Ecobox
Home
Blog
About
Tickets
Sessions
Venue & Hotel
Sponsors
POSTGRES OPEN
SEPT 16TH - 18TH ・ DALLAS
UPSERT use cases
Back
Date: Sept. 18, 2015
Time: 13:30 - 14:20
Room: Houston Ballroom B/C
Level: Intermediate
Feedback: Leave feedback
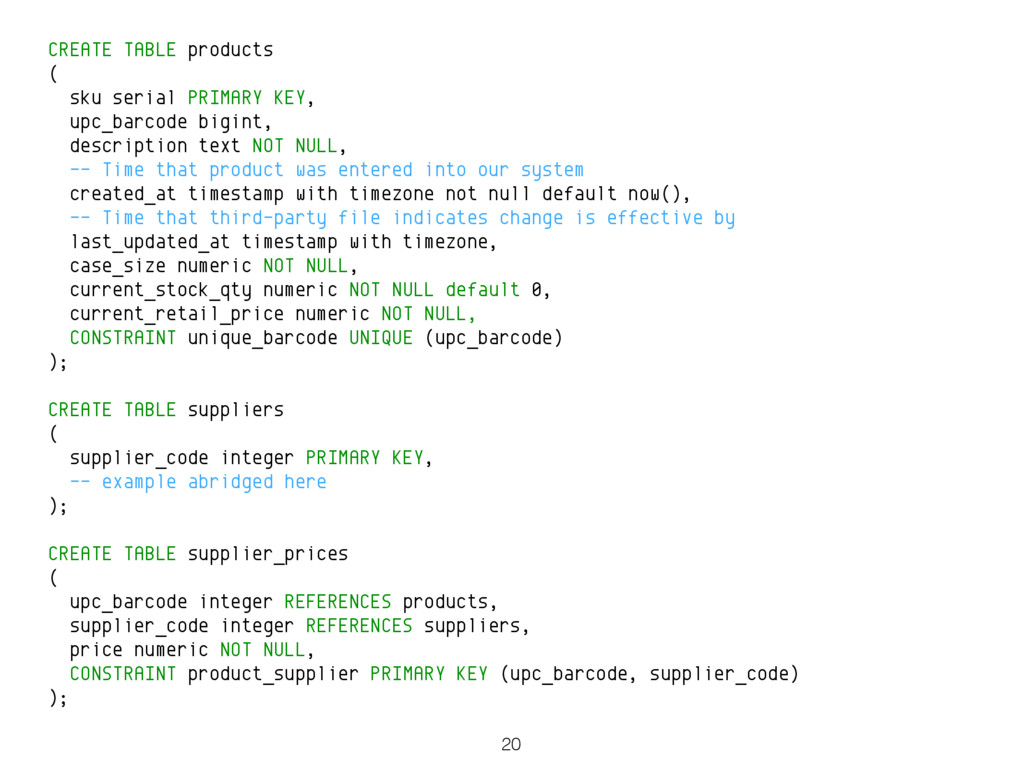
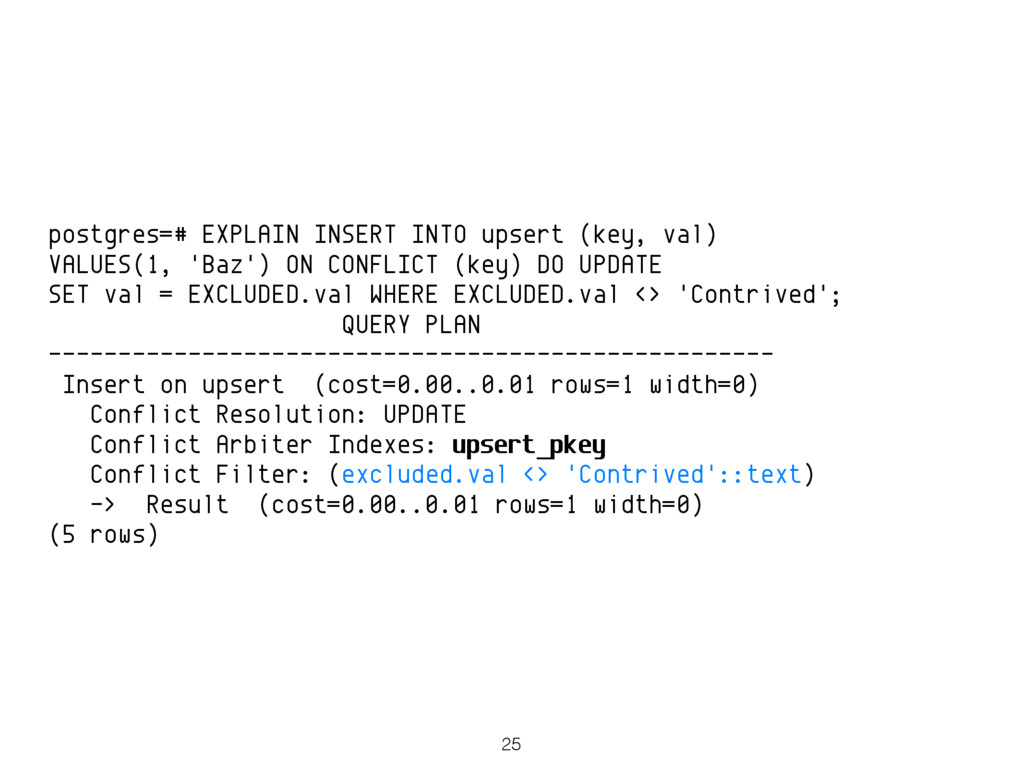
PostgreSQL 9.5 will have support for a feature that is popularly known as "UPSERT" - the ability to either insert or update a row according to whether an existing row with the same key exists. If such a row already exists, the implementation should update it. If not, a new row should be inserted. This is supported by way of a new high level syntax (a clause that extends the