Why, from experience, I believe XA 2PC (2-Phase-Commit) Transactions have too many downsides to warrant using them for their upsides, in most or nearly all situations. Here, I explore the reasons why it is problematic and I then explore some alternative strategies.
Note, to be clear, an XA 2PC transaction is not the same as a [local] ACID transaction, although there is some overlap in concepts and principles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
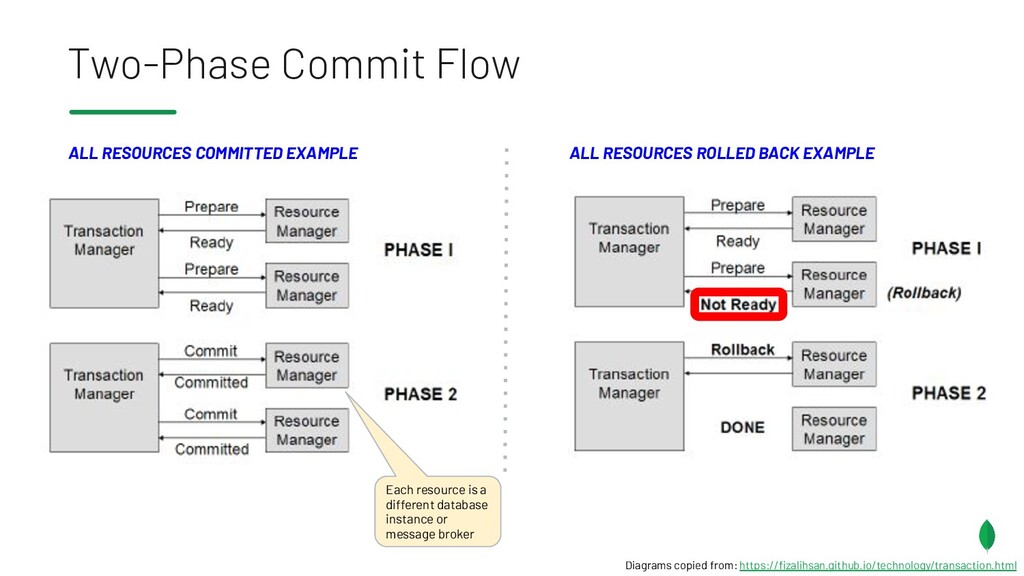{kind=link}
