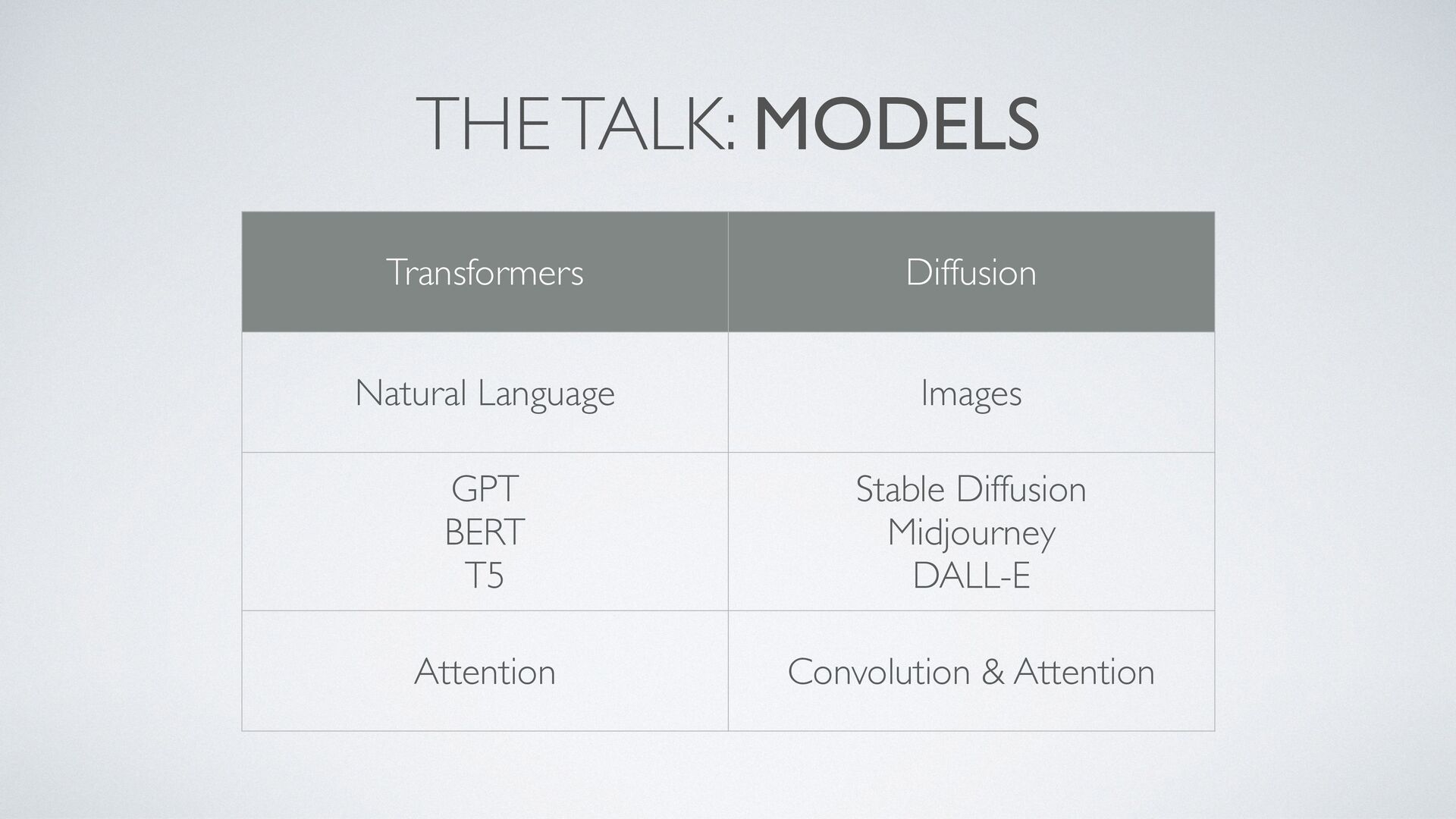
Neural networks have revolutionized AI, enabling machines to learn from data and make intelligent decisions. In this talk, we'll explore two popular architectures: Attention models and Diffusion models.
