5 Biological inspiration - Evolution • Natural selection – survival of the fittest • Genes for best fitness will be passed onto the next generation • Mutation – random changes can introduce new versions of genes which increase fitness • Speciation – over time new specialized species will arise Image source: Pixabay
6 Biological inspiration – Sexual reproduction • Offspring produced by two individuals • Each parent provides half of the genes • During meiosis two chromosomes undergo crossover to exchange homologous genetic material • Crossover creates genetic diversity Image source: Wikipedia
7 Biological inspiration – Development • Genetic information is not expressed directly • Genes encode a program for the development of the organism • Transcription factors control which genes are expressed in which cells, allowing reuse of genes at different stages and different places • Similar sets of genes under a different developmental program can create different species Image source: Wikipedia
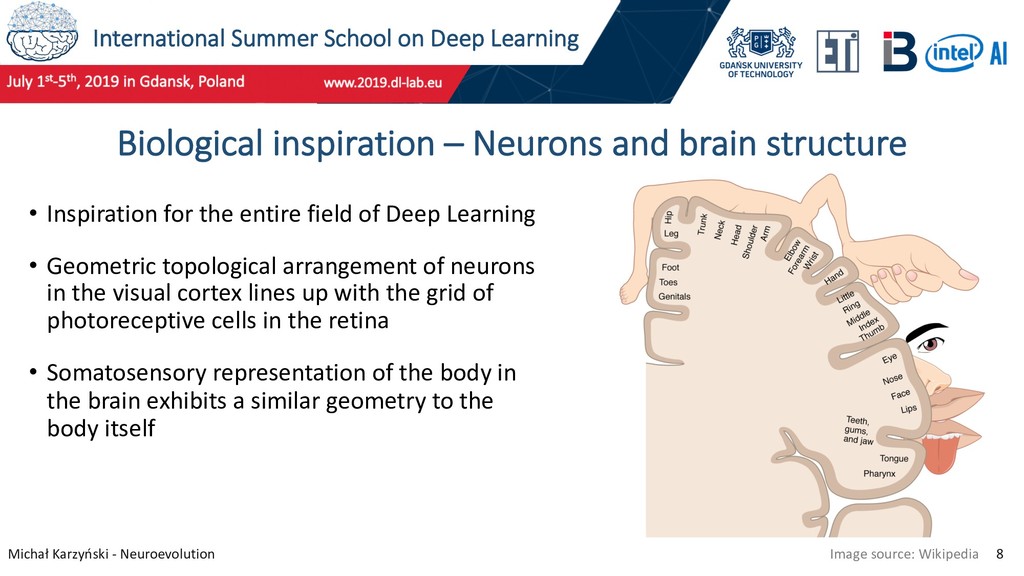
8 Biological inspiration – Neurons and brain structure • Inspiration for the entire field of Deep Learning • Geometric topological arrangement of neurons in the visual cortex lines up with the grid of photoreceptive cells in the retina • Somatosensory representation of the body in the brain exhibits a similar geometry to the body itself Image source: Wikipedia
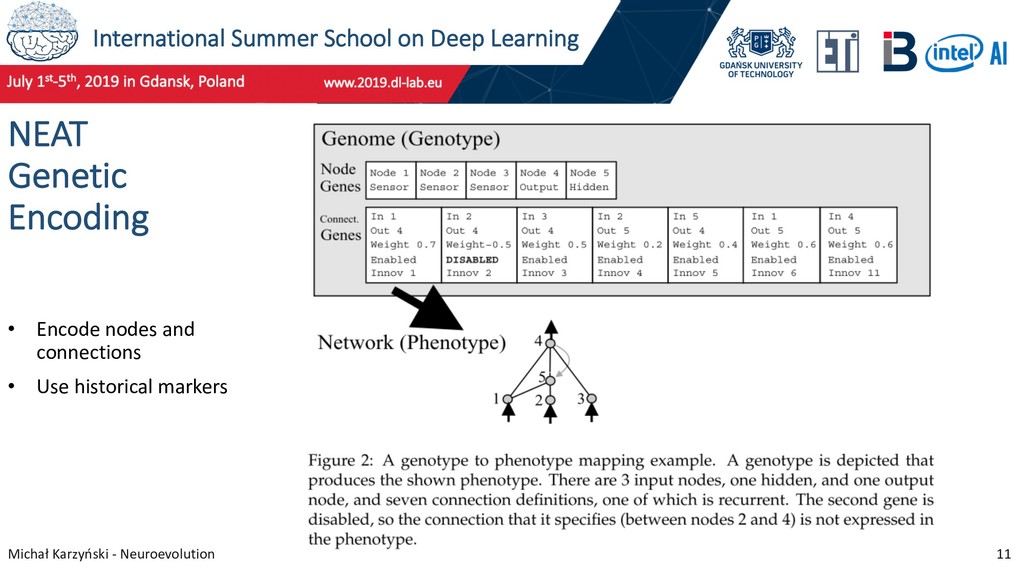
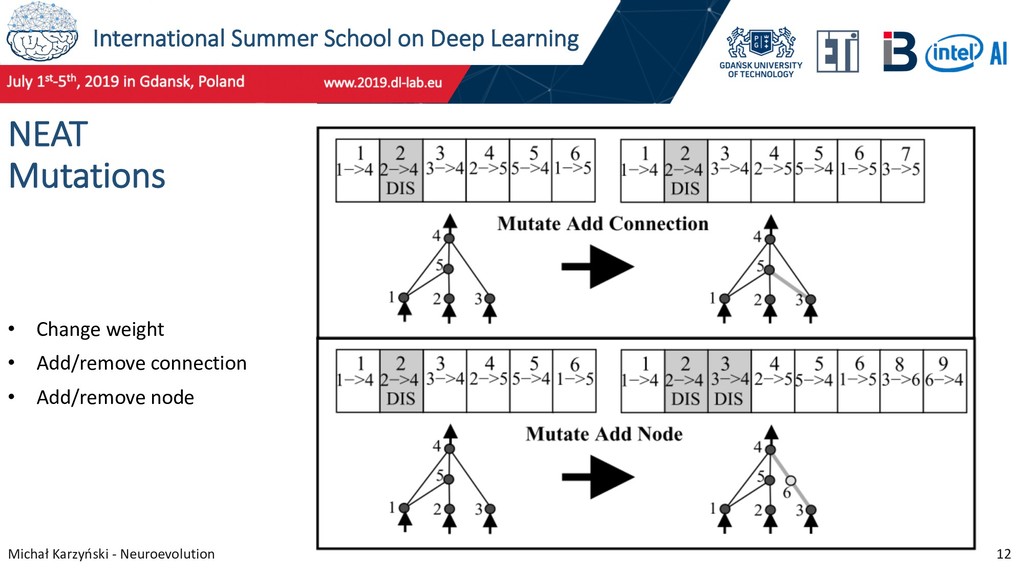
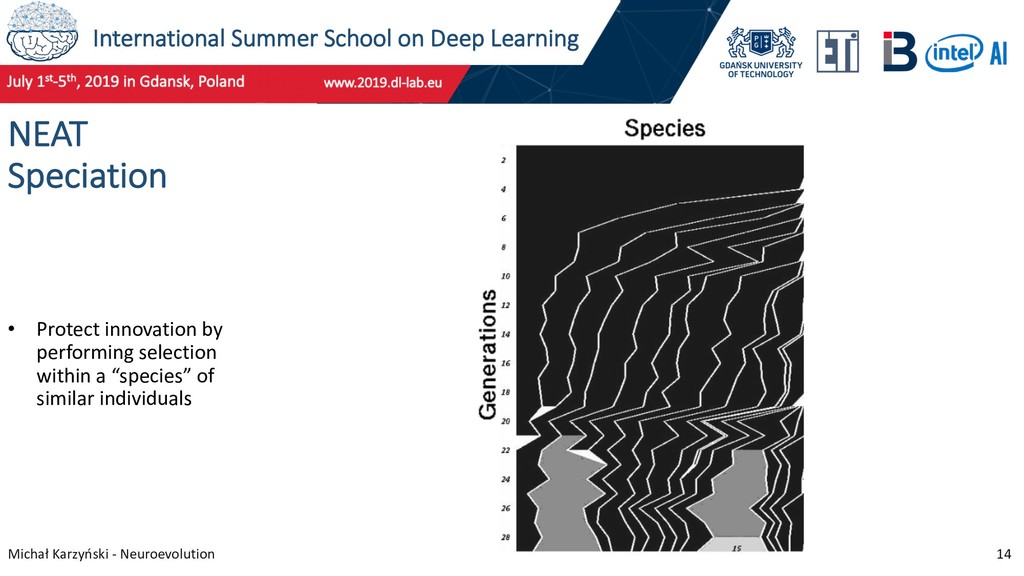
10 NeuroEvolution of Augmenting Topologies (NEAT) Research started in 2002, primarily led by Kenneth O. Stanley and Risto Miikkulainen at The University of Texas at Austin. NEAT algorithm features: • Allows crossover • Protects innovation through speciation • Starts with minimal genome (allow evolution to add only needed features) Stanley, K. O., & Miikkulainen, R. (2002). Evolving Neural Networks through Augmenting Topologies. Evolutionary Computation, 10(2), 99–127.
