Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deploy your own Spark cluster in 4 minutes usin...
Search
Pishen Tsai
December 05, 2015
Programming
630
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deploy your own Spark cluster in 4 minutes using sbt.
Pishen Tsai
December 05, 2015
More Decks by Pishen Tsai
See All by Pishen Tsai
Introduction to Minitime
pishen
1
170
都什麼時代了,你還在寫 while loop 嗎?
pishen
2
750
Pishen's Emacs Journey
pishen
0
160
Scala + Google Dataflow = Serverless Spark
pishen
6
880
Shapeless Introduction
pishen
2
930
ScalaKitchen
pishen
1
480
sbt-emr-spark
pishen
1
170
My Personal Report of Scala Kansai 2016
pishen
0
440
SBT Basic Concepts
pishen
1
670
Other Decks in Programming
See All in Programming
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
380
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
680
FDEが実現するAI駆動経営の現在地
gonta
2
190
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
190
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.8k
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
180
Foundation Models frameworkで画像分析
ryodeveloper
1
130
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
4
1.7k
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
890
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
180
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
200
霧の中の代数的エフェクト
funnyycat
1
410
Featured
See All Featured
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
WENDY [Excerpt]
tessaabrams
11
38k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
610
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Producing Creativity
orderedlist
PRO
348
40k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
My Coaching Mixtape
mlcsv
0
170
Making the Leap to Tech Lead
cromwellryan
135
10k
Transcript
Pishen Tsai @ KKBOX Deploy your own Spark cluster in
4 minutes using sbt
KKBOX / spark-deployer • SBT plugin. • Productively used in
KKBOX. • 100% Scala. https://github.com/KKBOX/spark-deployer
None
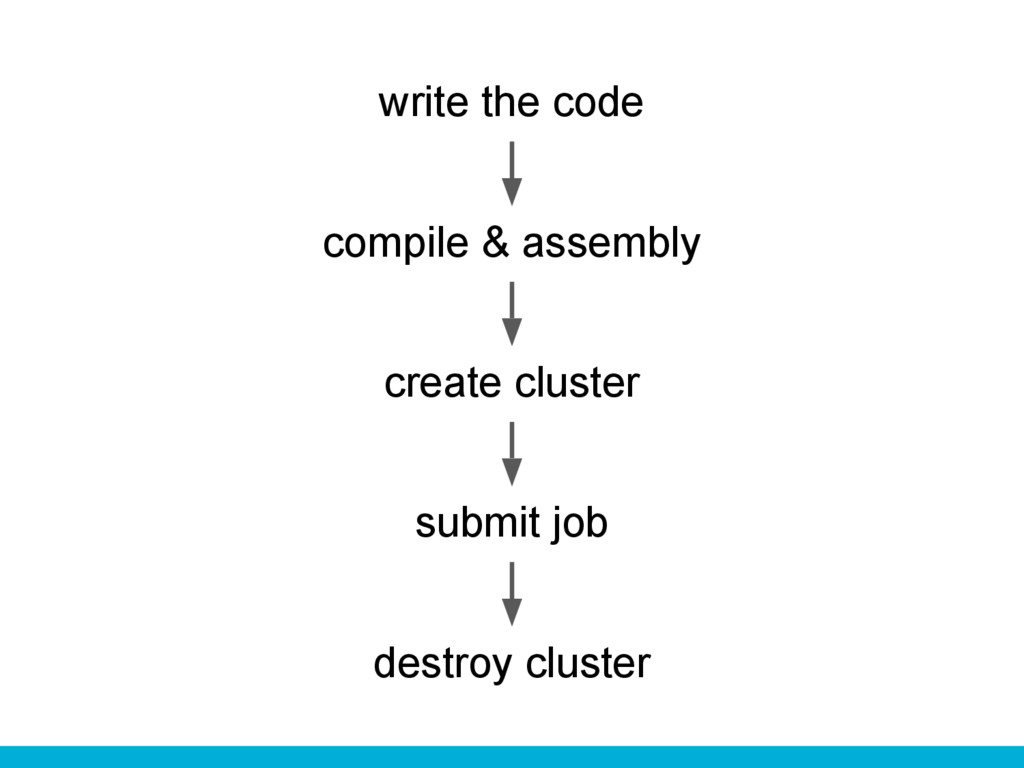
destroy cluster submit job create cluster write the code compile
& assembly
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
https://aws.amazon.com/elasticmapreduce/details/spark http://spark.apache.org/docs/latest/ec2-scripts.html spark-ec2: amazon emr:
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
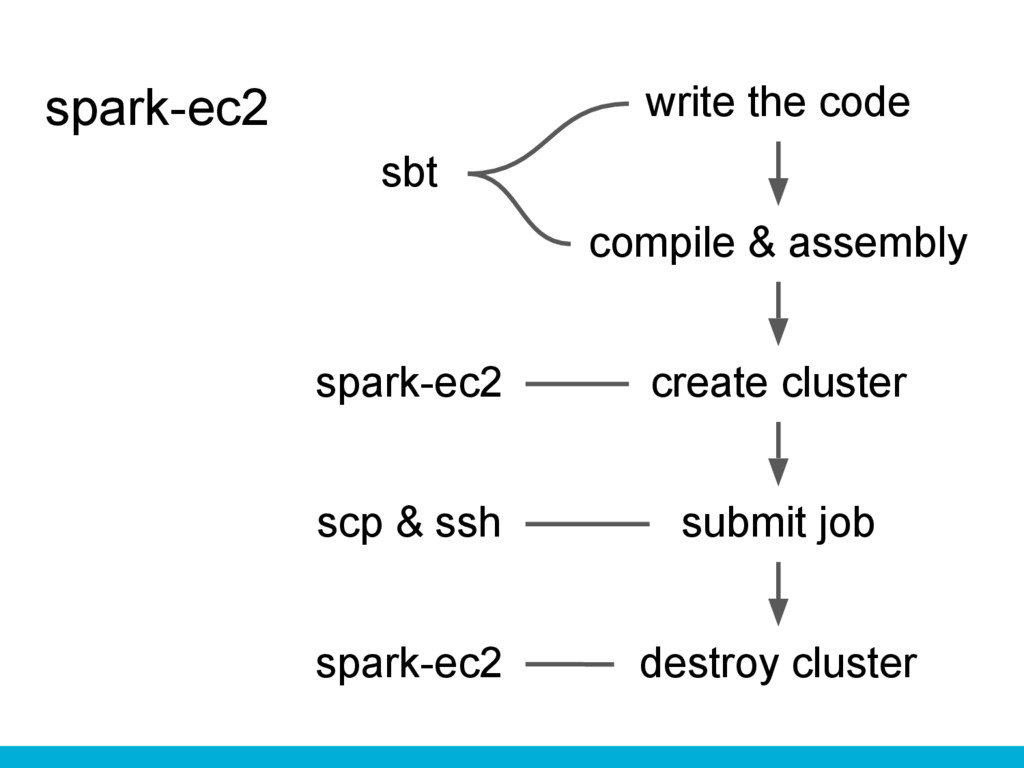
spark-ec2 write the code compile & assembly submit job create
cluster destroy cluster sbt scp & ssh spark-ec2 spark-ec2
spark-ec2’s commands $ sbt assembly $ spark-ec2 -k awskey -i
~/.ssh/awskey.pem -r us-west-2 -z us-west-2a --vpc-id=vpc-a28d24c7 -- subnet-id=subnet-4eb27b39 -s 2 -t c4.xlarge -m m4.large --spark-version=1.5.2 --copy-aws- credentials launch my-spark-cluster $ scp -i ~/.ssh/awskey.pem target/scala-2.10 /my_job-assembly-0.1.jar root@<copy-master-ip- by-yourself>:~/job.jar $ ssh -i ~/.ssh/awskey.pem root@<master-ip> '. /spark/bin/spark-submit --class mypackage.Main --master spark://<master-ip>:7077 --executor- memory 6G job.jar arg0' $ spark-ec2 -r us-west-2 destroy my-spark- cluster
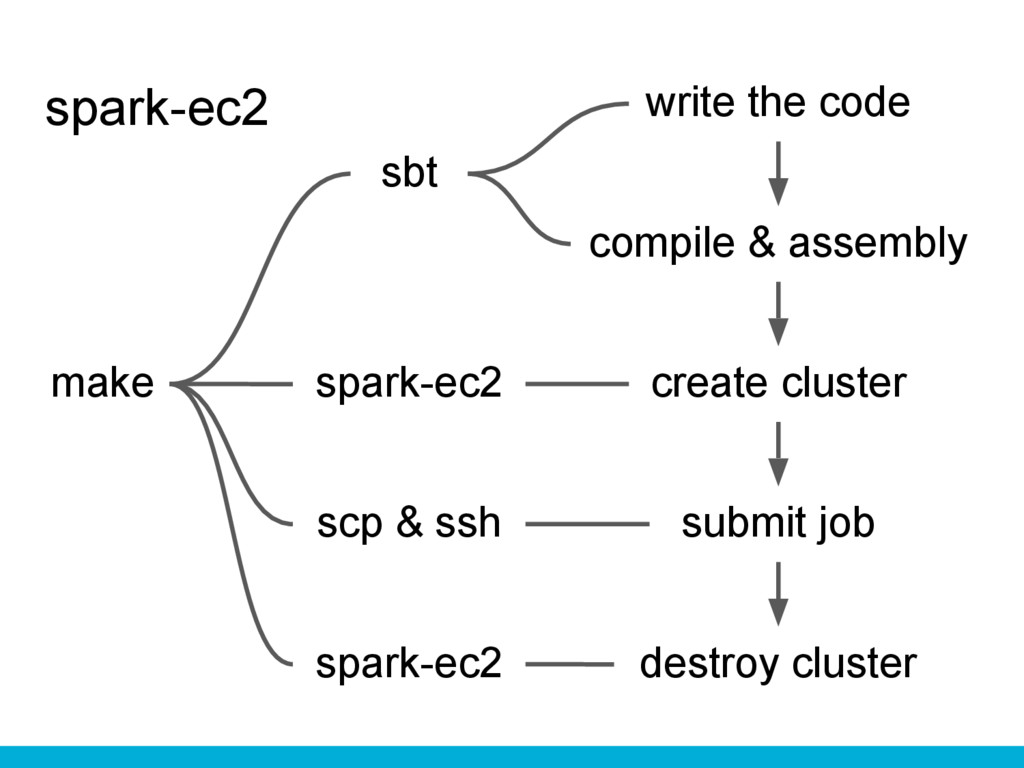
spark-ec2 write the code compile & assembly submit job create
cluster destroy cluster sbt spark-ec2 spark-ec2 scp & ssh make
spark-ec2’s bad parts Need to install sbt and spark-ec2. Need
