Share
第三回 全日本コンピュータビジョン勉強会 CVPR2020読み会@オンライン(前編)
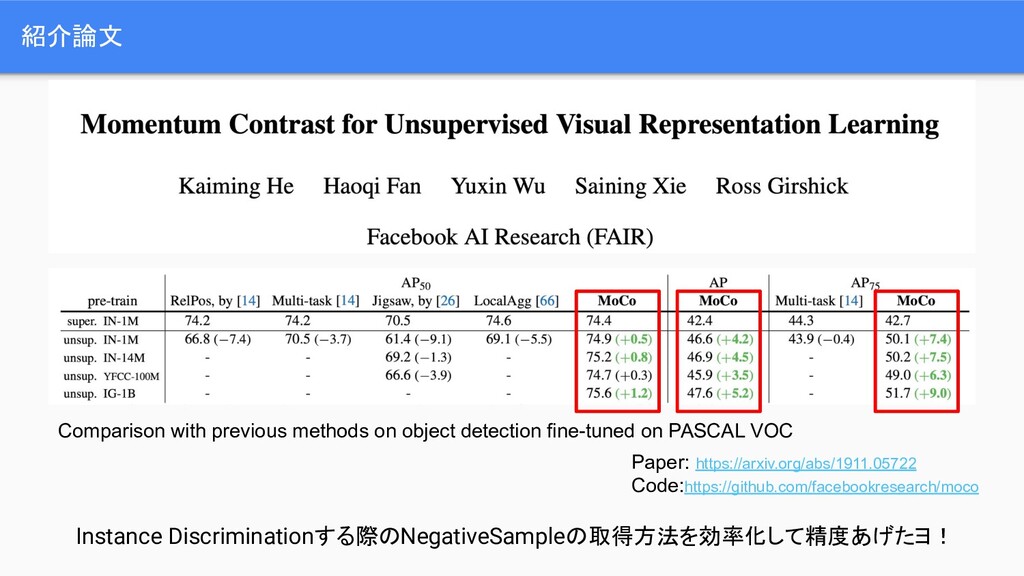
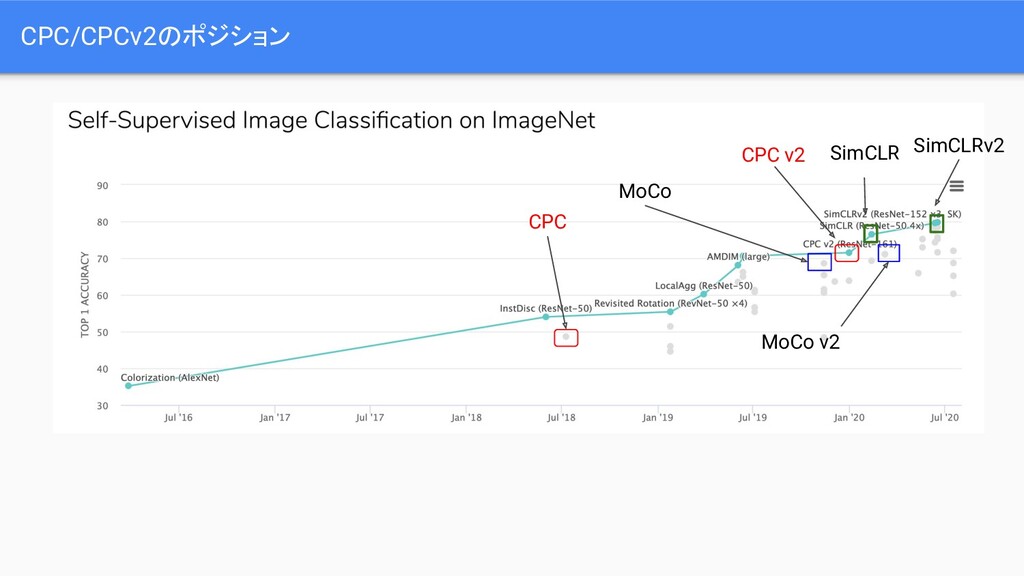
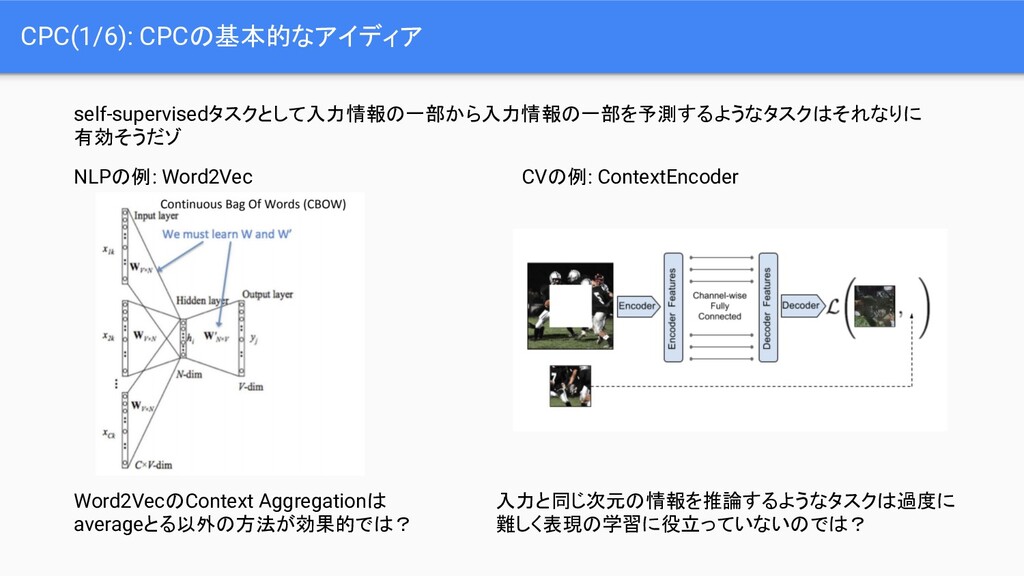
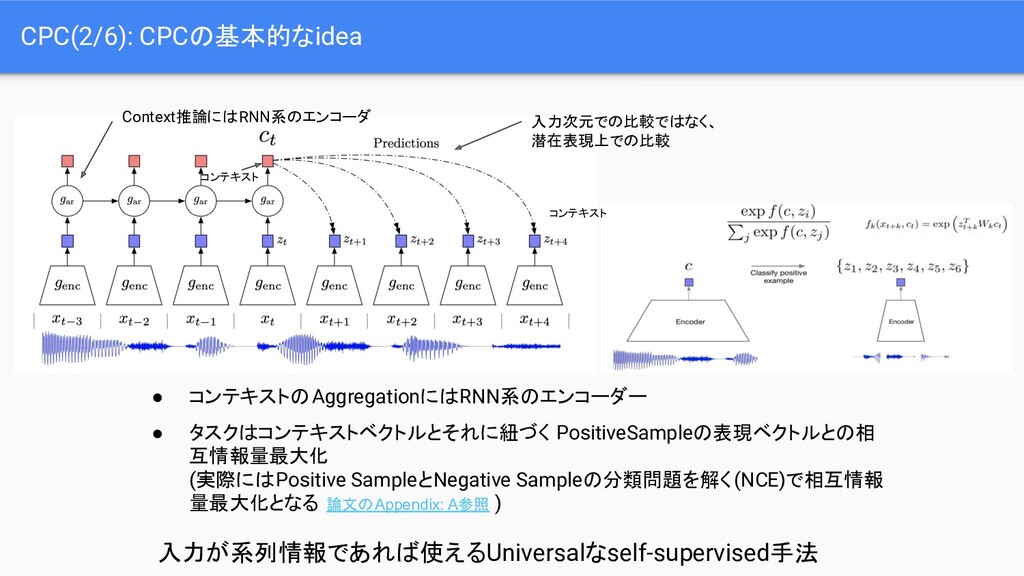
