Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Neural Netrorks for Classification : A Survey
Search
Playground
October 08, 2019
Research
49
0
Share
Neural Netrorks for Classification : A Survey
Playground
October 08, 2019
Other Decks in Research
See All in Research
typst の使い方:言語学を研究する学生のために
gitomochang
0
400
データサイエンティストをめぐる環境の違い2025年版〈一般ビジネスパーソン調査の国際比較〉
datascientistsociety
PRO
0
1.2k
姫路市 -都市OSの「再実装」-
hopin
0
1.7k
Aurora Serverless からAurora Serverless v2への課題と知見を論文から読み解く/Understanding the challenges and insights of moving from Aurora Serverless to Aurora Serverless v2 from a paper
bootjp
6
1.6k
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
140
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
100
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
270
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
930
The mathematics of transformers
gpeyre
0
250
ウェブ・ソーシャルメディア論文読み会 第36回: The Stepwise Deception: Simulating the Evolution from True News to Fake News with LLM Agents (EMNLP, 2025)
hkefka385
0
220
定数整数除算・剰余算最適化再考
herumi
1
110
AIスーパーコンピュータにおけるLLM学習処理性能の計測と可観測性 / AI Supercomputer LLM Benchmarking and Observability
yuukit
1
860
Featured
See All Featured
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
GraphQLとの向き合い方2022年版
quramy
50
15k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.3k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Fireside Chat
paigeccino
42
3.9k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
140
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
490
Done Done
chrislema
186
16k
Mobile First: as difficult as doing things right
swwweet
225
10k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
800
Transcript
Neural Networks for Classification:A Survey Taira Kuwahara
はじめに ※このスライドはNeural Networks for Classification:A Surveyを読み、まとめたもので す。 URLは最後のページの参考⽂献にて 2
⽬次 I. 序章 II. ニューラルネットワークと従来の分類器 III. 学習と凡化 IV. 特徴変数の選択 V.
誤分類コスト VI. 結論 3
I. 序章 4
機械学習 ・教師あり学習 ・教師なし学習 ・強化学習 5
分類(Classification) ▶ある物体を決められたグループへ分類 ▶ビジネス、科学、産業、医療分野 ▶ニューラルネットワークによる⾼精度な分類が⽬的 6
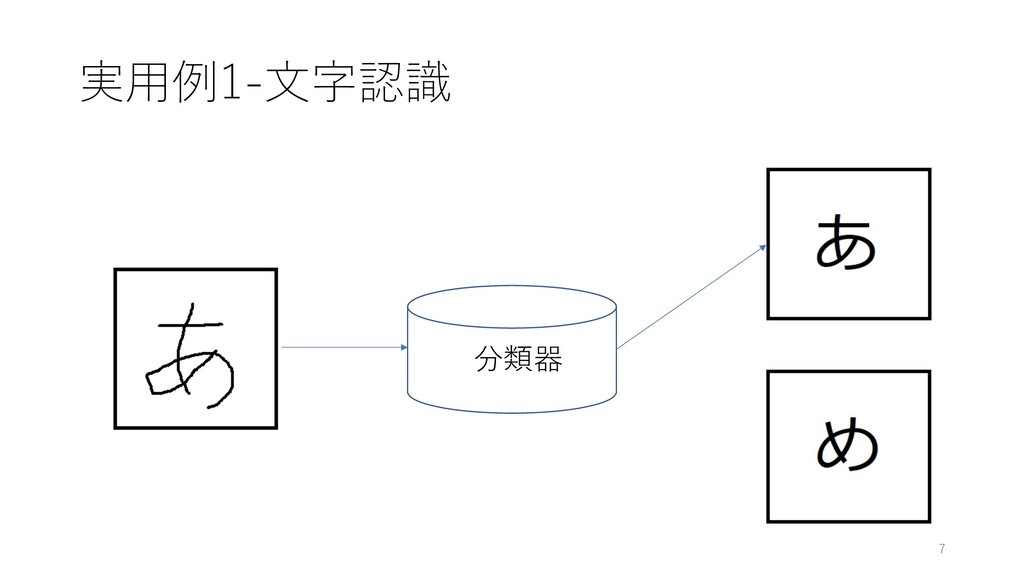
実⽤例1-⽂字認識 7 分類器
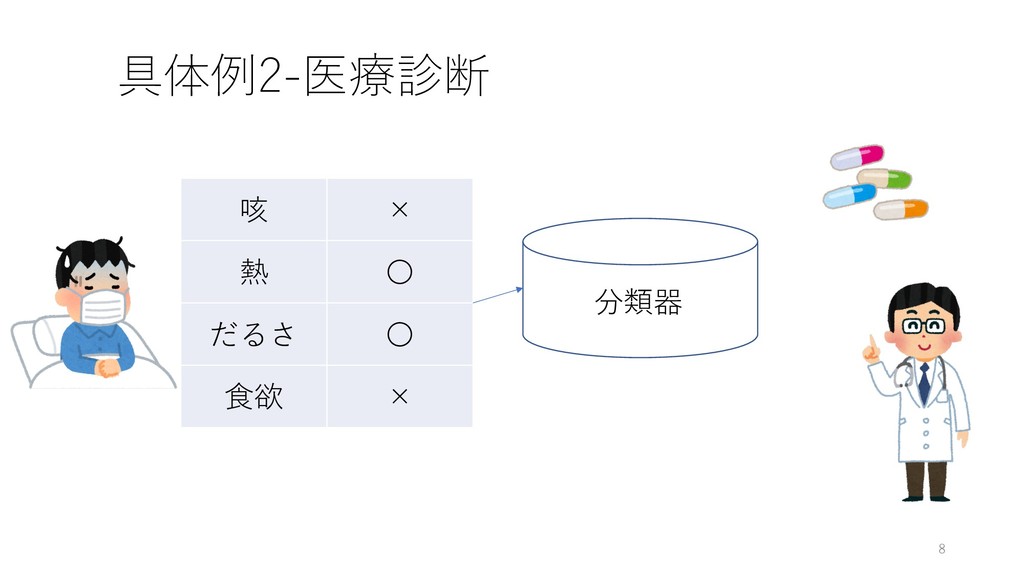
具体例2-医療診断 8 咳 × 熱 〇 だるさ 〇 ⾷欲 ×
分類器
II. ニューラルネットワークと従来の分類器 9
II.A ベイズクラス分類理論 10
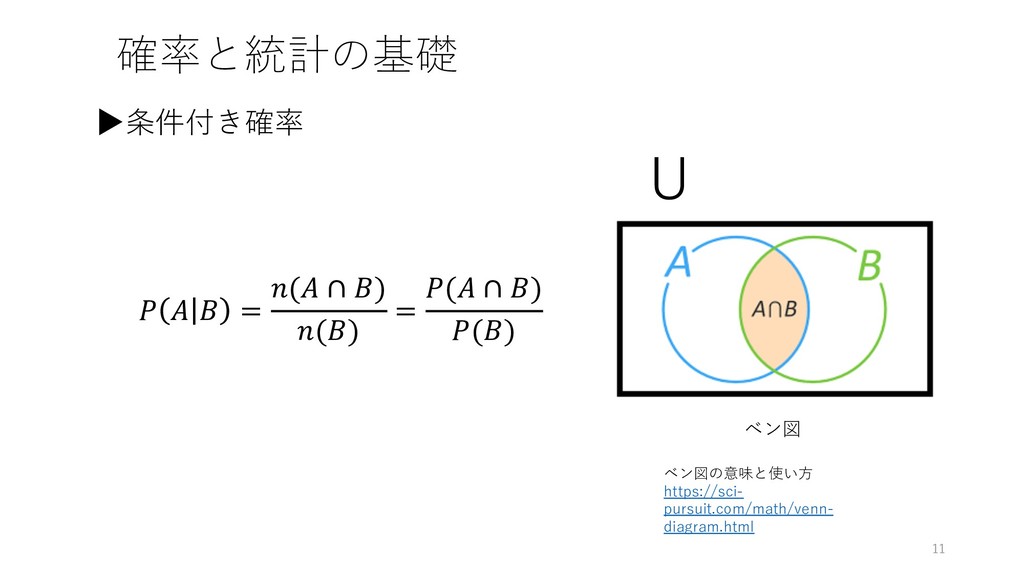
