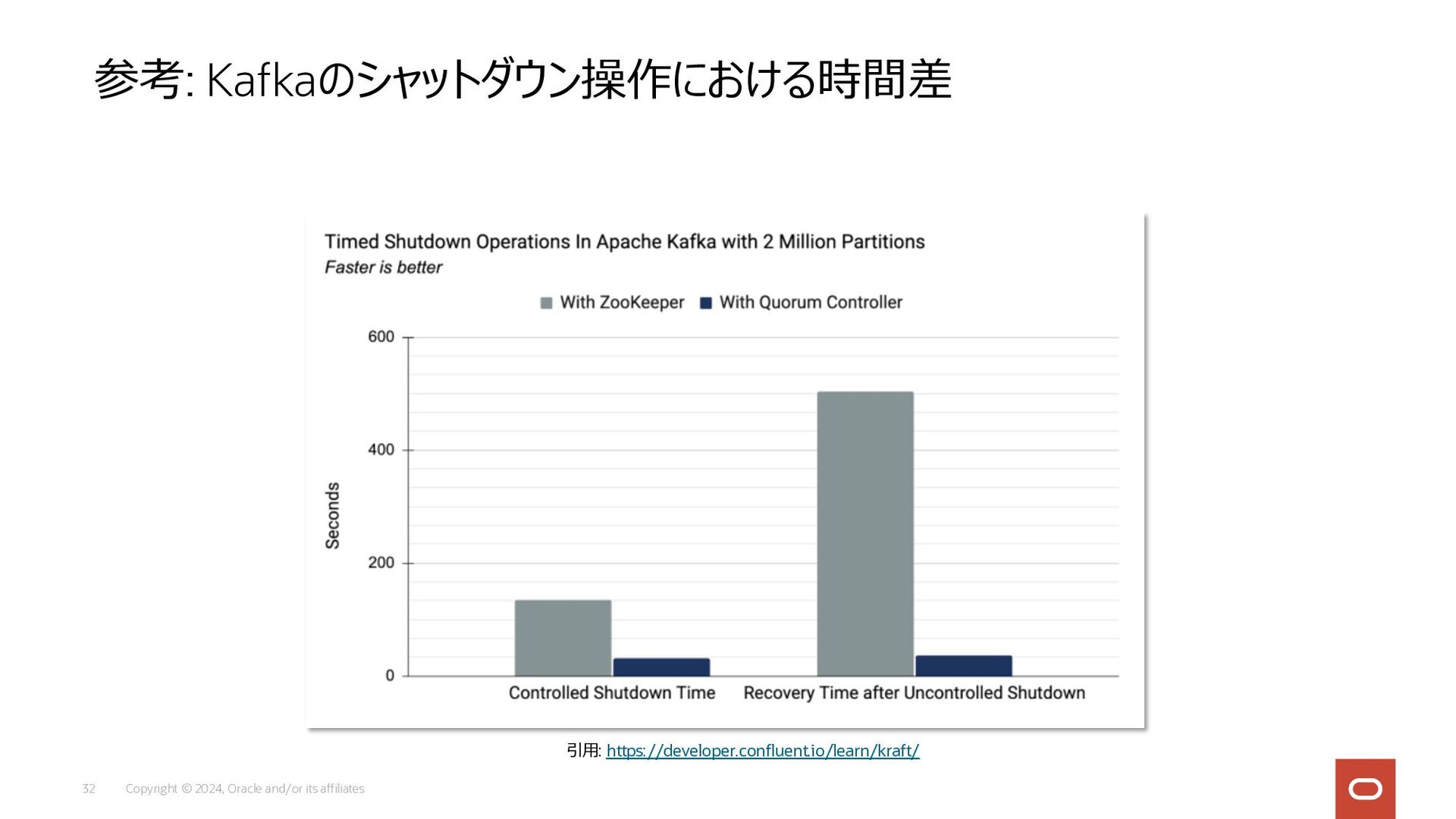
Copyright © 2024, Oracle and/or its affiliates 32 参考: Kafkaのシャットダウン操作における時間差
引⽤: https://developer.confluent.io/learn/kraft/
Copyright © 2024, Oracle and/or its affiliates 33 • コンセンサス・アルゴリズムの⼀種(Raft,
Paxos, …) • Paxosと⽐べ耐障害性や性能を維持しつつ、理解しやすいように設計 • 採⽤されている代表的なサービス/プロダクト • Kafka(KRaft), etcd, Oracle Global Distributed Database, … • 定義されている主な動作 • Leader election(リーダー選挙) • Log replication(ログ複製) 参考︓Raftについて https://www.docswell.com/s/shukawam/KW1YL4-etcd-raft Raftの基本動作とそれを 実現するRPCの概要について
Copyright © 2024, Oracle and/or its affiliates 34 • ClusterのUUIDを⽣成する
• ログディレクトリをフォーマットする • Kafka brokerを起動する • Kafka brokerを起動する(Docker) KRaftモードでのKafka brokerの起動 KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)" bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties bin/kafka-server-start.sh config/kraft/server.properties docker run -p 9092:9092 apache/kafka:3.7.0
Copyright © 2024, Oracle and/or its affiliates 35 Strimzi –
Kafka Kubernetes Operator
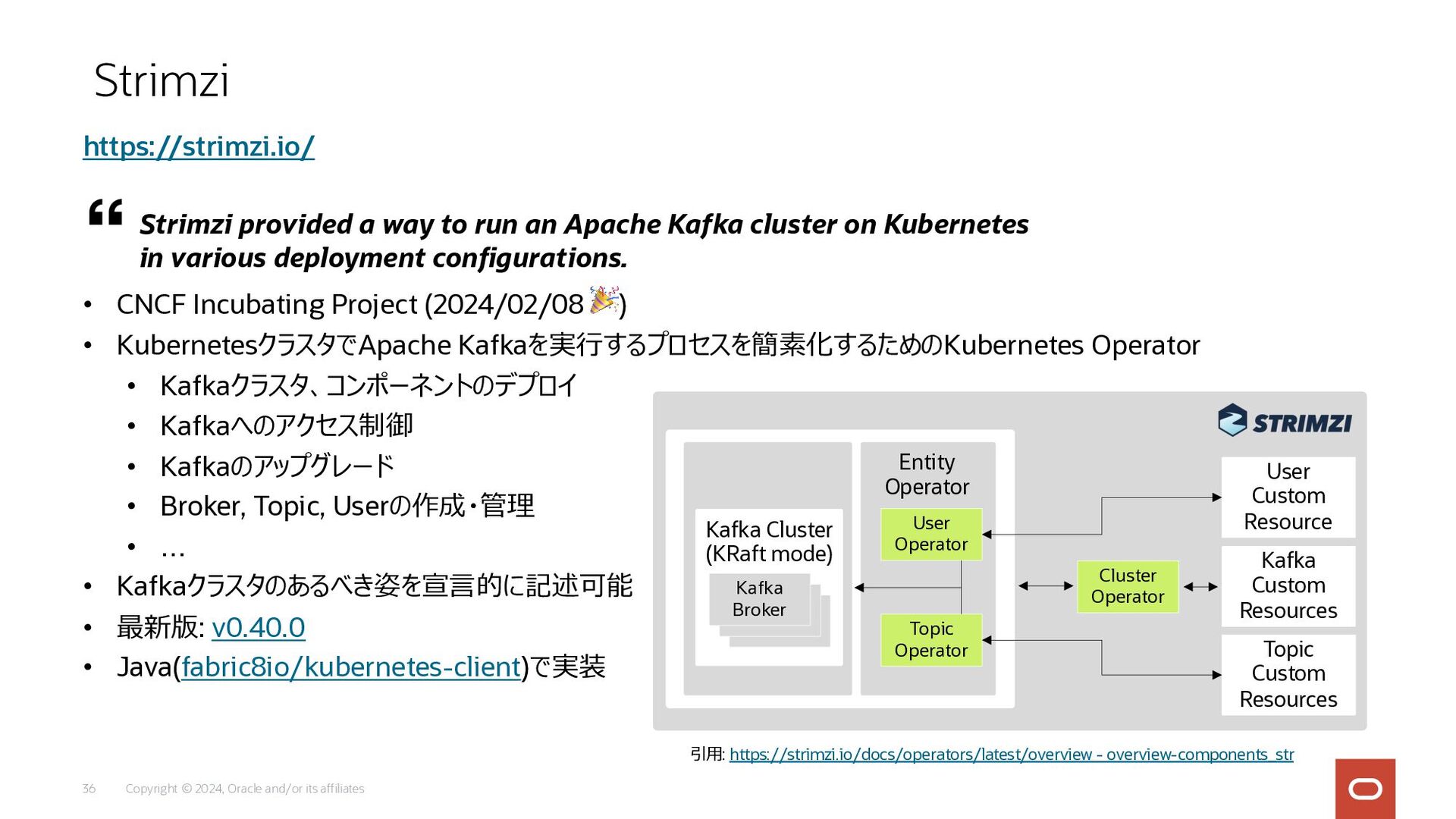
Copyright © 2024, Oracle and/or its affiliates 36 • CNCF
Incubating Project (2024/02/08 🎉) • KubernetesクラスタでApache Kafkaを実⾏するプロセスを簡素化するためのKubernetes Operator • Kafkaクラスタ、コンポーネントのデプロイ • Kafkaへのアクセス制御 • Kafkaのアップグレード • Broker, Topic, Userの作成・管理 • … • Kafkaクラスタのあるべき姿を宣⾔的に記述可能 • 最新版: v0.40.0 • Java(fabric8io/kubernetes-client)で実装 Strimzi https://strimzi.io/ Strimzi provided a way to run an Apache Kafka cluster on Kubernetes in various deployment configurations. 引⽤: https://strimzi.io/docs/operators/latest/overview - overview-components_str Kafka Broker Kafka Cluster (KRaft mode) Entity Operator User Operator Topic Operator Cluster Operator User Custom Resource Kafka Custom Resources Topic Custom Resources
