The Six Principles For Resilient Evolvability: Building robust yet flexible shared data applications
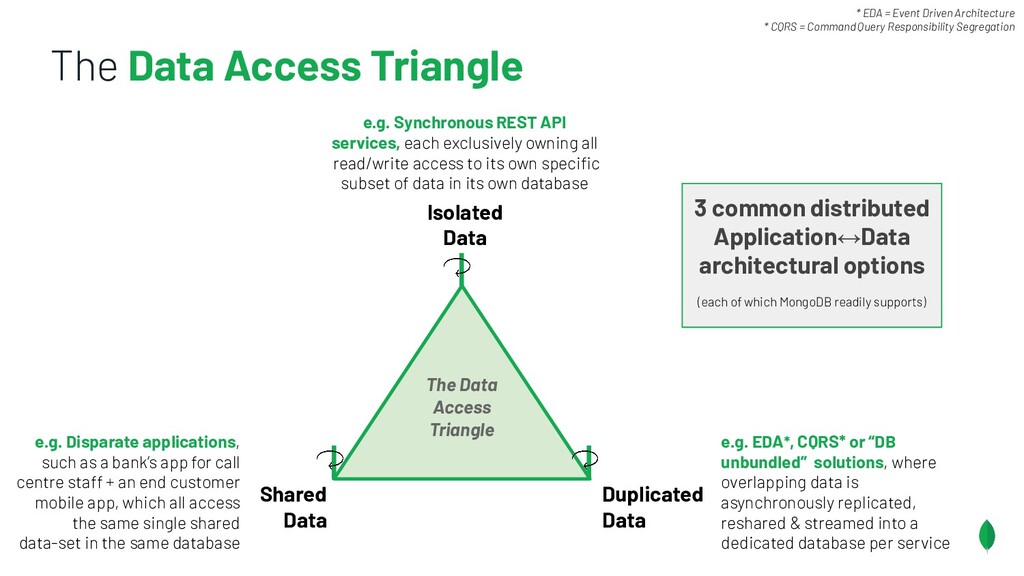
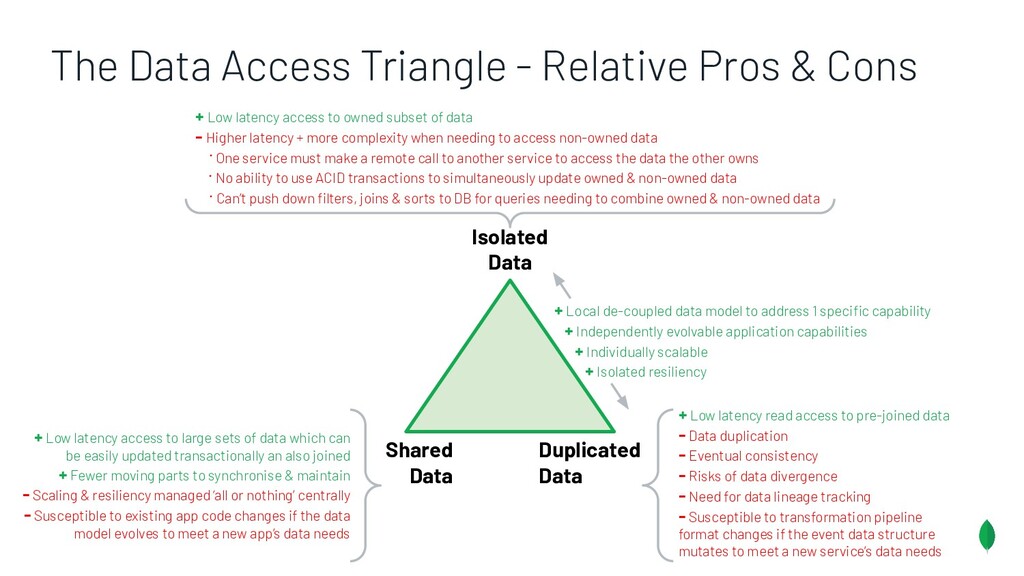
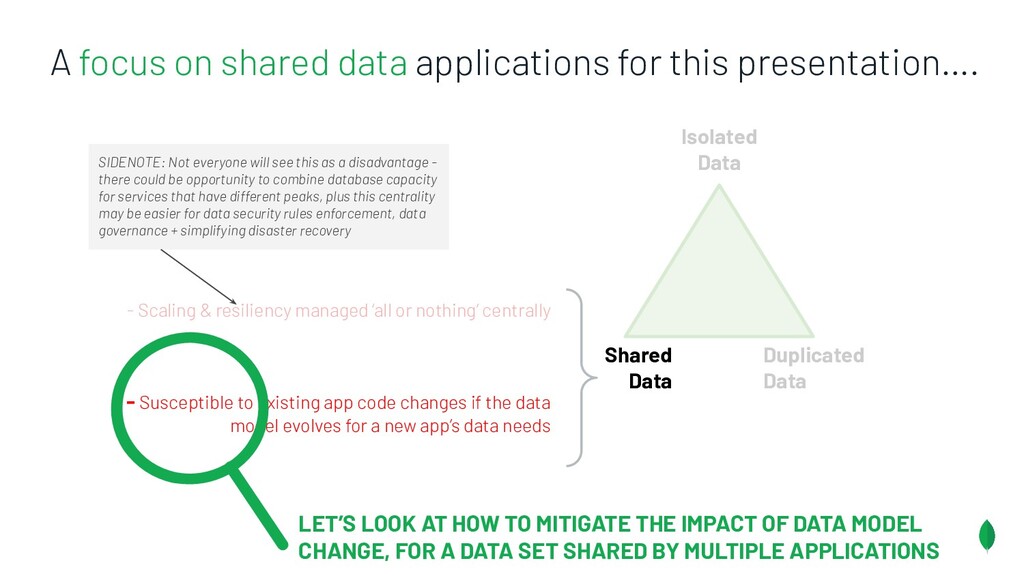
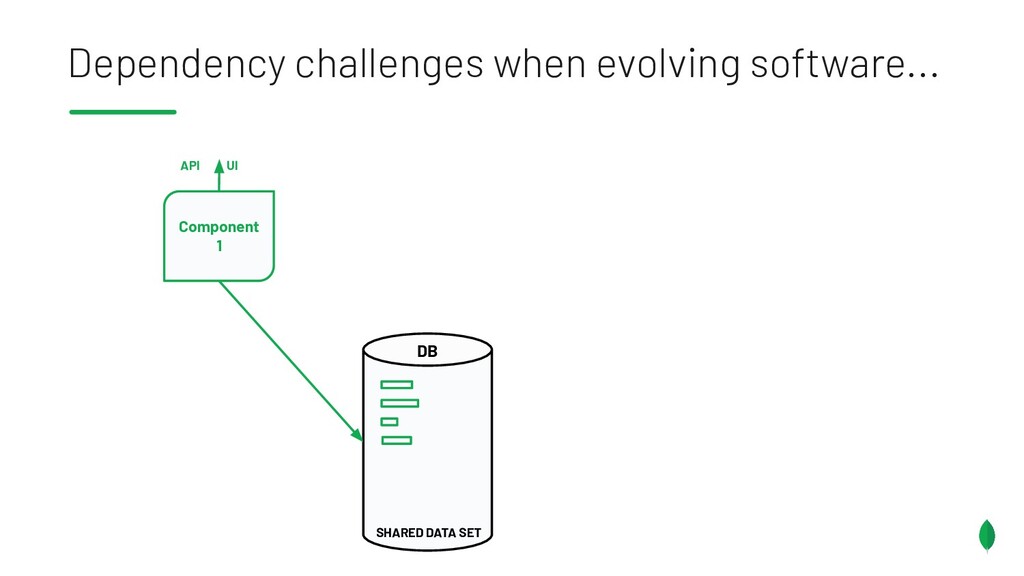
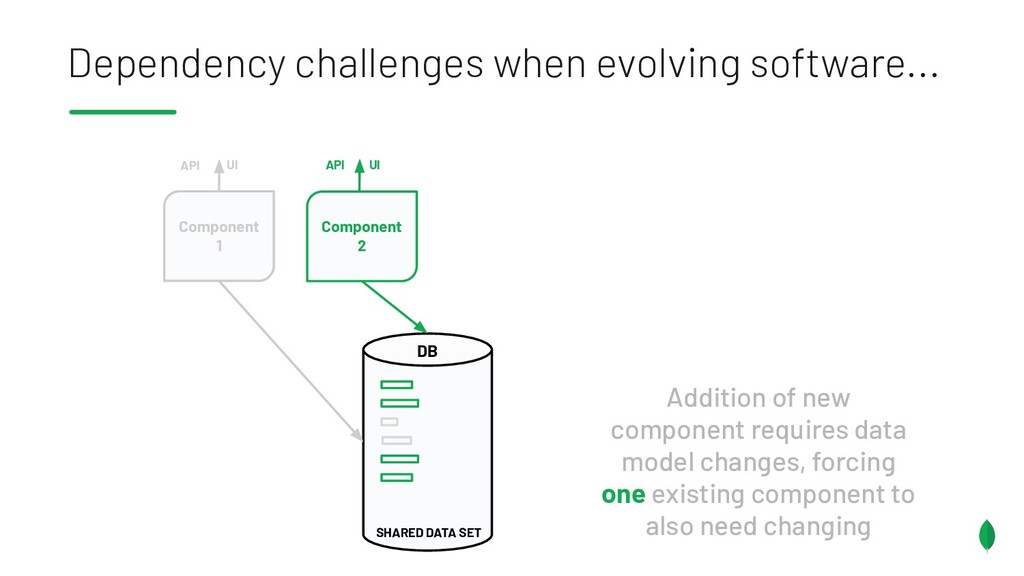