15 NEAT Ablation study • Evaluated on double pole balancing task (commonly used for reinforcement learning) • Evaluations: average number of individuals needed to complete task • Failure: no result within 1000 generations
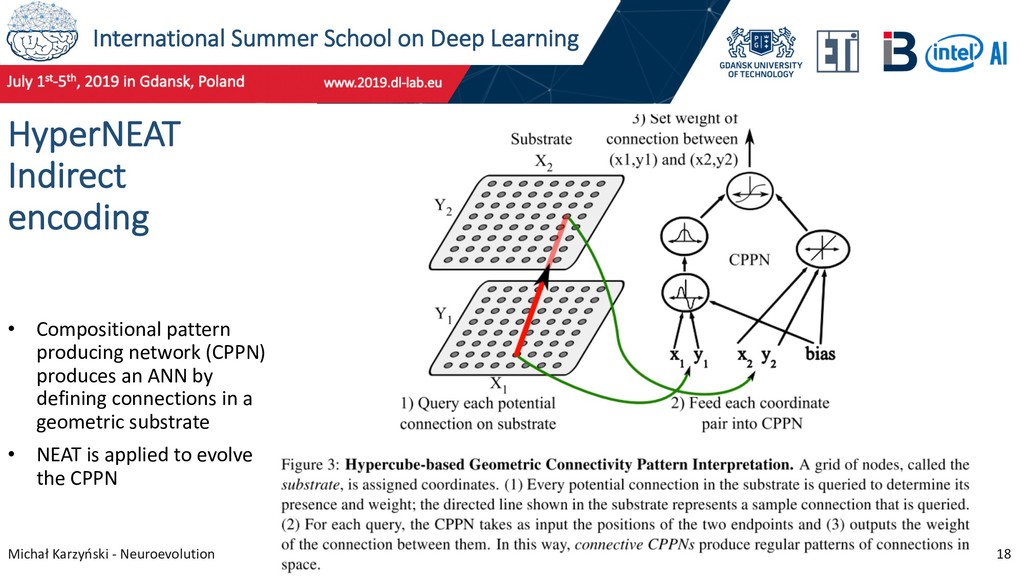
17 Hypercube-based NEAT (HyperNEAT) Builds on work on NEAT, starting around 2009. HyperNEAT extends NEAT by adding: • Mechanism simulating biological development • Indirect evolution – the developmental program is evolving, not the ANN itself • Substrate – ability to take advantage of spatial geometry of the problem domain Stanley, K. O., D’Ambrosio, D. B., & Gauci, J. (2009). A Hypercube-Based Encoding for Evolving Large-Scale Neural Networks. Artificial Life, 15(2), 185–212. Gauci, J., & Stanley, K. O. (2010). Autonomous Evolution of Topographic Regularities in Artificial Neural Networks - Neural Computation, 22(7), 1860–1898.
