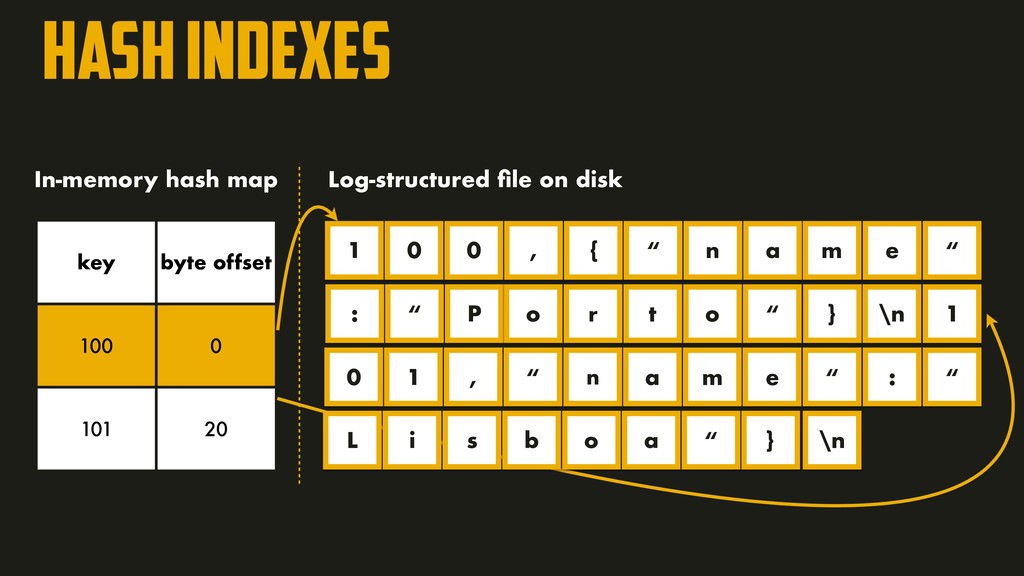
of keys, since the entire hash map must fit in memory! Scanning over a range of keys it’s not efficient — it would be necessary to look up each key individually in the hash maps.
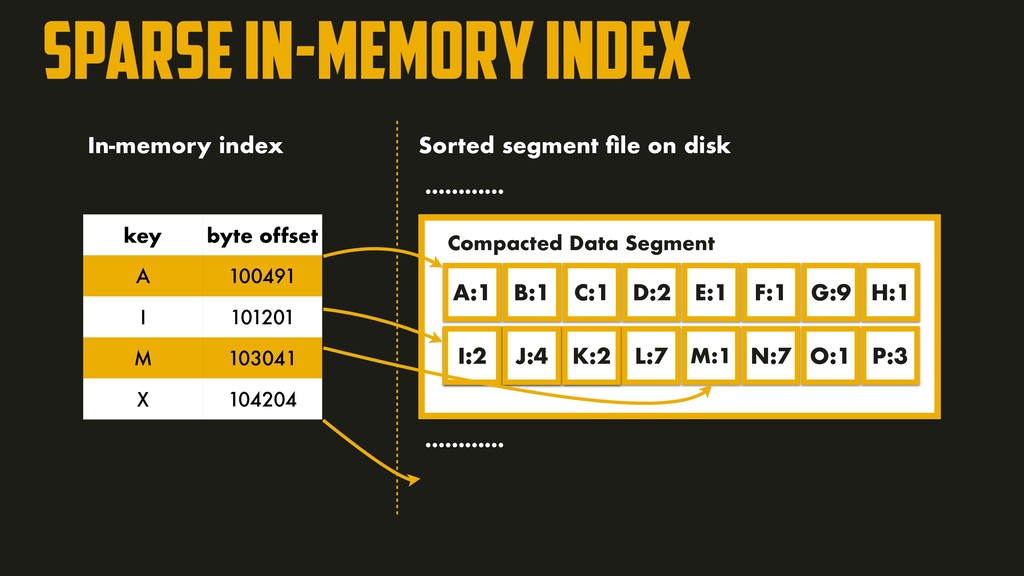
H:1 B:4 C:5 A:7 Compacted Data Segment I:2 J:4 K:2 L:7 M:1 N:7 O:1 P:3 key byte offset A 100491 I 101201 M 103041 X 104204 Sorted segment file on disk ………… ………… In-memory index
