Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Google Cloud Next'19 BigData Day
Search
orfeon
May 29, 2019
Programming
1.3k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Google Cloud Next'19 BigData Day
https://gcpug-tokyo.connpass.com/event/128568/
orfeon
May 29, 2019
More Decks by orfeon
See All by orfeon
Google Cloud Next'19 Data Analytics Products
orfeon
0
280
Other Decks in Programming
See All in Programming
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
290
Language Server 使ってる? 〜VSCode と Zed の場合〜 / Are you using a Language Server? ~For VS Code and Zed~
handlename
0
840
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
Webフレームワークの ベンチマークについて
yusukebe
0
200
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
580
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.7k
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
250
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
160
どこまでゆるくて許されるのか
tk3fftk
0
470
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
530
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.7k
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
260
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
331
22k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
WENDY [Excerpt]
tessaabrams
11
38k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Transcript
Cloud Next’19 BigData Day orfeon@merpay
自己紹介 • 名前: orfeon (Yoichi Nagai) ◦ orfeon@github, orfeonjp@twitter •
所属: 株式会社メルペイ Solutionチーム • 役割: Data Engineer@GCP
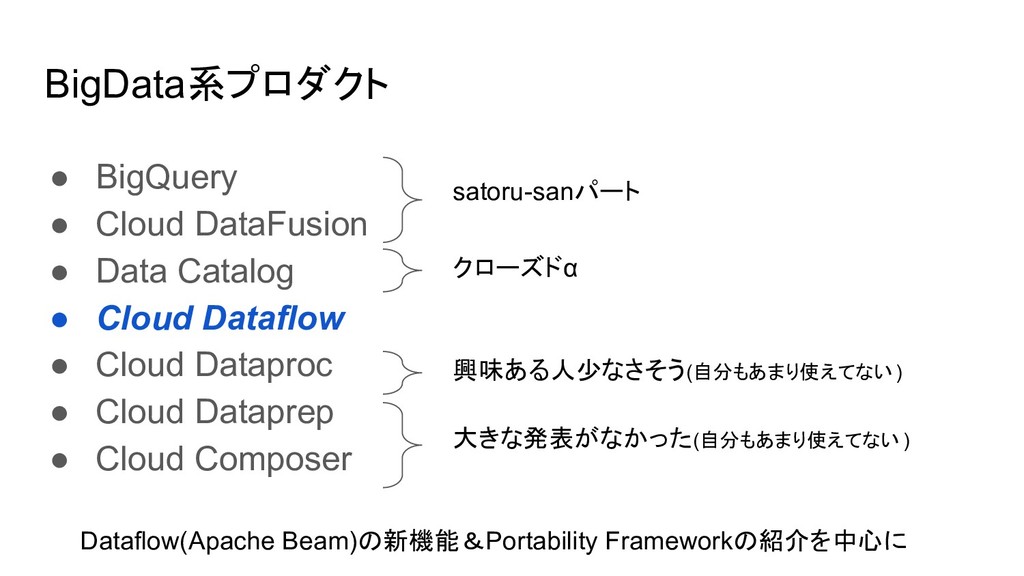
BigData系プロダクト • BigQuery • Cloud DataFusion • Data Catalog •
Cloud Dataflow • Cloud Dataproc • Cloud Dataprep • Cloud Composer
BigData系プロダクト • BigQuery • Cloud DataFusion • Data Catalog •
Cloud Dataflow • Cloud Dataproc • Cloud Dataprep • Cloud Composer satoru-sanパート クローズドα 興味ある人少なさそう(自分もあまり使えてない ) 大きな発表がなかった(自分もあまり使えてない ) Dataflow(Apache Beam)の新機能&Portability Frameworkの紹介を中心に
Cloud Dataflow 〜New Features • Streaming Engine & Streaming AutoScaling
(GA) ◦ 状態管理をサービスとして分離し、性能とコスパと可用性向上 • Dataflow SQL (Alpha) ◦ DataflowでStreamingデータとStorageデータをSQLで同時に扱えるように • Dataflow FlexRS (Beta) ◦ 遅延スケジュールで急がないジョブを安く動かせるように (概ねPreemptible VM分だけ安く) • Metrics,Alert (GA) • Python SDK ◦ Python 3 support (Alpha) ◦ Python Streaming (Beta) ◦ TensorFlow Extended, Kubeflow への統合強化 • Portability Framework ◦ カスタムコンテナ、Go SDK、複数言語で単一Pipeline
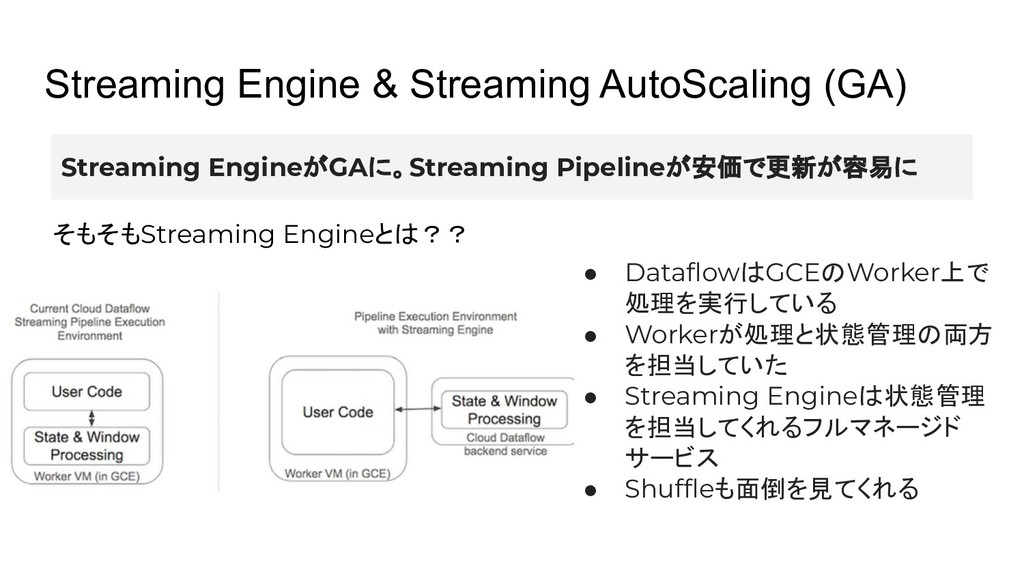
Streaming EngineがGAに。Streaming Pipelineが安価で更新が容易に そもそもStreaming Engineとは?? • DataflowはGCEのWorker上で 処理を実行している • Workerが処理と状態管理の両方