to design and maintain Makefiles. Slow startup time (~20mins).
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
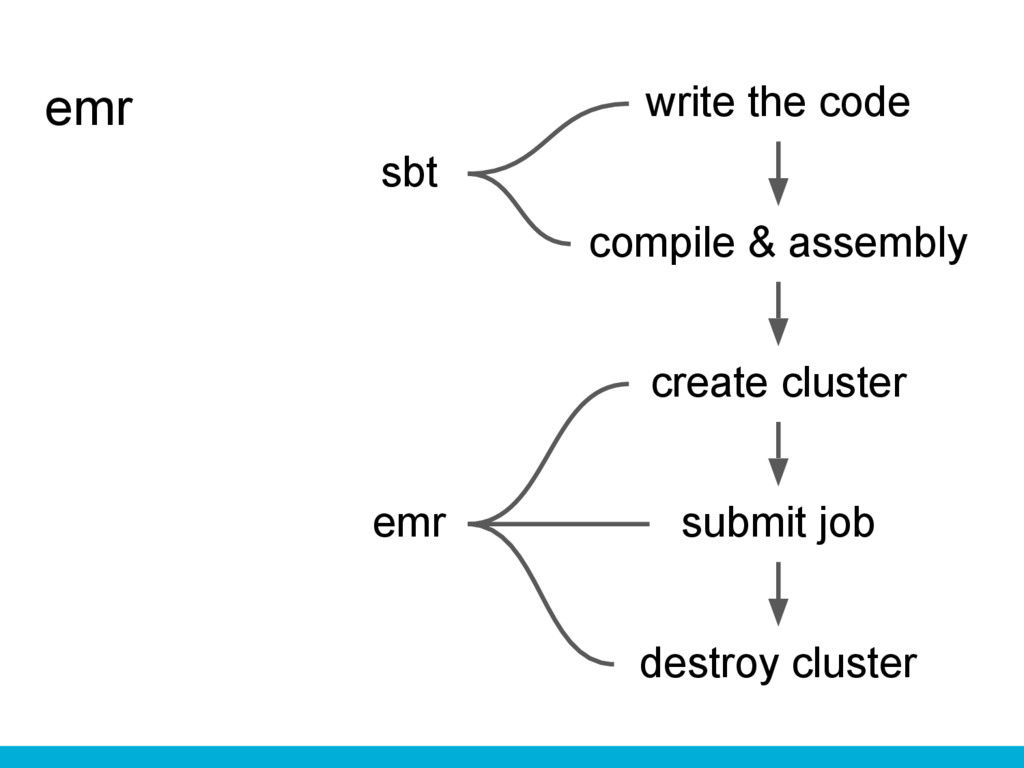
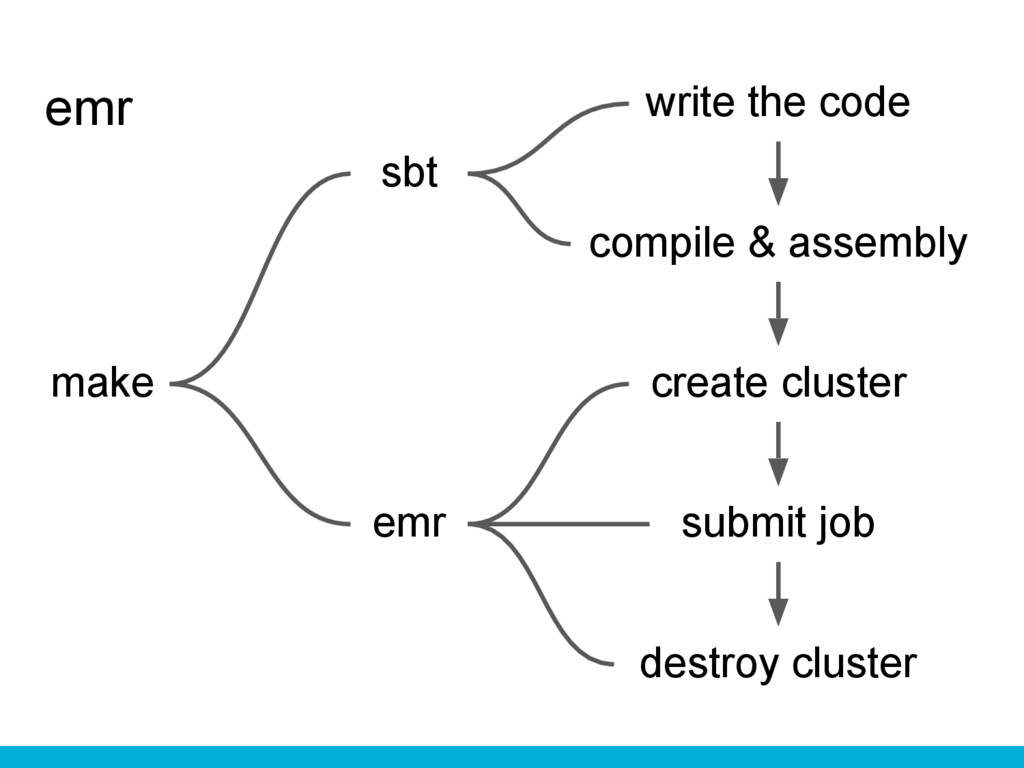
emr write the code compile & assembly submit job create
cluster destroy cluster sbt emr
emr’s commands $ sbt assembly $ aws emr create-cluster --name
my-spark-cluster --release-label emr-4.2.0 --instance-type m3. xlarge --instance-count 2 --applications Name=Spark --ec2-attributes KeyName=awskey --use- default-roles $ aws emr put --cluster-id j-2AXXXXXXGAPLF --key- pair-file ~/.ssh/mykey.pem --src target/scala- 2.10/my_job-assembly-0.1.jar --dest /home/hadoop/job.jar $ aws emr add-steps --cluster-id j-2AXXXXXXGAPLF --steps Type=Spark,Name=my-emr,ActionOnFailure= CONTINUE,Args=[--executor-memory,13G,--class, mypackage.Main,/home/hadoop/job.jar,arg0] $ aws emr terminate-clusters --cluster-id j-2AXX
emr write the code compile & assembly submit job create
cluster destroy cluster sbt emr make
emr’s bad parts Need to install sbt and emr. Need
to design and maintain Makefiles. Spark’s version is old. Restricted machine type.
