Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Google Cloud Next'19 Data Analytics Products
Search
orfeon
April 17, 2019
Technology
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Google Cloud Next'19 Data Analytics Products
https://mercaridev.connpass.com/event/125881/
の発表資料です
orfeon
April 17, 2019
More Decks by orfeon
See All by orfeon
Google Cloud Next'19 BigData Day
orfeon
4
1.3k
Other Decks in Technology
See All in Technology
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.1k
Making sense of Google’s agentic dev tools
glaforge
1
180
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2.3k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
170
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
310
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
4
2.6k
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.1k
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
210
はじめてのWDM
miyukichi_ospf
1
140
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
1
250
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
Featured
See All Featured
AI: The stuff that nobody shows you
jnunemaker
PRO
8
820
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
220
Automating Front-end Workflow
addyosmani
1370
210k
How GitHub (no longer) Works
holman
316
150k
Navigating Weather and Climate Data
rabernat
0
310
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Test your architecture with Archunit
thirion
1
2.3k
Transcript
Cloud Next19 報告会 〜DataAnalytics系プロダクト発表紹介〜 orfeon@merpay
自己紹介 • 名前: Yoichi Nagai ◦ orfeon@github, orfeonjp@twitter • 所属:
merpay solution team • 役割: Data Engineer@GCP • 趣味: サイクリング 早めに着いたので ゴールデンブリッジに サイクリングに行ったら あいにくの霧。。。
ビッグデータ・分析系プロダクト • Cloud Dataflow • Cloud Data Fusion • Data
Catalog • BigQuery • AutoML • ML API • Cloud Dataproc
Cloud Dataflow 〜New Features • Streaming Engine & Streaming AutoScaling
(GA) ◦ 状態管理をサービスとして分離し、性能とコスパと可用性向上 • Dataflow SQL (Alpha) ◦ BigQuery UIからSQLで記述した処理をDataflow実行できるように ◦ DataflowなのでStreamingで流れるデータに対して SQLで処理できるように • Dataflow FlexRS (Beta) ◦ Preemptible VMを併用できるように (Shuffle mode必須) ◦ 遅延スケジュールで急がないジョブを安く動かせるように (概ねPreemptible VM分だけ安く) • Python SDK ◦ Python 3 support (Alpha) ◦ Python Streaming (Beta) ◦ TensorFlow Extended, Kubeflow への統合強化 Advances in Stream Analytics (Cloud Next '19) Data Processing in Google Cloud: Hadoop, Spark, and Dataflow (Cloud Next '19) ※その他Flink Runner 強化なども
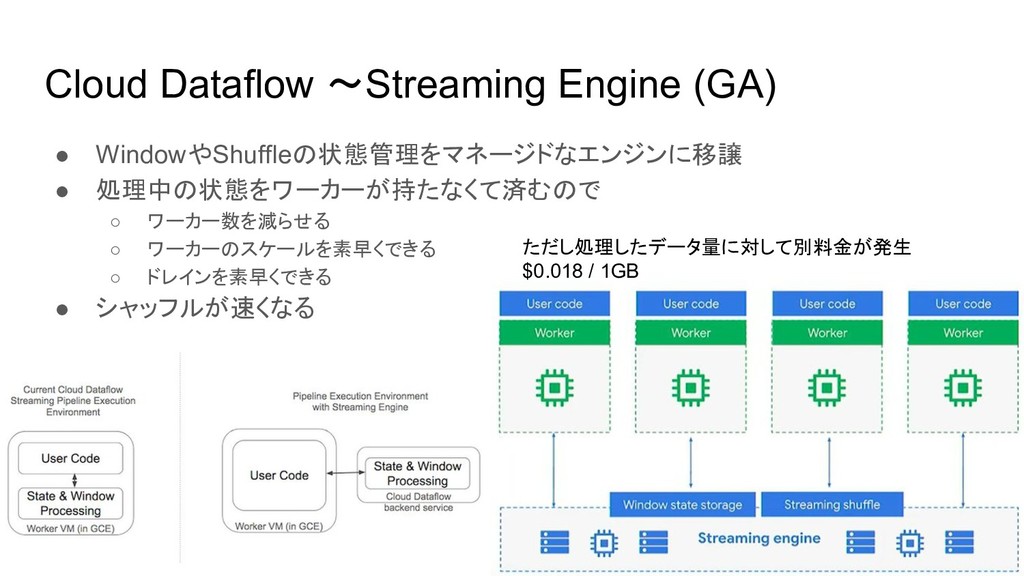
Cloud Dataflow 〜Streaming Engine (GA) • WindowやShuffleの状態管理をマネージドなエンジンに移譲 • 処理中の状態をワーカーが持たなくて済むので ◦
ワーカー数を減らせる ◦ ワーカーのスケールを素早くできる ◦ ドレインを素早くできる • シャッフルが速くなる ただし処理したデータ量に対して別料金が発生 $0.018 / 1GB
Cloud Dataflow 〜Dataflow SQL (Alpha: 5月予定) • BigQueryUIからSQLでDataflowジョブを実行可能に ◦ BatchとStreamingをSQLで統一的に扱えるように
(データアナリストがStreaming処理を扱える) • UDFをJava書けるように ◦ 複雑な処理の記述や集約 UDF関数も使えるように(今の所BigQuery UIからはできなさそう) PubSubから入る取引レコードと BigQueryのマスターレコードを Join して時間/地域ごとに集計 PubSubトピックからのレコードのス キーマはData Catalogに登録 TUMBLEは固定幅Window
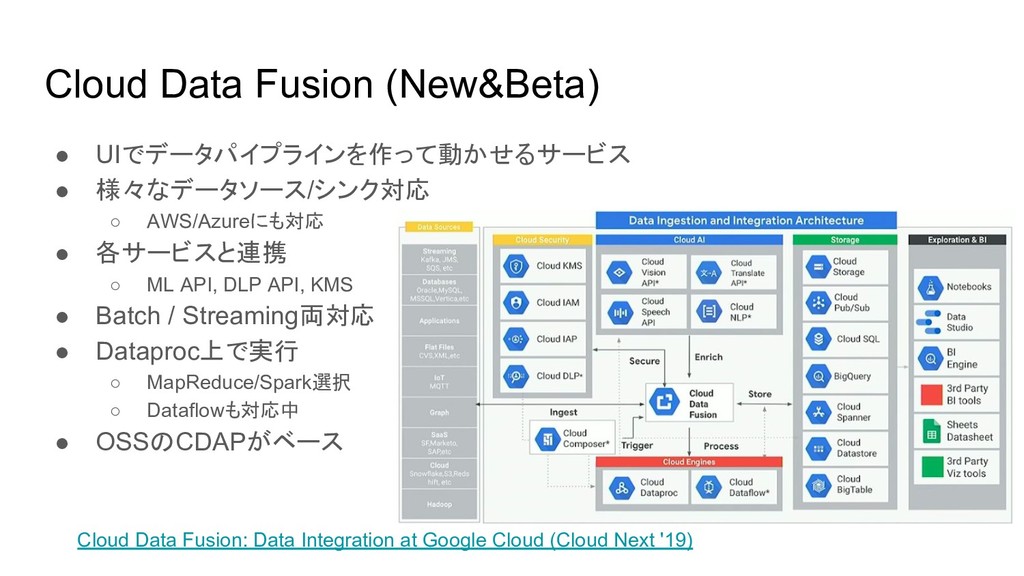
Cloud Data Fusion (New&Beta) • UIでデータパイプラインを作って動かせるサービス • 様々なデータソース/シンク対応 ◦ AWS/Azureにも対応
• 各サービスと連携 ◦ ML API, DLP API, KMS • Batch / Streaming両対応 • Dataproc上で実行 ◦ MapReduce/Spark選択 ◦ Dataflowも対応中 • OSSのCDAPがベース Cloud Data Fusion: Data Integration at Google Cloud (Cloud Next '19)
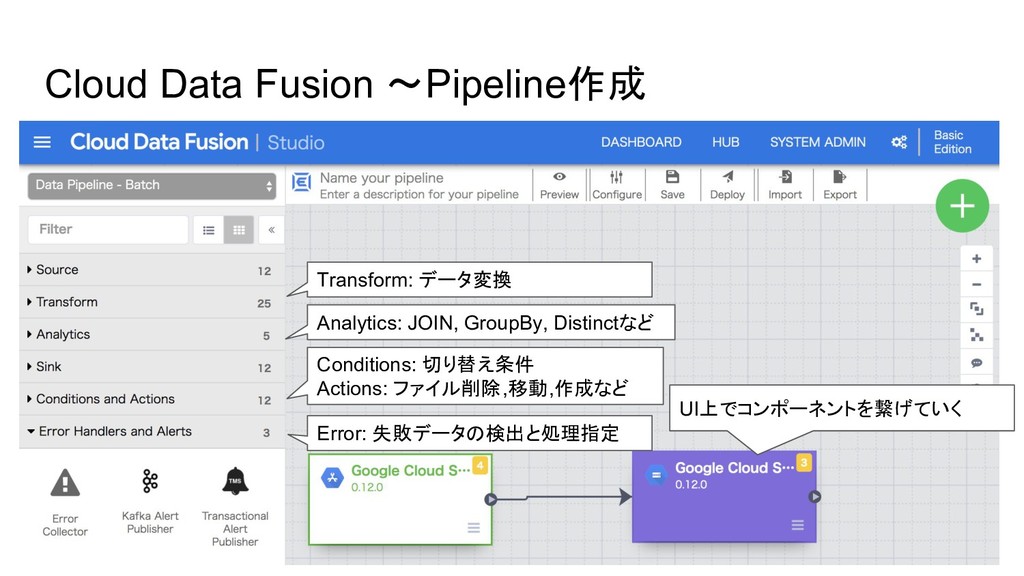