を担当していた • Streaming Engineは状態管理 を担当してくれるフルマネージド サービス • Shuffleも面倒を見てくれる Streaming Engine & Streaming AutoScaling (GA)
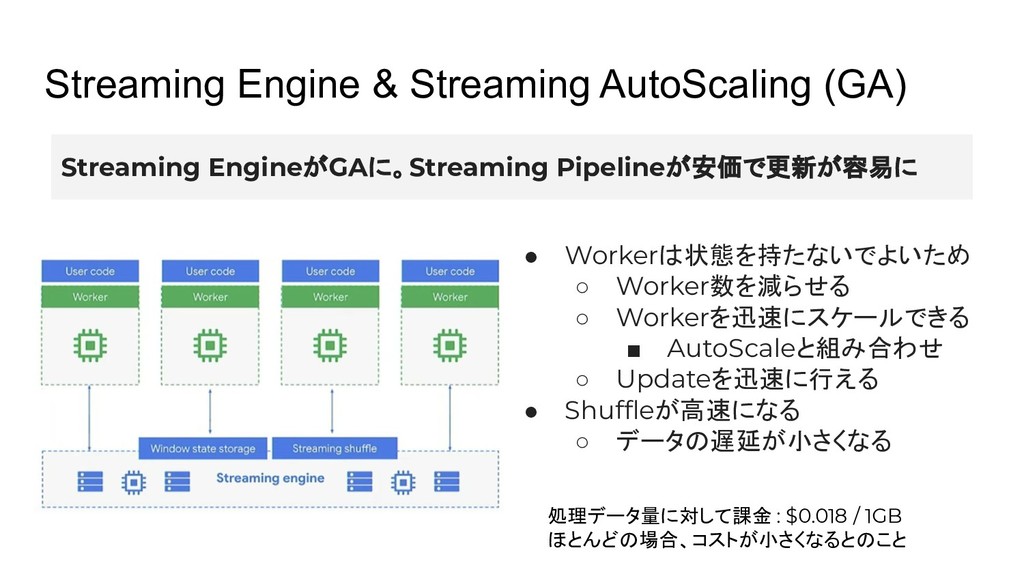
Streaming Engine & Streaming AutoScaling (GA) Streaming EngineがGAに。Streaming Pipelineが安価で更新が容易に •
Workerは状態を持たないでよいため ◦ Worker数を減らせる ◦ Workerを迅速にスケールできる ▪ AutoScaleと組み合わせ ◦ Updateを迅速に行える • Shuffleが高速になる ◦ データの遅延が小さくなる 処理データ量に対して課金 : $0.018 / 1GB ほとんどの場合、コストが小さくなるとのこと
Flex RS (β) 優先度の低いバッチ処理を安価に実行可能に --flexRSGoal=COST_OPTIMIZED 利用方法: オプションを指定(Beam SDK 2.12以降) •
Preemptible VMを併用してジョブを実行 ◦ 通常のVMと合わせて実行される • 状態管理をアウトソースできるShuffle Modeで実行する ◦ いつ落ちるかわからないPreemptible VMの影響を減らすため • 概ねPreemptible VM分だけ安くなる
Apache Beam SQL SQL文字列をパースして同等の処理を実行するTransformに変換 PCollection<Row> rows = ... PCollection<Row> filteredRows
=rows .apply(SqlTransform.query( "SELECT * FROM PCOLLECTION WHERE id=1")); 処理したい対象をPCollection<Row>に変換 SqlTransformをapplyしクエリ指定 (テーブル名は`PCOLLECTION`とする) PCollectionTuple tuple = PCollectionTuple .of( new TupleTag<>("T1"), record1), new TupleTag<>("T2"), record2)); PCollection <Row> output = tuple.apply( SqlTransform .query( "SELECT a.id, AVG(T1.rating)" + "FROM T1 INNER JOIN T2 ON T1.id == T2.id" )); 複数テーブルを用いる場合は TupleTagで 名前と対応づけて登録して用いる
Apache Beam SQL 〜機能対応 基本的な関数やJOINなどの機能は揃っている • 関数 ◦ Window関数 ◦
