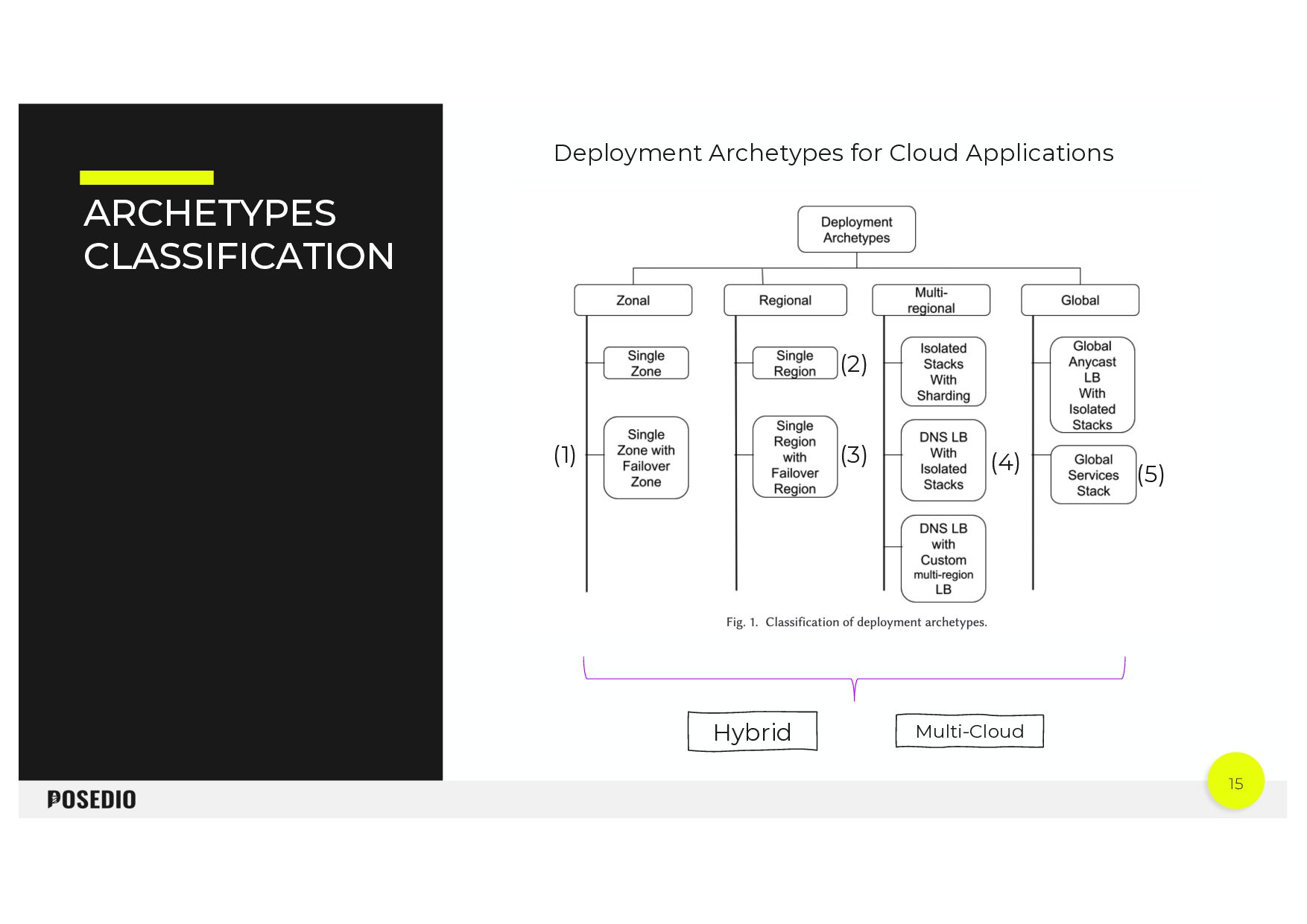
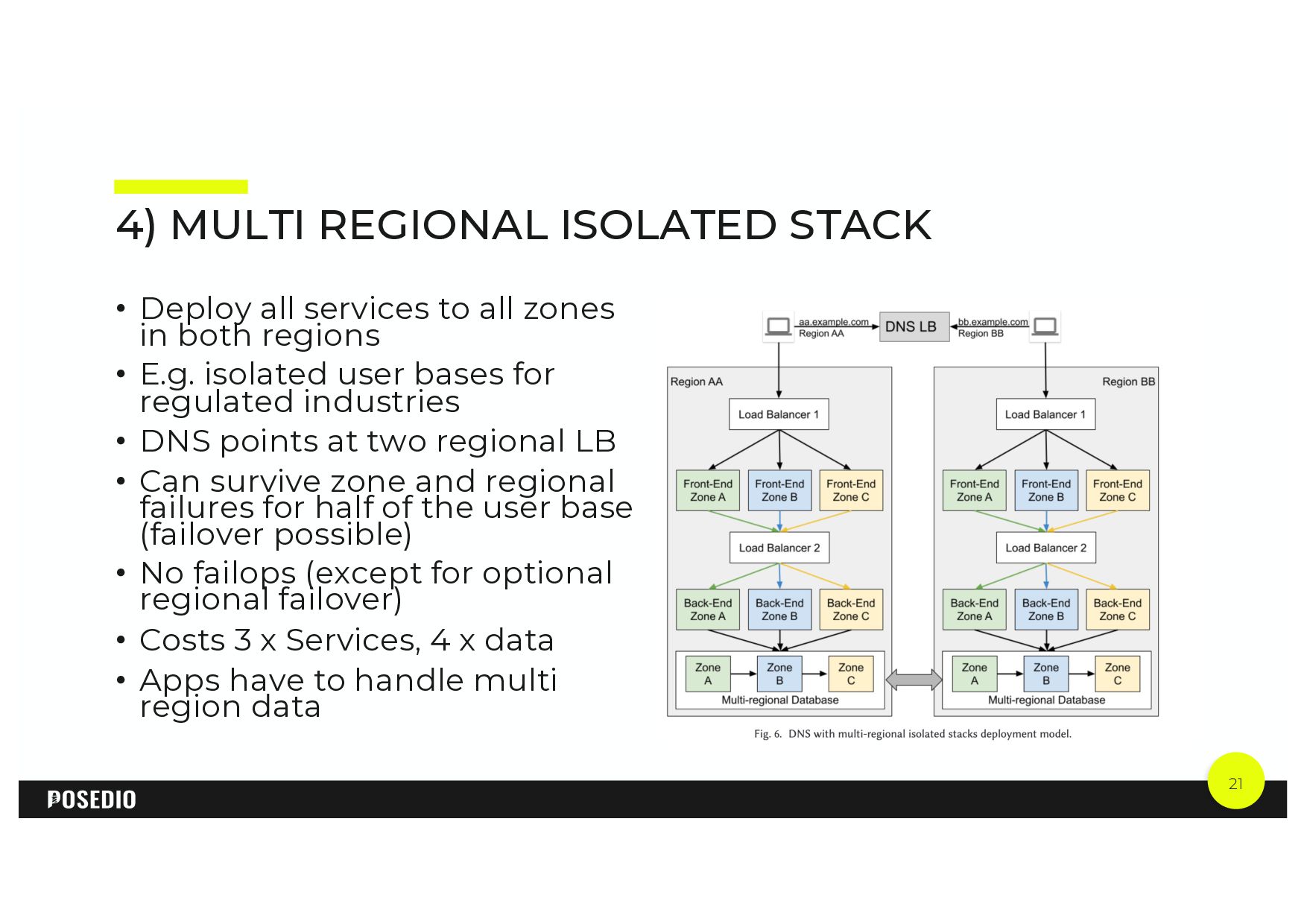
Achieving high availability while minimizing operational costs requires thorough exploration of the cloud architecture from the outset. The initial choice of a deployment archetype sets boundaries for the achievable service level agreements (SLAs). This talk delves into the various patterns available and guides on selecting the most appropriate strategy tailored to specific requirements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}