new Functional Programming language wholly based on a talk by Paul Chiusano RESISTANCE IS FUTILE YOU WILL BE ASSIMILATED Paul Chiusano @pchiusano the joys of an always live, never broken codebase slides by @philip_schwarz https://www.slideshare.net/pjschwarz
the goal, or the guiding philosophy behind unison is we want to try to make programming more fun, simpler, easier, eliminating needless complexity, and do that by being willing to rethink pretty much anything and everything about how programming currently works. So really just be willing to start from first principles and rethink things and say ‘hey, how do we want this to work?’. And that’s been kind of the guiding philosophy behind the development of unison, but early on in the development of unison we sort of hit on this one core idea, core technical idea, which I am going to spend the next two slides trying to explain clearly, and this one core idea ends up making so many other things much simpler. So, these next two slides are like the most important slides of the talk. Unison: the joy of an always live, never broken codebase Unison, and why the codebase of the future is a purely functional data structure Functional TV channel
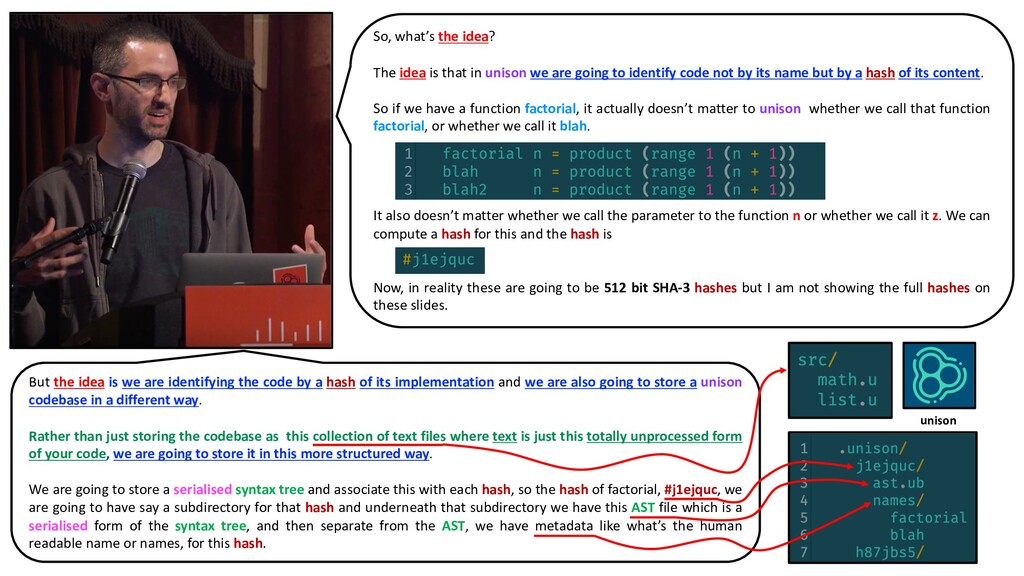
a hash of its implementation and we are also going to store a unison codebase in a different way. Rather than just storing the codebase as this collection of text files where text is just this totally unprocessed form of your code, we are going to store it in this more structured way. We are going to store a serialised syntax tree and associate this with each hash, so the hash of factorial, #j1ejquc, we are going to have say a subdirectory for that hash and underneath that subdirectory we have this AST file which is a serialised form of the syntax tree, and then separate from the AST, we have metadata like what’s the human readable name or names, for this hash. So, what’s the idea? The idea is that in unison we are going to identify code not by its name but by a hash of its content. So if we have a function factorial, it actually doesn’t matter to unison whether we call that function factorial, or whether we call it blah. It also doesn’t matter whether we call the parameter to the function n or whether we call it z. We can compute a hash for this and the hash is Now, in reality these are going to be 512 bit SHA-3 hashes but I am not showing the full hashes on these slides. unison
serialised syntax tree, so this is also important. If we look at factorial, it is defined in terms of product, range and plus. And so what is actually stored in the syntax tree is not those names but the hashes of those definitions. And then furthermore, when we compute the hash of factorial we even normalise away what the local variables are called, like the parameter to the function and so forth, so those don’t impact the hash. And so, bottom line, unlike names, a unison hash uniquely identifies the exact implementation of a definition and pins down all its dependencies. So it’s an unambiguous way of referring to a piece of code that never changes. OK, so is that pretty clear? .unison/ j1ejquc/ ast.ub names/ factorial blah 8h7jbs5/ unison Paul Chiusano @pchiusano