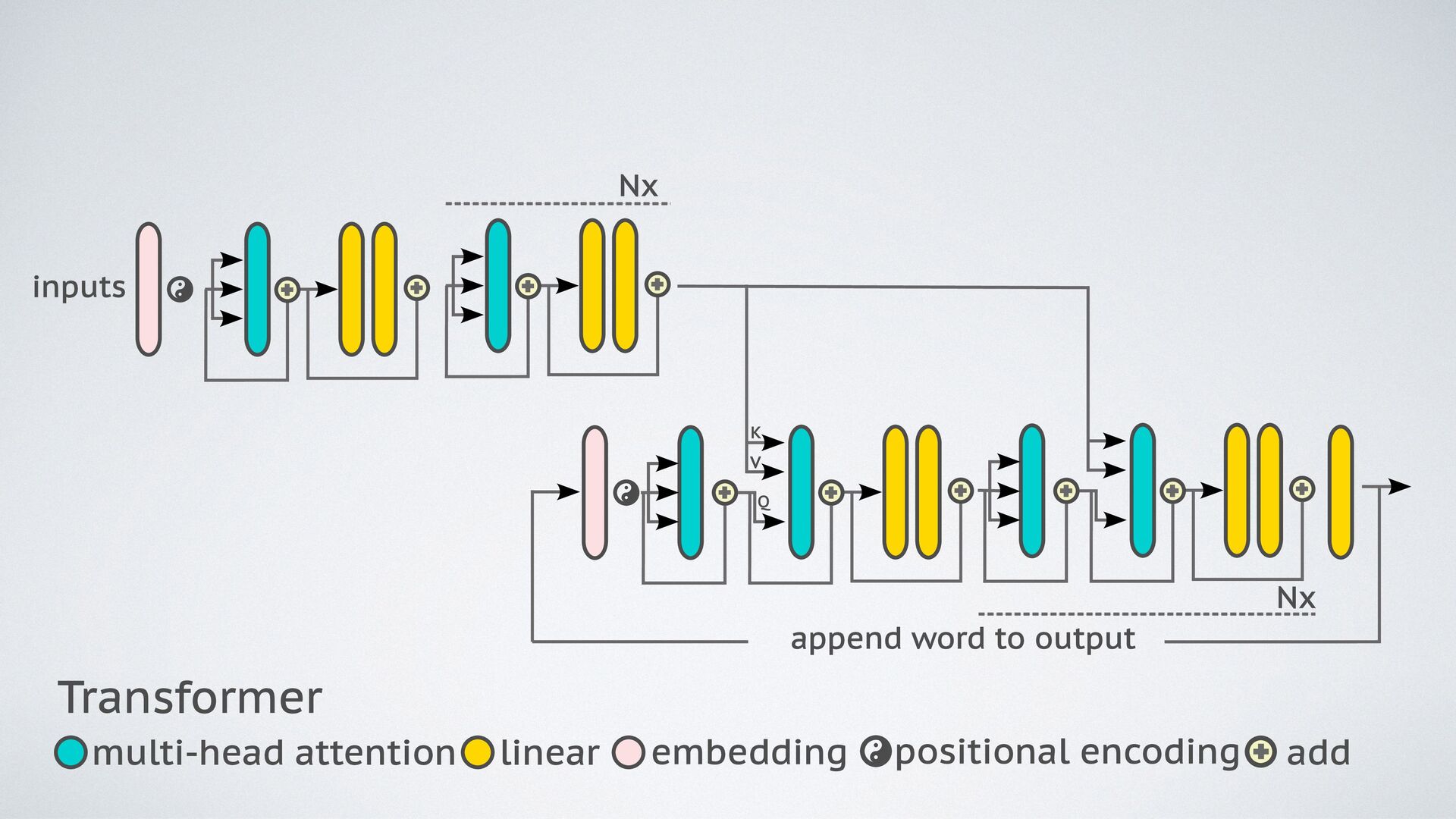
First up, we'll discuss Attention models and how they've contributed to the success of large language models like ChatGPT. We'll explore how the Attention mechanism helps GPT focus on specific parts of a text sequence and how this mechanism has been applied to different tasks in natural language processing.
