Apple Intelligence brings powerful, private, and fast on-device models directly to our users. But what about users on older hardware? And what happens when a task is too complex or the input is too large for the local model's context window? We can't just show an error.
This is where a **Hybrid AI** strategy becomes essential.
In this session, we'll explore how to build a smart, resilient system that gets the best of both worlds: the instant speed of on-device inference and the power of large-scale cloud models. We'll build a practical solution in Swift from the ground up.
You will learn how to:
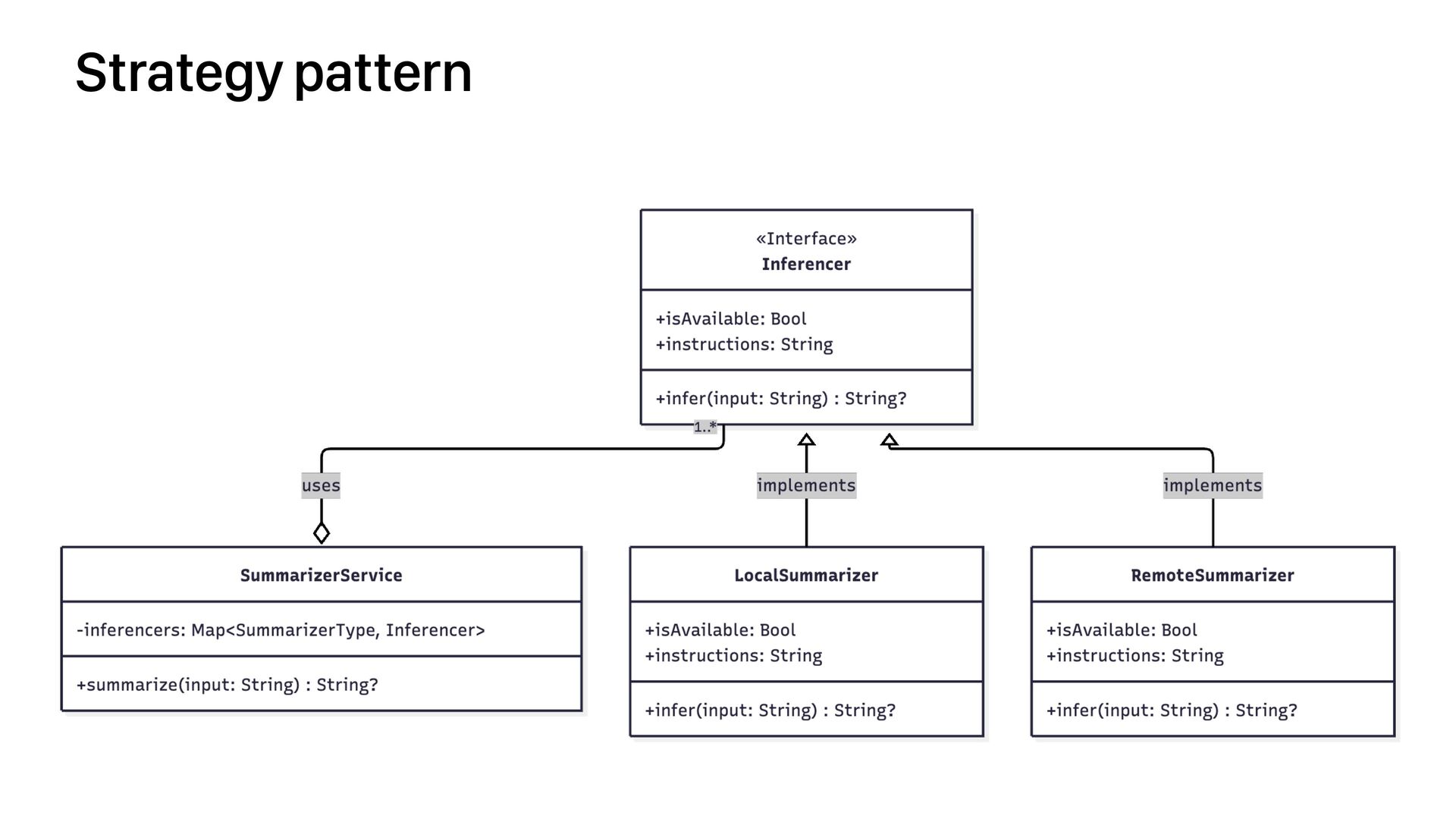
- Create a clean, protocol-oriented architecture to abstract local and remote inference services.
- Use Apple's new `FoundationModels` API to run fast, on-device generation.
- Implement a seamless fallback to a powerful cloud model, like Google's Gemini via Firebase AI.
- Strategically decide *when* to fall back—from simple OS availability checks to handling specific errors like `LMError.contextWindowExceeded`.
By the end of this talk, you'll have a robust pattern for building intelligent features that are fast, capable, and—most importantly—available to *all* your users, not just those on the latest hardware.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}