INSERT statement) that more or less relieves the application developer from having to give any thought to race conditions. This common operation for client applications is set to become far simpler and far less error-prone than legacy ad-hoc approaches to UPSERT involving subtransactions. Moreover, the new implementation performs much better than those legacy approaches.
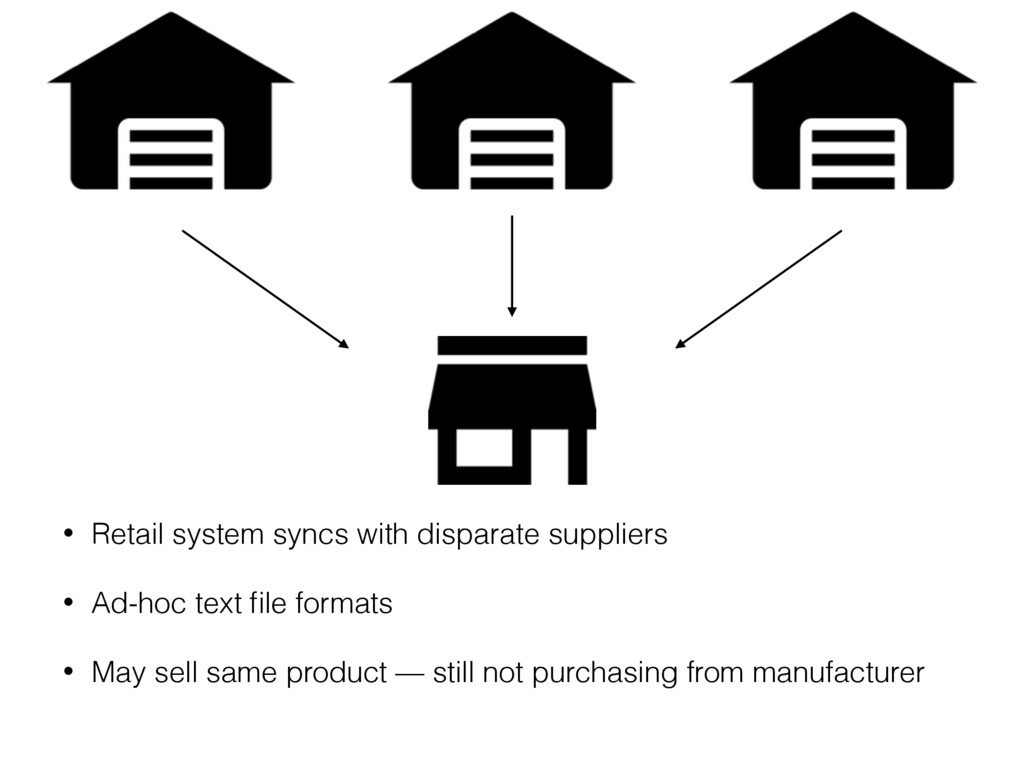
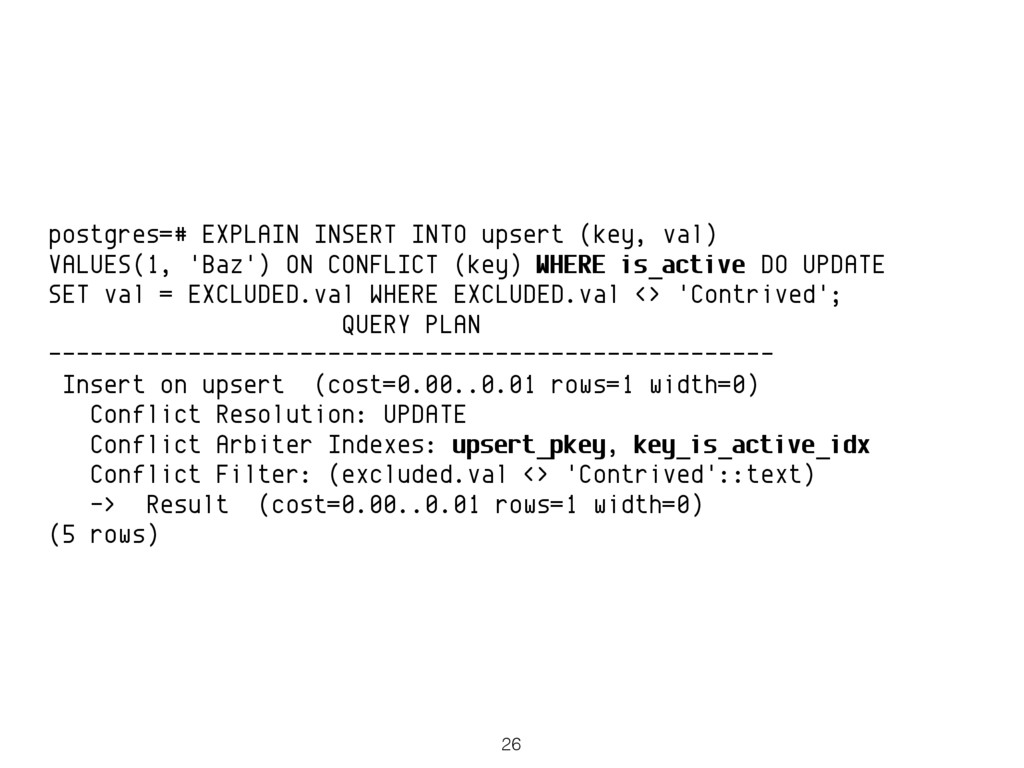
While the feature is most obviously compelling for OLTP and web application use cases, it's also true that the syntax is powerful enough to be very useful in many real world data integration scenarios. The non-standard PostgreSQL syntax offer explicit, fine grained control over where and how to update. For example, an update may not actually affect an existing row due to not satisfying some additional criteria (i.e. due to not passing the ON CONFLICT ... DO UPDATE special, dedicated WHERE clause).
This talk gives an overview of the feature from a high level, and examines these use cases. You will learn how you might want to use the new UPSERT feature in your application beyond the obvious. In passing, there will be brief discussion of why UPSERT's implementation proved to be a hard problem, and, relatedly, why a custom syntax was used instead of the SQL standard's MERGE syntax.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}