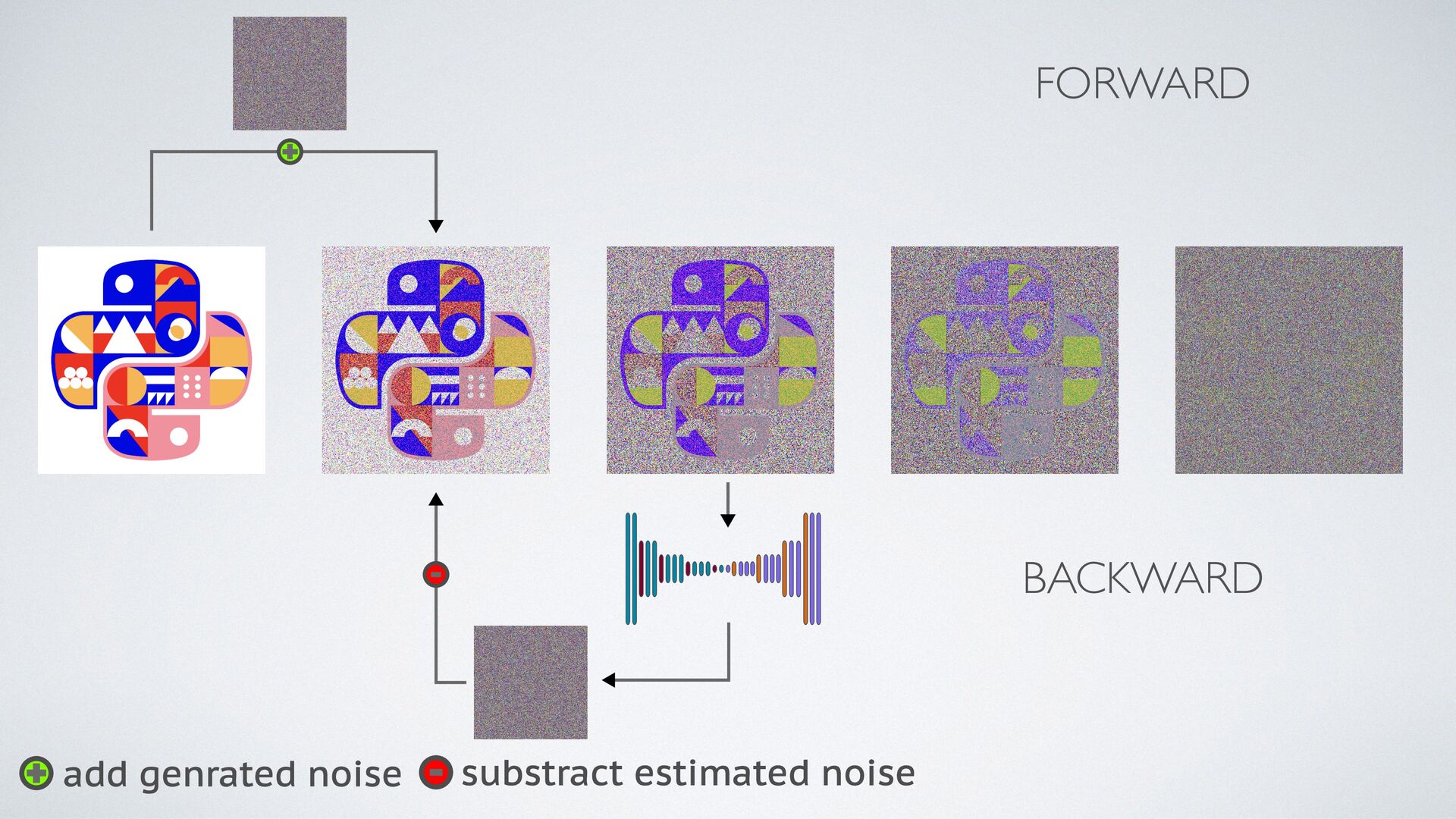
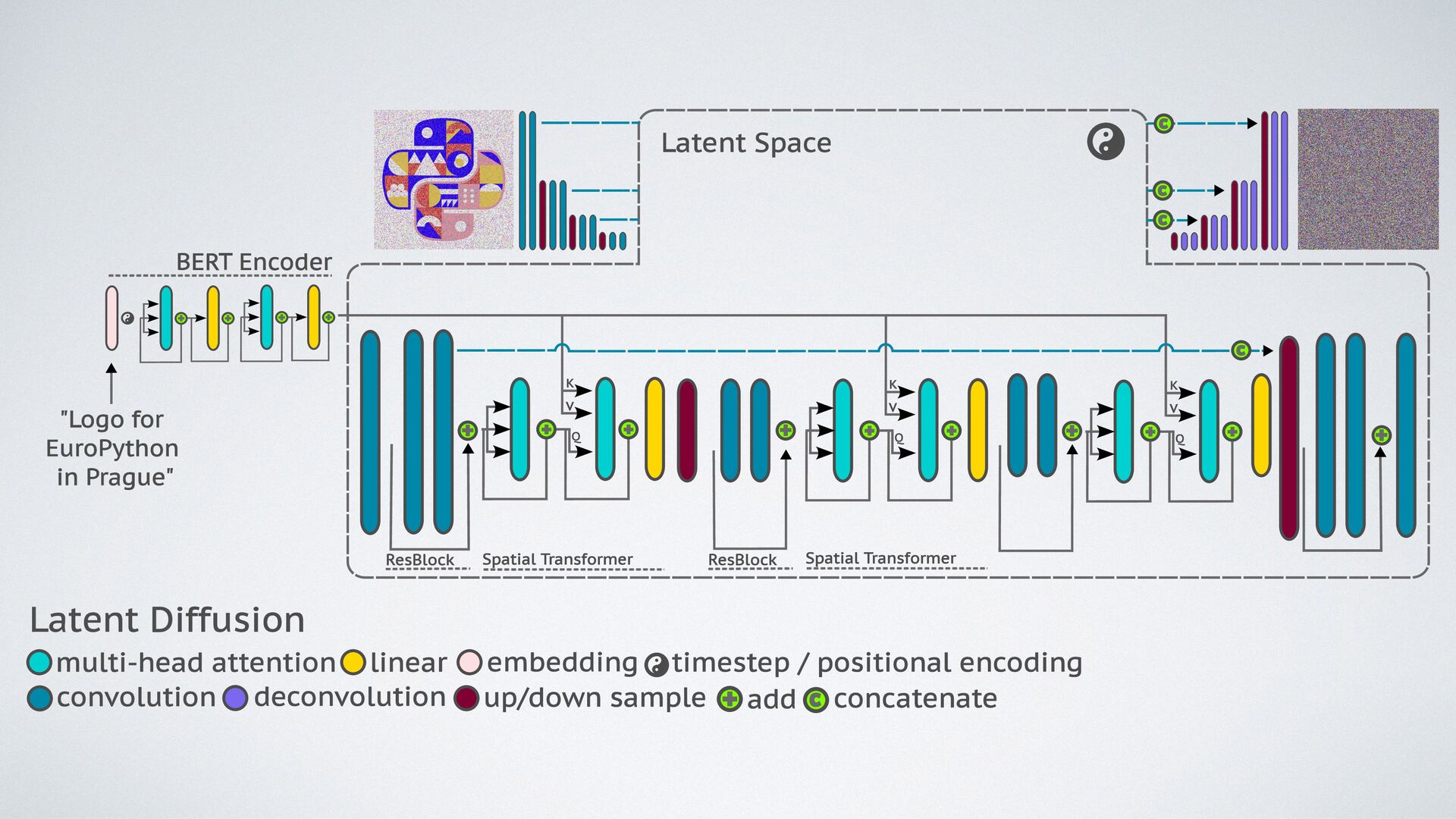
Next, we'll dive into Diffusion models, a class of generative models that have shown remarkable performance in image synthesis. We'll explain how they work and their potential applications in the creative industry.