as = foldl (acc a -> a * acc) 1 as factorial : Nat -> Nat factorial n = product (range 1 (n + 1)) > factorial 4 I found and typechecked these definitions in ~/dev/unison/factorial.u. If you do an `add` or `update` , here's how your codebase would change: ⍟ These new definitions are ok to `add`: factorial : .base.Nat -> .base.Nat product : [.base.Nat] -> .base.Nat Now evaluating any watch expressions (lines starting with `>`)... 10 | > factorial 4 ⧩ 24 > > add ⍟ I've added these definitions: factorial : .base.Nat -> .base.Nat product : [.base.Nat] -> .base.Nat > > view product product : [.base.Nat] -> .base.Nat product as = use .base.Nat * .base.List.foldl (acc a -> a * acc) 1 as > Let’s fire up ucm, the unison codebase manager. ~/dev/unison--> ucm _____ _ | | |___|_|___ ___ ___ | | | | |_ -| . | | |_____|_|_|_|___|___|_|_| Welcome to Unison! I'm currently watching for changes to .u files under ~/dev/unison Type help to get help. .> Now let’s edit new file factorial.u and write in it the factorial function and the product function it depends on. The instant we save the file, ucm tells us it has found the factorial and product functions and what their signatures are and that they are ok to add to the codebase. At the bottom of the file we write a watch expression (a line starting with >) that uses our new functions to compute the factorial of 4. When ucm reaches our watch expression it tells us what line number it is on, evaluates the expression, and tells us what its value is, i.e. 24. Let’s go ahead and tell ucm to add our functions to the codebase, which it does. 1 2 3 > view factorial factorial : .base.Nat -> .base.Nat factorial n = use .base.Nat + product (.base.List.range 1 (n + 1)) > 3 Now that ucm has added our functions to the codebase we can ask it to view the functions. 4 6 5
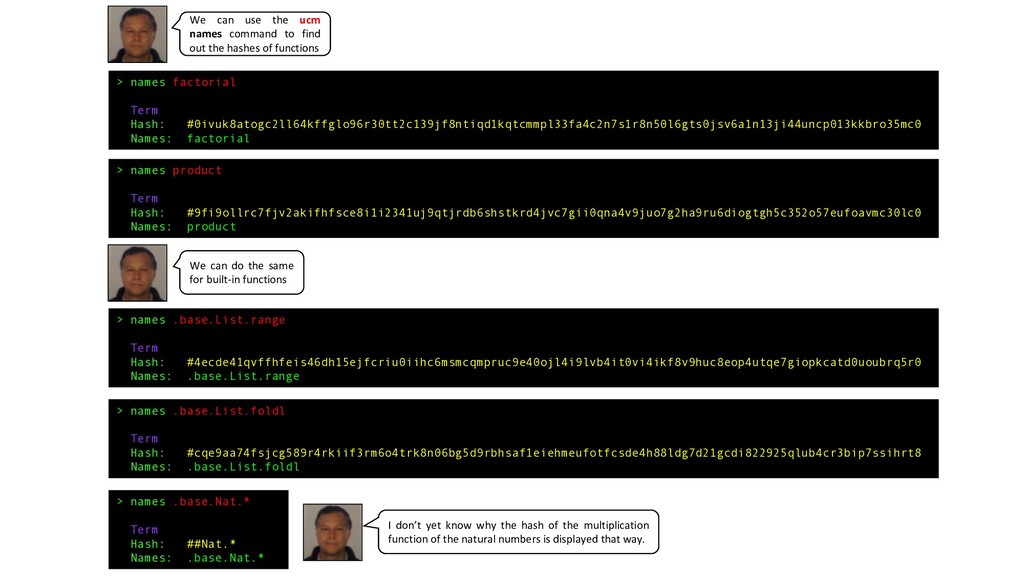
product Term Hash: #9fi9ollrc7fjv2akifhfsce8i1i2341uj9qtjrdb6shstkrd4jvc7gii0qna4v9juo7g2ha9ru6diogtgh5c352o57eufoavmc30lc0 Names: product > names .base.List.range Term Hash: #4ecde41qvffhfeis46dh15ejfcriu0iihc6msmcqmpruc9e40ojl4i9lvb4it0vi4ikf8v9huc8eop4utqe7giopkcatd0uoubrq5r0 Names: .base.List.range > names .base.List.foldl Term Hash: #cqe9aa74fsjcg589r4rkiif3rm6o4trk8n06bg5d9rbhsaf1eiehmeufotfcsde4h88ldg7d21gcdi822925qlub4cr3bip7ssihrt8 Names: .base.List.foldl > names .base.Nat.* Term Hash: ##Nat.* Names: .base.Nat.* We can use the ucm names command to find out the hashes of functions We can do the same for built-in functions I don’t yet know why the hash of the multiplication function of the natural numbers is displayed that way.