Copyright © 2024, Oracle and/or its affiliates 37 Strimziで提供されるCustom Resource
kubectl api-resources --api-group "kafka.strimzi.io" NAME SHORTNAMES APIVERSION NAMESPACED KIND kafkabridges kb kafka.strimzi.io/v1beta2 true KafkaBridge kafkaconnectors kctr kafka.strimzi.io/v1beta2 true KafkaConnector kafkaconnects kc kafka.strimzi.io/v1beta2 true KafkaConnect kafkamirrormaker2s kmm2 kafka.strimzi.io/v1beta2 true KafkaMirrorMaker2 kafkamirrormakers kmm kafka.strimzi.io/v1beta2 true KafkaMirrorMaker kafkanodepools knp kafka.strimzi.io/v1beta2 true KafkaNodePool kafkarebalances kr kafka.strimzi.io/v1beta2 true KafkaRebalance kafkas k kafka.strimzi.io/v1beta2 true Kafka kafkatopics kt kafka.strimzi.io/v1beta2 true KafkaTopic kafkausers ku kafka.strimzi.io/v1beta2 true KafkaUser
Copyright © 2024, Oracle and/or its affiliates 38 Custom Resource
概要 KafkaBridge Kafka Bridge(Kafkaクラスタと対話するためのRestfulインタフェースを提供 ≒ Rest Proxy)作成⽤ KafkaConnector Kafka Connectのクラスタ作成⽤ KafkaConnect Kafka Connectorのインスタンス作成⽤ KafkaMirrorMaker2 Kafka MirrorMaker2作成⽤ KafkaMirrorMaker Kafka MirrorMaker(MirrorMaker1)作成⽤ KafkaNodePool Kafkaクラスタ内でのKafkaノードの集合定義 KafkaRebalance リバランス発⽣時の挙動を制御するためのポリシー設定⽤ Kafka Kafkaクラスタ作成⽤ KafkaTopic Kafka – Topic作成⽤ KafkaUser Kafkaクラスタの内部ユーザー管理⽤ Strimziで提供されるCustom Resourceの概要
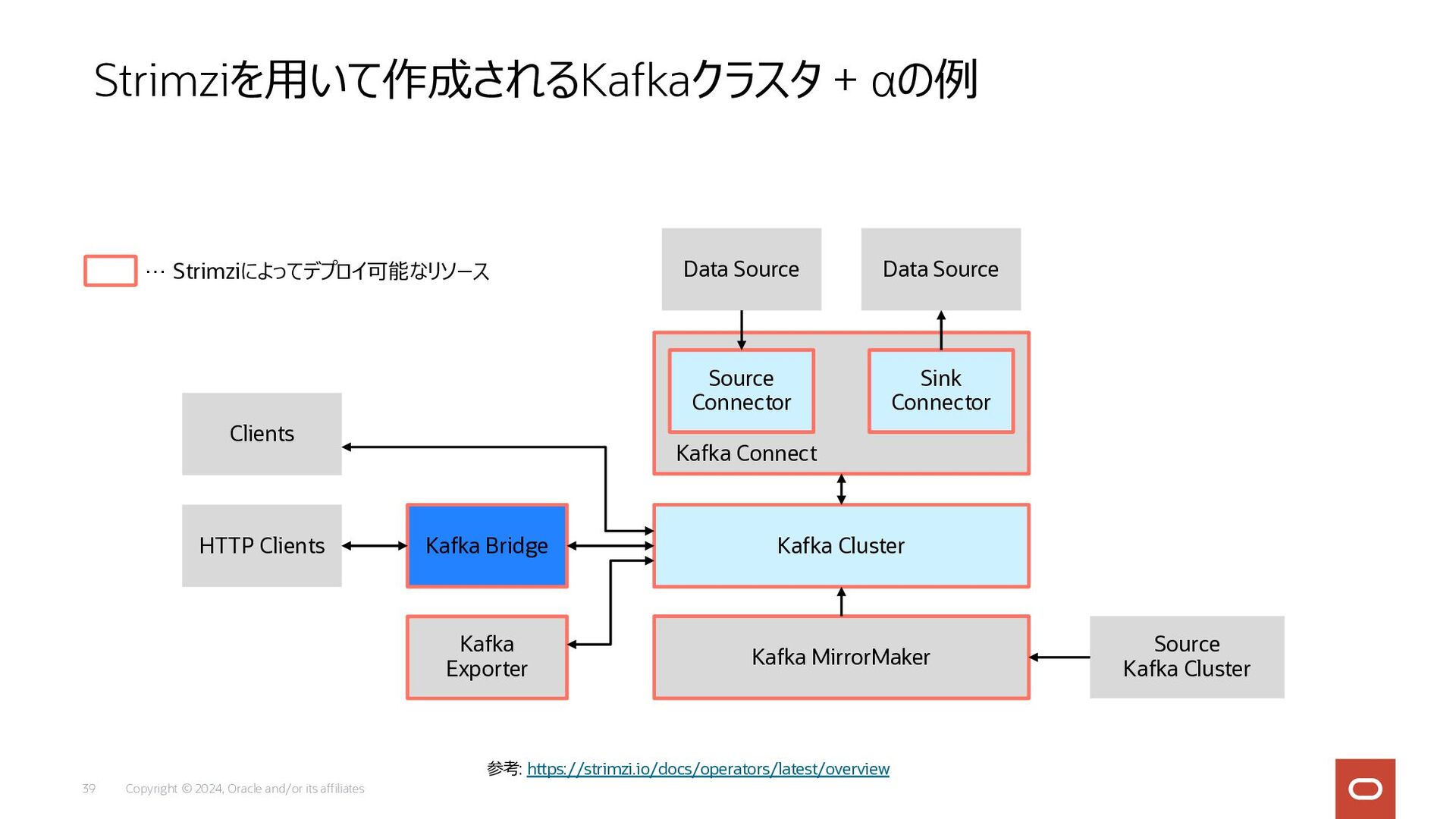
Copyright © 2024, Oracle and/or its affiliates 39 Strimziを⽤いて作成されるKafkaクラスタ +
αの例 参考: https://strimzi.io/docs/operators/latest/overview Clients HTTP Clients Kafka Bridge Kafka Exporter Kafka MirrorMaker Source Kafka Cluster Kafka Cluster Data Source Data Source Source Connector Sink Connector Kafka Connect Strimziによってデプロイ可能なリソース …
