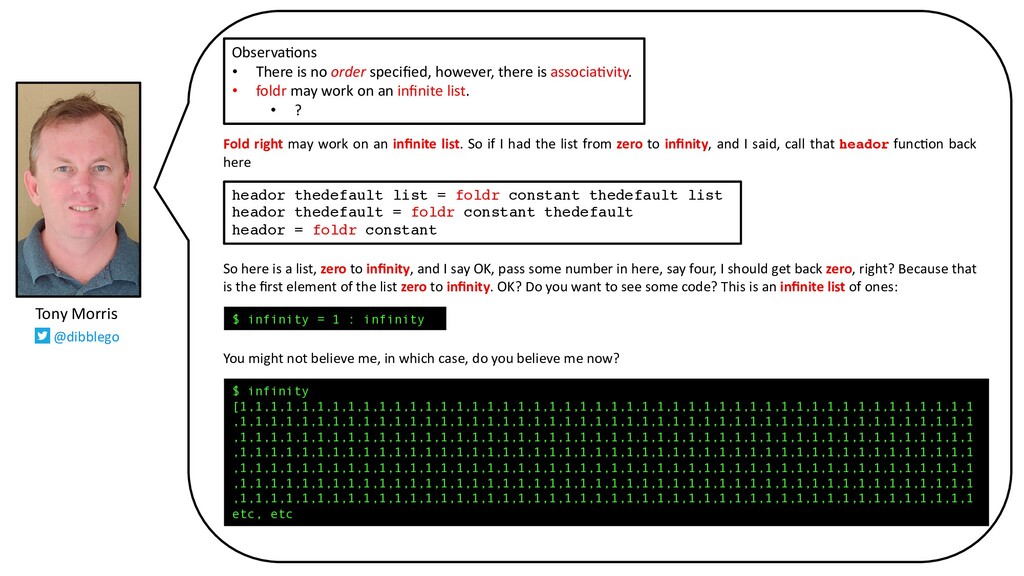
I had the list from zero to infinity, and I said, call that heador func@on back here So here is a list, zero to infinity, and I say OK, pass some number in here, say four, I should get back zero, right? Because that is the first element of the list zero to infinity. OK? Do you want to see some code? This is an infinite list of ones: You might not believe me, in which case, do you believe me now? Observa9ons • There is no order specified, however, there is associa9vity. • foldr may work on an infinite list. • ? Tony Morris @dibblego heador thedefault list = foldr constant thedefault list heador thedefault = foldr constant thedefault heador = foldr constant $ infinity [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 etc, etc $ infinity = 1 : infinity
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![reverse ∷ α → [α] reverse = 𝑓𝑜𝑙𝑑𝑟 𝑠𝑛𝑜𝑐 𝒘𝒉𝒆𝒓𝒆](https://files.speakerdeck.com/presentations/865687cef8aa4d21adb79880c520cb7f/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
: (A, Duration) = { def getTime](https://files.speakerdeck.com/presentations/865687cef8aa4d21adb79880c520cb7f/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(b0: B)(next: (B, A) => B): Seq[B]](https://files.speakerdeck.com/presentations/865687cef8aa4d21adb79880c520cb7f/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![fold λ Haskell> foldl (+) 0 [1,2,3,4] 10 Haskell> take](https://files.speakerdeck.com/presentations/865687cef8aa4d21adb79880c520cb7f/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}