18 HyperNEAT Indirect encoding • Compositional pattern producing network (CPPN) produces an ANN by defining connections in a geometric substrate • NEAT is applied to evolve the CPPN
21 HyperNEAT Checkers • A CPPN calculates the weight of connections between the board and a hidden layer (AB) or the hidden layer and the output layer (BC) • Output of ANN is the score of the move to this position
24 Deep Neuroevolution • Builds on the success of deep neural networks (AlexNet, VGG, GoogLeNet, ResNet, etc.) • Steps away from building a custom feed-forward neural network edge-by-edge • Genes now represent layers of a deep neural network and their attributes (e.g.: type: Convolution, attributes: strides, padding, output channels, etc.) • Mutations can add or remove layers, change their type or attribute values • Combines two search algorithms: genetic algorithms for architecture search and backpropagation for training
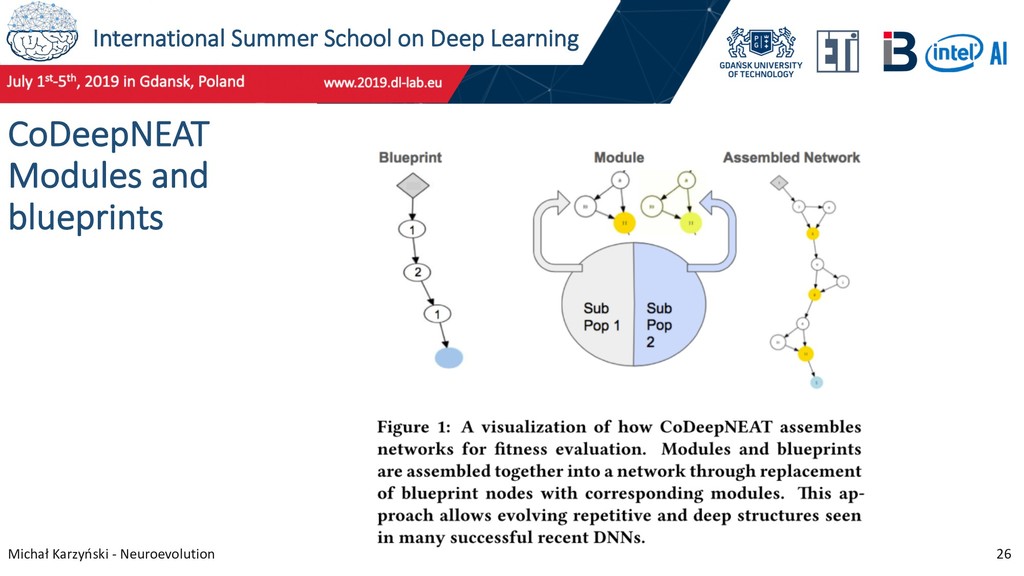
25 CoDeepNEAT Research on NEAT continues into the Deep Neuroevolution era at Cognizant, an AI startup. DeepNEAT - NEAT approach is used, but each node in a chromosome now represents a network layer. CoDeepNEAT – two populations of modules and blueprints are evolved