By the end of the talk, you'll have a better understanding of these cutting-edge neural network architectures.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
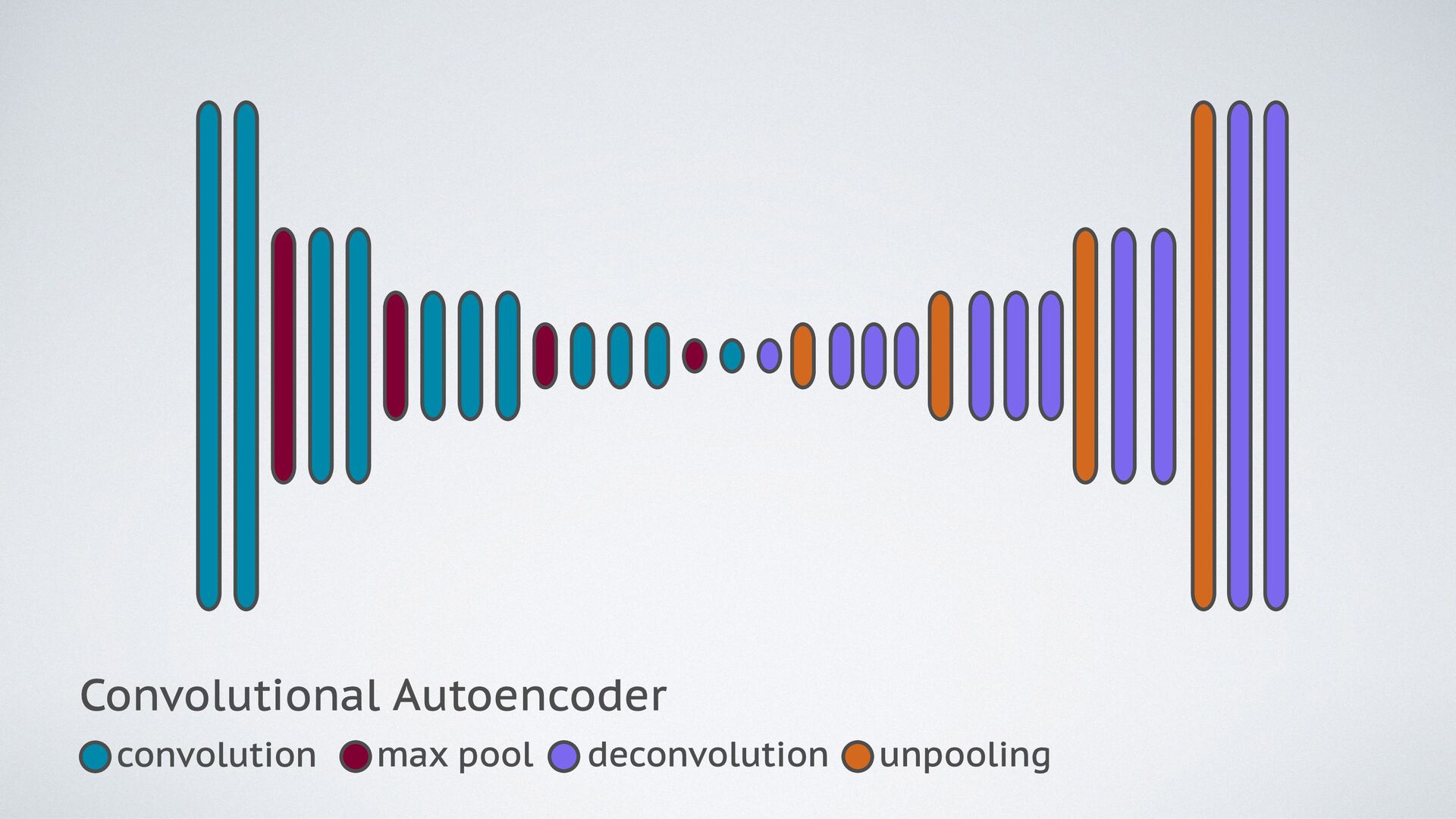{kind=link}
{kind=link}