Copyright © 2024, Oracle and/or its affiliates 40 Strimziを⽤いたKafkaクラスタ +
αの構築例 Kafka Cluster – KafkaNodePool apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: controller namespace: kafka labels: strimzi.io/cluster: ochacafe spec: replicas: 3 roles: - controller storage: type: ephemeral --- apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: broker namespace: kafka labels: strimzi.io/cluster: ochacafe spec: replicas: 3 roles: - broker storage: type: ephemeral Controllerとして3台の Kafka Brokerを稼働させる Brokerとして3台の Kafka Brokerを稼働させる
Copyright © 2024, Oracle and/or its affiliates 41 Strimziを⽤いたKafkaクラスタ +
αの構築例 Kafka Cluster – Kafka apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: ochacafe namespace: ochacafe annotations: strimzi.io/node-pools: enabled strimzi.io/kraft: enabled # ... 続く ... # ... 続き ... spec: kafka: version: 3.7.0 metadataVersion: 3.7-IV4 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true config: offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 default.replication.factor: 3 num.partitions: 3 min.insync.replicas: 2 entityOperator: topicOperator: {} userOperator: {} Node Poolの使⽤と KRaftモードの有効化 クラスタに対する デフォルト設定
Copyright © 2024, Oracle and/or its affiliates 42 Strimziを⽤いたKafkaクラスタ +
αの構築例 Kafka Bridge apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: ochacafe spec: replicas: 1 bootstrapServers: ochacafe-kafka-bootstrap:9092 http: port: 8080 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ochacafe namespace: kafka annotations: kubernetes.io/ingress.class: nginx cert-manager.io/cluster-issuer: letsencrypt-prod spec: tls: - hosts: - kafka.shukawam.me secretName: shukawam-tls-secret-kafka rules: - host: kafka.shukawam.me http: paths: - path: / pathType: Prefix backend: service: name: ochacafe-bridge-service port: number: 8080 Bootstrap ServerのService名を指定 クラスタ外に公開したいなら、 必要に応じてIngress等も作成
Copyright © 2024, Oracle and/or its affiliates 43 Strimziを⽤いたKafkaクラスタ +
αの構築例 KafkaTopic apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: ochacafe labels: strimzi.io/cluster: ochacafe spec: # 省略した場合は、クラスタのdefault設定から引き継がれる # partitions: 3 # replicas: 3 config: # トピック固有の設定 retention.ms: 7200000 segment.bytes: 1073741824 # kafka.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: ochacafe namespace: ochacafe annotations: strimzi.io/node-pools: enabled strimzi.io/kraft: enabled spec: # ... 省略 ... config: offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 default.replication.factor: 3 num.partitions: 3 min.insync.replicas: 2 entityOperator: topicOperator: {} userOperator: {}
Copyright © 2024, Oracle and/or its affiliates 44 Kafkaと分散トレーシング
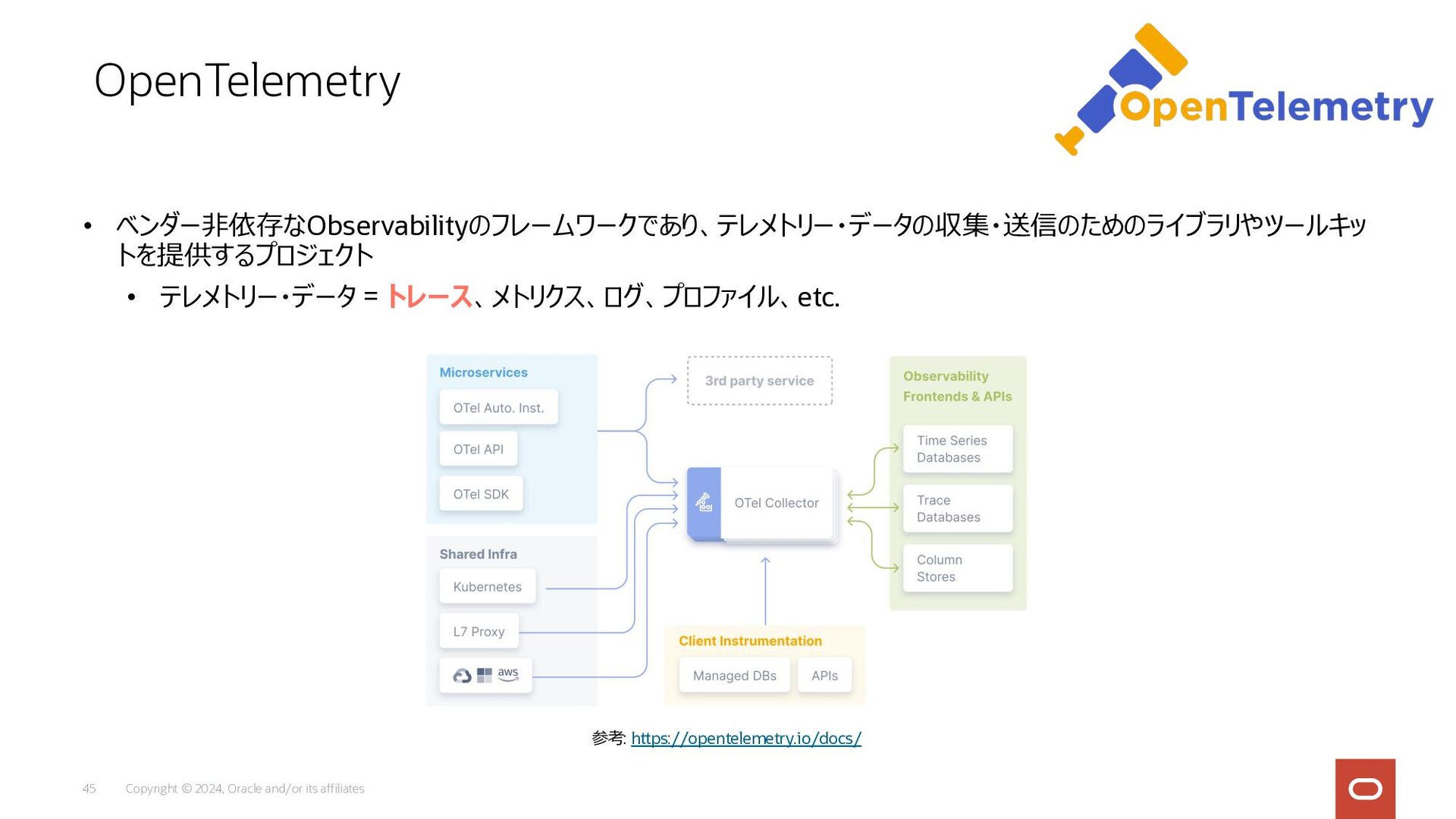
Copyright © 2024, Oracle and/or its affiliates 45 • ベンダー⾮依存なObservabilityのフレームワークであり、テレメトリー・データの収集・送信のためのライブラリやツールキッ
トを提供するプロジェクト • テレメトリー・データ = トレース、メトリクス、ログ、プロファイル、etc. OpenTelemetry 参考: https://opentelemetry.io/docs/
Copyright © 2024, Oracle and/or its affiliates 46 Kafkaを⽤いた⾮同期通信でも分散トレーシングがしたい •
Producer/Consumer間で適切にトレース情報を伝播させる必要がある • Producer側 → スパンを⽣成し、Kafka HeaderにContext情報をInject • Consumer側 → Kafka HeaderにInjectされたContext情報をExtractし、スパンを⽣成する Javaの場合は、以下のいずれかで対応可 • Kafkaクライアントをトレース可能なクライアントでラップする // 割愛 • KafkaのInterceptor*として、⾃動的にトレース情報を追加するようなInterceptorを登録する • e.g. opentelemetry-kafka-clients-2.6 • Consumer側のエージェントに設定を追加する • otel.instrumentation.messaging.experimental.receive-telemetry.enabled: true *: Brokerに送信される前、受信したRecordをアプリケーションに渡される前に任意の処理が実⾏可能な機構のこと Kafka + OpenTelemetry