separately using DeepNEAT. The blueprint chromosome is a graph where each node contains a pointer to a particular module species. For fitness evaluation, the modules and blueprints are combined to create an ANN. Miikkulainen, R. et al. (2017). Evolving Deep Neural Networks.
27 CoDeepNEAT CIFAR-10 • 92.7% accuracy on CIFAR-10 • Training time was limited, so evolutionary pressure created fast training networks (120 epoch to converge)
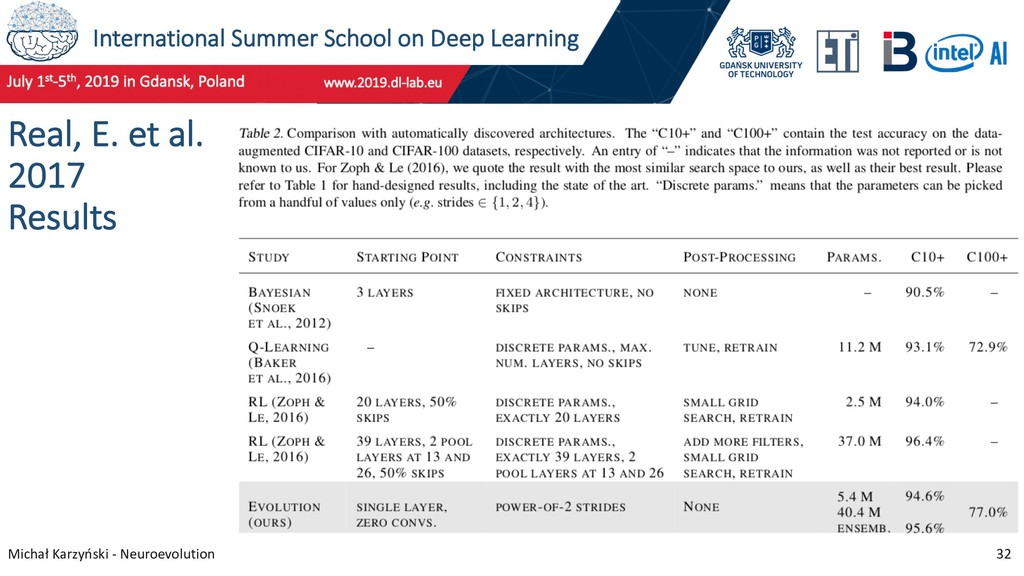
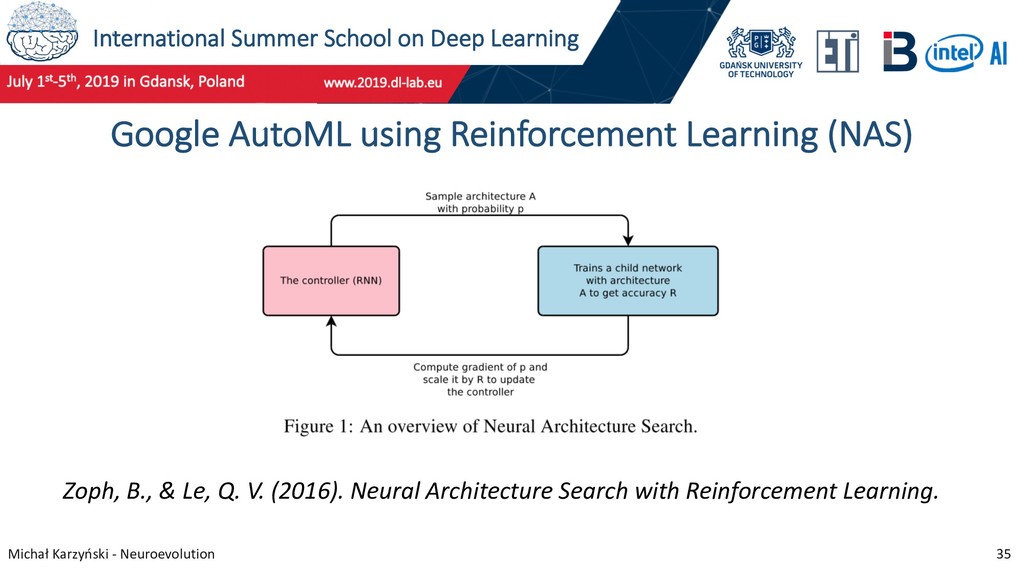
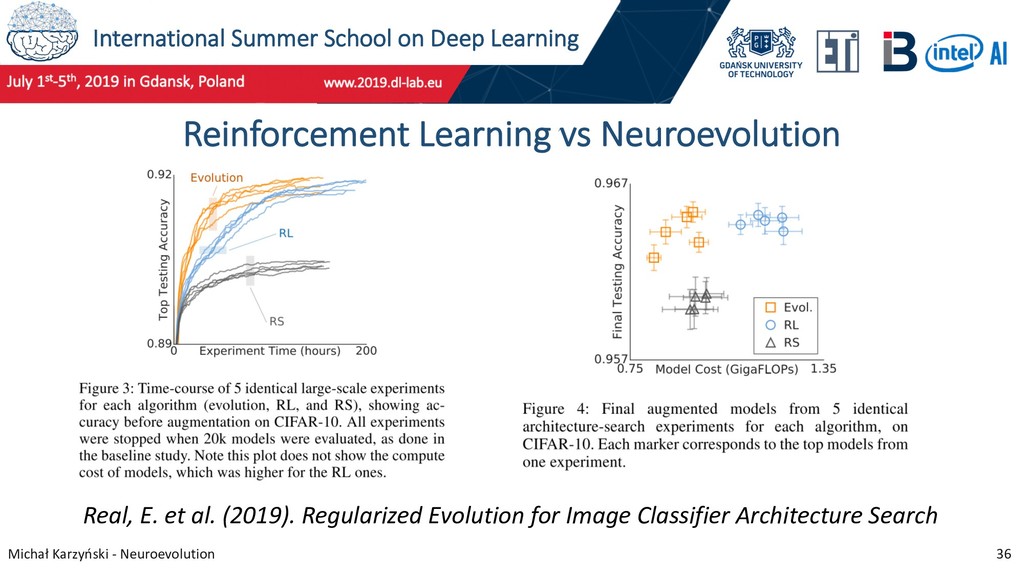
29 Neuroevolution research at Google Teams at Google Brain and DeepMind are working on neural architecture search methods based on genetic algorithms. In 2017 they published an influential paper on evolving image classifiers and achieved 94.6% accuracy on CIFAR-10 with no human participation in neural network design. Real, E. et al. (2017). Large-Scale Evolution of Image Classifiers
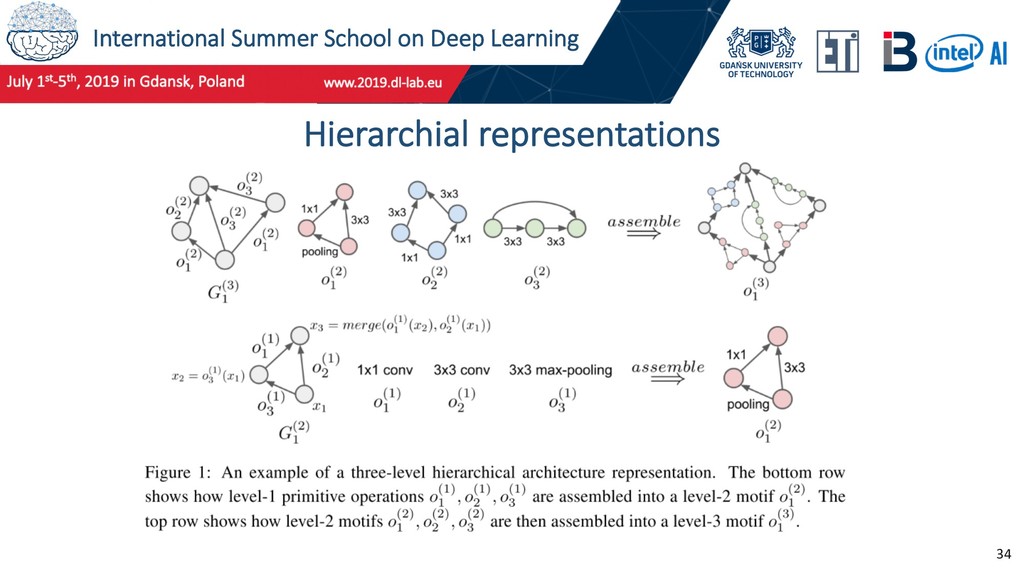
by reusable modules in human-created networks such as Inception, ResNet, etc. Build up more complex structures from simpler ones. Results in much faster evolution than a non-hierarchial representation. Similar in concept to modules and blueprints of CoDeepNEAT. Liu, H., Simonyan, K., Vinyals, O., Fernando, C., & Kavukcuoglu, K. (2017). Hierarchical Representations for Efficient Architecture Search