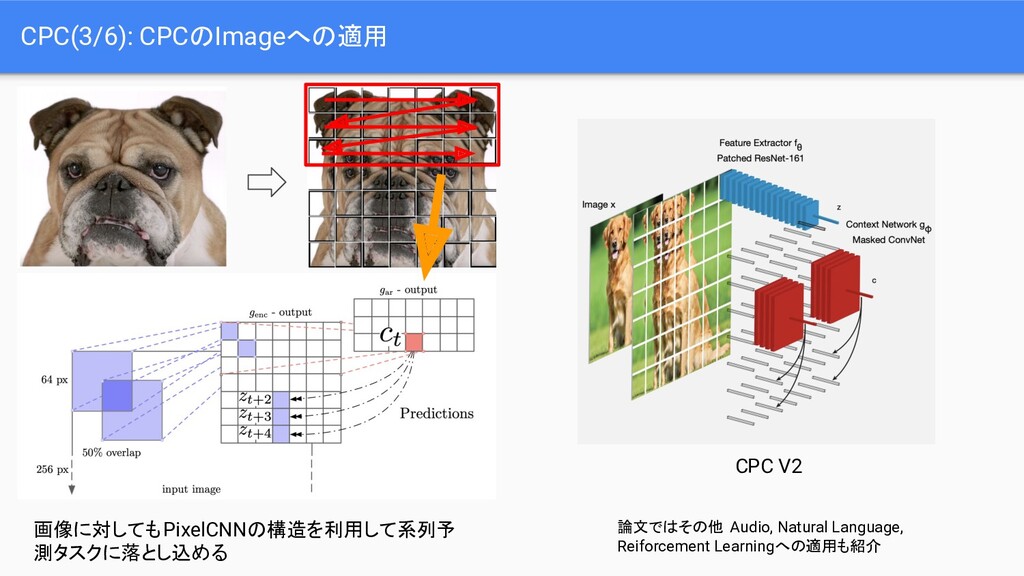
Momentum Contrast for Unsupervised Visual Representation Learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
