HPC HPC needs outstrip HPC market’s ability to fund the development Computational graphics and compute are highly aligned High efficiency parallel computing is core to Nvidia GeForce Quadro Tegra
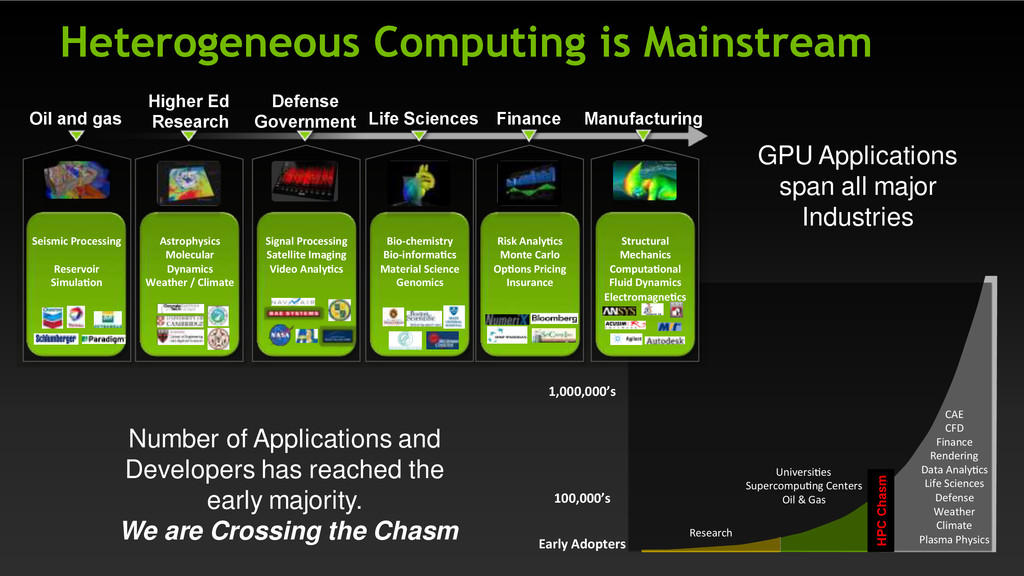
Supercompu ng Centers Oil & Gas CAE CFD Finance Rendering Data Analy cs Life Sciences Defense Weather Climate Plasma Physics 100,000’s HPC Chasm Finance Defense Government Higher Ed Research Oil and gas Life Sciences Manufacturing Seismic Processing Reservoir Simula on Astrophysics Molecular Dynamics Weather / Climate Signal Processing Satellite Imaging Video Analy cs Bio-chemistry Bio-informa cs Material Science Genomics Risk Analy cs Monte Carlo Op ons Pricing Insurance Structural Mechanics Computa onal Fluid Dynamics Electromagne cs GPU Applications span all major Industries Number of Applications and Developers has reached the early majority. We are Crossing the Chasm
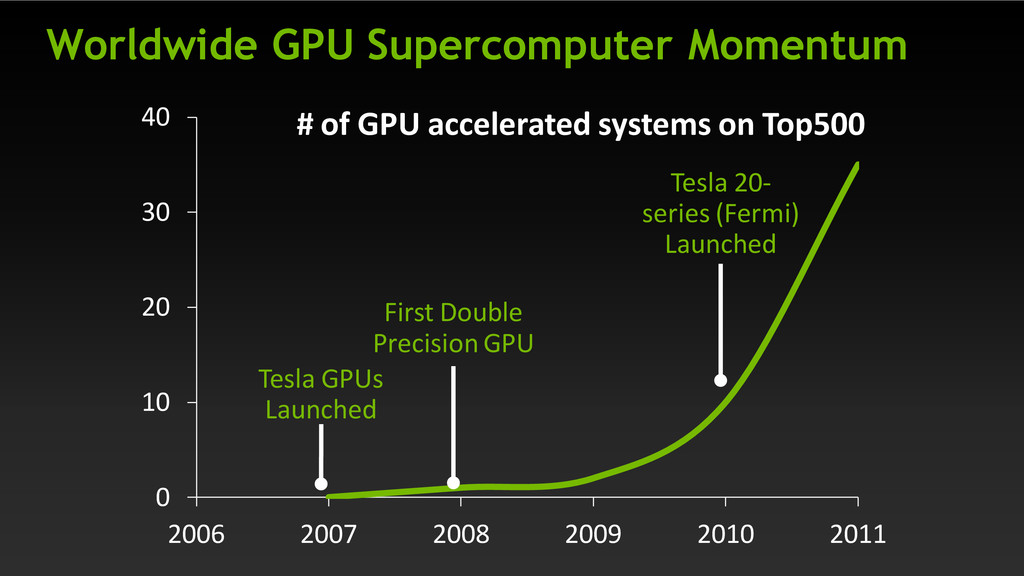
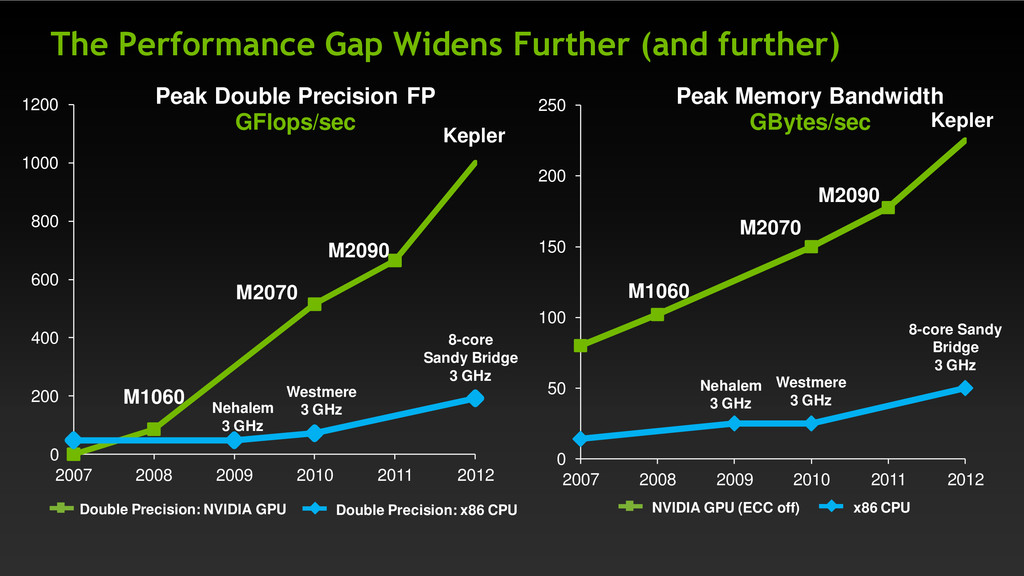