am going to spend the rest of this talk going through them and demonstrating how they work in the current version of unison. We get this nice story for doing codebase management. We don’t have builds anymore. You are never waiting for your codebase to compile. We can do renaming without breaking anything. We can even cache the result of tests so we don’t have to keep running the same tests over and over again. And then we also get this nice story for doing refactorings and making changes to our codebase without ever breaking anything. Benefits: • No builds, easy renames, test caching • An always live (never broken) codebase, even mid-refactoring Our codebase is always going to be in a working state. It is never going to be broken, in a state in which we can’t run it. Even when we are in the middle of a refactoring. There are also all these other benefits…, which I am not going to talk about today which are very nice and which kind of emerge from this core idea. I gave a talk at strangeloop a couple of months ago that kind of talked through some of these if you are interested, but I am just going to be focusing on these two for most of this talk. unison test cache always live codebase
are storing the names as separate metadata and we are identifying code by the hash it is pretty easy to swap out that metadata with something else. If I want to rename factorial to transmogrify, all I need to do is swap out that metadata of factorial and replace it with transmogrify. And I am just updating that data in one place. To do this rename I am not modifying a whole bunch of text files and generating a huge diff. I am really just making that change in one place and what is very important is that this rename doesn’t break anyone. It’s not like the refactoring, the renaming that the IDE can do, but then [with that,] if you are a library author and you publish a library and then you rename some of the definitions that’s going to break all your downstream library users. Renames in unison don’t break anyone because all the references to definitions, like factorial, are not by name, they are references by hash. unison
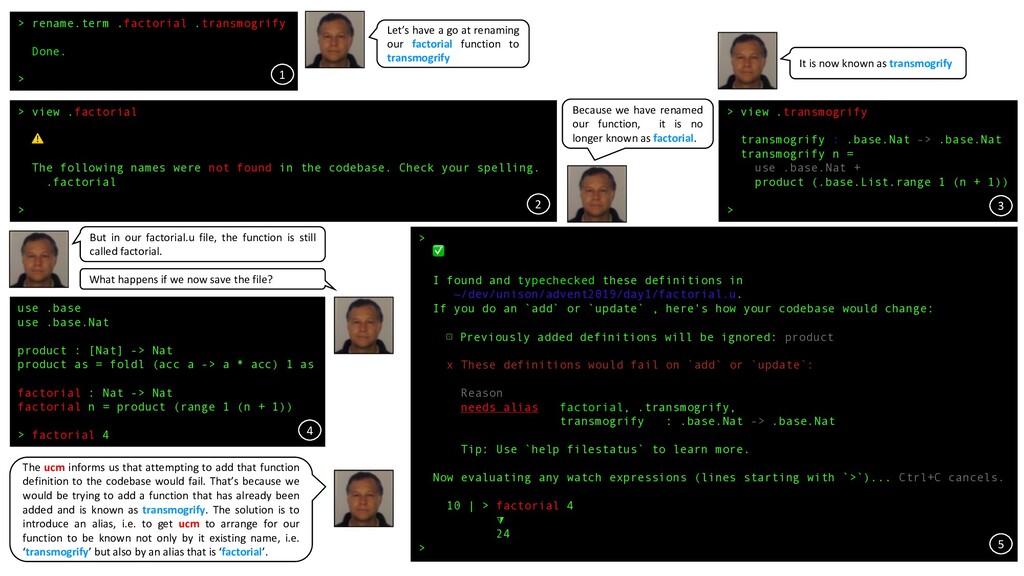
at renaming our factorial function to transmogrify > view .factorial ⚠ The following names were not found in the codebase. Check your spelling. .factorial > Because we have renamed our function, it is no longer known as factorial. 5 2 3 4 1 > ✅ I found and typechecked these definitions in ~/dev/unison/advent2019/day1/factorial.u. If you do an `add` or `update` , here's how your codebase would change: ⊡ Previously added definitions will be ignored: product x These definitions would fail on `add` or `update`: Reason needs alias factorial, .transmogrify, transmogrify : .base.Nat -> .base.Nat Tip: Use `help filestatus` to learn more. Now evaluating any watch expressions (lines starting with `>`)... Ctrl+C cancels. 