{kind=link}
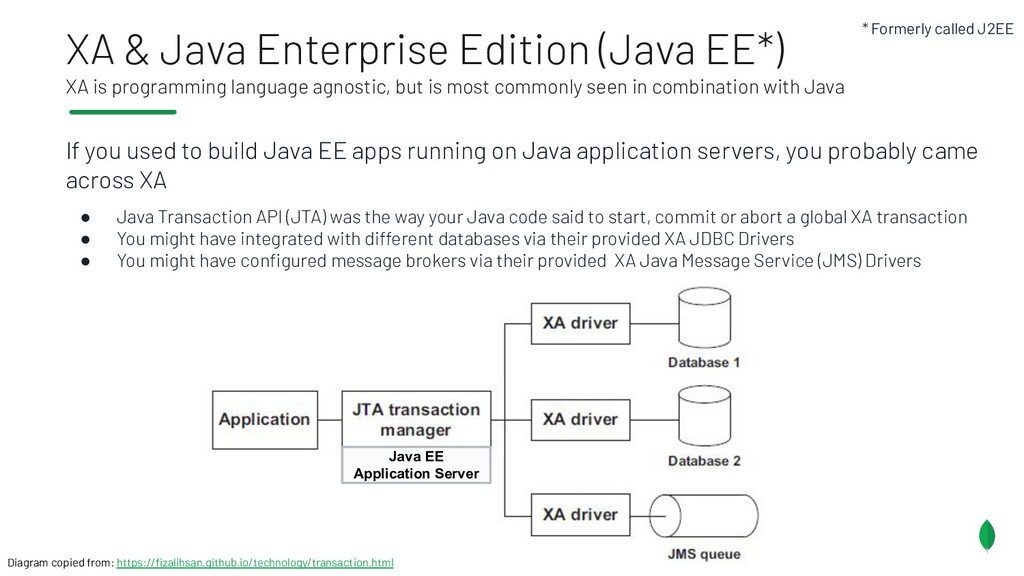{kind=link}
{kind=link}
{kind=link}
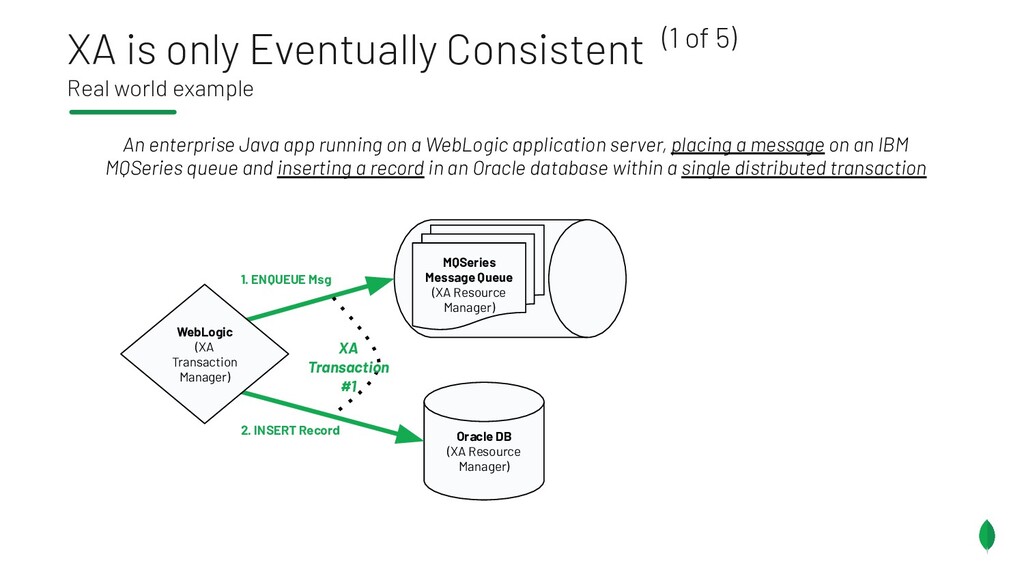{kind=link}
{kind=link}
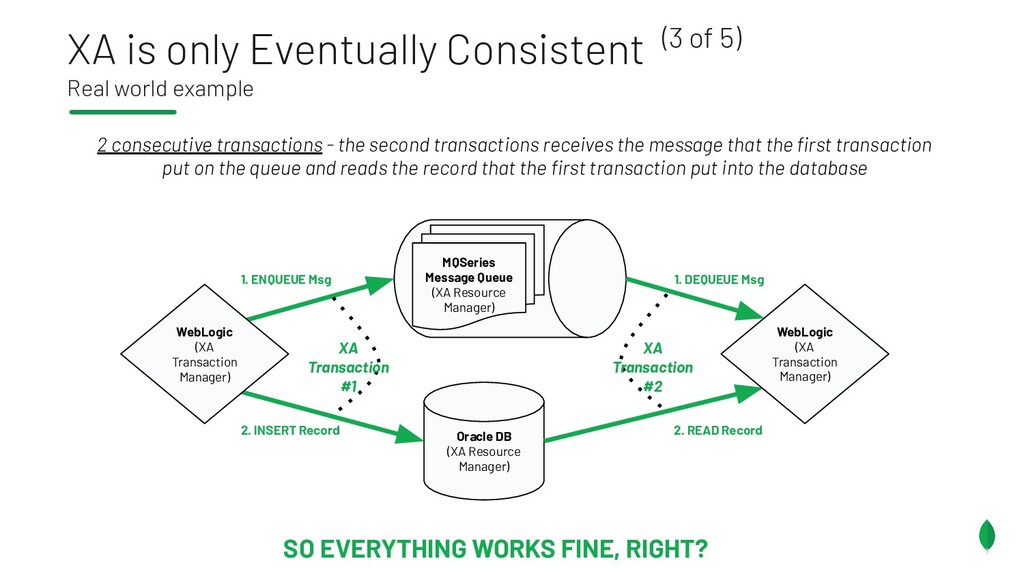{kind=link}
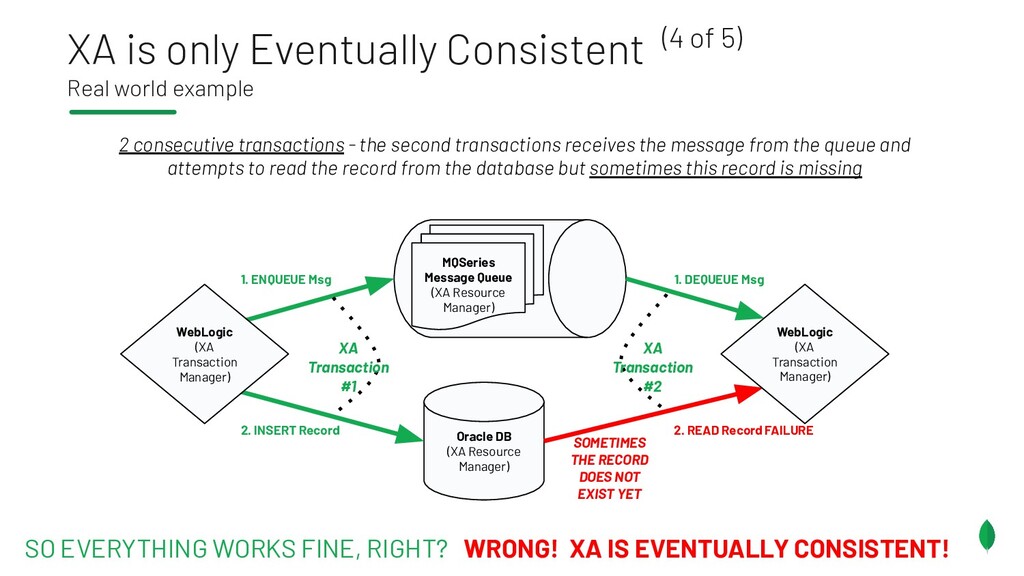