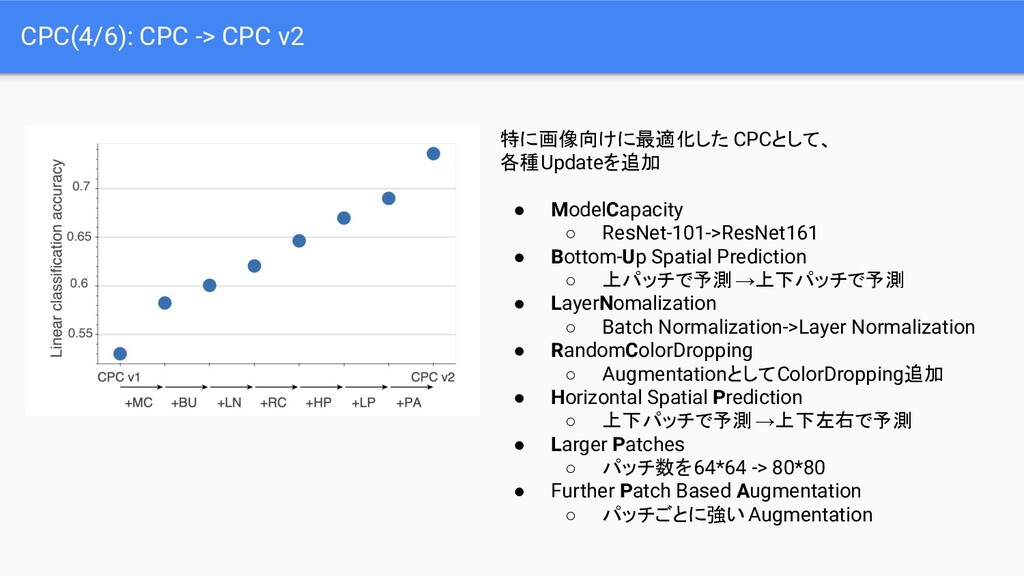{kind=link}
{kind=link}
{kind=link}
{kind=link}
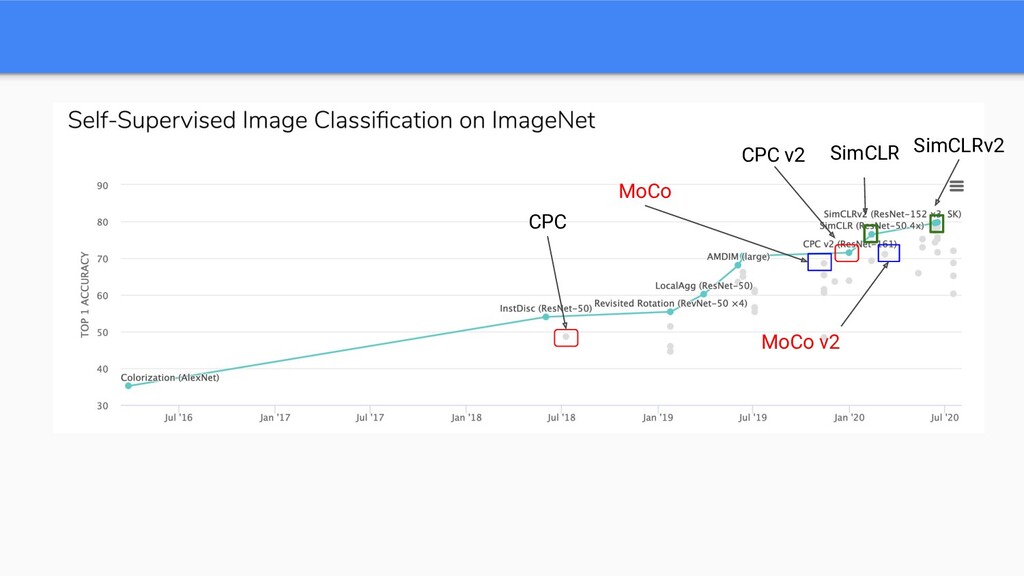{kind=link}
![other image Instance Discrimination [1805.01978] Unsupervised Feature Learning