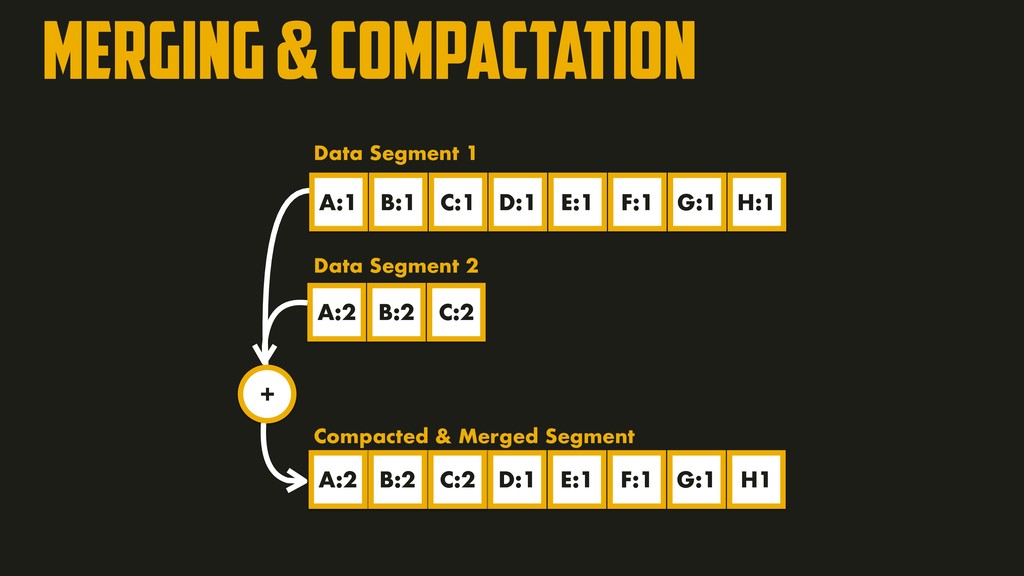
are more recent than all values in the other segment. When multiple segments contain the same key, the value from the most recent segment is kept and older segments are discarded. In order to find a particular key in the file, there’s no longer need to keep the full index in memory!
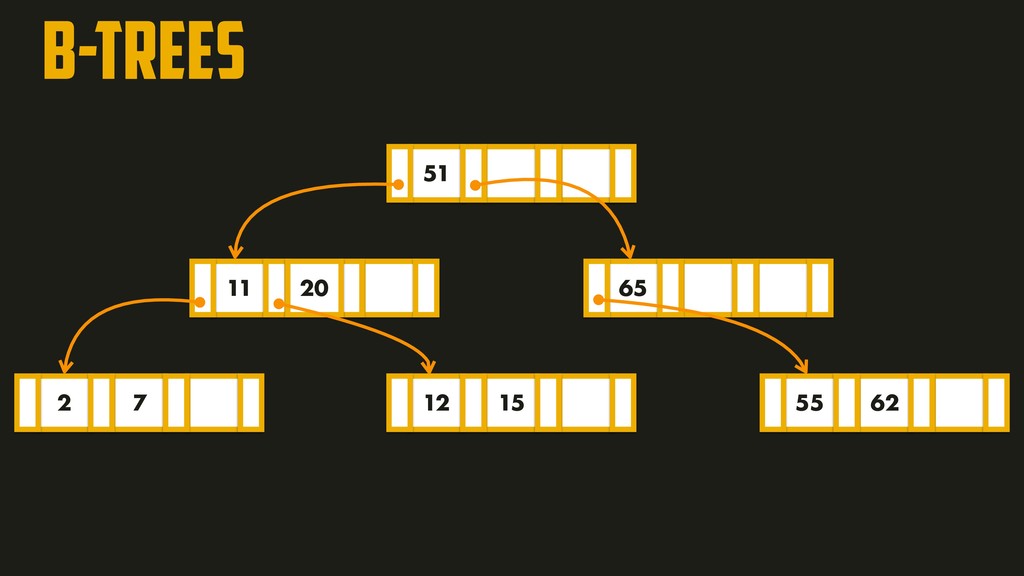
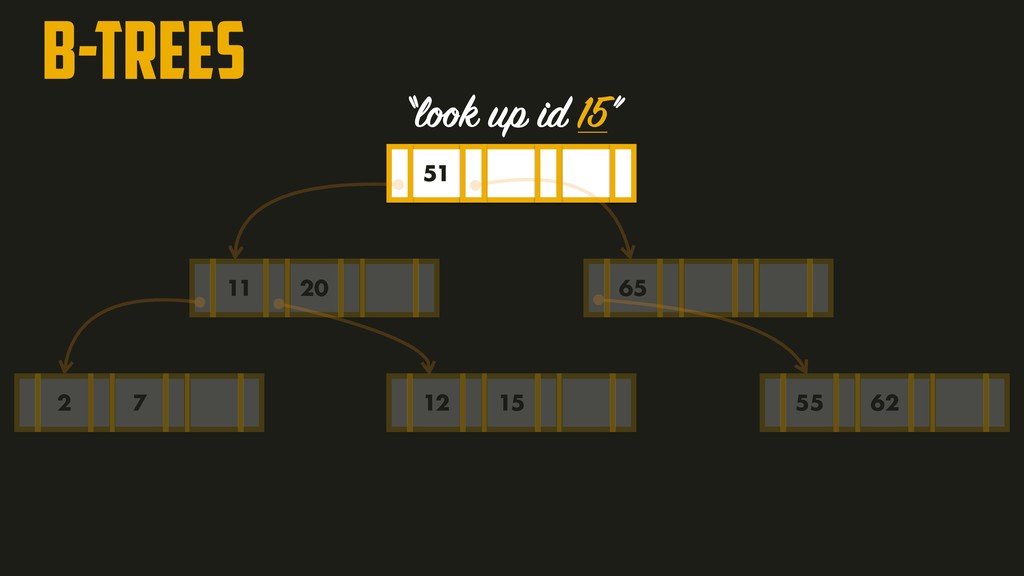