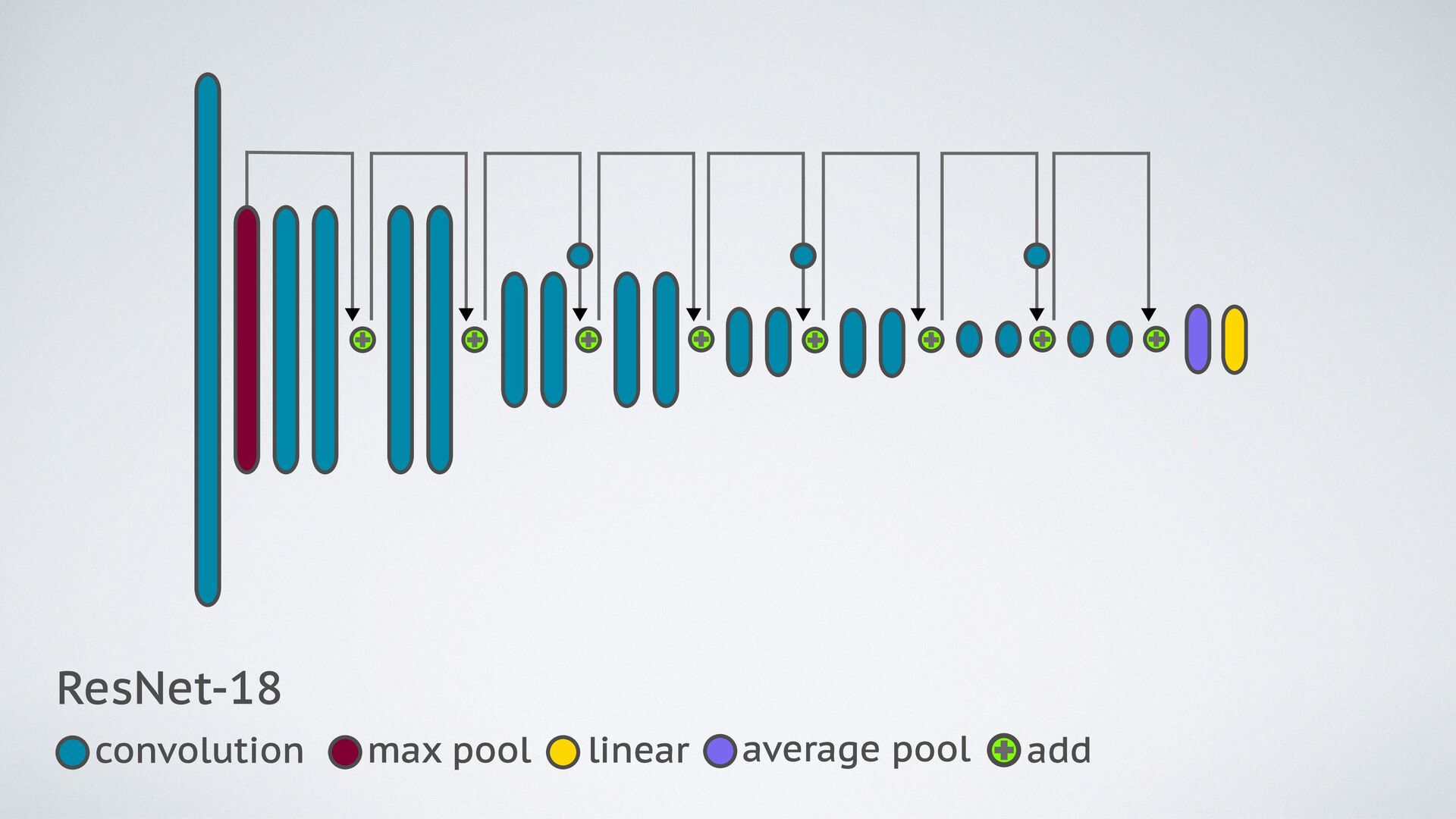{kind=link}
{kind=link}
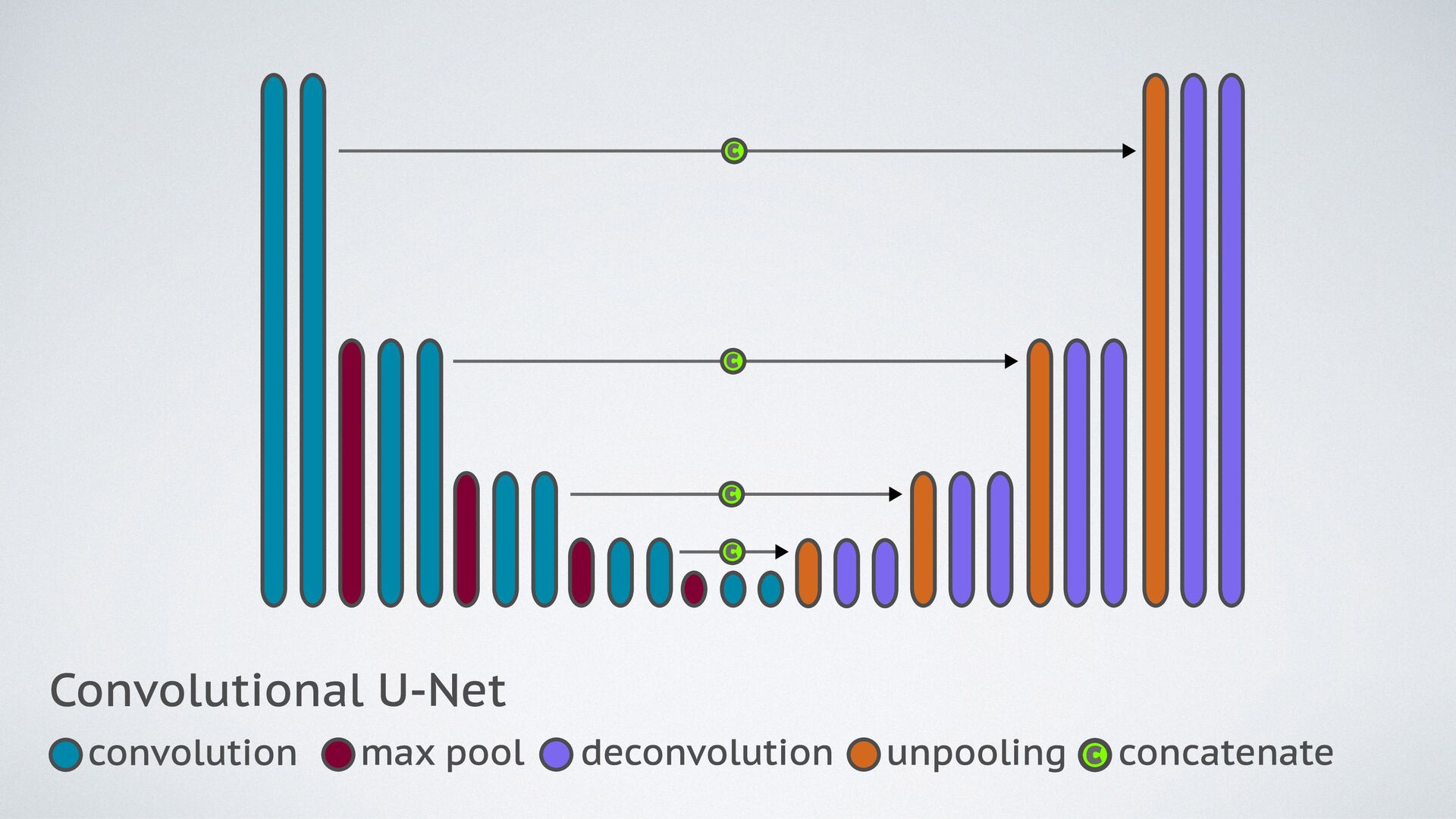{kind=link}