10 | > factorial 4 ⧩ 24 > > view .transmogrify transmogrify : .base.Nat -> .base.Nat transmogrify n = use .base.Nat + product (.base.List.range 1 (n + 1)) > It is now known as transmogrify 3 use .base use .base.Nat product : [Nat] -> Nat product as = foldl (acc a -> a * acc) 1 as factorial : Nat -> Nat factorial n = product (range 1 (n + 1)) > factorial 4 But in our factorial.u file, the function is still called factorial. What happens if we now save the file? The ucm informs us that attempting to add that function definition to the codebase would fail. That’s because we would be trying to add a function that has already been added and is known as transmogrify. The solution is to introduce an alias, i.e. to get ucm to arrange for our function to be known not only by it existing name, i.e. ‘transmogrify’ but also by an alias that is ‘factorial’. 5 4
I want to show you what happens if, following this renaming of our function from factorial to transmogrify, I ask ucm to provide me with the code for transmogrify. > edit transmogrify ☝ I added these definitions to the top of /Users/philipschwarz/dev/unison/factorial.u transmogrify : .base.Nat -> .base.Nat transmogrify n = use .base.Nat + product (.base.List.range 1 (n + 1)) You can edit them there, then do `update` to replace the definitions currently in this namespace. > transmogrify : .base.Nat -> .base.Nat transmogrify n = use .base.Nat + product (.base.List.range 1 (n + 1)) ---- Anything below this line is ignored by Unison. use .base use .base.Nat product : [Nat] -> Nat product as = foldl (acc a -> a * acc) 1 as factorial : Nat -> Nat factorial n = product (range 1 (n + 1)) > factorial 4 The ucm goes to the unison file we last edited, i.e. factorial.u, adds the code for transmogrify at the top of the file, and comments out everything that was already in the file, i.e. the code for product and factorial, by adding a marker line above it. Here is what the contents of factorial.u look as a result of the edit. Now let’s deal with that alias we wanted to introduce. > names .factorial Term Hash: #0ivuk8atogc2ll64kffglo96r30tt2c139jf8ntiqd1kqtcmmpl33fa4c2n7s1r8n50l6gts0jsv6a1n13ji44uncp013kkbro35mc0 Names: .factorial .transmogrify > Because we have introduced the factorial alias, our function is now known as both transmogrify and factorial. Its hash has remained the same. 1 2 4 3
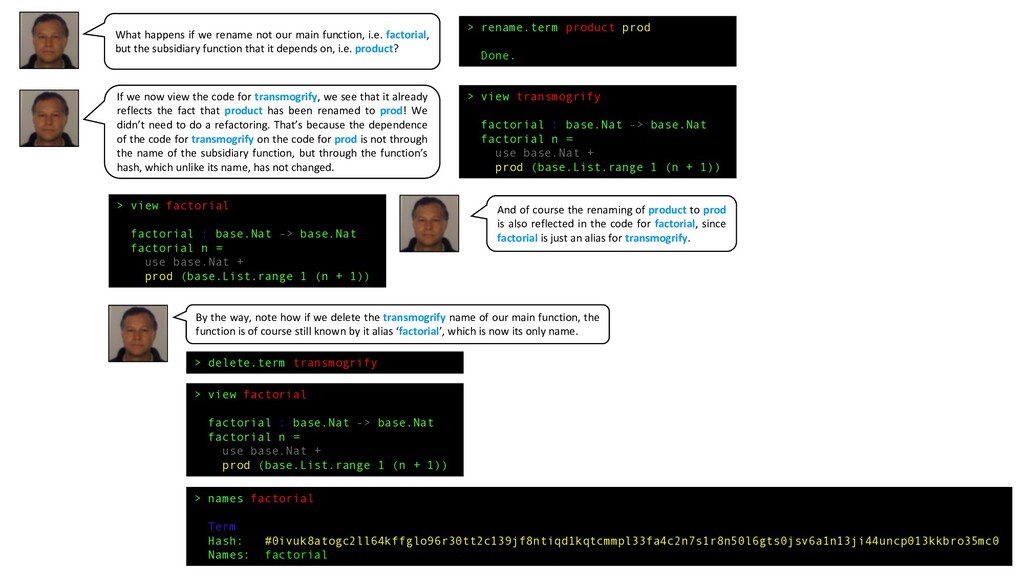
