This slide deck is my homage to SICP, the book which first introduced me to the Functional Programming triad of map, filter and fold.
It was during my Computer Science degree that a fellow student gave me a copy of the first edition, not long after the book came out.
I have not yet come across a better introduction to these three functions.
The upcoming slides are closely based on the second edition of the book, a free online copy of which can be found here:
https://mitpress.mit.edu/sites/default/files/sicp/full-text/book/book.html.
Download for original image quality.
Errata:
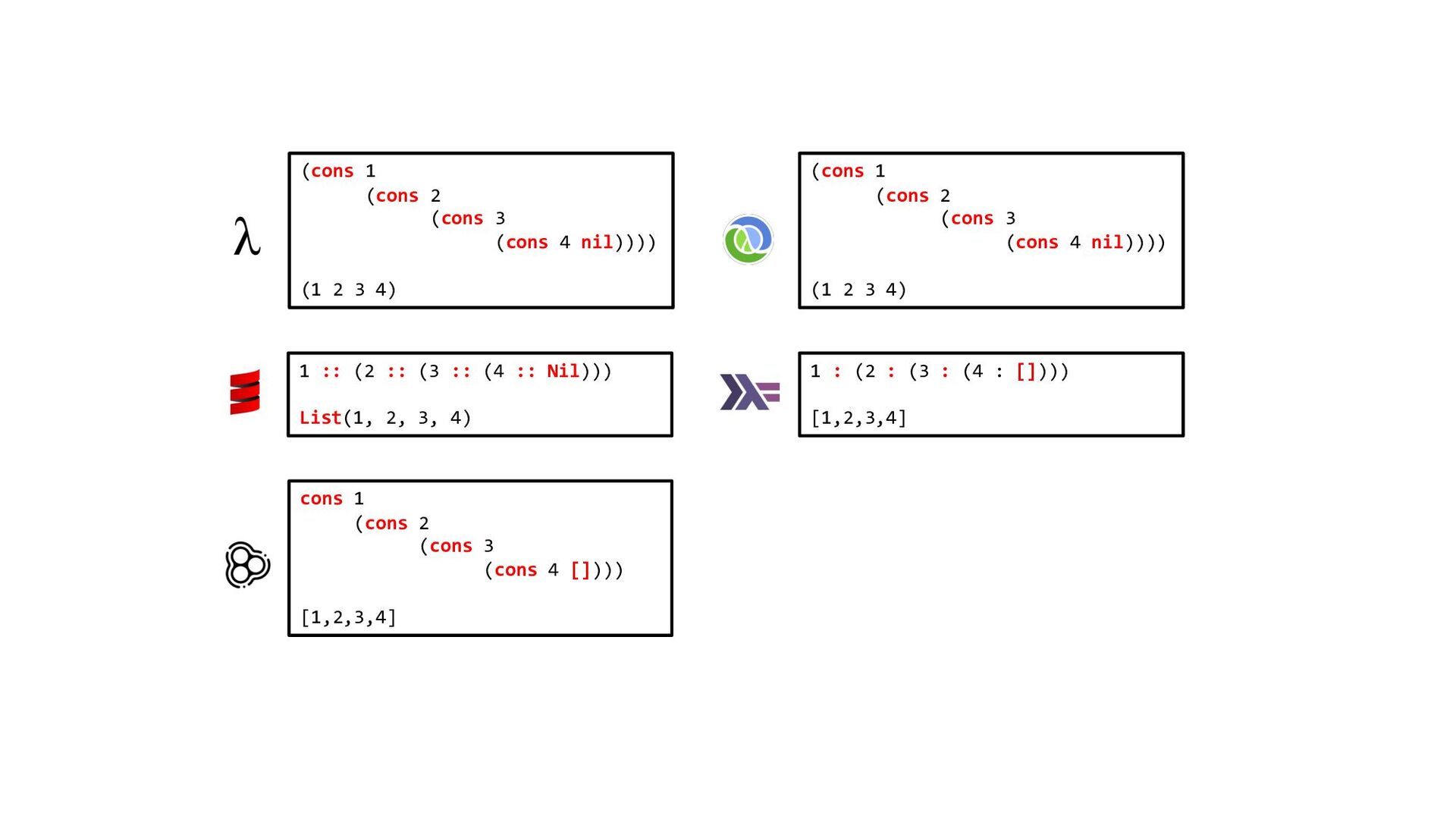
slide 20: the Clojure map function is in fact the Scheme one repeated - see code below for correction.
Scheme code: https://github.com/philipschwarz/the-fp-triad-of-map-filter-and-fold-scheme
Clojure code: https://github.com/philipschwarz/the-fp-triad-of-map-filter-and-fold-clojure
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(defn length [items] (if (empty? items) 0 (+ 1 (length](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_15.jpg){kind=link}
{kind=link}
![(defn append [list1 list2] (if (empty? list1) list2 (cons (first](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![(defn scale-list [items factor] (map #(* % factor) items)) def](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
: List[A] = sequence](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_34.jpg){kind=link}
 => B, initial: B, sequence: List[A]): B](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
: List[A] = tree match case Null =>](https://files.speakerdeck.com/presentations/7e1d52ab4873419da95175c3c66fb056/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}