Since sbt is a powerful build tool itself, why don’t
we let it handle all the dirty works for us?
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
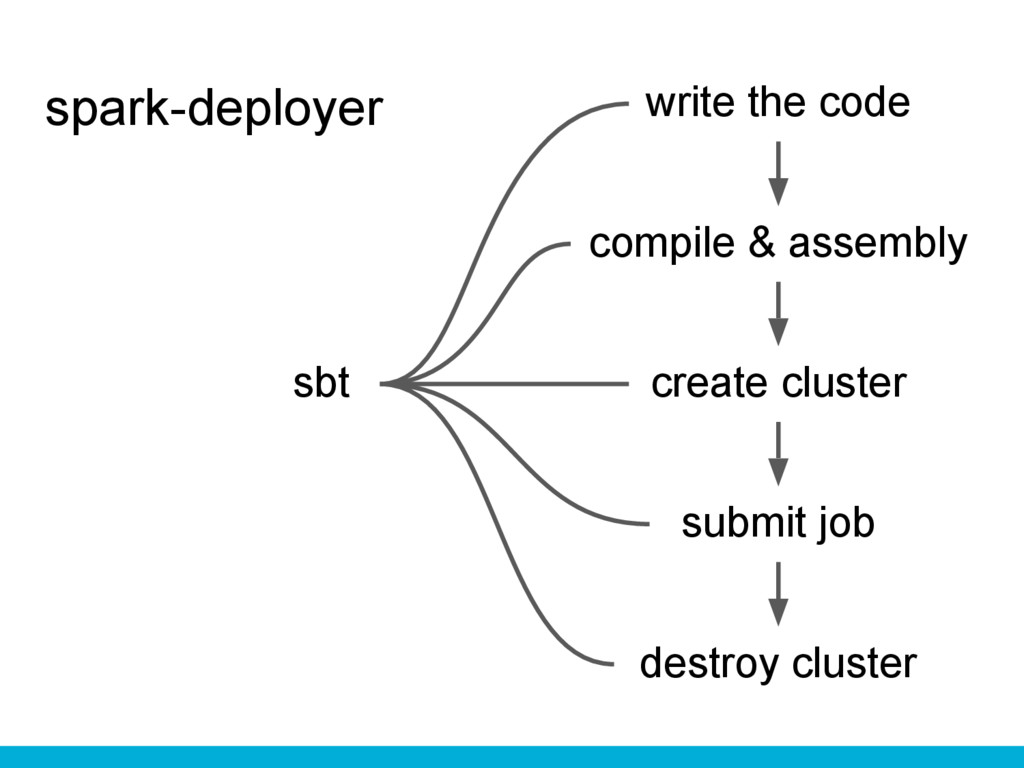
spark-deployer write the code compile & assembly submit job create
cluster destroy cluster sbt
spark-deployer’s commands $ sbt "sparkCreateCluster 2" $ sbt "sparkSubmitJob arg0"
$ sbt "sparkDestroyCluster"
spark-deployer’s good parts Need to install only sbt. No Makefile.
Easy to use. Let you focus on your code. Fast and parallel startup (~4mins). Dynamic scale out. Flexible design.
How to use it?
Prerequisites • java • sbt • export AWS_ACCESS_KEY_ID=... export AWS_SECRET_ACCESS_KEY=...
http://www.scala-sbt.org/0.13/tutorial/Manual-Installation.html#Unix sbt installation
Demo
• Report issues. • Join our gitter channel. • Send
pull requests. https://github.com/KKBOX/spark-deployer Give it a try, and share! KKBOX / spark-deployer
Thank you Pishen Tsai @ KKBOX KKBOX / spark-deployer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}