Cloud Data Fusion 〜Pipeline作成 UI上でコンポーネントを繋げていく Transform: データ変換 Analytics: JOIN, GroupBy,
Distinctなど Conditions: 切り替え条件 Actions: ファイル削除,移動,作成など Error: 失敗データの検出と処理指定
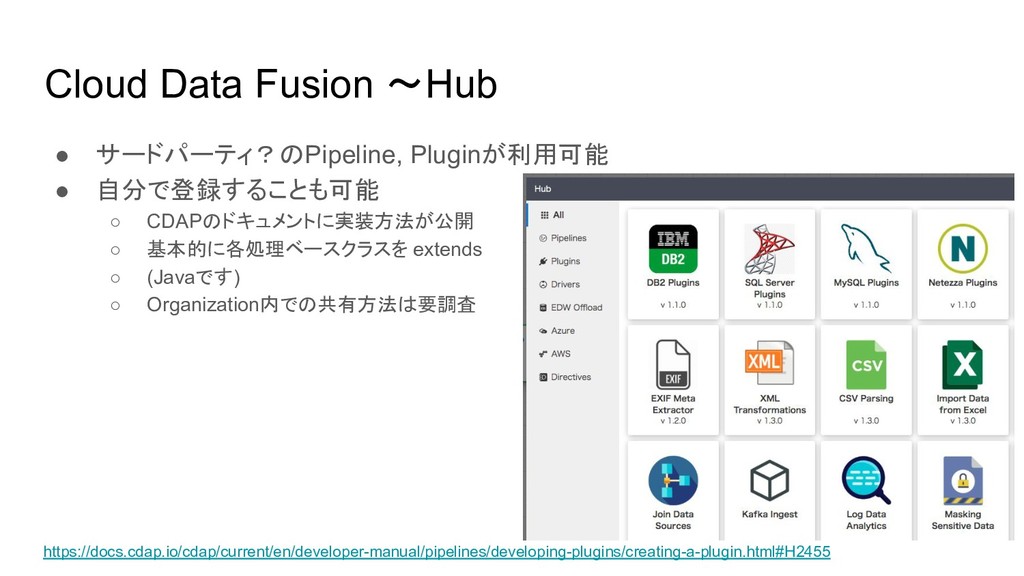
Cloud Data Fusion 〜Hub • サードパーティ?のPipeline, Pluginが利用可能 • 自分で登録することも可能 ◦
CDAPのドキュメントに実装方法が公開 ◦ 基本的に各処理ベースクラスを extends ◦ (Javaです) ◦ Organization内での共有方法は要調査 https://docs.cdap.io/cdap/current/en/developer-manual/pipelines/developing-plugins/creating-a-plugin.html#H2455
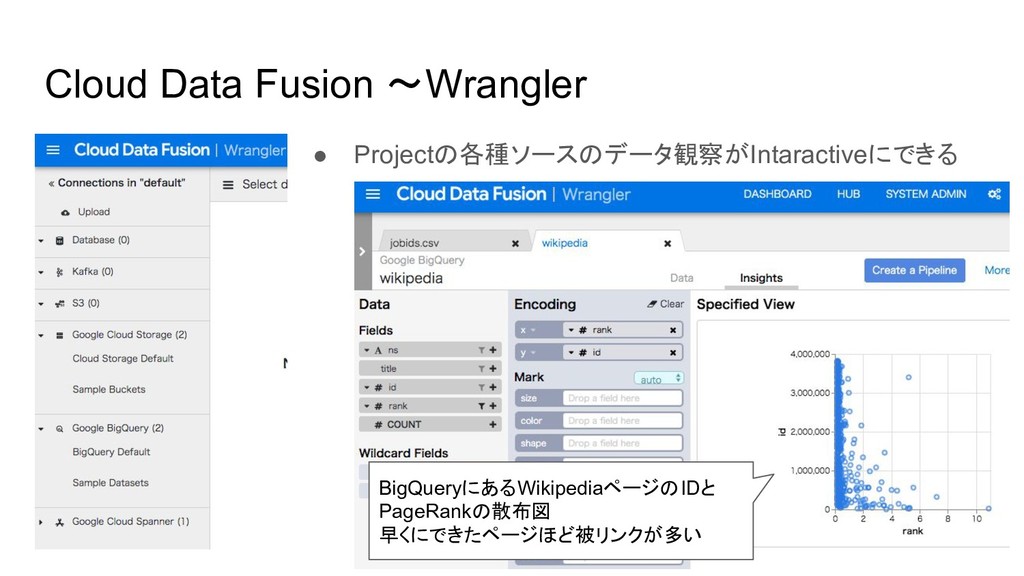
Cloud Data Fusion 〜Wrangler • Projectの各種ソースのデータ観察がIntaractiveにできる BigQueryにあるWikipediaページのIDと PageRankの散布図 早くにできたページほど被リンクが多い
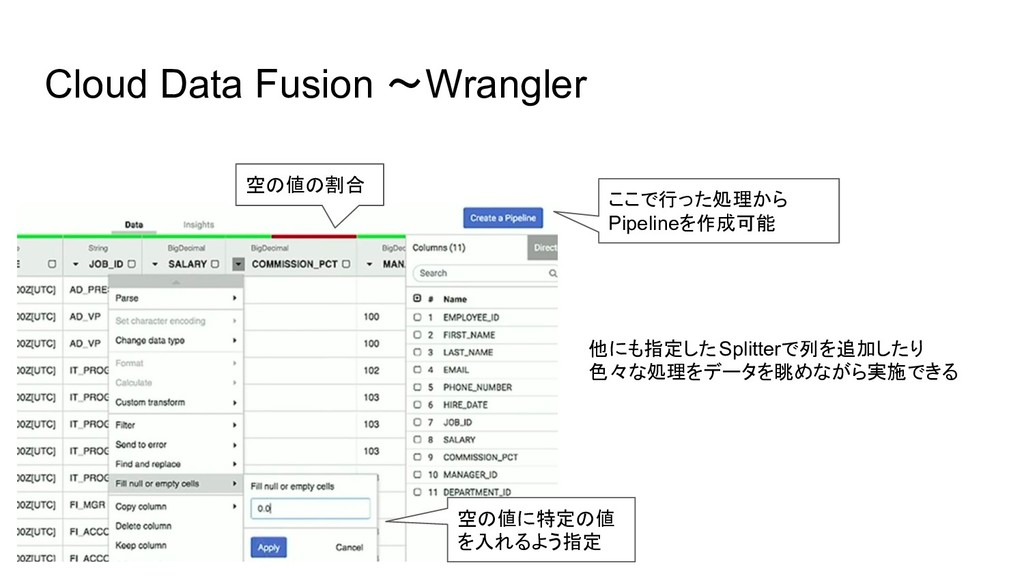
Cloud Data Fusion 〜Wrangler 空の値の割合 空の値に特定の値 を入れるよう指定 ここで行った処理から Pipelineを作成可能 他にも指定したSplitterで列を追加したり
色々な処理をデータを眺めながら実施できる
Cloud Data Fusion 〜お値段 • Basic: $1.8 / Hour ◦
Pipeline同時実行数上限2 ◦ 月の最初の120時間分は無料 ◦ 月ずっと動かしてた場合 $1,100 • Enterprise: $4.2 / Hour ◦ 同時実行無制限 ◦ Streaming対応 ◦ High Availability ◦ REST API ◦ Triggers / Schedules ◦ 月ずっと動かしてた場合 $3,000 個人で使う分には120時間無料枠 のあるBasicが良さそうだが使い終 わったら落とすように要注意!