of programming, porting, tuning Breadth of applicability Finer-grain parallel work, more CPU/GPU overlap GPUs will work well on any apps with high parallelism Tighter integration CPUs and GPUs, shared hierarchical memory, system interconnect 16 2 4 6 8 10 12 14 2008 2010 2012 2014 Tesla Fermi Kepler Maxwell Sustained DP GF / W
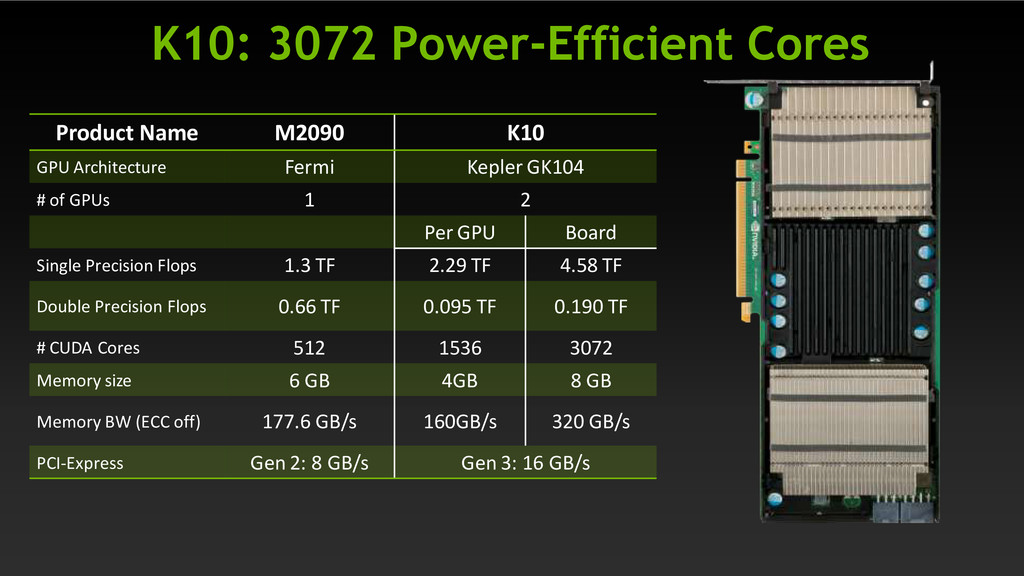
for single precision 2X Perf/W vs. Fermi “Gemini” config (2GPU/ card) 4 GB / GPU, 250W / card Target markets Seismic, Defense, signal and image processing Kepler II 4Q’12 High double precision perf 3X Perf/W vs. Fermi 1 GPU per board Up to 6 GB / GPU @ 225W Target markets Traditional HPC, Finance, Manufacturing, etc.
September 28, 2008: Four Major Challenges Energy and Power challenge Memory and Storage challenge Concurrency and Locality challenge Resiliency challenge Number one issue is power Extrapolations of current architectures and technology indicate over 100MW for an Exaflop! Power also constrains what we can put on a chip Available at www.darpa.mil/ipto/personnel/docs/ExaScale_Study_Initial.pdf
L0 I$ L0 D$ Lane — DFMAs, 20 GFLOPS P P P P P P P P Switch L1$ SM — 8 lanes, 160 GFLOPS 1024 SRAM Banks, 256KB each NI MC MC SM SM SM SM NoC SM LP LP SRA M SRA M SRA M Chip — 128 SMs, 20.48 TFLOPS + 8 