{kind=link}
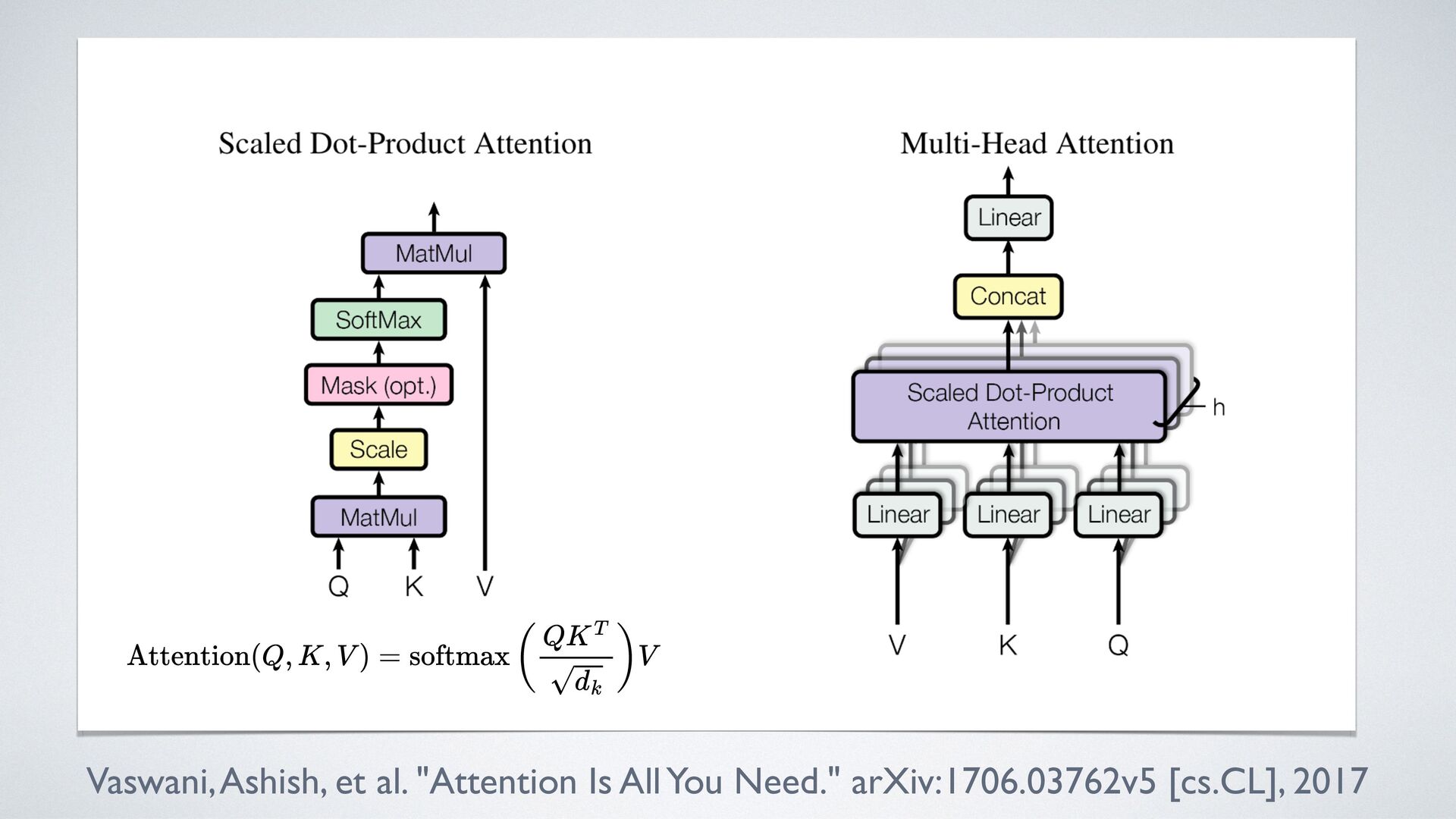{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}