{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
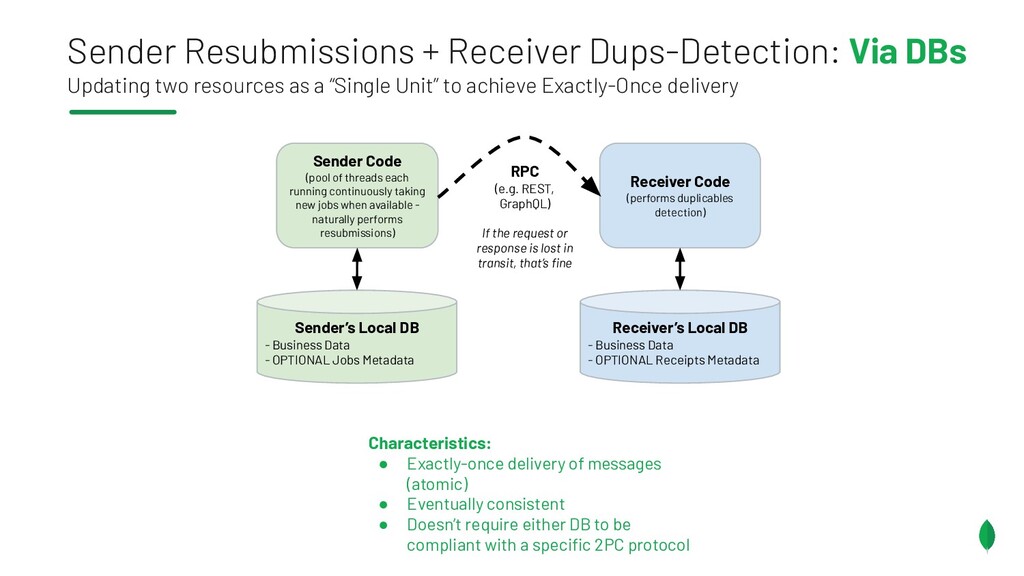{kind=link}
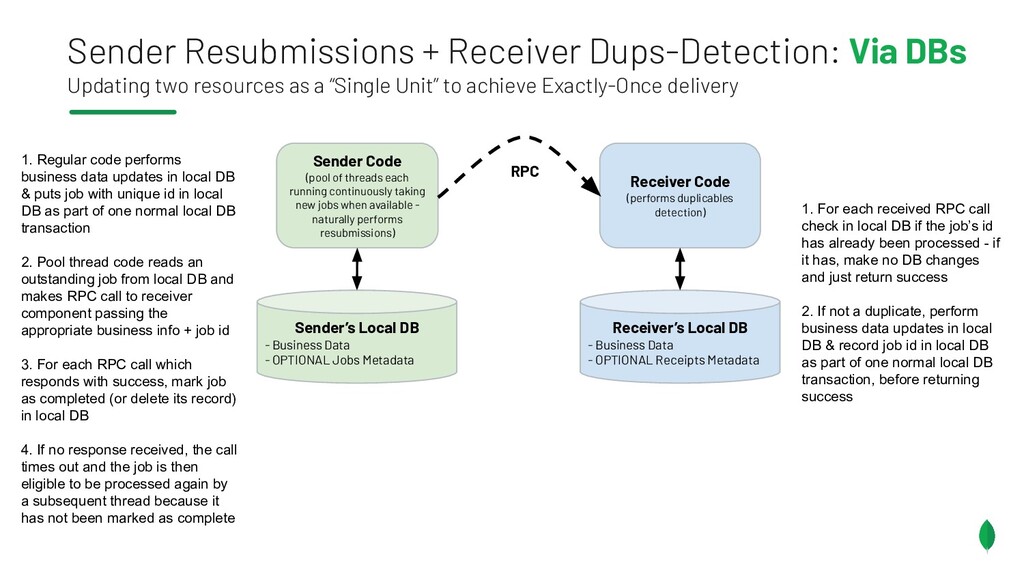{kind=link}
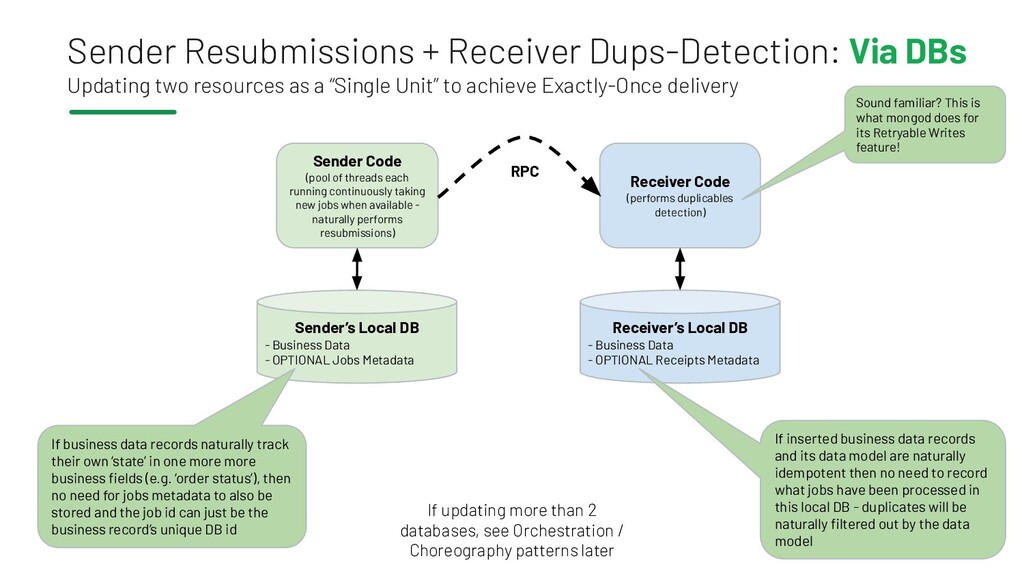{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}