確率と統計の基礎 11 ▶条件付き確率 ベン図 U = ( ∩ ) ()
= ( ∩ ) () ベン図の意味と使い⽅ https://sci- pursuit.com/math/venn- diagram.html
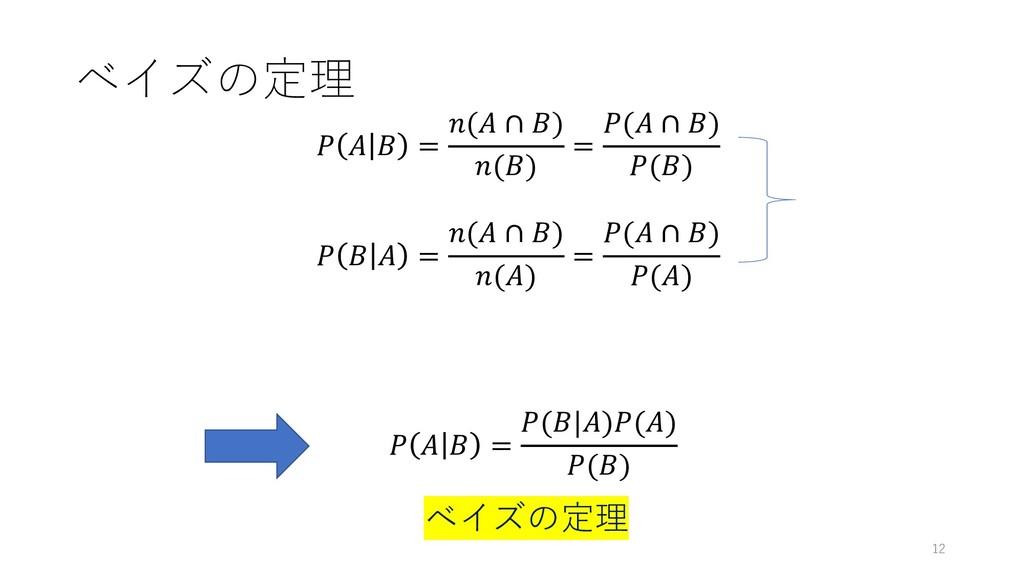
ベイズの定理 = ( ∩ ) () = ( ∩ )
() = ( ∩ ) () = ( ∩ ) () 12 = (|)() () ベイズの定理
前提条件 あるオブジェクトを分類することを考える ①x: データの羅列、特徴ベクトル = [- … . . 0]2
②4 : グループに分類されたとき ∈ {1,2,3, … } 13
Bayes Rule 4 = 4 (4) () … (1) 14
4| : 事後確率 4 : 事前確率 , (|4 ): 確率密度関数 ∈ {1,2,3, … … … , } 4 : グループ名
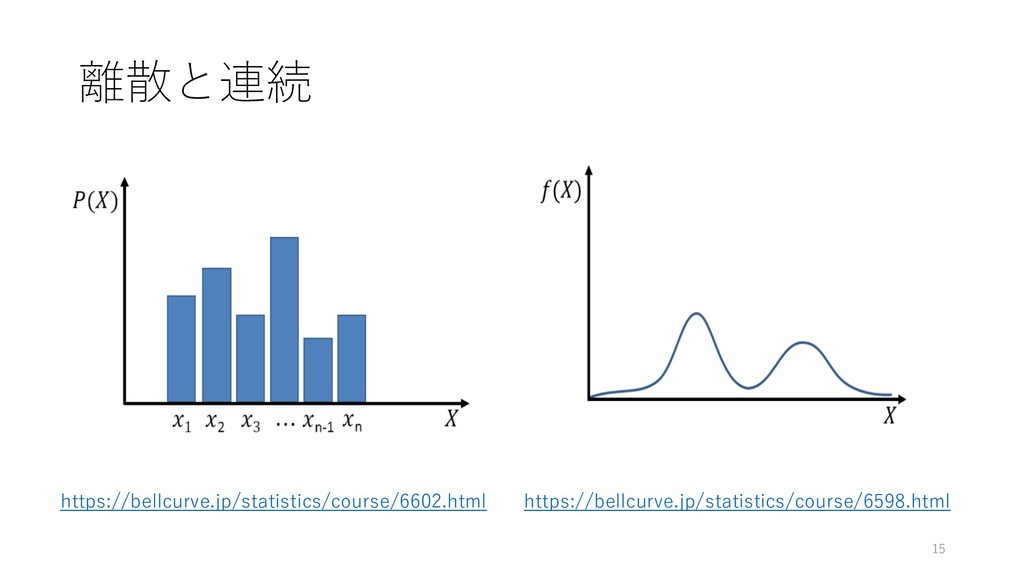
離散と連続 15 https://bellcurve.jp/statistics/course/6602.html https://bellcurve.jp/statistics/course/6598.html
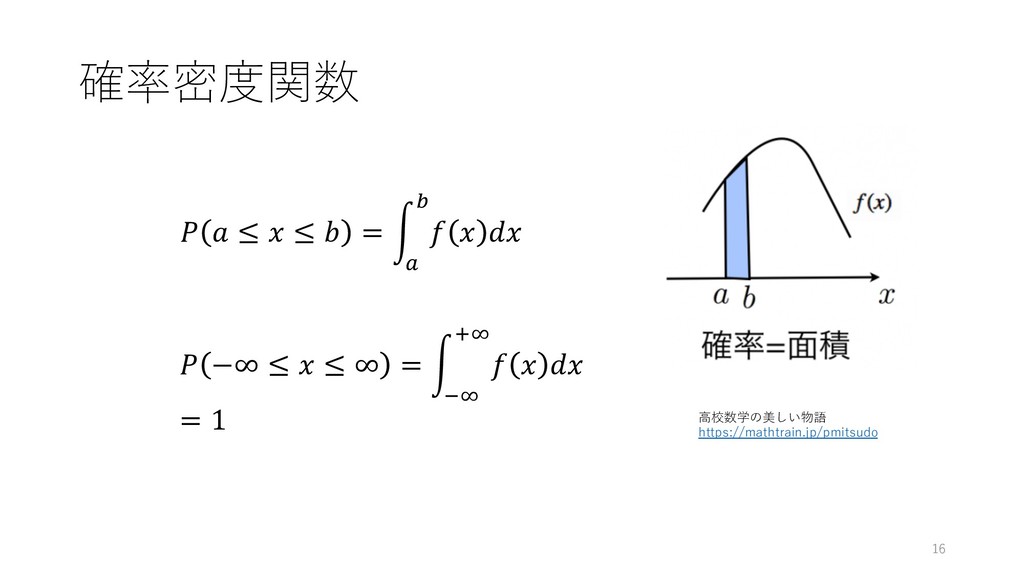
確率密度関数 16 ⾼校数学の美しい物語 https://mathtrain.jp/pmitsudo ≤ ≤ = D E F
−∞ ≤ ≤ ∞ = D JK LK = 1
Error 4 が正しい分類先のとき Error = P QR4 Q = 1
− (4 |) 17 , ∈ {1,2,3, … . . }
Errorの最⼩化 Error = 1 − (4 |) エラーを最⼩にするためには… T =
max Q … (2) 18 しかし…
問題点 1. 現実世界の確率密度関数はわかっていない、また標準正規 分布ではない。 2. 分類ミスによるコストしか考慮していない。 19
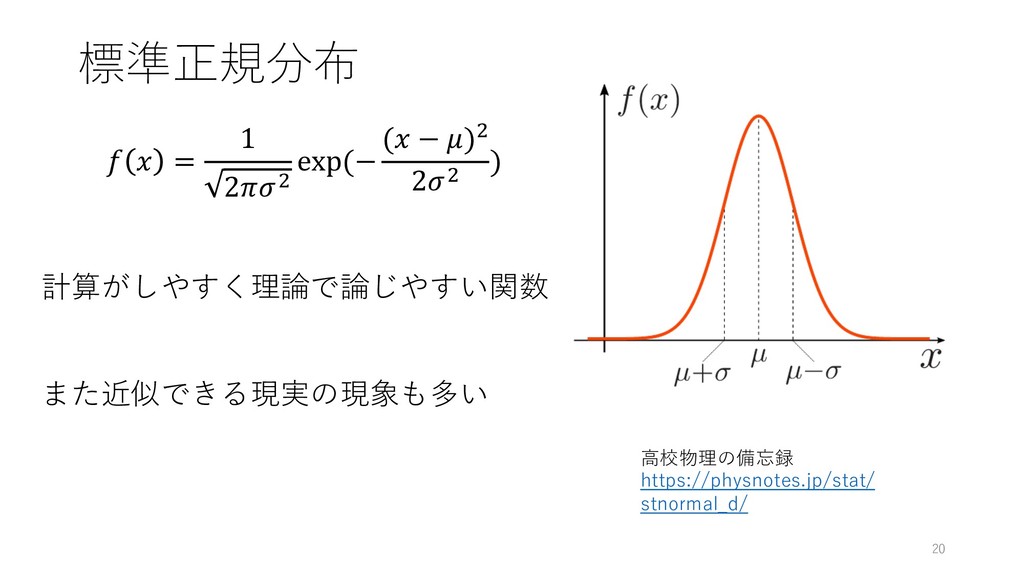
標準正規分布 20 ⾼校物理の備忘録 https://physnotes.jp/stat/ stnormal_d/ = 1 2Z exp(− (
− )Z 2Z ) 計算がしやすく理論で論じやすい関数 また近似できる現実の現象も多い
コスト Q = P 4_- ` Q4 (4 |) ,
= 1,2~ … (3) T = min Q () … (4) 21 Q4 : 正解はjであるが間違えてiに分類してし まったときのコスト