集約関数 ▪ MIN,MAX,SUM,AVG,COUNT以外 ◦ JSON関数 ◦ 配列以外のConstructor関数 https://beam.apache.org/documentation/dsls/sql/calcite/scalar-functions/ 現時点での主な未対応機能 • JOIN ◦ In-equal JOIN ◦ CROSS, FULL OUTER
Apache Beam SQL 〜UDF 通常(single row)UDFと集約UDFをサポート public static class CubicInteger
implements BeamSqlUdf { public static Integer eval(Integer input){ return input * input * input; } } public static class CubicIntegerFn implements SerializableFunction <Integer, Integer> { @Override public Integer apply(Integer input) { return input * input * input; } } String sql = "SELECT f_int, cubic1(f_int), cubic2(f_int) FROM TBL" ; PCollection<Row> result = input.apply("udfExample", SqlTransform.query(sql) .registerUdf("cubic1", CubicInteger.class) .registerUdf("cubic2", new CubicIntegerFn ()) 登録方法は2種類 - BeamSqlUdfを実装したClass - SerializableFunctionのInstance をregisterUdfで名前と登録 集約UDFの場合は 集約処理をカスタム CombineFnで記述 InstanceをregisterUdfで名前と登録
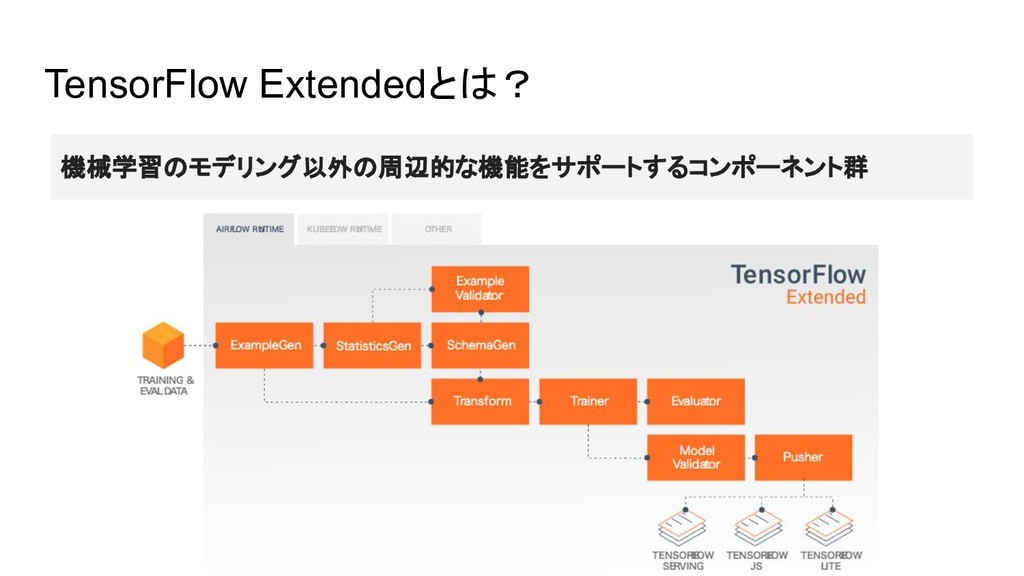
TensorFlow Extended (TFX) Dataflowの機能というわけではないが、 ML系セッションでDataflow(Apache Beam)との連携強化という文脈でちらほら BigData系とML系の中間で地味に埋もれそう話題なのでピックアップ
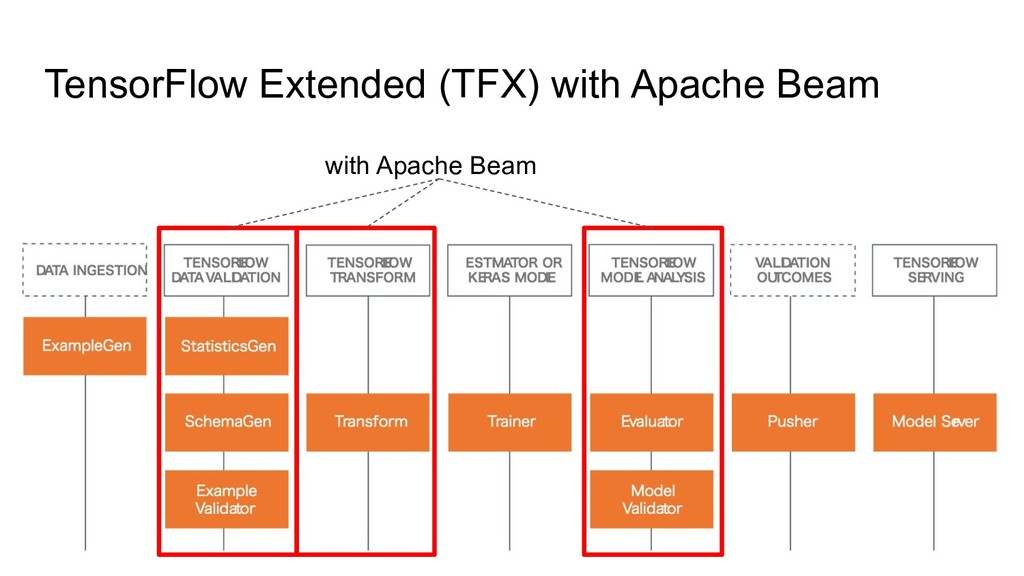
TensorFlow Extendedとは? 機械学習のモデリング以外の周辺的な機能をサポートするコンポーネント群
TensorFlow Extended (TFX) with Apache Beam with Apache Beam
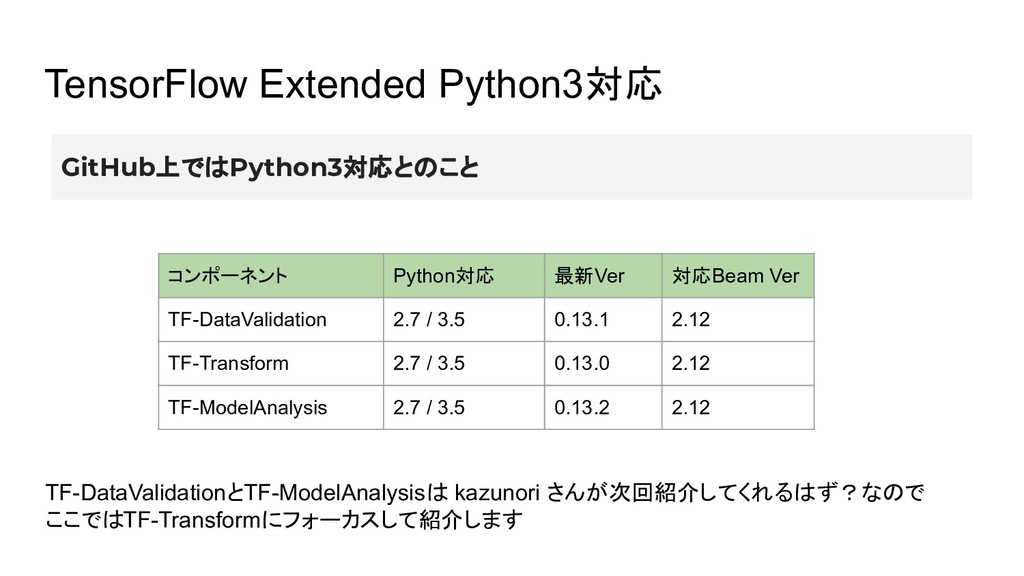
TensorFlow Extended Python3対応 コンポーネント Python対応 最新Ver 対応Beam Ver TF-DataValidation 2.7