Latency Processors GPU Chip 20TF DP 256MB 1.4TB/s DRAM BW 150GB/s Network BW DRAM Stack DRAM Stack DRAM Stack NV Memory Node MCM — 20 TFLOPS + 256 GB Echelon Architecture (1/2)
the future CUDA is the right platform for heterogeneous computing Future Homogeneous Program, Heterogeneous Execution GPUs can take advantage of all types of application parallelism Standard OS & language support for fine-grained parallelism (e.g. C++17) Unified Memory Architecture at GPU, Node, and Cluster levels Continued focus on productivity, performance Continued platform of choice for research and innovation
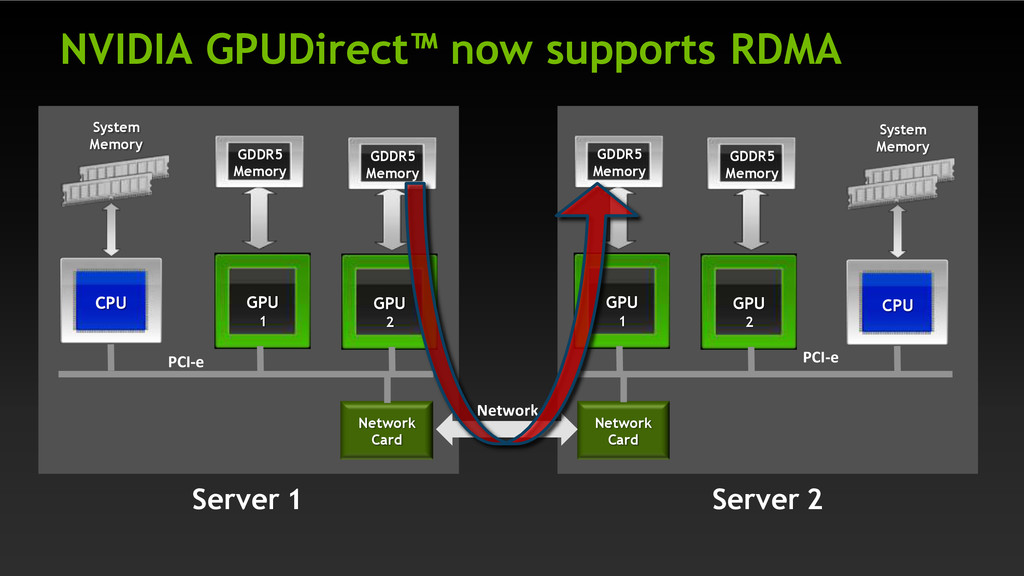
System Memory GDDR5 Memory GDDR5 Memory CPU Network Card Server 1 PCI-e GPU 1 GPU 2 GDDR5 Memory GDDR5 Memory System Memory CPU Network Card Server 2 Network
available with Open source LLVM Compiler SDK includes specification documentation, examples, and verifier Provides ability for anyone to add CUDA to new languages and processors Learn more at http://developer.nvidia.com/cuda-source CUDA C, C++, Fortran LLVM Compiler For CUDA NVIDIA GPUs x86 CPUs New Language Support New Processor Support