コスト 4 = 4 (4 ) () … (1) Q
= P 4_- ` Q4 (4 |) … (3) Q = P 4_- ` Q4 4 (4 ) () ()はすべてのグループに共通しているから P Q_- ` QT 4 (4 )が最⼩ 22 分類精度⾼
⽐較 -Z Z Z < Z- - - - Z
> -Z Z Z- - … (5) 確率密度関数によるコストの⾒積もり 23 事前確率でコストの予測が⽴つ
II.B ニューラルネットワークを⽤いた 事後確率推定 24
期待値(expectation) 全ての場合を考えて確率変数を平均化している 25 = D JK K k = P
m ( = ) = P m ( = ) = D JK K k 離散型 連続型 ℎ , = P p P m ℎ , ( = , = ) ℎ(, ) = D JK K D JK K ℎ , k,r ,
分散(variance) 分散は「期待値からの外れ具合」の期待値 ≡ [] 期待値からのズレの⼆乗を考える ≡ [ − Z] Xは変数
▶標準偏差 = [] 26
分散の補⾜説明 ▶なぜズレの⼆乗を考えるのか ・| − |だと場合わけが必要になる ・微分不可能な領域が⽣まれる 27
分散の最⼩値 − Z = は条件つき期待値 ・yは2進数で 正しい分類のとき1 間違った分類のとき0 28
写像関数 4 = 4 = 1・ 4 = 1 +
0・ 4 = 0 = 4 = 1 = 4 ・写像関数は事後確率 29
平均⼆乗誤差:MSE(mean squared error) MSE = P Q_- ` D {|
Q − Q Z + P Q_- ` D {| (Q |)(1 − (Q |)) ・第1項 ニューラルネットワークの写像による誤差 ・第2項 近似誤差(データの無作為性) 30
II.C ニューラルネットワークと従来の分類器 31
2グループ分類における判別式 = - | − (Z |) > 0であれば グループ1に分類すべき
< 0であれば グループ2に分類すべき 32
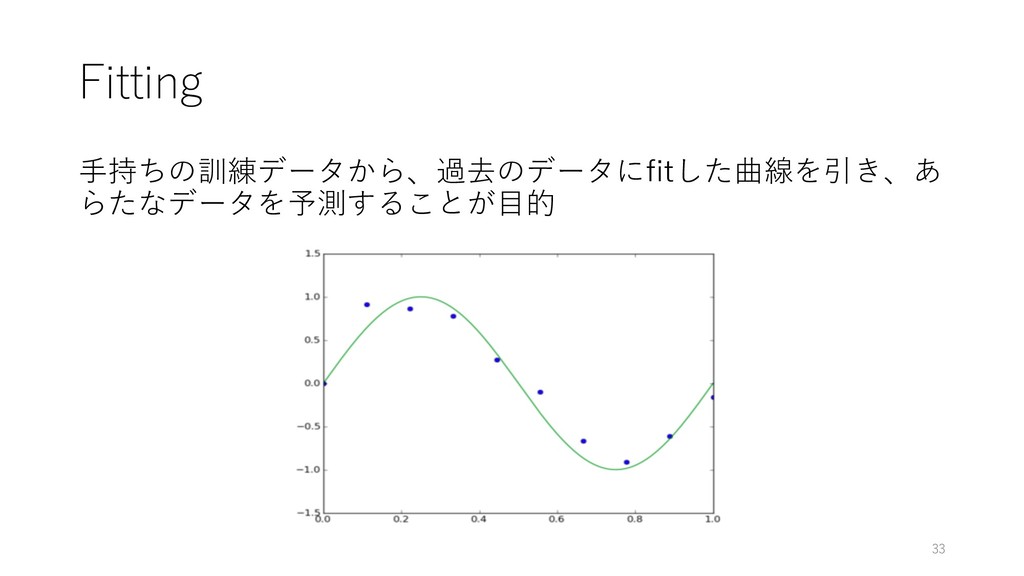
Fitting ⼿持ちの訓練データから、過去のデータにfitした曲線を引き、あ らたなデータを予測することが⽬的 33
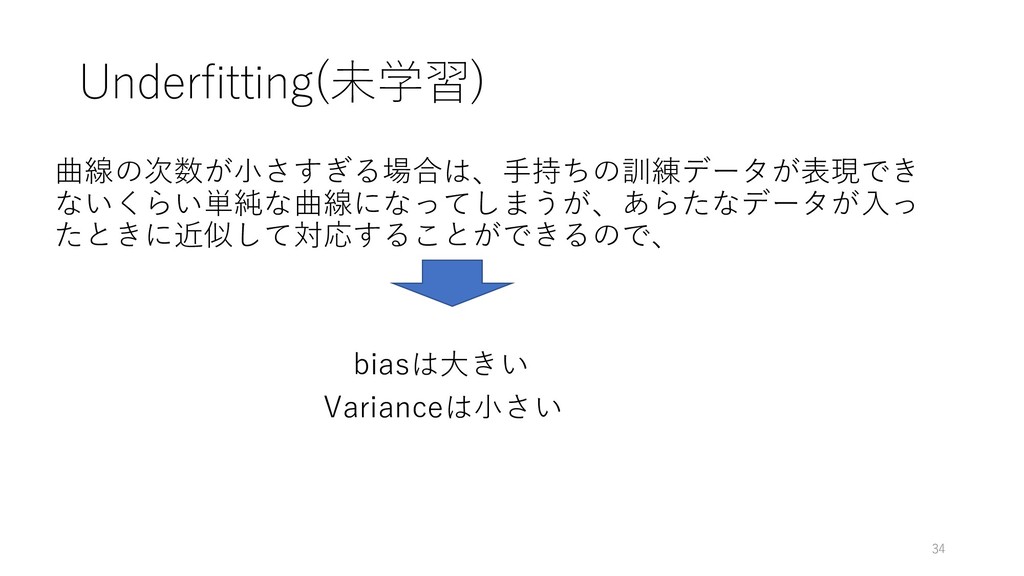
Underfitting(未学習) 曲線の次数が⼩さすぎる場合は、⼿持ちの訓練データが表現でき ないくらい単純な曲線になってしまうが、あらたなデータが⼊っ たときに近似して対応することができるので、 biasは⼤きい Varianceは⼩さい 34