/ 3.5 0.13.1 2.12 TF-Transform 2.7 / 3.5 0.13.0 2.12 TF-ModelAnalysis 2.7 / 3.5 0.13.2 2.12 GitHub上ではPython3対応とのこと TF-DataValidationとTF-ModelAnalysisは kazunori さんが次回紹介してくれるはず?なので ここではTF-Transformにフォーカスして紹介します
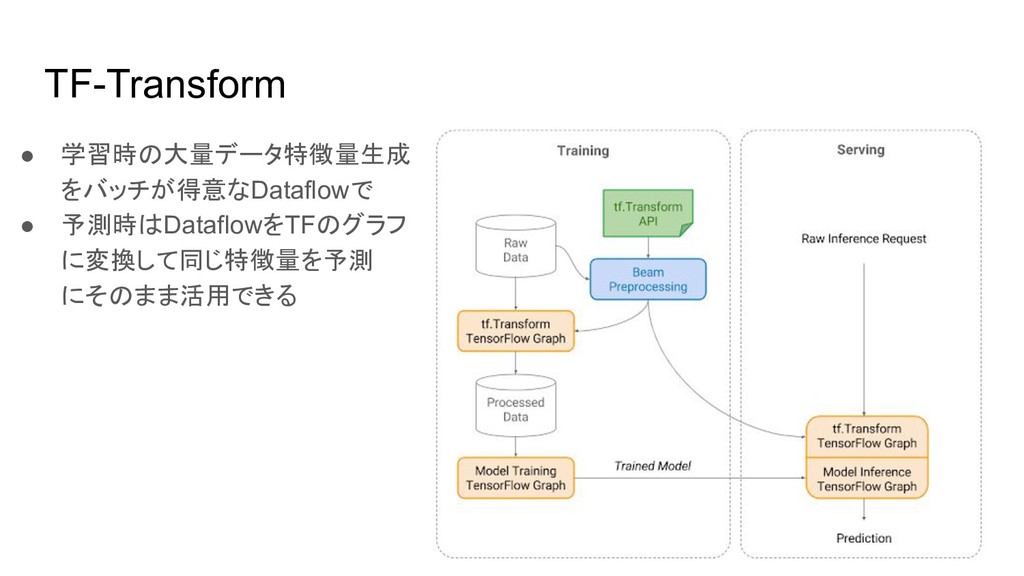
TF-Transform • 学習時の大量データ特徴量生成 をバッチが得意なDataflowで • 予測時はDataflowをTFのグラフ に変換して同じ特徴量を予測 にそのまま活用できる
TF-Transform コード例 def preprocessing_fn (inputs): return inputs.copy() with beam.Pipeline( options=options)
as pipeline: with tft_beam.Context( temp_dir="gs://xxxx/xxxx" ): raw_data = (pipeline | "Read" >> beam.io.ReadFromText( "gs://orfeon/inputs/input.csv" , skip_header_lines =1) | "Parse" >> beam.Map(tft.coders.CsvCoder([ "name","num1","num2"], METADATA.schema).decode)) (transformed_data, transformed_metadata), transform_fn = ( (raw_data, METADATA) | tft_beam.AnalyzeAndTransformDataset(preprocessing_fn)) transformed_data_coder = tft.coders.ExampleProtoCoder(transformed_metadata.schema) (transformed_data | 'EncodeTrainData' >> beam.Map(transformed_data_coder.encode) | 'WriteTrainData' >> beam.io.WriteToTFRecord( "gs://xxxx/output.tfrecord" )) transform_fn | 'WriteTransformFn' >> tft_beam.WriteTransformFn( "gs://xxxx/yyyy" ) Beamの変換関数 をTensorFlowの グラフとして保存 TF-Transformでやりたい処理を記載 入出力はTensor (関数は後述) TF-Transformの再利用する関数 変換と処理を同時に実行