base.Nat -> base.Nat factorial n = use base.Nat + prod (base.List.range 1 (n + 1)) > view transmogrify factorial : base.Nat -> base.Nat factorial n = use base.Nat + prod (base.List.range 1 (n + 1)) > delete.term transmogrify What happens if we rename not our main function, i.e. factorial, but the subsidiary function that it depends on, i.e. product? If we now view the code for transmogrify, we see that it already reflects the fact that product has been renamed to prod! We didn’t need to do a refactoring. That’s because the dependence of the code for transmogrify on the code for prod is not through the name of the subsidiary function, but through the function’s hash, which unlike its name, has not changed. And of course the renaming of product to prod is also reflected in the code for factorial, since factorial is just an alias for transmogrify. By the way, note how if we delete the transmogrify name of our main function, the function is of course still known by it alias ‘factorial’, which is now its only name. > view factorial factorial : base.Nat -> base.Nat factorial n = use base.Nat + prod (base.List.range 1 (n + 1)) > names factorial Term Hash: #0ivuk8atogc2ll64kffglo96r30tt2c139jf8ntiqd1kqtcmmpl33fa4c2n7s1r8n50l6gts0jsv6a1n13ji44uncp013kkbro35mc0 Names: factorial
nice. We also don’t have builds anymore. When we go to write new code that depends on a definition like factorial that we have already written, well, once factorial has been parsed and type-checked and added to the unison codebase, it never changes and we never need to parse or type-check it again, we can just look up, hey, what is the type of factorial? The way that we can do that is again associated with the hash for factorial. We store the syntax tree, but also, hey, what was the type, after type checking this hash? No Builds And so when we are writing code, unison really is only ever having to type check the code that we are actively editing at that moment, it is never having to do a full rebuild of all the code or anything like that. And also what is important is that once anyone has written a definition and added it to the codebase, no one else who gets that code needs to parse or type-check that again. So this is not just like a compilation cache that is local to your IDE, it is actually part of the unison codebase. .unison/ j1ejquc/ ast.ub type.ub names/ factorial blah 8h7jbs5/ unison stores not only the syntax tree for the function with a given hash, but also its type once anyone has written a definition and added it to the codebase, no one else who gets that code needs to build it! unison
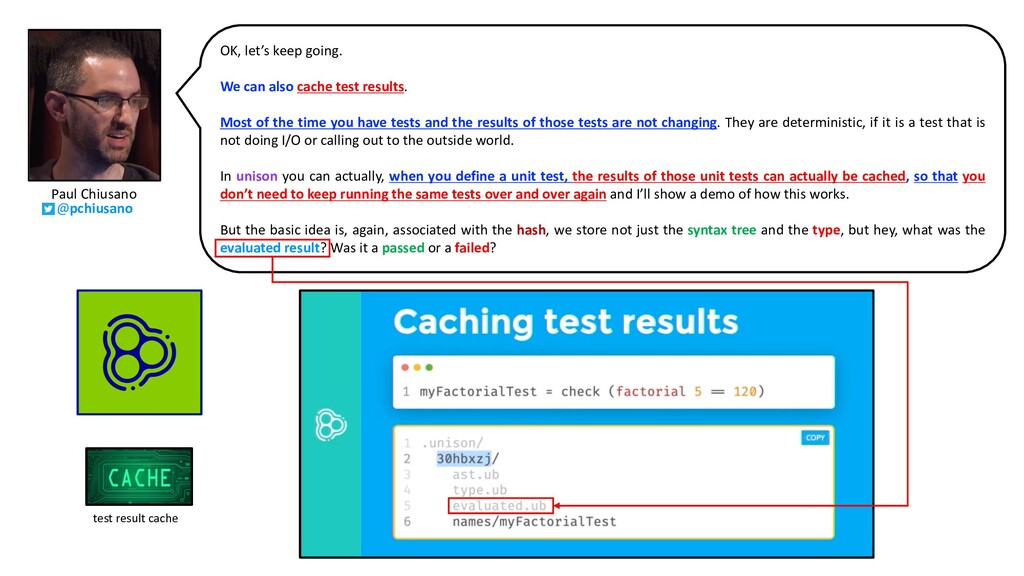