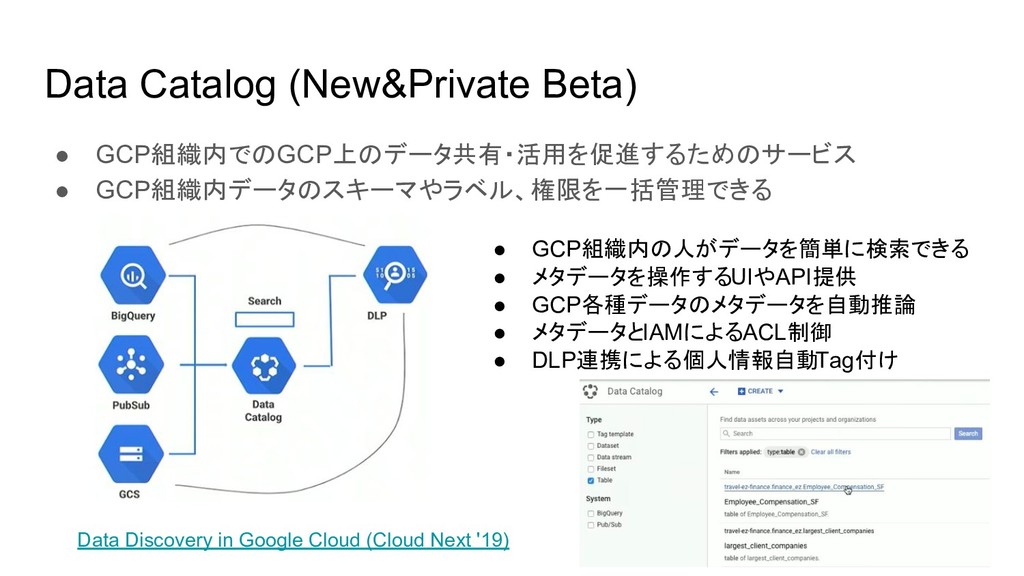
Data Catalog (New&Private Beta) • GCP組織内でのGCP上のデータ共有・活用を促進するためのサービス • GCP組織内データのスキーマやラベル、権限を一括管理できる Data Discovery
in Google Cloud (Cloud Next '19) • GCP組織内の人がデータを簡単に検索できる • メタデータを操作するUIやAPI提供 • GCP各種データのメタデータを自動推論 • メタデータとIAMによるACL制御 • DLP連携による個人情報自動Tag付け
Data Catalog 〜メタデータとは • Technical Metadata (自動的に付与される) ◦ Name: table,
column ◦ Description: table, column ◦ Date: created, modified • Business Metadata (ユーザが付与する) ◦ Tableの個人情報の有無 ◦ データのオーナー ◦ データの有効期限(delete by, retain till) ◦ カラム計算ロジック ◦ データ品質スコア Metadataの入力項目をTemplateとして用意 することも可能. 入力型も指定できる (string, double, bool, enum, datetime) タグの値ごとにIAMと権限を指定可能
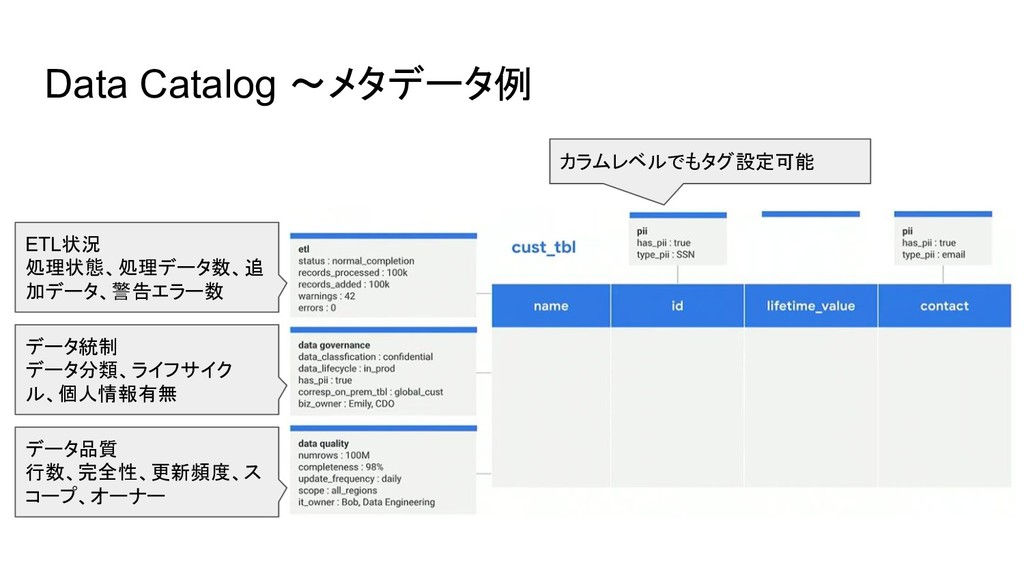
Data Catalog 〜メタデータ例 データ品質 行数、完全性、更新頻度、ス コープ、オーナー カラムレベルでもタグ設定可能 データ統制 データ分類、ライフサイク ル、個人情報有無
ETL状況 処理状態、処理データ数、追 加データ、警告エラー数
AutoML 〜New Features • AutoML Vision ◦ Object detection (Beta)
◦ AutoML Vision Edge (Beta) • AutoML Natural Language ◦ Entity extraction (Beta) ◦ Sentiment analysis (Beta) • AutoML Video Intelligence (New Beta) • AutoML Tables (New Beta) ◦ 構造化データのカスタム学習ができるように