TF-Transform 変換関数 • 集約系 ◦ tft.max, tft.mean, tft.min, tft.sum, tft.var
◦ tft.bucketize, tft.bucketize_per_key, tft.quantiles • 変換系 ◦ tft.string_to_int ◦ tft.scale_0_1, tft.scale_z_score • 辞書系 ◦ tft.compute_and_apply_vocabulary • 分析処理系 ◦ tft.tfidf, tft.ngram, tft.pca バッチでカテゴリカルな値や平均・分散などの値を保存しグラフに埋め込む 実行時の集計には対応しない (Streamingで過去5分間の平均との差分など )
DataflowをPython3 で動かすときの注意 • --requirements_file を指定しても pip3でInstallしてくれない(Python2で入る) ◦ Cloud Dataflow Worker環境にはTFXはいない
◦ setup.pyの sudo pip3 install … を実行してなんとか動く • ちょっとした処理が遅い ◦ ローカルだと10秒くらい, Javaだと2分程度で終わるのが7分くらい ◦ 大部分がWorkerのセットアップ
Portability Framework セッション中、それ自体が取り上げられることはないが カスタムコンテナ、Go SDK、複数言語Pipelineなど断片的な話題がちらほら これらを包括する概念としてまとめて紹介
Portability Framework とは? • Apache BeamではSDKで大きく2種類のコードを書く ◦ パイプライン制御: ▪ PCollection,
PTransrmを組み合わせて作る抽象的なパイプライン構造 ◦ ユーザロジック(UDF): ▪ DoFnやカスタムCombineFnなどで実データをどう扱うかを記載 SDK言語と、パイプライン制御/UDF実行環境を分離するフレームワーク 現状これら2種類のコードはRunnerで単一のJobに変換され (原則的に)同じ実行環境で動いている
Portability Framework とは? 〜現状の問題 1 • SDK言語で記載されたパイプライン制御とユーザロジックをJobに翻訳 ◦ SDK言語 x
ミドルウェア(Runner)ごとにJob翻訳処理が必要 ◦ ユーザロジックはミドルウェアが言語サポートしていないと厳しい • Hadoop系譜が多い分散処理FWはJava製プロダクトが圧倒的に多い ◦ -> Runner対応言語もJavaのみ対応ばかりの実情。。 Runnerの複数言語対応の開発の負担が大きい 多言語Runnerが出てこない -> Java以外で動かしたい人がいつまでたってもBeamを使えない 機械学習エンジニア、アプリケーションエンジニアも、バリバリ、バッチ処理書きたい ....!