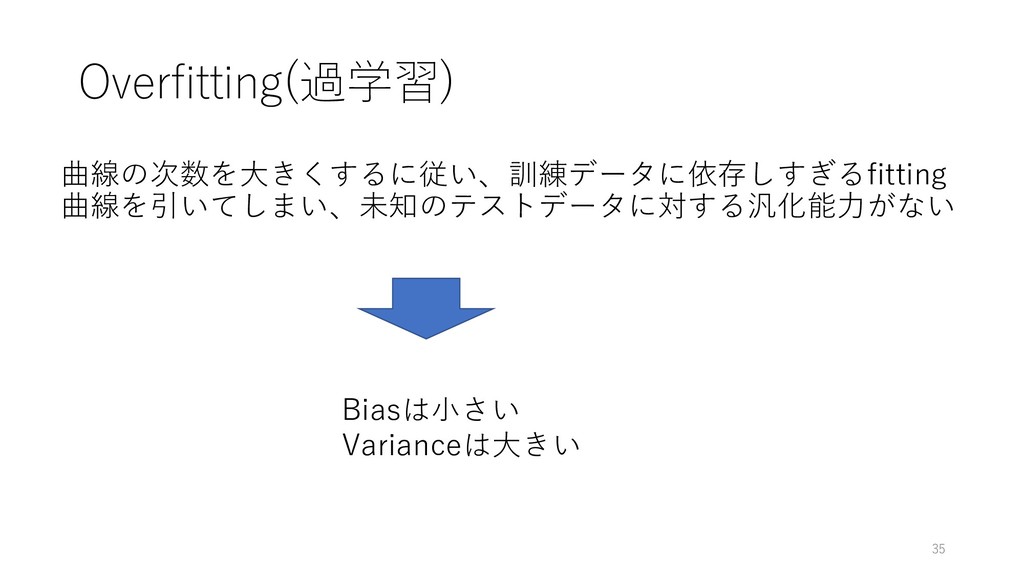
Overfitting(過学習) 曲線の次数を⼤きくするに従い、訓練データに依存しすぎるfitting 曲線を引いてしまい、未知のテストデータに対する汎化能⼒がない 35 Biasは⼩さい Varianceは⼤きい
良いfitting UnderfittingとOverfittingのジレンマ(トレードオフ) 36 ちょうどいいfitting曲線を⾒つける
III. 学習と凡化 37
III.A. 予測エラーにおけるバイアスと分散の混合 38
= + ∈ {0, 1} ただしεは平均0で分散σ2の確率分布に従う 39 = = -
… (12) ノイズ
MSEの計算 = − ; • Z = − Z +
; • − Z = ‰ − ; • Z = − Z + ‰ ; • − Z 40 次のページへ Z … 固有エラー • :N個の訓練データセット
MSEの計算の続き ‰ ; • − Z ‰ ; • −
Z + ‰ ; • − ‰ ; • Z 41 バイアス項 分散項
III.B. 予測エラーを減らすための⽅法論 42
アンサンブル分類器 ・個別の分類器を組み合わせることで、全体として優れた分類器 のモデルを⽣成する。(組み合わせ⽅が様々) ・個別の分類器同⼠の相関関係が⼩さいほど、分類精度の優れた アンサンブル分類器を⽣成することができる。 ・分散を極めて⼩さくすることができる。 43
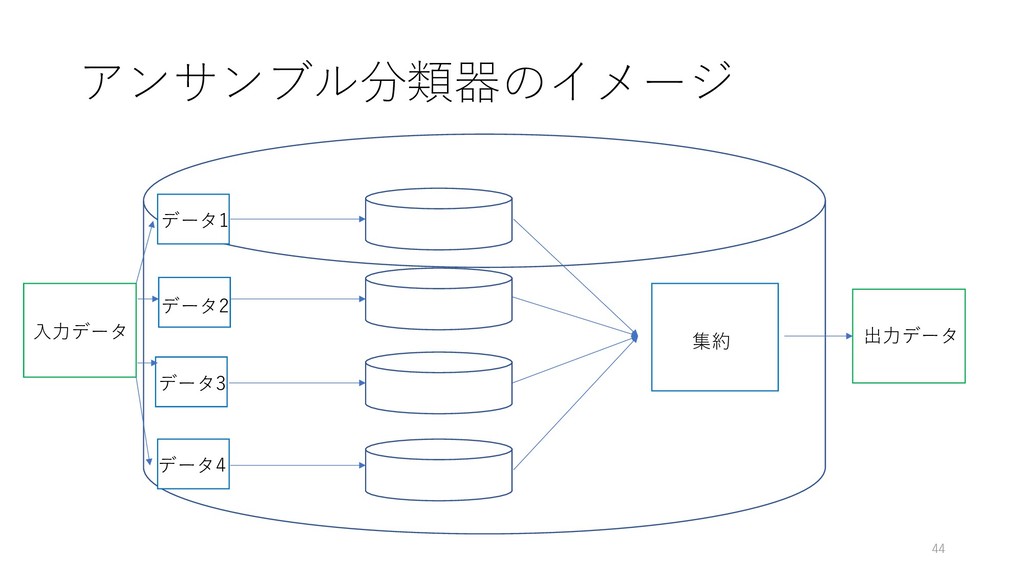
アンサンブル分類器のイメージ 44 ⼊⼒データ 出⼒データ 集約 データ1 データ2 データ3 データ4
組み合わせ⽅ ・個別の分類器の出⼒を平均値を経由して組み合わせる。 ・個別の分類機の多数決(voting)によって採⽤する出⼒を決定 45
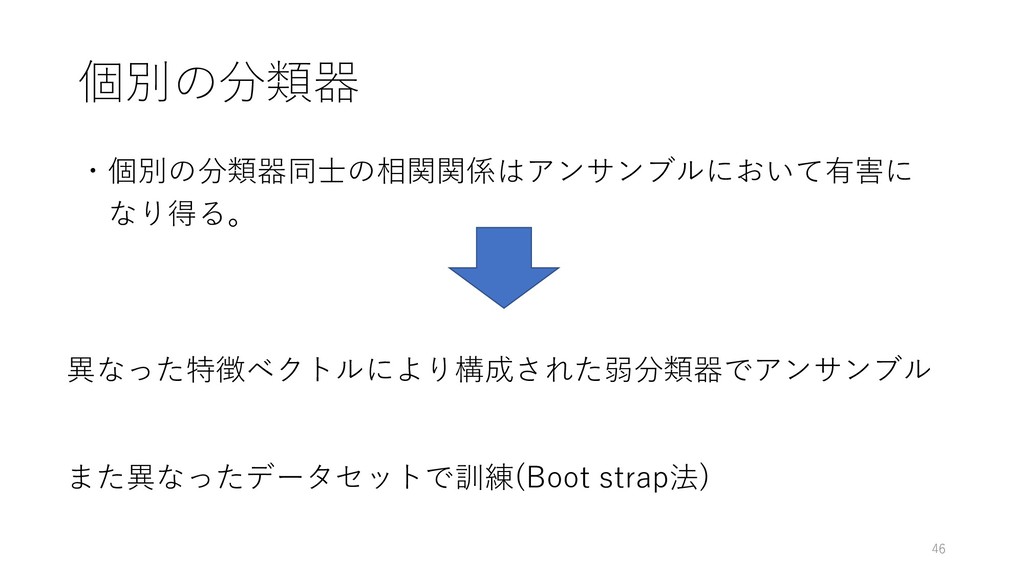
個別の分類器 ・個別の分類器同⼠の相関関係はアンサンブルにおいて有害に なり得る。 46 異なった特徴ベクトルにより構成された弱分類器でアンサンブル また異なったデータセットで訓練(Boot strap法)
Boot strap法 あるN個のデータXがあるとする = - , Z , … …