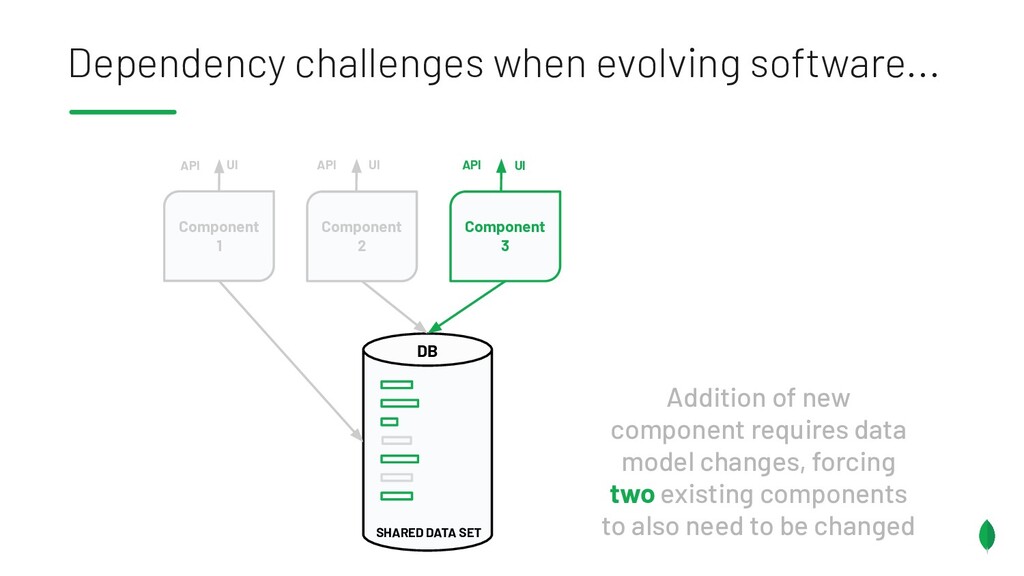
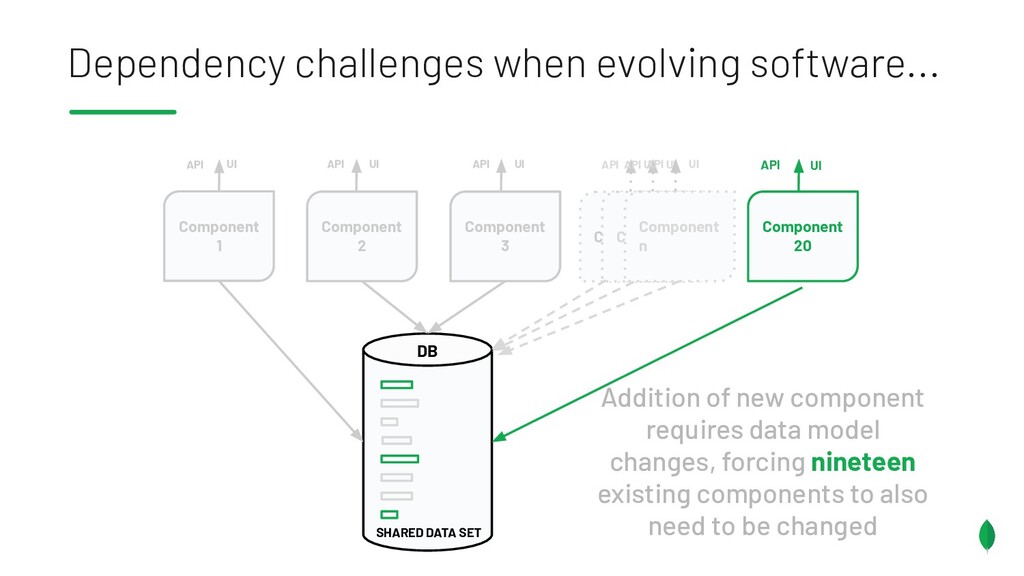
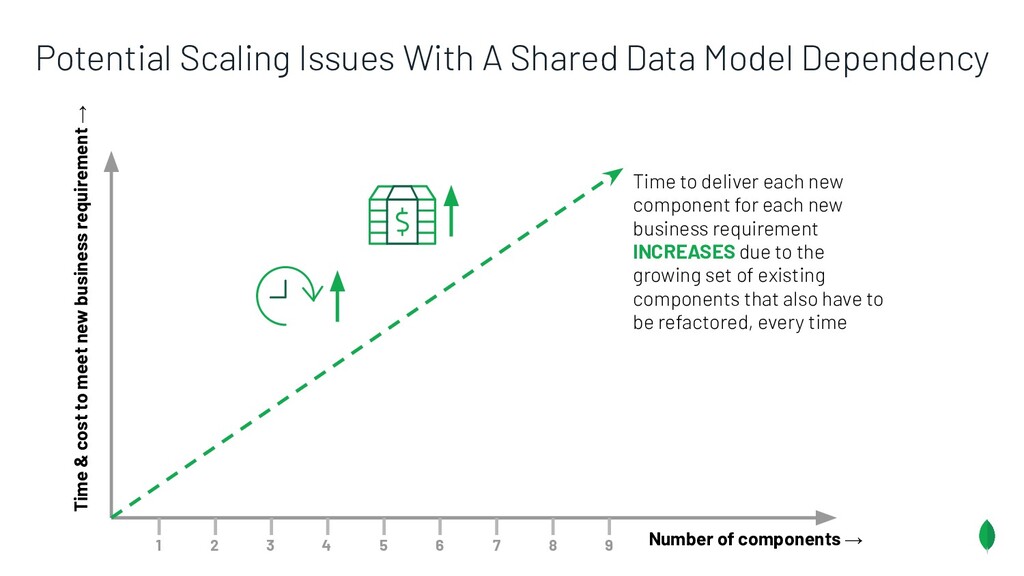
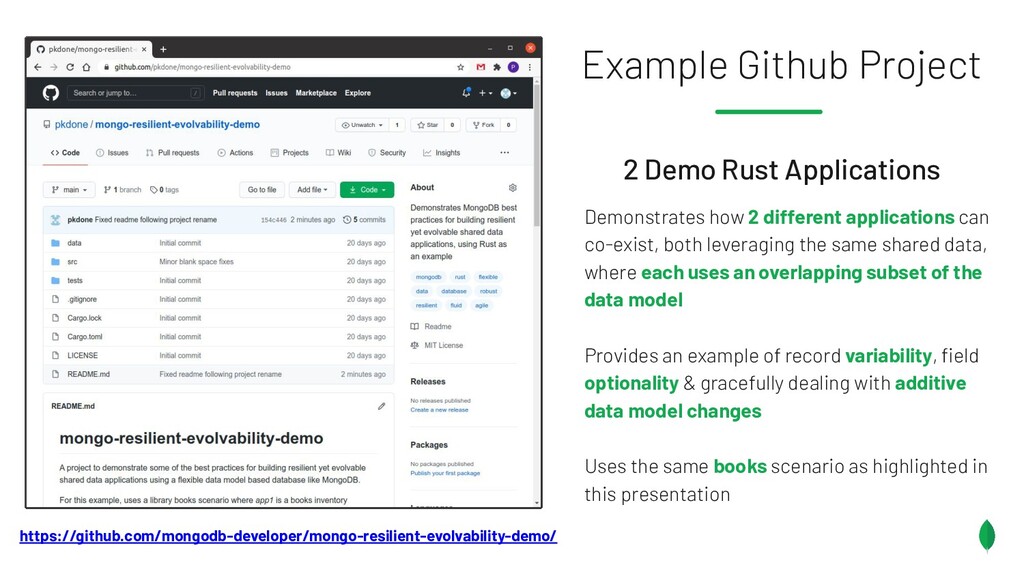
Principles to follow when building applications & services which are on different release trains, but have the overlapping dependencies on a shared data set. Also discusses something coined the Data Access Triangle, including Shared Data, Isolated Data and Duplicated Data, and some of the trade-offs of each. Accompanied by an example application on GitHub: https://github.com/pkdone/mongo-resilient-evolvability-demo
@TheDonester
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Rust structs serialised using Serde #[derive(Serialize, Deserialize)] struct Book {](https://files.speakerdeck.com/presentations/91f089067bfd448a872e00230d40a2b9/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}