Portability Framework とは? 〜現状の問題 2 • 環境構築手順をアプリケーションコードに記載 ◦ 実行環境構築やファイル(検索インデックスなど)取得など •
Worker起動時の初期処理が重い ◦ Python SDK の requirements.txtやsetup.pyなど指定すると時間が掛かる ◦ スケール速度に影響 ユーザが実行環境を細かくコントロールできない
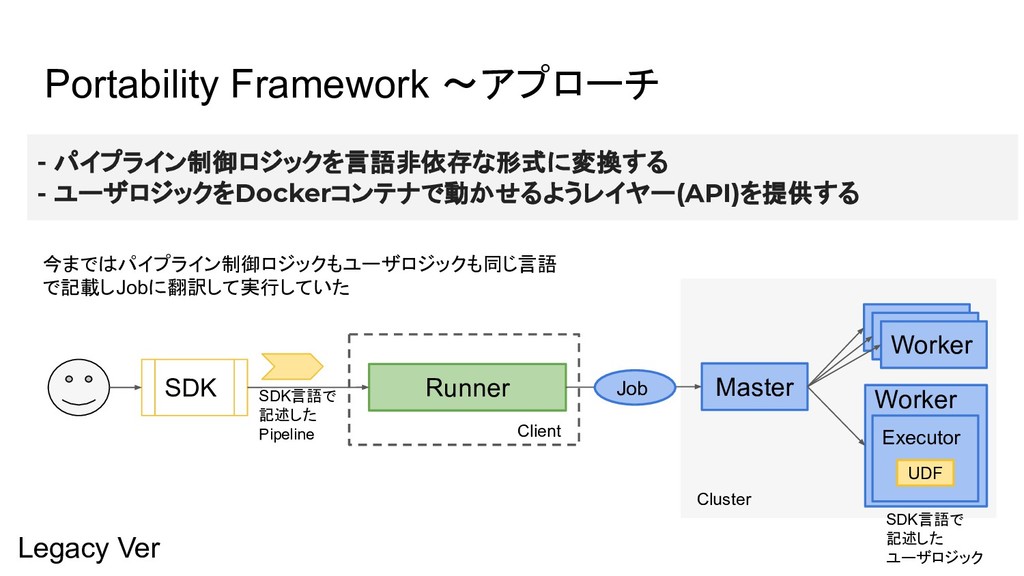
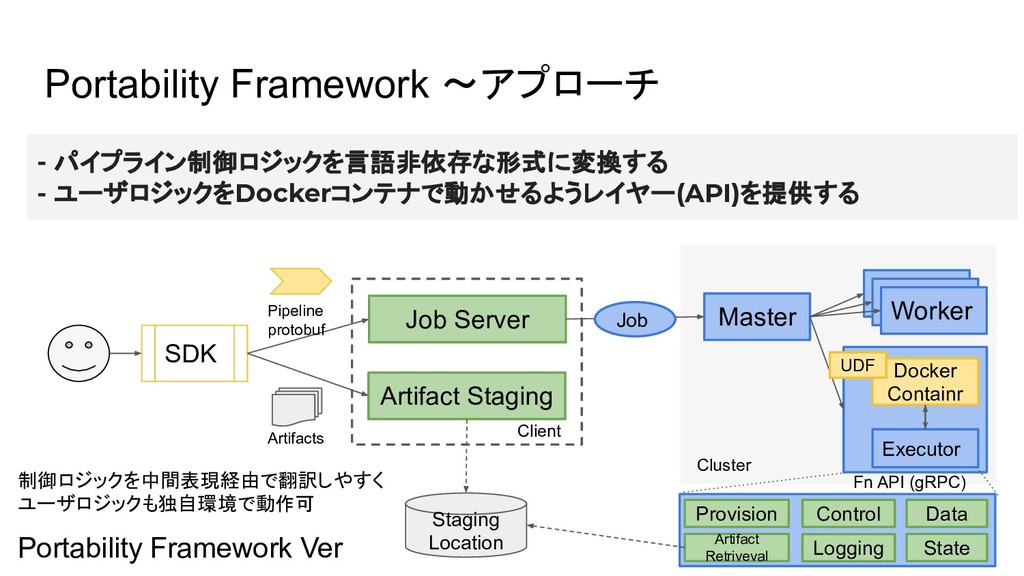
Portability Framework 〜アプローチ - パイプライン制御ロジックを言語非依存な形式に変換する - ユーザロジックをDockerコンテナで動かせるようレイヤー(API)を提供する SDK Runner Master
Worker Worker Worker Worker Executor Client Job UDF Cluster SDK言語で 記述した Pipeline Legacy Ver 今まではパイプライン制御ロジックもユーザロジックも同じ言語 で記載しJobに翻訳して実行していた SDK言語で 記述した ユーザロジック
Portability Framework 〜アプローチ - パイプライン制御ロジックを言語非依存な形式に変換する - ユーザロジックをDockerコンテナで動かせるようレイヤー(API)を提供する SDK Job Server
Artifact Staging Pipeline protobuf Artifacts Master Worker Worker Worker Docker Containr Executor Client Job UDF Staging Location Provision Control Data Logging State Artifact Retriveval Cluster Fn API (gRPC) Portability Framework Ver 制御ロジックを中間表現経由で翻訳しやすく ユーザロジックも独自環境で動作可
Portability Framework メリット • 一つのパイプラインで複数言語で記載したTransformを動かせる ◦ 例: Connectorが充実しているJavaのIOをPythonで使える ◦ 例:
既存データパイプラインに予測モデルTransformを組み込む ▪ データエンジニアと機械学習エンジニアの連携 • 実行環境をコントロールしやすくなる ◦ ML Opsと相性が良さそう(MLモデルごとコンテナイメージとして管理) Beamを好きなプログラミング言語・環境で動かせるように
Portability Framework デメリット • 初期評価では15%ほど性能的にオーバーヘッドがあるとのこと ◦ 数TBのデータで1段階JOIN、集計を行ったような内容(うろ覚え) • オーバーヘッドの大部分はgRPCによる通信部分とコンテナ管理 性能上のオーバーヘッドがある
Javaの世界で全て完結できる人にとってはあまりメリットはない?
Portability Framework 対応状況 Flink Runner が先行。Java/Pythonですでに基本的な機能に対応済み https://docs.google.com/spreadsheets/d/1KDa_FGn1ShjomGd-UUDOhuh2q73de2tPz6BqHpzqvNI/edit#gid=0
Portability Framework 対応状況(Dataflow) DataflowでもSDK Go(Experimental)がPortability Frameworkで対応 • Dataflow Go の進捗はDataflowのPortability対応の進捗に直結
• 一方、PythonはLegacyで開発が進んでいるため難しい状況に ◦ Legacyで機能追加が先か、Porability対応が先か。。。 Dataflow SQLは現時点ではSQLをJavaに置き換えているようなので Portabilityとは無関係(?)
所感 • Apache Flink の Beam への熱意がすごい ◦ Potability Frameworkに関しては本家を凌ぐ対応スピード
◦ オンプレで動かすならFlinkは良い選択肢になりそう • Apache Beamの勉強にはBeam Summitの動画がとてもわかりやすい ◦ https://www.youtube.com/channel/UChNnb_YO_7B0HlW6FhAXZZQ/videos • GCPではStreaming系処理の基幹的な位置付けになっていきそう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}