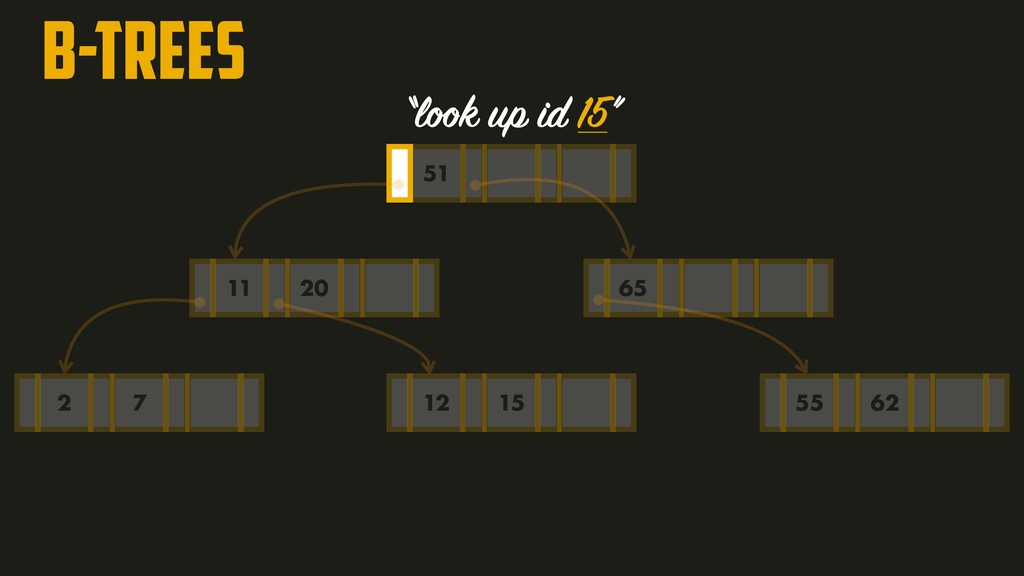
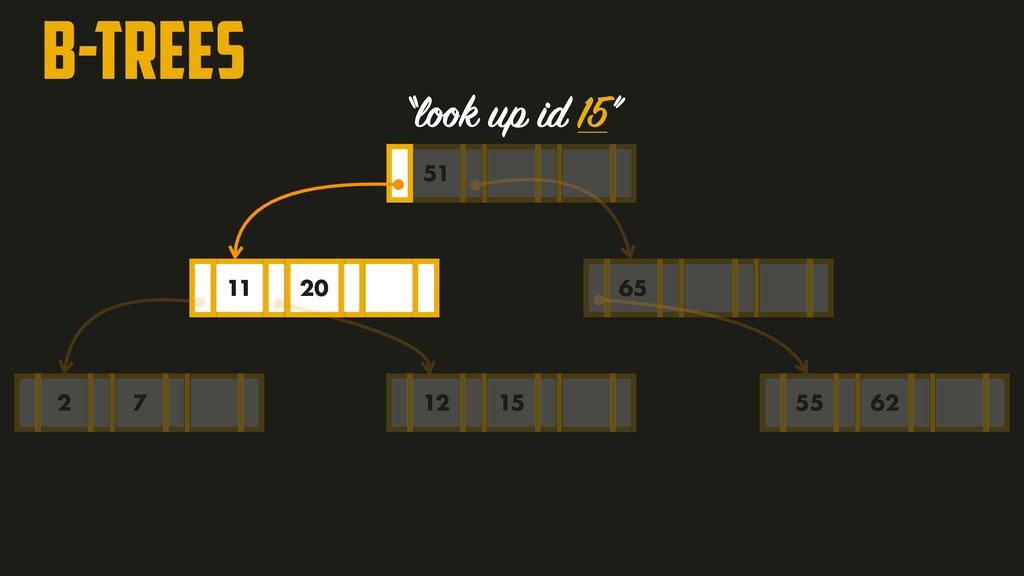
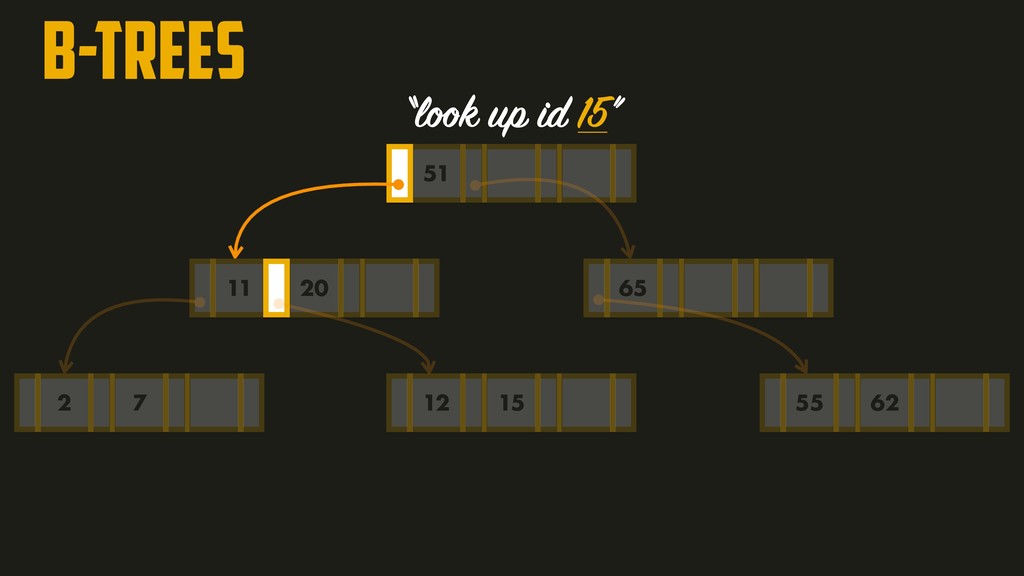
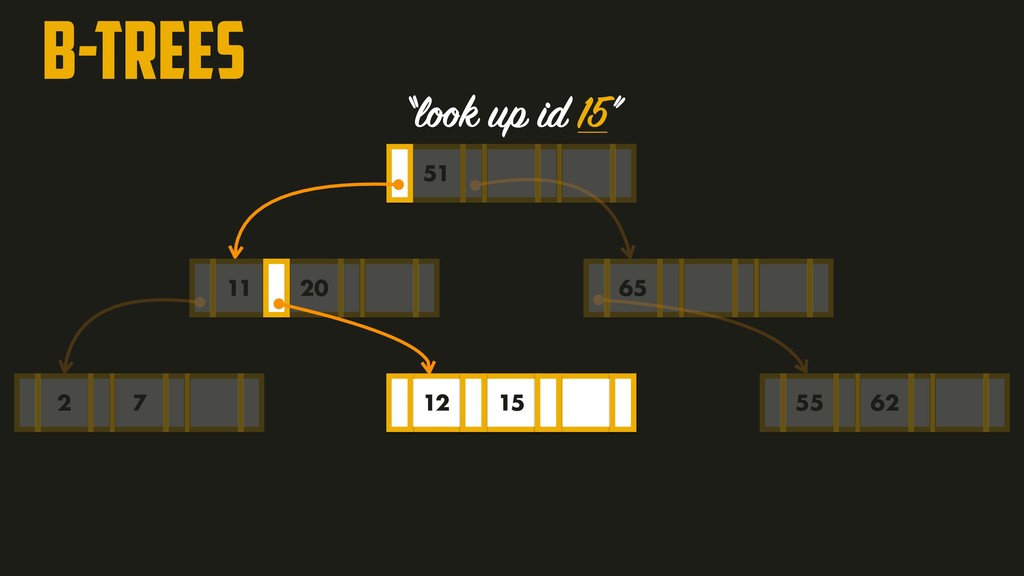
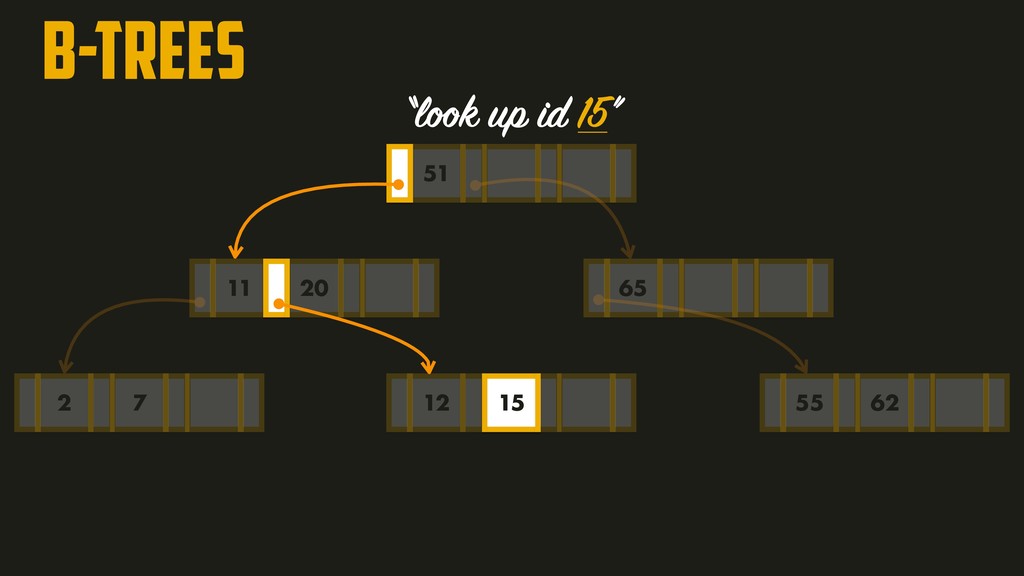
page is called the branching factor (~hundreds). In order to add a new key, we need to find the page within the key range and split into two pages if there’s no space to accommodate it. A four-level tree of 4KB pages with a branching factor of 500 can store up to 256TB!!!
before it can be applied to the pages of the tree itself. Used to restore the B-tree back to a consistent state after a crash. Writing all modifications to the WAL means that a B-tree index must write every piece of data at least twice!!!
multiple writes to the disk. Write amplification has a direct performance cost! The more that a storage engine writes to disk, the fewer writes per second it can handle.
must write every piece of data at least twice — once to the write-ahead log and once to the tree page! Reads are slower on LSM-trees since they have to check several data structures and SSTables at different stages of compaction! LSM-trees are able to sustain higher write throughput due to lower write amplification and sequential writes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}