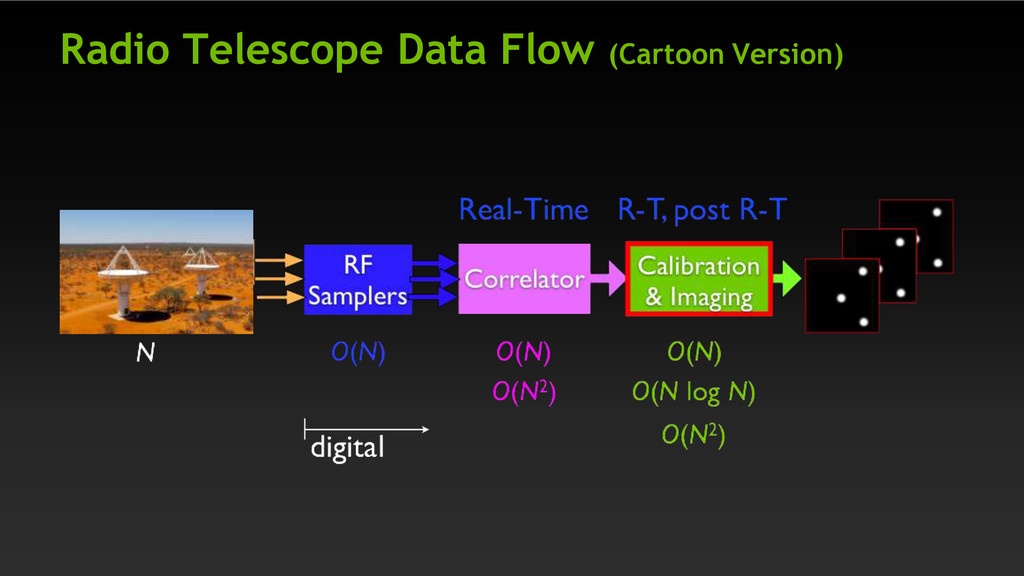
ideal for large antenna counts High performance open-source library, developed by Clark (NVIDIA) * Kepler II estimated performance similar to SGEMM (high % of peak) Calibration and Imaging Gridding - Coordinate mapping of input data to a regular grid Dominant time sink in compute pipeline - exascale required for SKA2 Other image processing steps CUFFT – Highly optimized Fast Fourier Transform library Coordinate transformations natural for a graphics processor Signal Processing For example, Pulsar detection * https://github.com/GPU-correlators/xGPU
astronomy ASKAP Stage 1 – Western Australia LEDA – United States of America LOFAR – Europe MWA – Western Australia PAPER – South Africa LOFAR LEDA MWA ASKAP PAPER
science is here to help is in compute for the long haul (exascale and beyond) Is already a part of the Radio Astronomy ecosystem Contacts Jeremy Purches, Business Development Manager – [email protected] Tim Lanfear, Solution Architect – [email protected] Mike Clark, DevTech Astronomy – [email protected] John Ashley, Solution Architect – [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}