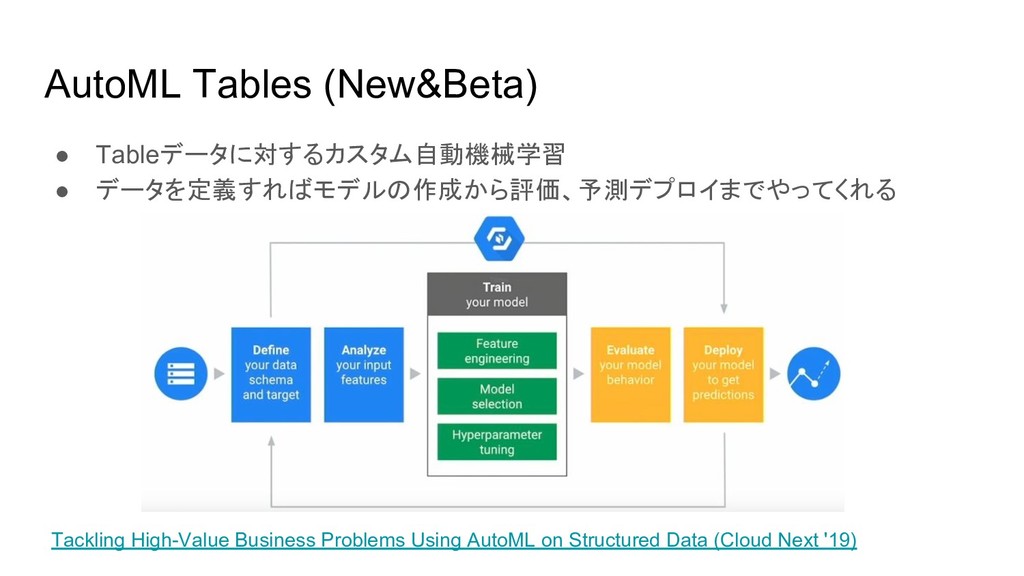
AutoML Tables (New&Beta) • Tableデータに対するカスタム自動機械学習 • データを定義すればモデルの作成から評価、予測デプロイまでやってくれる Tackling High-Value Business
Problems Using AutoML on Structured Data (Cloud Next '19)
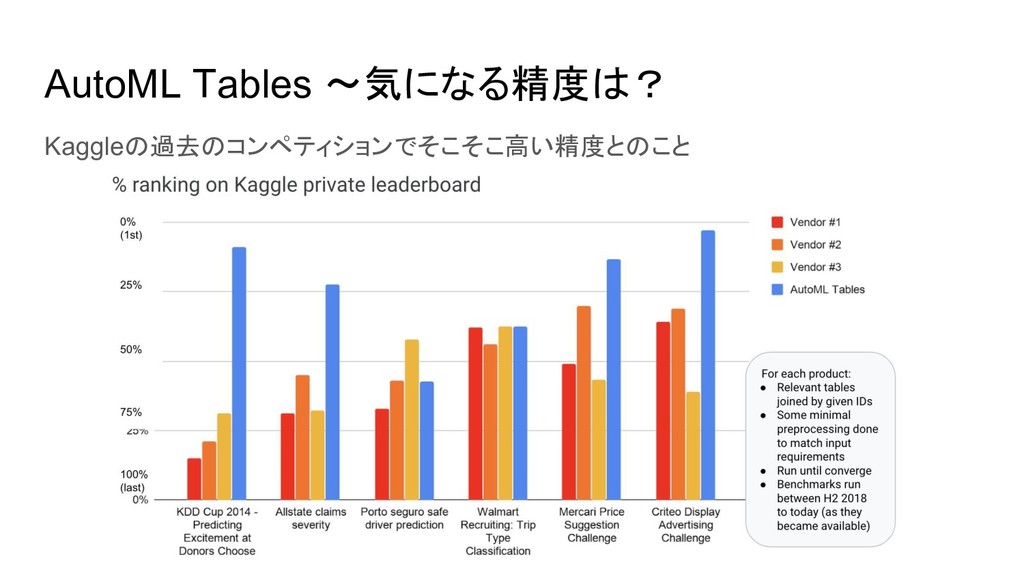
AutoML Tables 〜気になる精度は? Kaggleの過去のコンペティションでそこそこ高い精度とのこと
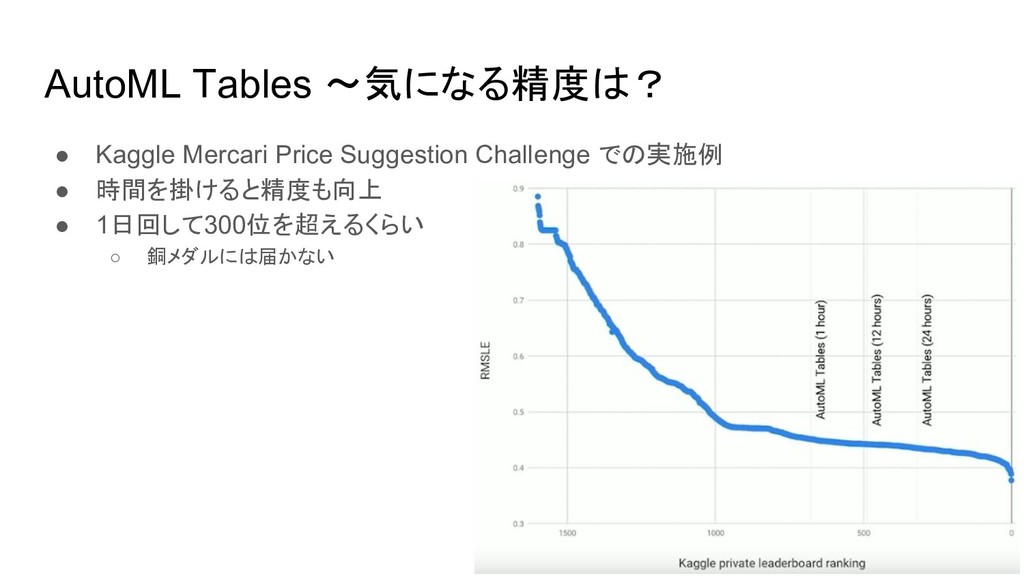
AutoML Tables 〜気になる精度は? • Kaggle Mercari Price Suggestion Challenge での実施例
• 時間を掛けると精度も向上 • 1日回して300位を超えるくらい ◦ 銅メダルには届かない
AutoML Tables 〜気になる精度は? NEXTの裏でやってた Kaggle Days(Kaggleのカンファレンス)で の5時間Hackathonで47チーム中2位 ! (1位チームの1人はKaggle Master)
ちなみに有償AutoML製品のH2O.aiも 4位入賞 時間が限られた場合だとAutoMLは人間のExpertにも肉薄
AutoML Tables 〜仕組み • NNだけじゃないらしい? ◦ 小さいデータ -> LogisticReg ◦
大きいデータ -> NN ◦ Tree based architecture? 詳細については近くペーパーを出すとのこと
AutoML Tables 〜入力データ型 AutoML data types CSV (on GCS) BigQuery