Most of the time you have tests and the results of those tests are not changing. They are deterministic, if it is a test that is not doing I/O or calling out to the outside world. In unison you can actually, when you define a unit test, the results of those unit tests can actually be cached, so that you don’t need to keep running the same tests over and over again and I’ll show a demo of how this works. But the basic idea is, again, associated with the hash, we store not just the syntax tree and the type, but hey, what was the evaluated result? Was it a passed or a failed? test result cache Paul Chiusano @pchiusano
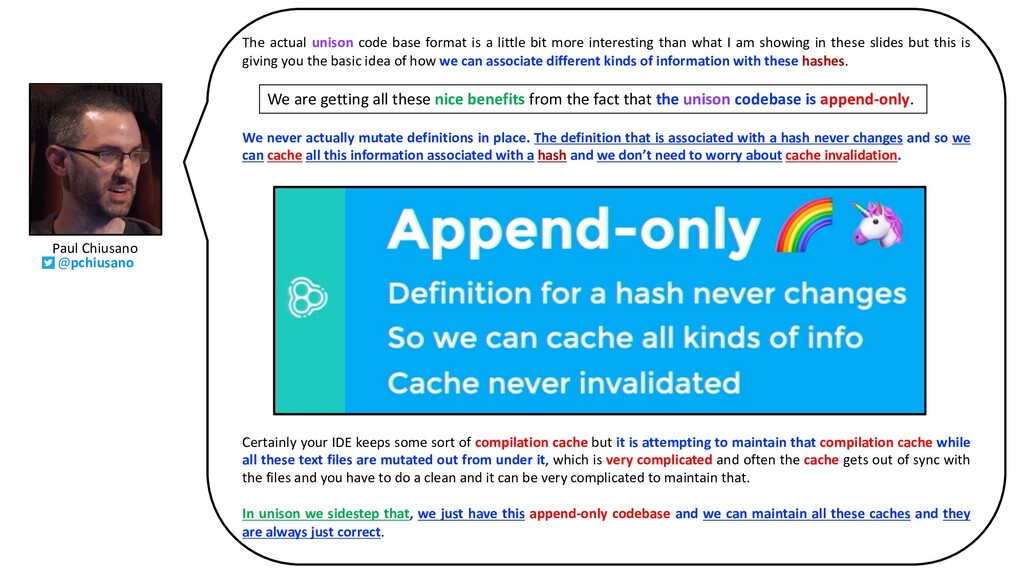
more interesting than what I am showing in these slides but this is giving you the basic idea of how we can associate different kinds of information with these hashes. We are getting all these nice benefits from the fact that the unison codebase is apped-only. We never actually mutate definitions in place. The definition that is associated with a hash never changes and so we can cache all this information associated with a hash and we don’t need to worry about cache invalidation. Certainly your IDE keeps some sort of compilation cache but it is attempting to maintain that compilation cache while all these text files are mutated out from under it, which is very complicated and often the cache gets out of sync with the files and you have to do a clean and it can be very complicated to maintain that. In unison we sidestep that, we just have this append-only codebase and we can maintain all these caches and they are always just correct. We are getting all these nice benefits from the fact that the unison codebase is append-only. Paul Chiusano @pchiusano
going to actually do a live demo and we’ll see how this goes, but before I just like, HOLY CRAP It’s like we discovered this alternate reality, this self-consistent alternate reality of programming where we are sort of getting all these things kind of ‘for free‘ that are just emerging from one idea. So I thought that that was cool, something that has made unison something that it is very cool to work on. Paul Chiusano
Now see the live demo, which lasts 19 minutes and begins 12 minutes into Paul’s talk. @philip_schwarz OK, I am going to switch to a live demo, let’s see how it goes SBTB 2019: Paul Chiusano Unison, and why the codebase of the future is a purely functional data structure. https://www.youtube.com/watch?v=IvENPX0MAZ4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![use .base use .base.Nat product : [Nat] -> Nat product](https://files.speakerdeck.com/presentations/b1ec8dba7a8041a985f850cb651e5998/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}