… . • Xからランダムに重複を含んでN個を復元抽出することにより、 新たなデータセットを作成 - = {- , Z , Z , … … … , •J- } Z = {- , - , - , … … … , •JZ } Š = {‹ , ‹ , ‹ , … … … , • } 47 …
Boot strap法(続き) = ∗, ∗ − ∗, ⺟集団の誤識別率の予測値 = ,
− 1 P Q_- Š () biasを推定するためにBoot strap法が⽤いられる。 48
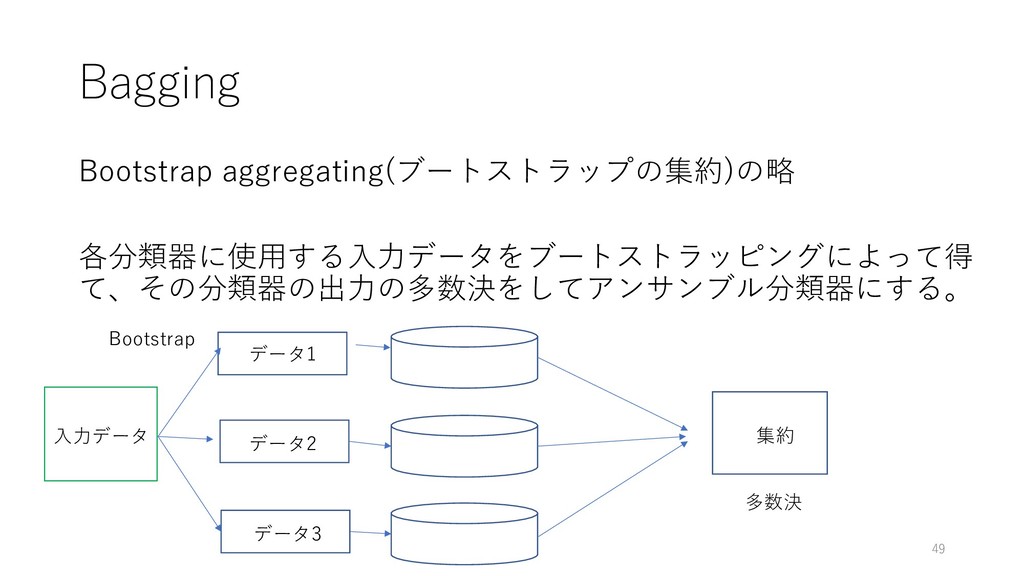
Bagging Bootstrap aggregating(ブートストラップの集約)の略 各分類器に使⽤する⼊⼒データをブートストラッピングによって得 て、その分類器の出⼒の多数決をしてアンサンブル分類器にする。 49 ⼊⼒データ Bootstrap データ1 データ2
データ3 多数決 集約
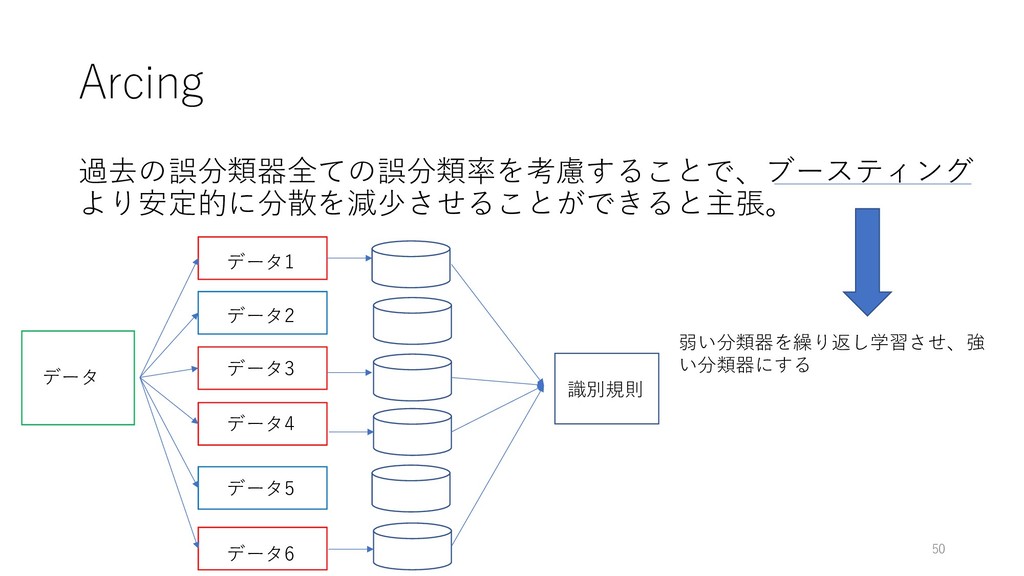
Arcing 過去の誤分類器全ての誤分類率を考慮することで、ブースティング より安定的に分散を減少させることができると主張。 50 弱い分類器を繰り返し学習させ、強 い分類器にする データ データ1 データ2 データ3
データ4 データ5 データ6 識別規則
総括 ・アンサンブル分類器の作成⼿順は様々な種類があるので、さま ざまな⼈がそれぞれの⼿法を主張している。 ・それぞれの⽅法にメリットとデメリットがある。 51
IV. 特徴変数の選択 52
特徴変数の選択 ・満⾜させるような予測パフォーマンスを引き起こす特徴変数の 集合を発⾒することが⽬的 ・次元の呪いより、分類器への⼊⼒変数の数を制限することが 必要であり、かつ有効である。 ・変数全体の集合のうちの⼩さな部分集合のみを⽤いることに より、サンプル外学習のパフォーマンスは向上する。 53
次元の呪い ・データが⾼次元になりすぎると、分類や回帰がうまく作⽤ しなくなる。 ・この現象を防ぐために、次元を減らしたり、変数を減らしたり する。 ・次元が三次元を超えると⼈間の直感がきかなくなる。 54
統計的な特徴選択 ・統計的な特徴選択の⼿法は、ニューラルネットワークがノンパラメ トリックであるという性質のため直接適⽤することは不可能である。 ・ノンパラメトリックとは、分布の具体的な関数を決めつけない設定 のことである。 ・近年、ニューラルネットワーク分類器のための特徴変数選択 と次元の減少という⽅法が発達している。 ・統計的にそれぞれ独⽴している特徴変数を⽤いることでクラ ス分類器の性能が向上する。 55