data types Numeric ◯ INT64,FLOAT64,STRING,NUMERIC Categorical ◯ INT64,FLOAT64,STRING,NUMERIC,BOOL, DATE,DATETIME,TIME,TIMESTAMP Text ◯ STRING Timestamp ◯ DATE,DATETIME,TIMESTAMP Array × ARRAY Struct × STRUCT 高い予測モデルを実現するには複雑なデータ構造を埋め込む BigQueryの方が良さそう?
AutoML Tables 〜お値段 • Training: ◦ $19.32 / Hour(実行時間) ▪
n1-standard-4 インスタンス 92台分の価格とのこと • Prediction ◦ Deployment ▪ $0.005 / GB(モデルサイズ) / Hour(稼働時間) / Machine(Default: 9台) ◦ Prediction ▪ Batch: 1.16 / Hour (最初の6時間は無料) ▪ Online: 0.21 / Hour
AutoML Tables 〜その他 • レコード数は10万未満だと、現時点ではAutoMLは活かしきれない ◦ 公式ドキュメントの推奨レコード数 ▪ 分類: 50
x 特徴量数 ▪ 回帰: 200 x 特徴量数 • より複雑なデータだと効果的(数値 + テキストなど) • 画像は現時点では現状非対応だが対応を検討している • 学習した予測モデルは現状ダウンロード不可だが対応を検討している
BigQuery 〜New Features • BigQuery ML ◦ Core (GA) ◦
K-means clustering (Beta) ◦ Matrix-Factorization (Alpha) ◦ DNN (分類/回帰) (Alpha) ◦ TensorFlow Model import (Alpha) • BigQuery BI Engine (Beta) • BigQuery Data Transfer Service (Beta) • Connected sheets (Beta) • BigQuery Storage API (Beta) • BigQuery GIS (GA)
ML API 〜New Features • Vision API ◦ Vision Product