via Non-Parametric](https://files.speakerdeck.com/presentations/cc1ac2d9b6c34ceb99fd28ddad1162e2/slide_15.jpg){kind=link}
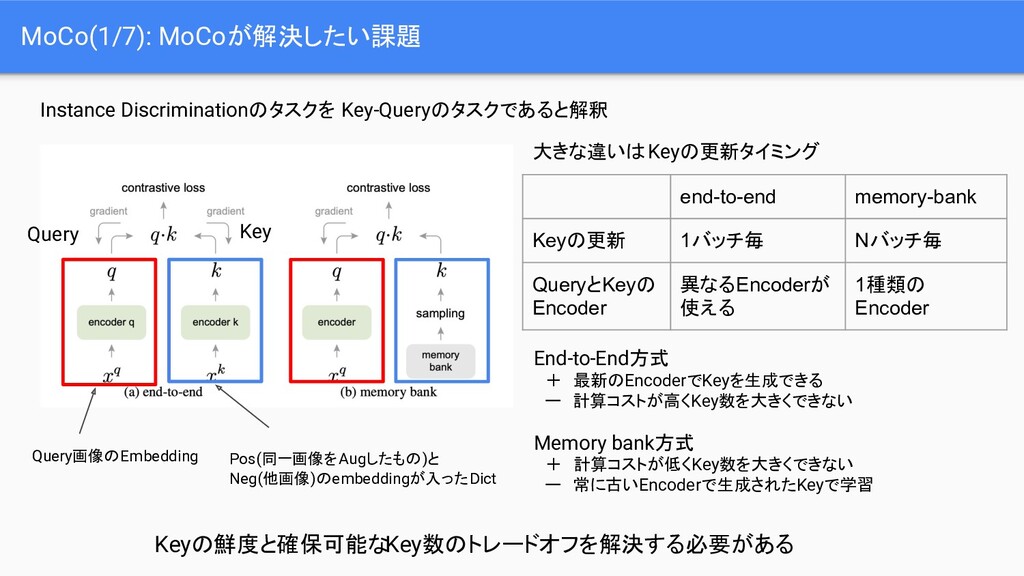{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