Copyright © 2024, Oracle and/or its affiliates 47 opentelemetry-kafka-clients-2.6を⽤いた実装例 –
Producer側 Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("linger.ms", 1); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put(“interceptor.classes”, TracingProducerInterceptor.class.getName()); # 追加 Producer<String, String> producer = new KafkaProducer<>(props); IntStream.range(0, 100).forEach(i -> { producer.send(new ProducerRecord<String, String>("my-topic", String.format("key-%s", Integer.toString(i)), String.format("value-%s", Integer.toString(i)))); }); producer.close();
Copyright © 2024, Oracle and/or its affiliates 48 参考: TracingProducerInterceptorの実装
public class TracingProducerInterceptor<K, V> implements ProducerInterceptor<K, V> { private static final KafkaTelemetry telemetry = KafkaTelemetry.create(GlobalOpenTelemetry.get()); @Override @CanIgnoreReturnValue public ProducerRecord<K, V> onSend(ProducerRecord<K, V> producerRecord) { telemetry.buildAndInjectSpan(producerRecord, clientId); return producerRecord; } // ... 省略 ... } <K, V> void buildAndInjectSpan(ProducerRecord<K, V> record, String clientId) { Context parentContext = Context.current(); KafkaProducerRequest request = KafkaProducerRequest.create(record, clientId); if (!producerInstrumenter.shouldStart(parentContext, request)) { return; } Context context = producerInstrumenter.start(parentContext, request); if (producerPropagationEnabled) { try { propagator().inject(context, record.headers(), SETTER); # RecordのヘッダーにContext情報をインジェクト } catch (Throwable t) { logger.log(WARNING, "failed to inject span context. sending record second time?", t); } } producerInstrumenter.end(context, request, null, null); }
Copyright © 2024, Oracle and/or its affiliates 49 opentelemetry-kafka-clients-2.6を⽤いた実装例 –
Consumer側 Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("interceptor.classes", TracingConsumerInterceptor.class.getName()); # 追加 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); records.forEach(record -> { logger.info(String.format("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value())); }); }
Copyright © 2024, Oracle and/or its affiliates 50 参考: TracingConsumerInterceptorの実装
public class TracingConsumerInterceptor<K, V> implements ConsumerInterceptor<K, V> { private static final KafkaTelemetry telemetry = KafkaTelemetry.builder(GlobalOpenTelemetry.get()) .setMessagingReceiveInstrumentationEnabled(ConfigPropertiesUtil.getBoolean( "otel.instrumentation.messaging.experimental.receive-telemetry.enabled", false)).build(); @Override @CanIgnoreReturnValue public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) { Context receiveContext = telemetry.buildAndFinishSpan(records, consumerGroup, clientId, timer); # ... 省略 ... return telemetry.addTracing(records, consumerContext); } } <K, V> Context buildAndFinishSpan( ConsumerRecords<K, V> records, String consumerGroup, String clientId, Timer timer) { Context parentContext = Context.current(); KafkaReceiveRequest request = KafkaReceiveRequest.create(records, consumerGroup, clientId); Context context = null; if (consumerReceiveInstrumenter.shouldStart(parentContext, request)) { context = InstrumenterUtil.startAndEnd( # Context情報のExtractと新しいスパンの⽣成 consumerReceiveInstrumenter, parentContext, request, null, null, timer.startTime(), timer.now()); } }
Copyright © 2024, Oracle and/or its affiliates 51 以下の設定だけでOK︕ Producer側
Consumer側 エージェントを⽤いた⾃動計装の場合 java -javaagent:path/to/opentelemetry-javaagent.jar ¥ -Dotel.service.name=kafka-producer -jar my-kafka-producer.jar java -javaagent:path/to/opentelemetry-javaagent.jar ¥ -Dotel.service.name= kafka-consumer ¥ -Dotel.instrumentation.messaging.experimental.receive-telemetry.enabled=true ¥ -jar my-kafka-consumer.jar
Copyright © 2024, Oracle and/or its affiliates 52 • Java(Helidon)で実装されたKafkaのProducer/Consumer間の⾮同期通信をOpenTelemetry
Java Agentを⽤ いた⾃動計装でトレースが繋がることを確認する • StrimziによってデプロイされるKafka Exporterからメトリクスが取得できることを確認する Demo: Kafka + Observability namespace: monitoring namespace: kafka namespace: ochacafe kafka-producer kafka-consumer Prometheus OpenObserve (OTLPのバックエンド + ダッシュボード) kafka cluster (KRaft mode) load- generator
Copyright © 2024, Oracle and/or its affiliates 53 Kafka •
https://kafka.apache.org/ • https://learning.oreilly.com/library/view/kafka-the-definitive/9781492043072/ KIP-500 • https://cwiki.apache.org/confluence/display/KAFKA/KIP- 500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum Strimzi • https://strimzi.io/ Kafka + OpenTelemetry • https://opentelemetry.io/blog/2022/instrument-kafka-clients/ Demo code • https://github.com/oracle-japan/ochacafe-kafka 参考情報
Thank you Copyright © 2024, Oracle and/or its affiliates 54
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}