特徴選択の⽅法論(PCA法) ・もともとのデータから本質的なデータを減らすことはしないで、 次元を減らす⽅法である。 ・ニューラルネットワーク訓練の前処理⽅法として使⽤される。 ・教師なし学習の⼀種で、⽬標出⼒と⼊⼒特徴間の相関を考慮 していない。 ・⾮線形な相関構造をもつ複雑な問題は対処できない。 56
発⾒的な⼊⼒変数の評価⽅法(その1) ・出⼒変数に対する⼊⼒変数の相対的な重要性や貢献度を⾒積 もる⽅法論の提案 ・最もシンプルなのは、⼊⼒の重みの絶対値を合計する⽅法論 57 重要な隠れノードの重みの影響を考慮していない。
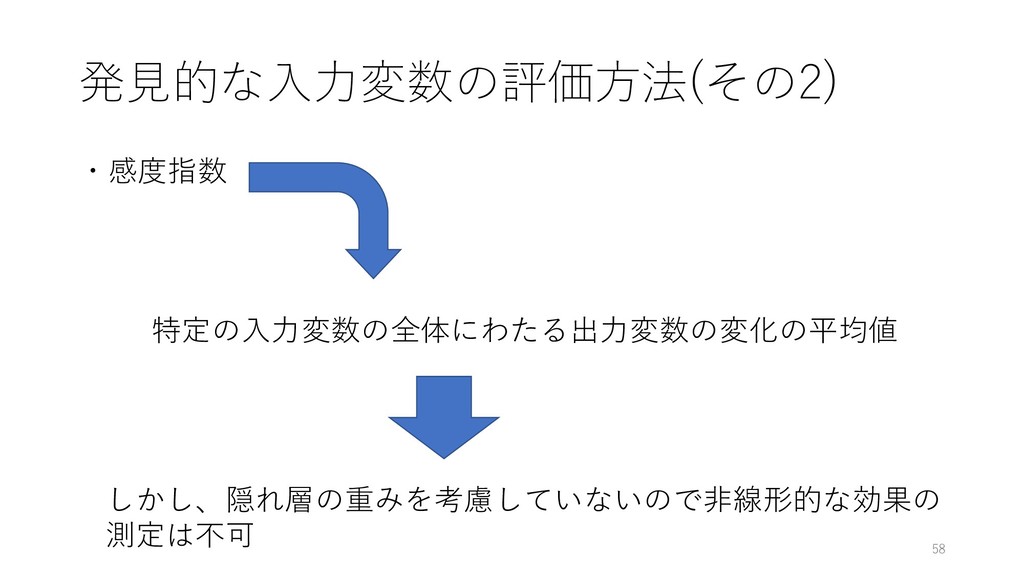
・感度指数 58 発⾒的な⼊⼒変数の評価⽅法(その2) 特定の⼊⼒変数の全体にわたる出⼒変数の変化の平均値 しかし、隠れ層の重みを考慮していないので⾮線形的な効果の 測定は不可
・⼊⼒重みと隠れ重み、出⼒における⼊⼒重みと隠れ重みの相互 関係を考慮する。 ・例えば、⼊⼒層から隠れ層への重みと隠れ層から出⼒層への重み の積の合計値である擬似重みを考える。 ・他には、隠れ層を関連する個々の⼊⼒ノードの部分に分割し、 特定の⼊⼒ノードへ貢献する隠れ層の重みのパーセンテージを 指標にする。 59 発⾒的な⼊⼒変数の評価⽅法(その3)
前進法と後退法(発⾒的) ・前進法…すべての特徴量をデータから取り除いた状態で、特徴 量を⼀つずつ⼊れていき、分類精度の改善が起こらなくなるまで 特徴量を⼊れる。 ・後退法…すべての特徴量をデータに⼊れておき、そこから不要 だと予測される特徴量を⼀つずつ取り除いていき、分類精度の変 化がなくなるまで続ける。 60
重み除去とノード剪定 61 ・不必要なリンクの重みや⼊⼒ノードを除去するために、重み 除去やノード剪定がよく⾏われる。 ・OBD(optimal brain damage)では、簡略化されたヘッセ⾏列 に基づいて、顕著性が計算される。
総括 ・特徴選択におけるあらゆる⼿順は⾃⼰発⾒的で特徴の除去や 追加を正当化するため、統計的で厳格なテストが不⾜する。 特徴選択におけるパフォーマンスは⼀貫性がなく、強固ではない 可能性がある。 よって⼀般性があり、系統的な特徴選択の⽅法論のさらなる発達 が必要である。 62
V. 誤分類コスト 63
均等な誤分類コストの問題点 ・研究者達はミス分類のコストを分類先において同⼀であると 想定している。 ・0~1のコスト関数を減らすことだけが唯⼀の⽬的 ・コスト関数はモデルの発達を容易にしているが、現実世界の問 題にはそぐわない。 ・不均等な誤分類コストが現実世界の問題においては好ましい。 64