Search (GA) ◦ Batch prediction, PDF online annotation. • Natural Language API ◦ 日本語、ロシア語サポート • Translation API V3 ◦ ユーザ辞書対応 • Video Intelligence API ◦ OCR対応 (GA) ◦ Object tracking (GA) ◦ Streaming video annotation (Beta)
Cloud Dataproc 〜New Features • Version 1.4 (GA) (Spark2.4, Python3,
Flink1.6 support) • Autoscaling (Beta) • Enhanced Flexibility Mode (Alpha) ◦ Preemptible VM でも効率的に動くよう、 ShuffleデータをPrimary NodeのHDFSに保存 • SparkR Jobs (Beta) • New Connectors ◦ BigQuery Read Connector (New) ◦ Cloud Spanner Connector for Spark (New) ◦ CGS Connector (性能向上) Random access for columnar files (4x), Multithreaded access • Optional components on Console (ANACONDA, ZooKeeper, Presto, Jupyter, Zeppelin) • Customer Managed EncryptKey (GA), Dataproc Kerberos (Beta) • Component Gateway (Alpha): Apache KNOX Cloud Dataproc’s Newest Features (Cloud Next '19)
所感 • DataAnalytics関連ではプログラミングレスに使えるプロダクト が多かった • DataflowSQL / Data Fusion +
AutoML / BigQueryML など プログラムを書かずにMLパイプラインをある程度まで 作れるように。 GCPで機械学習の民主化が着実に進んでいる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}