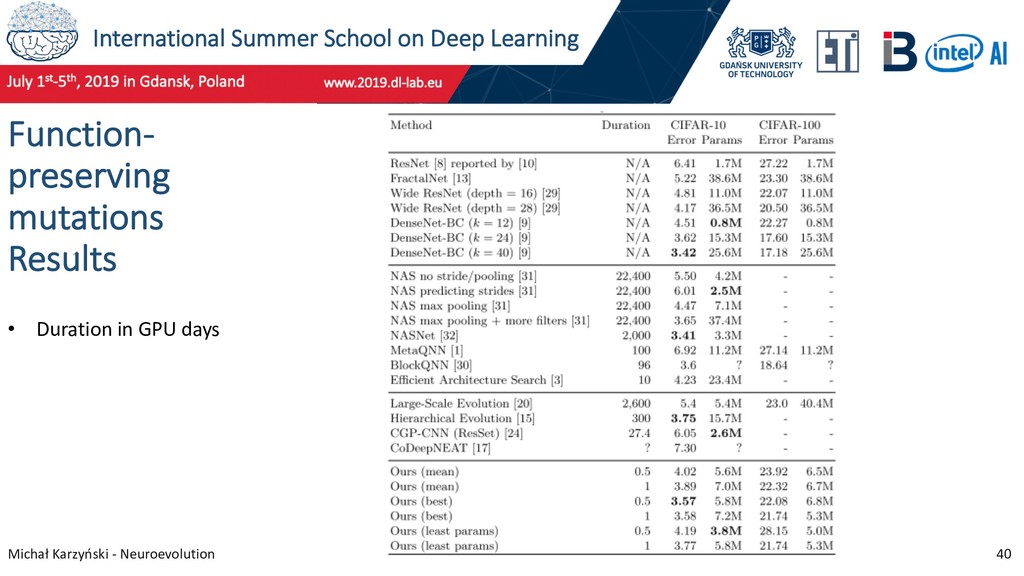
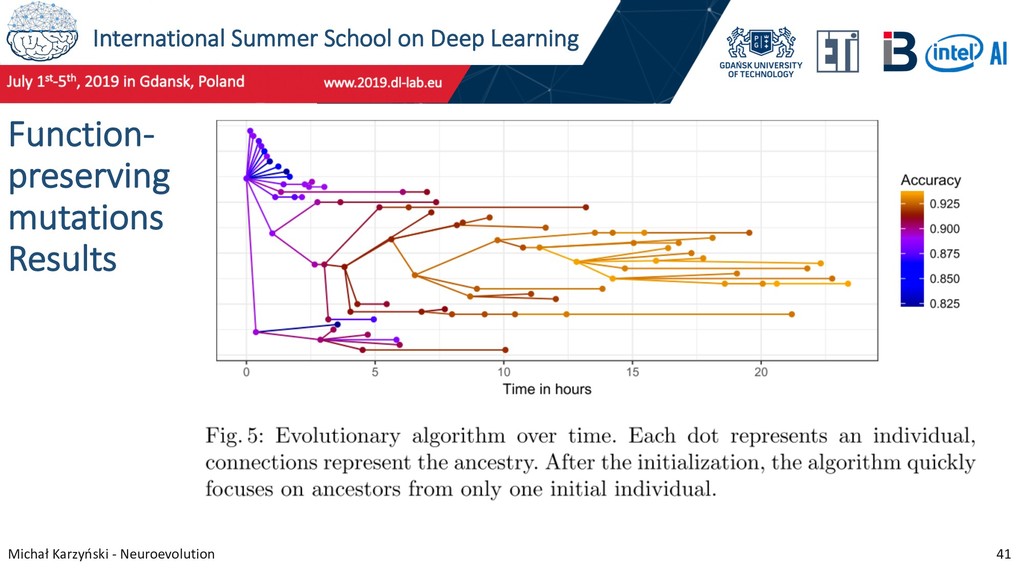
37 Function-preserving mutations New research performed at IBM, based on work by Chen et al. (ICLR, 2016), who proposed function-preserving transformations for transfer learning. Chen, T., Goodfellow, I., & Shlens, J. (2016). Net2Net: Accelerating Learning via Knowledge Transfer
38 Function-preserving mutations Martin Wistuba at IBM described the following function-preserving transformations: • Layer Widening – increase the number of filters in a convolutional layer • Layer Deepening – deepen a network by inserting an additional convolutional or fully connected layer • Kernel Widening – increase the kernel size in a convolutional layer by padding with zeros • Insert Skip Connections – initialize connection weights to produce zeros • Branch Layers – insert branching into network Wistuba, M. (2019). Deep learning architecture search by neuro-cell-based evolution with function-preserving mutations.
39 Function-preserving mutations He used them to create a set of function-preserving mutations: • Insert Convolution • Branch and Insert Convolution • Insert Skip • Alter Number of Filters • Alter Number of Units • Alter Kernel Size • Branch Convolution
42 Takeaways • AutoML is a powerful technique, starting to outperform human ability • Neuroevolution is a viable approach to AutoML • Research in the are is ongoing and likely to generate results in near future • Computational costs are very high and put a limit on research
43 Takeaways • Deep Neuroevolution combines evolutionary search with weight training by backpropagation • Lamarckian evolution – passing on learned weight to the next generation improves search performance • Function-preserving mutations make Lamarckian evolution possible • Efficient methods perform multi-level evolution: smaller modules and larger networks
44 Interesting research questions • What is the best genome encoding for Neuroevolution? • What other mutations can be added to the search? • Can “substrate geometry” be used in Deep Neuroevolution (like in HyperNEAT)? • Will a training network (RL) approach be more efficient than evolutionary search? • We need good open-source frameworks for Deep Neuroevolution research
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}