誤分類コストにおける研究者の提案 ・重みづけられたエラー関数の使⽤ ・相対的なクラスの重要性や誤分類コストについての事前知識の 組み込み 65
VI. 結論 66
結論 ・事後確率推定(ベイズ推定) ・ニューラル分類器と従来の分類器との関係性 ・ニューラルネットワーク分類における学習と凡化の関係 ・ニューラルな分類器のperformance向上するにあたっての問題点 ・2000年までの10年間で理論的な発達と実際の適⽤においての前進 67
結論 ・ニューラルネットワークは、まだ未解決の問題点あり ・この論⽂は、さまざまな論⽂の説の引⽤をまとめた論⽂ 68
参考⽂献 [1] 「Neural Networks for Classification:A Survey」 http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33 0.284&rep=rep1&type=pdf [2]
「はじめてのパターン認識」 69
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前提条件 あるオブジェクトを分類することを考える ①x: データの羅列、特徴ベクトル = [- … . . 0]2](https://files.speakerdeck.com/presentations/d8d63ea5e40941ce830b6f640d5e5d59/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![分散(variance) 分散は「期待値からの外れ具合」の期待値 ≡ [] 期待値からのズレの⼆乗を考える ≡ [ − Z] Xは変数](https://files.speakerdeck.com/presentations/d8d63ea5e40941ce830b6f640d5e5d59/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考⽂献 [1] 「Neural Networks for Classification:A Survey」 http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33 0.284&rep=rep1&type=pdf [2]](https://files.speakerdeck.com/presentations/d8d63ea5e40941ce830b6f640d5e5d59/slide_68.jpg){kind=link}