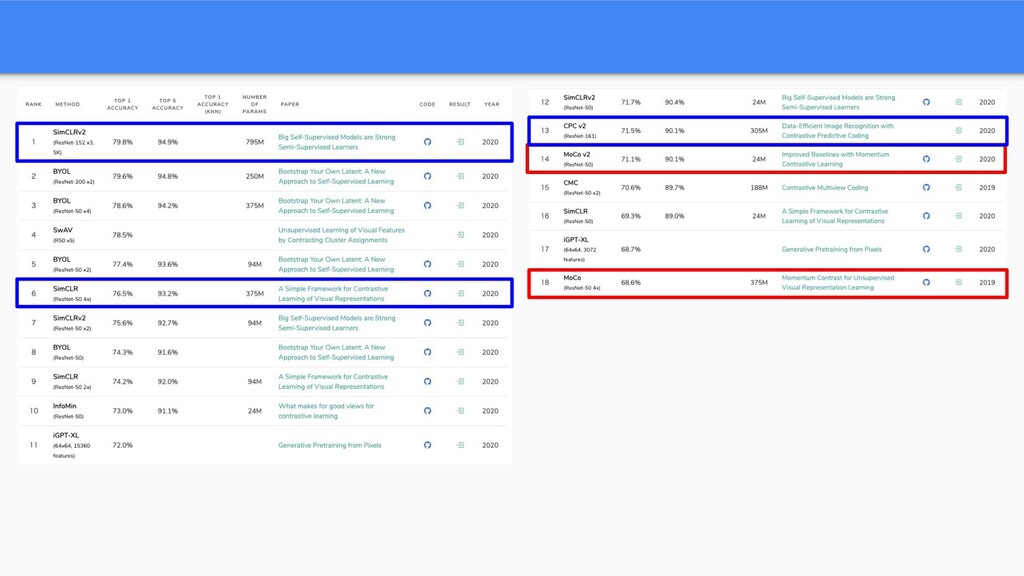{kind=link}
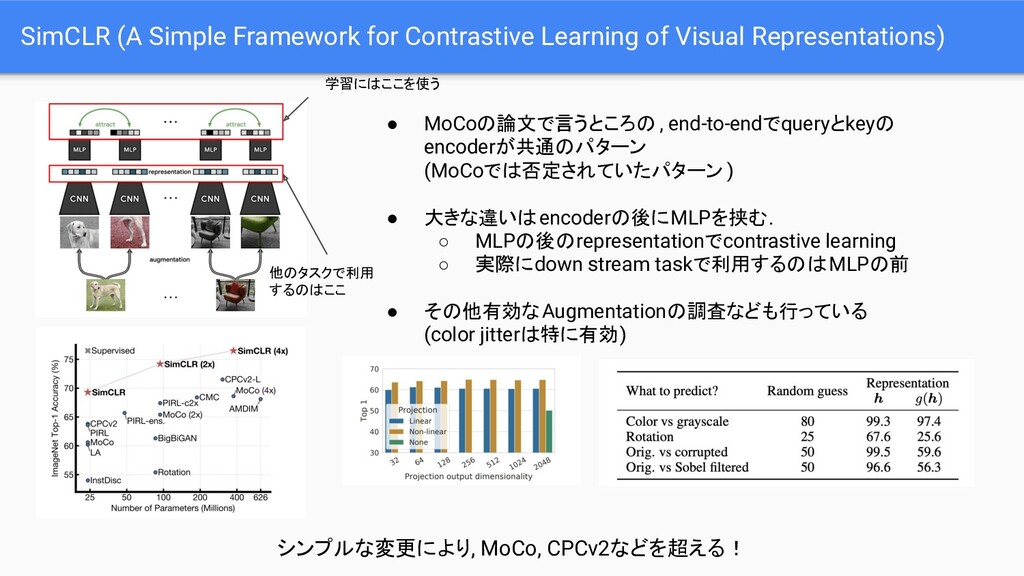{kind=link}
{kind=link}
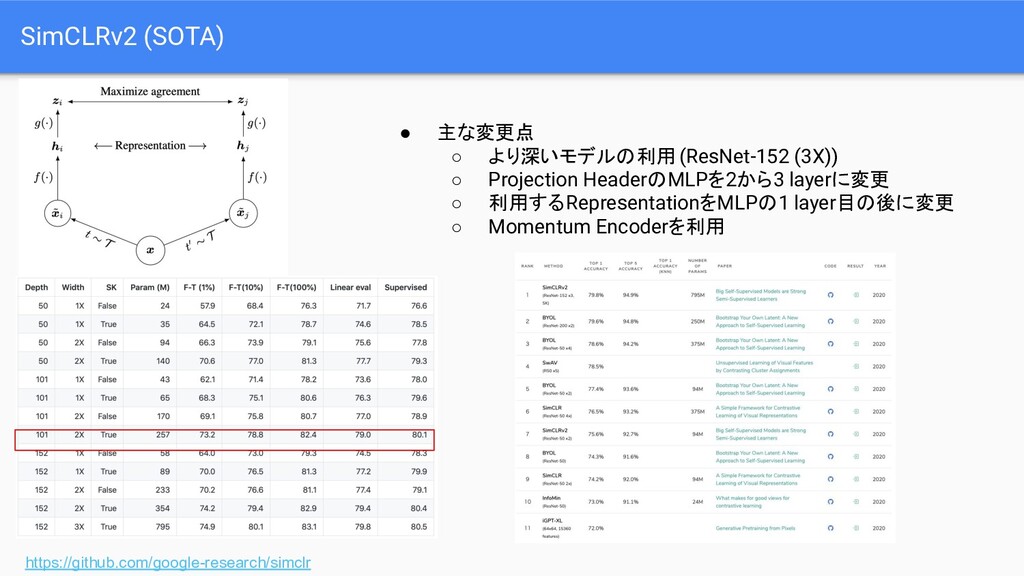{kind=link}
{kind=link}